知识点回顾:
- Dataset 类的_getitem_和_len_方法(本质是 python 的特殊方法)
- Dataloader 类
- minist 手写数据集的了解
零基础学 Python 机器学习:Dataset 和 Dataloader 类
作为你的老师,我会用生活例子 + 分步代码 + 详细解释的方式,把知识点拆解得明明白白。先从最基础的概念开始,再逐步过渡到实际应用,保证你能听懂、能上手。
课前铺垫:为什么需要 Dataset 和 Dataloader?
我们先想一个生活场景:你是一个小吃店老板,需要从仓库里拿食材做饭。仓库里的食材乱七八糟堆着(原始数据),你每次做饭要拿5 个鸡蛋、2 斤面粉(一批数据),还要偶尔换顺序拿(打乱数据),如果每次都手动翻找,效率太低了。
这时候,你需要:
- 整理仓库 :把食材按类别摆好,标上编号,知道总共有多少(这就是Dataset的作用);
- 找个帮手 :让帮手按你的要求,一次拿指定数量的食材,还能打乱顺序(这就是Dataloader的作用)。
在机器学习中,数据就是 "食材",模型训练就是 "做饭"。Dataset 和 Dataloader 是 PyTorch 框架中用来整理和加载数据的核心工具,今天我们就把这两个工具学透。
知识点 1:Python 的特殊方法 ------len__和__getitem
在学 Dataset 之前,必须先搞懂两个 Python魔术方法 (特殊方法):__len__和__getitem__。它们是 Dataset 的 "基石",用双下划线__包裹,是 Python 的内置约定。
1.1 __len__方法:返回 "数量"
当你调用len(对象)时,Python 会自动去执行这个对象的__len__方法,返回的就是对象的长度 / 数量。
举个栗子:我的水果袋
python
# 定义一个"水果袋"类
class MyFruitBag:
def __init__(self):
# 袋子里的水果(初始化数据)
self.fruits = ["苹果", "香蕉", "橙子", "葡萄"]
# 实现__len__方法:返回水果的数量
def __len__(self):
return len(self.fruits)
# 创建水果袋对象
my_bag = MyFruitBag()
# 调用len(),本质是调用my_bag.__len__()
print("水果袋里有多少水果?", len(my_bag)) # 输出:4
print("直接调用__len__:", my_bag.__len__()) # 输出:4总结 :__len__的作用就是告诉外界 "我这个对象里有多少个元素"。
1.2 __getitem__方法:按 "下标" 取元素
当你用对象[下标](比如list[0])访问元素时,Python 会自动执行这个对象的__getitem__方法,参数是下标,返回对应位置的元素。
继续扩展:从水果袋里拿水果
python
class MyFruitBag:
def __init__(self):
self.fruits = ["苹果", "香蕉", "橙子", "葡萄"]
def __len__(self):
return len(self.fruits)
# 实现__getitem__方法:根据下标返回水果
def __getitem__(self, index):
# index是传入的下标(比如0、1)
return self.fruits[index]
my_bag = MyFruitBag()
# 用下标取水果,本质是调用my_bag.__getitem__(0)
print("第0个水果:", my_bag[0]) # 输出:苹果
print("第2个水果:", my_bag[2]) # 输出:橙子
print("直接调用__getitem__:", my_bag.__getitem__(3)) # 输出:葡萄总结 :__getitem__的作用是 "按位置取元素",让我们能像操作列表一样操作自定义对象。
知识点 2:PyTorch 的 Dataset 类
PyTorch 提供了一个抽象类 (可以理解为 "数据模板"):torch.utils.data.Dataset,专门用来封装数据集。
2.1 Dataset 的核心约定
这个模板规定:如果你想创建自己的数据集,必须继承 Dataset 类,并且实现__len__和__getitem__这两个方法。
为什么?因为后续的 Dataloader 需要通过这两个方法获取数据的总数量和单个样本,就像你需要知道水果袋里有多少水果,才能让帮手按批次拿取一样。
2.2 实战:自定义一个水果标签数据集
假设我们有一批水果和对应的标签(苹果 = 0,香蕉 = 1,橙子 = 2,葡萄 = 3),我们用 Dataset 来封装它。
步骤 1:导入 Dataset 类
python
# 导入PyTorch的Dataset类
from torch.utils.data import Dataset步骤 2:定义自己的数据集类
python
class FruitDataset(Dataset):
# 构造方法:初始化数据(相当于给水果袋装水果)
def __init__(self):
# 水果名称列表(特征)
self.fruit_names = ["苹果", "香蕉", "橙子", "葡萄", "草莓", "芒果"]
# 对应的标签列表(标签)
self.fruit_labels = [0, 1, 2, 3, 4, 5]
# 必须实现:返回数据集的总样本数
def __len__(self):
# 水果数量和标签数量一致,返回其一即可
return len(self.fruit_names)
# 必须实现:根据下标返回一个样本(特征+标签)
def __getitem__(self, index):
# 取对应下标的水果名和标签
name = self.fruit_names[index]
label = self.fruit_labels[index]
# 返回元组(特征,标签)
return name, label步骤 3:测试自定义 Dataset
python
# 创建数据集对象
fruit_dataset = FruitDataset()
# 1. 查看总样本数(调用__len__)
print("数据集总样本数:", len(fruit_dataset)) # 输出:6
# 2. 按下标取样本(调用__getitem__)
print("第0个样本:", fruit_dataset[0]) # 输出:('苹果', 0)
print("第3个样本:", fruit_dataset[3]) # 输出:('葡萄', 3)
# 3. 遍历所有样本
for i in range(len(fruit_dataset)):
name, label = fruit_dataset[i]
print(f"第{i}个样本:水果={name},标签={label}")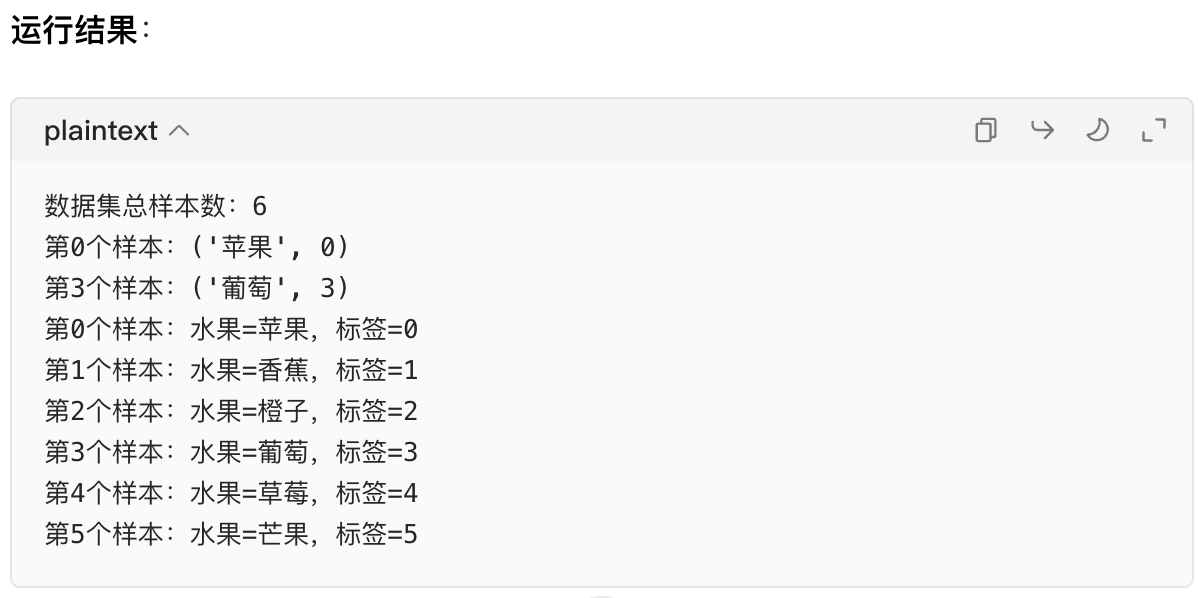
核心理解 :Dataset 的本质是把数据整理成 "可按下标访问、可查数量" 的格式,方便后续操作。
知识点 3:PyTorch 的 Dataloader 类
有了 Dataset,我们可以一个个取样本,但机器学习训练时,一次只取一个样本效率太低(就像做饭一次只拿一个鸡蛋)。
这时候需要Dataloader :它是 PyTorch 的 "数据搬运工",能从 Dataset 中按批次取数据、打乱数据顺序、多线程加载,极大提升训练效率。
3.1 Dataloader 的核心参数
| 参数名 | 作用 | 通俗解释 |
|---|---|---|
| dataset | 要加载的数据集对象 | 告诉搬运工从哪个仓库拿食材 |
| batch_size | 每批的样本数量 | 一次拿多少个食材(比如 2 个) |
| shuffle | 是否打乱数据顺序 | 拿食材时要不要随机拿(训练时建议 True) |
| num_workers | 加载数据的线程数 | 找几个帮手一起搬(Windows 建议设 0,避免报错) |
3.2 实战:用 Dataloader 加载水果数据集
步骤 1:导入 Dataloader 类
python
from torch.utils.data import DataLoader步骤 2:创建 Dataloader 对象
python
# 创建数据加载器
fruit_dataloader = DataLoader(
dataset=fruit_dataset, # 要加载的数据集
batch_size=2, # 每批2个样本
shuffle=True, # 打乱数据顺序
num_workers=0 # 单线程加载
)步骤 3:遍历 Dataloader
Dataloader 是可迭代对象 ,可以用 for 循环遍历,每次得到的是一批样本。
python
# 遍历Dataloader(batch_idx是批次编号)
for batch_idx, (names, labels) in enumerate(fruit_dataloader):
print(f"第{batch_idx}批数据:")
print(f"水果名:{names}")
print(f"标签:{labels}")
print("-" * 20)
3.3 关键对比:Dataset vs Dataloader
| Dataset | Dataloader |
|---|---|
单个样本访问(如dataset[0]) |
批量样本访问(如一批 2 个) |
| 只能按顺序取 | 可打乱顺序取 |
| 单线程 | 可多线程加速 |
核心理解 :Dataloader 的本质是把 Dataset 里的样本 "打包成批",方便模型训练。
知识点 4:MNIST 手写数字数据集
学完了 Dataset 和 Dataloader,我们来实战一个真实的机器学习数据集------MNIST,它是手写数字识别的 "入门必学数据集",相当于机器学习的 "Hello World"。
4.1 MNIST 数据集介绍
- 内容:包含 70000 张手写数字(0-9)的灰度图片,其中 60000 张训练集,10000 张测试集。
- 每张图片:28×28 像素的灰度图(像素值 0-255,0 是黑色,255 是白色)。
- 标签:对应图片中的数字(0-9)。
4.2 实战:加载 MNIST 数据集
PyTorch 的torchvision库已经封装好了 MNIST 的 Dataset,我们可以直接用,不用自己写。
步骤 1:安装依赖(如果没装)
python
pip install torch torchvision matplotlib步骤 2:导入所需模块
python
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt # 用来画图步骤 3:数据预处理
MNIST 的原始数据是 PIL 图片格式,我们需要转换成 PyTorch 的张量(Tensor)(模型只能处理张量)。
python
# 定义预处理流程:把图片转成张量,并归一化(像素值从0-255转成0-1)
transform = transforms.Compose([
transforms.ToTensor() # 核心:PIL图片 → Tensor
])步骤 4:加载 MNIST 数据集
python
# 加载训练集
train_dataset = datasets.MNIST(
root='./data', # 数据保存的路径(本地没有会自动下载)
train=True, # True=训练集,False=测试集
download=True, # 自动下载数据
transform=transform # 应用预处理
)
# 加载测试集
test_dataset = datasets.MNIST(
root='./data',
train=False,
download=True,
transform=transform
)步骤 5:查看 MNIST 的基本信息
python
# 查看样本数量
print("训练集样本数:", len(train_dataset)) # 输出:60000
print("测试集样本数:", len(test_dataset)) # 输出:10000
# 查看单个样本
img, label = train_dataset[0]
print("图片张量的形状:", img.shape) # 输出:torch.Size([1, 28, 28])
# 1=通道数(灰度图只有1个通道),28×28=图片尺寸
print("标签:", label) # 输出:5(第一个样本是数字5)步骤 6:可视化 MNIST 样本
让我们看看手写数字长什么样:
python
# 把张量转换成numpy数组(方便画图)
img_np = img.squeeze().numpy() # squeeze()去掉通道维度,变成28×28
# 画图
plt.imshow(img_np, cmap='gray') # 灰度图
plt.title(f"Label: {label}") # 标题显示标签
plt.axis('off') # 隐藏坐标轴
plt.show()效果:你会看到一张手写的数字 5 的图片,是不是很直观?
步骤 7:用 Dataloader 加载 MNIST
python
# 创建训练集的Dataloader
train_dataloader = DataLoader(
dataset=train_dataset,
batch_size=64, # 每批64个样本(训练常用64/128)
shuffle=True, # 训练时打乱数据
num_workers=0
)
# 创建测试集的Dataloader
test_dataloader = DataLoader(
dataset=test_dataset,
batch_size=64,
shuffle=False, # 测试时不用打乱
num_workers=0
)
# 查看一批数据的形状
for batch_idx, (imgs, labels) in enumerate(train_dataloader):
print(f"第{batch_idx}批数据:")
print("图片张量形状:", imgs.shape) # 输出:torch.Size([64, 1, 28, 28])
print("标签形状:", labels.shape) # 输出:torch.Size([64])
break # 只看第一批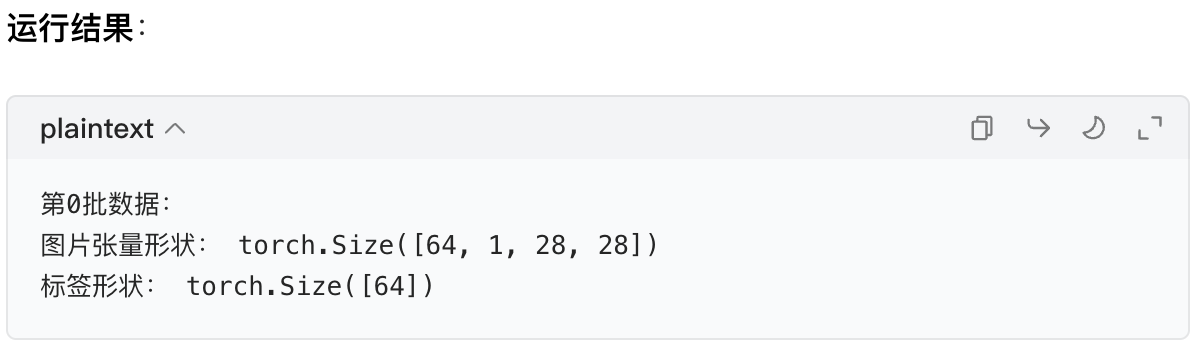
核心理解:64 是批次大小,所以一批有 64 张 28×28 的图片,对应 64 个标签。
总结:知识点梳理
今天我们学的内容可以用一句话总结:用 Dataset 整理数据(定数量、按下标取),用 Dataloader 批量加载数据(定批次、可打乱),MNIST 是练手的经典数据集。
核心知识点回顾

下一步建议
你可以自己动手跑一遍今天的代码,修改参数(比如batch_size改成 32,shuffle改成 False),看看结果有什么变化,这样能更快理解!
如何提高CIFAR-10数据集样本的分辨率?
CIFAR-10 数据集的样本本身是32×32 像素的低分辨率图像,没有对应的 "原生高分辨率版本" ,因此 "提高其分辨率" 实际是通过图像超分辨率(Super Resolution)技术,从低分辨率(LR)样本生成高分辨率(HR)的近似图像(并非还原真实的高分辨率原图)。
以下是两种主流实现方法,从简单到进阶,适配你的学习场景:
方法 1:传统插值法(简单易实现,基础放大)
通过像素插值算法直接放大图像,优点是速度快、无需训练,缺点是细节恢复效果一般(仅做像素填充)。
常用插值类型
| 方法 | 特点 | 效果 |
|---|---|---|
| 双线性插值 | 基于相邻 4 个像素加权计算 | 平滑但细节模糊 |
| 双三次插值 | 基于相邻 16 个像素加权计算 | 比双线性更清晰,边缘更自然 |
实现代码(用 OpenCV/PIL 库)
以双三次插值放大到 128×128为例:
python
import cv2
import numpy as np
from torchvision import datasets, transforms
# 1. 加载CIFAR-10样本(取第0个样本)
cifar10 = datasets.CIFAR10(root="./data", train=True, download=True)
img_32x32 = cifar10[0][0] # 原始32×32 PIL图像
# 2. 用双三次插值放大到128×128
img_128x128 = img_32x32.resize((128, 128), resample=Image.BICUBIC)
# 3. 显示对比
plt.figure(figsize=(8, 4))
plt.subplot(121)
plt.imshow(img_32x32)
plt.title("Original (32×32)")
plt.axis('off')
plt.subplot(122)
plt.imshow(img_128x128)
plt.title("Bicubic Interpolation (128×128)")
plt.axis('off')
plt.show()方法 2:深度学习超分辨率法(效果更优,细节更丰富)
通过超分辨率模型学习 "低分辨率→高分辨率" 的映射关系,能生成更接近真实纹理的高分辨率图像,是当前主流方案。
经典超分辨率模型
| 模型 | 特点 | 适用场景 |
|---|---|---|
| SRCNN | 首个深度学习超分模型 | 入门学习 |
| ESPCN | 速度快,适合实时放大 | 轻量化场景 |
| SRGAN | 生成细节更逼真(带对抗训练) | 对视觉效果要求高的场景 |
实现代码(用预训练模型,无需自行训练)
以ESPCN 模型(放大 4 倍至 128×128) 为例:
python
import torch
from torchvision import models
from torchvision.transforms import ToTensor, ToPILImage
# 1. 加载预训练的ESPCN模型(放大4倍)
espcn = models.quantization.espcn(pretrained=True).eval()
upsample_factor = 4 # 放大倍数
# 2. 处理CIFAR-10样本
img_32x32 = cifar10[0][0] # 原始32×32 PIL图像
tensor = ToTensor()(img_32x32).unsqueeze(0) # 转成模型输入格式(BCHW)
# 3. 超分辨率推理
with torch.no_grad():
img_128x128 = espcn(tensor)
# 4. 转成PIL图像并显示
img_128x128_pil = ToPILImage()(img_128x128.squeeze())
plt.figure(figsize=(8, 4))
plt.subplot(121)
plt.imshow(img_32x32)
plt.title("Original (32×32)")
plt.axis('off')
plt.subplot(122)
plt.imshow(img_128x128_pil)
plt.title("ESPCN Super Resolution (128×128)")
plt.axis('off')
plt.show()关键说明
- 超分辨率是 "生成近似的高分辨率图像",并非还原 CIFAR-10 样本的真实高分辨率版本(因为原始样本本身没有更高分辨率的来源);
- 传统插值法适合快速放大,深度学习法则能生成更自然的细节,但需要依赖预训练模型或自行训练(训练需高分辨率数据集,如 DIV2K)。
作业:了解下 cifar 数据集,尝试获取其中一张图片。
Mac OS 系统下了解 CIFAR 数据集并获取单张图片
我们接着上节课的知识,用"生活类比 + 分步代码 + Mac 系统适配" 的方式,带你认识 CIFAR 数据集,并且亲手提取、显示其中一张图片。全程保持通俗易懂,和之前学的 MNIST、Dataset/Dataloader 知识联动,让你轻松上手。
一、先搞懂:CIFAR 数据集是什么?
你可以把 CIFAR 数据集理解为 **"升级版的 MNIST"**,只不过从手写数字变成了日常物体的彩色图片。
1.1 CIFAR 的两个主要版本
| 版本 | 类别数量 | 每个类别样本数 | 总样本数 | 图片规格 | 内容举例 |
|---|---|---|---|---|---|
| CIFAR-10 | 10 个 | 6000 张 | 60000 张 | 32×32 像素彩色图(RGB) | 飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车 |
| CIFAR-100 | 100 个 | 600 张 | 60000 张 | 32×32 像素彩色图(RGB) | 分为 20 个超类(比如动物、植物),每个超类包含 5 个子类(比如猫科、犬科) |
1.2 和 MNIST 的核心区别
- MNIST 是28×28 灰度图 (只有 1 个颜色通道),CIFAR 是32×32 彩色图(有 RGB 3 个颜色通道);
- MNIST 只有 10 个数字类别,CIFAR-100 有更多细分类别,更贴近真实场景。
1.3 学习目标
我们以CIFAR-10为例(入门首选,更简单),完成:
- 加载 CIFAR-10 数据集;
- 查看数据集的基本信息;
- 提取其中一张图片并可视化显示。
二、Mac OS 下的详细操作步骤
Mac OS 系统和 Windows 的核心区别主要是文件路径 (Mac 用/,和 Python 默认路径一致)和num_workers 参数(Mac 可以设大于 0,不会轻易报错),我们会在代码里特别标注。
前提步骤:确认环境(提前准备)
首先确保你的 Mac 上已经安装了必要的库(和上节课的 MNIST 一样),如果没装,打开终端(Terminal)执行以下命令:

安装PyTorch、torchvision(包含CIFAR数据集)、matplotlib(画图) pip3 install torch torchvision matplotlib
注:Mac 上如果用
pip报错,可以用pip3,因为 Mac 默认的 Python3 需要用pip3。
步骤 1:导入所需模块
和上节课加载 MNIST 的思路一致,我们需要导入 PyTorch 相关模块和画图工具:
python
# 导入PyTorch核心库
import torch
# 导入torchvision的数据集和数据预处理模块
from torchvision import datasets, transforms
# 导入画图工具(用来显示图片)
import matplotlib.pyplot as plt步骤 2:定义数据预处理规则
CIFAR 的原始数据是PIL 图片格式 (和 MNIST 一样),我们需要把它转换成 PyTorch 的张量(Tensor)(模型只能处理张量),这一步和 MNIST 的预处理几乎一样。
python
# 定义预处理流程:把PIL图片转成Tensor
transform = transforms.Compose([
transforms.ToTensor() # 核心:将图片转换为张量,同时把像素值从0-255归一化到0-1
])小解释:彩色图片的像素值是 RGB 三个通道,每个通道的取值都是 0-255,
ToTensor()会把它们统一转成 0-1 之间的浮点数,方便模型计算。
步骤 3:加载 CIFAR-10 数据集
PyTorch 的torchvision.datasets已经封装好了 CIFAR-10 数据集,我们可以直接调用,和加载 MNIST 的代码结构完全一样(复用你学过的 Dataset 知识)。
python
# 加载CIFAR-10训练集
cifar10_train = datasets.CIFAR10(
root='./data', # 数据保存的路径(Mac下会在当前文件夹创建data文件夹,自动下载数据)
train=True, # True=训练集,False=测试集
download=True, # 本地没有数据就自动下载(Mac下载速度通常很快)
transform=transform # 应用我们定义的预处理
)
# (可选)加载CIFAR-10测试集(今天主要用训练集)
cifar10_test = datasets.CIFAR10(
root='./data',
train=False,
download=True,
transform=transform
)第一次运行时,会自动下载 CIFAR-10 的压缩包(约 170MB),下载完成后会自动解压到
./data文件夹,后续运行就不会重复下载了。
步骤 4:查看 CIFAR 数据集的基本信息(回顾 Dataset 的__len__和__getitem__)
CIFAR10 类也是继承自 PyTorch 的 Dataset 类,所以它也有我们学过的__len__和__getitem__方法,我们可以用这些方法查看数据。
4.1 查看数据集的总样本数(调用__len__)
python
print("CIFAR-10训练集总样本数:", len(cifar10_train)) # 输出:50000
print("CIFAR-10测试集总样本数:", len(cifar10_test)) # 输出:100004.2 查看 CIFAR 的类别名称
CIFAR-10 的 10 个类别有固定的名称,我们可以直接查看数据集的classes属性:
python
# 查看CIFAR-10的类别列表
classes = cifar10_train.classes
print("CIFAR-10的类别:", classes)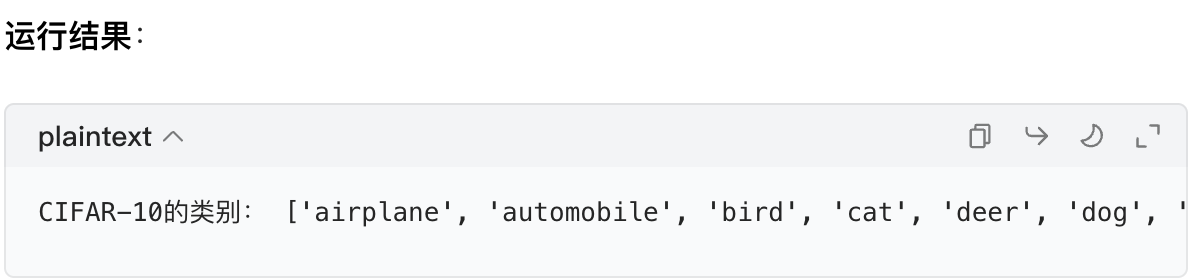
翻译一下:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车。
4.3 提取单个样本(调用__getitem__)
用数据集[index]的方式取单个样本,返回的是(图片张量,标签):
python
# 取训练集中的第0个样本
img_tensor, label = cifar10_train[0]
# 查看图片张量的形状
print("图片张量的形状:", img_tensor.shape) # 输出:torch.Size([3, 32, 32])
# 解释:3=RGB三个颜色通道,32×32=图片的宽和高
print("样本的标签:", label) # 输出:6(对应类别是frog,青蛙)
print("标签对应的类别名称:", classes[label]) # 输出:frog这里和 MNIST 的区别:MNIST 的张量形状是
[1,28,28](1 个灰度通道),而 CIFAR 是[3,32,32](3 个彩色通道)。
步骤 5:提取并可视化单张图片(重点!)
现在我们已经拿到了图片的张量,接下来要把它转换成 Matplotlib 能显示的格式,然后画出来。
5.1 张量格式转换(关键!)
Matplotlib 显示图片需要的格式是:(高度,宽度,通道数) (比如 32×32×3),而我们的张量格式是:(通道数,高度,宽度)(3×32×32),所以需要转换维度顺序。
我们用permute方法来调整维度:
python
# 转换维度:从(3,32,32) → (32,32,3)
img_show = img_tensor.permute(1, 2, 0)小解释:
permute(1,2,0)的意思是,把原来的第 1 个维度(高度 32)放到第 0 位,第 2 个维度(宽度 32)放到第 1 位,第 0 个维度(通道 3)放到第 2 位。
5.2 显示图片
用 Matplotlib 的imshow方法显示图片:
python
# 画图
plt.figure(figsize=(4, 4)) # 设置图片大小为4×4英寸(Mac下显示更清晰)
plt.imshow(img_show) # 传入转换后的图片
plt.title(f"Label: {label} ({classes[label]})") # 标题显示标签和类别名称
plt.axis('off') # 隐藏坐标轴(更美观)
plt.show()运行效果:你会在 Mac 的绘图窗口中看到一张 32×32 的彩色图片,内容是一只青蛙(因为标签 6 对应 frog),虽然图片有点模糊(毕竟只有 32×32 像素),但能清晰看出物体类型。
三、拓展:用 Dataloader 加载一批 CIFAR 数据(回顾上节课的 Dataloader)
如果你想批量加载 CIFAR 数据,也可以用 Dataloader,Mac 系统下num_workers可以设为 2(多线程加载,速度更快):
python
from torch.utils.data import DataLoader
# 创建CIFAR-10的Dataloader
cifar10_dataloader = DataLoader(
dataset=cifar10_train,
batch_size=4, # 每批4个样本
shuffle=True, # 打乱顺序
num_workers=2 # Mac下设2个线程,加载更快(Windows建议设0)
)
# 遍历一批数据
for batch_idx, (imgs, labels) in enumerate(cifar10_dataloader):
print("一批图片的张量形状:", imgs.shape) # 输出:torch.Size([4, 3, 32, 32])
print("一批标签的形状:", labels.shape) # 输出:torch.Size([4])
# 显示这批中的第一张图片
img_show = imgs[0].permute(1, 2, 0)
plt.imshow(img_show)
plt.title(classes[labels[0]])
plt.axis('off')
plt.show()
break # 只看第一批四、Mac 系统的小注意事项
- 路径问题 :Mac 下的文件路径用
./表示当前文件夹,和 Python 的默认路径一致,无需额外调整; - num_workers 参数:Mac 下可以设为 1、2 等(根据你的 CPU 核心数),能加速数据加载,而 Windows 建议设 0 避免报错;
- 图片显示 :Matplotlib 在 Mac 下会自动弹出绘图窗口,如果没显示,可以检查是否安装了
matplotlib的后端(通常无需额外设置)。
五、总结
今天我们在 Mac 系统下完成了:
- 认识了 CIFAR-10 数据集(32×32 彩色图,10 个日常物体类别);
- 用
torchvision.datasets.CIFAR10加载了数据集(复用了 Dataset 的知识); - 提取了单个样本,并通过维度转换显示了图片;
- (可选)用 Dataloader 批量加载了数据。
核心知识点还是Dataset 的__len__和__getitem__ ,以及张量的维度转换 (彩色图的 RGB 通道处理)。你可以尝试修改代码中的index(比如取第 10 个、第 100 个样本),看看不同的图片是什么,这样能更直观地理解 CIFAR 数据集~