论文标题
Hybrid Large Language Models and Reinforcement Learning for Energy-Efficient Multi-Satellite Scheduling: Boosting the Performance from Scratch
混合大语言模型与强化学习用于高能效多星调度:从零开始的性能提升
作者
Hyojun Ahn、Gyu Seon Kim(学生会员,IEEE)、In-Sop Cho、Soyi Jung(高级会员,IEEE)、Joongheon Kim(高级会员,IEEE)
出处
IEEE Internet of Things Journal,2025 年已录用(作者稿,尚未正式排版),DOI: 10.1109/JIOT.2025.3645077
研究背景与动机
低轨(LEO)巨型星座能为全球提供低时延、大容量覆盖,但卫星 7.5 km s⁻¹ 的高速运动导致拓扑持续剧变,传统调度策略难以实时收敛。纯强化学习(RL)虽可在线适应,却需数百万轮迭代才能稳定,等到策略收敛时轨道环境早已变化。作者观察到近期大语言模型(LLM)在推理与策略生成上的突破,提出"用 LLM 先给 RL 一个好起点",让卫星在轨只跑轻量 RL,地面一次性 LLM 推理即可。
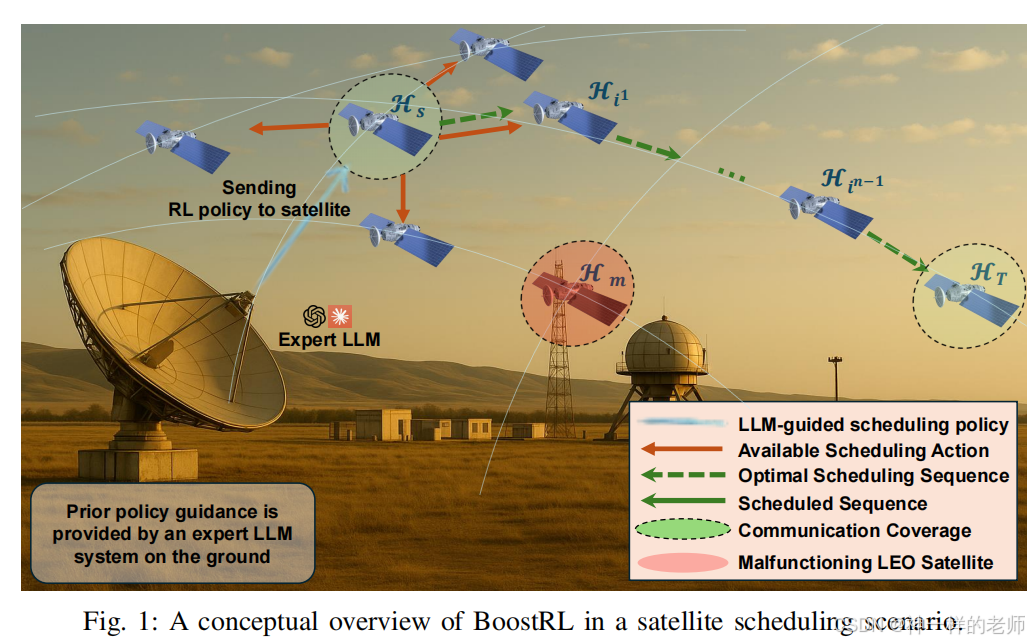
核心贡献
首次把 LLM 引入 LEO 调度领域,提出 BoostRL 框架:
-
离线阶段:地面 LLM 读取当前星座拓扑、失效节点、轨道根数,生成"初始策略概率表";
-
在线阶段:星上 DQN 以该表初始化 Q 值并持续更新,LLM 影响随训练指数衰减;
-
整体收敛速度提升 48%,最终调度效率再提高 16%,且对失效卫星具有天然避障能力。
第二节 预备知识
回顾 LEO 星座拓扑建模方式(四向永久星间链、Walker 构型)、TLE 轨道外推、自由空间路径损耗(FSPL)与跳数联合目标函数;总结既有研究------从最短跳数、分层路由、到近年深度强化学习,指出它们仍依赖随机或启发式初始策略,在拓扑剧变时需重新探索。
第三节 动态建模
给出基于 SGP4 的精确轨道递推公式,把 TLE 六根数转为时变经纬度,再计算大圆距离;把失效卫星视为永久阻塞节点,任何链路只要一端在失效集 M 内即不可用。该模型成为后续 RL 状态-动作空间的实时输入。
第四节 算法设计
状态:每颗卫星的连续 10 个时刻的经纬度序列、源/目的/失效节点经纬度、两两卫星距离矩阵。
动作:从四邻居中选下一跳,若邻居在 M 内则掩码概率置 0。
奖励:由距离项与终止项加权,距离项按 FSPL 公式惩罚路径损耗,终止项在到达目的时给正奖励 ξ、选中失效节点给惩罚 η、每步小惩罚 ε。
LLM 增强机制:
-
提示模板(图 4)让 LLM 扮演"星座网络专家",直接输出 25×4 的 JSON 概率表;
-
Q 值初始化时,LLM 推荐动作对应 Q_high,其余 Q_low;
-
损失函数增加 LLM 指导项 −α(t)π_LLM·log π_θ,随训练指数衰减;
-
星上只保存 3 层 MLP 的 Q 网络,推理延迟 <1 ms,LLM 重推理周期 ≥1 h。
第五节 实验评估
仿真规模:25 颗 LEO 卫星,源节点(−90°, −180°)、目的节点(90°, 180°),永久失效节点 {7,14,17},邻居数 4,使用真实 TLE 数据。
基准:纯 DQN、A2C;BoostRL 分别搭载 GPT-o1-pro、GPT-o3、GPT-4o、Claude-3.7-Sonnet。
结果:
-
奖励曲线:BoostRL 在 2 k 回合即收敛,比 DQN 快 3×,比 A2C 快 5×;GPT-o1-pro 初始策略最佳,GPT-4o 最差。
-
跳数与成功率:BoostRL 平均 5.06 跳、成功率 99%;DQN 5.98 跳、89%;A2C 12.5 跳、27%。
-
FSPL:BoostRL 比 DQN 低 12%,比 A2C 低 60%。
-
轨迹可视化:BoostRL 给出近乎大圆的最短 5 跳路径;A2C 迂回 15 跳,总距离多出 140%。
-
LLM 敏感性:结构化推理能力强的模型(o1-pro)显著优于对话优化型(4o),说明"LLM 选得对"比"LLM 更大"更重要。
第六节 结论与展望
BoostRL 首次验证"LLM 给先验、RL 做微调"在动态空间网络中的可行性,显著减少训练能耗并提升在轨决策质量。未来工作包括:
-
将框架扩展到千颗量级星座,研究分层联邦 RL;
-
采用量化/蒸馏 LLM,实现星上轻量推理;
-
在真实卫星平台上做硬件在环验证,考虑星地链路延迟、计算功耗、单粒子翻转等实际约束。