FutureX 要点总结(小鹏)
关键图表说明
Figure 1 :展示了 FutureX 的整体架构
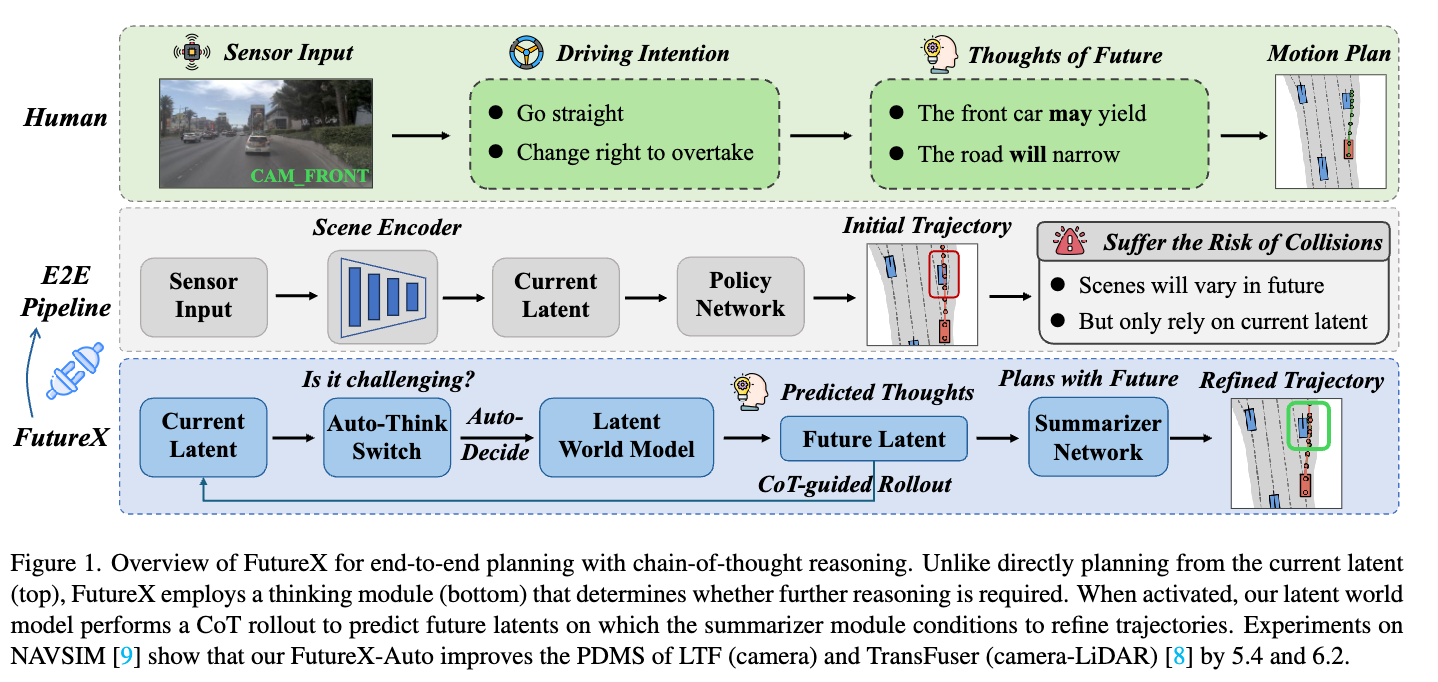
- 顶部:直接从当前潜在状态规划(传统方法)
- 底部:通过思考模块决定是否需要进一步推理,激活时进行 CoT 展开预测未来潜在状态,Summarizer 模块基于此精炼轨迹
一、相关工作 (Related Work)
论文在第2节回顾了以下方向:
1. 端到端自动驾驶 (End-to-End Autonomous Driving)
- 分为两类:模仿学习 (Imitation Learning, IL) 和 强化学习 (Reinforcement Learning, RL)
- 代表性方法:
- LTF
- TransFuser
- DriveTransformer
- VAD (Vectorized scene representation)
- DiffusionDrive
- SparseDrive等
2. 世界模型 (World Model)
- 用于建模场景演化
- 相关工作:
- GAIA
- World4Drive
- Epona
- Driving into the Future等
3. Chain-of-Thought (CoT) 推理
- 在自动驾驶中的应用:
- DriveLM
- DriveVLM
- Emma等
- 局限性:这些方法主要在文本域生成解释,与实际的控制过程脱节
二、核心思想 (Core Idea)
1. 问题定义
- 现有端到端系统仅基于当前场景进行单次前向预测,在高度动态的交通环境中可能产生次优响应
- 自车行为会改变未来场景,需要推理未来场景演化
2. 解决方案
- 引入潜在 Chain-of-Thought 推理:将 CoT 重新解释为状态演化和动作选择
- 每个推理步骤对应潜在世界模型的前向展开,随后进行内部策略评估
- 建立推理(思考)与规划(行动)之间的可微分、可学习接口
3. 工作流程
当前场景 → Auto-think Switch → 判断是否需要推理
↓
[需要] → Thinking 模式 → 潜在世界模型 CoT 展开 → 预测未来场景表示
↓
Summarizer Network → 基于未来表示和初始计划预测偏移量 → 精炼运动计划
[不需要] → Instant 模式 → 直接前向生成运动计划核心组件:
- Auto-think Switch:评估当前场景的规划难度,决定是否激活世界模型
- Thinking 模式:潜在世界模型进行 CoT 引导的展开,预测未来场景表示
- Summarizer Network:基于未来表示和初始运动计划预测偏移量
- Instant 模式:简单场景下直接前向生成运动计划
三、创新点 (Contributions)
1. 概念创新
- 将 CoT 重新定义为潜在未来推理:在可学习的世界模型-策略循环中进行显式状态演化和动作选择
2. 方法创新
- 提出 FutureX:首个 CoT 驱动的潜在世界模型
- Auto-Think Switch:选择性激活推理,在性能和效率之间取得平衡,适合实时部署
3. 实验验证
- 在经典骨干网络(LTF、TransFuser)上达到 SOTA
- 在仅相机和相机-激光雷达两种设置下均有效
四、实验结论 (Experimental Results)
1. 性能提升
在 NAVSIM 基准测试中,FutureX-Auto 相比基线方法显著提升:
| 方法 | 模态 | PDMS 提升 |
|---|---|---|
| LTF | Camera | +5.4 |
| TransFuser | Camera-LiDAR | +6.2 |
2. 主要优势
- ✅ 生成更合理的运动计划
- ✅ 减少碰撞
- ✅ 不牺牲效率(通过 Auto-Think Switch 实现性能与效率的平衡)
3. 实验设置
- 基准测试:NAVSIM
- 评估指标:PDMS (Planning Domain Metric Score) 等
- 支持模态:相机和相机-激光雷达两种模态
4. 整体结论
- FutureX 通过潜在 CoT 推理增强端到端规划器,在复杂动态交通环境中表现更好
- 方法具有通用性,可应用于多种端到端自动驾驶架构
论文信息
- 标题:FutureX: Enhance End-to-End Autonomous Driving via Latent Chain-of-Thought World Model
- arXiv:https://arxiv.org/abs/2512.11226v1
- 代码:将发布
- 作者:Hongbin Lin, Yiming Yang, Yifan Zhang, Chaoda Zheng, 等