A Survey on Data Synthesis and Augmentation for Large Language Models(大型语言模型的数据合成与增强综述)
1. 作者

2. 年份
2024
零、摘要
大型语言模型(LLM)的成功与否,本质上与用于训练和评估的海量、多样化和高质量数据的可用性息息相关。然而,高质量数据的增长速度明显落后于训练数据集的扩展速度,从而导致迫在眉睫的数据耗尽危机。这突显了提高数据效率和探索新数据来源的迫切需求。在此背景下,合成数据已成为一种有前景的解决方案。目前,数据生成主要包括两种主要方法:数据增强和合成。本文全面回顾并总结了LLM生命周期中的数据生成技术,包括数据准备、预训练、微调、指令调整、偏好对齐和应用。此外,我们还讨论了这些方法目前面临的限制,并探讨了未来发展和研究的潜在途径。我们的愿望是使研究人员清楚地了解这些方法,使他们能够在构建LLM时迅速确定适当的数据生成策略,同时为未来的探索提供有价值的见解。
一、介绍
-
近年来,LLM在许多行业取得了巨大的进步。但是大模型的性能高度依赖它们接受训练的数据的质量和数量。
-
大模型对训练数据集的需求增长速度远高于数据增长的速度,最后可用数据会被用尽,导致LLM无法继续进步。因此,数据合成与数据扩充技术对于LLM的发展是至关重要的。
-
该领域在时间上和位置上的趋势
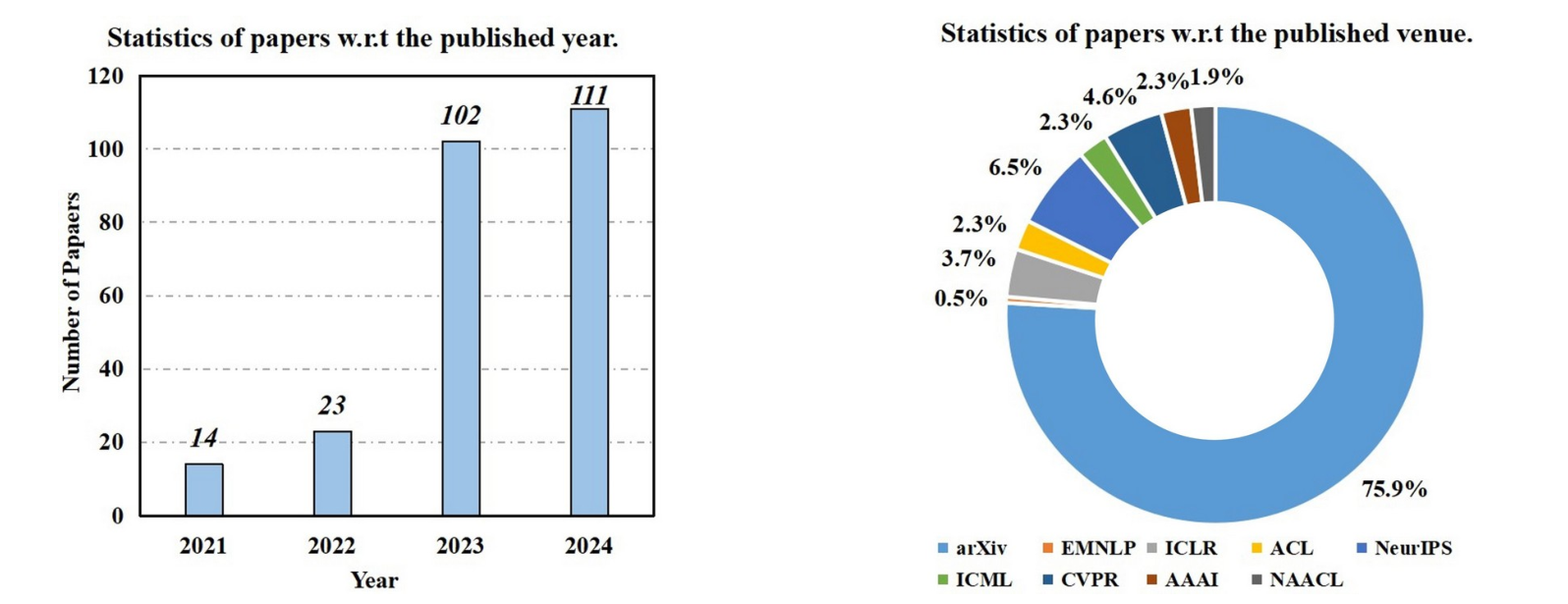
- 以前的调查主要侧重于应用这些方法来支持特定的下游任务或 LLM 的特定阶段,我们的工作强调面向 LLM 的技术在提高 LLM 在其生命周期和核心功能的各个阶段的整体性能方面的直接作用。
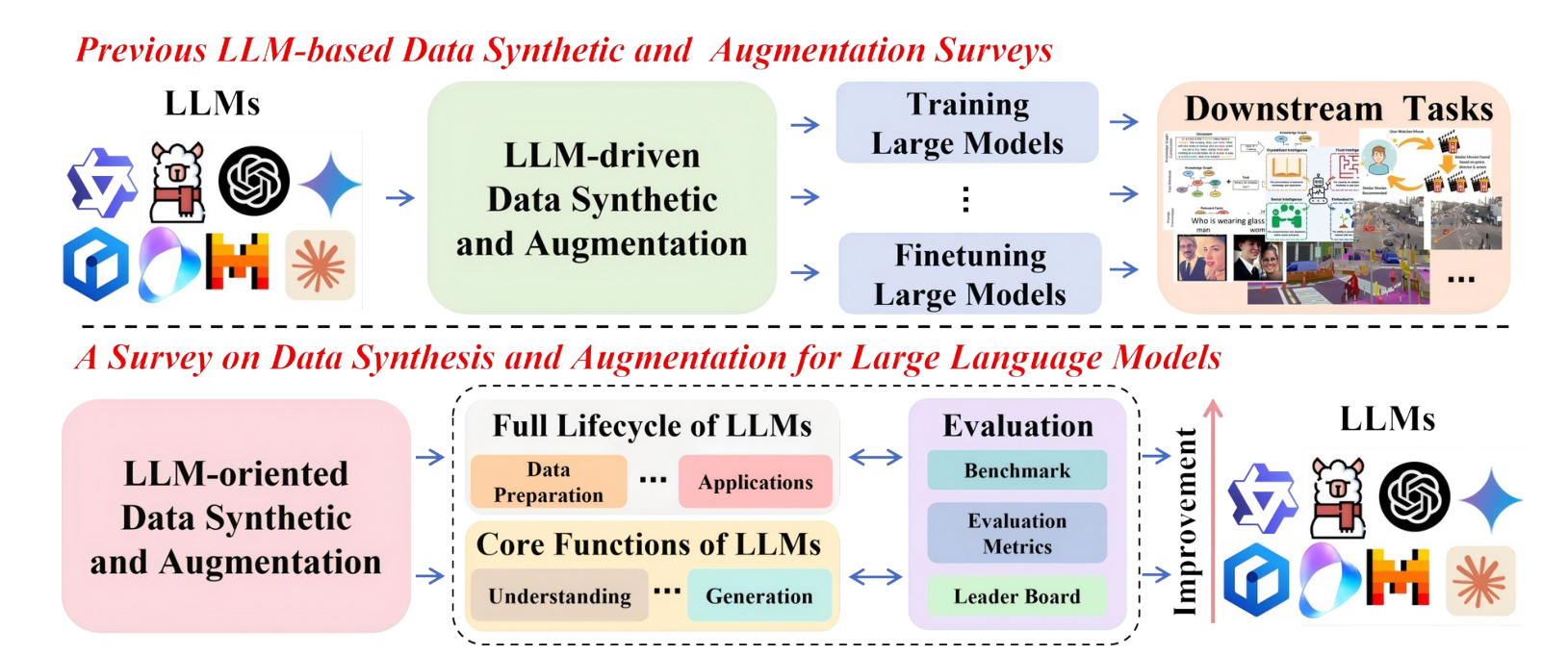
- 本综述的主要内容和分类

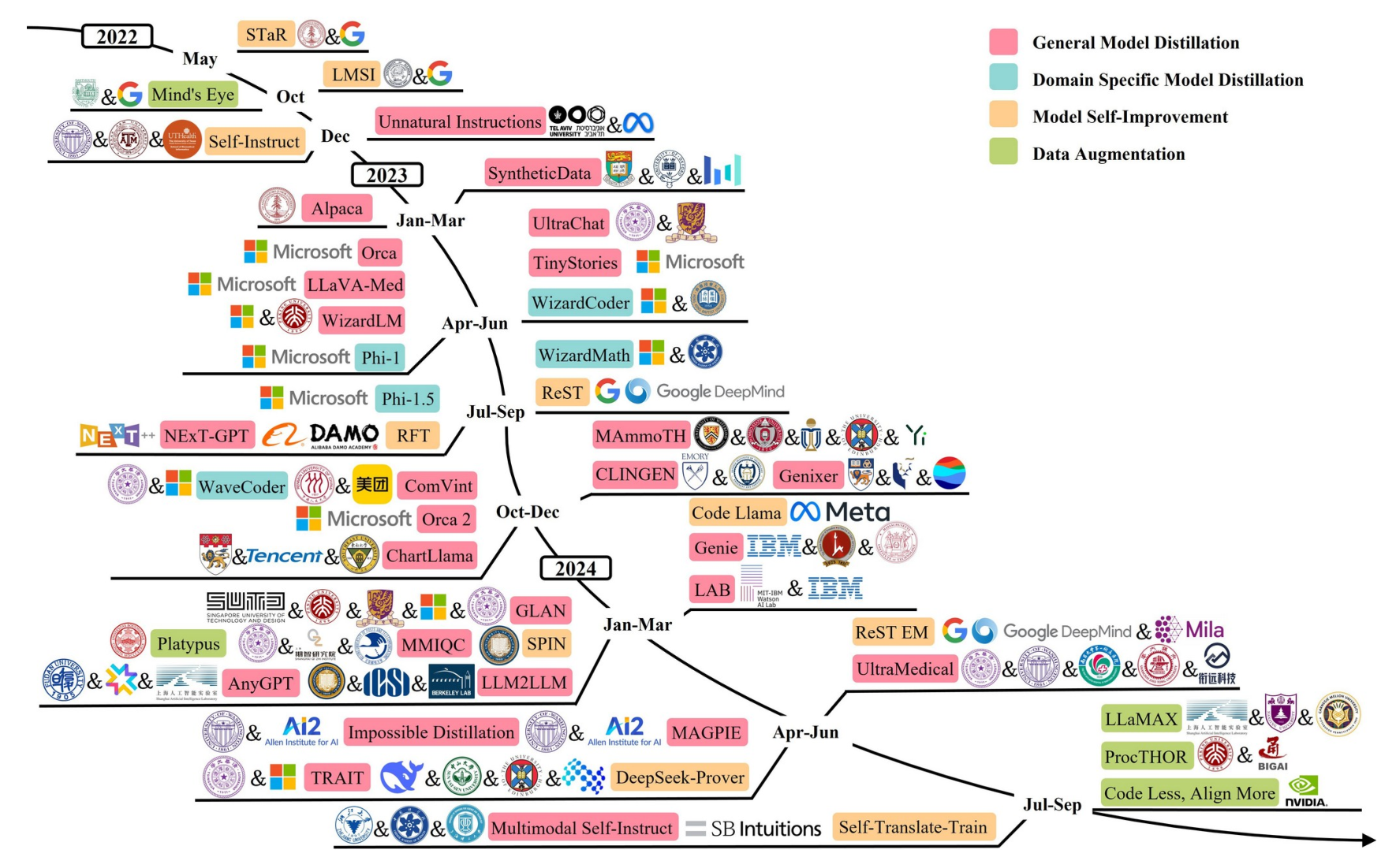
- LLM的数据扩充与合成的发展
二、分类法
2.1 数据扩充
-
数据扩充是一种从数据到数据的生成方法,通常涉及处理原始数据以增加其多样性和数量,而不显著改变其本质特征。
-
我们系统地将现有的数据扩充研究分为三个不同的类别:数据标注,数据重构,和协同标注。
- 数据标注:数据标注致力于利用LLMs全面的语言理解能力来标注大量未标注的数据集。
- **数据重构:数据重构包括将现有数据转换和重组为更大范围的变量,从而促进更细粒度的数据扩充。
- 协同标注:协同标注指的是人类标注者和LLM在标注过程中的协作努力。通过集成两种标注方法的优势,联合标注不仅降低了标注成本,还同时提高了标注性能,从而形成了一种更加高效和有效的数据标注方法。
2.2 数据合成
- 数据合成旨在从零开始或基于生成模型创建全新的数据,这类似于真实数据的分布。
- 本文将数据合成方法分为三大类:通用模型蒸馏,领域模型蒸馏和模型自我提升.
- 通用模型蒸馏:通用模型蒸馏涉及利用强大的通用模型,通常具有较大的参数和卓越的性能,如 StableVicuna、ChatGPT和GPT-4,以生成可以增强较弱模型能力的数据集。
- 领域模型蒸馏:领域模型蒸馏涉及到模型的利用,这些模型被定制在特定的领域内生成数据。当通用模型无法满足行业应用的特定需求时,这种方法通常是必要的。
- 模型自我提升:模型自我提升是指模型生成更高质量的数据以增强其能力的过程。
三、LLM全生命周期中的数据合成和扩充
3.1 数据准备
在数据准备阶段,数据合成和扩充旨在生成多样化和高质量的数据集,用于 LLM的训练,解决现实世界数据稀缺的挑战。
3.1.1 通用模型蒸馏
这种方式旨在利用通用LLM的强大功能来提取高质量的数据。
- 从种子生成数据:为了合成用于特定任务的数据集,用少量相关的例子来提示 LLM 可以有效地以低成本产生高质量的数据集。
- 合成推理步骤:为了增强 LLMs 的推理能力,在数据合成过程中产生了额外的推理步骤。
- 可控性合成:为了控制合成数据的质量,对具有可控性的数据合成技术进行了研究。
- 从头开始合成数据:避免依赖种子数据集,从头开始合成数据
- 合成多模态数据:与单峰类似,促使像GPT这样强大的LLM基于种子集合合成数据也是多峰数据合成的最常见方法 。
3.1.2 数据扩充
数据扩充旨在进一步处理现有数据,以获得更多样化的高质量数据。
- 数据标注:数据标注旨在利用 LLM 的语言理解能力来标注未标注的数据集。
- 数据重构:数据重构试图将现有的数据转换成更大范围的变化,它通常涉及到利用 prompt 工程来指导 LLM 生成重新格式化的数据。
- 协同标注:协同标注是指人类和LLM一起标注未标注数据的过程。
- 非LLM驱动的数据增强:一些方法不使用 LLM 来合成或过滤高质量的数据。
3.2 预训练
在预训练阶段,数据合成和扩充可以为 LLMs 提供丰富、多样和可控的训练数据,从而提高模型性能并减少偏差。
3.2.1 模型自我提升
在预训练阶段,模型自我提升表示通过LLM合成数据,并进一步利用合成数据来预训练相同的 LLM。
3.2.2 通用模型蒸馏
通用模型蒸馏表示利用通用LLM提取高质量数据的强大能力。
3.2.3 数据扩充
数据扩充旨在进一步处理现有数据,以获得更加多样化的数据集。在预训练阶段,主要有两种方法:数据重构和非LLMs驱动的方法。
- 数据重构:对原始数据集进行转换,以获得具有多样性和质量的新数据集。
- 非 LLMs 驱动:其他方法在不利用 LLM 的情况下扩充原始数据集。
3.3 微调
3.3.1 模型自我提升
模型自我提升方法使LLM能够通过反馈过程从其输出中学习,从而消除了对外部支持的需要。根据该方法是否使用迭代自我改进和合成数据的模态,我们将现有的自我改进策略分为两类:单次自我提升和迭代自我提升。
- 单次自我提升:表示通过 LLM 合成数据,然后使用合成的数据对相同的 LLM 执行单次微调的过程。一类方法包括向训练数据集补充信息,另一类方法基于现有种子数据合成新样本。
- 迭代自我提升:为了提高合成数据的质量、多样性和数量,各种方法迭代地合成数据集,并在循环中提升自己。
3.3.2 通用模型蒸馏
通用模型蒸馏表示从强大的LLM中提取高质量的微调数据。在本综述中,我们将现有的通用模型提取方法分为五类:通过种子合成数据、迭代式合成数据、合成推理步骤、基于分类法的合成和合成多模态数据。
- 通过种子合成数据:从现有实例或数据种子中合成数据是最常见的方法。
- 迭代合成数据:为了构建具有多样性的高质量数据,一些方法构建可以多次执行的框架。
- 合成推理步骤:最近的研究集中在通过模仿学习提高 LLM 的性能,利用大型基础模型(LFM)产生的输出。然而,较小的语言模型倾向于模仿 LFM 的风格,而不是推理过程。
- 基于分类法的合成:上述方法大多基于合成来自种子的数据集,而最近的研究采用了另一种新颖的方法,通过分类学驱动的方法来合成数据集。
- 合成多模态数据:通用模型蒸馏对于多模态应用也有很大的潜力。
3.3.3 数据扩充
数据扩充涉及通过各种技术增强现有数据,以创建更广泛、更多样的数据集。在微调阶段,主要有两种方法:数据标记和数据重构。
- 数据标注:数据标注表示为未标记的数据生成注释。
- 数据重构:数据重构是指将现有数据转换成更多样化的形式,从而扩充数据。
3.4 指令调整
在指令调优阶段,数据合成旨在探索合成指令或提示内容,以通过 LLMs 生成遵循指令的高质量数据。根据合成数据的方式,它们包括以下几类:通用模型蒸馏、模型自我提升、数据扩充
3.4.1 通用模型蒸馏
为了获得多样化的数据,一种流行的方法是采用更强的LLM来合成数据并执行针对较弱 LLM 的指令调整,包括单模态综合和多模态综合。
- 单一模态:单一模态通过教师 LLMs 合成特定类型的数据。
- 多模态:多模态通过 LLMs 生成跨模态数据。
3.4.2 模型的自我提升
模型自改进旨在从模型本身引导合成数据,包括单模态合成和多模态合成
- 单一模态:这个类别生成单模态数据,通过 LLM 本身实现指令调优。
- 多模态:以上设计了各种指令示例来提高 LLM 的对齐能力。但是,这些作品通常都是纯文字的。另一类通过 LLM 本身合成多模态数据。
3.4.3 数据扩充
数据扩充旨在通过多样化训练样本来增强模型性能,而不需要额外的数据。它利用高质量的指令或提示来生成用户期望的和匹配目标任务的扩充数据。主要有三种类型:数据标注、数据重构和协同标注。
- 数据标记:数据标注采用 LLM 的语言理解能力来标注未标注的示例。
- 数据重构:数据重构将现有数据转换成其他变体,以满足目标任务的数据格式要求。
- 协同标注:协同标注的目的是共同注释来自人类和 LLM 的数据。
3.5 偏好对齐
偏好对齐是通过系统地提炼大型模型以匹配复杂的人类偏好来实现的。这一过程始于一般模型提炼,它综合了广泛的偏好数据,提供了跨不同任务的基本一致性。领域模型提取然后使用专门的数据集优化模型,增强特定领域的性能。模型自我提升允许模型使用自我生成的反馈,在最少的人工干预下迭代地改进它们的能力。数据扩充通过扩展和多样化训练数据来进一步加强模型概括。这些相互关联的方法形成了一个一致的框架,用于优化与一般和特定领域人类偏好的模型对齐。
3.5.1 通用模型蒸馏
通用模型蒸馏。通用模型提炼旨在通过利用大型语言模型(LLM)和外部工具来更好地将模型与复杂的人类偏好相匹配,从而生成高质量的偏好数据。这一过程对于提高LLM在实际应用中的性能至关重要,特别是在安全性、可靠性和伦理考虑等领域。这种方法的主要挑战之一是模型固有的偏见和局限性。为了解决这个问题,可以从多个模型中提取精华,而不是依赖单个模型,以减少偏差并增加响应的多样性。
3.5.2 领域模型蒸馏
领域模型蒸馏侧重于通过在专门的领域和特定的数据集上训练模型来优化特定任务的模型,通常使用强化学习和偏好建模技术。这种方法使模型能够在不同的领域中表现良好,增强了它们处理复杂的、专门的任务的能力。通过这个过程,模型被蒸馏以满足各种领域的要求,包括面向安全的场景,总结,数学问题解决,基于搜索的问题回答,以及代码生成和逻辑推理。
3.5.3 模型自我提升
模型自我提升的重点是使较弱的LLM能够迭代地增强它们的性能,而不需要额外的人工注释数据。这种方法包括两个类别:自我反馈循环和依靠外部评估者评估模型的响应。这两种方法都旨在通过减少对人工干预的依赖来创建可扩展的改进系统,允许模型通过内部调整或外部指导来不断优化其性能。
3.5.4 数据扩充
数据扩充对于通过创建现有数据的特定于任务的变化来增强大型模型对齐是必不可少的,这加强了模型的泛化和稳健性。这种方法增加了训练数据的多样性,而不需要额外的数据收集。 像数据标注,数据重构,和协同标注被用于确保补充的数据保持相关和一致,有助于跨各种任务的更精确的模型性能。
3.6 应用
大多数大型语言模型都是在通用语料库上进行预训练和微调的。然而,与大量的通用数据不同,特定领域的数据集通常很少,因为创建它们需要大量的知识。为了解决这个问题,许多研究已经探索了具有为每个应用定制的不同特征的专门数据的合成。
3.6.1 数学
在数学场景中应用LLM,涉及问题理解和回答,需要密集的逻辑推理。许多研究人员提出,在训练语料库中生成更多的基本原理语料库和不同的问题和答案有助于模型更好地理解和推理。多样化的问题和解决方案也可以增强逻辑思维模式的数学理解和推理能力。由于数学问题和答案是可验证的,一些方法通过自我生成的模拟问题和已经被自己或外部工具和模型验证的证明来扩展训练语料库。
3.6.2 科学
科学应用需要对知识密集型概念和推理的深刻理解,这需要高质量的数据集来进行有效的指令微调。然而,生成这样的数据集是具有挑战性的,因为不同学科之间的格式各不相同,并且底层逻辑可能难以表达。统一不同学科的格式是处理科学相关语料库的第一步,通过将结构化数据转换成可读文本或专门的标记器。然后从收集的原始数据中生成指令调节数据集。
3.6.3 代码生成
产生增强代码生成性能的合成数据已经被研究了很长时间,这需要清楚地理解问题和精确的推理来产生正确的代码。由于可以在模拟编码环境中轻松验证代码的准确性,这使得能够为编码任务生成大规模指令内调整数据集。
3.6.4 医疗
在医疗应用中,大模型主要作为医疗对话聊天机器人,需要与患者进行多轮对话交互。为了实现交互式数据合成,首先收集专门的文档作为种子语料库,例如医疗诊断记录。在此基础上,借助于通用大型语言模型,可以生成不同的问答对,并用于提高理解能力产生有益的反应。在处理敏感病历时,隐私也是一个首要问题,一些文献从知识图中提取医学知识,并生成没有任何个人信息的合成医学文本。
3.6.5 法律。
以法学硕士为基础的法律助理因提供负担得起和方便的法律服务,特别是在法律问答和咨询领域,已经获得了相当大的关注。最近的研究集中在通过使用数据合成来提高响应的清晰度和正确性的微调数据集的数量和质量。
四、功能
从 LLMs 的功能角度来看,数据扩充和合成可分为四类:理解、逻辑、记忆和生成。通过探索 LLMs 中的四个基本功能,数据合成和扩充可以充分捕捉大规模数据中的内在模式,并将其有效地应用于下游应用和任务
4.1 理解
理解功能利用对 LLM 的强大语言理解来理解数据。从理解的内容来看,它包括单模态理解和多模态理解。单模态理解主要理解文本的语义,包括文本理解和语义标注。多模态理解结合了多种模态。
4.2 逻辑
逻辑功能在合成和扩充数据的过程中充分利用推理和逻辑功能。根据逻辑的应用,有以下三类:代码逻辑、数学逻辑和推理。
4.3 记忆
当合成数据时,记忆功能记住并利用 LLM 中先前学习的信息。根据记忆内容的性质,记忆功能可以分为三类:程序记忆、语义记忆和情景记忆。
4.4 生成
生成功能旨在为下游任务和应用程序生成连贯且上下文相关的内容。基于生成内容的形式,有以下两类:内容生成(例如,文本和多模态生成)和检索增强生成。
五、挑战与局限
5.1 合成与扩充的方法
尽管合成和扩充数据很重要,但是使用不同的合成和扩充方法仍然存在严峻的挑战
- 对 LLM 的依赖
- 模型训练中的复杂评估和去污染
- RLAIF 中的不确定性和搜索复杂性
- 不稳定和不一致的逻辑路径
5.2 数据质量
与已经存在的多样、可信、高质量的真实数据不同,数据合成和扩充的性质可能会影响生成数据的质量。
- 数据多样性
- 长尾现象
- 可靠性
- 分布不一致
5.3 数据合成与扩充的影响
- 隐私
- 安全
- 社会影响
5.4 对不同应用和任务的影响
- 泛化
- 可转移性和领域适配
5.5 未来方向
- 多模态合成
- 实时合成
- 领域模型蒸馏
- 大规模合成
- 稳健的质量评估指标
- 伦理考虑与负责任的数据合成和增强
六、结论
数据合成和扩充对于推进LLM至关重要,特别是在满足LLM对大规模和高质量数据的需求方面。这项调查提供了一个面向 LLM 的数据合成和增强技术的全面审查,系统地探索了它们在 LLM 的整个生命周期和核心功能中的应用,同时建立了一个连接现有研究的框架,强调了关键方法,并阐明了优势和局限性。我们预计,面向 LLM 的数据合成和增强方法的进步将释放新的可能性,以提高数据效率,改善跨任务的通用性,并推动以数据为中心的人工智能的发展。我们希望这项调查能作为未来研究的基础,激励面向 LLM 的数据合成和增强领域的创新和进步。