一、集成学习的随机森林
1.集成学习的含义:
集成学习是将多个基学习器进行组合,来实现比单一学习器显著优越的学习性能
2.集成学习的方法:
- bagging方法:典型的是随机森林(我们要学习的)
- boosting方法:典型的是Xgboost
- stacking方法:堆叠模型
3.集成学习的应用:
- 分类问题集成
- 回归问题集成
- 特征选取集成(特征选取,也就是分辨出哪些特征是有效的哪些是无效的)
4.随机森林
1)什么是随机森林
很多个决策树,把数据给每个决策树,但是这个数据是随机选择一些数据给一个决策树,下一个决策树在进行随机选取,每个决策树得到的数据不是百分百,且是随机的,很多个决策树虽然没有学百分百,但很多个一共就学了全部的数据,,除此之外,也不是所有特征都给一个决策树,特征也随机
随机森林的特点:
- 数据采样随机
- 特征选取随机
- 森林
- 基学习器为决策树
2)随机森林的优缺点
优点:
- 具有极高的准确率
- 随机性的引入,使得随机森林的抗噪声能力很强。(噪声也就是异常数据,在某一个类别中会出现其他类的,有可能是人为统计结果时出错)
- 随机性的引入,使得随机森林不容易过拟合
- 能够处理很高维度的数据,不用做特征选择
- 容易实现并行化
- 缺点:
- 当随机森林中的决策树个数很多时,训练需要的空间和时间会比较大
3)随机森林生成步骤
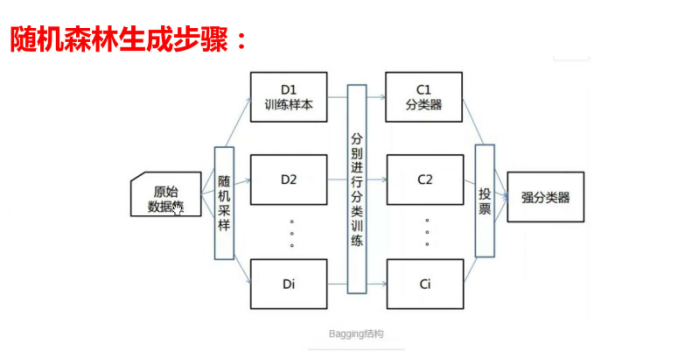
4)构造随机森林


还有
- min_impurity_split(同决策树):这个值限制了决策树的增长,如果某节点的不纯度(基于基尼系数,均方差)小于这个阈值则该点不再生成了节点,即为叶子节点。一般不改动默认值1e-7
- bootstrap=True(随机森林独有):是否又放回的采样,按默认,有放回采样
- n_jobs=1:并行job个数,这个在是bagging训练过程中有重要作用可以并行从而提高性能。1=不并行;n为n个并行,为-1的时候cpu有多少core就启动多少job,但有时候为-1会报错。
等有很多参数,其中最重要的是


5)垃圾邮件的识别(随机森林)
数据:

这里word_freq_xxx表示某个单词出现的百分比,例如这里address词出现的百分比

char_freq_1~6,匹配的电子邮件中字符的百分比
Capital_run_length_xxx中有三个,分别是Capital_run_length,Capital_run_length_average,Capital_run_length_total,这三个意思分别为最长不间断大写字母序列的长度、不间断大写字母序列的平均长度、电子邮件中大写字母的总数。
最后一列就是label,标签
代码:
python
import pandas as pd
def cm_plot(y, yp):#混淆矩阵绘制
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x), horizontalalignment='center',
verticalalignment = 'center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
df=pd.read_csv("D:\learn\代码所用文本\spambase.csv")
data=df.iloc[:,:-1]
result=df.iloc[:,-1]
from sklearn.model_selection import train_test_split
data_train,data_test,result_train,result_test=train_test_split(data,result,
test_size=0.2,random_state=100)
from sklearn.ensemble import RandomForestClassifier
forest=RandomForestClassifier(n_estimators=100,max_features=0.8,random_state=0)
forest.fit(data_train,result_train)
from sklearn import metrics
train_pre=forest.predict(data_train)
print(metrics.classification_report(result_train,train_pre,digits=6))
# cm_plot(result_train,train_pre).show()
test_pre=forest.predict(data_test)
print(metrics.classification_report(result_test,test_pre))
# cm_plot(result_test,test_pre).show()
# forest.score(data_test,result_test)也有很高的准确率和召回率

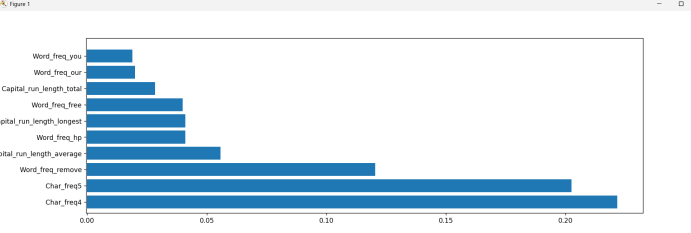
在上面代码最后加入以下代码,就可以得到重要特征的排名,这里是只取了前十的排名。并绘图站输出排名的条形统计图
python
'''特征重要程度排名'''
import matplotlib.pyplot as plt
importances=forest.feature_importances_#这个属性保存了模型中特征的重要性
im=pd.DataFrame(importances,columns=['importances'])
clos=df.columns
clos_1=clos.values
clos_2=clos_1.tolist()
clos=clos_2[0:-1]
im['clos']=clos
'''排序并只选择前十的'''
im=im.sort_values(by=['importances'],ascending=False)[:10]
'''画图画出排列前十的重要特征'''
index=range(len(im))
plt.yticks(index,im.clos)#用于获取或设置y轴的刻度和标签
plt.barh(index,im['importances'])#用于创建水平条形图
plt.show()得到图形:
二、贝叶斯算法
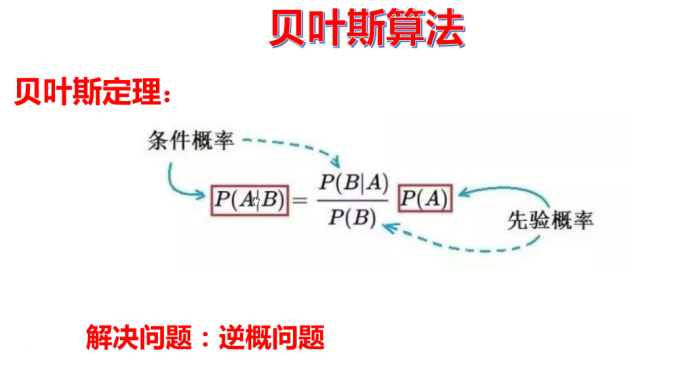
1.贝叶斯的原理
贝叶斯算法一般运用于自然原处理。

贝叶斯处理数学问题:
一个学校里面有60%的男生,40%的女生
100%的男生穿长裤,50%的女生穿长裤,50%穿裙子
此时一个穿长裤的学生走过来,出于高度近视看不清,判断一下这个长裤学生是女生的概率?

贝叶斯用于实例:
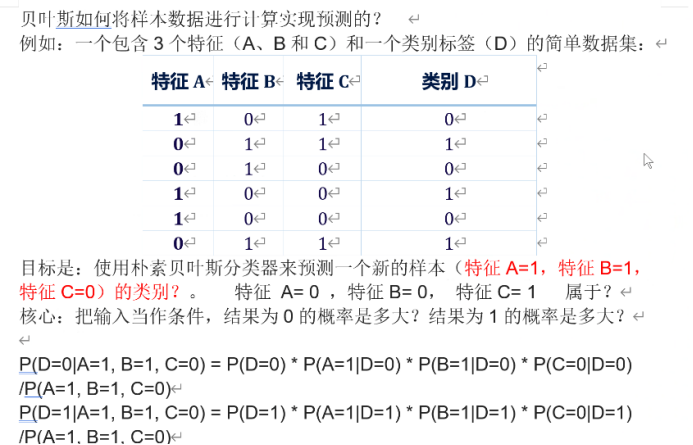
也就是我们输入一个数据,数据中中没有这种情况,此时就要求出这条数据是某个类别的概率,也就是为1的概率,和为0的概率,谁概率大就可能属于哪个类别,上图得到的两个式子分母一样,比较分子就行。

2.构建一个贝叶斯算法模型

参数很少,没什么需要控制的
3.鸢尾花判断(贝叶斯分类)
鸢尾花数据之前使用过,但是我这里使用的是没有表头的
如果使用之前的数据就需要注意这里数据的处理
代码:
python
import pandas as pd
def cm_plot(y, yp):#混淆矩阵绘制
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x), horizontalalignment='center',
verticalalignment = 'center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
data=pd.read_csv("D:\learn\代码所用文本\iris.csv",header=None)#None表示文件无表头
data=data.drop(0,axis=1)#把第一列删除
X=data.iloc[:,:-1]
Y=data.iloc[:,-1]
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=0)
from sklearn.naive_bayes import MultinomialNB#导入贝叶斯分类器
bayes=MultinomialNB(alpha=1)
bayes.fit(x_train,y_train)
from sklearn import metrics
train_pre=bayes.predict(x_train)
# cm_plot(y_train,train_pre).show()
print(metrics.classification_report(y_train, train_pre))
test_pre=bayes.predict(x_test)
# cm_plot(y_test,test_pre).show()
print(metrics.classification_report(y_test, test_pre))结果:
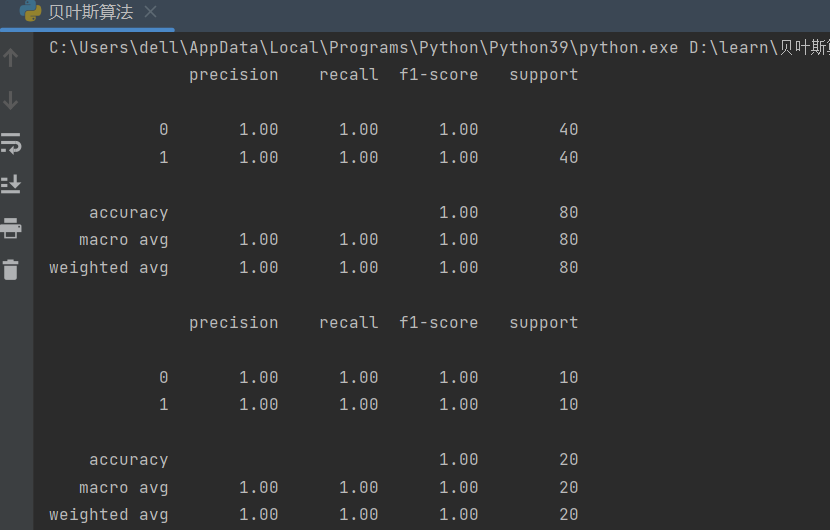
结果看似很高,但其实贝叶斯算法应用到实际问题中准确率不是很高,这里是数据的原因才会使得准确率很高。