
https://shandaai.github.io/project_mio_page/
官网有交互式演示视频(CSDN审核没通过,感兴趣的可以去看一下)
M.I.O 项目:面向数字人交互式智能的创新框架
M.I.O(Multimodal Interactive Omni-Avator,多模态交互式全维度智能体)是由盛大AI研究院东京分部(Shanda AI Research Tokyo)联合东京大学、东京理科大学团队研发的数字人智能框架,核心目标是突破现有数字人的"模仿性局限",实现具备真正交互式智能的数字人系统,相关研究成果已以论文形式发布于arXiv(2025年,编号2512.13674,领域:cs.CV)。
一、项目背景:现有数字人的核心痛点
当前多数数字人仅能"表面模仿"人类行为,缺乏关键的交互式智能------无法在语音、面部表情、身体动作、外观呈现等多维度上,生成"实时响应、情感连贯、人格一致"的交互反馈,难以满足真实场景下的自然互动需求。
二、核心定位:数字人的"自主智能体"转型
M.I.O 首次将数字人定义为具备三大核心能力的自主智能体:
- 人格一致性表达:多模态输出(语音、表情、动作)始终贴合设定人格;
- 自适应交互:能根据用户输入的上下文动态调整回应策略;
- 自我进化:具备持续优化交互效果的潜力。
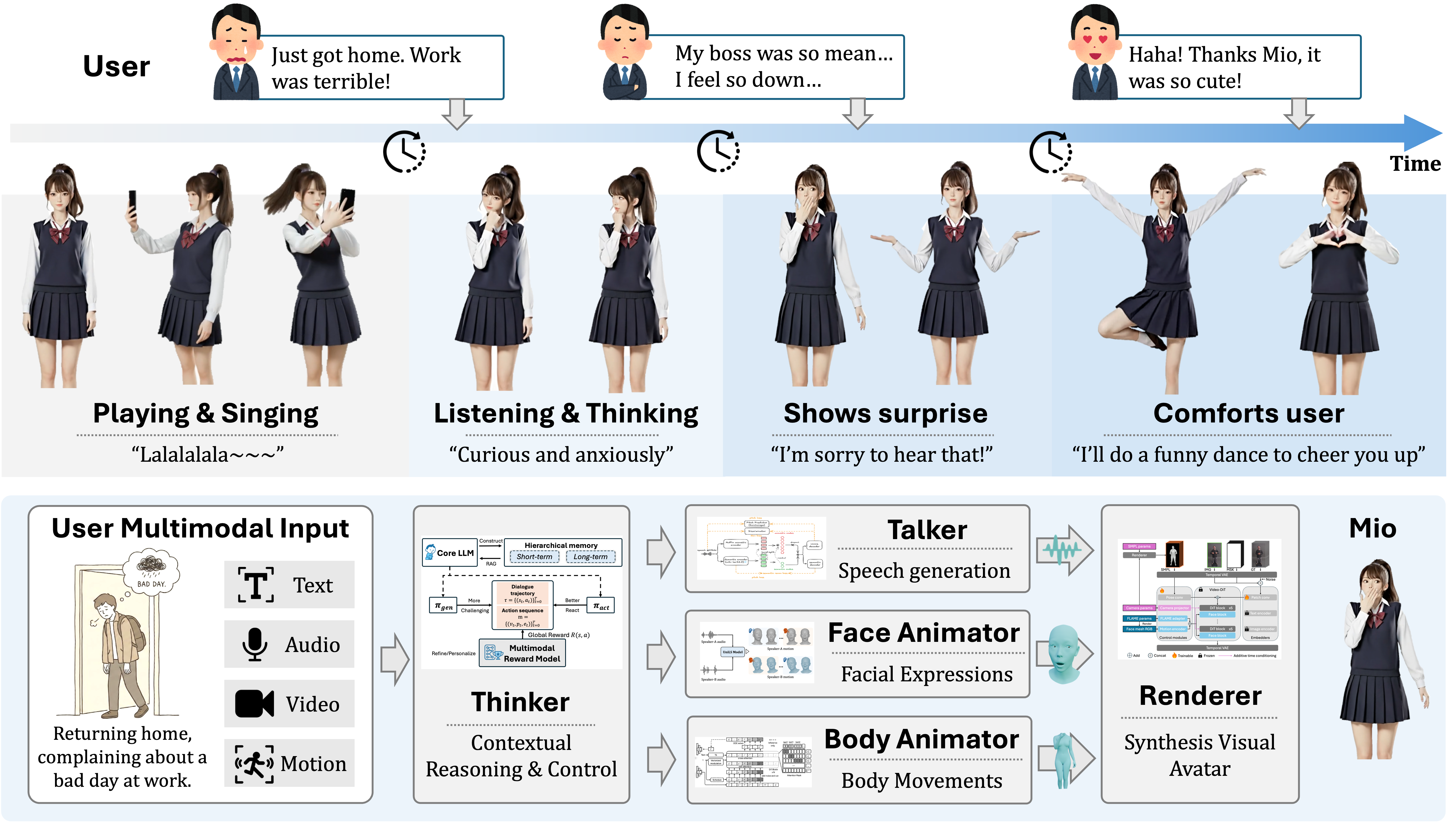
三、核心框架:五级级联模块(端到端可控)
项目设计了"思考-表达-呈现"全链路的五大模块,实现多模态交互的协同生成:
| 模块名称 | 核心功能 |
|---|---|
| Thinker(思考器) | 核心控制单元,负责上下文推理、用户意图理解与交互逻辑调度,是智能决策核心; |
| Talker(表达器) | 基于核心大语言模型(Core LLM),生成与语境匹配的多模态语音(文本+音频); |
| Facial Animator(面部动画器) | 同步语音与情绪,生成自然、连贯的面部表情; |
| Body Animator(身体动画器) | 结合交互场景与情绪状态,生成协调的身体动作; |
| Renderer(渲染器) | 整合语音、表情、动作,输出最终的可视化数字人形象,实现端到端可控。 |
四、关键创新:交互式智能评估基准
为解决"数字人智能难以量化"的问题,M.I.O 首次提出一套多维度评估基准,从5个核心维度衡量数字人的交互式智能:
- 语音一致性(与语境、人格匹配);
- 表情自然度(情绪传递准确);
- 动作协调性(与语音、表情同步);
- 视觉风格统一性(外观与交互场景适配);
- 人格连贯性(长期交互中保持设定人格不变)。
五、应用示例:真实场景交互演示
项目文档中展示了典型交互场景:
如需查看完整论文或演示视频,可访问项目官网(https://shandaai.github.io/project_mio_page/)或arXiv论文链接:https://arxiv.org/abs/2512.13674。
