开心一刻
一天,老婆笑容满面的冲到我面前
老婆:你娶我到底是图我啥
我:便宜
老婆笑容瞬间消失,气呼呼的道:你会不会说话?
并且强调:我爸当年那是可怜你,没跟你多要
我:不是,你爸不是这么说的
老婆:那怎么说的
我开始学着老丈人的口吻:不许退,给你便宜点

INSERT ON DUPLICATE KEY UPDATE
关于 INSERT ... ON DUPLICATE KEY UPDATE,相信大家都有所了解,是 MySQL 针对
不存在则插入,存在则更新
的一种方言实现;存不存在 该如何判定呢,基于表的 唯一索引 或 主键
举个例子,如果列 a 被声明为 唯一 且表中已经存在 a=1 的记录,则以下两条语句具有类似的效果
sql
INSERT INTO t1 (a,b,c) VALUES (1,2,3)
ON DUPLICATE KEY UPDATE c=c+1;
UPDATE t1 SET c=c+1 WHERE a=1;假设我们有表
sql
CREATE TABLE `tbl_insert_on_update` (
`id` bigint NOT NULL,
`name` varchar(255) NOT NULL,
`uk_column1` varchar(255) NOT NULL,
`uk_column2` varchar(255) NOT NULL,
`remark` text,
PRIMARY KEY (`id`),
UNIQUE KEY `name` (`name`)
) ENGINE=InnoDB一开始表中没有数据,那么
sql
INSERT tbl_insert_on_update(id, name, uk_column1, uk_column2, remark)
VALUES(1, '张三', '20050101001', '男一号', '风一样的男子')
ON DUPLICATE KEY UPDATE uk_column1='20050101002', uk_column2='男二号', remark='狂风一样的男子';的作用,相信大家都知道,与
sql
INSERT tbl_insert_on_update(id, name, uk_column1, uk_column2, remark)
VALUES(1, '张三', '20050101001', '男一号', '风一样的男子');作用一样,会往表中插入一条新的记录;如果再执行一次
sql
INSERT tbl_insert_on_update(id, name, uk_column1, uk_column2, remark)
VALUES(1, '张三', '20050101001', '男一号', '风一样的男子')
ON DUPLICATE KEY UPDATE uk_column1='20050101002', uk_column2='男二号', remark='狂风一样的男子';呢,会是怎么样的结果?相信大家都知道

与
sql
UPDATE tbl_insert_on_update SET uk_column1='20050101002', uk_column2='男二号', remark='狂风一样的男子' WHERE id = 1;的效果一样。我们接着做个简单调整,拿掉 name
sql
INSERT tbl_insert_on_update(id, uk_column1, uk_column2, remark)
VALUES(1, '20050101001', '男一号', '风一样的男子')
ON DUPLICATE KEY UPDATE uk_column1='20050101003', uk_column2='男三号', remark='暴风一样的男子';或者拿掉 id
sql
INSERT tbl_insert_on_update(name, uk_column1, uk_column2, remark)
VALUES('张三', '20050101001', '男一号', '风一样的男子')
ON DUPLICATE KEY UPDATE uk_column1='20050101003', uk_column2='男三号', remark='暴风一样的男子';会是怎么样的一个结果,你们可以大胆猜一下。这两个 SQL 的执行结果是一样的

此时你们是不是有疑问呢
为什么拿掉
name和拿掉id的 INSERT ... ON DUPLICATE KEY UPDATE 的执行结果会是一样的?
这个问题先放一放,我们先录入女一号的数据
sql
INSERT tbl_insert_on_update(id, name, uk_column1, uk_column2, remark)
VALUES(2, '婉儿', '20050101001X', '女一号', '花一样的女子');假设我们要修改女一号的信息,包括 姓名,是不是可以这么实现
sql
INSERT tbl_insert_on_update(id, name, uk_column1, uk_column2, remark)
VALUES(2, '婉儿', '20050101001X', '女一号', '花一样的女子')
ON DUPLICATE KEY UPDATE, name='张三', uk_column1='20050101002X', uk_column2='女二号', remark='牵牛花一样的女子';有什么问题吗,执行下就知道了嘛
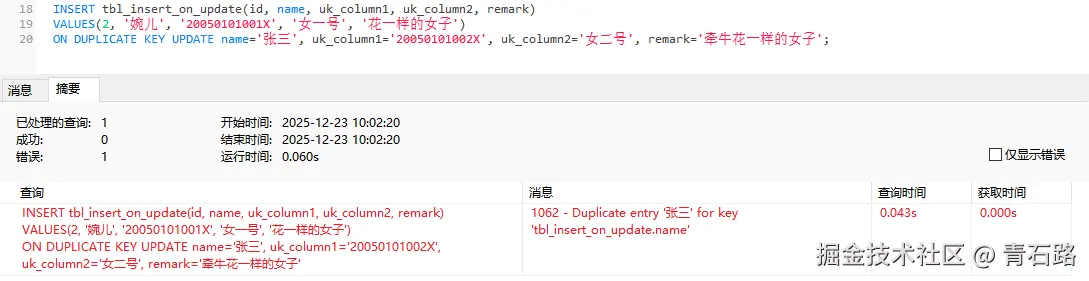
执行报错了,提示
1062 - Duplicate entry '张三' for key 'tbl_insert_on_update.name'
这个错误信息我们是不是很熟悉?不就是唯一索引冲突吗?那么问题又来了
用了MySQL的INSERT ON DUPLICATE KEY UPDATE,为什么还会唯一索引冲突?
如何判断是否存在
我们写 INSERT ... ON DUPLICATE KEY UPDATE 语句时,并未指定用哪个 主键 或者 唯一索引 来判定记录是否存在
Oracle、SQL Server、PostgreSQL 的
MERGE有类似作用
sqlMERGE INTO TBL_INSERT_ON_UPDATE t USING ( SELECT 1 AS ID, '张三' AS NAME, '20050101001' AS UK_COLUMN1, '男一号' AS UK_COLUMN2, '风一样的男子' AS REMARK FROM dual ) s ON (t.NAME = s.NAME) -- 基于 NAME 字段匹配 WHEN MATCHED THEN UPDATE SET t.ID = s.ID, t.UK_COLUMN1 = s.UK_COLUMN1, t.UK_COLUMN2 = s.UK_COLUMN2, t.REMARK = s.REMARK WHEN NOT MATCHED THEN INSERT (ID, NAME, UK_COLUMN1, UK_COLUMN2, REMARK) VALUES (s.ID, s.NAME, s.UK_COLUMN1, s.UK_COLUMN2, s.REMARK);其中的
ON明确指定匹配字段(根据哪些字段判断记录是否存在),一般是指定主键字段或唯一索引字段
那 MySQL 是如何判定记录是否存在的呢?我们可以翻阅下官方文档:INSERT ... ON DUPLICATE KEY UPDATE Statement。一开头有如下一段描述
If you specify an
ON DUPLICATE KEY UPDATEclause and a row to be inserted would cause a duplicate value in aUNIQUEindex orPRIMARY KEY, anUPDATEof the old row occurs当我们使用
ON DUPLICATE KEY UPDATE子句时,插入的行导致唯一索引或者主键重复时,会更新旧的行
通过这段话,我们只知道 MySQL 是根据唯一索引或主键来判定行是否存在,并不知道
- 先根据主键判定,不冲突之后再根据唯一索引判定?
- 有多个唯一索引时,这些唯一索引的判定优先级是怎样的?
官方文档里面并未明确说明这些问题,只是在结尾进行了如下说明
An
INSERT ... ON DUPLICATE KEY UPDATEstatement against a table having more than one unique or primary key is also marked as unsafe. (Bug #11765650, Bug #58637)当表中有多个唯一索引或者主键时,INSERT ... ON DUPLICATE KEY UPDATE 语句不安全
不安全代表执行结果不固定,会出现我们预期之外的结果
工作原理
如果让你们来实现 不存在则插入,存在则更新,你们会怎么实现?
逐个查询主键以及所有唯一索引,判断该行数据是否存在,一旦存在则根据重复的主键或者唯一索引进行 UPDATE,都不存在则进行 INSERT;这不仅是你们最容易想到的实现方式,也是我最容易想到的方式。
但 MySQL 并未采用这种方式,而是采用了另外一种更高效的方式,先尝试插入,存储引擎会向所有相关的唯一索引(包括主键) 中插入对应的索引条目,如果都插入成功,说明数据行不存在,那么 INSERT 数据行;一旦存储引擎尝试插入某个唯一索引时,发现该数据行已经存在,会立即停止插入动作,并向MySQL服务层抛出 重复键 错误,服务层收到重复键错误后,并不会让整个语句失败(因为使用了 ON DUPLICATE KEY UPDATE 子句),而是转换执行模式,会先回滚之前的插入,然后根据重复的那个唯一索引找到数据行对应的 旧行 数据,最后 UPDATE 数据行;总结下来分三步
-
尝试插入
所有唯一索引(包括主键)都插入成功,则插入数据行,相当于完成普通的
INSERT一旦某个唯一索引插入失败,则立即停止插入,存储引擎会向上层抛出一个
重复键错误 -
模式转换
MySQL服务器收到重复键后,发现执行语句中有
ON DUPLICATE KEY UPDATE子句,不会直接让整个语句失败,而是先回滚之前的那部分唯一索引的插入,然后根据插入失败的唯一索引找到已经存在的旧行 -
执行更新
根据插入失败的唯一索引,对旧行执行更新操作,相当于完成普通的
UPDATE
整个 尝试-失败-转换-更新 过程时一个原子操作,那么完全成功,要么完全失败;相比于 先查询后判断 的传统实现,这种实现方式效率更高。
问题答疑
前面涉及到两个问题,现在我们来解惑下
-
为什么拿掉
name和拿掉id的 INSERT ... ON DUPLICATE KEY UPDATE 的执行结果会是一样的?sql-- 拿掉name INSERT tbl_insert_on_update(id, uk_column1, uk_column2, remark) VALUES(1, '20050101001', '男一号', '风一样的男子') ON DUPLICATE KEY UPDATE uk_column1='20050101003', uk_column2='男三号', remark='暴风一样的男子'; -- 拿掉id INSERT tbl_insert_on_update(name, uk_column1, uk_column2, remark) VALUES('张三', '20050101001', '男一号', '风一样的男子') ON DUPLICATE KEY UPDATE uk_column1='20050101003', uk_column2='男三号', remark='暴风一样的男子';这个问题是不是很简单,我们一起来分析下
sqlINSERT tbl_insert_on_update(id, uk_column1, uk_column2, remark) VALUES(1, '20050101001', '男一号', '风一样的男子') ON DUPLICATE KEY UPDATE uk_column1='20050101003', uk_column2='男三号', remark='暴风一样的男子';INSERT 的字段中没有
name,但有id,可想而知判断数据行是否存在,用到的是主键,因为id=1的记录已经存在,所以根据 id 去更新其他字段值;那么执行结果与如下 SQL 一致sqlUPDATE tbl_insert_on_update SET uk_column1='20050101003', uk_column2='男三号', remark='暴风一样的男子' WHERE id = 1;同理
sqlINSERT tbl_insert_on_update(name, uk_column1, uk_column2, remark) VALUES('张三', '20050101001', '男一号', '风一样的男子') ON DUPLICATE KEY UPDATE uk_column1='20050101003', uk_column2='男三号', remark='暴风一样的男子';INSERT 的字段中没有
id,但有name,可想而知判断数据行是否存在,用到的是唯一索引,因为name=张三的记录已经存在,所以根据 name 去更新其他字段值;那么执行结果与如下 SQL 一致sqlUPDATE tbl_insert_on_update SET uk_column1='20050101003', uk_column2='男三号', remark='暴风一样的男子' WHERE name = '张三';id = 1与name = '张三'指向的本来就是同一行数据,更新的列与列值都一致,那么执行结果自然就一样了 -
存在多个唯一索引(包含主键)时,判断数据行是否存在,这些唯一索引的优先级顺序是怎样的?
MySQL 官方文档并未明确说明这个优先级顺序,但在 MySQL 的实现中肯定有这个优先级顺序的实现算法,可能跟版本、存储引擎有关
基于
8.0.31版本,简单测试出以下优先级主键 > 唯一索引
唯一索引之间按创建顺序,先创建的优先级高
官方文档已经明确说明:当表中有多个唯一索引或者主键时,INSERT ... ON DUPLICATE KEY UPDATE 语句不安全,所以如上的测试结果并不具备确定性,不能作为使用准则
-
用了MySQL的INSERT ON DUPLICATE KEY UPDATE,怎么还报唯一索引冲突错误
MySQL是基于尝试插入的第一个冲突的唯一索引来执行更新的,更新的字段完全有可能触发其他唯一索引(包括主键)冲突
这个问题根本不成立!
总结
-
不管是 MySQL,还是 Oracle、SQL Server、PostgreSQL,针对
不存在则插入,存在则更新判断数据是否存在的逻辑都是一样的,只是 MySQL 不需要显示指定判存的唯一索引(包括主键),由 MySQL 引擎内部自动实现 -
关于判断数据行是否存在,多个唯一索引的优先级,看似能测出 MySQL 中的优先级,但并不具备确定性,不能作为使用准则
类似不确定的排序问题还有:我试图扯掉这条 SQL 的底裤
-
INSERT ... ON DUPLICATE KEY UPDATE 使用过程中有一些需要注意的点,需要结合自己的业务来分析是否可以忽略这些点