通过 PaddleOCR CLI 安装 vLLM 推理加速框架: 把 PaddleOCR-VL 真正跑在生产环境中

在上一篇《使用 Docker 一键部署 PaddleOCR-VL:新手保姆级教程》发布后,我收到了工程师 Dario 的一条反馈,其中有一句话非常"工程师视角":
"fits perfectly within Google Cloud Run GPU in its smallest configuration (L4 GPU + 16GB RAM)"
这句话其实验证了一件非常重要、但经常被忽略的事情:
预加载模型 + vLLM 风格的推理服务设计,已经不只是"跑得快",而是真正解决了生产环境中最痛的点。
具体来说,它意味着:
- Serverless GPU 场景可行
- 最小规格 GPU(L4)即可运行
- 冷启动时间明显下降
- 成本、性能与稳定性达到一个工程上的平衡点
本篇文章,将在上一篇 Docker 部署教程的基础上,继续介绍如何通过 PaddleOCR CLI 安装并使用 vLLM 推理加速框架 。如果你还没完成基础部署,建议先阅读《使用 Docker 一键部署 PaddleOCR-VL:新手保姆级教程》 再继续。
下面直接进入实操。
一、在虚拟环境中安装vLLM
推理加速框架(如 vLLM、SGLang)对 CUDA、Torch、编译工具链依赖较重,非常容易与现有PaddlePaddle环境冲突 。因此:必须在虚拟环境中安装和使用推理加速框架。
由于paddleocr-vl镜像中,没有安装 nvcc 等编译工具,所以,在安装vllm前,必须先安装 FlashAttention 的预编译版本。
完整流程如下:
bash
# 创建虚拟环境
python -m venv .venv_vlm
# 激活虚拟环境
source .venv_vlm/bin/activate
# 安装 PaddleOCR
python -m pip install "paddleocr[doc-parser]"
# 安装FlashAttention的预编译版本(避免 nvcc 编译失败)
python -m pip install https://github.com/mjun0812/flash-attention-prebuild-wheels/releases/download/v0.3.14/flash_attn-2.8.2+cu128torch2.8-cp310-cp310-linux_x86_64.whl
# 安装vllm
paddleocr install_genai_server_deps vllm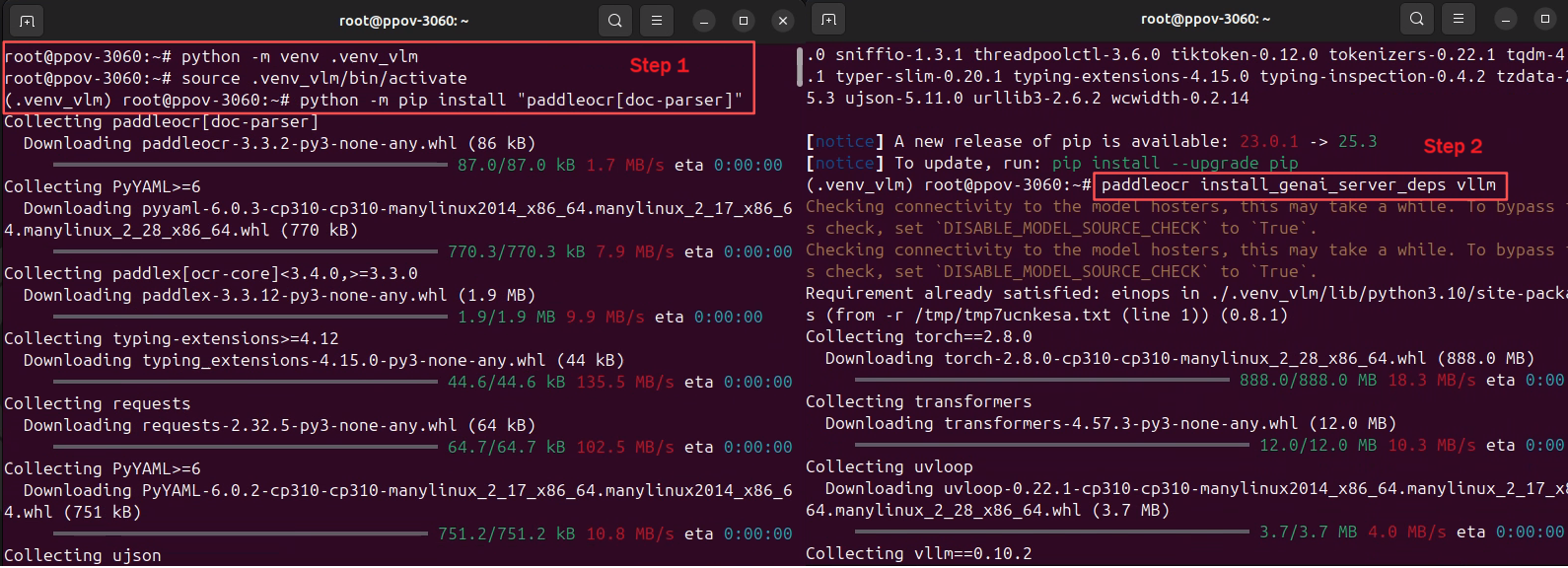
💡 这一点在很多环境中都会踩坑,先装 FlashAttention的预编译版本, 再装 vLLM 是关键顺序
二、启动 PaddleOCR-VL 推理服务
依赖安装完成后,直接启动基于vllm的PaddleOCR-VL推理服务:
bash
paddleocr genai_server \
--model_name PaddleOCR-VL-0.9B \
--backend vllm \
--port 8118 \
--backend_config <(echo -e 'gpu-memory-utilization: 0.8')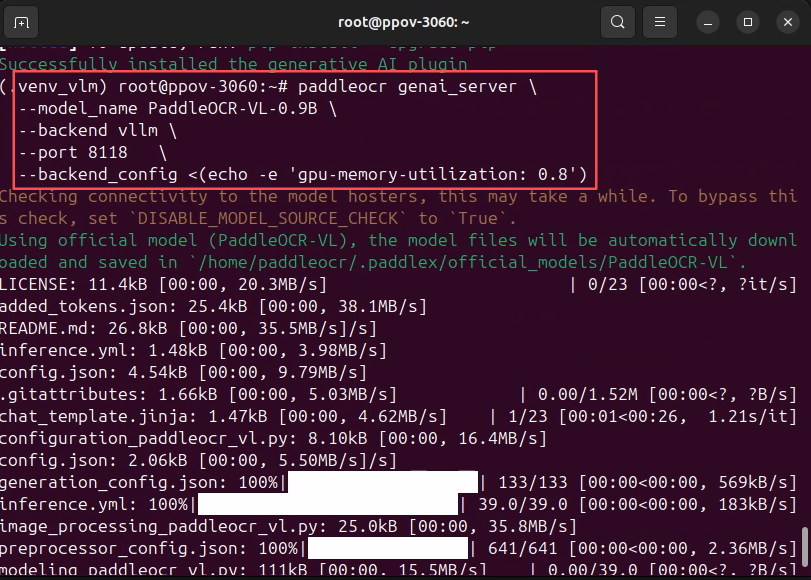
该命令会完成三件关键事情:
- 启动时预加载模型(降低冷启动)
- 使用 vLLM 作为高性能推理后端
- 对外暴露标准化推理服务接口
paddleocr genai_server 命令,常用参数说明
| 参数 | 说明 |
|---|---|
--model_name |
模型名称 |
--model_dir |
模型目录(可选) |
--host |
服务监听地址 |
--port |
服务端口 |
--backend |
推理后端(vllm / sglang) |
--backend_config |
后端 YAML 配置 |
在生产环境中,backend_config 常用于控制:
- 并发数
- 显存占用
- 吞吐与延迟平衡
详情参见:
vllm_config.yaml 文件范例:
yaml
gpu-memory-utilization: 0.8
max-num-seqs: 128三、编写客户端程序访问vllm
3.1 使用Python CLI访问vllm推理服务
bash
# 下载测试图片到本地
curl -o paddleocr_vl_demo.png \
https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png
# 调用vLLM推理服务
paddleocr doc_parser --input paddleocr_vl_demo.png --vl_rec_backend vllm-server --vl_rec_server_url http://localhost:8118/v1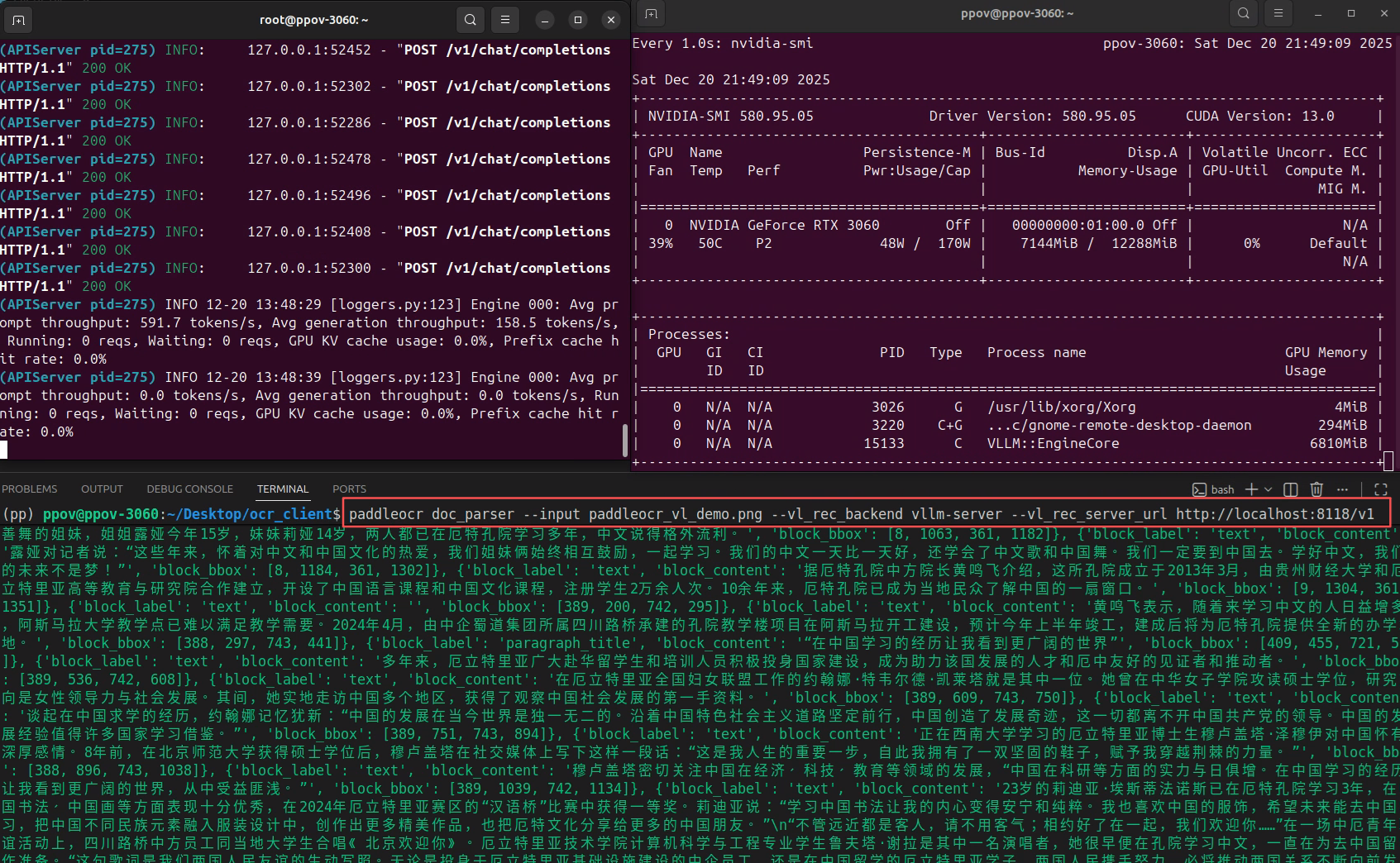
3.2 使用Python API访问vllm推理服务
客户端Python代码如下所示:
python
from paddleocr import PaddleOCRVL
pipeline = PaddleOCRVL(vl_rec_backend="vllm-server", vl_rec_server_url="http://127.0.0.1:8118/v1")
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png")
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")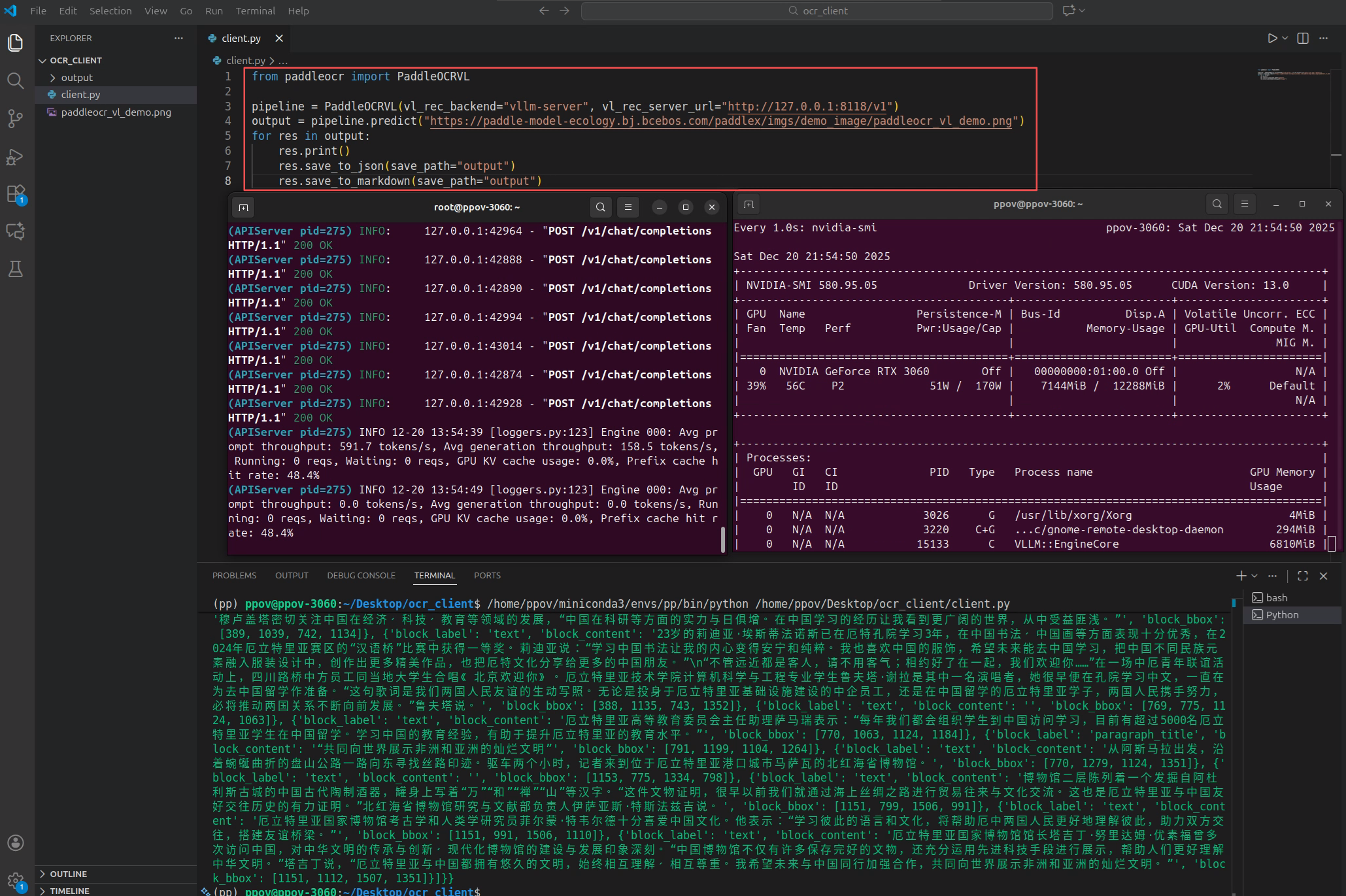
四、小结:这一步,才是真正"生产级"的关键
如果说上一篇 Docker 教程解决的是:
"如何把 PaddleOCR-VL 跑起来"
那么这一篇解决的就是:
"如何让它稳定、低成本、可扩展地跑在生产环境里"
回到文章开头那句话:
它之所以能完美适配最小规格的 Serverless GPU,
本质原因就是:模型预加载 + 推理后端解耦的工程设计。
这也是 PaddleOCR-VL 推理方向上,一个非常值得学习、也非常"工程化"的实践。
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com
更多精彩内容请关注"算力魔方®"!