**🔍**本文核心贡献如下:
-
提出YOLO11-4K高效架构:通过引入P2细粒度检测层与轻量级GhostConv主干网络,实现对4K全景图像的端到端实时检测,在保持精度的同时大幅降低计算负担。
-
构建首个4K全景检测基准数据集:手动标注CVIP360数据集,提供6,876帧边界框标注,填补高分辨率全景小目标检测公共数据集的空白。
-
实现显著性能提升:相比基线模型,推理速度提升近75%(28.3ms/帧),检测精度mAP@50达到0.95,在小目标与极端畸变场景中表现优异。
-
验证跨数据集泛化能力:在非全景交通数据集MRTMD上性能优于主流模型,证明架构在高分辨率通用检测任务中的有效性。

博主简介

AI小怪兽 | 计算机视觉布道者 | 视觉检测领域创新者
深耕计算机视觉与深度学习领域,专注于视觉检测前沿技术的探索与突破。长期致力于YOLO系列算法的结构性创新、性能极限优化与工业级落地实践,旨在打通从学术研究到产业应用的最后一公里。
🚀 核心专长与技术创新
-
YOLO算法结构性创新 :于CSDN平台原创发布《YOLOv13魔术师》、《YOLOv12魔术师》等全系列深度专栏。系统性提出并开源了多项原创自研模块 ,在模型轻量化设计、多维度注意力机制融合、特征金字塔重构等关键方向完成了一系列突破性实践,为行业提供了具备高参考价值的技术路径与完整解决方案。
-
技术生态建设与知识传播 :独立运营 "计算机视觉大作战" 公众号(粉丝1.6万),成功构建高质量的技术交流社群。致力于将复杂算法转化为通俗易懂的解读与可复现的工程代码,显著降低了计算机视觉的技术入门门槛。
🏆 行业影响力与商业实践
-
荣获腾讯云年度影响力作者 与创作之星奖项,内容质量与专业性获行业权威平台认证。
-
全网累计拥有 7万+ 垂直领域技术受众,专栏文章总阅读量突破百万,在目标检测领域形成了广泛的学术与工业影响力。
-
具备丰富的企业级项目交付经验,曾为工业视觉检测、智慧城市安防等多个关键领域提供定制化的算法模型与解决方案,驱动业务智能化升级。
💡 未来方向与使命
秉持 "让每一行代码都有温度" 的技术理念,未来将持续聚焦于实时检测、语义分割及工业缺陷检测的商业化闭环等核心方向。愿与业界同仁协同创新,共同推动技术边界,以坚实的技术能力赋能实体经济与行业变革。
原创自研系列, 25年计算机视觉顶会创新点
应用系列篇:
23、24年最火系列,加入24年改进点内涵100+优化改进篇,涨点小能手,助力科研,好评率极高
原理介绍

论文: https://arxiv.org/pdf/2512.16493
摘要 :全方位360°图像的处理因其固有的空间扭曲、宽广视野及超高分辨率输入,为目标检测带来显著挑战。YOLO等传统检测器通常针对标准图像尺寸(如640×640像素)进行优化,面对360°视觉中典型的4K或更高分辨率图像时,常难以应对其计算需求。为解决这些局限,我们提出了YOLO11-4K------一个专为4K全景图像设计的高效实时检测框架。该架构引入了新颖的多尺度检测头,其中包含P2层以提升对在较粗尺度上常被遗漏的小目标的检测敏感性;同时采用基于GhostConv的骨干网络,在保持表征能力的同时降低计算复杂度。为支持评估,我们手工标注了CVIP360数据集,生成了6,876个帧级边界框,并提供了一个公开可用的、专为4K全景场景准备的检测基准。YOLO11-4K实现了0.95的mAP@50,每帧推理耗时28.3毫秒,与YOLO11(112.3毫秒)相比延迟降低了75%,同时提升了准确率(mAP@50 = 0.95 对比 0.908)。这种效率与精度的平衡,使得该框架能够在广阔的360°环境中实现稳健的目标检测,非常适用于现实世界的高分辨率全景应用。尽管本工作聚焦于4K全方位图像,但该方法广泛适用于自主导航、监控和增强现实等领域的高分辨率检测任务。
关键词:YOLO11-4K · 4K全景图像 · 多尺度检测 · 小目标检测 · 高分辨率效率
1 引言
实时目标检测随着单阶段检测器的发展取得了显著进步,尤其是YOLO系列1--11。这些架构在中等分辨率图像(通常在640×640像素左右)上有效地平衡了速度与精度。然而,将这些检测器扩展到超高清分辨率输入(如4K,3840×2160像素)具有挑战性,主要源于巨大的计算成本和较慢的推理速度,这对小目标检测尤为不利。这些挑战在全景视觉系统中更为严峻,因为等距柱状投影会导致几何扭曲以及物体在360°图像中的非均匀缩放。保持原生4K分辨率对于精确检测小而远的物体至关重要,但要实时做到这一点却很困难。
先前的研究,例如Růžička和Franchetti提出的两阶段注意力流水线12,尝试通过使用YOLOv2进行粗到细的推理来解决高分辨率检测问题。他们的方法利用GPU并行性来提高计算效率,在4K视频上实现了3-6 FPS,在8K视频上实现了2 FPS。虽然有效,但这种多阶段策略增加了复杂性,并未针对端到端的实时推理进行优化。为应对这些局限性,我们提出了YOLO11-4K,这是一个专为4K全景图像上的实时性能而设计的全卷积检测框架。我们的贡献包括:
-
端到端4K全景检测:YOLO11-4K直接处理全分辨率图像,无需下采样或裁剪,保留了整个360°视野内用于检测的关键空间信息。
-
手动标注CVIP360数据集:我们生成了6,876个帧级边界框,创建了一个适用于4K全景场景检测的基准,使得对高分辨率小目标检测的严格评估成为可能。该标注数据集已在GitHub上发布。
-
改进的小目标检测:我们在网络早期添加了一个P2检测头(一个在高分辨率特征图上运行的额外早期预测层),以捕获更精细的空间细节,从而改进了标准检测层经常遗漏的小目标的检测。
-
高效计算:通过使用轻量级卷积模块,如用于以更少参数生成特征图的GhostConv、用于高效特征聚合的C3Ghost以及用于降低核复杂度的C3k2,我们在保持强大特征表示和检测精度的同时减少了计算量。
凭借这些改进,YOLO11-4K在现代GPU上实现了每4K帧21.4毫秒的实时推理速度,显著超越了标准YOLO架构,同时保持了检测精度。这项工作为高分辨率360°场景中的小目标检测提供了一个可扩展且实用的解决方案,在自主系统、监控和增强现实等领域具有潜在应用价值。
2 YOLO11-4K架构
YOLO11-4K是Ultralytics YOLO1111框架的专门扩展版本,旨在解决超高分辨率全景图像(3840×3840像素)中实时小目标检测的挑战。由于这类图像的规模以及物体的非均匀空间分布,它们带来了严重的计算和几何复杂性。为克服这些问题,YOLO11-4K整合了多项架构修改,包括用于精细尺度特征提取的P2检测层、用于高效表示学习的轻量级GhostConv和C3Ghost模块,以及端到端的全分辨率处理,以实现对整个360°视场的精确实时检测。
2.1 设计概述
如图1所示,YOLO11-4K架构包含三个关键组成部分:
-
对4K等距柱状全景图输入的显式支持,能够在广阔的360°视野中进行精确检测,同时保留与投影相关的空间畸变。
-
一个基于GhostConv的骨干网络,专为高效、低成本的特征提取而设计。
-
一个四尺度检测头(P2--P5),利用C3k2模块改进对小目标和大型目标的检测。
该架构设计表明,实时处理可以与超高分辨率输入处理同时实现。通过精心选择轻量级卷积模块并战略性地扩展检测头,YOLO11-4K为360°环境中的高分辨率目标检测提供了一个实用且高效的解决方案。
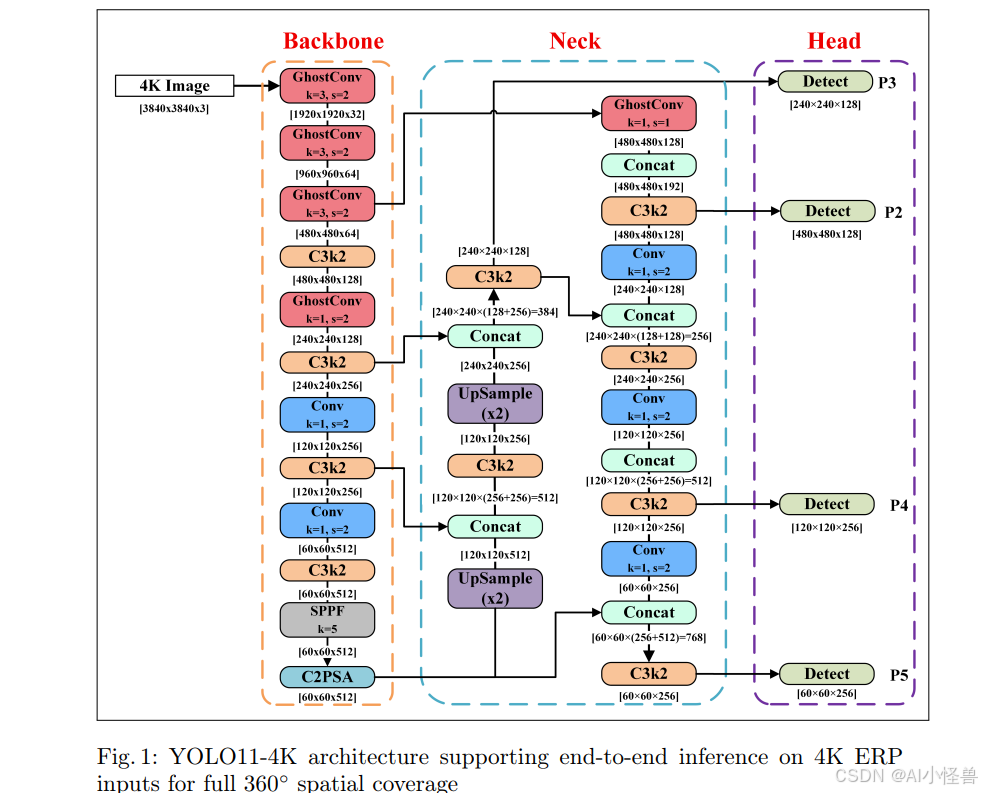
2.2 对高分辨率输入的支持
YOLO11-4K的一个定义性特征是其能够直接处理4K分辨率输入(3840×3840像素),这相较于先前YOLO模型使用的标准640×640分辨率有大幅提升。这种高分辨率处理对于保留精细的空间细节至关重要,特别是对于分布在全景图像360°视野中的小而远的物体。尽管输入分辨率的增加带来了更大的计算需求,但YOLO11-4K通过使用轻量级GhostConv模块和高效的骨干网络设计来抵消这种开销,从而在不牺牲检测精度的情况下实现实时推理。
2.3 轻量级骨干网络
YOLO11-4K的骨干网络旨在从高分辨率全景输入中高效提取层次化特征。为了减轻标准卷积中的冗余,检测器采用了幻影卷积13,它通过使用廉价的线性运算代替昂贵的卷积来生成大量特征图,从而在保持精度的同时减少冗余和计算量。该操作首先应用1×1卷积来捕获本质特征,然后使用低成本的5×5线性变换来推导额外的特征图。这些图被拼接起来形成最终输出,这对于实时处理3840×3840像素图像是一个至关重要的考量。
后续阶段集成了YOLO11架构14的几个核心组件。这些包括C3k2模块(通过将3×3瓶颈卷积替换为2×2内核实现的标准C3块的计算高效变体)、空间金字塔池化-快速(SPPF)模块(通过顺序最大池化以最小开销捕获多尺度上下文),以及C2PSA注意力机制(自适应增强空间和通道维度的特征响应,以提高表征保真度)。
2.4 小目标感知检测头-P2
在原始的YOLO11设计中,检测头通常在P3(细粒度、高分辨率空间细节,适用于小目标)、P4(平衡细节和语义上下文)和P5(编码更抽象、高层特征,适用于较大目标)特征图上运行,这对许多应用来说已足够。然而,它们可能无法捕获极高分辨率图像中小目标检测所需的精细细节。为了克服这一限制,YOLO11-4K引入了一个新的P2检测分支,专门为高分辨率小目标检测设计。该分支直接从骨干网络(接入第1层GhostConv的输出)提取输入尺度1/4处的早期高分辨率特征图,然后通过一系列GhostConv和C3k2模块来细化这些特征。
YOLO11-4K中的检测头通过跨尺度逐步上采样和拼接特征图来执行多尺度融合。从最深的P5特征开始,模型对其进行上采样并与P4特征拼接,然后用C3k2模块细化组合后的输出。重复此过程以融合P3特征,从而实现跨多个尺度的检测。与此并行,新添加的P2分支直接将细化后的高分辨率特征提供给检测层。最后,检测模块聚合来自P2、P3、P4和P5分支的输出,使网络能够以更高的精度同时检测小、中、大型目标。
通过集成GhostConv以提高计算效率、增加P2检测分支以增强小目标敏感性,并扩展到4K输入分辨率,YOLO11-4K在高分辨率全景图像的实时目标检测方面取得了显著进步。该架构在速度和精度之间保持了谨慎的平衡,解决了在广阔视野中进行小目标检测所固有的挑战。
3 实施
YOLO11-4K架构是通过使用PyTorch深度学习库扩展Ultralytics YOLOv11框架来实现的。训练在高分辨率全景图像数据集上进行,利用混合精度训练来加速收敛并减少GPU内存消耗。我们采用了优化的训练计划和数据增强技术,以在检测精度和推理速度之间取得平衡。以下小节详细描述了训练设置、数据集和实施细节。
3.1 训练配置
YOLO11-4K使用Ultralytics训练流水线进行训练,并采用了为4K分辨率输入定制的配置。训练过程运行了50个周期,输入图像大小为3840×3840像素,并启用了自动混合精度训练(amp=True),该技术在大多数操作中使用16位计算,同时在必要时保留32位精度,以减少GPU内存使用并加速训练。为防止过拟合,实施了提前停止策略,耐心值为10个周期。由于处理高分辨率图像需要大量内存,批次大小被限制为1。
训练在澳大利亚国家计算基础设施(NCI)的Gadi超级计算机上进行,使用了gpuvolta队列,该队列提供访问配备双NVIDIA Volta GPU的节点。这种双GPU配置被用来实现高效的并行处理,从而提高了训练吞吐量并减少了收敛时间。
训练流水线使用了Ultralytics内置的超参数调优机制,选择了AdamW优化器,学习率为0.001667,β1 = 0.9,β2 = 0.999。该优化器对不同参数组应用差异化的权重衰减:大部分权重为0.0005,其他参数(包括偏置)为0.0。由于是双GPU设置,梯度累积(一种在多次小批次计算梯度后再更新权重的技术,可在内存有限时有效模拟更大的批次大小)被禁用。梯度同步由Ultralytics框架中的数据并行训练逻辑自动处理。尽管每个GPU的批次较小,但此配置结合AdamW和适当的学习率调度,成功实现了收敛,同时保持了在高分辨率输入上的泛化能力。
3.2 数据集
为了在高分辨率全景场景上训练和评估YOLO11-4K模型,我们使用了CVIP360数据集15。该数据集专为360°视觉应用设计,包含使用Garmin VIRB 360相机捕获的多样化高分辨率等距柱状投影(ERP)图像集合,涵盖室内和室外场景。尽管最初发布时带有深度估计标注,但CVIP360缺少目标检测所需的边界框标签。为克服这一限制,我们使用Roboflow17平台重新标注了该数据集,将CVIP360扩展为一个可用于检测的基准,使得在360°环境中训练和评估小目标检测器成为可能。
如图2所示,数据集中的所有图像均以4K分辨率提供,这使其特别适用于宽视野(FoV)条件下的小目标检测和评估 。该数据集主要关注360°视频帧内的行人检测。由于该数据集最初是为深度估计设计的,它为每个视频序列提供了一个单一的标注文件。为了便于逐帧检测任务,使用Roboflow平台对数据集进行了手动重新标注,总共产生了6,876张标注图像。这些可直接用于检测的标注已在GitHub上公开提供:https://github.com/huma-96/CVIP360_BBox_Annotations。为确保鲁棒性并减轻因数据集划分导致的偏差,我们采用了五折交叉验证策略。整个数据集被随机分为五个大小相等的折。在每次迭代中,四折用于训练和验证(其中这四折的80%用于训练,20%用于验证),而剩余的一折作为独立的测试集。最终的性能指标通过平均五个模型的成绩得出。

由于ERP图像中存在几何畸变,CVIP360数据集为评估模型在非平面表示中的鲁棒性提供了一个具有挑战性的基准。物体在360°FoV中的空间分布和尺度变化与本工作的目标非常契合,即旨在增强全景视觉环境中的检测性能,特别是对于小而远的物体。
跨数据集评估 为了评估在非全景图像之外的跨数据集泛化能力,我们还在2160p分辨率下使用多分辨率交通监控数据集(MRTMD)19对所有模型进行了额外评估。MRTMD是一个多类别交通数据集,包含自行车、汽车、摩托车和公共汽车等类别;其特点是场景密集、尺度变化极端以及包含许多超小远距离目标。我们使用与CVIP360相同的评估流水线(检测阈值和IoU设置)以确保可比性。
3.3 评估指标
为了全面评估YOLO11-4K的检测性能,我们采用了基准评估中使用的标准目标检测指标,特别关注实时处理要求和小目标检测精度。
平均精度均值(mAP):mAP是目标检测的标准度量,通过计算所有类别的精确率-召回率性能(AP)的平均值得到,其中AP对应于每个类别的精确率-召回率曲线下的面积。为了全面评估检测精度,我们同时报告mAP@0.50和mAP@0.50:0.95。mAP@0.50分数捕获了在中等交并比(IoU)阈值下的性能,表明模型检测和分类IoU至少为50%的物体的能力。相比之下,mAP@0.50:0.95提供了在十个IoU阈值(从0.50到0.95,增量为0.05)上的平均分数,对模型的定位精度和整体鲁棒性提供了更严格和更详细的评估。
精确率与召回率:我们计算在验证集和测试集上的精确率和召回率,以评估模型正确识别真正例的能力,同时最小化假正例和假负例。这些指标对于小目标检测尤为重要,因为在小目标检测中类别不平衡和定位模糊更常见。精确率(P)和召回率(R)定义如下:
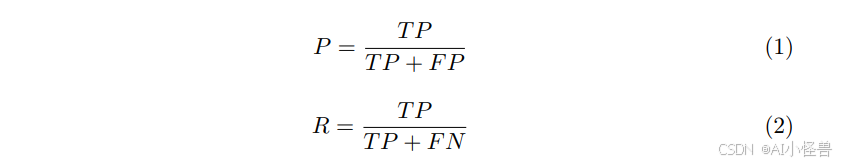
其中,TP、FP和FN分别表示真正例、假正例和假负例。
推理速度(FPS):实时性能对于高分辨率全景应用至关重要。我们使用双NVIDIA Volta GPU和4K(3840×3840)分辨率输入,以每秒帧数(FPS)来测量YOLO11-4K的推理速度。该指标评估了在时间敏感场景中部署模型的实用性。
通过结合定位精度、实时吞吐量和尺度敏感评估,这一多指标框架能够在高分辨率全景图像所带来的挑战性条件下,对模型性能进行严格而全面的评估。
4 结果与讨论
本节详细分析了YOLO11-4K在CVIP360数据集上的性能,比较了其在小目标检测方面的检测精度、速度和鲁棒性。我们还讨论了架构选择------特别是使用GhostConv、包含P2检测头以及采用高分辨率输入------如何促成了所观察到的改进。表1总结了YOLO11-4K、YOLO11以及一些更早版本的YOLO在CVIP360数据集的验证集和测试集分割上的性能。YOLO11-4K在精确率、召回率和mAP@50方面取得了最高的综合性能,同时在所有评估模型中提供了最快的推理速度。
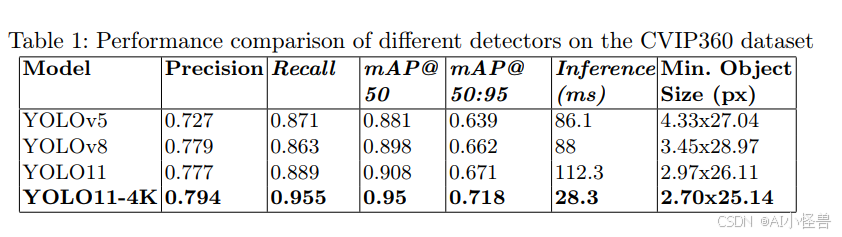
YOLO11-4K的一个关键优势是其推理效率。在处理3840×3840高分辨率全景图像时,其每张图像的推理时间为21.4毫秒,几乎是YOLO11的五倍快。这种速度提升很大程度上归功于混合骨干网络设计,该设计在浅层阶段结合了GhostConv层,在深层阶段使用了标准卷积,并进行了卷积核-步长参数调优,从而高效地平衡了计算成本与表征能力。
图3展示了YOLO11-4K在室内和室外4K全景场景上的定性检测结果。该模型能有效地在整个360°视野中检测小、中型及部分被遮挡的物体。在整个测试集中,总共检测到1,604个物体,平均物体尺寸为28.9 × 133.2像素。检测到的最小物体尺寸为2.7 × 25.1像素,最大物体尺寸为126.5 × 319.8像素。

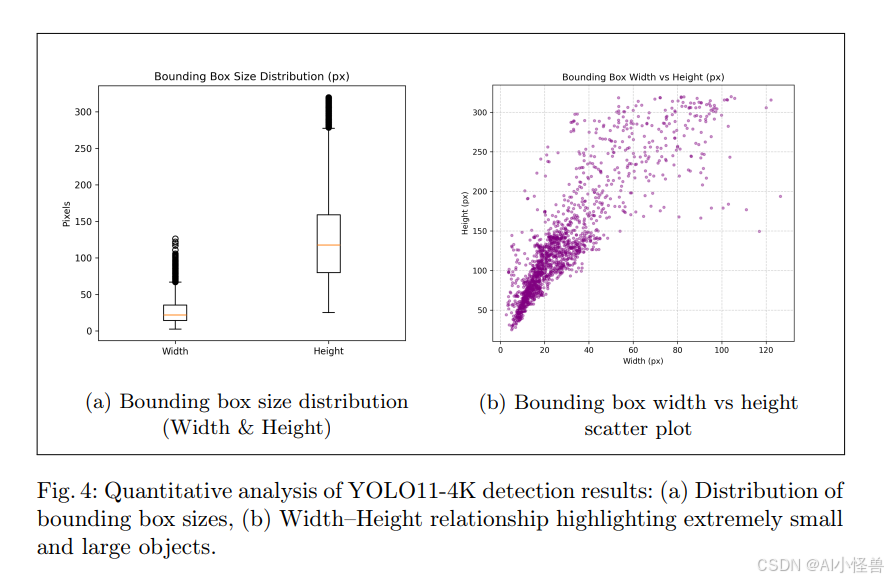
我们进一步分析了检测物体在整个测试集中的分布情况。图4展示了YOLO11-4K的边界框统计信息。图4(a)显示了一个总结检测物体整体尺寸变异性的箱线图,突出了非常小物体的普遍存在;而图4(b)展示了边界框宽度与高度的散点图,证明YOLO11-4K能成功检测极其微小的物体(小至2.7 × 25.14像素)。在整个测试集中,总共检测到1,604个物体,平均尺寸为28.9 × 133.2像素,这证实了模型在高分辨率4K全景图像中进行小目标检测的强大能力,并补充了关于遮挡和极微小物体检测的定性示例。
YOLO11-4K为实时4K全方位目标检测树立了新的技术水平,超越了先前的YOLO变体和其他轻量级架构。总体而言,它为实时360°检测提供了一个实用、高吞吐量的解决方案,能有效捕获小尺度目标而不影响推理速度。
4.1 跨数据集泛化
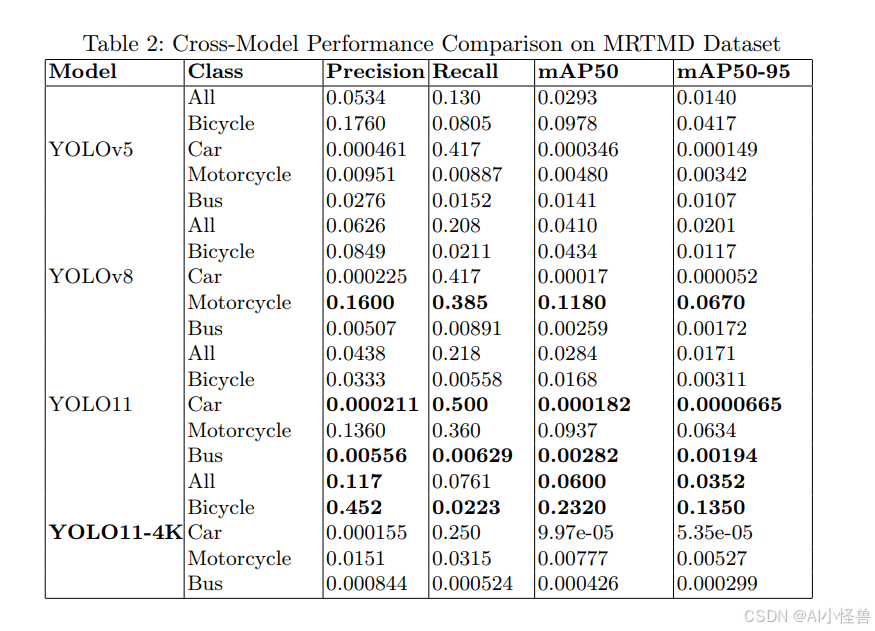
为了评估跨数据集泛化能力,YOLO11-4K在4K多分辨率交通监控数据集(MRTMD)19上进行了测试。该数据集包含具有显著尺度变化和许多超小目标的多类别交通场景。与CVIP360中的360°等距柱状图像不同,MRTMD由标准平面图像组成,这构成了一个具有挑战性的领域偏移。尽管如此,YOLO11-4K中的架构增强,特别是P2检测头和混合GhostConv/Conv骨干网络,旨在保留精细的空间细节,预计即使在非全方位设置下也有利于小目标检测。所有MRTMD评估均使用原生4K分辨率,并采用与CVIP360相同的阈值和IoU标准。
表2展示了YOLOv5、YOLOv8、YOLO11和YOLO11-4K在具有挑战性的MRTMD数据集上的跨模型性能。总体而言,由于训练数据有限、尺度变化极端、物体排列密集以及超小远距离物体普遍存在,所有模型的绝对mAP值都较低。尽管面临这些挑战,YOLO11-4K始终优于基线模型,突显了其架构创新的有效性。特别是,该模型在主要由小且远距离目标组成的自行车类别上取得了0.232的mAP,证明了P2检测头和混合GhostConv/Conv骨干网络在保留细粒度空间特征方面的优势。虽然像汽车这类稀有类别的性能由于样本有限而表现出高方差,但总体趋势证实YOLO11-4K能够泛化到360°全景图像之外,并改善标准高分辨率场景中的小目标检测,保持了精度与推理效率之间的平衡。
5 消融研究
为了理解YOLO11-4K中每个架构组件的贡献,我们使用3840×3840分辨率输入进行了系统的消融实验。每个消融配置均在五折交叉验证协议下进行评估,结果取各折平均值以减少方差并更好地反映模型稳定性,结果亦在表3中呈现。基线模型YOLO11s实现了0.908的mAP@50和112.3毫秒的推理时间。
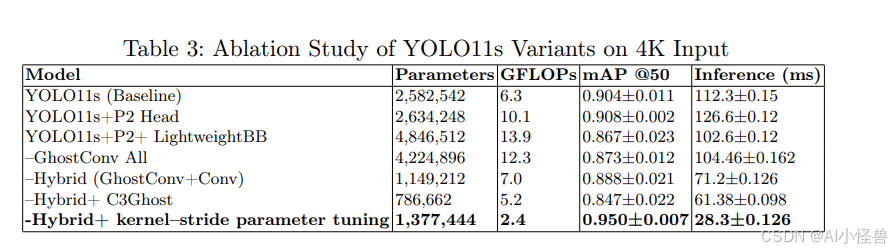
在YOLO11基线中引入P2检测头,通过使模型能够更好地从早期层捕获细粒度特征,带来了轻微的检测精度提升。这种增强是以参数和延迟适度增加为代价的。
接下来,我们测试了一个名为 lightweightBB(轻量级骨干网络)的变体,其中标准骨干网络被一个计算优化的架构所取代。该轻量级骨干网络通过使用跨步卷积进行逐步空间下采样、在早期层使用通道数更少的紧凑型C3k2模块以及尽可能使用1×1卷积压缩特征图来降低复杂性。虽然此配置将推理时间减少到102.6毫秒,但也导致精度下降(mAP@50: 0.867),表明了速度与精度之间的权衡。
将所有标准卷积替换为GhostConv模块带来了进一步的效率提升,减少了参数数量和计算负载,同时保持了0.873的相近mAP@50,尽管推理时间略微放缓至104.46毫秒。推理时间增加是因为GhostConv操作对GPU并行化的优化程度较低,导致了额外的内核启动和内存开销。虽然GhostConv减少了FLOPs,但其碎片化操作相比标准卷积层会减慢执行速度,因此选择性使用GhostConv有助于恢复速度效率。
我们还探索了一个混合模型,该模型在浅层融合GhostConv,在深层使用标准卷积。这种设置在精度和速度之间提供了更好的平衡之一,实现了0.888的mAP@50,推理时间仅为71.2毫秒。混合模型相比全GhostConv模型速度提升,可归因于不同卷积类型在网络深度上的计算效率差异。GhostConv在具有大型特征图的早期浅层中特别有效,能最小化冗余和计算。相反,空间维度较小但通道数较多的深层可能因GhostConv的线性操作和拼接步骤而产生开销,从而降低其效率。通过在这些深层使用标准卷积,混合模型获得了更快的推理速度。该策略利用了GhostConv在初始层的高效性和标准卷积在网络更深层的速度优势,从而在精度和性能之间取得了更有利的平衡。
同时使用GhostConv和C3Ghost(YOLO C3模块的轻量级版本,用Ghost卷积替换标准卷积以减少计算量和模型大小,同时保持相似的精度)16模块的紧凑版本实现了最少的参数量(786K)和快速的推理(61.38毫秒)。然而,它也记录了最低的mAP@50(0.847),表明在追求极致效率时存在显著的权衡。
最后,经过卷积核-步长参数调优(调整卷积核大小和步长以减少特征图维度并提高效率)的混合模型在精度和速度之间取得了良好的平衡。与基线YOLO11s(258万参数,6.3 GFLOPs,0.917 mAP@50,112.3毫秒推理时间)相比,该变体仅需138万参数和2.4 GFLOPs,却实现了最高的0.95 mAP@50。此外,其推理时间仅为28.3毫秒,远快于基线,这表明仔细的卷积核-步长调整可以显著减少计算量,同时提升检测性能。
总体而言,这些实验展示了每次修改如何影响速度-精度权衡,从而指导为全景图像中的高分辨率小目标检测设计高效模型。虽然YOLO11-4K普遍适用于高分辨率图像,但它特别针对全景360°图像进行了微调,增强了对等距柱状投影固有的空间畸变、宽视野和非均匀缩放的鲁棒性。这种微调提高了全景图像中常见的小型和扭曲物体的检测精度。
6 结论
在这项工作中,我们提出了YOLO11-4K,一个专为高分辨率4K全景图像设计的实时检测框架。通过集成轻量级GhostConv骨干网络和专用的P2检测层,该模型提高了小目标敏感性,同时显著降低了计算成本。在CVIP360数据集上的实验表明,YOLO11-4K实现了显著的速度提升,将推理时间减少了近75%,同时保持了强大的检测性能,为360°环境展示了精度与效率之间的有效平衡------由于极端畸变和高分辨率处理的需求,这些环境仍然特别具有挑战性。结果进一步表明模型在不同全景场景中具有良好的泛化能力。虽然本研究聚焦于4K输入,但此处介绍的架构原理广泛适用于其他高分辨率领域,包括自主导航、大规模监控和沉浸式AR/VR系统。未来的工作将探索自适应球面表示以及与多目标跟踪流水线的集成,以实现完整的实时360°感知。
7 局限性与未来工作
本研究的一个主要局限性是缺乏大规模的、公开可用的标注4K全方位数据集。据我们所知,CVIP360仍然是唯一提供适用于小目标检测的、带有边界框标注的原生4K分辨率数据集。虽然这项工作建立了坚实的基线,并在CVIP360上展示了所提出的YOLO11-4K架构的优势,但在更多高分辨率数据集上进行进一步验证将增强其泛化能力的主张。作为未来工作的一部分,我们计划:(i)将实验扩展到合成或半自动标注的4K全景图,以扩大评估覆盖范围;以及(ii)探索跨分辨率策略,包括从低分辨率全景数据集(例如1080p, 2K)进行领域自适应,以及扩展到4K的尺度分析,以量化鲁棒性。应对这些挑战将有助于为超高分辨率全方位图像中的实时小目标检测建立一个全面的基准。尽管YOLO11-4K在MRTMD上表现出改进的小目标敏感性,但由于极端尺度变化,其绝对性能仍然较低,这凸显了对高分辨率多类别基准的需求。