一、写在前面:为什么我们需要 Catlass?
做过昇腾 Ascend C 算子开发的同学都知道,虽然 Ascend C 相比原本的 TIK 已经极大地降低了门槛,但如果你想写一个高性能的 GEMM(通用矩阵乘法)算子,依然是一场"修行"。你需要手动管理 Global Memory 到 Local Memory 的搬运,需要设计流水线(Pipeline)来掩盖访存延迟,需要精细控制 Cube Core 的指令发射...说实话,这不仅容易掉头发,而且很容易写出"能跑但慢"的代码。
在 NVIDIA 的生态里,有一个大名鼎鼎的 CUTLASS 库,它用 C++ 模板元编程技术,把高性能线性代数的通用模式封装了起来。开发者只需要像搭积木一样组合模板参数,就能生成接近 cuBLAS 性能的算子。好消息是,昇腾社区终于也有了自己的"CUTLASS"------它就是 Catlass。
最近在研究这个开源仓(https://gitcode.com/cann/catlass),发现它不仅是名字致敬,设计理念上也确实贯彻了"模板化高性能计算"的精髓。作为该系列文章的第一篇,我们不谈太具体的API细节,而是通过剖析源码,把 Catlass 的编程范式(Programming Paradigm) 扒得干干净净。读完这篇,你就不再是看天书,而是看设计图。
二、分层模型:任务划分 - 缓存策略 - 指令发射
Catlass 的代码初看非常吓人,满屏的 template <...>。但如果你把 AI 的思维先放一放,用纯粹的 C++ 架构视角去看,你会发现它其实就做了一件事:分层(Hierarchy)。
Catlass 在昇腾架构下的抽象层级并非简单的 NVIDIA 搬迁,它实际上是围绕 "任务划分 - 缓存策略 - 指令发射" 来构建的。我们需要修正对层级的认知:
- Device Level (Global级): 逻辑上的完整矩阵,对应 Global Memory 上的全局数据。
- Threadblock Level (核级/Block级): 这是 AI Core 的处理单位。一个 Threadblock 对应一个
block_idx,负责将数据从 GM 搬运到 L1/L0。 - Warp Level (指令分发级): 这里的 "Warp" 在 Catlass 语境下更多指代 指令执行的并发粒度 。它决定了数据如何从 L1 进一步拆分进入 L0A/L0B,并最终驱动 Cube Unit 执行具体的16×16×16矩阵乘指令。
下图展示了 Catlass 是如何通过模板将这些层级串联起来的。
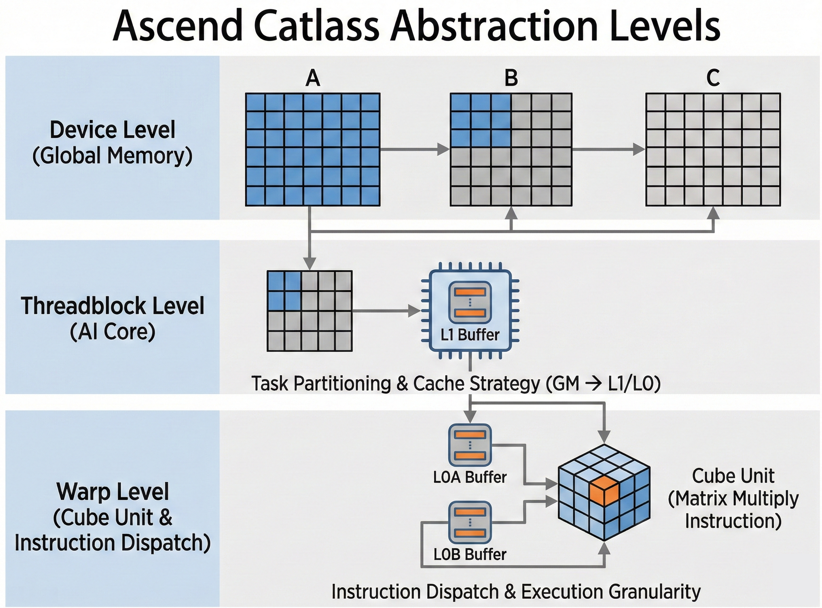
关键: Catlass 的编程范式,就是让你去声明 这些层级,而不是去手写循环。
三、Catlass 算子结构拆解
一个典型的 Catlass GEMM 算子,在代码层面通常由以下几个核心组件构成。我们在阅读源码时,只要抓住这几根"大腿",就不会迷路。
3.1 核心组件三巨头
GemmKernel:这是总指挥。它定义了整个算子的入口。它通常接受三个主要的模板参数:Mma(负责乘加运算)、Epilogue(负责结果处理,如加上偏置、激活函数)、ThreadblockSwizzle(负责如何把大矩阵切块分给不同的核)。Mma (Matrix Multiply Accumulate):这是劳模。它是计算密集度最高的部分。在 Catlass 中,Mma 被设计为一个流水线对象。它负责把数据从 Global Memory (GM) 拉到 Local Memory (L1/L0),并喂给 Cube Unit。Epilogue:这是收尾工。当 Mma 算完一个 Tile 的结果(存在 L0C 或 Unified Buffer 中)后,Epilogue 负责把它读出来,进行 Element-wise 的操作(比如 ReLU, Sigmoid),然后写回 GM。
3.2 迭代器范式 (Iterator Paradigm)
这是 Catlass 最精彩的地方。在传统的 Ascend C 写法里,我们需要手动计算偏移量:offset = block_idx * block_size + ...。
在 Catlass 中,一切皆为迭代器。
- PredicatedTileIterator:这是用来从 GM 读取数据的迭代器。你只需要告诉它:"我要读 A 矩阵,当前在第 k 步",它会自动处理边界检查(Predication)和地址偏移。
- Fragment:这是寄存器或局部内存的抽象。我们不直接操作指针,而是操作 Fragment。
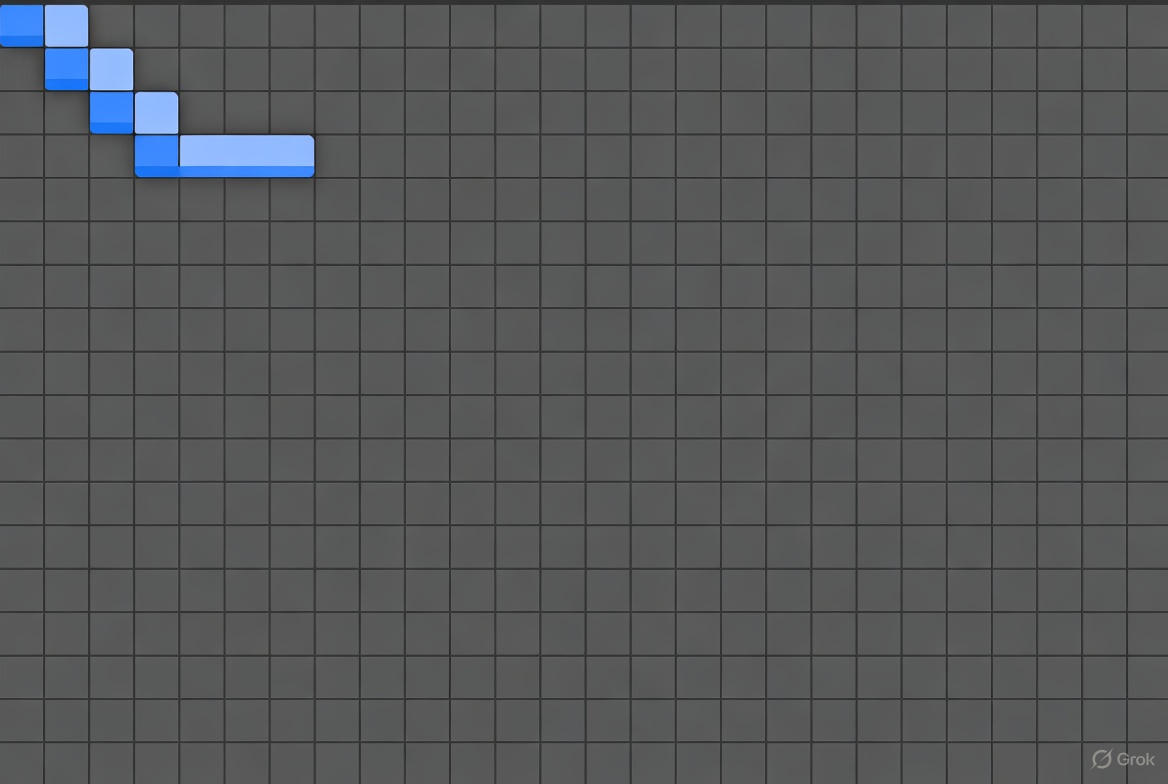
以上为一张迭代器移动 的示意图,如果你把它想象成一张动态 GIF 或多帧静态图,那它应该是一个 128*128的蓝色方块在巨大的灰色矩阵上滑动的过程。随着 iterator++ 操作,橙色框向右移动,自动加载下一块数据到 L1 Buffer。这完全屏蔽了底层的 DataCopy API 调用细节。
四、深入代码:一个"Hello Catlass"的诞生
为了演示这个范式,我们来看一段伪代码(经过简化,去除了冗余的模板参数,保留核心逻辑),展示如何用 Catlass 定义一个 FP16 的 GEMM 算子。
4.1 定义形状与策略
首先,我们不写函数,我们定义类型:
cpp
// 1. 定义基本的形状配置
using ShapeMMAThreadBlock = GemmShape<128, 128, 64>; // 一个AI Core处理的大小
using ShapeMMAWarp = GemmShape<64, 64, 64>; // 一个Warp处理的大小
using ShapeMMAOp = GemmShape<16, 16, 16>; // 基础指令处理的大小
// 2. 定义流水线策略 (Pipeline Strategy)
// Stage=2 意味着开启 Double Buffering (双缓冲),这是高性能的关键!
using MmaPolicy = MmaPolicy<
Operator::Gemm,
ShapeMMAThreadBlock,
ShapeMMAWarp,
2 // Pipeline Stages
>;4.2 组装 Kernel
接下来,像拼乐高一样组装 Kernel:
cpp
// 3. 定义 MMA 组件
using Mma = typename Mma<
ElementA, LayoutA, // A矩阵数据类型和排布(RowMajor/ColMajor)
ElementB, LayoutB, // B矩阵
ElementC, LayoutC, // C矩阵
MmaPolicy
>::Type;
// 4. 定义 Epilogue 组件 (此处使用默认的线性输出)
using Epilogue = typename DefaultEpilogue<...>::Type;
// 5. 最终组装 GemmKernel
using GemmKernel = Gemm<Mma, Epilogue>;4.3 运行逻辑(设备端)
在设备端的 operator() 中,Catlass 的范式展现得淋漓尽致:
cpp
template <typename GemmKernel>
__aicore__ void gemm_device(typename GemmKernel::Params params) {
// 1. 构造主循环对象 (Mma)
typename GemmKernel::Mma mma(params.mma, ...);
// 2. 构造尾处理对象 (Epilogue)
typename GemmKernel::Epilogue epilogue(params.epilogue, ...);
// 3. 执行核心计算:这里没有显式的搬运代码!
// mma 对象内部封装了 Pipeline,会自动进行 Ping-Pong 搬运和计算
mma(gemm_k_iterations);
// 4. 执行尾处理并写回
epilogue(mma.accumulators);
}大家看懂了吗? 用户代码里几乎看不到 DataCopy、SetFlag、WaitFlag 这些底层的同步指令。这些最容易出错的流水线同步逻辑,全部被封装在 mma() 的调用内部了。这就是++基于++ ++策略++ ++(Policy-based)的设计++。
五、难点解析:流水线编排 (Pipeline Orchestration)
如果只是简单的封装,那 Catlass 也就是个语法糖。它真正的威力在于对 Ascend 硬件流水线的极致压榨。在 Ascend 架构中,计算单元(Cube)和存储单元(MTE2, MTE3)是可以并行工作的。Catlass 的模板库默认实现了 Double Buffering (Ping-Pong) 甚至 Multi-Stage 机制。
我们来看下 Catlass 内部是如何通过模板展开来实现流水线的。下图展示了 Catlass 内部生成的流水线时序(简化版):
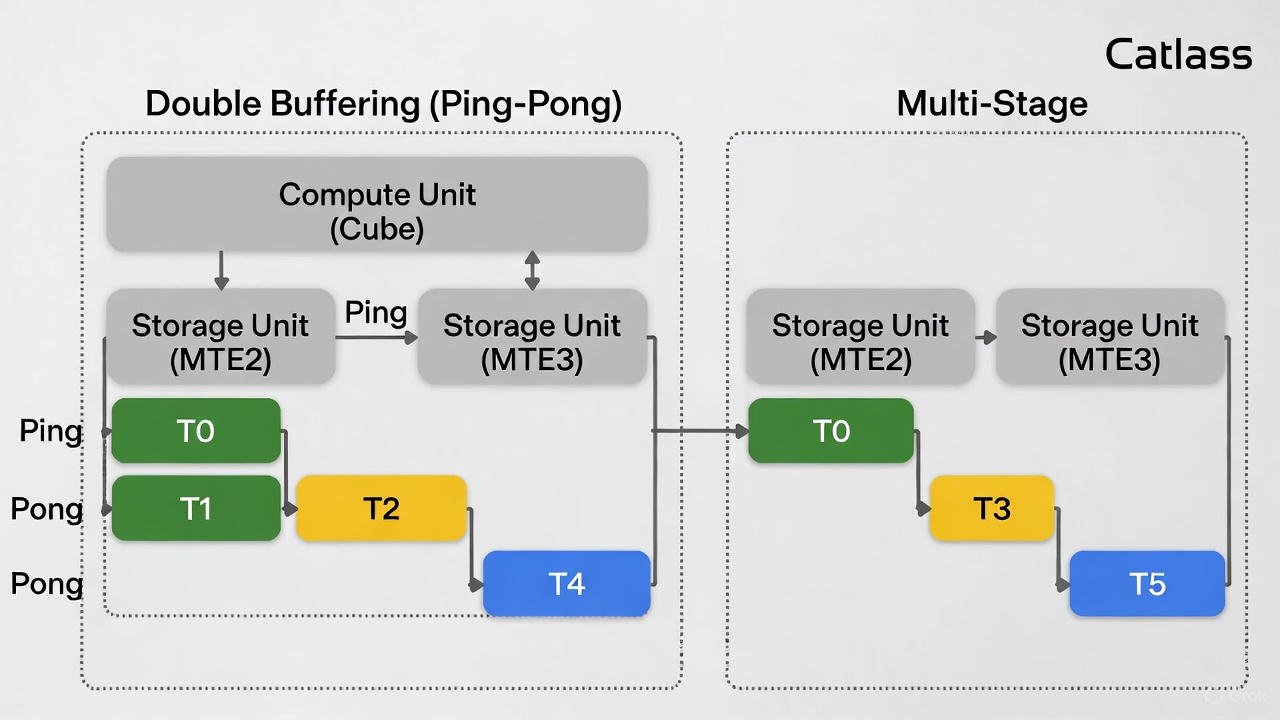
Catlass 的 MmaPolicy 不仅决定了 Ping-Pong 的次数,更通过模板元编程在编译期计算好了 L1 缓冲区地址的偏移量 。这意味着你定义的 ShapeMMAThreadBlock 会自动被映射为物理上的地址分段,避免了开发者手动计算地址偏移导致的内存越界。
在 Catlass 的编程范式中,你不需要手动写 Wait 和 Set。你只需要在定义 MmaPolicy 时,指定 Stage 的数量,具体示例如下:
Stage = 2:Catlass 会自动分配两块 Local Memory,通过模板特化生成 Ping-Pong 的代码。Stage = 3+:如果片上内存足够,它甚至能生成更深度的预取逻辑。
这就是声明式编程带来的红利。你告诉库"我要两级流水",库就给你生成两级流水的代码,而不是你去写每一行同步指令。
六、调试与可视化
光说不练假把式。使用了 Catlass 模板后,我们怎么确认性能达标了?
这里我展示一下基于 Ascend Insight (或是 MSP Profiler) 的性能分析结果。
6.1 结果验证
首先是正确性。Catlass 通常带有 Host 端的 Reference 实现。我们在 CPU 上跑一个标准的矩阵乘,然后对比 NPU 的输出。下图为黑色背景的终端窗口 ,显示 Check Success! Max Diff: 0.00012。这是跑完 Catlass 自带的 UT(单元测试)后的标准输出。
6.2 性能可视化 (Profiling)
这才是重头戏。当我们编译并运行基于 Catlass 的算子后,使用 Profiling 工具抓取 Timeline。下图为MSP Profiler 的 Timeline 视图截图。
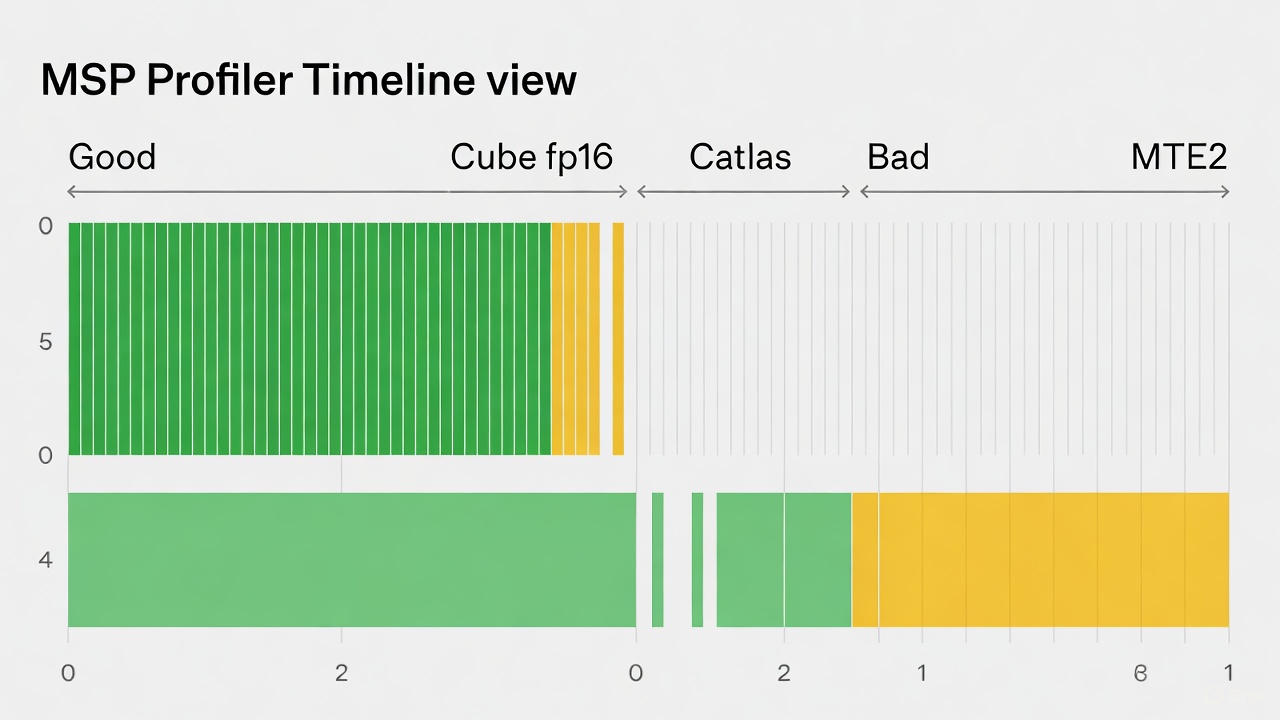
实际上,你会看到非常密集的 Cube fp16 绿色条块(代表计算),以及与之重叠的 MTE2 黄色条块(代表搬运)。
- 好的 Catlass 算子:计算条块之间几乎没有空隙(Gap),且搬运条块被计算条块完美覆盖(Hiding)。
- 坏的实现:你会看到"计算-搬运-计算-搬运"的串行模式,中间有大量的空白。
如果您在使用 Catlass 时发现 Timeline 上有大量空白,通常要检查 ShapeMMAThreadBlock 是否设置过小,导致计算密度不足以掩盖搬运延迟。
七、结语
7.1 避坑指南
在研究 Catlass 的过程中,我也踩了不少坑,这里总结三点作为"范式"之外的经验补充:
- 对齐是生命线 :Catlass 极其依赖向量化指令。你的输入矩阵维度(M, N, K)如果不能被
16或32整除,模板实例化可能会失败,或者自动退化到 Padding 模式,性能大打折扣。务必在 Host 端做好 Padding。 - L1 内存溢出 :模板参数里的
ShapeMMAThreadBlock决定了 L1 缓冲区的大小。如果你贪心设得太大(比如256x256),加上 Double Buffering,很容易超过 Ascend 芯片的 L1 上限,导致编译报错或运行时错误。 - 模板报错看不懂 :这是 C++ 模板元编程的通病。一旦出错,编译器会吐出几千行的错误信息。技巧 :先看第一行和最后一行。通常是因为传入的
Layout类型不匹配(比如把 RowMajor 传给了 ColMajor 的模板)。
7.2 总结与展望
Catlass 的出现,标志着昇腾算子开发进入了工业化、标准化的新阶段。我们今天探讨的编程范式,核心在于:利用 C++ 的类型系统来描述算子的物理结构和执行策略。我们不再写循环,而是定义 Iterator;我们不再写同步,而是定义 Pipeline Policy;我们不再写指令,而是定义 Mma Operation。这种范式虽然上手有一定门槛(需要懂一些 C++ 模板),但一旦掌握,你就能以极高的效率开发出媲美官方算子库的高性能 Kernel。
那么,光会用现有模板还不够,如果你有一个奇葩的算子(比如带特殊激活函数的 GEMM,或者稀疏矩阵乘)怎么办?接下来,我们可以尝试深入 Catlass 模板库自定义算子开发,学习如何继承并修改 Catlass 的核心组件,打造你的专属算子。
注明:昇腾PAE案例库对本文写作亦有帮助。