一、银行贷款案例最初版
通过网盘分享的文件:creditcard.csv
链接: https://pan.baidu.com/s/175T6Pjb_BWcc47S1bCciSQ 提取码: qm8f
python
import pandas as pd
from sklearn.model_selection import train_test_split
a=pd.read_csv('creditcard.csv')
x=a.drop('Class',axis=1)
y=a.Class
x_train,x_test,y_train,y_test=(train_test_split(x,y,test_size=0.3,random_state=1000))
from sklearn.linear_model import LogisticRegression
lr=LogisticRegression(C=0.01,max_iter=1000)
lr.fit(x_train,y_train)
from sklearn import metrics
train_predict=lr.predict(x_train)
train_sroce=lr.score(x_train,y_train)
print("自测准确率",train_sroce)
print("自测评估验证:")
print(metrics.classification_report(y_train,train_predict))
test_predict=lr.predict(x_test)
test_score=lr.score(x_test,y_test)
print("测试准确率",test_score)
print("测试评估验证")
print(metrics.classification_report(y_test,test_predict))执行结果:
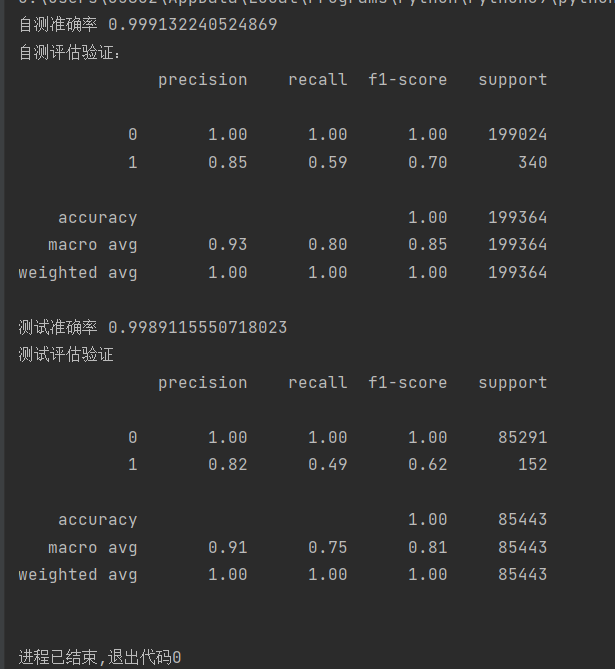
可以看到执行结果中准确率达到了0.99,以及是非常高的概率了,但是能不能直接使用呢,答案是不能的,为什么不能呢?
原因:接下来以一个实例来协助理解
实例:
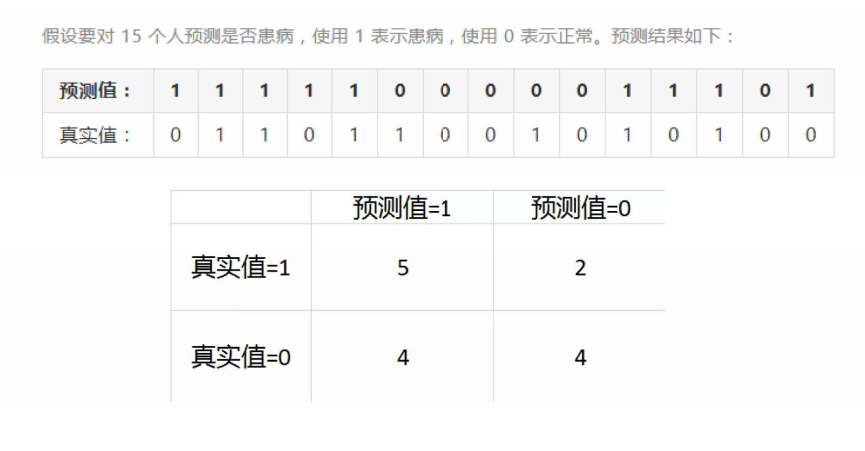


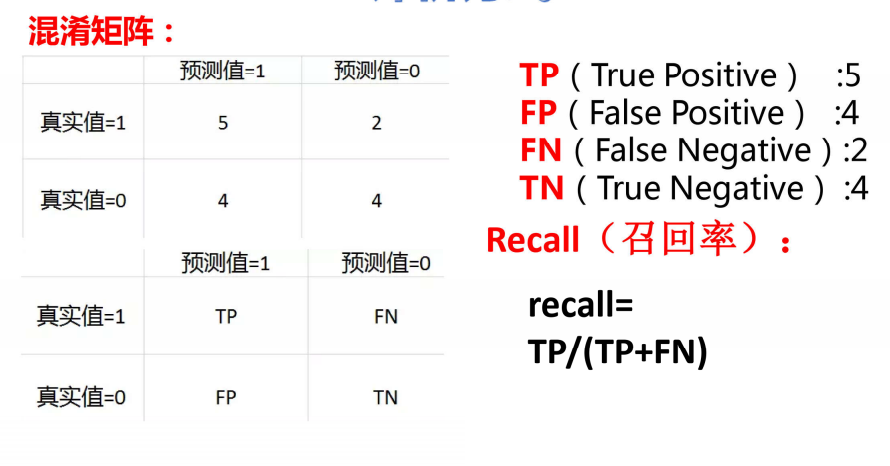

在这个实例中,我们应该注重的不是准确率,而是召回率,因为当如果一个人没有患病,机器检查出患病,只是让这个人再去看一次专家确定是否真的患病,但如果一个人患病,但是机器检查出没有患病,那么这个人就以为自己没患病,但实际这个人是患病的,那造成的后果是巨大的,所以在做训练时,我们要更加注重召回率,在上面的银行贷款案例中,我们可以看到召回率自测是0.59,而测试只有0.49左右,不是很高,那么我们应该怎么更改代码使得召回率增高呢
我们可以通过改变上面代码中C的值来增高召回率(C的值一般为0.001,0.01,0.1,1,10,100)
那么应该怎么得到C为多少时,召回率最大,这时候我们既可以用到交叉验证
二、银行贷款案例交叉验证版
python
'''加了交叉验证'''
import pandas as pd
import numpy as np
from sklearn.preprocessing import scale
def cm_plot(y,yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y,yp)
plt.matshow(cm,cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y],xy=(y,x),horizontalalignment='center',verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
data=pd.read_csv('creditcard.csv')
data['Amount']=scale(data[['Amount']])
a=data.drop(['Time'],axis=1)
from sklearn.model_selection import train_test_split
x=a.drop('Class',axis=1)
y=a.Class
x_train,x_test,y_train,y_test=(train_test_split(x,y,test_size=0.3,random_state=0))
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
scores=[]
c_param_range=[0.001,0.01,0.1,1,10,100]
for i in c_param_range:
lr=LogisticRegression(C=i,penalty='l2',solver='lbfgs',max_iter=1000)
score=cross_val_score(lr,x_train,y_train,cv=10,scoring='recall')
score_mean=sum(score)/len(score)
scores.append(score_mean)
print(score_mean)
best=c_param_range[np.argmax(scores)]
print("最优C值:",best)
lr=LogisticRegression(C=best,penalty='l2',solver='lbfgs',max_iter=1000)
from sklearn import metrics
lr.fit(x_train,y_train)
train_predict=lr.predict(x_train)
print("自测评估验证:")
print(metrics.classification_report(y_train,train_predict))
#自测混淆矩阵可视化
cm_plot(y_train,train_predict).show()
test_predict=lr.predict(x_test)
print("测试评估验证:")
print(metrics.classification_report(y_test,test_predict,digits=6))
#测试混淆矩阵可视化
cm_plot(y_test,test_predict).show()执行结果:
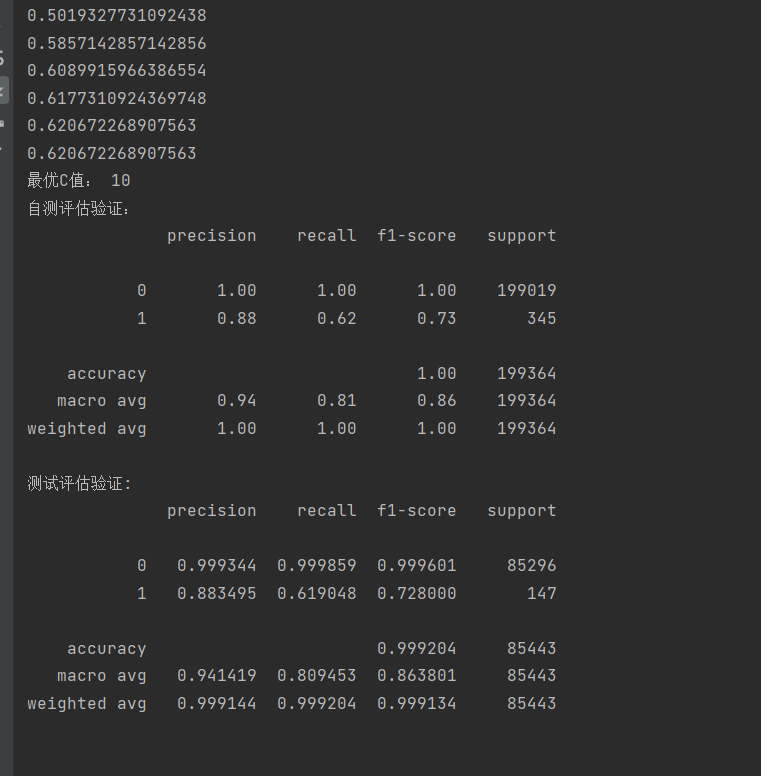
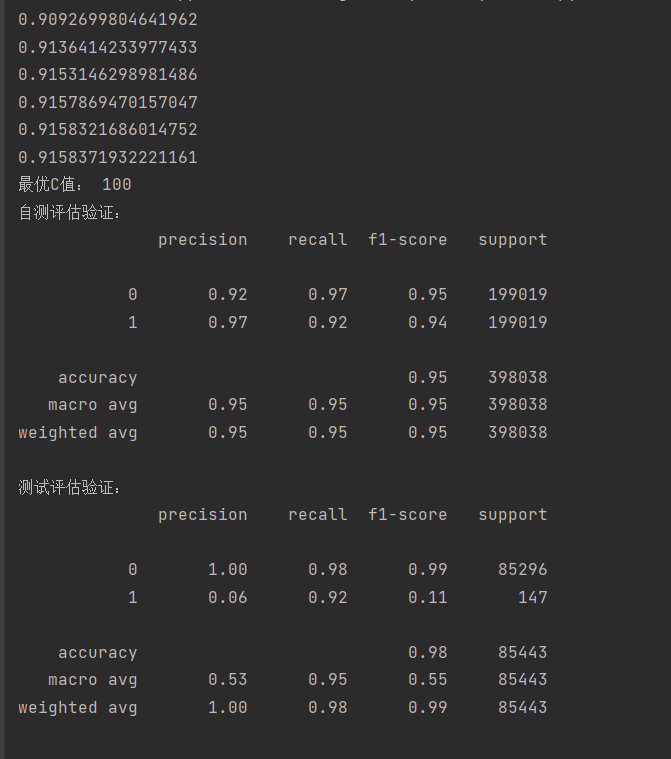
可以看到在进行交叉验证后,召回率增加到了0.62左右
需要注意的是在
score=cross_val_score(lr,x_train,y_train,cv=10,scoring='recall')代码中scoring='recall',是以召回率作为评估指标,若你的实例以的是精确率或者是别的,你也可以改成其他,但若使用召回率,recall只能使用在二分类中,想要在多分类中使用召回率作为评估指标,需要使用下图的一些参数

大多数情况下用 'weighted' ,因为它在 recall 后面加上了对类别不平衡的考虑。
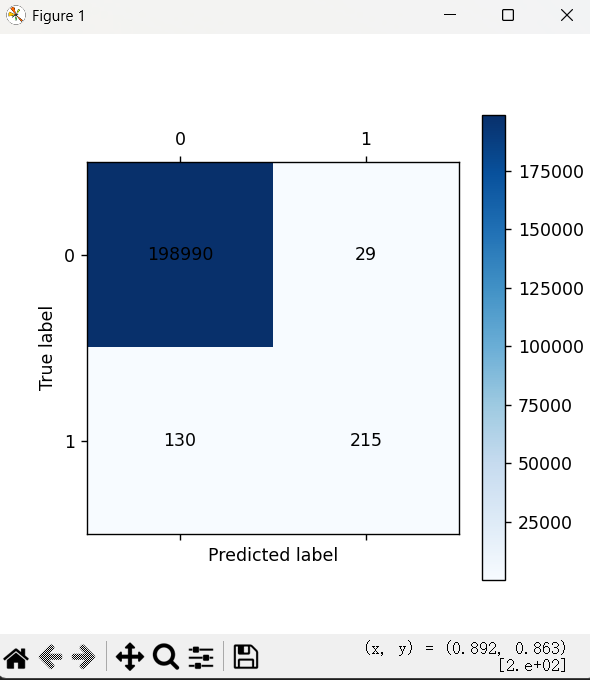
在代码中我们还进行了混淆矩阵的可视化处理,即
训练集:
测试集:
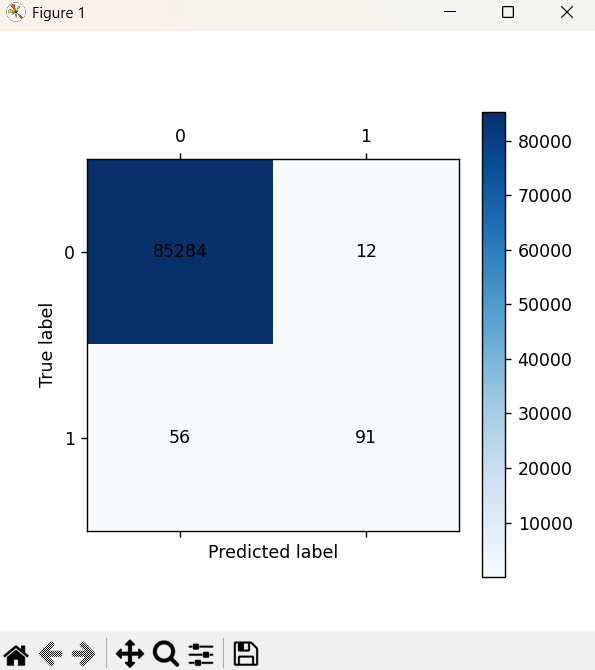
但仅仅使用交叉验证得到的召回率还不能直接使用,因为太低了,这时候我们能怎么做呢?
三、银行贷款案例下采样版
在这个银行贷款案例的数据中,我们可以看到大部分结果都是0,只有一小部分是1,这就使得训练的0和1的数据不平均,也会使用召回率不高,这时我们可以进行下采样,只采取等量的0和1数据进行训练
python
import pandas as pd
import numpy as np
from sklearn.preprocessing import scale
def cm_plot(y,yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y,yp)
plt.matshow(cm,cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y],xy=(y,x),horizontalalignment='center',verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
data=pd.read_csv('creditcard.csv')
data['Amount']=scale(data[['Amount']])
a=data.drop(['Time'],axis=1)
from sklearn.model_selection import train_test_split
x1=a.drop('Class',axis=1)
y1=a.Class
#选取0.7份作为训练集,0.3份作为测试集
x_train,x_test,y_train,y_test=(train_test_split(x1,y1,test_size=0.3,random_state=0))
x_train['Class']=y_train
data.train=x_train
# 在训练集中分别选取结果为0和结果为1的数据
one=data.train[data.train['Class']==1]
b=data.train[data.train['Class']==0]
# 选取和结果为1等量的数据
c=b.sample(len(one))
#将两份等量的数据再重新组合成一个列表
d=pd.concat([one,c])
x=d.drop('Class',axis=1)
y=d.Class
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
scores=[]
c_param_range=[0.001,0.01,0.1,1,10,100]
for i in c_param_range:
lr=LogisticRegression(C=i,penalty='l2',solver='lbfgs',max_iter=1000)
score=cross_val_score(lr,x,y,cv=10,scoring='recall')
score_mean=sum(score)/len(score)
scores.append(score_mean)
print(score_mean)
best=c_param_range[np.argmax(scores)]
print("最优C值:",best)
lr=LogisticRegression(C=best,penalty='l2',solver='lbfgs',max_iter=1000)
from sklearn import metrics
lr.fit(x,y)
train_predict=lr.predict(x)
print("自测评估验证:")
print(metrics.classification_report(y,train_predict))
cm_plot(y,train_predict).show()
test_predict=lr.predict(x_test)
print("测试评估验证")
print(metrics.classification_report(y_test,test_predict))
cm_plot(y_test,test_predict).show()执行结果:
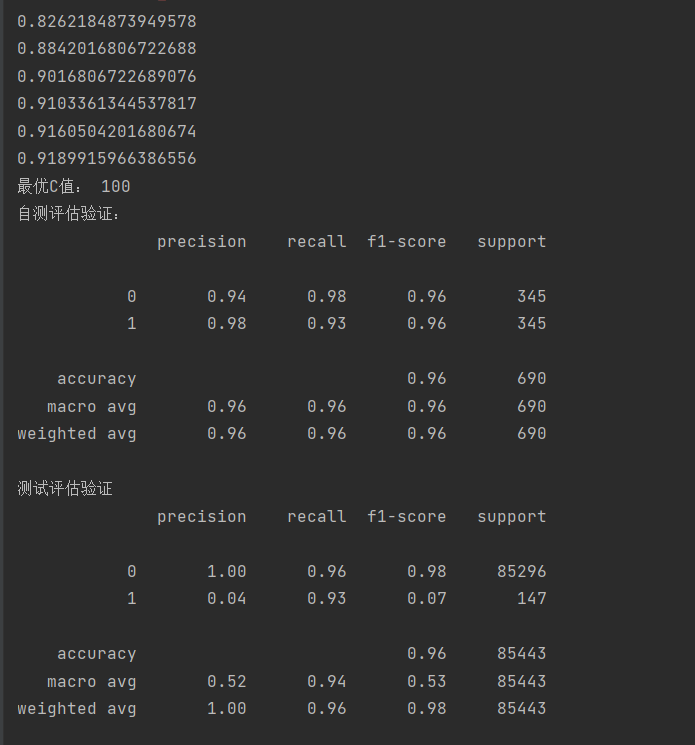
可以看到此时的召回率达到了0.93,这是就可以直接使用了,除了下采样,我们还可以通过过采样的方式来增加召回率
四、银行贷款案例过采样版
跟下采样很相似,但过采样是将少的数据增加到和多的数据一样多,再进行训练
python
import pandas as pd
import numpy as np
from sklearn.preprocessing import scale
from imblearn.over_sampling import SMOTE
def cm_plot(y,yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y,yp)
plt.matshow(cm,cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y],xy=(y,x),horizontalalignment='center',verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
data=pd.read_csv('creditcard.csv')
data['Amount']=scale(data[['Amount']])
a=data.drop(['Time'],axis=1)
from sklearn.model_selection import train_test_split
x1=a.drop('Class',axis=1)
y1=a.Class
x_train,x_test,y_train,y_test=(train_test_split(x1,y1,test_size=0.3,random_state=0))
over=SMOTE(random_state=0)
os_x_train,os_y_train=over.fit_resample(x_train,y_train)
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
scores=[]
c_param_range=[0.001,0.01,0.1,1,10,100]
for i in c_param_range:
lr=LogisticRegression(C=i,penalty='l2',solver='lbfgs',max_iter=1000)
score=cross_val_score(lr,os_x_train,os_y_train,cv=10,scoring='recall')
score_mean=sum(score)/len(score)
scores.append(score_mean)
print(score_mean)
best=c_param_range[np.argmax(scores)]
print("最优C值:",best)
lr=LogisticRegression(C=best,penalty='l2',solver='lbfgs',max_iter=1000)
from sklearn import metrics
lr.fit(os_x_train,os_y_train)
train_predict=lr.predict(os_x_train)
print("自测评估验证:")
print(metrics.classification_report(os_y_train,train_predict))
cm_plot(os_y_train,train_predict).show()
test_predict=lr.predict(x_test)
print("测试评估验证:")
print(metrics.classification_report(y_test,test_predict))
cm_plot(y_test,test_predict).show()这里使用了一个新的库:imblearn库,它是第三方库,需要在终端使用pip install imblearn进行下载
五、智能宿舍案例
通过网盘分享的文件:datingTestSet2.txt
链接: https://pan.baidu.com/s/1iUDEFt6M75RgL0dYJFGJQw 提取码: vkpp
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
def cm_plot(y,yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y,yp)
plt.matshow(cm,cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y],xy=(y,x),horizontalalignment='center',verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
# 读取数据(无表头,4列数据)
a = pd.read_csv('datingTestSet2.txt', sep='\t', header=None)
# 重命名列:前3列是特征,最后一列是标签
a.columns = ['F1', 'F2', 'F3', 'Class']
# 准备数据
x = a[['F1', 'F2', 'F3']]
y = a['Class']
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.3, random_state=1000
)
from sklearn.model_selection import cross_val_score
scores=[]
c_param_range=[0.001,0.01,0.1,1,10,100]
for i in c_param_range:
lr=LogisticRegression(C=i,penalty='l2',solver='lbfgs',max_iter=1000,multi_class='multinomial')
score=cross_val_score(lr,x_train,y_train,cv=10,scoring='recall_weighted')#'recall'只能用于二分类
score_mean=sum(score)/len(score)
scores.append(score_mean)
print(score_mean)
best=c_param_range[np.argmax(scores)]
print("最优C值:",best)
# 训练逻辑回归
lr = LogisticRegression(C=best,penalty='l2',solver='lbfgs', max_iter=1000,multi_class='multinomial')
lr.fit(x_train, y_train)
#自测
train_predict=lr.predict(x_train)
print("自测评估验证:")
print(metrics.classification_report(y_train,train_predict))
cm_plot(y_train,train_predict).show()
# 预测和评估
test_predict = lr.predict(x_test)
print("测试评估验证:")
print(metrics.classification_report(y_test,test_predict))
#可视化混淆矩阵
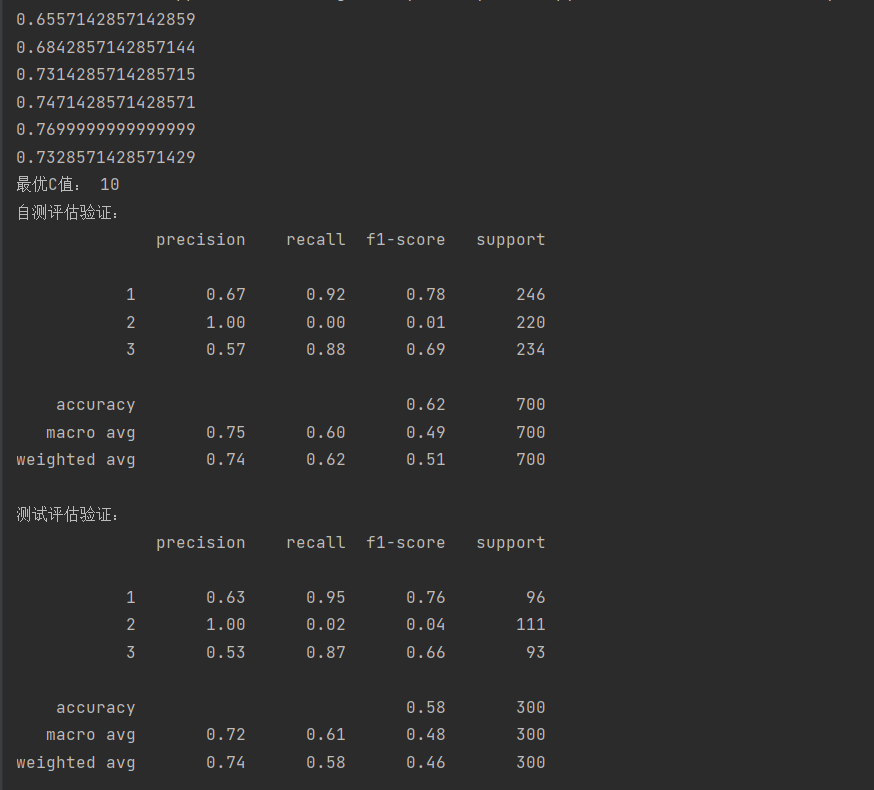
cm_plot(y_test,test_predict).show()这里不是进行二分类,所以在使用召回率作为评估指标时,就没有使用recall,而是使用了recall_weighted
执行结果: