ABSTRACT
作为推荐系统的关键环节,排序的任务是给用户提供一个有序的item列表。传统上,一个排序函数通过最优化全局表现从标注过的数据集中得到学习,它能够为每个独立的item输出一个排序分。然而,应用到每个item上的打分函数是独立的,同时也没有明确考虑item之间的相互影响及用户的偏好和意图,这可能带来一个次优解。
因此,我们提出了一个推荐系统的个性化的重排模型(personalized re-ranking model)。这个重排模型可以直接使用已有的排序特征向量,进而作为任何排序算法的后续模块进行简单的部署。这个模型通过使用一个transformer结构来高效地编码推荐列表中所有item的信息,进而直接优化整个推荐列表。特别地,这个transformer应用了一个self-attention机制,这样能够直接建模推荐列表中的任何item-pair的全局关系。我们也证明,如果引入一个预训练的embedding来学习不同用户的个性化编码函数,那么整体的表现能够得到进一步的提升。实验结果表明,提出的重排模型在离线基准和真实的在线电子商务系统中均获得了重要提升。
1. INTRODUCTION
排序是推荐系统的关键一环。一个排序算法给出的排序列表的质量对用户的满意度和推荐系统的收入都有很大影响。现阶段已有大量的排序算法被提出来优化排序表现。推荐系统中的典型排序只考虑了user-item特征,而忽视了列表中其他items的影响,尤其是那些被并行排列的items。尽管基于pairwise和listwise的LTR方法试图通过把item-pair和item-list作为输入来解决此问题,但是他们只关注优化损失函数来让label数据得到更好的利用,并没有对特征空间中的item之间的相互影响进行确切建模。
一些研究趋向于对item间的相互影响进行显示建模,以此改进先前阶段的排序算法生成的初始列表,这就是re-ranking阶段。其主要思想通过将intra-item模式编码到特征空间,并以此构造评分函数。现阶段编码特征向量最新的方法是基于RNN的,例如GlobalRerank和DLCM。它们把初始列表有序地输入给基于RNN的网络结构,同时在每个时间步输出编码向量。然而,基于RNN的方法对建模列表中item间的相互作用能力有限。先前被编码的item的特征信息会随着编码距离而衰减。受机器翻译领域Transformer结构启发,我们提出使用Transformer来建模item间的相互影响。Transformer结构使用self-attention机制(注意力机制),self-attention可以做到任意两个item能够直接互相影响而不会在编码距离上退化。与此同时,由于并行机制,Transformer的编码过程会比基于RNN的方法更有效。
除了item间的相互作用,推荐系统的重排也应该考虑交互的个性化编码函数。推荐系统中的重排通常是用户特定的,取决于用户的表现和意图。对一个对价格敏感的用户来说,"价格"特征之间的交互在重排序模型中应该更为重要。典型的全局编码函数可能不是最优的,因为它忽视了每个用户的特征分布之间的差异。例如,当用户关注价格比较时,具有不同价格的相似item在列表中往往更集中。当用户没有明显的购买意向时,推荐列表中的item往往更加多样化。因此,我们在Transformer结构中引入了一个个性化模块,来表示用户的偏好和对item交互的意图。在我们的个性化重排模型中,列表中的item和用户之间的交互可以同时被捕获。
本文的主要贡献如下:
- Problem:我们提出了一个推荐系统中的个性化的重排luation序问题,据我们所知,这是在大规模在线系统中的重排序任务中首次显式地引入个性化信息。实验结果证明了在列表表征中引入用户表征进行重排序的有效性。
- Model:我们使用具有个性化embedding装备的Transformer来计算初始输入排序列表的表征,并输出重排序分。与基于RNN的方法相比,self-attention机制使我们能够更有效、更高效地建模任意两个item之间用户特定的相互影响。
- Data:我们发布了本文使用的一个大规模数据集(电子商务重排序数据集)。这个数据集来自一个真实的电子商务推荐系统。数据集中的记录包含一个排序使用的推荐列表,记录用户-点击标签和特征。
- Evaluation:我们进行了离在线实验来证明我们提出的方法要明显优于最先进的方法。在线 A/B实验表明,我们的方法取得了更高的点击率和更高的实际系统收益。
2. RELATED WORK
我们的工作诣在改进base排序算法生成的初始排序列表。在这些基本排序算法中,LTR是一个被广泛使用的方法。根据损失函数的区别,LTR方法可以被分为三类:pointwise,pairwise,listwise。所有的这些方法学习一个全局打分函数,在这个函数中特定特征的权重也是全局学习的。然而,特征的权重应该有能力识别item之间间的交互和用户与item之间的交互。
与我们工作最接近的重排方法,它们使用整个初始列表作为输入,同时建模不同方式下item间的复杂依赖。如1使用单向GRU把整个列表的信息编码到每个item的表征。37使用LSTM、3使用pointer网络不仅能够编码整个列表信息,也能够通过一个解码器生成重排后的列表。对于这些要么使用GRU要么使用LSTM来编码item的依赖的方法,编码能力受限于编码距离。在本文中,我们使用类transformer的编码器,基于注意力机制在O(1)的距离下对任意两个item间的交互进行建模。除此之外,对于那些使用解码器来顺序生成有序列表的方法,它们不适用于要求严格约束标准的在线排序系统。当顺序解码器使用在t-1时间选出的item作为输入来选择t时刻的item时,它不能并行处理,并需要n次推理,这里的n的输出列表的长度。2提出了一个能够并行对item进行打分的groupwise的评分函数,但是由于这个函数需要枚举列表中每个可能的item组合,它的计算代价很高。
3. RE-RANKING MODEL FORMULATION
在本章节,我们先给出推荐系统中LTR和重排方法的初步知识。然后我们阐述本文诣在解决的问题。本文使用的符号如下:
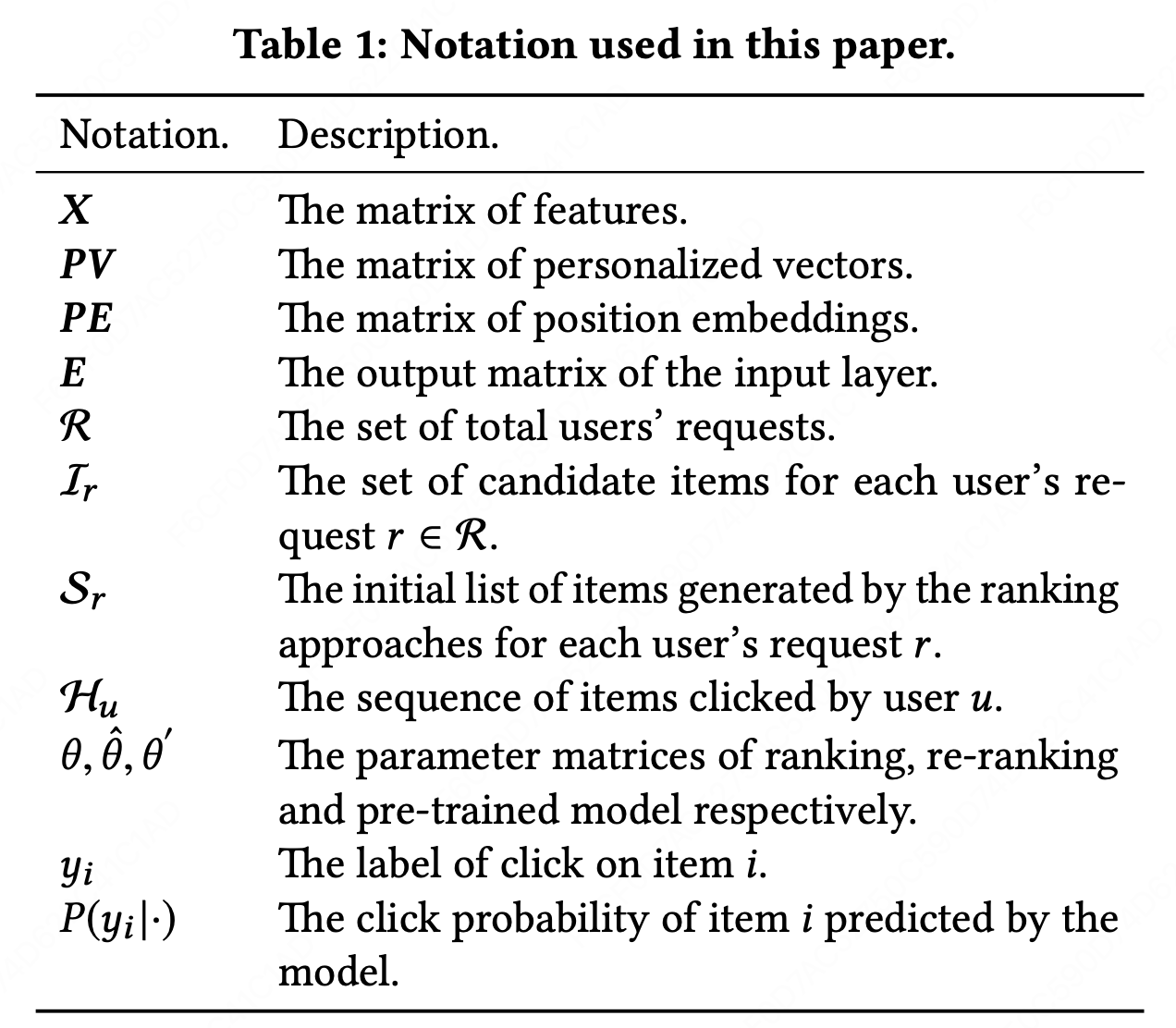
LTR在真实世界的系统中被广泛用于排序,目的是为信息检索和推荐系统生成有序的列表。LTR方法根据items的特征向量,学习一个全局的评分函数。有了这个评分函数,LTR方法通过对候选集中每个item进行打分来输出一个有序的列表。这个全局的评分函数通常通过最小化下面的损失函数学到:
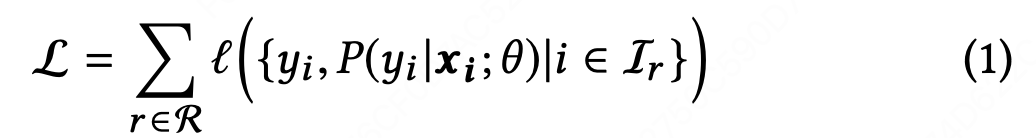
-
R is the set of all users' requests for recommendation.(推荐系统中所有用户的请求集)
-
Ir is the candidate set of items for request r ∈R. (请求r的item候选集)
-
xi represents the feature space of item i.(item i的特征空间)
-
yi is the label on item i, i.e., click or not. (item i的点击label)
-
**P(yi |xi;θ)**is the predicted click probability of item i given by the ranking model with parameters θ. (参数为θ的排序模型对item i预估的点击概率)
-
ℓ is the loss computed with yi and P(yi |xi ; θ). (真实label与预估概率计算出来的loss)
然而,对于学到一个好的打分函数而言,xi 并不够。我们发现,推荐系统中的排序应该考虑下面的一些额外信息:(a)item-pairs间的相互影响;(b)用户和items之间的交互。item-pairs之间的相互影响能够直接从初始列表Sr中学得,其中Sr是已有的LTR模型为请求r生成的结果列表。已有工作提出了一些方法来充分利用item-pairs之间交互信息。然而,几乎没有研究考虑用户和items之间的交互。item-pairs交互的影响程度在用户间是千变万化的。在本文中,我们引入一个个性化矩阵PV来学习用户指定的编码函数,使得这个函数有能力建模item-pairs间的个性化相互影响。该模型的损失函数如下:
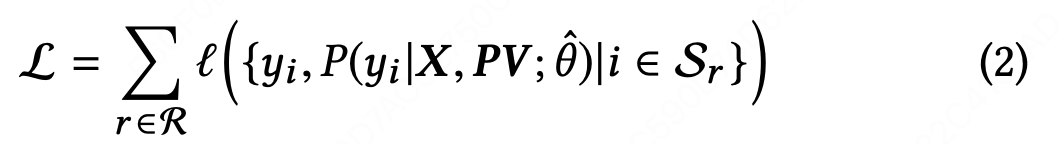
其中,Sr是先前排序模型给出的初始列表,是我们的重排模型的参数,X是列表中所有item的特征矩阵。
4. PERSONALIZED RE-RANKING MODEL
该章节,我们首先对我们提出的个性化重排模型PRM进行概述,然后我们详细介绍我们模型的每个组成部分。
4.1 Model Architecture
PRM模型的网络结构如下图所示:
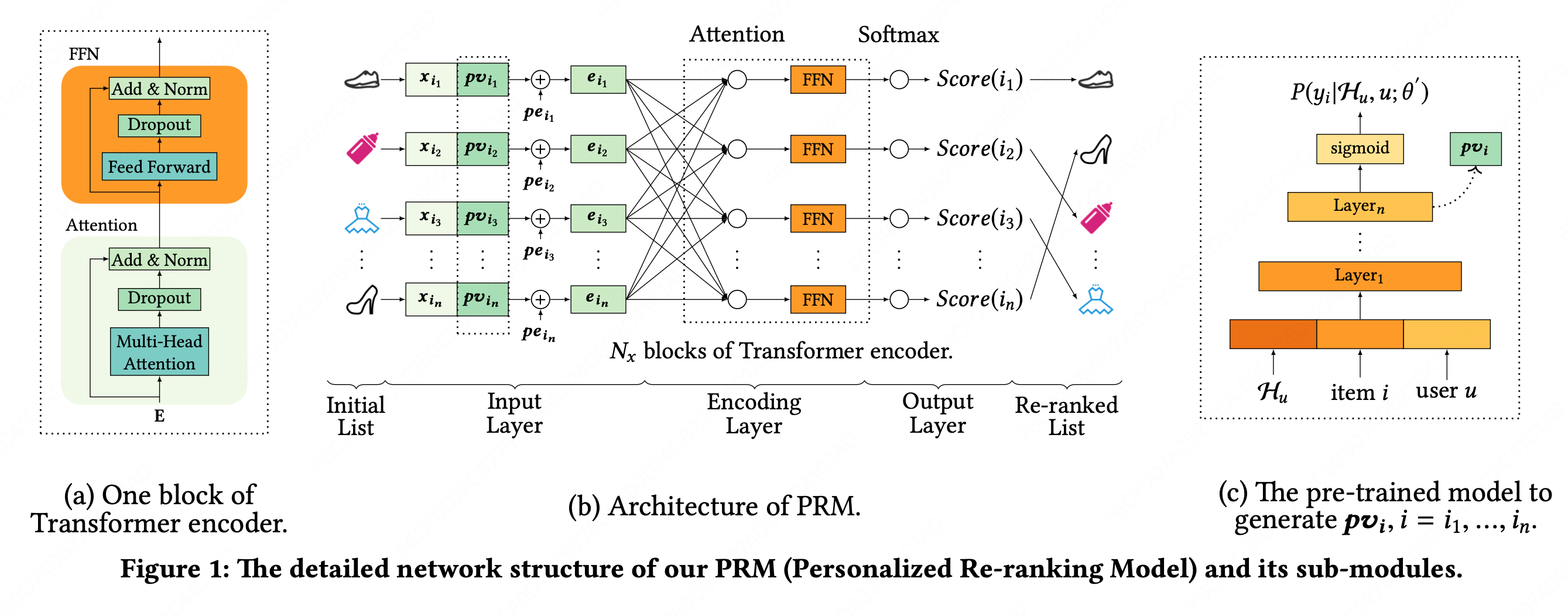
**PRM模型由三部分组成:input layer、encoding layer、output layer。**它将前序排序方法生成的item的初始列表作为输入,并输出一个重排后的列表。
4.2 Input Layer
4.3 Encoding Layer
4.4 Output Layer
4.5 Personalized Module
参考文献