机器学习概述
人工智能三大概念
- AL:人工智能,机器模拟人类
- ML:机器学习,能像人一样思考
- DL:深度学习,像人一样活动
机器学习的概念
让机器自动学习,而不是基于规则的编程
深度学习
也叫深度神经网络,大脑仿生,设计一层一层的神经元模拟万事万物
三者之间的关系
- 机器学习是实现人工智能的一种途径
- 深度学习是机器学习的一种方法
学习方式
基于规则,这没什么好解释的,就是自己指定规则,严格按照规则。
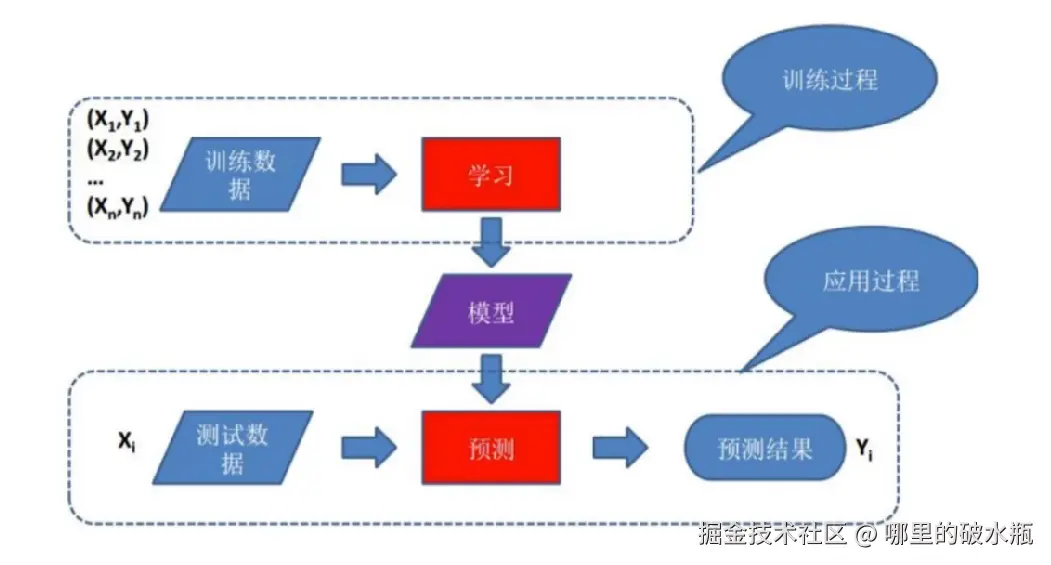
基于模型的学习
让机器自己学习从历史数据中获得经验、训练模型:
发展史

1956年夏季,以麦卡赛、明斯基、罗切斯特和申农等为首的一批有远见卓识的年轻科学家在一起聚会,共同研究和探讨用机器模拟智能的一系列有关问题,并首次提出了"人工智能"这一术语,它标志着"人工智能"这门新兴学科的正式诞生。
1956 年被认为是人工智能元年
1950-1970 符号主义流派:专家系统占主导地位
1950:图灵设计国际象棋程序
1962:IBM Arthur Samuel 的跳棋程序战胜人类高手(人工智能第一次浪潮)
1980-2000
统计主义流派:主要用统计模型解决问题
1993:Vapnik提出SVM
1997:IBM 深蓝战胜卡斯帕罗夫(人工智能第二次浪潮)
2010-2017
神经网络、深度学习流派
2012:AlexNet深度学习的开山之作
2016:Google AlphaGO 战胜李世石(人工智能第三次浪潮)
2017-至今
大规模预训练模型
2017年,自然语言处理NLP的Transformer框架出现
2018年,Bert和GPT的出现
2022年,chatGPT的出现,进入到大规模模型AIGC发展的阶段
机器学习发展三要素
数据、算法、算力三要素相互作用,是AI发展的基石
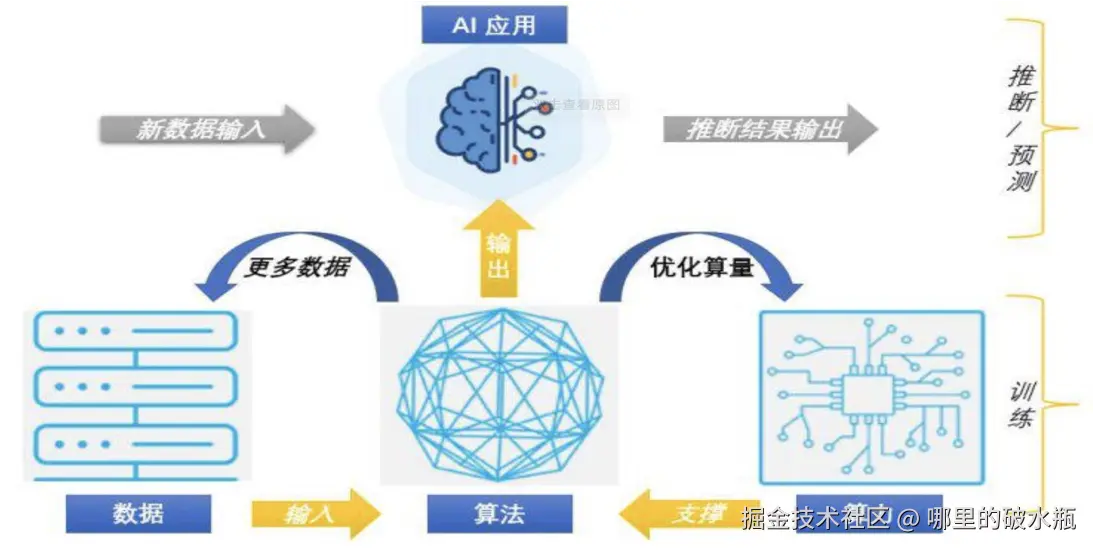
- CPU:负责调度任务、计算任务等;主要适合I\O密集型的任务
- GPU:更加适合矩阵运算;主要适合计算密集型任务
- TPU:Tensor,专门针对神经网络训练设计一款处理器
常用术语
样本,特征,标签/目标值
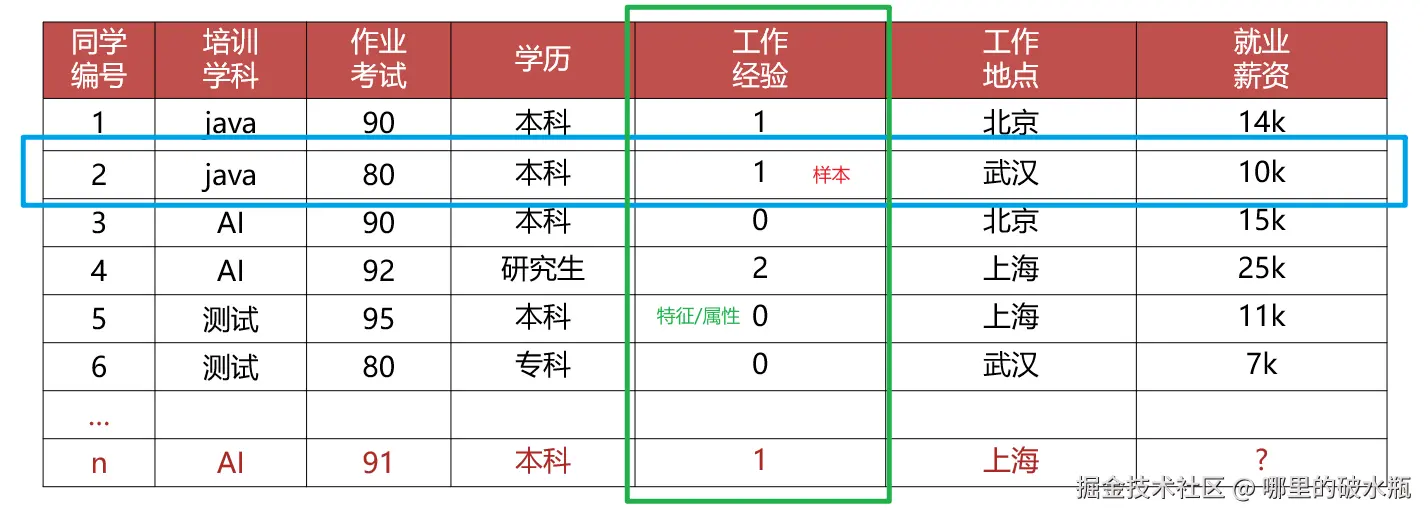
假设就业薪资是计算出来的。那么就业薪资就是标签。
对于整个结果叫做数据集
还有一种叫,我们针对于整个训练集,分为,正式和测试,正式数据叫train ,测试数据叫test 。比如对于标签 的测试数据,我们可以说:y_test ,对于样本 的测试数据,可以说:x_test
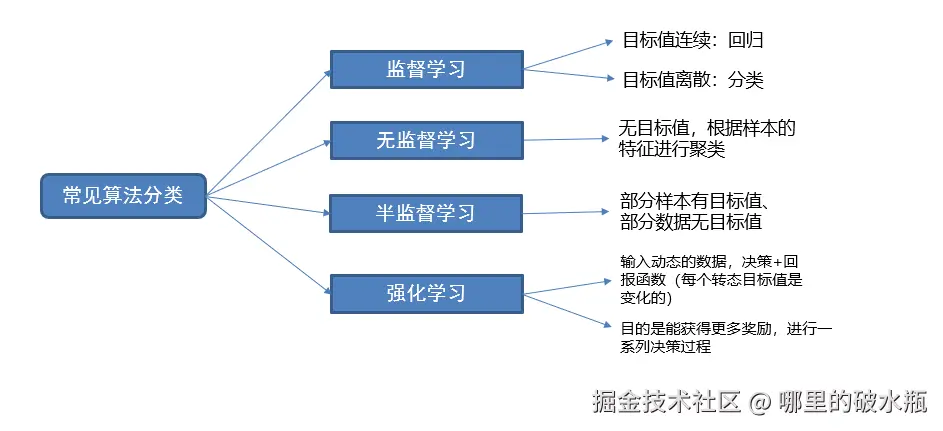
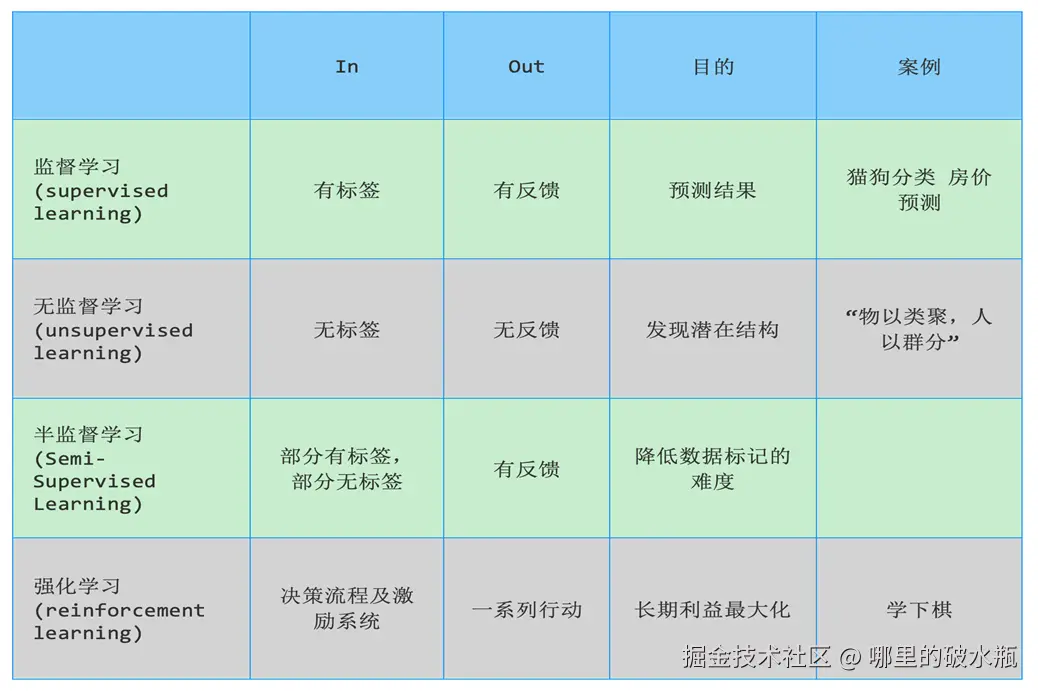
算法分类
有监督学习是:有特征、有标签
即输入的数据是由特征值目标值组成的。如下图

又可以分为:连续或者不连续
- 连续的采用:回归
- 不连续的采用:分类
不连续 = 分类
为什么叫分类呢,没有特定关系。比如要预测的结果是,好评/中评/差评,没有关系,不能排序。又分为了二分类和多分类
- 二分类:比如 猫/非猫
- 多分类:好评/中评/差评等等
这个值又叫离散值。
连续 = 回归
根据一些特征,可以推断出一个具体的数值。
比如房子的面积、楼层、位置,可以推断出价格。
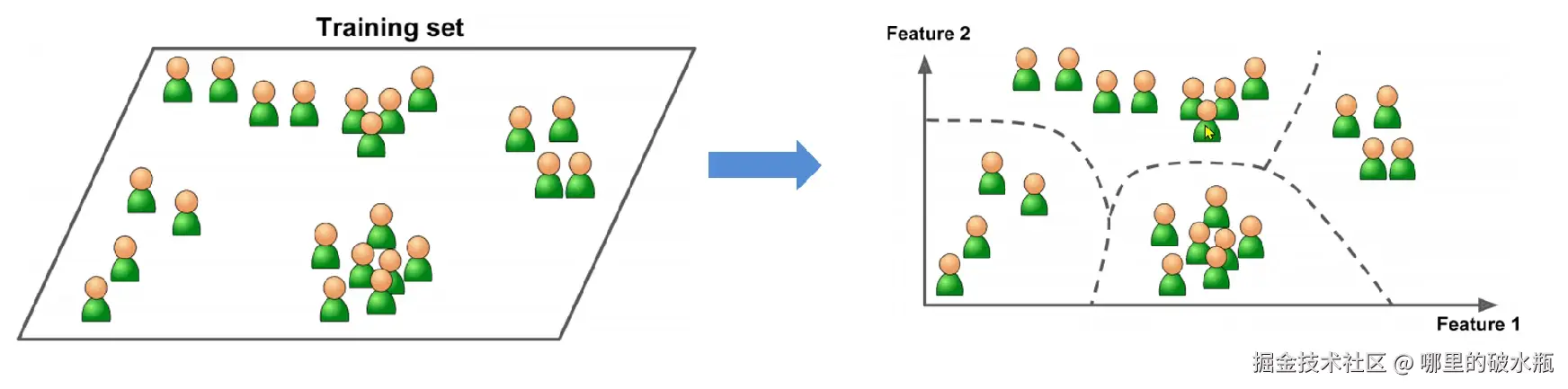
无监督学习是:有特征、无标签
即输入的数据,没有被标记,未知的类型,没有标签。
会产生聚类问题
根据样本间的相似性对样本进行聚类,发现事物内部结构及相互关系。
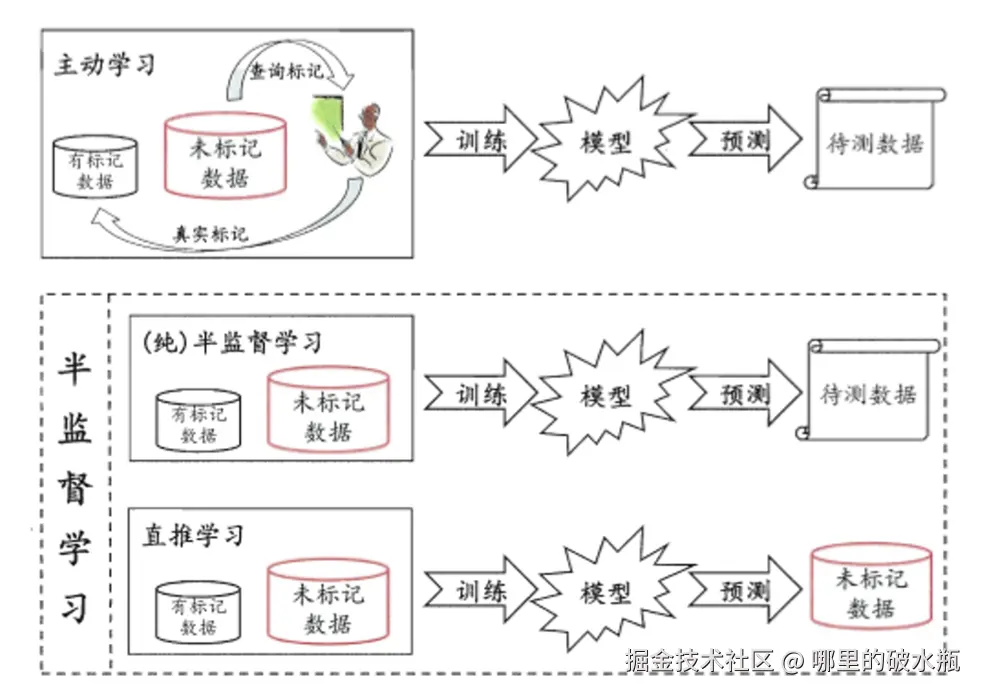
半监督学习
工作流程
- 让专家标注少量数据,利用已经标注的数据(也就是带有标签的数据)训练出一个模型
- 再利用该模型去套用未标记的数据,结果并不完全正确
- 通过询问领域专家分类结果与模型做对比,我们只需要对结果进行整改,从而对模型做进一步改善和提高。
意义是降低专家数据标注的次数,用于提高效率。
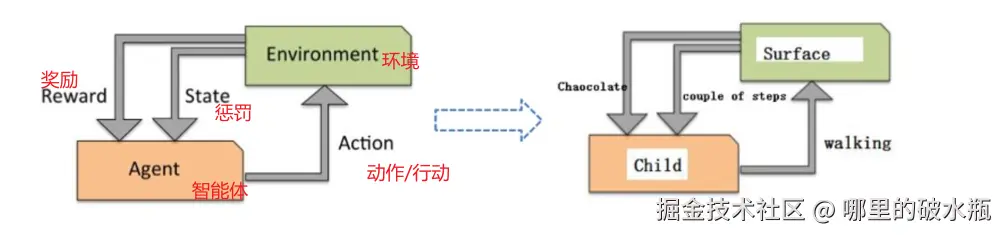
强化学习
- 强化学习(Reinforcement Learning):机器学习的一个重要分支
- 应用场景:里程碑AlphaGo围棋、各类游戏、对抗比赛、无人驾驶场景
是针对深度学习使用的。
建模流程

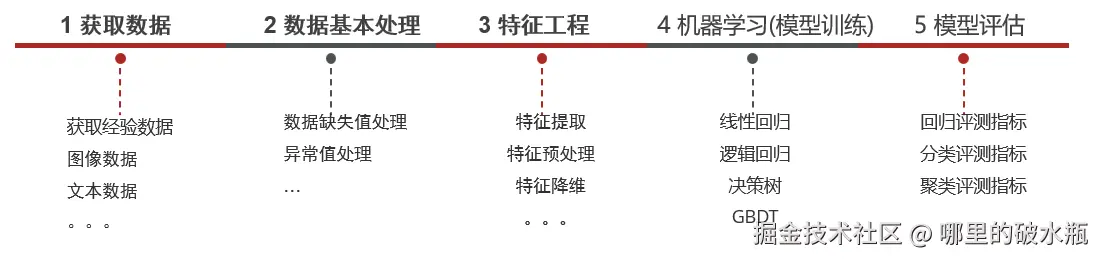
在整个建模流程中,数据基本处理、特征工程一般是耗时、耗精力最多的。
有监督学习模型训练和模型预测
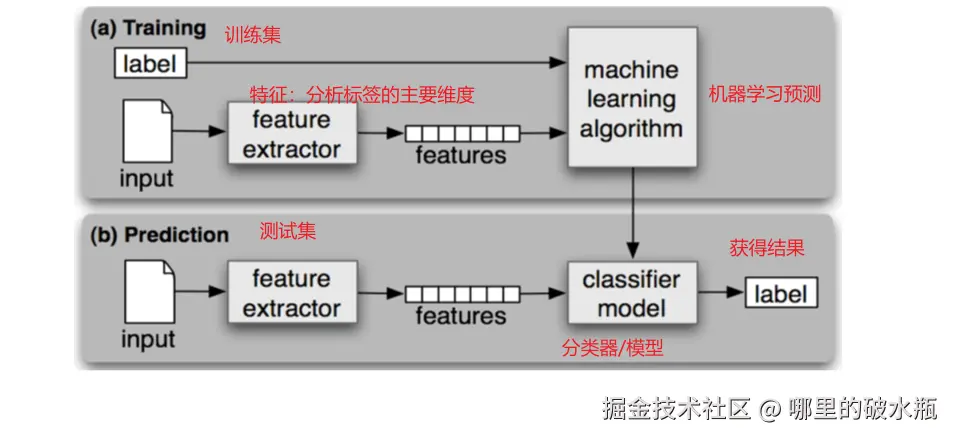
机器学习建模的一般步骤
- 获取数据:搜集与完成机器学习任务相关的数据集
- 数据基本处理:数据集中异常值,缺失值的处理等
- 特征工程:对数据特征进行提取、转成向量,让模型达到最好的效果
- 机器学习(模型训练):选择合适的算法对模型进行训练
- 根据不同的任务来选中不同的算法;有监督学习,无监督学习,半监督学习,强化学习
- 模型评估:评估效果好上线服务,评估效果不好则重复上述步骤
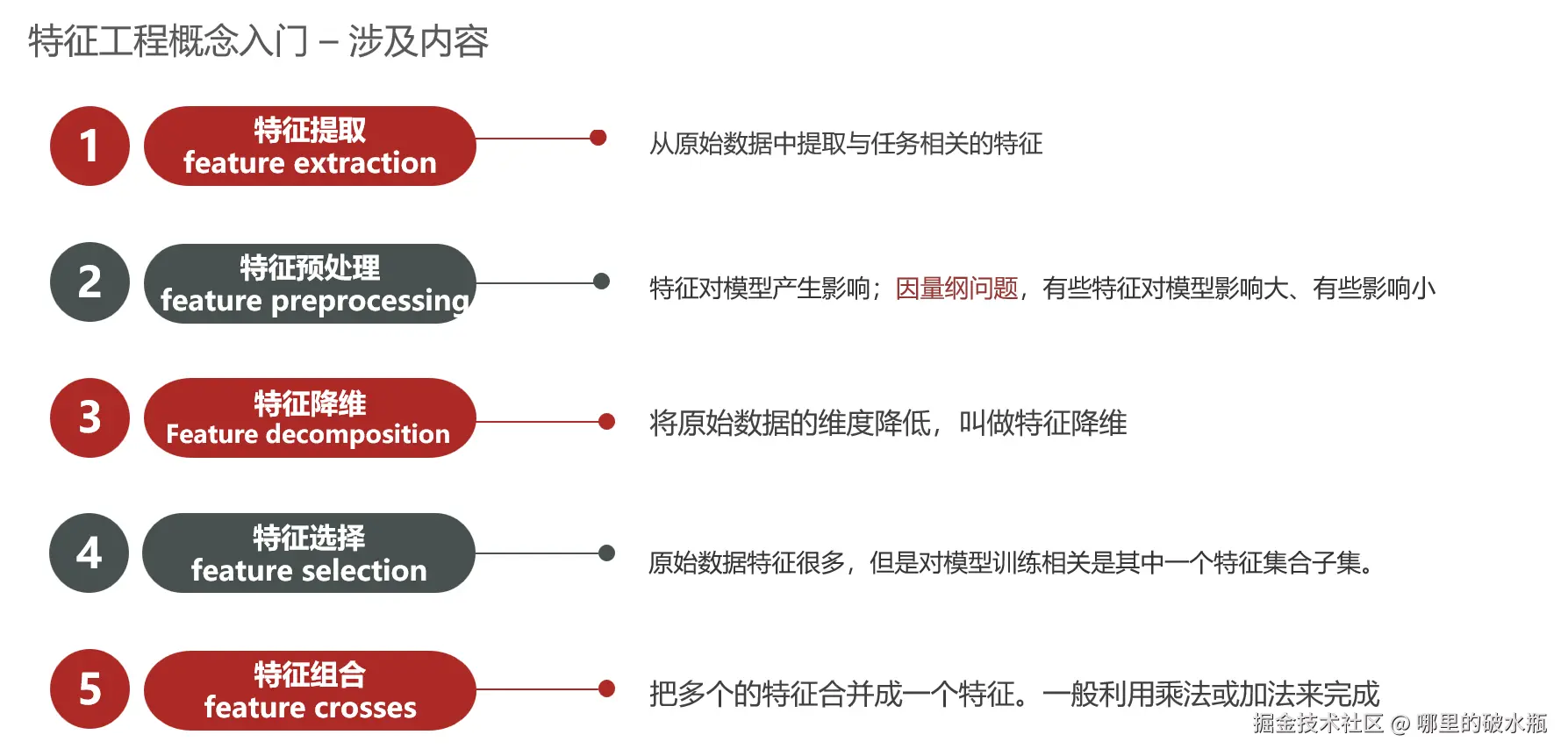
特征工程
下面将用房子举例说明:
什么是特征
描述了房子的多个参数,比如面积、位置、楼层等等。
利用专业背景知识和技巧处理数据,让机器学习算法效果最好。这个过程就是特征工程。
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
特征提取
特征提取从无到有的做行列向量数据

这一步要做一些处理:如归一化,标准化
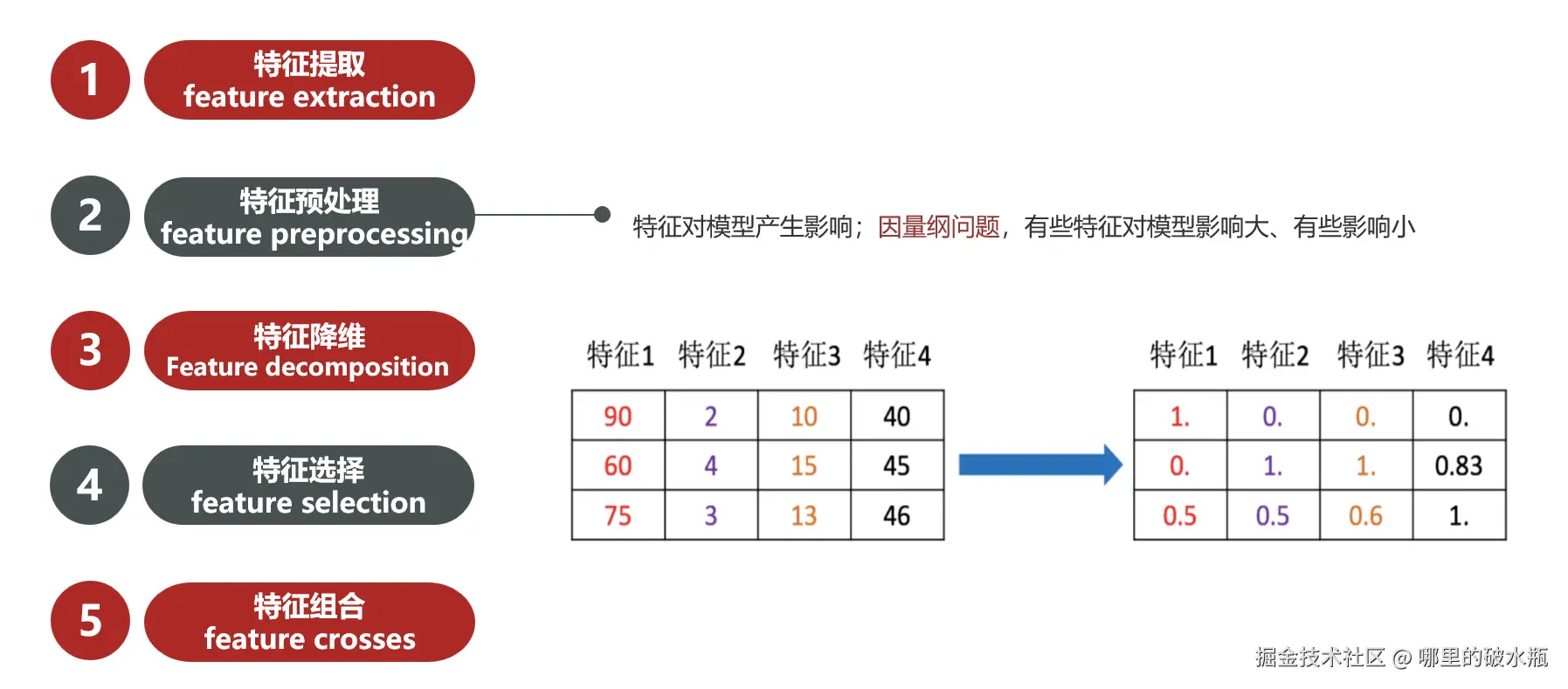
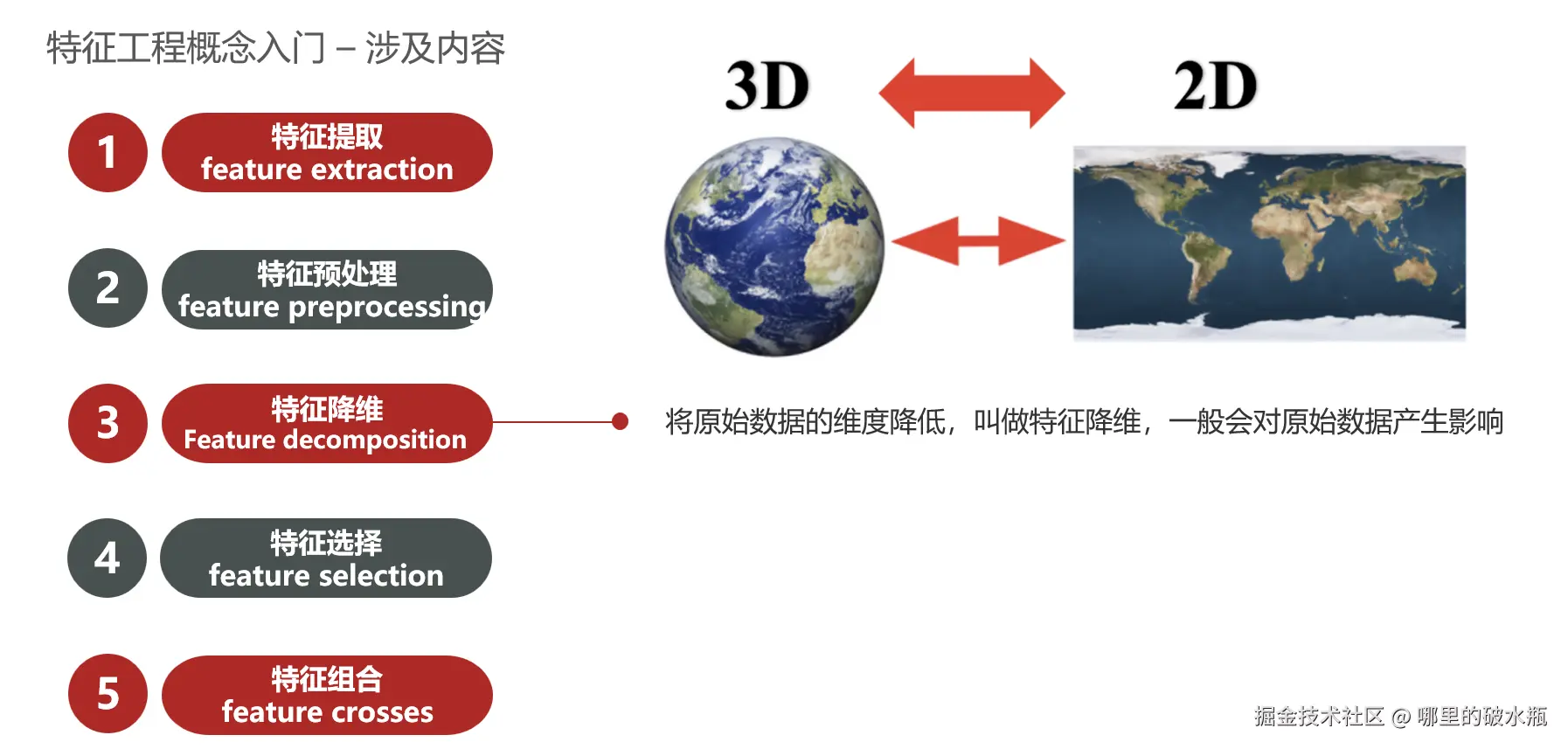
特征降维
将数据从3个特征 变成2个特征。一般会对原始数据产生影响。
比如:数据库里的有三张表,合并成一张表叫宽表(记录了三个表的核心字段)。
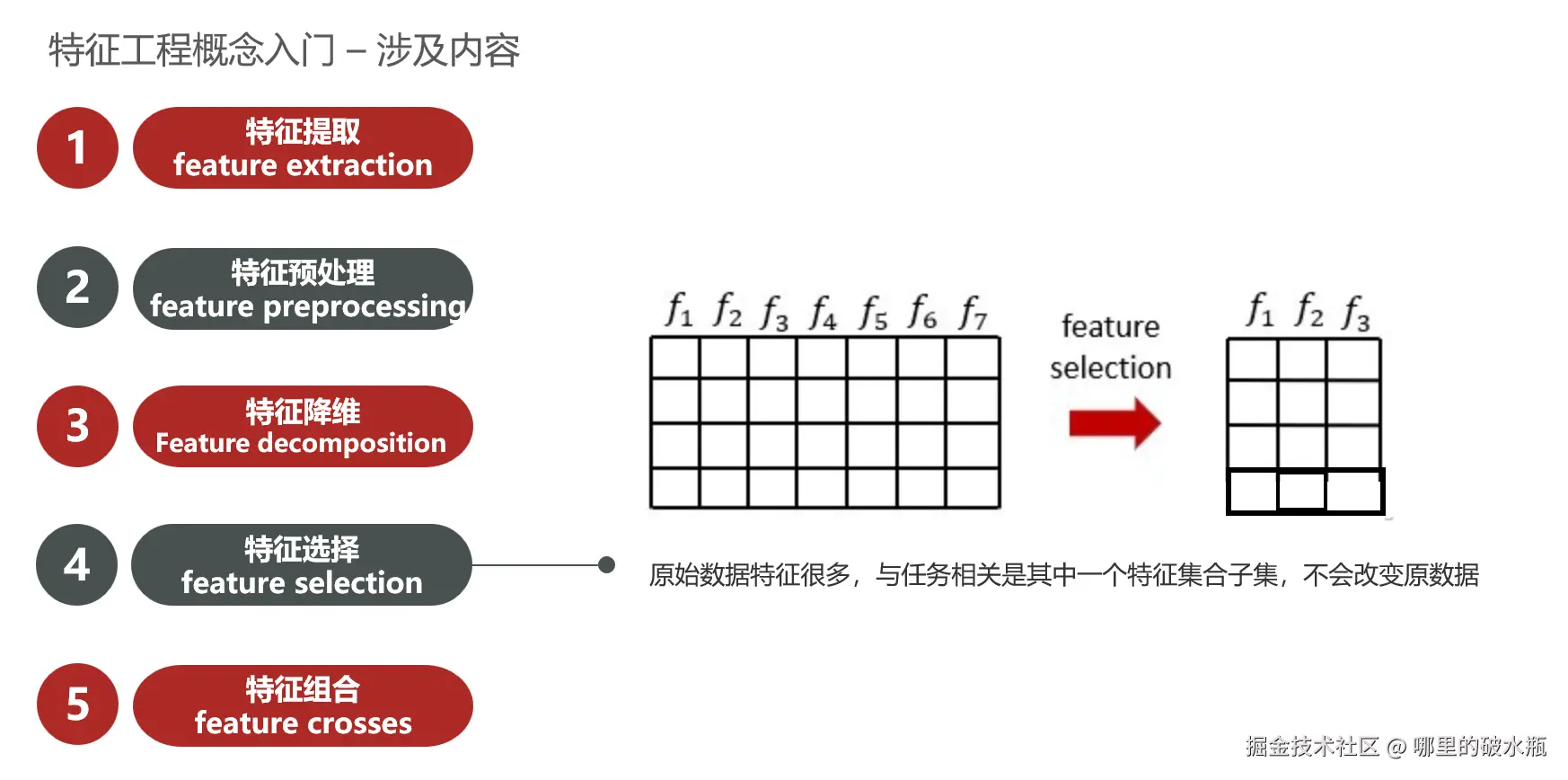
特征选择
特征提取后,有很多特征,需要从众多特征中选取较为重要的特征,叫做特征选择。
特征组合

总结
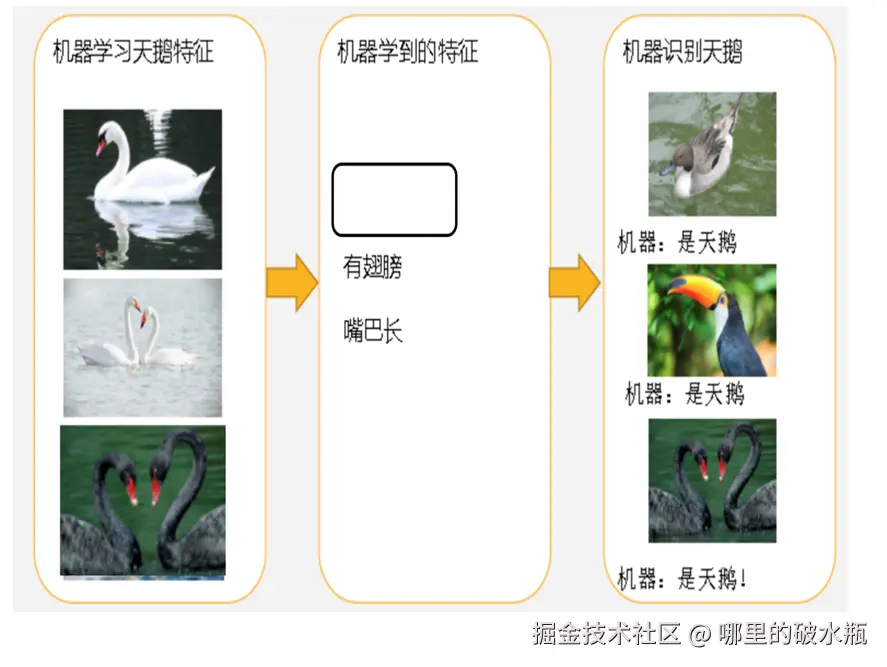
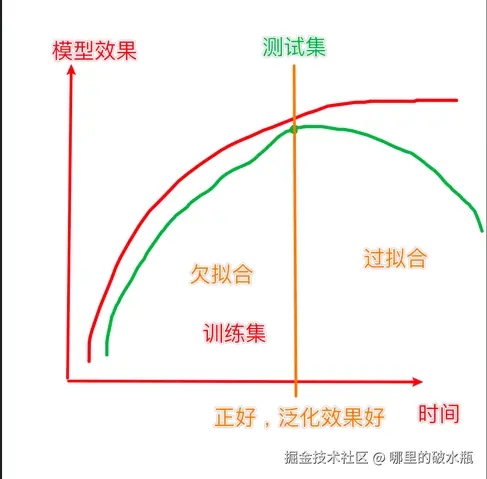
拟合
- 拟合:用在机器学习领域,用来表示模型对样本点的拟合情况
- 欠拟合:模型在训练集上表现很差、在测试集表现也很差
- 过拟合:模型在训练集上表现很好、在测试集表现很差
欠拟合例子
过拟合
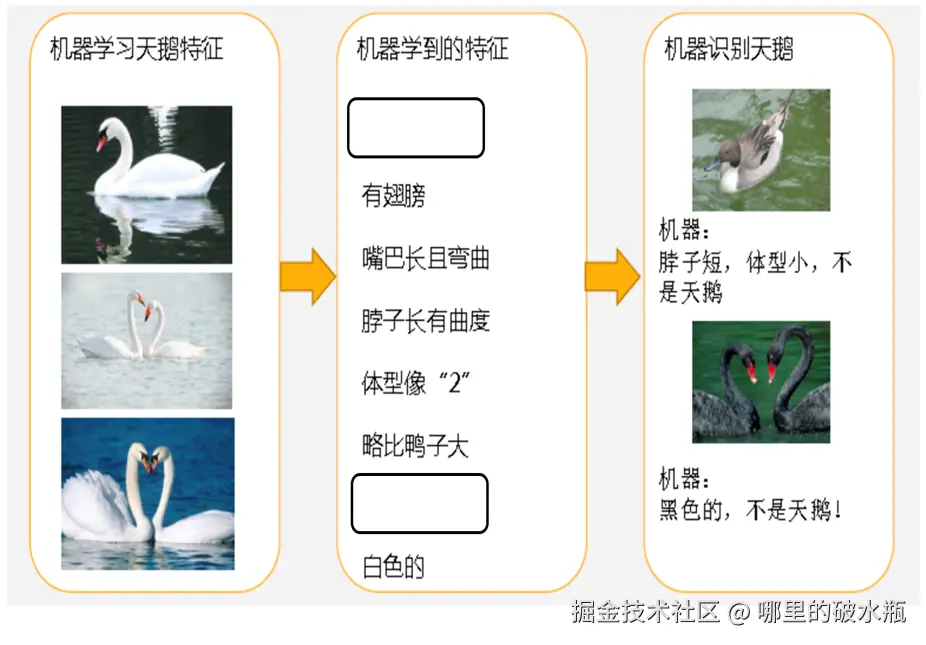
- 欠拟合产生的原因:模型过于简单
- 过拟合产的原因:模型太过于复杂、数据不纯、训练数据太少
泛化:模型在新数据集(非训练数据)上的表现好坏的能力。
奥卡姆剃刀原则:给定两个具有相同泛化误差的模型,较简单的模型比较复杂的模型更可取
下面是一张表达了,拟合关系的图
开发环境搭建 scikit-learn
- 简单高效的数据挖掘和数据分析工具
- 可供大家使用,可在各种环境中重复使用
- 建立在NumPy,SciPy和matplotlib上
- 开源,可商业使用-获取BSD许可证
bash
pip install scikit-learn机器学习的流程
- 数据准备
- 数据预处理
- 特征工程
- 特征提取
- 特征预处理
- 特征降维
- 特征选取
- 特征组合
- 模型训练
- 模型评估
- 模型预测
官网 scikit-learn.org/stable/inde...
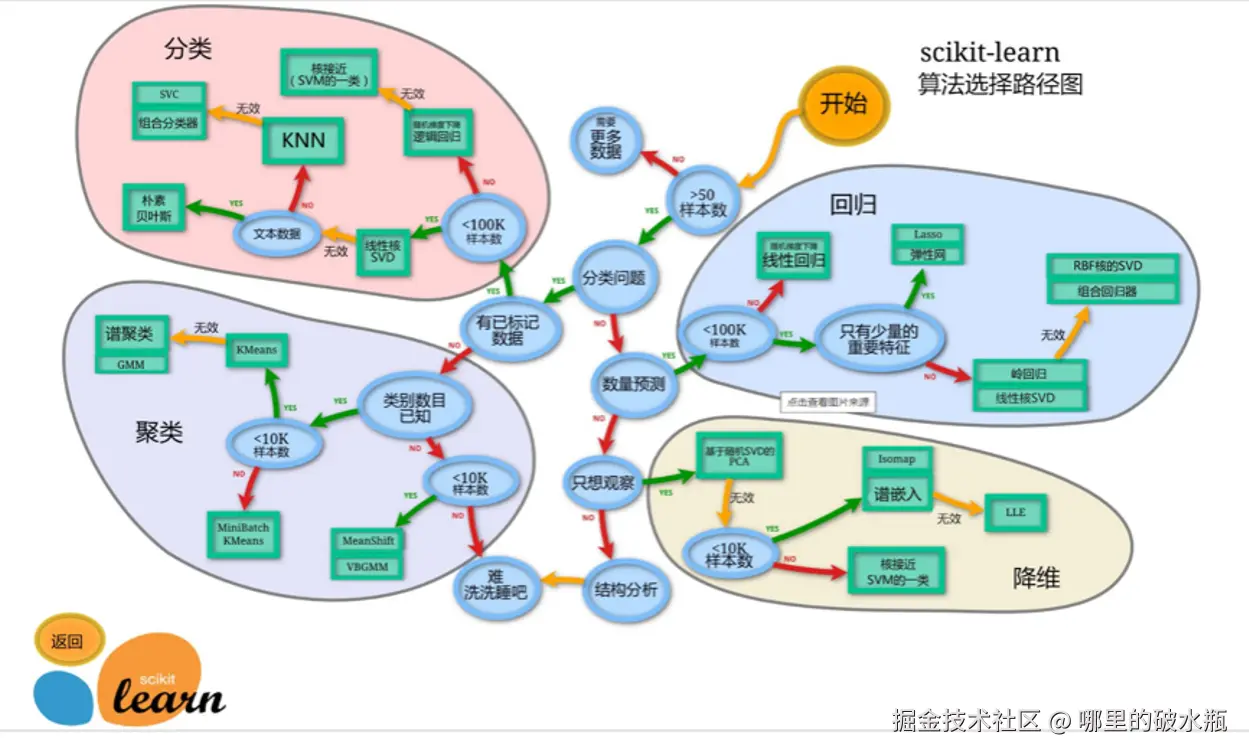
算法选择路线
knn 算法
knn算法也叫k近邻算法,是属于分类的一种。
knn思想:如果一个样本在特征空间中的 k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别
它既可以做分类也可以做回归,那是怎么做的呢,就是找到离你最近,最相似的样本。
假设我们有五个样本,这个时候就有两个问题,第一个叫分类,第二个叫回归。
- 分类是离你最近的五个样本投票,那个多,你就是谁。
- 回归是根据票数进行排序,找到最小值(具体算法不一定)
分类 K 近邻算法
样本相似性:样本都是属于一个任务数据集的。样本距离越近则越相似。
欧式距离:对应坐标轴差值平方和开根号
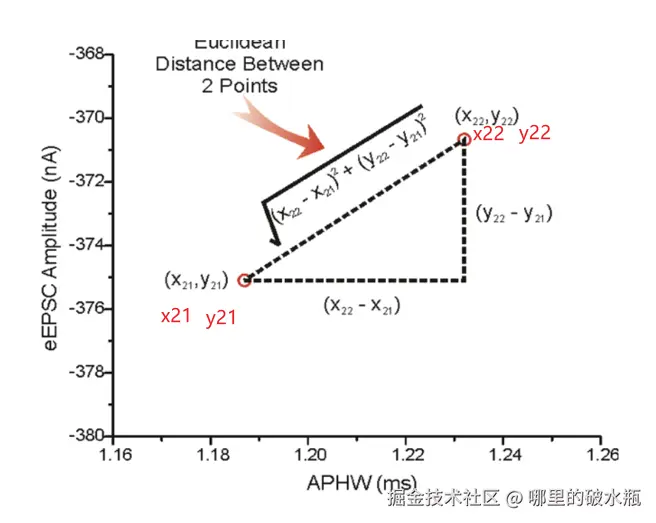
二维平面上点a(x₁,y₁)与b(x₂,y₂)间的欧氏距离:
d12=(x1−x2)2+(y1−y2)2
三维空间点 a(x1,y1,z1)与 b(x2,y2,z2)间的欧氏距离为
d12=(x1−x2)2+(y1−y2)2+(z1−z2)2
n维空间点 a(x11,x12,...,x1n)与 b(x21,x22,...,x2n)(两个n维向量)间的欧氏距离为
d12=∑k=1n(x1k−x2k)2 。
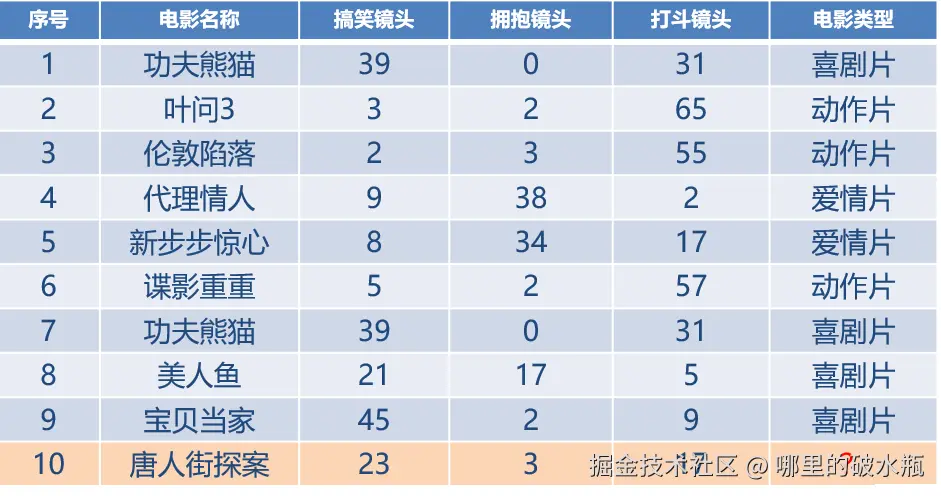
案例,计算过程
求,唐人街探案的欧氏距离,对比功夫熊猫。
谁减去谁不重要,因为开根号可以避免,这里就使用大的减去小的。
- (39−23)2=256+(3−0)2=9+(31−17)2=196 =461=21.47
- 如果 k = 5,将要计算5个最小值排序的情况。将这个五个值,相加平方开根号的过程。
回归 K 值选择
K值过小:用较小邻域中的训练实例进行预测
- 容易受到异常点的影响
- K值的减小就意味着整体模型变得复杂,容易发生过拟合
样本越多,KNN 越稳定,K 越大,越能抵抗噪声,样本越少 + K 越小,最容易被误导。
K值过大:用较大邻域中的训练实例进行预测
- 受到样本均衡的问题
- 且K值的增大就意味着整体的模型变得简单,欠拟合
样本少时,K 一大,预测永远是最多类别。
超参与交叉验证
超惨是指用户传递过来的参数
统计k中样本最多的那个类别,将未知样本归属于该类别。
- 计算未知样本到每一个训练样本的距离
- 将训练样本根据距离大小升序排列
- 取出距离最近的 K 个训练样本
- 进行多数表决,统计 K 个样本中哪个类别的样本个数最多
- 将未知的样本归属到出现次数最多的类别
回归问题的处理流程:
- 计算未知样本到每一个训练样本的距离
- 将训练样本根据距离大小升序排列
- 取出距离最近的 K 个训练样本
- 把这个 K 个样本的目标值计算其平均值
- 作为将未知的样本预测的值
注意类别型的,字符串形式没有办法求平均值。
实际工作中经常使用交叉验证的方式,并且大部分k值较小。
knn 是寻找与未知样本最近距离的k个样本,采用的是欧式距离
KNN 分类算法实现
概述:找距离测试集最近的K个样本,进行投票,标签最多,就用它作为测试集的结果。
- 思路1:分类思路,投票选最多的
- 思路2:回归思路,求均值
分类思路
- 基于欧式距离计算每个训练集,距离测试集的距离
- 欧氏距离:对应维度差值的平方和,开平方根
- 按照距离值,进行升序排列,找到距离最小的那K个样本
- 分类思路:投票选举,票数最多的标签值 -> 作为测试集的标签。
- 如果标签票数一样,参考最简单的模型,就是距离最近的那个结果。奥卡姆剃刀

为什么预测结果是1呢,首先,看最近的3个邻居,那么最后是,0,1,1。于是1大于0,结果是1。
那如果看最近的2个邻居,一个 0 , 1,取那个呢,不要看顺序,它会取0,为什么,因为 0 小,它取最小值。
py
# 导入 KNN 分类对象
from sklearn.neighbors import KNeighborsClassifier
# 参考3个最近的K
estimator = KNeighborsClassifier(n_neighbors=3)
# 准备数据集
x_train = [[1], [2], [3], [4]]
y_train = [0, 0, 1, 1] # 分类法:2分法
# 准备测试集
x_test = [[5]]
# 模型训练
estimator.fit(x_train, y_train)
# 模型预测,获取测试集的预测标签
y_test = estimator.predict(x_test)
print(y_test)KNN 回归算法实现
为什么结果是 0.15 呢。
找到距离最小的样本是,0.1 和 0.2
那相加 / 2 = 0.15
py
# 导入 KNN 回归算法
from sklearn.neighbors import KNeighborsRegressor
# 参考2个最近的K
estimator = KNeighborsRegressor(n_neighbors=2)
# 准备数据集
# 验证
# 差值: (9,17,8) (10,5,1) (20, 6, 2) (18, 12, 5)
# 平方和 434 126 440 493
# 开平方根 20.83 11.22 20.98 22.20
x_train = [[12, 27, 3], [13, 15, 10], [23, 16, 9], [21, 22, 6]]
y_train = [0.1, 0.2, 0.3, 0.4]
# 准备测试集
x_test = [[3, 10, 11]]
# 模型训练
estimator.fit(x_train, y_train)
# 模型预测,获取测试集的预测结果
y_test = estimator.predict(x_test)
print(y_test)距离计算方法
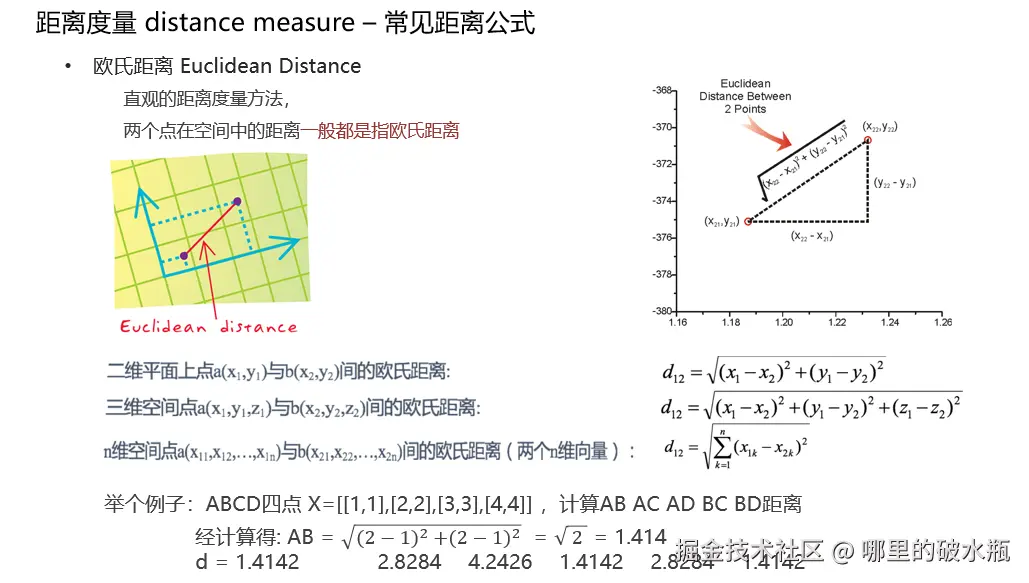
曼哈顿距离
也称为城市街区距离,曼哈顿城市特点:横平竖直
d12=∑k=1n∣x1k−x2k∣
举个例子:ABCD四点 X= \[1,1, 2,2, 3,3, 4,4 ]
计算AB AC AD BC BD曼哈顿距离
经计算得: AB =|2−1|+ ⌈2−1⌉= 2
d = 2 4 6 2 4 2
为什么是这样呢,如下图
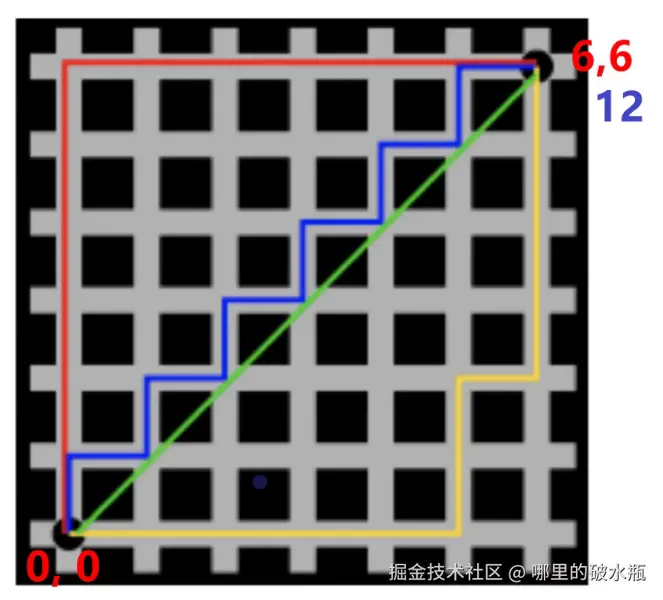
- 从 0 到 6的位置,走完x是六步,走完y是6步。
- 用 x和y 的 6 - 0,相加刚好是12。
切比雪夫距离
和曼哈顿距离有点像,曼哈顿不会斜着走,而切比雪夫是可以的,先斜着走,再直线距离。

其中 i 表示多个,可以用多组绝对值计算,i 表示的是维度索引,是一组而不是一个
d12=max(∣x1i−x2i∣)
闵可夫斯基距离
不是一种新的距离的度量方式。
是对多个距离度量公式的概括性的表述
d12=p∑k=1n∣x1k−x2k∣p
其中p是一个变参数:
- 当 p=1 时,就是曼哈顿距离
- 当 p=2 时,就是欧氏距离
- 当 p→∞ 时,就是切比雪夫距离
根据 p 的不同,闵氏距离可表示某一类种的距离
特征预处理
归一化
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级 ,容易影响(支配)目标结果,使得一些模型(算法)无法学习到其它的特征。
其实也就是脏数据,比如没有人的身高3米多,也没有人的体重800斤。要对这些脏数据进行处理。
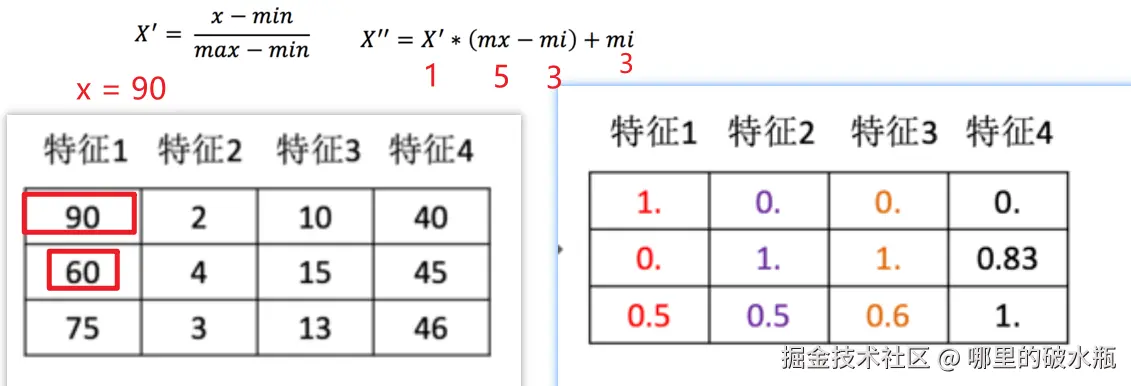
公式: x′=max−minx−min
归一化后的值(范围在 0,1)
上面能计算出归一化的值,当然也能反归一化,也就是逆向还原。
Min-Max标准化的区间映射公式:
x′′=x′∗(mx−mi)+mi
这里有个特别注意的点:mx 和 mi,是区间最小值和最大值,是自己指定的,希望压到多大和多小。
解释: 公式解释
- x:特征列中,某个具体要计算的值。
- min:该特征列的最小值。
- max:该特征列的最大值。
- mx:区间的最大值,默认的区间是 0,1,即:mx=1
- mi:区间的最小值,默认的区间是 0,1,即:mi=0
归一化的弊端:
即使该特征列的数据再多,也只会受到该列的最大值,最小值的影响,可能导致:数据不均衡。
如果最大值或者最小值又恰巧是异常值,就会导致计算结果偏差,又叫鲁棒性较差
案例,假设区间是,5,3
py
# 导入归一化的包
from sklearn.preprocessing import MinMaxScaler
# 创建数据集
x_train = [[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]]
# 创建归一化对象
# 解释:feature_range 表示区间,这里设置为3,5,默认是 0,1
transfer = MinMaxScaler(feature_range=(3, 5))
# 执行归一化操作
# fit_transform 针对于训练集的,即:训练 + 转换(归一化)
# fit 针对测试集,只有转换,归一化,返回归一化对象
x_train_new = transfer.fit_transform(x_train)
# transfer.fit(x_train)
print(x_train_new)跑完答案
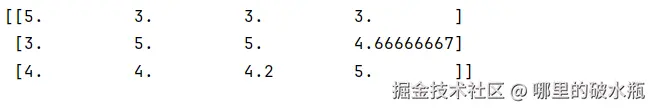
适用于小数据集的运算。
标准化
计算公式
x′=σ(x−mean)
它适合于大数据集的应用场景。一般用标准化处理。
注意:数据计算是按列算的,比如:90,60,75
py
# 导入标准化的包
from sklearn.preprocessing import StandardScaler
# 创建数据集
x_train = [[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]]
# 创建标准化对象
transfer = StandardScaler()
# 执行标准化操作
# fit_transform 针对于训练集的,即:训练 + 转换(标准化)
# fit 针对测试集,只有转换,标准化,返回标准化对象
x_train_new = transfer.fit_transform(x_train)
# transfer.fit(x_train)
# print(x_train_new)
# 查看方差
print(transfer.var_)
# 查看平均值
print(transfer.mean_)
# 查看标准差
print(transfer.scale_)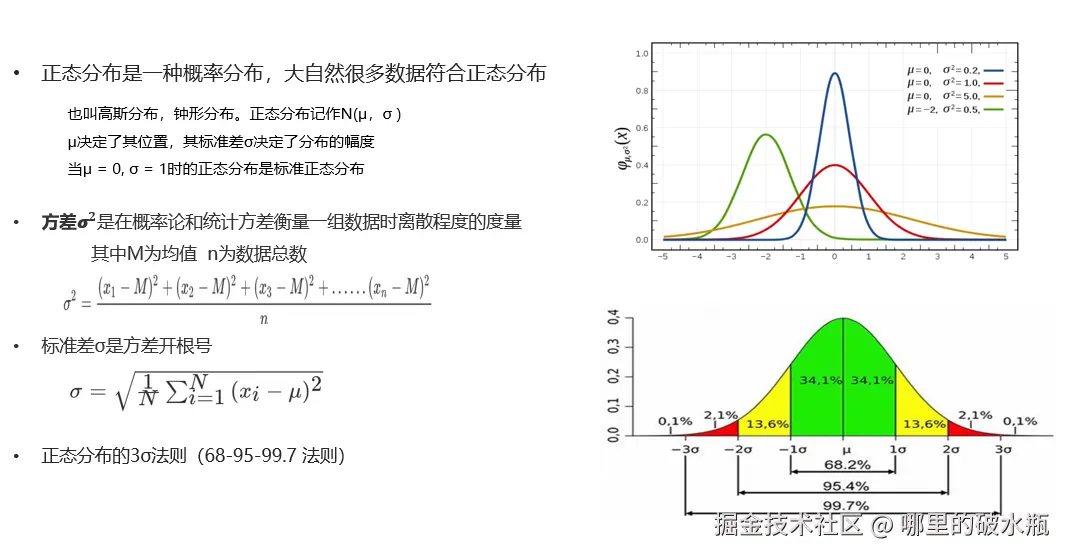
总结
数据归一化
- 如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变
- 应用场景:最大值与最小值非常容易受异常点影响,鲁棒性较差,只适合传统精确小数据场景
数据标准化
- 如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大
- 应用场景:适合现代嘈杂大数据场景。(以后就是用你了)
利用KNN算法对鸢尾花分类
实现流程:
- 获取数据集
- 数据基本处理
- 数据集预处理-数据标准化
- 机器学习(模型训练)
- 模型评估
- 模型预测

查看数据
- x_train 是数据集,对应 data
- y_train 是标签集,对应 target
- target_names 是标签的语义
py
from sklearn.datasets import load_iris
def test_load_iris():
iris_data = load_iris()
# iris_data,结果是字典。
# print(iris_data)
# 查看数据集,即:特征列,分别是:sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
# print(iris_data.data[:5])
# 查看数据集,即标签列
# print(iris_data.target[:5])
# 查特征列,标签列,即数据集的条数
# print(len(iris_data.data), len(iris_data.target))
# 查看数据集的列名
# print(iris_data.feature_names)
# 具体标签名 ['setosa' 'versicolor' 'virginica']
print(iris_data.target_names)
# 查看所有 key 的名字
print(iris_data.keys())
if __name__ == '__main__':
# 加载数据集
test_load_iris()转为 DataFrame 对象 / 绘制散点图
py
if __name__ == '__main__':
# 中文显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 加载数据集
iris_data = load_iris()
# 封装成对象
frame = pd.DataFrame(data=iris_data.data, columns=iris_data.feature_names, )
frame['label'] = iris_data.target
# 绘制成散点图
# fit_reg 去除拟合回归线
sns.lmplot(data=frame, y='petal width (cm)', x='petal length (cm)',
hue='label', fit_reg=False)
plt.title('鸢尾花数据集展示')
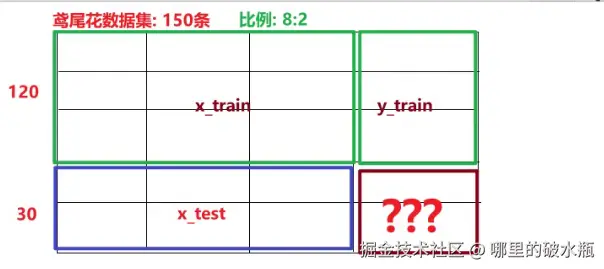
plt.show()区分数据集和测试集
py
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
if __name__ == '__main__':
# 加载数据集
iris_data = load_iris()
# 特征是 data,标签是 target
# 切分训练集和测试集
# 参数1:要被切分的特征
# 参数2:要被切分的标签
# 参数3:测试集的比例,这里是20
# 参数4:随机种子,种子一致
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=70)
# 打印测试结果
print(f'训练集的特征: {x_train}')
print(f'训练集的标签: {y_train}')
print(f'训练集的条数: {len(x_train)}, {len(y_train)}')
print(f'测试集的特征: {x_test}')
print(f'测试集的标签: {y_test}')
print(f'测试集的条数: {len(x_test)}, {len(y_test)}')模型预测和评估
py
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
if __name__ == '__main__':
# 1. 加载数据集
iris_data = load_iris()
# 2. 数据预处理
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=70)
# 3. 特征工程
# 此处无需手动实现,数据已经转换完毕,分别是:花萼的长度,花萼的宽度,花瓣的长度,花瓣的宽度
# 字段名如下:sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
# 4. 特征预处理(归一化、标准化),我们发现特征共 4 列,差值都不大。可以不做,这里学习一下。
# 标准化
transfer = StandardScaler()
# 对于训练集数据,做训练+转换
x_train = transfer.fit_transform(x_train)
# 对于测试机数据 做转换
x_test = transfer.transform(x_test)
# 5. 特征降维、特征选取、特征组合、这里不需要做,因为数据比较简单
# 6. 模型训练,选分类
estimator = KNeighborsClassifier(n_neighbors=5)
# 具体训练代码
estimator.fit(x_test, y_test)
# 7. 模型预测
# 对测试集进行数据预测
y_predict = estimator.predict(x_test)
print(f'模型预测的结果为{y_predict}')
print(f'测试集真实数据为{y_test}')
# 对新的数据集做测试
# 准备新的数据集
x_test_new = [[3.6, 1.5, 1.5, 0.3]]
# 对新数据重新标准化处理
x_test_new = transfer.transform(x_test_new)
# 模型预测
y_predict_new = estimator.predict(x_test_new)
print(f'模型预测结果为:{y_predict_new}')
# 查看上述的特征 -> 各结果标签的 概率值,结果为 0 1 2,查看每个值的概率
y_predict_proba_new = estimator.predict_proba(x_test_new)
print(f'模型预测概率结果为:{y_predict_proba_new}') # 模型预测概率结果为:[[0.2 0.8 0. ]],根据顺序,表示百分百80是 1 分类
# 8. 模型评估
# KNN 算法评估,主要参考 准确率,即:预测正确的数量 / 总数量
# 方式一:针对于测试集的特征 和 测试集的标签,进行预测,一般不太准确,不建议使用
# 这种方式可以预测前和预测后进行评估,因为没有用到 predict 的值
print(f'准确率:{estimator.score(x_test, y_test)}') # 准确率:0.9666666666666667
# 方式二:针对预测值(y_predict)和测试集的真实标签(y_test)进行评估
# 主要是做模型预测后的评估
print(f'模型准确率:{accuracy_score(y_test, y_predict)}') # 模型准确率:0.9666666666666667fit_transform 和 transform 的区别
fit_transform 是先基于训练集的特征做,拟合,例如获取均值,标准差,方差等信息,再基于内置好的模型(标准化)对象,调整参数,进行转换。
比如:
- StandardScaler → 计算每列的均值和标准差
- MinMaxScaler → 计算每列的最小值和最大值
- PCA → 计算协方差矩阵和特征向量
上面这些,只会学习一次,后面直接使用这些参数。
而 transform
作用:使用 fit 学到的参数对数据进行转换
比如:
- 标准化:(X - mean) / std
- 归一化:(X - min) / (max - min)
不会重新计算均值/标准差,直接用已有参数。
总结
- fit_transform 再第一次使用
交叉验证
什么是交叉验证?
它是一种更加完善的,可信度更高的模型预估方式,思路是:把数据集分成 N 份,每次都取 1 份当作测试集,其他的当作训练集,然后计算模型的评分,接下来,再用下一份作为测试集,其他作为训练集,计算模型评分,分成几份,就进行几次计算,最后计算所有评分的均值,当做模型的最终评分。

交叉验证法原理:将数据集划分为 cv=4 份
- 第一次:把第一份数据做验证集,其他数据做训练
- 第二次:把第二份数据做验证集,其他数据做训练
- ... 以此类推,总共训练4次,评估4次。
- 使用训练集+验证集多次评估模型,取平均值做交叉验证为模型得分
- 若k=5模型得分最好,再使用全部训练集(训练集+验证集) 对k=5模型再训练一遍,再使用测试集对k=5模型做评估
好处:交叉验证的结果,比单一切分训练集和测试集,获取的评分结果,可信度更高
细节:
- 把数据集分成 N 份,就叫 N折交叉验证。
- 交叉验证一般和网格搜索一起使用。
交叉验证法,是划分数据集的一种方法,目的就是为了得到更加准确可信的模型评分。
网格搜索
为什么需要网格搜索?
- 模型有很多超参数,其能力也存在很大的差异。需要手动产生很多超参数组合,来训练模型
- 每组超参数都采用交叉验证评估,最后选出最优参数组合建立模型。
网格搜索是模型调参的有力工具。寻找最优超参数的工具!
只需要将若干参数 传递给网格搜索对象 ,它自动帮我们完成不同超参数的组合、模型训练、模型评估,最终返回一组最优的超参数。
网络搜索就说寻找最优的超惨。
网格搜索 + 交叉验证的强力组合 (模型选择和调优)
- 交叉验证解决模型的数据输入问题(数据集划分)得到更可靠的模型
- 网格搜索解决超参数的组合
- 两个组合再一起形成一个模型参数调优的解决方案
总而言之,网络搜索 + 交叉验证目的就说为了寻找模型的最优解决方案,追求较高的效率。
交叉验证和网格搜索实战
一般会对,下面代码的 CV 循环,比如循环20次,它会告诉20次那次好,然后由我们逐个的去判断。
原因:
- 因为折数不一样,超参也不一样。
- 只跑一次是判断不出来最终结果的
py
estimator = GridSearchCV(estimator=estimator, param_grid=param_dict, cv=5)完整代码
py
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
if __name__ == '__main__':
# 1. 加载数据集
iris_data = load_iris()
# 2. 数据预处理
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2,
random_state=22)
# 3. 特征预处理
transfer = StandardScaler()
transfer.fit_transform(x_train)
transfer.transform(x_test)
# 4. 模型训练,选分类,注意此时不需要传递 K 的值
estimator = KNeighborsClassifier()
# 4.1 定义字典,记录超参可能出现的值
# 注意这些值不能写死,
param_dict = {'n_neighbors': list(range(1, 21))}
# 4.2 创建网格搜索对象
# 参数1:模型对象。参数2:超参字典,参数3:交叉验证的折数
# 返回一个更加强大的模型对象
estimator = GridSearchCV(estimator=estimator, param_grid=param_dict, cv=5)
# 模型训练
estimator.fit(x_test, y_test)
# 5. 模型预测
y_predict = estimator.predict(x_test)
print(f'模型预测的结果为{y_predict}')
# 6. 打印网格搜索 和 交叉验证的 结果
print(estimator.best_score_) # 最优组合的平均分 0.9666666666666668
print(estimator.best_estimator_) # 最优组合的模型对象 KNeighborsClassifier(n_neighbors=6)
print(estimator.best_params_) # 最优组合的超参(仅供参考) {'n_neighbors': 6}
print(estimator.cv_results_) # 所有组合的 评分结果(过程)
# {'mean_fit_time': array([0.00020003, 0.00019999, 0.00019984, 0.00040126, 0.00019999]), 'std_fit_time': array([0.00040007, 0.00039997, 0.00039968, 0.00049144, 0.00039997]), 'mean_score_time': array([0.00110083, 0.00140481, 0.00130205, 0.00100107, 0.00140252]), 'std_score_time': array([0.00020204, 0.00037565, 0.00039944, 0.00063234, 0.00049298]), 'param_n_neighbors': masked_array(data=[1, 2, 3, 5, 7],
# mask=[False, False, False, False, False],
# fill_value=999999), 'params': [{'n_neighbors': 1}, {'n_neighbors': 2}, {'n_neighbors': 3}, {'n_neighbors': 5},
# {'n_neighbors': 7}], 'split0_test_score': array([0.83333333, 0.83333333, 0.83333333, 0.83333333, 0.83333333]),
# 'split1_test_score': array([1. , 0.83333333, 1. , 0.66666667, 0.66666667]), 'split2_test_score':
# array([1., 1., 1., 1., 1.]), 'split3_test_score': array([1., 1., 1., 1., 1.]), 'split4_test_score': array([1.
# , 1. , 1. , 1. , 0.83333333]), 'mean_test_score': array([0.96666667, 0.93333333, 0.96666667,
# 0.9 , 0.86666667]), 'std_test_score': array([0.06666667, 0.08164966, 0.06666667, 0.13333333, 0.12472191]),
# 'rank_test_score': array([1, 3, 1, 4, 5], dtype=int32)}
# 7. 结合上述的结果,对模型再次评估
estimator = KNeighborsClassifier(n_neighbors=6)
estimator.fit(x_train, y_train)
y_predict = estimator.predict(x_test)
print(f'准确率:{accuracy_score(y_test, y_predict)}') # 准确率:0.9333333333333333数字识别
根据像素点生成图片
已知数据
- MNIST手写数字识别
- 1999年发布,成为分类算法基准测试的基础
- MNIST仍然是研究人员和学习者的可靠资源
从数万个手写图像的数据集中正确识别数字
数据介绍
- 数据文件 train.csv 和 test.csv 包含从 0 到 9 的手绘数字的灰度图像
- 每个图像高 28 像素,宽28 像素,共784个像素
- 每个像素取值范围0,255,取值越大意味着该像素颜色越深
- 训练数据集(train.csv)共785列。
- 第一列为标签,为该图片对应的手写数字。其余784列为该图像的像素值
- 训练集中的特征名称均有pixel前缀,后面的数字(0,783)代表了像素的序号。
py
import sys
from collections import Counter
import matplotlib.pyplot as plt
import pandas as pd
if __name__ == '__main__':
idx = 20
# 获取数据
data = pd.read_csv(r'E:\BaiduNetdiskDownload\手写数字识别.csv')
# 判断用户传入的索引是否合法
if idx < 0 or idx >= len(data):
print('索引不合法')
sys.exit(1)
# 获取所有的行,从第一列开始,不包含第 0 列
x = data.iloc[:, 1:]
y = data.iloc[:, 0]
# 查看下每个数字一共有多少个,注意是 collections 下的
# 数字的种类Counter({1: 4684, 7: 4401, 3: 4351, 9: 4188, 2: 4177, 6: 4137, 0: 4132, 4: 4072, 8: 4063, 5: 3795})
print(f'数字的种类{Counter(y)}')
print(f'像素的形状{x.shape}')
print(f'索引对应的数字是:{y[idx]}')
# 绘制图片
# x.iloc[idx] 返回的是列名+数据
# x.iloc[idx].values 整合成一个数组
# reshape(28, 28) 转换为 28*28 的像素点,因为图片就说 28 * 28
# 结果就是 一个 28*28 的矩阵,,每28个是一个数组
digit = x.iloc[idx].values.reshape(28, 28)
# 绘制图片
plt.imshow(digit, cmap='gray') # 灰度图
# 不显示坐标轴
plt.axis('off')
plt.show()
模型保存
py
import joblib
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
if __name__ == '__main__':
# 1. 获取数据
data = pd.read_csv('./手写数字识别.csv')
# 2. 数据预处理
# 像素点,特征
x = data.iloc[:, 1:]
# 标签
y = data.iloc[:, 0]
# stratify 表示参考 y 轴数据分布划分数据集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=7, stratify=y)
# 3. 特征工程
transfer = StandardScaler()
transfer.fit_transform(x_train)
transfer.transform(x_test)
# 4. 模型训练
estimator = KNeighborsClassifier(n_neighbors=5)
estimator.fit(x_train, y_train)
# 5. 模型评估
print(f'准确率:{estimator.score(x_test, y_test)}') # 准确率:0.9653571428571428
# 6. 模型评估
# pkl 是 pandas 独有的文件格式
# pth 也是可以的
joblib.dump(estimator, '/knn.pkl')图片数字识别
因为,加载的图片,是一个0~1的数值,需要 * 255
py
import joblib
import matplotlib.pyplot as plt
import pandas as pd
if __name__ == '__main__':
# 1. 加载图片
# 打印出来是 28 * 28 的矩阵
img = plt.imread('./demo.png')
# 值如果是2,表示灰度图
print(img.ndim)
# 转 0~255
img = img * 255
# 显示图片
plt.imshow(img, cmap='gray')
plt.show()
# 转换成 一行 矩阵,最多是 28 * 28 = 784列,但是还需要计算,可以直接写 -1,表示能转多少转多少
img = img.reshape(1, -1)
# 读取模型
knn = joblib.load('/knn.pkl')
# 用训练时的特征名构造
feature_names = knn.feature_names_in_
img_df = pd.DataFrame(img, columns=feature_names)
# 模型预测
y_predict = knn.predict(img_df)
print(y_predict)