Q1、公平的糖果交换
1、题目描述
爱丽丝和鲍勃拥有不同总数量的糖果。给你两个数组 aliceSizes 和 bobSizes ,aliceSizes[i] 是爱丽丝拥有的第 i 盒糖果中的糖果数量,bobSizes[j] 是鲍勃拥有的第 j 盒糖果中的糖果数量。
两人想要互相交换一盒糖果,这样在交换之后,他们就可以拥有相同总数量的糖果。一个人拥有的糖果总数量是他们每盒糖果数量的总和。
返回一个整数数组 answer,其中 answer[0] 是爱丽丝必须交换的糖果盒中的糖果的数目,answer[1] 是鲍勃必须交换的糖果盒中的糖果的数目。如果存在多个答案,你可以返回其中 任何一个 。题目测试用例保证存在与输入对应的答案。
示例 1:
输入:aliceSizes = [1,1], bobSizes = [2,2] 输出:[1,2]示例 2:
输入:aliceSizes = [1,2], bobSizes = [2,3] 输出:[1,2]示例 3:
输入:aliceSizes = [2], bobSizes = [1,3] 输出:[2,3]示例 4:
输入:aliceSizes = [1,2,5], bobSizes = [2,4] 输出:[5,4]提示:
1 <= aliceSizes.length, bobSizes.length <= 1041 <= aliceSizes[i], bobSizes[j] <= 105- 爱丽丝和鲍勃的糖果总数量不同。
- 题目数据保证对于给定的输入至少存在一个有效答案。
2、解题思路
方法一:哈希集合法
- 计算两人糖果总数的差值
- 确定需要交换的糖果数量的差值
- 使用哈希集合快速查找是否存在满足条件的交换对
方法二:排序+双指针法
- 对两个数组进行排序
- 使用双指针法寻找满足条件的交换对
3、代码实现
C++
c++
// 方法一: 哈希集合法
class Solution {
public:
vector<int> fairCandySwap(vector<int>& aliceSizes, vector<int>& bobSizes) {
// 计算两人糖果总数
int sumA = accumulate(aliceSizes.begin(), aliceSizes.end(), 0);
int sumB = accumulate(bobSizes.begin(), bobSizes.end(), 0);
// 计算需要交换的差值
int delta = (sumA - sumB) / 2;
// 将爱丽丝的糖果存入哈希集合
unordered_set<int> aliceSet(aliceSizes.begin(), aliceSizes.end());
// 遍历鲍勃的糖果, 寻找满足条件的交换对
for (int y : bobSizes) {
int x = y + delta;
if (aliceSet.count(x)) {
return {x, y};
}
}
return {}; // 题目保证有解, 这里不会执行
}
};
c++
// 方法二: 排序 + 双指针法
class Solution {
public:
vector<int> fairCandySwap(vector<int>& aliceSizes, vector<int>& bobSizes) {
// 计算两人糖果总数
int sumA = accumulate(aliceSizes.begin(), aliceSizes.end(), 0);
int sumB = accumulate(bobSizes.begin(), bobSizes.end(), 0);
int delta = (sumA - sumB) / 2;
// 排序两个数组
sort(aliceSizes.begin(), aliceSizes.end());
sort(bobSizes.begin(), bobSizes.end());
// 双指针查找
int i = 0, j = 0;
while (i < aliceSizes.size() && j < bobSizes.size()) {
int diff = aliceSizes[i] - bobSizes[j];
if (diff == delta) {
return {aliceSizes[i], bobSizes[j]};
} else if (diff < delta) {
++i;
} else {
++j;
}
}
return {}; // 题目保证有解,这里不会执行
}
};Java
java
// 方法一: 哈希集合法
class Solution {
public int[] fairCandySwap(int[] aliceSizes, int[] bobSizes) {
// 计算两人糖果总数
int sumA = Arrays.stream(aliceSizes).sum();
int sumB = Arrays.stream(bobSizes).sum();
// 计算需要交换的差值
int delta = (sumA - sumB) / 2;
// 将爱丽丝的糖果存入哈希集合
Set<Integer> aliceSet = new HashSet<>();
for (int num : aliceSizes) {
aliceSet.add(num);
}
// 遍历鲍勃的糖果,寻找满足条件的交换对
for (int y : bobSizes) {
int x = y + delta;
if (aliceSet.contains(x)) {
return new int[] { x, y };
}
}
return new int[0]; // 题目保证有解,这里不会执行
}
}
java
// 方法二: 排序 + 双指针法
class Solution {
public int[] fairCandySwap(int[] aliceSizes, int[] bobSizes) {
// 计算两人糖果总数
int sumA = Arrays.stream(aliceSizes).sum();
int sumB = Arrays.stream(bobSizes).sum();
int delta = (sumA - sumB) / 2;
// 排序两个数组
Arrays.sort(aliceSizes);
Arrays.sort(bobSizes);
// 双指针查找
int i = 0, j = 0;
while (i < aliceSizes.length && j < bobSizes.length) {
int diff = aliceSizes[i] - bobSizes[j];
if (diff == delta) {
return new int[] { aliceSizes[i], bobSizes[j] };
} else if (diff < delta) {
i++;
} else {
j++;
}
}
return new int[0]; // 题目保证有解,这里不会执行
}
}Python
python
# 方法一: 哈希集合法
class Solution:
def fairCandySwap(self, aliceSizes: List[int], bobSizes: List[int]) -> List[int]:
# 计算两人糖果总数
sumA = sum(aliceSizes)
sumB = sum(bobSizes)
# 计算需要交换的差值
delta = (sumA - sumB) // 2
# 将爱丽丝的糖果存入集合
aliceSet = set(aliceSizes)
# 遍历鲍勃的糖果,寻找满足条件的交换对
for y in bobSizes:
x = y + delta
if x in aliceSet:
return [x, y]
return [] # 题目保证有解,这里不会执行
python
# 方法二: 排序 + 双指针法
class Solution:
def fairCandySwap(self, aliceSizes: List[int], bobSizes: List[int]) -> List[int]:
# 计算两人糖果总数
sumA = sum(aliceSizes)
sumB = sum(bobSizes)
delta = (sumA - sumB) // 2
# 排序两个数组
aliceSizes.sort()
bobSizes.sort()
# 双指针查找
i, j = 0, 0
while i < len(aliceSizes) and j < len(bobSizes):
diff = aliceSizes[i] - bobSizes[j]
if diff == delta:
return [aliceSizes[i], bobSizes[j]]
elif diff < delta:
i += 1
else:
j += 1
return [] # 题目保证有解,这里不会执行4、复杂度分析
方法一:哈希集合法
- 时间复杂度:O(m+n),其中m和n分别是两个数组的长度
- 空间复杂度:O(m),用于存储爱丽丝的糖果盒
方法二:排序+双指针法
- 时间复杂度:O(mlogm + nlogn),排序的时间复杂度
- 空间复杂度:O(1)或O(logm + logn),取决于排序算法的实现
Q2、查找和替换模式
1、题目描述
你有一个单词列表 words 和一个模式 pattern,你想知道 words 中的哪些单词与模式匹配。
如果存在字母的排列 p ,使得将模式中的每个字母 x 替换为 p(x) 之后,我们就得到了所需的单词,那么单词与模式是匹配的。
(回想一下,字母的排列是从字母到字母的双射:每个字母映射到另一个字母,没有两个字母映射到同一个字母。)
返回 words 中与给定模式匹配的单词列表。
你可以按任何顺序返回答案。
示例:
输入:words = ["abc","deq","mee","aqq","dkd","ccc"], pattern = "abb" 输出:["mee","aqq"] 解释: "mee" 与模式匹配,因为存在排列 {a -> m, b -> e, ...}。 "ccc" 与模式不匹配,因为 {a -> c, b -> c, ...} 不是排列。 因为 a 和 b 映射到同一个字母。提示:
1 <= words.length <= 501 <= pattern.length = words[i].length <= 20
2、解题思路
方法一:双向映射检查法
- 检查单词到模式的映射是否一致
- 同时检查模式到单词的映射是否一致
- 只有两个方向都满足一一对应关系才匹配
方法二:规范化法
- 将单词和模式都转换为相同的规范化形式
- 比较规范化后的结果是否相同
3、代码实现
C++
c++
// 方法1: 双向映射检查法
class Solution {
private:
bool match(string& word, string& pattern) {
unordered_map<char, char> wordToPat; // 单词到模式的映射
unordered_map<char, char> patToWord; // 模式到单词的映射
for (int i = 0; i < word.size(); ++i) {
char w = word[i], p = pattern[i];
// 检查单词到模式的映射
if (wordToPat.count(w) && wordToPat[w] != p) {
return false;
}
// 检查模式到单词的映射
if (patToWord.count(p) && patToWord[p] != w) {
return false;
}
// 建立双向映射关系
wordToPat[w] = p;
patToWord[p] = w;
}
return true;
}
public:
vector<string> findAndReplacePattern(vector<string>& words, string pattern) {
vector<string> result;
for (auto& word : words) {
if (match(word, pattern)) {
result.push_back(word);
}
}
return result;
}
};
c++
// 方法2: 规范化法
class Solution {
private:
string normalize(string s) {
unordered_map<char, int> mapping;
int counter = 0;
string result;
for (char c : s) {
if (!mapping.count(c)) {
mapping[c] = counter++;
}
result += to_string(mapping[c]) + " ";
}
return result;
}
public:
vector<string> findAndReplacePattern(vector<string>& words, string pattern) {
string patternNorm = normalize(pattern);
vector<string> result;
for (auto& word : words) {
if (normalize(word) == patternNorm) {
result.push_back(word);
}
}
return result;
}
};Java
java
// 方法1: 双向映射检查法
class Solution {
private boolean match(String word, String pattern) {
Map<Character, Character> wordToPat = new HashMap<>();
Map<Character, Character> patToWord = new HashMap<>();
for (int i = 0; i < word.length(); i++) {
char w = word.charAt(i);
char p = pattern.charAt(i);
// 检查单词到模式的映射
if (wordToPat.containsKey(w) && wordToPat.get(w) != p) {
return false;
}
// 检查模式到单词的映射
if (patToWord.containsKey(p) && patToWord.get(p) != w) {
return false;
}
// 建立双向映射关系
wordToPat.put(w, p);
patToWord.put(p, w);
}
return true;
}
public List<String> findAndReplacePattern(String[] words, String pattern) {
List<String> result = new ArrayList<>();
for (String word : words) {
if (match(word, pattern)) {
result.add(word);
}
}
return result;
}
}
java
// 方法2: 规范化法
class Solution {
private String normalize(String s) {
Map<Character, Integer> mapping = new HashMap<>();
int counter = 0;
StringBuilder sb = new StringBuilder();
for (char c : s.toCharArray()) {
if (!mapping.containsKey(c)) {
mapping.put(c, counter++);
}
sb.append(mapping.get(c)).append(" ");
}
return sb.toString();
}
public List<String> findAndReplacePattern(String[] words, String pattern) {
String patternNorm = normalize(pattern);
List<String> result = new ArrayList<>();
for (String word : words) {
if (normalize(word).equals(patternNorm)) {
result.add(word);
}
}
return result;
}
}Python
python
# 方法1: 双向映射检查法
class Solution:
def findAndReplacePattern(self, words: List[str], pattern: str) -> List[str]:
def match(word):
if len(word) != len(pattern):
return False
word_to_pat = {}
pat_to_word = {}
for w, p in zip(word, pattern):
# 检查单词到模式的映射
if w in word_to_pat and word_to_pat[w] != p:
return False
# 检查模式到单词的映射
if p in pat_to_word and pat_to_word[p] != w:
return False
# 建立双向映射关系
word_to_pat[w] = p
pat_to_word[p] = w
return True
return [word for word in words if match(word)]
python
# 方法2: 规范化法
class Solution:
def findAndReplacePattern(self, words: List[str], pattern: str) -> List[str]:
def normalize(s):
mapping = {}
counter = 0
result = []
for c in s:
if c not in mapping:
mapping[c] = counter
counter += 1
result.append(str(mapping[c]))
return ' '.join(result)
pattern_norm = normalize(pattern)
return [word for word in words if normalize(word) == pattern_norm]4、复杂度分析
方法一:双向映射检查法
- 时间复杂度:O(n*m),其中n是单词数量,m是单词长度
- 空间复杂度:O(m),用于存储字符映射
方法二:规范化法
- 时间复杂度:O(n*m)
- 空间复杂度:O(m)
Q3、根据前序和后序遍历构造二叉树
1、题目描述
给定两个整数数组,preorder 和 postorder ,其中 preorder 是一个具有 无重复 值的二叉树的前序遍历,postorder 是同一棵树的后序遍历,重构并返回二叉树。
如果存在多个答案,您可以返回其中 任何 一个。
示例 1:
输入:preorder = [1,2,4,5,3,6,7], postorder = [4,5,2,6,7,3,1] 输出:[1,2,3,4,5,6,7]示例 2:
输入: preorder = [1], postorder = [1] 输出: [1]提示:
1 <= preorder.length <= 301 <= preorder[i] <= preorder.lengthpreorder中所有值都 不同postorder.length == preorder.length1 <= postorder[i] <= postorder.lengthpostorder中所有值都 不同- 保证
preorder和postorder是同一棵二叉树的前序遍历和后序遍历
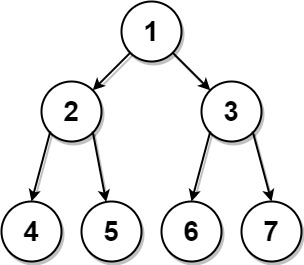
2、解题思路
方法一:递归构造法
- 前序遍历的第一个元素是根节点,后序遍历的最后一个元素也是根节点
- 在前序遍历中找到左子树的根节点(即根节点后的第一个节点)
- 在后序遍历中找到该左子树根节点的位置,从而确定左子树和右子树的范围
- 递归构建左右子树
方法二:哈希优化递归法
- 使用哈希表存储postorder中值到索引的映射,优化查找效率
- 递归构建树结构,利用哈希表快速定位分割点
方法三:迭代构造法
- 使用栈来模拟递归过程
- 维护当前子树的根节点和构建状态
- 根据前序和后序序列的特点逐步构建树结构
3、代码实现
C++
c++
// 方法1: 递归构造法
class Solution {
public:
TreeNode* constructFromPrePost(vector<int>& preorder, vector<int>& postorder) {
int n = preorder.size();
if (n == 0) {
return nullptr;
}
// 创建根节点
TreeNode* root = new TreeNode(preorder[0]);
if (n == 1) {
return root;
}
// 在前序遍历中, 左子树的根是 preorder[1]
// 在后序遍历中找到左子树根的位置
int leftRootVal = preorder[1];
int leftRootPosInPost = 0;
for (; leftRootPosInPost < n; ++leftRootPosInPost) {
if (postorder[leftRootPosInPost] == leftRootVal) {
break;
}
}
// 计算左子树节点数
int leftSize = leftRootPosInPost + 1;
// 递归构建左右子树
vector<int> leftPre(preorder.begin() + 1, preorder.begin() + 1 + leftSize);
vector<int> leftPost(postorder.begin(), postorder.begin() + leftSize);
root->left = constructFromPrePost(leftPre, leftPost);
vector<int> rightPre(preorder.begin() + 1 + leftSize, preorder.end());
vector<int> rightPost(postorder.begin() + leftSize, postorder.end() - 1);
root->right = constructFromPrePost(rightPre, rightPost);
return root;
}
};
c++
// 方法2: 哈希优化递归法
class Solution {
public:
TreeNode* constructFromPrePost(vector<int>& preorder, vector<int>& postorder) {
unordered_map<int, int> postMap;
for (int i = 0; i < postorder.size(); ++i) {
postMap[postorder[i]] = i;
}
function<TreeNode*(int, int, int, int)> build = [&](int preLeft, int preRight, int postLeft, int postRight) -> TreeNode* {
if (preLeft > preRight) {
return nullptr;
}
TreeNode* root = new TreeNode(preorder[preLeft]);
if (preLeft == preRight) {
return root;
}
int leftRootVal = preorder[preLeft + 1];
int leftRootPos = postMap[leftRootVal];
int leftSize = leftRootPos - postLeft + 1;
root->left = build(preLeft + 1, preLeft + leftSize, postLeft, leftRootPos);
root->right = build(preLeft + leftSize + 1, preRight, leftRootPos + 1, postRight - 1);
return root;
};
return build(0, preorder.size() - 1, 0, postorder.size() - 1);
}
};
c++
// 方法3: 迭代构造法
class Solution {
public:
TreeNode* constructFromPrePost(vector<int>& preorder, vector<int>& postorder) {
if (preorder.empty()) {
return nullptr;
}
stack<TreeNode*> stk;
TreeNode* root = new TreeNode(preorder[0]);
stk.push(root);
for (int i = 1, j = 0; i < preorder.size(); ++i) {
TreeNode* node = new TreeNode(preorder[i]);
while (stk.top()->val == postorder[j]) {
stk.pop();
++j;
}
if (!stk.top()->left) {
stk.top()->left = node;
} else {
stk.top()->right = node;
}
stk.push(node);
}
return root;
}
};Java
java
// 方法1: 递归构造法
class Solution {
public TreeNode constructFromPrePost(int[] preorder, int[] postorder) {
int n = preorder.length;
if (n == 0) {
return null;
}
TreeNode root = new TreeNode(preorder[0]);
if (n == 1) {
return root;
}
int leftRootVal = preorder[1];
int leftRootPosInPost = 0;
for (; leftRootPosInPost < n; leftRootPosInPost++) {
if (postorder[leftRootPosInPost] == leftRootVal) {
break;
}
}
int leftSize = leftRootPosInPost + 1;
root.left = constructFromPrePost(
Arrays.copyOfRange(preorder, 1, 1 + leftSize),
Arrays.copyOfRange(postorder, 0, leftSize));
root.right = constructFromPrePost(
Arrays.copyOfRange(preorder, 1 + leftSize, n),
Arrays.copyOfRange(postorder, leftSize, n - 1));
return root;
}
}
java
// 方法2: 哈希优化递归法
class Solution {
private Map<Integer, Integer> postMap = new HashMap<>();
public TreeNode constructFromPrePost(int[] preorder, int[] postorder) {
for (int i = 0; i < postorder.length; i++) {
postMap.put(postorder[i], i);
}
return build(preorder, 0, preorder.length - 1, 0, postorder.length - 1);
}
private TreeNode build(int[] preorder, int preLeft, int preRight, int postLeft, int postRight) {
if (preLeft > preRight) {
return null;
}
TreeNode root = new TreeNode(preorder[preLeft]);
if (preLeft == preRight) {
return root;
}
int leftRootVal = preorder[preLeft + 1];
int leftRootPos = postMap.get(leftRootVal);
int leftSize = leftRootPos - postLeft + 1;
root.left = build(preorder, preLeft + 1, preLeft + leftSize, postLeft, leftRootPos);
root.right = build(preorder, preLeft + leftSize + 1, preRight, leftRootPos + 1, postRight - 1);
return root;
}
}
java
// 方法3: 迭代构造法
class Solution {
public TreeNode constructFromPrePost(int[] preorder, int[] postorder) {
if (preorder.length == 0) {
return null;
}
Deque<TreeNode> stack = new ArrayDeque<>();
TreeNode root = new TreeNode(preorder[0]);
stack.push(root);
for (int i = 1, j = 0; i < preorder.length; i++) {
TreeNode node = new TreeNode(preorder[i]);
while (stack.peek().val == postorder[j]) {
stack.pop();
j++;
}
if (stack.peek().left == null) {
stack.peek().left = node;
} else {
stack.peek().right = node;
}
stack.push(node);
}
return root;
}
}Python
python
# 方法1: 递归构造法
class Solution:
def constructFromPrePost(self, preorder: List[int], postorder: List[int]) -> Optional[TreeNode]:
if not preorder:
return None
root = TreeNode(preorder[0])
if len(preorder) == 1:
return root
left_root_val = preorder[1]
left_size = postorder.index(left_root_val) + 1
root.left = self.constructFromPrePost(
preorder[1:1+left_size],
postorder[:left_size]
)
root.right = self.constructFromPrePost(
preorder[1+left_size:],
postorder[left_size:-1]
)
return root
python
# 方法2: 哈希优化递归法
class Solution:
def constructFromPrePost(self, preorder: List[int], postorder: List[int]) -> Optional[TreeNode]:
post_map = {val: idx for idx, val in enumerate(postorder)}
def build(pre_left, pre_right, post_left, post_right):
if pre_left > pre_right:
return None
root = TreeNode(preorder[pre_left])
if pre_left == pre_right:
return root
left_root_val = preorder[pre_left + 1]
left_root_pos = post_map[left_root_val]
left_size = left_root_pos - post_left + 1
root.left = build(pre_left + 1, pre_left + left_size, post_left, left_root_pos)
root.right = build(pre_left + left_size + 1, pre_right, left_root_pos + 1, post_right - 1)
return root
return build(0, len(preorder) - 1, 0, len(postorder) - 1)
python
# 方法3: 迭代构造法
class Solution:
def constructFromPrePost(self, preorder: List[int], postorder: List[int]) -> Optional[TreeNode]:
if not preorder:
return None
root = TreeNode(preorder[0])
stack = [root]
j = 0
for i in range(1, len(preorder)):
node = TreeNode(preorder[i])
while stack[-1].val == postorder[j]:
stack.pop()
j += 1
if not stack[-1].left:
stack[-1].left = node
else:
stack[-1].right = node
stack.append(node)
return root4、复杂度分析
方法一:递归构造法
- 时间复杂度:O(n^2),最坏情况下每次在postorder中查找位置需要O(n)时间
- 空间复杂度:O(n),递归栈的深度
方法二:哈希优化递归法
- 时间复杂度:O(n),哈希表使查找时间降为O(1)
- 空间复杂度:O(n),哈希表存储空间
方法三:迭代构造法
- 时间复杂度:O(n),每个节点处理一次
- 空间复杂度:O(n),栈的空间
Q4、子序列宽度之和
1、题目描述
一个序列的 宽度 定义为该序列中最大元素和最小元素的差值。
给你一个整数数组 nums ,返回 nums 的所有非空 子序列 的 宽度之和 。由于答案可能非常大,请返回对 109 + 7 取余 后的结果。
子序列 定义为从一个数组里删除一些(或者不删除)元素,但不改变剩下元素的顺序得到的数组。例如,[3,6,2,7] 就是数组 [0,3,1,6,2,2,7] 的一个子序列。
示例 1:
输入:nums = [2,1,3] 输出:6 解释:子序列为 [1], [2], [3], [2,1], [2,3], [1,3], [2,1,3] 。 相应的宽度是 0, 0, 0, 1, 1, 2, 2 。 宽度之和是 6 。示例 2:
输入:nums = [2] 输出:0提示:
1 <= nums.length <= 1051 <= nums[i] <= 105
2、解题思路
方法一:排序后数学计算
- 首先对数组进行排序,这样我们可以方便地计算每个元素作为最大值和最小值时的贡献
- 对于每个元素numsi,计算它作为最大值和最小值的次数
- 使用数学公式计算总宽度和:sum(numsi * (2i - 2(n-1-i))) for all i
3、代码实现
C++
c++
class Solution {
public:
int sumSubseqWidths(vector<int>& nums) {
const int MOD = 1e9 + 7;
sort(nums.begin(), nums.end());
int n = nums.size();
vector<long long> pow2(n);
pow2[0] = 1;
for (int i = 1; i < n; ++i) {
pow2[i] = (pow2[i - 1] * 2) % MOD;
}
long long res = 0;
for (int i = 0; i < n; ++i) {
res = (res + nums[i] * (pow2[i] - pow2[n - 1 - i])) % MOD;
}
return (res + MOD) % MOD;
}
};Java
java
class Solution {
public int sumSubseqWidths(int[] nums) {
final int MOD = 1000000007;
Arrays.sort(nums);
int n = nums.length;
long[] pow2 = new long[n];
pow2[0] = 1;
for (int i = 1; i < n; i++) {
pow2[i] = (pow2[i - 1] * 2) % MOD;
}
long res = 0;
for (int i = 0; i < n; i++) {
res = (res + nums[i] * (pow2[i] - pow2[n - 1 - i])) % MOD;
}
return (int) ((res + MOD) % MOD);
}
}Python
python
class Solution:
def sumSubseqWidths(self, nums: List[int]) -> int:
MOD = 10**9 + 7
nums.sort()
n = len(nums)
pow2 = [1] * n
for i in range(1, n):
pow2[i] = (pow2[i-1] * 2) % MOD
res = 0
for i in range(n):
res = (res + nums[i] * (pow2[i] - pow2[n-1-i])) % MOD
return res4、复杂度分析
方法一:排序后数学计算
- 时间复杂度:O(n log n),主要来自排序
- 空间复杂度:O(1),仅使用常数空间