在 RAG(检索增强生成)系统中,索引就像图书馆的 "智能导航系统"------ 它决定了能否快速找到与问题最相关的信息,直接影响最终答案的准确性和响应速度。经过对向量嵌入、多模态支持、向量数据库、Milvus 实践及索引优化的系统学习,我终于摸清了 RAG 索引从构建到优化的完整逻辑。这篇笔记就把这些硬核知识掰开揉碎,用通俗易懂的语言分享给大家,帮你避开坑、用对方法。
一、向量嵌入:索引的 "信息翻译官"
要让机器理解文本、图像等非结构化数据,第一步就是把它们转换成可计算的数学语言 ------ 这就是向量嵌入(Embedding)的核心作用。它就像一位精准的翻译官,把复杂的原始数据翻译成低维、稠密的向量,让后续检索能快速捕捉语义关联。
1. 嵌入的本质:语义的数学编码
向量嵌入不是随机生成的数字数组,而是对数据语义的精准编码。核心原则很简单:语义相似的对象,向量距离更近;语义无关的对象,向量距离更远。比如 "猫" 和 "狗" 的向量会靠得很近,而 "猫" 和 "电脑" 的向量会相距甚远。
衡量这种相似度主要有三种方法:
- 余弦相似度:最常用,计算两个向量夹角的余弦值,越接近 1 越相似;
- 点积:向量归一化后与余弦相似度等价,计算更高效;
- 欧氏距离:空间中两点的直线距离,数值越小越相似。
2. 嵌入技术的进化之路
嵌入技术的发展始终围绕 "更精准捕捉语义" 展开,大致分为三个阶段:
- 静态词嵌入(Word2Vec、GloVe):为每个单词生成固定向量,能实现 "国王 - 男人 + 女人≈王后" 这样的语义运算,但无法处理一词多义,比如 "苹果公司" 和 "吃苹果" 中的 "苹果" 向量完全相同;
- 动态上下文嵌入(BERT):基于 Transformer 编码器,能根据上下文生成不同向量,彻底解决了一词多义问题,同一个词在不同语境下会有不同的向量表示;
- RAG 时代的嵌入需求:随着 RAG 的兴起,嵌入模型被提出了更高要求 ------ 要能适应专业领域(法律、医疗)的术语,支持长文档、图像等多模态数据,还要兼顾检索效率,于是诞生了像 BGE-M3 这样支持混合检索的先进模型。
3. 嵌入模型的训练秘诀
现代嵌入模型大多基于 BERT 的变体,核心是通过自监督学习从海量文本中汲取知识:
- 掩码语言模型(MLM):随机遮盖句子中 15% 的词,让模型预测原始词,迫使模型学习词与上下文的关系;
- 下一句预测(NSP):让模型判断两个句子是否连贯,学习句子间的逻辑关系(后续 RoBERTa 等模型已移除这一任务);
- 度量学习与对比学习:通过 "拉近相似样本、推远不相似样本" 的策略,优化向量空间的语义分布,让检索更精准。
二、多模态嵌入:打破数据类型的 "次元壁"
传统文本嵌入无法处理图像、音频等数据,而现实世界的信息往往是多模态的 ------ 比如 "一张红色汽车的图片" 这样的查询,就需要图文跨模态的理解能力。多模态嵌入的目标,就是打破不同数据类型的 "模态墙",让图像、文本等数据在同一个向量空间中对齐。
1. 多模态嵌入的核心:跨模态对齐
多模态嵌入的关键是让不同模态的语义在向量空间中对应。比如 "奔跑的狗" 的文本向量,要和真实的狗奔跑图片的向量距离足够近。实现这一目标的核心技术是对比学习,以经典的 CLIP 模型为例:
CLIP 采用双编码器架构,一个处理图像,一个处理文本。训练时,模型会最大化正确图文对的相似度,最小化错误配对的相似度,通过 "拉近正例、推远负例",让模型学会跨模态的语义关联。
2. 现代多模态模型代表:BGE-M3
BGE-M3 是当前多模态嵌入的优秀代表,核心特性可以概括为 "M3":
- 多语言性:原生支持 100 多种语言,轻松实现跨语言图文检索;
- 多功能性:同时支持密集检索、多向量检索和稀疏检索,适配不同场景;
- 多粒度性:能处理从短句到 8192 个 token 的长文档,覆盖更多需求。
3. 代码实操:图文多模态编码
用 BGE-M3 模型可以轻松实现文本、图像及图文组合的编码,核心代码如下
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
import torch
from visual_bge.visual_bge.modeling import Visualized_BGE
model = Visualized_BGE(model_name_bge="BAAI/bge-base-en-v1.5",
model_weight="../../models/bge/Visualized_base_en_v1.5.pth")
model.eval()
with torch.no_grad():
text_emb = model.encode(text="datawhale开源组织的logo")
img_emb_1 = model.encode(image="../../data/C3/imgs/datawhale01.png")
multi_emb_1 = model.encode(image="../../data/C3/imgs/datawhale01.png", text="datawhale开源组织的logo")
img_emb_2 = model.encode(image="../../data/C3/imgs/datawhale02.png")
multi_emb_2 = model.encode(image="../../data/C3/imgs/datawhale02.png", text="datawhale开源组织的logo")
# 计算相似度
sim_1 = img_emb_1 @ img_emb_2.T
sim_2 = img_emb_1 @ multi_emb_1.T
sim_3 = text_emb @ multi_emb_1.T
sim_4 = multi_emb_1 @ multi_emb_2.T
print("=== 相似度计算结果 ===")
print(f"纯图像 vs 纯图像: {sim_1}")
print(f"图文结合1 vs 纯图像: {sim_2}")
print(f"图文结合1 vs 纯文本: {sim_3}")
print(f"图文结合1 vs 图文结合2: {sim_4}")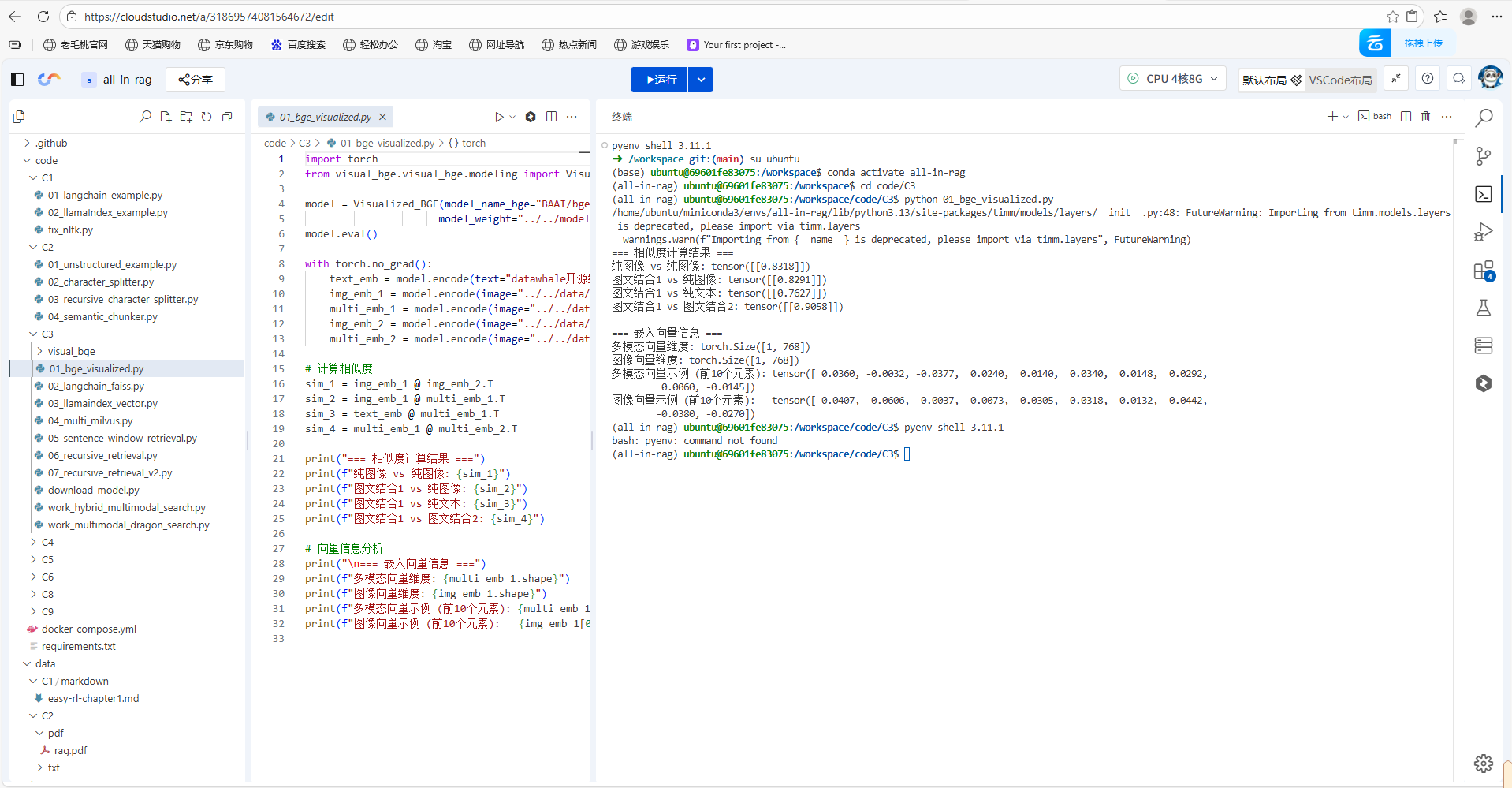
三、向量数据库:海量向量的 "高效管家"
有了向量,如何快速从数百万、数十亿向量中找到最相似的 Top-K 个?这就需要向量数据库 ------ 专门为高维向量设计的存储和检索系统,是 RAG 系统的 "知识库核心"。
1. 向量数据库 vs 传统数据库:不是替代,而是互补
很多人会疑惑,为什么不用 MySQL 这样的传统数据库存储向量?两者的核心差异在于处理的数据类型和查询方式:
| 维度 | 向量数据库 | 传统数据库(RDBMS) |
|---|---|---|
| 核心数据 | 高维向量 | 结构化数据(文本、数字) |
| 查询方式 | 相似性搜索(ANN) | 精确匹配(WHERE 条件) |
| 索引机制 | HNSW、IVF 等 ANN 索引 | B-Tree、Hash 索引 |
| 适用场景 | AI 应用、RAG、推荐系统 | 业务系统、金融交易 |
| 数据规模 | 轻松应对千亿级向量 | 千万到亿级行数据 |
简单来说,传统数据库擅长 "找确定的东西",比如 "查询年龄 = 25 的用户";向量数据库擅长 "找相似的东西",比如 "找到与用户问题最相关的文档"。在实际应用中,两者通常结合使用:传统数据库存储业务元数据,向量数据库存储向量和非结构化数据。
2. 向量数据库的工作原理:高效检索的核心技术
向量数据库能实现毫秒级检索,关键在于优化的索引技术和分层架构:
- 存储层:优化高维向量存储,支持分布式部署,应对海量数据;
- 索引层:采用专门的 ANN(近似最近邻)索引,常见类型包括:
- 基于图的 HNSW:构建多层邻近图,查询速度快、召回率高;
- 基于量化的 IVF/PQ:通过聚类和压缩向量,平衡速度和精度;
- 基于哈希的 LSH:将相似向量映射到同一 "桶",适合海量数据快速筛选;
- 查询层:支持相似性搜索、元数据过滤、范围查询等复合查询;
- 服务层:管理连接、监控日志,确保高可用。
3. 主流向量数据库选型指南
不同向量数据库各有侧重,选择时要结合场景需求:
- 新手入门 / 小型项目:ChromaDB(轻量无依赖,零配置安装)、FAISS(Facebook 开源,适合本地原型开发);
- 生产环境 / 大规模应用:Milvus(开源分布式,支持 GPU 加速)、Weaviate(支持 GraphQL,多模态友好)、Pinecone(托管服务,高可用低延迟);
- 性能敏感场景:Qdrant(Rust 开发,低延迟高并发)。
4. 本地向量存储实操:FAISS 入门
FAISS 是 Facebook 开源的轻量级向量检索库,适合快速原型开发,核心代码如下:
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_core.documents import Document
# 1. 示例文本和嵌入模型
texts = [
"张三是法外狂徒",
"FAISS是一个用于高效相似性搜索和密集向量聚类的库。",
"LangChain是一个用于开发由语言模型驱动的应用程序的框架。"
]
docs = [Document(page_content=t) for t in texts]
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
# 2. 创建向量存储并保存到本地
vectorstore = FAISS.from_documents(docs, embeddings)
local_faiss_path = "./faiss_index_store"
vectorstore.save_local(local_faiss_path)
print(f"FAISS index has been saved to {local_faiss_path}")
# 3. 加载索引并执行查询
# 加载时需指定相同的嵌入模型,并允许反序列化
loaded_vectorstore = FAISS.load_local(
local_faiss_path,
embeddings,
allow_dangerous_deserialization=True
)
# 相似性搜索
query = "FAISS是做什么的?"
results = loaded_vectorstore.similarity_search(query, k=1)
print(f"\n查询: '{query}'")
print("相似度最高的文档:")
for doc in results:
print(f"- {doc.page_content}")
四、Milvus 深度实践:生产级向量数据库的核心玩法
Milvus 是开源分布式向量数据库的代表,专为生产环境设计,支持十亿级向量检索。通过 Milvus 的实践,能更深入理解向量数据库的核心概念和高级功能。
1. Milvus 的核心组件:数据的 "组织架构"
Milvus 用清晰的组件来组织数据,就像图书馆的管理体系:
- Collection(集合):相当于图书馆,是数据的顶层容器,类似关系型数据库的表;
- Partition(分区):相当于图书馆的不同区域(小说区、科技区),按规则隔离数据,提升检索效率;
- Schema(模式):相当于图书登记规则,定义数据字段,包括主键、向量字段、标量字段(元数据);
- Entity(实体):相当于具体的一本书,是数据的基本单位;
- Alias(别名):相当于动态书单,可指向不同 Collection,实现数据无缝更新。
2. 索引选择:平衡速度与精度的艺术
Milvus 支持多种向量索引,选择时需要在数据规模、内存限制、查询性能之间权衡:
- FLAT(精确查找):暴力搜索,召回率 100%,但速度慢,适合百万级以下小规模数据;
- IVF 系列(IVF_FLAT、IVF_SQ8):聚类分桶后搜索,平衡性能和精度,是通用场景首选;
- HNSW:基于多层图结构,检索速度极快、召回率高,适合低延迟场景,但内存占用大;
- DiskANN:专为 SSD 优化,支持十亿级海量数据,适合无法全量载入内存的场景。
3. 高级检索功能:满足复杂业务需求
Milvus 的强大之处在于支持多种增强检索功能,能应对复杂场景:
- 过滤检索:结合向量相似性和标量过滤,比如 "查找与红色连衣裙相似的商品,且价格 < 500 元";
- 范围检索:返回相似度在阈值范围内的所有结果,比如 "查找与人脸相似度> 0.9 的图像";
- 多向量混合检索:同时检索多个向量字段(文本向量、图像向量),融合结果提升精度;
- 分组检索:确保返回结果来自不同分组,提升多样性,比如 "检索机器学习文档,确保来自不同书籍"。
五、索引优化:让 RAG 检索更精准、更高效
索引构建不是一劳永逸的,需要通过优化策略提升检索质量。LlamaIndex 提供的两种核心优化方案 ------ 上下文扩展和结构化索引,能有效解决传统 RAG 的痛点。
1. 上下文扩展:句子窗口检索
传统 RAG 面临两难:小块文本检索精确但上下文不足,大块文本上下文丰富但噪音多。句子窗口检索巧妙解决了这一矛盾,核心思路是 "为检索精确性索引小块,为生成质量扩展上下文"。
2. 结构化索引:大规模知识库的检索利器
当知识库包含数百个文档时,无差别向量搜索会效率低下、噪音干扰多。结构化索引通过 "元数据 + 向量搜索" 的组合,缩小检索范围,提升精准度。
核心思路是为文本块附加结构化元数据(文件名、章节、日期等),检索时先通过元数据过滤,再执行向量搜索。比如查询 "2023 年 Q2 财报中的 AI 论述",流程如下:
- 元数据预过滤:筛选出
document_type="财报"、year=2023、quarter="Q2"的文档子集; - 向量搜索:在筛选后的子集内,检索与 "AI 论述" 相关的文本块。
六、总结:索引构建与优化的完整方法论
经过这段时间的学习,我梳理出了 RAG 索引构建与优化的完整方法论,核心可以概括为 "三步走":
第一步:打好基础 ------ 高质量向量嵌入
- 选择合适的嵌入模型:通用场景用 BGE、E5 系列,专业领域用微调后的模型;
- 确保数据质量:文本分块合理(单句或小段落),多模态数据预处理规范;
- 关注核心指标:向量维度、最大处理 Token 数,平衡语义表达和检索效率。
第二步:选对工具 ------ 匹配场景的向量数据库
- 小规模项目:优先 ChromaDB、FAISS,快速验证想法;
- 生产环境:选择 Milvus、Weaviate、Pinecone,保障高可用和扩展性;
- 多模态需求:优先支持跨模态检索的数据库,如 Weaviate、Milvus。
第三步:持续优化 ------ 解锁高级功能
- 检索精度优化:用句子窗口检索、结构化索引 + 元数据过滤;
- 检索效率优化:合理选择索引类型,利用分区减少检索范围;
- 复杂场景适配:用多向量混合检索、递归检索,应对多数据源、多模态需求。
RAG 索引的核心价值在于 "让正确的信息被快速找到",这需要对嵌入技术、向量数据库、优化策略有深入理解。掌握这些知识后,就能搭建出高效、精准、稳定的 RAG 检索系统,为后续的生成环节提供坚实支撑。