一、缓存一致性问题的本质
在Java后端开发中,我们习惯通过@Cacheable注解或RedisTemplate操作缓存,但真正理解缓存一致性,必须深入到分布式系统的CAP理论层面。缓存一致性问题的本质是:在分布式环境下,同一份数据存在于数据库和缓存两个存储介质中,如何保证两者数据的一致性。
1.1 CAP理论与一致性
根据CAP理论,分布式系统无法同时满足一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。在缓存场景中:
- 强一致性:任何时刻读取缓存和数据库的数据完全相同,代价是性能下降
- 最终一致性:允许短暂的数据不一致,但最终会达到一致状态,是大多数系统的选择
- 弱一致性:不保证何时达到一致,适用于对一致性要求极低的场景
1.2 一致性问题的分类
| 问题类型 | 描述 | 危害程度 | 评估依据 |
|---|---|---|---|
| 缓存与DB不一致 | 缓存数据是旧值,DB是新值 | 高 | 持续到缓存过期,影响用户体验 |
| 并发写导致错乱 | 多线程同时写入导致数据覆盖 | 高 | 数据永久错误,需人工修复 |
| 删除缓存失败 | DB更新成功但缓存删除失败 | 高 | 网络抖动时发生,需重试机制 |
| 读写并发冲突 | 读线程回填旧值覆盖新值 | 中 | 需缓存miss+特定时序,罕见 |
缓存架构总览图:
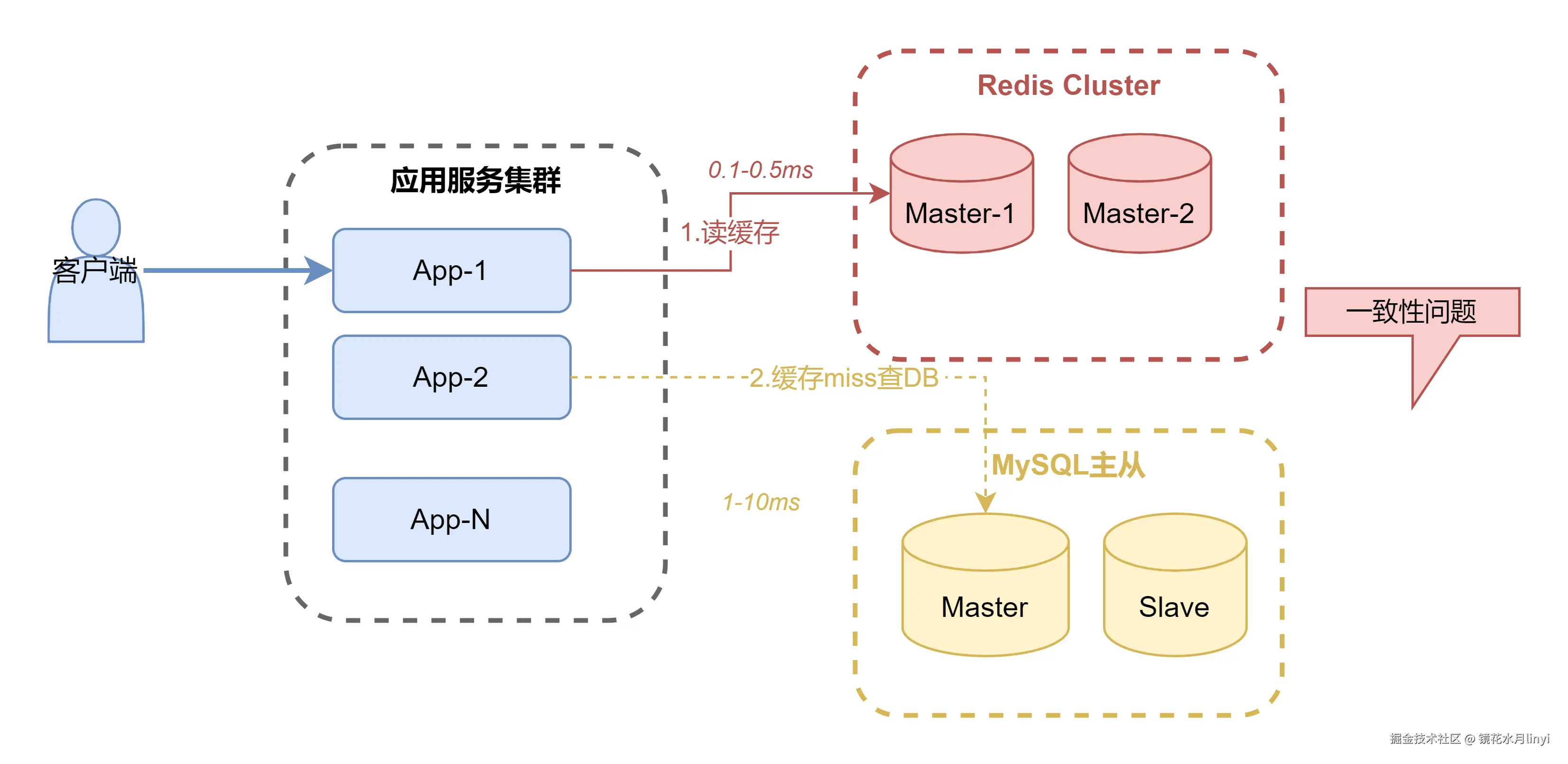
1.3 为什么需要缓存?
缓存的核心价值在于以空间换时间,将热点数据存储在内存中,减少数据库访问压力。
经典业务场景:电商商品详情页
java
// 无缓存:每次请求都查询数据库
public Product getProduct(Long productId) {
return productMapper.selectById(productId);
// QPS上限:约500-1000(受限于数据库连接池和磁盘IO)
}
// 有缓存:优先从Redis读取
public Product getProductWithCache(Long productId) {
String key = "product:" + productId;
Product product = redisTemplate.opsForValue().get(key);
if (product == null) {
product = productMapper.selectById(productId);
if (product != null) {
redisTemplate.opsForValue().set(key, product, 30, TimeUnit.MINUTES);
}
}
return product;
// QPS上限:约10000-50000(取决于Redis集群规模)
}二、缓存读写策略详解
业界主流的缓存读写策略有三种,它们在一致性、性能、复杂度之间做出不同的权衡。理解这三种策略的本质区别,是选择合适方案的前提。
2.1 三种经典缓存策略对比
| 策略 | 读流程 | 写流程 | 一致性 | 复杂度 | 适用场景 |
|---|---|---|---|---|---|
| Cache Aside | 先读缓存,miss则读DB并回填 | 先更新DB,再删除缓存 | 最终一致 | 低 | 通用场景(推荐) |
| Read/Write Through | 应用只与缓存交互 | 缓存代理负责同步DB | 强一致 | 高 | 缓存中间件支持 |
| Write Behind | 应用只与缓存交互 | 缓存异步批量写DB | 弱一致 | 高 | 写密集、允许丢数据 |
三种缓存策略架构对比图:
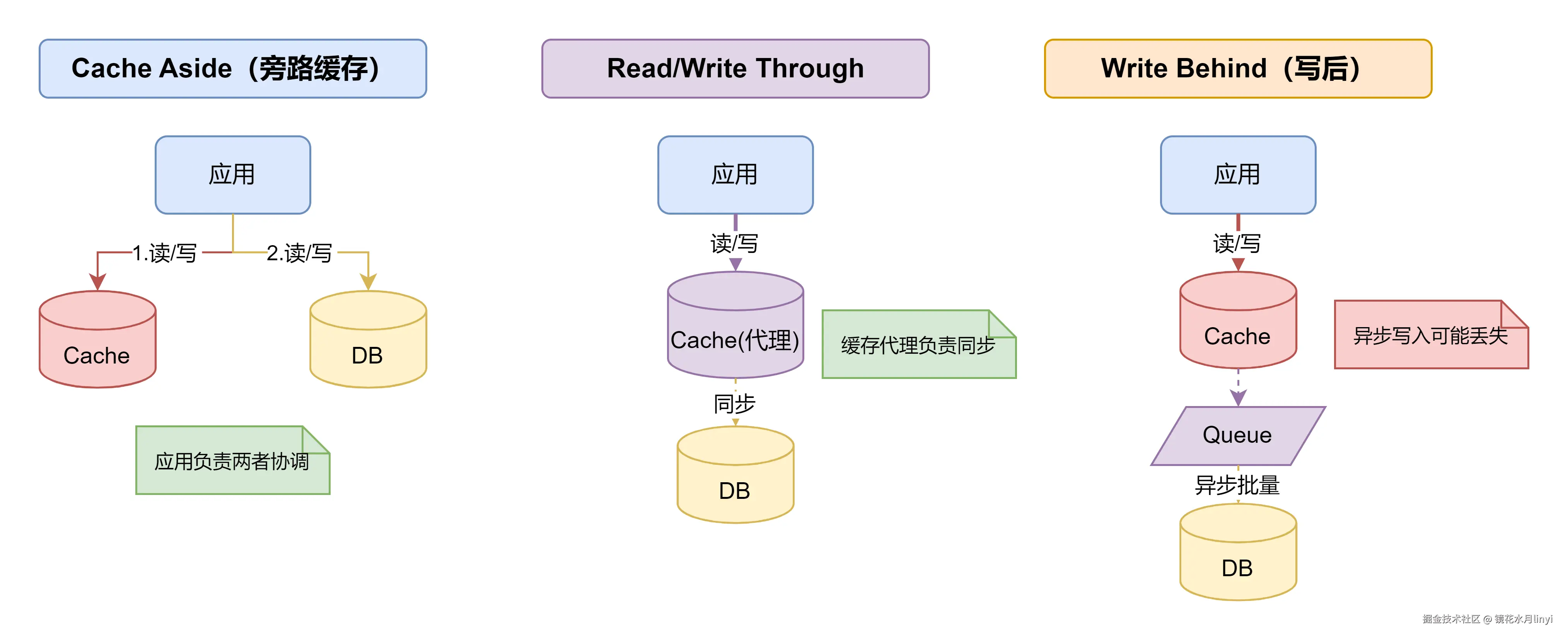
策略选择建议:
- Cache Aside:应用层控制缓存逻辑,灵活性高,是绝大多数互联网公司的首选
- Read/Write Through:需要缓存中间件支持(如Redis Module),适合有强一致性需求且中间件支持的场景
- Write Behind:写入性能极高,但存在数据丢失风险,仅适用于日志、统计等可丢失场景
2.2 Cache Aside模式详解(业界主流)
Cache Aside模式(旁路缓存)是业界使用最广泛的缓存策略,其核心思想是应用程序同时维护缓存和数据库,而不是依赖缓存中间件自动同步。
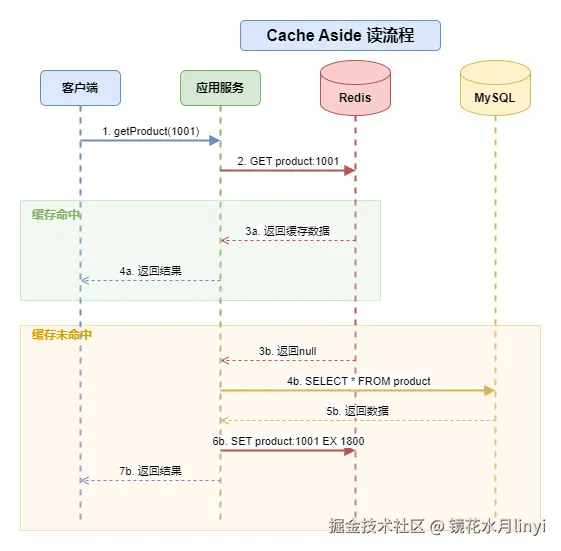
读流程核心逻辑:
- 先查询缓存,命中则直接返回
- 缓存未命中,查询数据库
- 将数据库结果回填到缓存(设置合理的过期时间)
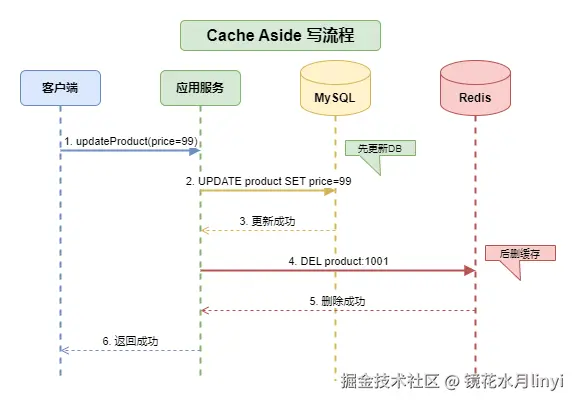
写流程核心逻辑:
- 先更新数据库(保证数据持久化)
- 再删除缓存(而非更新缓存)
Cache Aside读流程图:
Cache Aside写流程图:
Java实现代码:
java
@Service
@Slf4j
public class ProductService {
@Autowired
private ProductMapper productMapper;
@Autowired
private StringRedisTemplate redisTemplate;
private static final String PRODUCT_KEY_PREFIX = "product:";
private static final long CACHE_TTL = 30 * 60; // 30分钟
/**
* Cache Aside 读取模式
*/
public Product getProduct(Long productId) {
String key = PRODUCT_KEY_PREFIX + productId;
// 1. 先查缓存
String json = redisTemplate.opsForValue().get(key);
if (StringUtils.hasText(json)) {
return JSON.parseObject(json, Product.class);
}
// 2. 缓存未命中,查数据库
Product product = productMapper.selectById(productId);
// 3. 回填缓存(注意空值处理,防止缓存穿透)
if (product != null) {
redisTemplate.opsForValue().set(key, JSON.toJSONString(product),
CACHE_TTL, TimeUnit.SECONDS);
} else {
redisTemplate.opsForValue().set(key, "", 60, TimeUnit.SECONDS);
}
return product;
}
/**
* Cache Aside 写入模式
*/
@Transactional(rollbackFor = Exception.class)
public void updateProduct(Product product) {
// 1. 先更新数据库
productMapper.updateById(product);
// 2. 再删除缓存
String key = PRODUCT_KEY_PREFIX + product.getId();
redisTemplate.delete(key);
}
}三、缓存一致性问题深度分析
这是缓存一致性最核心的章节,我们来深入分析几个关键问题:为什么删除而不是更新?为什么先更新DB后删缓存?这些问题的答案直接决定了系统的数据一致性。
3.1 为什么是"删除缓存"而不是"更新缓存"?
这是一个面试高频问题。直觉上,更新缓存似乎更高效(避免下次cache miss),但实际上删除缓存才是正确选择,原因有二:
原因一:避免并发写导致数据错乱
假设两个线程同时更新同一条数据:
- 线程A更新DB为100,然后准备更新缓存
- 线程B更新DB为200,然后更新缓存为200
- 线程A由于网络延迟,最后才更新缓存为100
- 结果:DB=200,缓存=100,数据不一致!
原因二:避免无效的缓存计算
如果缓存数据是经过复杂计算得出的(如多表JOIN、聚合统计),每次更新都重新计算是浪费资源。而删除缓存后,只有真正被访问时才计算,这就是懒加载思想。
| 方案 | 优点 | 缺点 | 推荐度 |
|---|---|---|---|
| 更新缓存 | 缓存始终有值,无穿透风险 | 并发写导致数据错乱、无效计算 | 不推荐 |
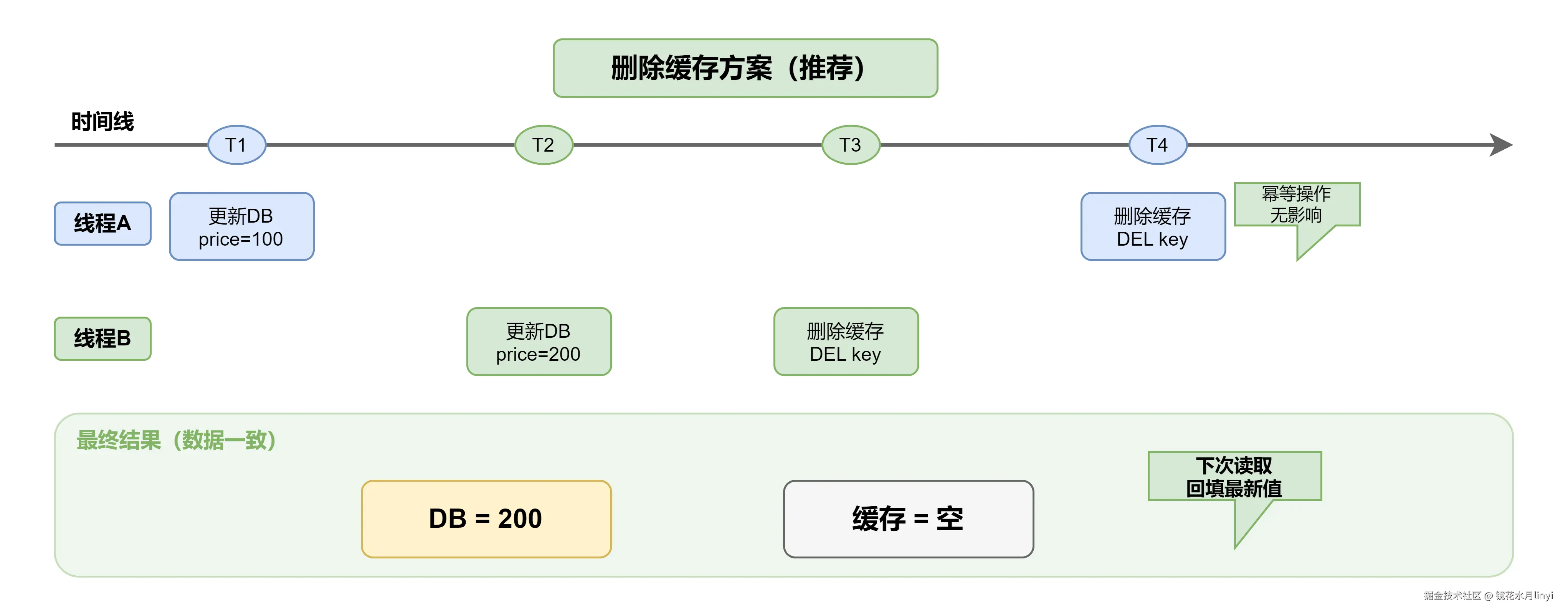
| 删除缓存 | 简单可靠、避免并发问题、懒加载 | 下次读有一次cache miss | 推荐 |
并发更新缓存导致数据错乱示意图:

删除缓存方案(推荐):
3.2 为什么是"先更新DB,后删除缓存"?
这是另一个高频面试题。既然要操作DB和缓存,那必然有先后顺序,我们来分析两种组合:
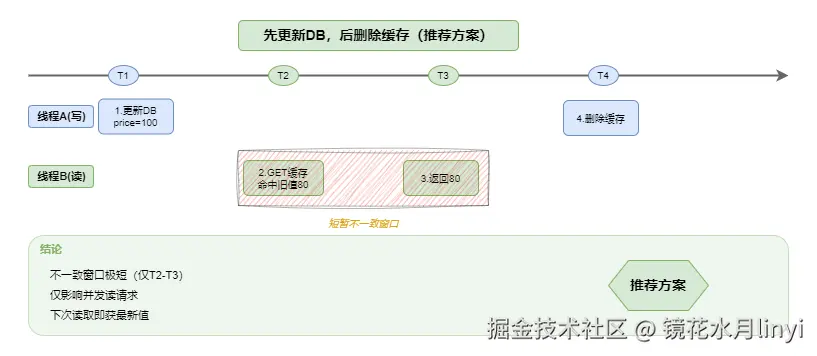
组合一:先更新DB,后删除缓存(推荐)
时间线: T1: 线程A更新DB (price=100) T2: 线程B读取缓存(命中旧值80) T3: 线程B返回旧值80 T4: 线程A删除缓存 T5: 后续请求读取DB,获得最新值100
这种方案的问题是:在T2-T3时间窗口内,可能读到旧数据。但这个窗口极短(通常<1ms),且下次读取就能获得最新值。
方案对比分析图:
组合二:先删除缓存,后更新DB(不推荐)
时间线: T1: 线程A删除缓存 T2: 线程B读取缓存(未命中) T3: 线程B读取DB(旧值80) T4: 线程A更新DB (price=100) T5: 线程B将旧值80写入缓存 T6: 后续请求读取缓存,持续返回旧值80!
这种方案的严重问题是:缓存中会长时间存储旧数据,直到缓存过期或下次更新才能修复。
先删除缓存后更新DB的问题:
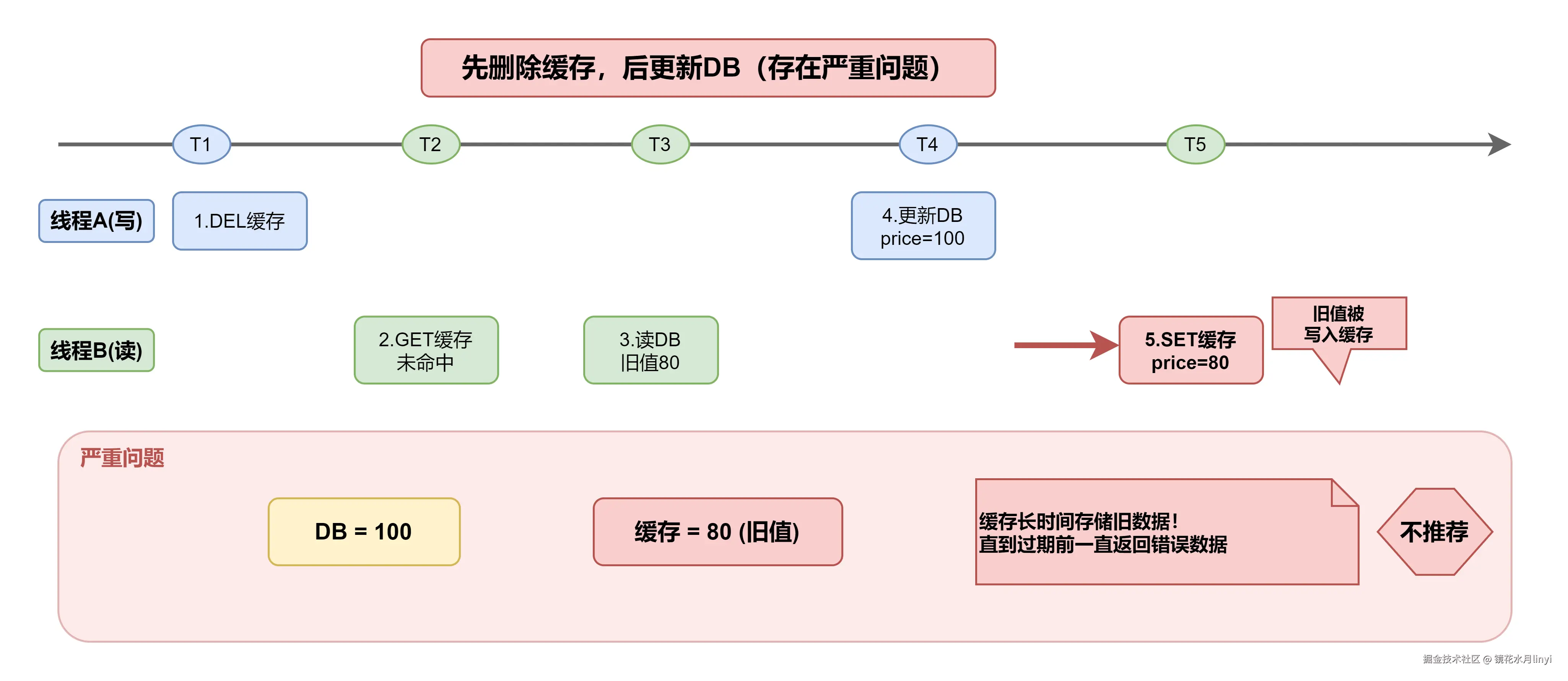
结论:先更新DB,后删除缓存是最佳实践。虽然存在短暂不一致窗口,但这是可接受的最终一致性;而先删缓存可能导致长时间数据错误。
3.3 删除缓存失败怎么办?
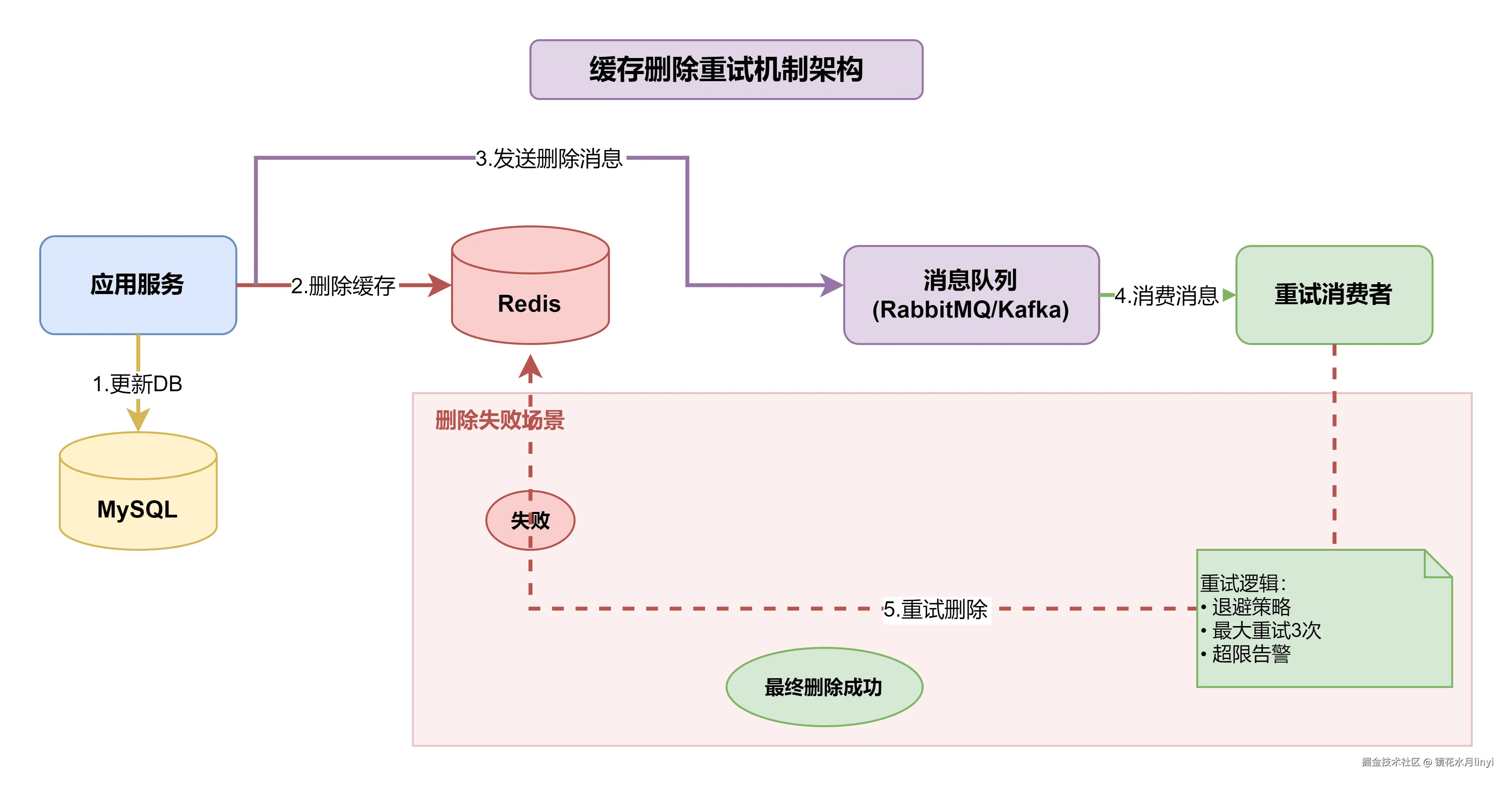
在分布式环境中,网络是不可靠的。如果DB更新成功,但缓存删除失败(网络抖动、Redis故障等),就会导致缓存中一直存储旧数据。
解决方案:基于消息队列的异步重试机制
核心思路:
- 尝试删除缓存
- 如果失败,将删除任务发送到消息队列
- 消费者异步重试删除,采用退避策略
- 超过最大重试次数则告警,人工介入
重试机制架构图:
Java实现:
java
@Service
@Slf4j
public class ProductService {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* 带重试机制的缓存删除
*/
public void deleteCache(String key) {
try {
Boolean deleted = redisTemplate.delete(key);
if (Boolean.TRUE.equals(deleted)) {
return;
}
} catch (Exception e) {
log.error("Failed to delete cache: {}", key, e);
}
// 删除失败,发送到消息队列进行异步重试
CacheDeleteMessage message = new CacheDeleteMessage(key, 0);
rabbitTemplate.convertAndSend("cache.delete.queue", message);
}
}
@Component
@Slf4j
public class CacheDeleteRetryConsumer {
private static final int MAX_RETRY = 3;
@RabbitListener(queues = "cache.delete.queue")
public void handleCacheDelete(CacheDeleteMessage message) {
String key = message.getKey();
int retryCount = message.getRetryCount();
try {
Thread.sleep(100 * (retryCount + 1)); // 退避策略
redisTemplate.delete(key);
} catch (Exception e) {
if (retryCount < MAX_RETRY) {
message.setRetryCount(retryCount + 1);
rabbitTemplate.convertAndSend("cache.delete.queue", message);
} else {
log.error("Max retry reached for cache delete: {}", key);
}
}
}
}四、延迟双删策略
延迟双删是针对极端并发场景的补充方案。虽然"先更新DB后删缓存"已经是最佳实践,但在特定条件下仍可能出现数据不一致。
方案演进说明:你可能注意到,第三章强调"先更新DB后删缓存",而延迟双删却采用"先删缓存"。这看似矛盾,实则是不同场景的权衡:
- 基本方案追求简单可靠,适用于99%的场景
- 延迟双删针对极端并发,通过第一次删除"临时封锁"读请求,牺牲少量性能换取更高一致性
- 两者可以结合使用:先删缓存→更新DB→延迟再删,覆盖更多边界场景
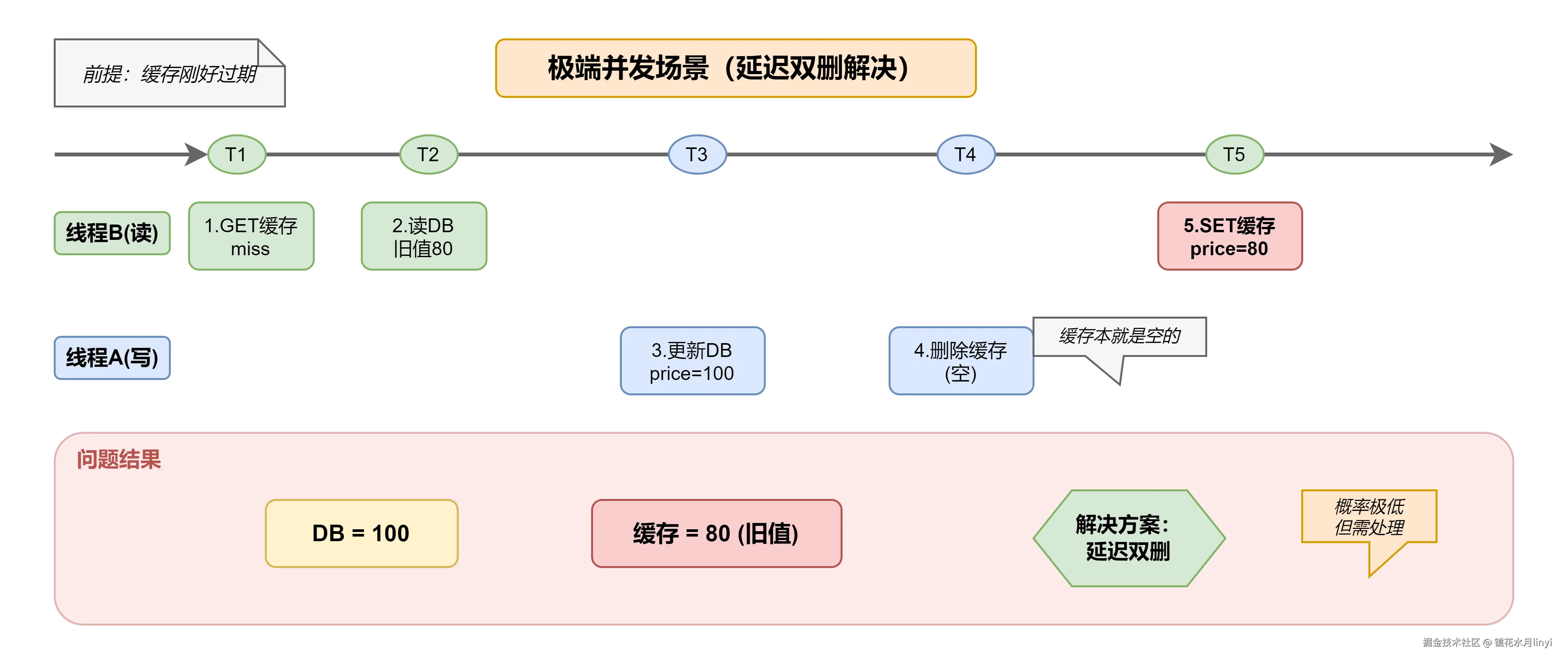
4.1 为什么需要延迟双删?
触发条件(同时满足):
- 缓存刚好在此时过期(或不存在)
- 读请求在写请求"更新DB"和"删除缓存"之间到达
- 读请求的"回填缓存"操作晚于写请求的"删除缓存"
这种情况概率极低(通常<0.01%),但在高并发场景下确实可能发生。
极端并发场景分析图:
4.2 延迟双删实现
延迟双删流程图:

Java实现:
java
@Service
@Slf4j
public class ProductService {
@Autowired
private ProductMapper productMapper;
@Autowired
private StringRedisTemplate redisTemplate;
private static final String PRODUCT_KEY_PREFIX = "product:";
/**
* 延迟双删策略
*/
@Transactional(rollbackFor = Exception.class)
public void updateProductWithDoubleDelete(Product product, long delayMs) {
String key = PRODUCT_KEY_PREFIX + product.getId();
// 1. 第一次删除缓存
redisTemplate.delete(key);
// 2. 更新数据库
productMapper.updateById(product);
// 3. 延迟第二次删除缓存
CompletableFuture.delayedExecutor(delayMs, TimeUnit.MILLISECONDS)
.execute(() -> redisTemplate.delete(key));
}
}延迟双删的局限性:
| 优点 | 缺点 |
|---|---|
| 解决极端并发问题 | 延迟期间仍可能不一致 |
| 实现相对简单 | 增加系统复杂度 |
| 无需额外中间件 | 延迟时间难以精确计算 |
建议:对于大多数业务场景,"先更新DB后删缓存 + 合理的过期时间"已经足够。只有在对一致性要求较高且写并发较大的场景,才需要引入延迟双删。
五、基于Binlog的最终一致性方案
基于Binlog的方案是业务代码零侵入的终极方案,通过监听MySQL的Binlog变更,异步同步到缓存。这种方案常用于:
- 微服务架构下的数据同步
- 对一致性要求较高但允许秒级延迟的场景
- 需要解耦业务代码与缓存逻辑的场景
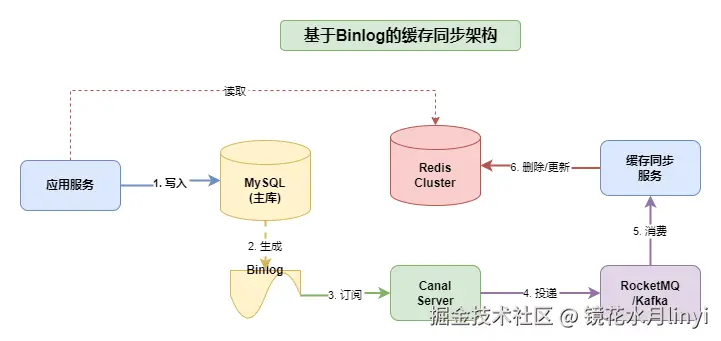
5.1 方案架构
核心组件:
- Canal:阿里开源的MySQL Binlog增量订阅组件,伪装成MySQL从库
- 消息队列:Kafka/RocketMQ,用于解耦和削峰
- 缓存同步服务:消费Binlog消息,执行缓存更新/删除
Binlog缓存同步架构图:
5.2 Canal配置与使用
MySQL开启Binlog:
sql
[mysqld]
log-bin=mysql-bin
binlog-format=ROW
server-id=1
-- 创建Canal用户
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal123';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';Java消费端实现(完整版):
java
import com.alibaba.fastjson.JSON;
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.spring.annotation.RocketMQMessageListener;
import org.apache.rocketmq.spring.core.RocketMQListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
import java.util.Map;
import java.util.concurrent.TimeUnit;
/**
* Binlog缓存同步服务 - 处理INSERT/UPDATE/DELETE事件
*/
@Service
@Slf4j
@RocketMQMessageListener(topic = "canal_product_topic", consumerGroup = "cache_sync_group")
public class CanalMessageConsumer implements RocketMQListener<CanalMessage> {
@Autowired
private StringRedisTemplate redisTemplate;
private static final String CACHE_KEY_PREFIX = "product:";
private static final long CACHE_TTL = 30 * 60; // 30分钟
@Override
public void onMessage(CanalMessage message) {
if (!"product".equals(message.getTable())) {
return;
}
String eventType = message.getType();
log.info("Received binlog event: table={}, type={}", message.getTable(), eventType);
try {
for (Map<String, String> data : message.getData()) {
String id = data.get("id");
String key = CACHE_KEY_PREFIX + id;
switch (eventType) {
case "INSERT":
case "UPDATE":
// 方式一:直接删除缓存(推荐,简单可靠)
redisTemplate.delete(key);
// 方式二:更新缓存(可选,适合读多写少)
// String json = JSON.toJSONString(data);
// redisTemplate.opsForValue().set(key, json, CACHE_TTL, TimeUnit.SECONDS);
break;
case "DELETE":
redisTemplate.delete(key);
break;
default:
log.warn("Unknown event type: {}", eventType);
}
}
} catch (Exception e) {
log.error("Failed to process binlog message: {}", message, e);
// 消费失败,RocketMQ会自动重试
throw new RuntimeException("Binlog sync failed", e);
}
}
}
/**
* Canal消息实体
*/
@Data
public class CanalMessage {
private String database;
private String table;
private String type; // INSERT, UPDATE, DELETE
private List<Map<String, String>> data;
private List<Map<String, String>> old; // UPDATE时的旧值
}5.3 Binlog方案的可靠性与监控
潜在风险与应对:
| 风险点 | 描述 | 应对措施 |
|---|---|---|
| Canal延迟 | Binlog解析+MQ投递,通常1-5秒 | Prometheus监控Canal延迟,超阈值告警 |
| Canal故障 | 进程挂掉或主从切换 | 部署高可用集群,Zookeeper选主 |
| MQ消费失败 | 网络抖动或Redis故障 | 配置重试策略,死信队列兜底 |
| 消息积压 | 写入高峰期处理不及时 | 扩容消费者,监控lag指标 |
监控要点:
yaml
# Prometheus监控指标示例
canal_binlog_delay_seconds # Canal解析延迟
rocketmq_consumer_lag # 消费积压量
redis_cache_sync_success # 同步成功率
redis_cache_sync_latency # 同步延迟5.4 Binlog方案优缺点
| 维度 | 优点 | 缺点 |
|---|---|---|
| 一致性 | 最终一致性保证强 | 存在1-5秒延迟(Canal+MQ) |
| 侵入性 | 业务代码零侵入 | 需运维Canal/Zookeeper集群 |
| 可靠性 | Binlog本身不丢失 | 下游消费可能失败,需重试机制 |
| 扩展性 | 支持多表、多数据源同步 | 架构复杂度显著增加 |
与Debezium对比:Debezium是另一个流行的CDC工具,支持更多数据库(PostgreSQL、MongoDB等),与Kafka Connector集成更好。Canal更适合国内MySQL生态,社区活跃度高。
六、分布式锁方案
当业务对一致性有强要求(如金融交易、库存扣减)时,可以使用分布式锁来保证缓存和数据库的强一致性。
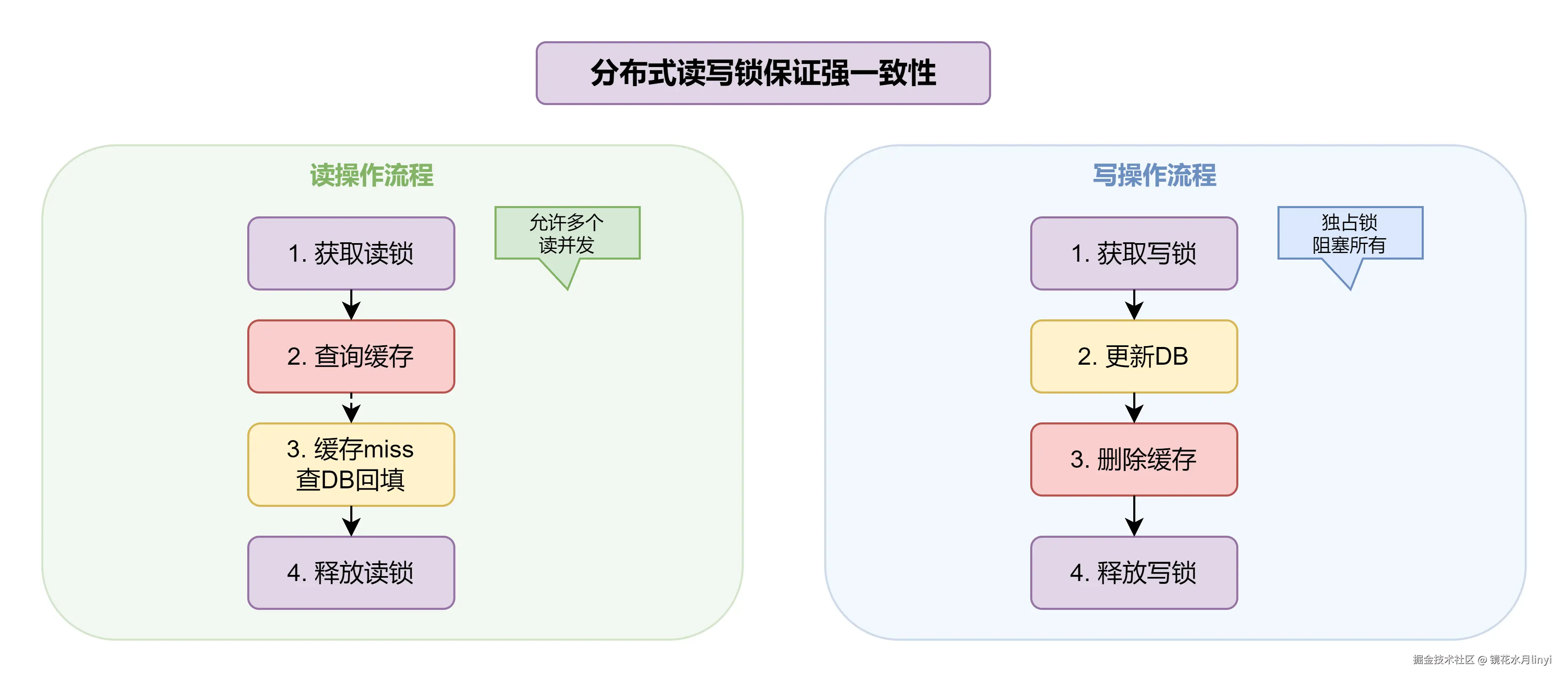
6.1 读写锁保证强一致性
核心思想:
- 读操作获取读锁,允许多个读并发
- 写操作获取写锁,独占访问,阻塞其他读写
- 写锁释放后,其他读请求才能继续,保证读到最新数据
分布式读写锁架构图:
Java完整实现:
java
@Service
@Slf4j
public class ProductService {
@Autowired
private RedissonClient redissonClient;
@Autowired
private ProductMapper productMapper;
@Autowired
private StringRedisTemplate redisTemplate;
private static final String LOCK_KEY_PREFIX = "lock:product:";
private static final String CACHE_KEY_PREFIX = "product:";
/**
* 带读锁的查询
*/
public Product getProductWithLock(Long productId) {
String lockKey = LOCK_KEY_PREFIX + productId;
String cacheKey = CACHE_KEY_PREFIX + productId;
RReadWriteLock rwLock = redissonClient.getReadWriteLock(lockKey);
RLock readLock = rwLock.readLock();
try {
// 获取读锁,允许多个读并发
readLock.lock(10, TimeUnit.SECONDS);
// 先查缓存
String json = redisTemplate.opsForValue().get(cacheKey);
if (StringUtils.hasText(json)) {
return JSON.parseObject(json, Product.class);
}
// 缓存miss,查数据库并回填
Product product = productMapper.selectById(productId);
if (product != null) {
redisTemplate.opsForValue().set(cacheKey,
JSON.toJSONString(product), 30, TimeUnit.MINUTES);
}
return product;
} finally {
if (readLock.isHeldByCurrentThread()) {
readLock.unlock();
}
}
}
/**
* 带写锁的更新
*/
@Transactional(rollbackFor = Exception.class)
public void updateProductWithLock(Product product) {
String lockKey = LOCK_KEY_PREFIX + product.getId();
String cacheKey = CACHE_KEY_PREFIX + product.getId();
RReadWriteLock rwLock = redissonClient.getReadWriteLock(lockKey);
RLock writeLock = rwLock.writeLock();
try {
// 获取写锁,独占访问
writeLock.lock(30, TimeUnit.SECONDS);
// 更新数据库
productMapper.updateById(product);
// 删除缓存
redisTemplate.delete(cacheKey);
log.info("Product updated with lock: {}", product.getId());
} finally {
if (writeLock.isHeldByCurrentThread()) {
writeLock.unlock();
}
}
}
}读写锁兼容性:
| 当前持有 | 读锁请求 | 写锁请求 |
|---|---|---|
| 无锁 | 允许 | 允许 |
| 读锁 | 允许 | 阻塞 |
| 写锁 | 阻塞 | 阻塞 |
分布式锁方案的注意事项:
- 锁粒度:锁的Key应该细化到具体数据ID,避免锁范围过大影响性能
- 超时设置:必须设置锁超时,防止死锁
- 性能影响:读写锁会降低系统吞吐量,仅在强一致性场景使用
- 锁续期:对于长事务,考虑使用Redisson的看门狗机制自动续期
- 锁重入:Redisson的RReadWriteLock支持锁重入,同一线程可多次获取
建议 :分布式锁方案仅适用于读多写少且对一致性有强要求的场景(如账户余额、库存扣减)。对于一般业务,Cache Aside + 合理TTL已足够。
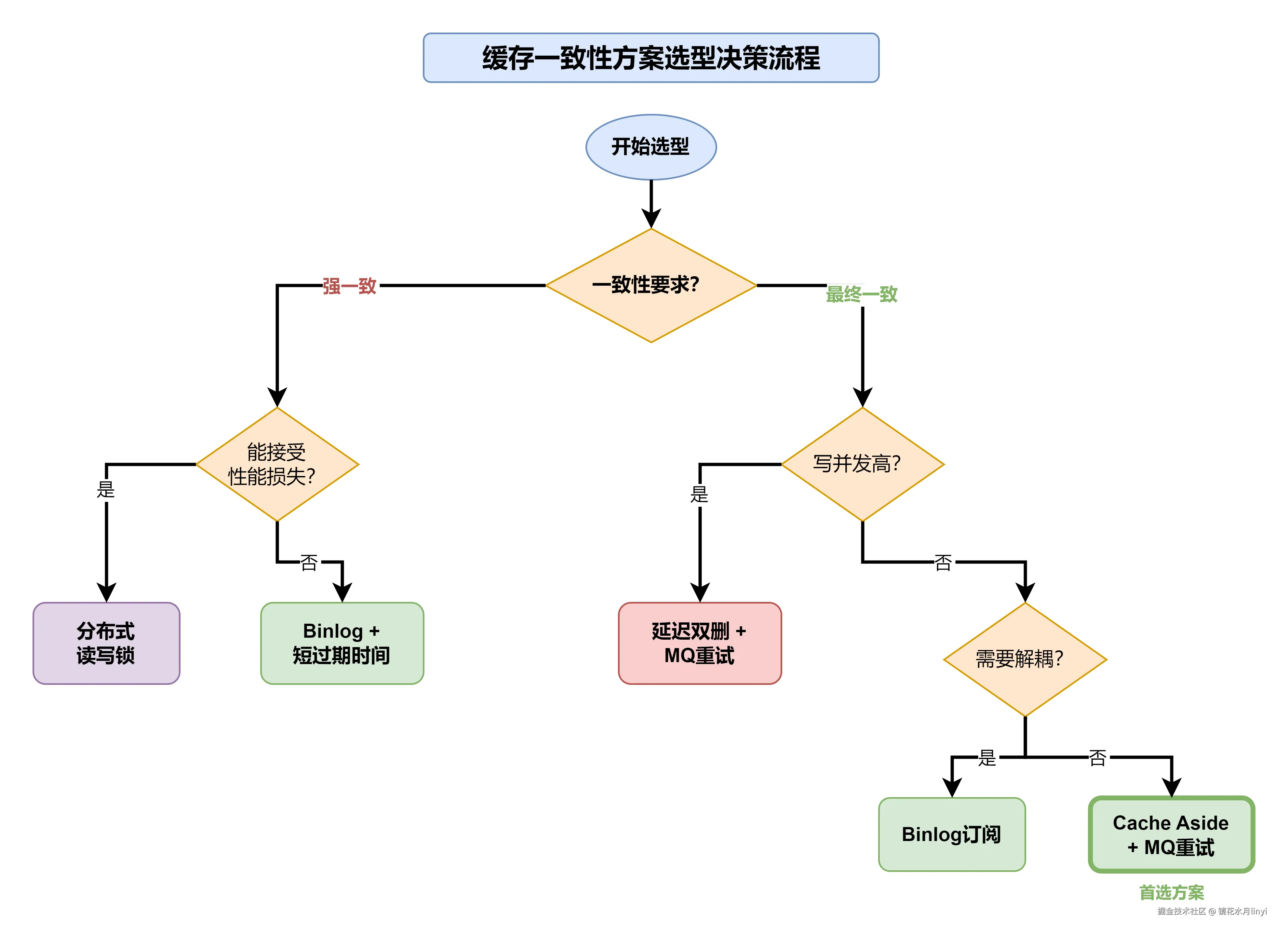
七、缓存一致性方案选型指南
选择合适的缓存一致性方案,需要综合考虑业务场景、一致性要求、系统复杂度等因素。
7.1 方案对比总结
| 方案 | 一致性级别 | 实现复杂度 | 性能影响 | 适用场景 |
|---|---|---|---|---|
| Cache Aside | 最终一致(ms级) | 低 | 无 | 通用场景(首选) |
| 延迟双删 | 最终一致(百ms级) | 中 | 低 | 并发写入较多 |
| MQ重试 | 最终一致(秒级) | 中 | 无 | 网络不稳定 |
| Binlog订阅 | 最终一致(秒级) | 高 | 无 | 强一致性、数据同步 |
| 分布式锁 | 强一致 | 中 | 高 | 金融级要求 |
7.2 决策流程图
7.3 缓存三大经典问题
除了一致性问题,缓存还有三个必须处理的经典问题:
| 问题 | 描述 | 解决方案 |
|---|---|---|
| 缓存穿透 | 查询不存在的数据,每次都打到DB | 缓存空值、布隆过滤器 |
| 缓存击穿 | 热点Key过期瞬间,大量请求打到DB | 分布式锁、永不过期+异步更新 |
| 缓存雪崩 | 大量Key同时过期,DB瞬间压力剧增 | 过期时间加随机值、多级缓存 |
7.3.1 缓存穿透防护
方案一:缓存空值
java
public Product getProduct(Long productId) {
String key = "product:" + productId;
String json = redisTemplate.opsForValue().get(key);
// 缓存命中(包括空值标记)
if (json != null) {
if (json.isEmpty()) {
return null; // 空值标记,防止穿透
}
return JSON.parseObject(json, Product.class);
}
// 查询数据库
Product product = productMapper.selectById(productId);
if (product != null) {
redisTemplate.opsForValue().set(key, JSON.toJSONString(product), 30, TimeUnit.MINUTES);
} else {
// 缓存空值,短过期时间
redisTemplate.opsForValue().set(key, "", 5, TimeUnit.MINUTES);
}
return product;
}方案二:布隆过滤器(Redisson实现)
java
@Service
@Slf4j
public class ProductService {
@Autowired
private RedissonClient redissonClient;
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private ProductMapper productMapper;
private RBloomFilter<Long> bloomFilter;
@PostConstruct
public void initBloomFilter() {
// 初始化布隆过滤器:预计元素数量100w,误判率0.01%
bloomFilter = redissonClient.getBloomFilter("product:bloom");
bloomFilter.tryInit(1_000_000L, 0.0001);
// 预热:加载所有商品ID
List<Long> allIds = productMapper.selectAllIds();
allIds.forEach(bloomFilter::add);
log.info("Bloom filter initialized with {} products", allIds.size());
}
public Product getProductWithBloom(Long productId) {
// 1. 布隆过滤器快速判断
if (!bloomFilter.contains(productId)) {
log.debug("Product {} not in bloom filter", productId);
return null; // 一定不存在
}
// 2. 布隆过滤器判断存在,但可能误判,继续查缓存和DB
String key = "product:" + productId;
String json = redisTemplate.opsForValue().get(key);
if (StringUtils.hasText(json)) {
return JSON.parseObject(json, Product.class);
}
Product product = productMapper.selectById(productId);
if (product != null) {
redisTemplate.opsForValue().set(key, JSON.toJSONString(product), 30, TimeUnit.MINUTES);
}
return product;
}
}7.3.2 缓存击穿防护
方案一:分布式锁重建缓存
java
public Product getProductWithLockRebuild(Long productId) {
String cacheKey = "product:" + productId;
String lockKey = "lock:rebuild:" + productId;
// 1. 先查缓存
String json = redisTemplate.opsForValue().get(cacheKey);
if (StringUtils.hasText(json)) {
return JSON.parseObject(json, Product.class);
}
// 2. 缓存miss,尝试获取锁重建
RLock lock = redissonClient.getLock(lockKey);
try {
// 等待最多3秒获取锁
if (lock.tryLock(3, 10, TimeUnit.SECONDS)) {
// 双重检查
json = redisTemplate.opsForValue().get(cacheKey);
if (StringUtils.hasText(json)) {
return JSON.parseObject(json, Product.class);
}
// 查询DB并重建缓存
Product product = productMapper.selectById(productId);
if (product != null) {
redisTemplate.opsForValue().set(cacheKey,
JSON.toJSONString(product), 30, TimeUnit.MINUTES);
}
return product;
} else {
// 获取锁失败,短暂等待后重试
Thread.sleep(100);
return getProductWithLockRebuild(productId);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("Lock interrupted", e);
} finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}方案二:逻辑过期+异步更新
java
@Data
public class CacheData<T> {
private T data;
private long expireTime; // 逻辑过期时间戳
}
public Product getProductWithLogicalExpire(Long productId) {
String cacheKey = "product:" + productId;
String json = redisTemplate.opsForValue().get(cacheKey);
if (!StringUtils.hasText(json)) {
return null; // 需要预热
}
CacheData<Product> cacheData = JSON.parseObject(json,
new TypeReference<CacheData<Product>>(){});
// 未过期,直接返回
if (cacheData.getExpireTime() > System.currentTimeMillis()) {
return cacheData.getData();
}
// 已过期,异步更新
String lockKey = "lock:async:" + productId;
RLock lock = redissonClient.getLock(lockKey);
if (lock.tryLock()) {
// 异步更新缓存
CompletableFuture.runAsync(() -> {
try {
Product product = productMapper.selectById(productId);
CacheData<Product> newData = new CacheData<>();
newData.setData(product);
newData.setExpireTime(System.currentTimeMillis() + 30 * 60 * 1000);
redisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(newData));
} finally {
lock.unlock();
}
});
}
// 返回旧数据(兜底)
return cacheData.getData();
}7.3.3 缓存雪崩防护
随机过期时间
java
private static final Random RANDOM = new Random();
public void setWithRandomExpire(String key, Object value, long baseMinutes) {
// 基础过期时间 + 随机0-10分钟
long randomMinutes = baseMinutes + RANDOM.nextInt(10);
redisTemplate.opsForValue().set(key, JSON.toJSONString(value),
randomMinutes, TimeUnit.MINUTES);
}
// 批量设置时使用
public void batchSetProducts(List<Product> products) {
products.forEach(p -> {
String key = "product:" + p.getId();
setWithRandomExpire(key, p, 30); // 30-40分钟随机过期
});
}八、总结
缓存一致性是分布式系统中的经典难题,没有银弹方案,只有适合业务场景的最佳实践。
方案选择速查表
| 业务场景 | 推荐方案 | 理由 |
|---|---|---|
| 一般业务(如商品详情) | Cache Aside + 过期时间 | 简单可靠,满足最终一致 |
| 高并发写入(如秒杀库存) | 延迟双删 + MQ重试 | 解决极端并发场景 |
| 数据同步(如搜索索引) | Binlog订阅 | 业务零侵入 |
| 金融交易 | 分布式读写锁 | 强一致性保证 |
又是没有大厂约面日子😣😣😣,小编还在找实习的路上,这篇文章是我的笔记汇总整理。
参考文献
- Redis官方文档 - Caching Patterns
- Canal GitHub
- Debezium - Change Data Capture
- 美团技术博客 - 缓存那些事
- AWS Caching Best Practices
- 《Redis设计与实现》- 黄健宏
- 《分布式系统:概念与设计》- George Coulouris
- Redis 7.0 Release Notes