TL;DR
- 场景:Hadoop2/YARN 生态中用 Tez 替代 MapReduce,给 Hive/Pig 提速。
- 结论:关键在 tez.lib.uris(HDFS 包路径)+ 全节点一致的 tez-site.xml/Classpath + Hive 引擎切换。
- 产出:一套可落地的 Tez 安装配置清单 + 版本矩阵 + 错误速查卡。
基本介绍
Tez (发音为"tez") 是一个运行在 Hadoop 生态系统中的高效数据处理框架,旨在优化批处理和交互式查询。作为 Apache 基金会下的顶级开源项目(Apache Tez),它最初由 Hortonworks 开发,现已成为 Hadoop 生态系统中重要的数据处理组件。
Tez 的核心设计目标是作为 MapReduce 的替代执行引擎,它通过引入更灵活的执行模型显著提高了处理效率。与传统的 MapReduce 相比,Tez 具有以下显著优势:
- 采用有向无环图(DAG)执行模型,允许更复杂的数据处理流水线
- 支持动态任务调度和资源分配
- 减少了中间结果的磁盘I/O开销
- 提供更细粒度的任务执行控制
在实际应用中,Tez 被广泛应用于以下场景:
- Hive 查询加速(作为执行引擎)
- Pig 脚本处理
- 复杂ETL流程
- 交互式分析查询
技术架构方面,Tez 包含以下关键组件:
- Tez API:提供编程接口
- Tez Runtime:执行引擎核心
- DAG 调度器:管理任务执行顺序
- 资源管理器接口:与YARN集成
性能测试表明,对于典型的工作负载,Tez 相比传统MapReduce可以带来2-10倍的性能提升,特别是在处理复杂查询和多阶段任务时优势更为明显。
Tez 的背景
-
MapReduce 的局限性: Hadoop 最初是基于 MapReduce 编程模型设计的,这种模型虽然概念简单、易于理解,但在处理复杂的数据处理任务时存在明显的效率问题。MapReduce 采用严格的"map-shuffle-reduce"执行流程,每个任务阶段(map 或 reduce)都需要将中间结果写入磁盘,这种频繁的磁盘I/O操作会带来显著的性能开销。例如,在一个典型的ETL(抽取-转换-加载)作业中,数据可能需要经过多个map和reduce阶段,每次都会产生磁盘写入,导致整体处理延迟增加。此外,MapReduce 的批处理特性使得它对迭代算法(如机器学习)和交互式查询的支持较差。
-
Tez 的改进与优势: 为了解决MapReduce的这些限制,Apache Tez应运而生。Tez通过引入更灵活的执行引擎,允许开发者构建复杂的数据处理DAG(有向无环图),而不是局限于固定的map-reduce阶段。例如,一个典型的Hive查询在Tez上运行时,可以将多个操作(如过滤、聚合、连接等)组织成一个优化的执行计划,避免了中间结果的多次落盘。Tez还支持内存中的数据处理,显著减少了I/O开销。实际应用中,Tez可以将某些Hive查询的性能提升数倍,特别是在处理多表连接或复杂聚合时效果尤为明显。此外,Tez与YARN的深度集成使其能够更好地利用集群资源,支持更细粒度的任务调度。
核心解释
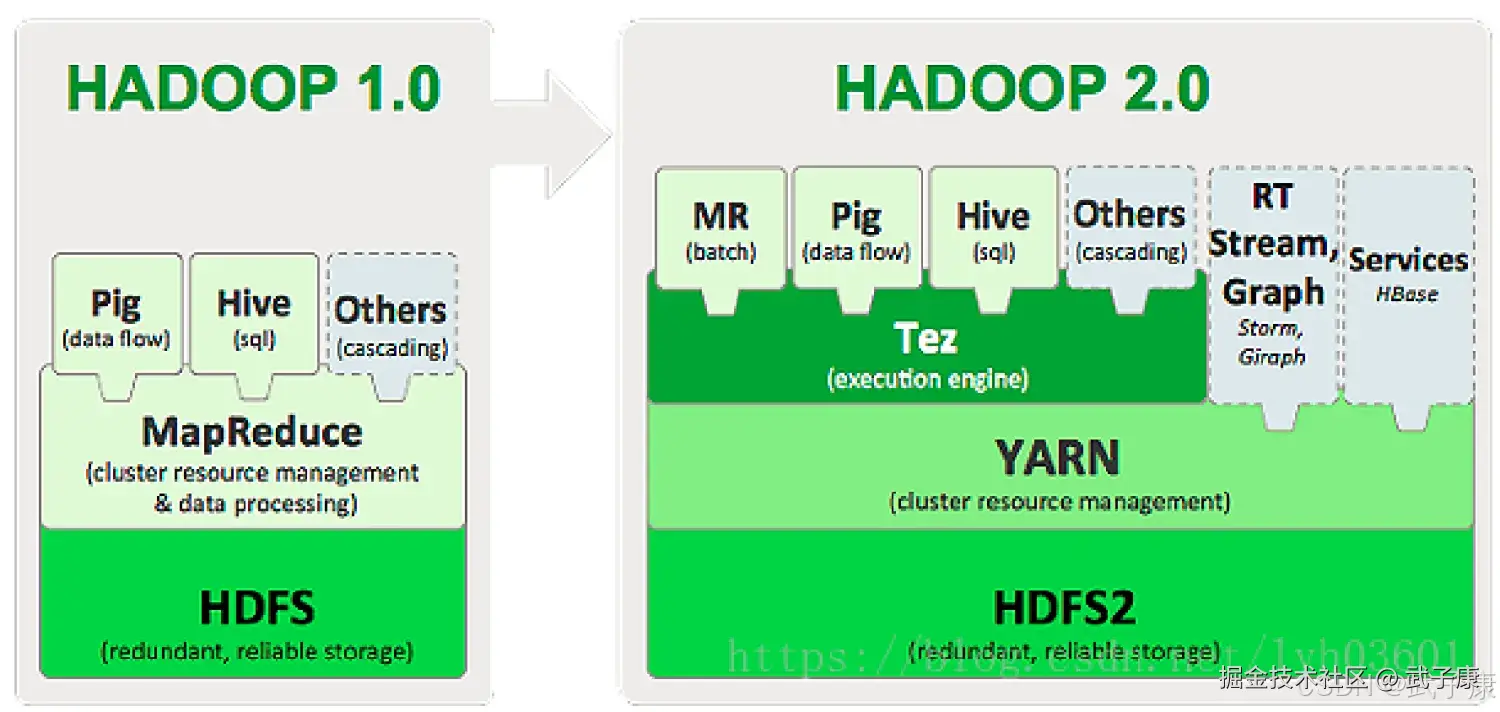
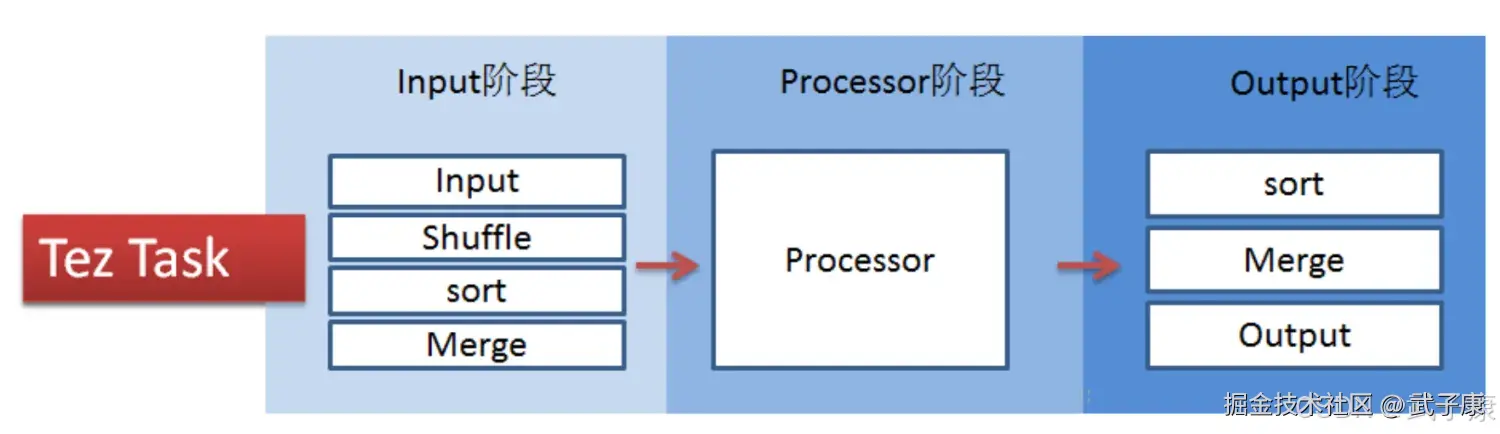
Tez将MapTask和ReduceTask进一步拆分为如下所示的内容:  Tez的Task由Input、Processor、Output阶段组成,可以表达所有复杂的Map、Reduce操作,如下图所示:
Tez的Task由Input、Processor、Output阶段组成,可以表达所有复杂的Map、Reduce操作,如下图所示:
Tez是一个基于Hadoop YARN构建的开源计算框架,它通过优化数据处理流程来显著提升作业执行效率。与传统MapReduce框架相比,Tez的核心优势在于其能够将多个相互依赖的作业转换为单个综合性的DAG(有向无环图)作业,这种优化带来了以下显著改进:
-
数据处理流程优化:
- 消除了传统MapReduce中多个作业间的冗余HDFS读写操作
- 中间数据直接在内存中传递,减少磁盘I/O开销
- 任务调度更加智能,能够识别和优化依赖关系
-
性能提升表现:
- 对于小型任务(如简单的数据转换或聚合查询),性能提升可达2-3倍
- 对于复杂的大型任务(涉及多表连接或复杂计算的ETL流程),性能提升更为显著,可达7-10倍
- 实际性能提升因数据规模、集群配置和查询复杂度而异
-
实际应用案例:
- Hortonworks已将Tez深度集成到Hive引擎中,作为默认执行引擎
- 在典型的TPC-DS基准测试中,使用Tez的Hive查询性能明显优于传统MapReduce
- 某电商平台的数据仓库中,月报表生成时间从原来的6小时缩短至45分钟
-
技术实现细节:
- 采用动态任务调度机制,根据运行时情况优化执行计划
- 支持细粒度的资源管理,可精确控制每个任务的资源分配
- 提供可视化工具帮助开发者理解和优化DAG执行流程
-
适用场景:
- 交互式查询(如Hive、Pig等SQL-on-Hadoop场景)
- 复杂ETL数据处理流程
- 机器学习特征工程中的多步骤数据处理
- 需要低延迟响应的数据分析任务
值得注意的是,Tez的性能优势在以下场景尤为突出:当作业包含多个连续的MapReduce步骤时,或者当中间数据量较大时,Tez的优化效果会更加明显。实际部署时建议结合具体业务场景进行性能调优。
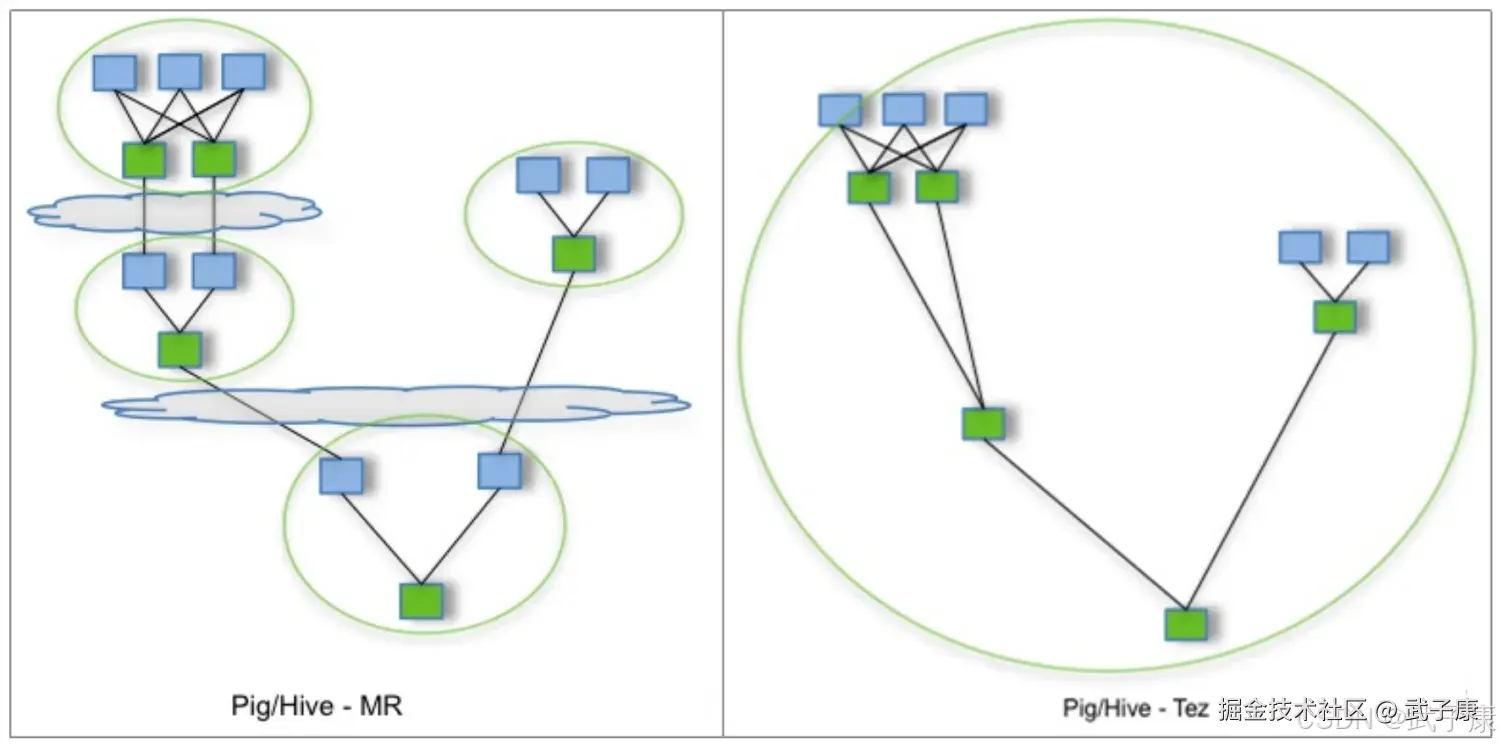
Tez+Hive仍然采用MapReduce计算框架,但对DAG的作业依赖关系进行了裁剪,并将多个小作业合并成一个大作业,不仅减少了计算量,而且写HDFS次数也大大减少。
Tez 的工作原理
- DAG 结构: 在 Tez 中,数据处理任务被表示为一个 DAG(Directed Acyclic Graph,有向无环图),其中每个节点代表一个处理任务,边表示数据的流动方向。不同于 MapReduce 固定的 map 和 reduce 阶段,Tez 可以定义任意数量的任务节点和数据流,从而更加灵活高效。
- 按需计算模型: Tez 支持按需加载数据,避免了不必要的中间结果存储。数据可以直接在内存中传递,减少磁盘操作,从而加速计算。
Tez 的特点
-
高效资源管理: Tez 与 YARN(Yet Another Resource Negotiator)深度集成,采用先进的资源调度算法,能够更智能地分配和使用集群资源。它通过实时监控工作负载的变化(如数据量、计算复杂度等),动态调整 CPU、内存等资源的分配比例。例如,在数据倾斜场景下,Tez 会自动为负载较重的节点分配更多资源,同时避免资源闲置浪费。这种机制相比传统静态资源分配方式可提升 30%以上的集群利用率。
-
可重用的容器: Tez 创新性地实现了容器复用机制。在 YARN 架构中,容器是基本的资源分配单元(包含固定的 CPU 和内存配额)。传统框架如 MapReduce 每个任务都需要新建容器,而 Tez 允许同一容器在多个任务间重复使用(如 Map 阶段完成后容器可直接用于 Reduce 阶段)。实测表明,这种机制可以减少 40% 的任务启动时间,特别适合需要频繁启停任务的迭代计算场景(如机器学习训练)。
-
延迟优化: Tez 通过两项核心技术显著降低处理延迟:一是采用内存化的数据流水线(pipelining),避免像 MapReduce 那样频繁将中间数据写入 HDFS;二是实现智能的任务拓扑优化,自动选择最短执行路径。例如在 Hive 查询中,Tez 可以将多个连续的 Map-Reduce 作业合并为一个 DAG 执行,使典型 TPC-DS 查询延迟降低 50-70%,达到准实时(near-real-time)响应水平。
-
容错性: Tez 提供多层次的容错机制:1)任务级重试(自动重试失败任务最多 3 次);2)基于检查点(checkpoint)的部分重算,仅需重新执行故障点之后的子任务;3)备用执行计划(speculative execution)应对慢节点问题。在 Amazon EMR 的实际应用中,这些机制使得 10%节点故障时的作业完成时间仅增加 15%,而传统框架通常需要完全重新执行。
安装部署
下载软件包: apache-tez-0.9.2-bin.tar.gz 解压缩:
shell
tar -zxvf apache-tez-0.9.0-bin.tar.gz
cd apache-tez-0.9.0-bin/share将tez的压缩包放到HDFS上:
shell
hdfs dfs -mkdir -p /user/tez
hdfs dfs -put tez.tar.gz /user/tez$HADOOP_HOME/etc/hadoop/ 下创建 tez-site.xml 文件,做如下配置:
xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 指定在hdfs上的tez包文件 -->
<property>
<name>tez.lib.uris</name>
<value>hdfs://hadoop1:9000/user/tez/tez.tar.gz</value>
</property>
</configuration>保存后将文件复制到集群所有节点
环境变量
增加客户端节点的配置:
shell
vim /etc/profile
export TEZ_CONF_DIR=$HADOOP_CONF_DIR
export TEZ_JARS=/opt/apps/tez/*:/opt/apps/tez/lib/*
export
HADOOP_CLASSPATH=$TEZ_CONF_DIR:$TEZ_JARS:$HADOOP_CLASSPATH单次配置
Hive这是Tez执行
shell
xhive
set hive.execution.engine=tez;永久配置
如果是想默认使用Tez,则需要在配置文件中进行修改:
shell
vim $HIVE_HOME/conf/hive-site.xml
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>Tez 与 Hive、Pig 的集成
- Hive on Tez: Hive 是一种基于 SQL 的数据仓库工具,最初使用 MapReduce 作为底层引擎。自从引入 Tez 后,Hive on Tez 大幅提升了查询性能,尤其是在复杂查询场景中。相比于传统的 MapReduce,Tez 的 DAG 模型使得 Hive 可以以更加并行化的方式执行查询。
- Pig on Tez: Pig 是一种面向数据流的编程语言,通常用于分析和处理大规模数据。Tez 也作为 Pig 的底层引擎使用,极大地提升了 Pig 脚本的执行效率。
Tez 的优势
- 高性能: 通过减少磁盘 IO、优化任务并行化和重用资源,Tez 显著提升了数据处理的性能,尤其是在复杂查询和数据流处理中。
- 灵活性: Tez 允许用户根据具体的数据处理需求,构建任意复杂的 DAG,从而打破了 MapReduce 固定阶段的限制。
- 可扩展性: Tez 在大规模数据处理环境中表现出色,适合在大数据集群中处理大规模、复杂的批处理和流式处理任务。
使用场景
- 数据仓库查询加速: 许多使用 Hive 的企业已经转向 Tez 来加速 SQL 查询,尤其是涉及到大数据集和复杂操作的场景。
- 批处理任务优化: Tez 的 DAG 模型使其非常适合执行复杂的批处理任务,如多阶段数据清洗、转换和加载(ETL)工作流。
- 实时或近实时处理: Tez 可以用于需要低延迟的场景,如实时数据分析和在线报告。
Tez 的局限性
- 学习曲线: 虽然 Tez 比 MapReduce 灵活高效,但它也更加复杂,要求开发者了解 DAG 模型及其配置。
- 任务复杂度: 对于非常简单的任务,Tez 的性能提升可能不明显,因此 Tez 更适用于复杂的、多阶段的任务场景。
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| 作业启动即失败:提示找不到 tez.tar.gz / FileNotFoundException | tez.lib.uris 指向的 HDFS 路径不存在或文件名不一致 | hdfs dfs -ls /user/tez + 核对 tez-site.xml 上传并统一文件名;确保 tez.lib.uris=hdfs://.../user/tez/tez.tar.gz 与实际一致 |
| Hive 切到 tez 仍走 MR | hive.execution.engine 未生效(会话/配置文件未加载) | Hive 里 set hive.execution.engine; 单次 set hive.execution.engine=tez;;永久写入 hive-site.xml 并重启相关服务/客户端 |
| NoClassDefFoundError: org/apache/tez/... | 客户端 classpath 未包含 Tez jars 或 TEZ_JARS 路径错误 | echo $HADOOP_CLASSPATH + 检查 /opt/apps/tez/lib 修正 TEZ_JARS 路径;把 Tez 解压目录与环境变量对齐;重新登录/source /etc/profile |
| 只有部分节点能跑,部分节点报类缺失/配置缺失 | tez-site.xml 未分发到全节点或版本不一致 | 对比各节点 $HADOOP_HOME/etc/hadoop/tez-site.xml 统一分发 tez-site.xml 到所有节点(含边缘节点/HS2 所在节点)并校验一致性 |
| Tez AM 启动失败、Container 反复重试 | YARN 资源不足、队列限制、ACL 或 AM 内存设置不匹配 | YARN RM UI/日志:ApplicationMaster 失败原因 调整队列资源/并发;降低并发或提高 AM/Task 内存;检查队列 ACL |
| Hive 报 TezTask 执行错误(return code 2 等) | 上游依赖未就绪(Tez lib、classpath、权限),或 SQL 触发大 shuffle | 先用最小 SQL 验证;看 HS2/Tez AM 日志 先跑简单查询验证链路;再逐步放大;必要时调 Tez/Hive 的内存与并行参数 |
| HDFS 权限错误:无法读取 /user/tez | 上传目录权限/属主不允许运行用户读取 | hdfs dfs -ls -h /user/tez 看权限与属主 给执行用户/组读权限;或将 Tez 包放到公共可读目录并规范权限配置 |
| 写了但不生效(尤其是 profile) | 环境变量未加载、写法断行导致 export 异常 | envgrep TEZ 检查是否存在 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-207 RabbitMQ Direct 交换器路由:RoutingKey 精确匹配、队列多绑定与日志分流实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解