一、Faster R-CNN
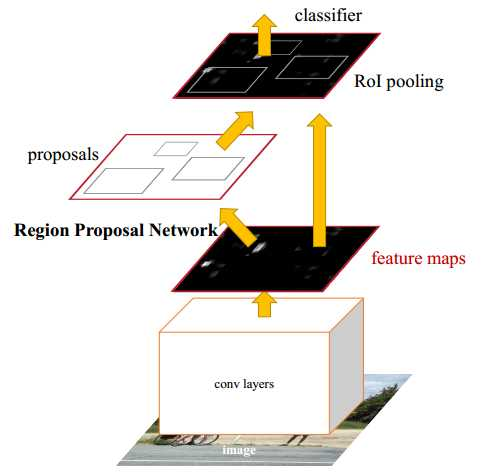
Faster R-CNN算法是一种端到端的目标检测模型,其关键突破是引入了区域建议网络)Region Proposal Network,RPN)。
(一)什么是端到端?
端到端就是将输入到输出的全部处理步骤整合进一个统一的模型进行联合学习和优化,无需独立设计或训练中间模块。
(二)发展历程
1、传统的目标检测流水线:
- 输入图片 → 人工设计特征(如HOG, SIFT) → 候选区域生成(如Selective Search) → 分类器(如SVM) → 输出结果
2、R-CNN
- 区域建议:完全依赖外部算法(Selective Search),与后续网络无关。
- 特征提取:每个候选区域都单独通过CNN计算,计算冗余。
- 分类与回归:使用独立的SVM和回归器。
3、Fast R-CNN
- 改进了R-CNN,将特征提取、分类、边框回归整合到了一个网络内进行训练
- 但是,它的区域建议仍然依赖外部算法(Selective Search)
4、Faster R-CNN
- 它引入了RPN
- RPN是一个全卷积网络,与主检测网络(Fast R-CNN)共享完整的卷积特征图。
- 工作流程:
- 输入图片通过一个共享的卷积网络(如VGG/ResNet)提取特征图
- 特征图同时输入给两个"头":
- RPN头:在特征图上滑动,直接预测出"可能存在物体"的候选区域(区域建议)
- Fast R-CNN头:利用RPN提出的候选区域,在同一个特征图上进行ROI池化,然后完成最终的物体分类和边界框精确回归。
二、YOLOv1
将检测问题转化为一个回归问题。
第一步:划分网络
将输入图像(如448x448)均匀划分为SxS个网格(如7x7)。
第二步:每个网格负责预测
每个网格单元格需要负责预测:
- B个边界框:每个框预测5个值(x, y, w, h, confidence)。
- (x, y):框中心相对于该网格单元的位置。
- (w, h):框的宽高相对于整个图像的比例。
- confidence(置信度):这个框包含物体的把握有多大 * 预测框与真实框的重合度。
- C个类别概率:无论预测多少个框,这个网格只预测一组类别概率,表示该网格内存在某类物体的概率。
第三步:整合输出
网络最终输出一个 S x S x (B5 + C) 的张量。例如7x7网格,预测2个框,20个类别,输出就是 7 x 7 x (25 + 20) = 7 x 7 x 30。通过这个固定大小的张量,就编码了整张图的所有检测结果
三、YOLOv3
1、Darknet-53骨干网络:更强的特征提取器
核心思想:借鉴ResNet的成果经验,解决深层网络中的梯度消失问题。
2、锚框机制(先验框)的优化:更准的起点
核心思想:让网络预测框的起点(锚框)更贴合数据集中物体的真实形状,降低学习难度,提升定位精度。
YOLOv1的局限:每个网格预测2个框,其形状是网络从头开始学习的,效率较低且难以覆盖多样的物体形状。
YOLOv3的改进:
- K-means聚类生成:在训练集的所有真实标注框上,使用K-means算法对框的宽高进行聚类(不关心中心点位置)。YOLOv3为3个不同尺度的输出层分别聚类出9组宽高,总共9个先验锚框。
- 预测调整量:网络不再直接预测框的绝对坐标,而是预测相对于预先分配好的锚框的偏移量(tx,ty,tw,th)和置信度。
- 分配策略:训练时,计算每个真实框与所有锚框的IOU,将真实框分配给与其形状最匹配的锚框,由该锚框所在的网格负责预测。
3、多尺度预测(特征金字塔网络,FPN思想):通吃大小目标
核心思想,在不同层次的特征图上进行检测,让浅层特征负责小物体,深层特征负责大物体,解决多尺度目标检测难题。
问题根源:CNN深层特征图尺寸小,感受野大,语义信息强,适合检测大物体;浅层特征图尺寸大,感受野小,细节信息丰富,适合检测小物体。传统单一尺度的检测器(如在最后的特征图上检测)会丢失小物体信息。
YOLOv3的解决方案:
- (1)三个检测头:在Darknet-53的基础上,网络在三个不同尺度的特征图上添加了检测层
- 尺度一(深层次):13 x 13 特征图 → 负责检测大物体。
- 尺度二(中层次):26 x 26 特征图 → 负责检测中物体。
- 尺度三(浅层次):52 x 52 特征图 → 负责检测小物体。
- (2)特征融合(上采样与拼接)
四、YOLOv5
集大成者,成为工程实践的标杆。融合了大量当时有效的"技巧":更强的数据增强(Mosaic)、更优的骨干网络(CSPDarknet)、更高效的特征融合(PANet)、自适应的锚框计算等,在速度和精度上达到极佳平衡。
灵活配置:提供 nano/tiny/small/medium/large 五种模型尺寸,适配不同硬件环境。
yaml
# YOLOv5 五种预训练模型(检测任务)
yolov5n.pt: # Nano - 1.9M参数 - 边缘设备(树莓派、手机)
yolov5s.pt: # Small - 7.2M参数 - 轻量级应用
yolov5m.pt: # Medium - 21M参数 - 平衡型(最常用)
yolov5l.pt: # Large - 47M参数 - 高精度需求
yolov5x.pt: # XLarge - 87M参数 - 服务器/云端
# 性能对比(COCO数据集)
模型 | mAP@0.5 | 速度(FPS) | 内存占用 | 适用场景
--------|---------|-----------|----------|---------
yolov5n | 45.7 | 280 | 1.8GB | 嵌入式、移动端
yolov5s | 56.8 | 220 | 2.4GB | 实时视频流
yolov5m | 64.1 | 140 | 4.2GB | 通用检测
yolov5l | 67.3 | 99 | 6.8GB | 工业质检
yolov5x | 68.9 | 75 | 10.1GB | 自动驾驶这里的原文https://blog.csdn.net/afghjhg/article/details/155888665
五、YOLOv8
改进骨干网络:采用 RepVGG 风格的卷积块,提升推理速度。
混合损失函数:结合 CIoU 损失与 BCEWithLogitsLoss,优化训练稳定性。
动态标签分配:通过 TaskAlignedAssigner 实现正负样本自适应匹配。
统一架构设计:一个框架,囊括检测,分割,分类和关键点检测四种任务。
六、YOLOv10
无NMS设计
YOLOv10通过"双标签分配"和"一致性匹配"训练策略,让网络在推理时每个目标只产生一个高质量预测框,从而彻底消除了对后处理NMS的依赖。
(一)为什么需要NMS?
1、冗余预测问题:对于一个真实物体,会有多个锚框预测它,产生大量重叠的预测框。
2、NMS的作用:NMS是一个后处理步骤,它遍历所有预测框,保留置信度最高的,并抑制掉与其高度重叠的其他框。
3、NMS的缺点:
拖慢速度:NMS计算(尤其是排序和IOU计算),会拖累整体FPS;
超参数敏感:NMS阈值需要手动调整,阈值设置不好,会导致漏检(阈值太高)或误检(阈值太低);
破坏端到端性:NMS是一个不可微的启发式后处理,打断了从图像到结果的纯神经网络流水线,无法通过梯度反向传播优化。
(二)解决方案
1、双标签分配策略
传统做法(单标签分配):在训练时,一个真实物体通常被分配给多个预测框(正样本)去学习。这导致网络学会了对同一个物体产生多个相似的高分预测。推理时自然需要NMS来清理。
YOLOv10的双标签分配:
第一个标签分配(一对一):采用类似于DETR的匈牙利匹配,强制每个真实物体只匹配一个最优的预测框。这确保了在"一对一"分支上,每个物体只有一个对应的预测输出。
第二个标签分配(一对多):同时保留传统的"一对多"分配(如YOLO的标签分配规则),让多个预测框去学习同一个物体。
关键:两个分配策略同时用于训练同一个网络。
2、一致性匹配训练
目标:让"一对一"分支学到的独特性,去引导和约束"一对多"分支,最终让整个网络在"一对多"模式下也能表现出"一对一"的行为------即每个物体只输出一个最佳预测。
如何实现?
网络有两个输出头:一个用于"一对一"预测,一个用于"一对多"预测,但它们共享主干特征。
损失函数设计:
"一对多"分支使用常规的检测损失。
"一对一"分支除了检测损失,还增加了一个一致性约束损失。这个损失要求"一对一"分支选出的那个最优预测框,在"一对多"分支的对应位置也必须是得分最高的框。
效果:通过这种约束,"一对多"分支中那些非最优的、负责预测同一物体的其他框,会被训练得得分很低。在推理时,只需一个简单的置信度阈值过滤(如只保留得分>0.5的框),剩下的就是不多不少、正好每个物体一个的预测框。