什么?决定 AI 上限的已不再是底座模型,而是外围的「推理编排」(Orchestration)。
在 LLM 完全不变的前提下,仅靠一套 Agentic System,就能让 AI 的智力表现原地暴涨一截。
在看了「AI 推理和自我改进系统」初创公司 Poetiq 的最新评测之后,有人得出了这样的结论。

部分截图
近日,Poetiq 表示其使用 ARC-AGI-2 测试集,在他们的系统上(称为 meta-system)运行了 GPT-5.2 X-High。该测试集通常被用来衡量当前 SOTA 模型在复杂抽象推理任务上的表现。
结果显示,在相同的 Poetiq 测试平台上,GPT‑5.2 X‑High 在完整的 PUBLIC-EVAL 数据集上的成绩高达 75%,这比之前的 SOTA 高出了约 15%,同时每个问题的成本低于 8 美元。
这里的 PUBLIC-EVAL 是 ARC 测试的一部分,前者一般包含基础推理任务和标准的 NLP、数学推理测试,适合广泛的模型评测,数据集更为公开、标准;后者包含更多复杂且富有挑战性的推理问题,考察模型的抽象推理、常识推理、创新能力等,是针对高水平模型的推理极限测试。

下图展示了各个 SOTA 模型在 PUBLIC-EVAL 数据集上的成绩分布:
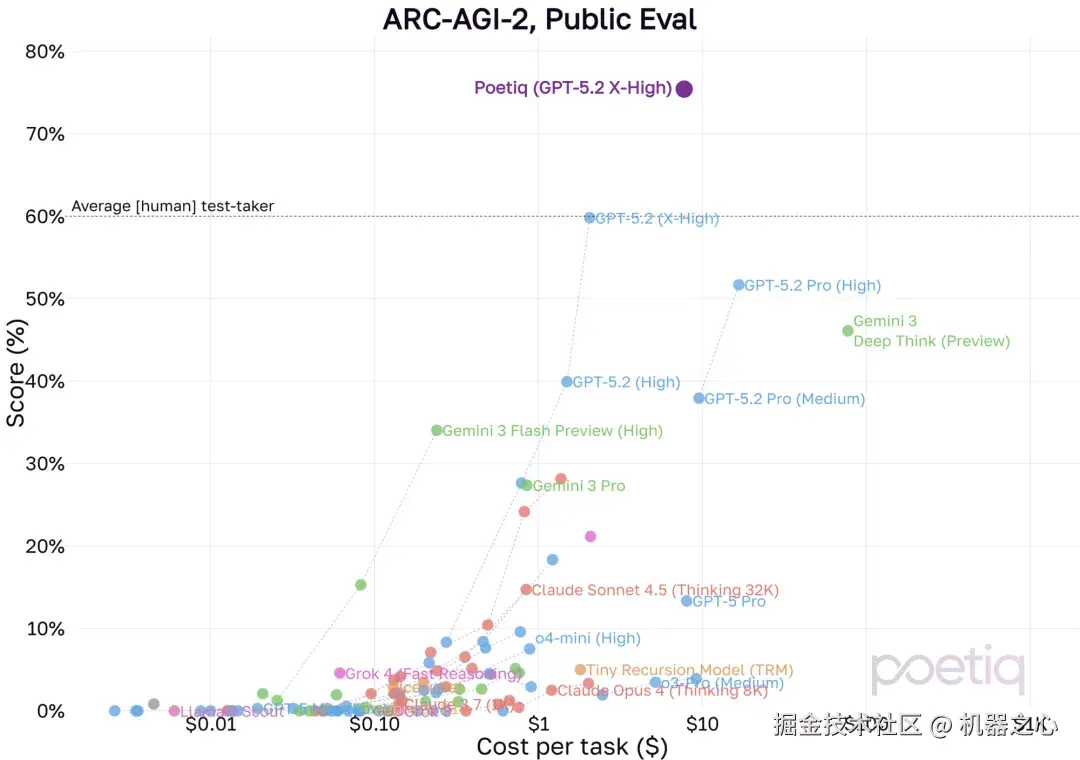
Poetiq 还特别强调了,其没有对 GPT-5.2 进行任何再训练或模型特定的优化。
在如此短的时间内,相较于 Poetiq 之前在 PUBLIC-EVAL 数据集上测试的其他模型,GPT-5.2 在准确率和价格方面实现了显著改进。
Poetiq 进一步做出设想:如果在 PUBLIC-EVAL 测试中表现好的规律能够延续到 ARC Prize 官方的 SEMI-PRIVATE 测试中,那么「GPT-5.2 X-High + Poetiq」会比以往任何系统配置都更强、更好。
ARC Prize 总裁 Greg Kamradt 表示,「很高兴看到 Poetiq 发布 GPT-5.2 X-High 的结果。如果这个成绩能保持下去,他们的系统看起来能很好地处理模型交换。不过,在 OpenAI API 的基础设施问题解决之前,结果还没有得到完全验证。」
这里的模型交换指的是:系统通过切换不同的模型来应对不同的任务需求,而无需对系统或模型进行大规模的调整或重新训练。

OpenAI 总裁 Greg Brockman 也转推表示:GPT-5.2 在 ARC-AGI-2 上超越人类基准成绩。
对于全新的测试结果,评论区提出了更多问题,比如「每个任务平均需要多长时间」。
Poetiq 回复称,「我们现在没有专门收集这些统计数据,最简单的问题大概在 8 到 10 分钟后就能完成,而最难的问题必须在 12 小时之前终止,以保持在时间限制内。所以,未来肯定还有改进的空间。」
还有人指出「大部分改进似乎来自于测试框架和协调机制,而不是任何模型特定的调优。没有训练变更的情况下,ARC-AGI-2 上提高了大约 15%,这表明仅在搜索、路由和终止逻辑方面就还有很大的提升空间」。
可问题是:为什么在这个设置中,X-High 每个任务的成本比 High 还要低?是因为它通过更早找到正确的解决方案而更快收敛,还是因为测试框架更积极地修剪了无效的推理过程?
对于这个问题,Poetiq 肯定了「X-High 只是比 High 更快地收敛到正确的答案」这一观点。
6 人团队打造 Meta-system 系统
Poetiq 是一支由 6 位研究员和工程师组成的团队,有多位核心成员来自 Google DeepMind 。
-
Ian Fischer (联合创始人 & 联席 CEO): 曾是 Google DeepMind 的资深研究员;
-
Shumeet Baluja (联合创始人 & 联席 CEO): 同样出身于 Google/DeepMind 的资深专家。

Poetiq 能够取得上述成绩,关键在于其构建的 meta-system(元系统)。
Meta-system 不依赖特定的大模型,可以与任何前沿模型配合使用(如 Gemini 3、GPT-5.1、Grok 等),而不是训练或微调模型本身,这意味着它能随着新模型发布快速适配并提升性能。
Poetiq meta-system 构建了一种迭代式推理过程,其与传统一次性生成答案的方法不同,有两个主要机制:
-
迭代式的问题求解循环:系统并不是只向模型提出一次问题,而是利用大语言模型(LLM)生成一个潜在的解决方案,随后接收反馈、分析反馈,并再次调用 LLM 对方案进行改进。这种多步骤、自我改进的过程,使系统能够逐步构建并不断完善最终答案。
-
自我审计(Self-Auditing):系统能够自主审计自身的运行进度,并自行判断何时已经获得足够的信息、当前解决方案是否令人满意,从而决定终止整个过程。这种自我监控机制对于避免不必要的计算浪费、有效降低整体成本至关重要。
Poetiq 还特别强调,他们所有 meta-system 的适配工作是在新模型发布前完成的,而且系统从未直接接触过 ARC-AGI 任务集,但依然在多个不同模型上取得跨版本、跨模型族的性能提升,说明 meta-system 对 reasoning 策略具有良好的泛化能力。
正是这种灵活、强大且具备递归能力的架构,使得 Poetiq 这样一支小规模团队,能够在极短时间内取得一系列最先进(SOTA)的成果。
对于这个 meta-system,有人认为「太棒了。在模型之上构建智能,而不是在模型内部构建,意味着可以在几个小时内适配新模型,非常高明。适配开源模型,并且成功迁移到新的封闭模型,这表明捕捉到的东西是推理过程本身的基本规律,而不是模型特定的怪癖。」
