
2025.3
1.摘要
background
多模态大语言模型(MLLMs)在多模态理解方面表现出色。在音频和语音领域,LLM结合音频编码器已在自动语音识别(ASR)上取得了SOTA效果 。
然而,视觉和视听语音识别(VSR/AVSR)------这类利用唇部运动信息来增强抗噪能力的任务------却鲜有研究关注如何利用LLM来实现 。
现有的AVSR方法通常依赖昂贵的大规模标注数据(如100K小时),或者复杂的自监督学习流程 。
innovation
提出了 Llama-AVSR,这是一个利用预训练LLM进行ASR、VSR和AVSR任务的新框架 。
参数高效 :保持预训练的音频/视频编码器和LLM冻结(frozen),仅训练模态特定的投影层(Projectors)和LLM中的LoRA模块 。
SOTA****性能 :在最大的公共AVSR基准数据集LRS3上,ASR和AVSR任务均取得了新的SOTA结果(WER分别为0.79%和0.77%) 。
关键发现 :揭示了预训练编码器的选择、LoRA的集成方式以及**模态感知压缩率(modality-aware compression rates)**是性能与效率权衡的关键因素 。
- 方法 Method
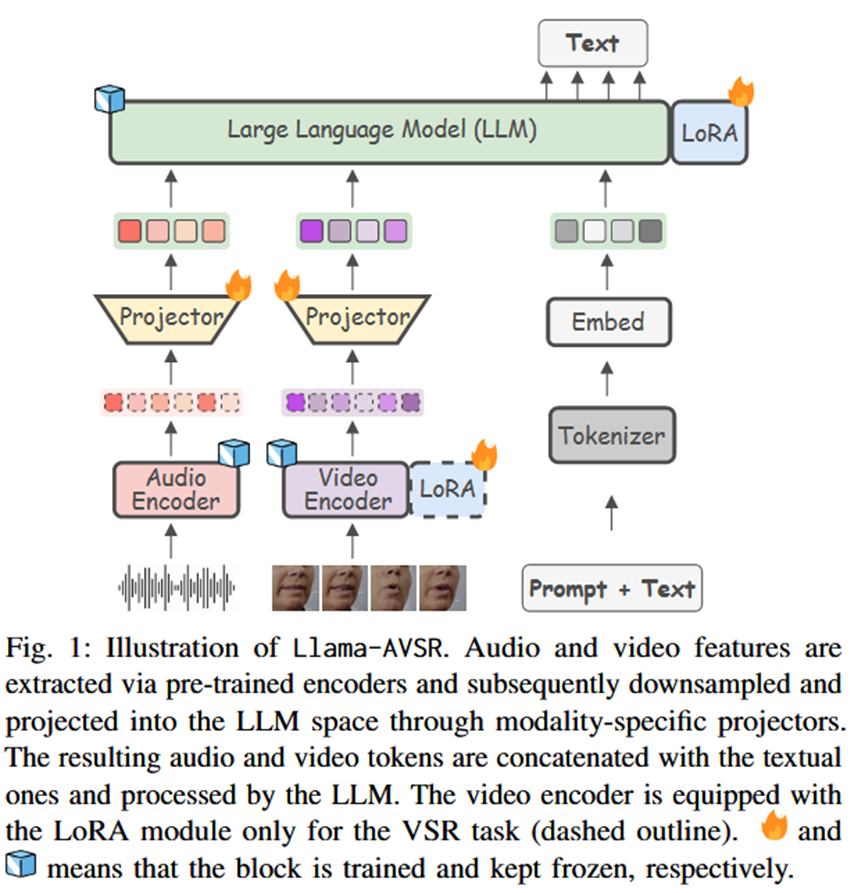
总分结构汇报:
该方法采用基于Decoder-only的架构 15,Pipeline如图1所示 16。核心思想是将音频和视频特征转化为LLM可理解的Token,与文本Token拼接后输入LLM进行自回归生成。
具体组件及流程:
-
- 模态特定的预训练编码器 (Modality-specific Pre-trained Encoders):
输入:原始音频波形 和/或 嘴部ROI视频帧 17。
处理 :使用 Whisper 提取音频特征,使用 AV-HuBERT 提取视频特征 18。
状态:编码器在训练期间保持冻结。仅在VSR任务中,视频编码器会加入一个可训练的LoRA模块 19。
-
- 模态特定的投影器 (Modality-specific Projector):
功能:连接编码器和LLM,同时负责**降采样(Downsampling)**以减少计算量 20202020。
操作:首先将 K 个连续特征沿隐藏层维度拼接(压缩率为 K),然后通过两个线性层映射到LLM的嵌入空间。
输出:音频Token (X_aud) 和 视频Token (X_vid)。
-
- 大语言模型 (LLM):
模型:主要使用 Llama 3.1-8B(也探索了TinyLlama, Llama2等) 23。
输入:拼接后的序列:Prompt + Audio/Video Tokens + Text Tokens
微调方式 :LLM主体冻结,仅训练 LoRA 模块 25。
输出:自回归生成的文本转录 Y。
- 实验 Experimental Results
数据集:
评测/训练核心:LRS3 (433小时标注视频) 28。
扩展数据:LRS3 + VoxCeleb2 (共1756小时,通过Whisper伪标注) 29。
低资源设置:LRS3 trainval set (30小时) 30。
主要实验结论:
-
ASR性能 :Llama-AVSR在1756小时数据下达到 0.79% WER,刷新SOTA。仅用433小时数据时(1.1% WER)也优于全量微调Whisper-Large(2.3% WER)的方法,且参数量极少(42M vs 1.5B)31313131。
-
VSR性能:在使用433小时数据时,优于之前的LLM基线(VSP-LLM),主要得益于使用了AV-HuBERT作为视觉编码器 32323232。
-
AVSR性能 :达到 0.77% WER (1756h)。视频模态的引入显著提高了噪声环境下的鲁棒性 33333333。
-
压缩率分析:音频Token可以承受较高的压缩率(K=5)而不掉点;视频Token对压缩率敏感,K值增大性能下降明显 34343434。
-
总结 Conclusion
利用现有的高性能预训练大模型(如Llama 3.1)和专用编码器(Whisper, AV-HuBERT),通过极少量的参数微调(LoRA + Projector),即可在视听语音识别任务上达到超越传统全量训练方法的SOTA性能 。