网址:https://chat.deepseek.com/share/par9nbluvaliqe3dzh
视频链接:跟着大佬三个小时吃透【OpenCV特征检测】,上交大博士带你深挖图像拼接与Harris角点检测,绝对通俗易懂!!!(opencv/深度学习/人工智能)_哔哩哔哩_bilibili
文章目录
- [1、OpenCV 特征检测入门笔记](#1、OpenCV 特征检测入门笔记)
-
- 一、特征检测的应用场景
-
- [1. 图像搜索(以图搜图)](#1. 图像搜索(以图搜图))
- [2. 拼图游戏](#2. 拼图游戏)
- [3. 全景图像拼接](#3. 全景图像拼接)
- 二、什么是图像特征?
- 三、角点(Corner)作为关键特征
- 四、总结与核心要点
- [2、OpenCV Harris角点检测笔记](#2、OpenCV Harris角点检测笔记)
-
- 一、Harris角点检测原理
-
- [1. 基本思想](#1. 基本思想)
- [2. 三种检测情况](#2. 三种检测情况)
- [3. 数学原理简化](#3. 数学原理简化)
- [二、OpenCV Harris角点检测API](#二、OpenCV Harris角点检测API)
- 三、代码实现步骤
-
- [1. 基本流程](#1. 基本流程)
- [2. 参数调整技巧](#2. 参数调整技巧)
- 四、实际应用注意事项
-
- [1. 图像预处理](#1. 图像预处理)
- [2. Harris角点检测的优缺点](#2. Harris角点检测的优缺点)
- [3. 与后续学习的关联](#3. 与后续学习的关联)
- 五、总结要点
- [3、OpenCV Shi-Tomasi角点检测笔记](#3、OpenCV Shi-Tomasi角点检测笔记)
-
- 一、Shi-Tomasi角点检测概述
-
- [1. 与Harris的关系](#1. 与Harris的关系)
- [2. 核心优势](#2. 核心优势)
- [二、OpenCV API详解](#二、OpenCV API详解)
- 三、各参数作用详解
-
- [1. `qualityLevel`(角点质量)](#1.
qualityLevel(角点质量)) - [2. `minDistance`(最小距离)](#2.
minDistance(最小距离)) - [3. `useHarrisDetector`(检测器选择)](#3.
useHarrisDetector(检测器选择)) - [4. `maxCorners`(最大角点数)](#4.
maxCorners(最大角点数))
- [1. `qualityLevel`(角点质量)](#1.
- 四、代码实现步骤
-
- [1. 基本Shi-Tomasi角点检测](#1. 基本Shi-Tomasi角点检测)
- [2. 使用Harris角点检测模式](#2. 使用Harris角点检测模式)
- 五、参数调整效果对比
-
- [1. `qualityLevel`影响](#1.
qualityLevel影响) - [2. `minDistance`影响](#2.
minDistance影响) - [3. `maxCorners`影响](#3.
maxCorners影响)
- [1. `qualityLevel`影响](#1.
- [六、Shi-Tomasi vs Harris比较](#六、Shi-Tomasi vs Harris比较)
- 七、实际应用建议
-
- [1. 参数选择技巧](#1. 参数选择技巧)
- [2. 预处理优化](#2. 预处理优化)
- [3. 性能考虑](#3. 性能考虑)
- 八、总结要点
- [4、OpenCV SIFT特征检测笔记](#4、OpenCV SIFT特征检测笔记)
-
- 一、SIFT特征检测概述
-
- [1. SIFT定义](#1. SIFT定义)
- [2. SIFT vs Harris对比](#2. SIFT vs Harris对比)
- [3. Harris的局限性图示](#3. Harris的局限性图示)
- 二、SIFT工作原理简介
-
- [1. 尺度不变性实现](#1. 尺度不变性实现)
- [2. 关键步骤](#2. 关键步骤)
- [三、OpenCV SIFT API使用](#三、OpenCV SIFT API使用)
-
- [1. SIFT在OpenCV中的位置](#1. SIFT在OpenCV中的位置)
- [2. 基本使用流程](#2. 基本使用流程)
- [3. 关键API详解](#3. 关键API详解)
-
- [3.1 创建SIFT检测器](#3.1 创建SIFT检测器)
- [3.2 检测关键点](#3.2 检测关键点)
- [3.3 绘制关键点](#3.3 绘制关键点)
- 四、SIFT特征描述子
-
- [1. 获取特征描述子](#1. 获取特征描述子)
- [2. 完整示例(检测+描述)](#2. 完整示例(检测+描述))
- 五、SIFT特性与应用
-
- [1. SIFT关键特性](#1. SIFT关键特性)
- [2. 主要应用场景](#2. 主要应用场景)
- [3. SIFT优势](#3. SIFT优势)
- [4. SIFT局限性](#4. SIFT局限性)
- 六、与后续学习关联
-
- [1. 特征匹配流程](#1. 特征匹配流程)
- [2. 后续技术](#2. 后续技术)
- 七、总结要点
- [5、OpenCV SIFT特征描述子笔记](#5、OpenCV SIFT特征描述子笔记)
-
- [一、关键点 vs 描述子:概念与区别](#一、关键点 vs 描述子:概念与区别)
-
- [1. 关键点(Keypoints)](#1. 关键点(Keypoints))
- [2. 描述子(Descriptors)](#2. 描述子(Descriptors))
- [3. 两者关系](#3. 两者关系)
- 二、SIFT描述子计算原理
-
- [1. 生成过程](#1. 生成过程)
- [2. 关键特性](#2. 关键特性)
- [三、OpenCV SIFT描述子API](#三、OpenCV SIFT描述子API)
-
- [1. 三种计算方法](#1. 三种计算方法)
- [2. API参数说明](#2. API参数说明)
- 四、代码实现与详解
-
- [1. 完整代码示例](#1. 完整代码示例)
- [2. 描述子数据结构分析](#2. 描述子数据结构分析)
- [3. 关键点详细信息](#3. 关键点详细信息)
- 五、描述子的应用
-
- [1. 特征匹配流程](#1. 特征匹配流程)
- [2. 匹配方法(后续课程)](#2. 匹配方法(后续课程))
- [3. 实际应用场景](#3. 实际应用场景)
- 六、高级应用技巧
-
- [1. 描述子可视化](#1. 描述子可视化)
- [2. 描述子匹配基础](#2. 描述子匹配基础)
- 七、常见问题与解决方案
-
- [1. 描述子维度问题](#1. 描述子维度问题)
- [2. 内存占用问题](#2. 内存占用问题)
- [3. 计算效率问题](#3. 计算效率问题)
- 八、总结要点
- [6、OpenCV SURF特征检测笔记](#6、OpenCV SURF特征检测笔记)
-
- 一、SURF概述
-
- [1. SURF定义](#1. SURF定义)
- [2. SURF vs SIFT对比](#2. SURF vs SIFT对比)
- [3. SURF优势](#3. SURF优势)
- 二、SURF实现原理简析
-
- [1. 特征检测(加速原理)](#1. 特征检测(加速原理))
- [2. 描述子计算](#2. 描述子计算)
- [三、OpenCV SURF API使用](#三、OpenCV SURF API使用)
-
- [1. 基本使用步骤](#1. 基本使用步骤)
- [2. SURF_create参数详解](#2. SURF_create参数详解)
- 四、代码实现与比较
-
- [1. SURF完整示例](#1. SURF完整示例)
- [2. SURF与SIFT对比代码](#2. SURF与SIFT对比代码)
- [3. SURF参数调优示例](#3. SURF参数调优示例)
- 五、SURF在不同OpenCV版本中的使用
-
- [1. OpenCV 3.x版本](#1. OpenCV 3.x版本)
- [2. OpenCV 4.x版本](#2. OpenCV 4.x版本)
- [3. 版本兼容性处理](#3. 版本兼容性处理)
- 六、SURF实际应用场景
-
- [1. 实时应用](#1. 实时应用)
- [2. 性能敏感场景](#2. 性能敏感场景)
- [3. 与SIFT选择建议](#3. 与SIFT选择建议)
- 七、常见问题与解决方案
-
- [1. 无法创建SURF检测器](#1. 无法创建SURF检测器)
- [2. 特征点数量不合适](#2. 特征点数量不合适)
- [3. 计算速度仍不够快](#3. 计算速度仍不够快)
- 八、总结要点
- [7、OpenCV ORB特征检测笔记](#7、OpenCV ORB特征检测笔记)
-
- 一、ORB概述
-
- [1. ORB定义](#1. ORB定义)
- [2. ORB vs SIFT vs SURF对比](#2. ORB vs SIFT vs SURF对比)
- [3. ORB设计哲学](#3. ORB设计哲学)
- [4. ORB组成技术详解](#4. ORB组成技术详解)
- 二、ORB工作原理简析
-
- [1. 特征检测(oFAST)](#1. 特征检测(oFAST))
- [2. 描述子计算(rBRIEF)](#2. 描述子计算(rBRIEF))
- [三、OpenCV ORB API使用](#三、OpenCV ORB API使用)
-
- [1. 基本使用步骤](#1. 基本使用步骤)
- [2. ORB_create参数详解](#2. ORB_create参数详解)
- 四、代码实现与对比
-
- [1. ORB完整示例](#1. ORB完整示例)
- [2. 三种算法性能对比](#2. 三种算法性能对比)
- [3. ORB参数调优示例](#3. ORB参数调优示例)
- 五、ORB在实际应用中的特点
-
- [1. 描述子特性](#1. 描述子特性)
- [2. 实时性表现](#2. 实时性表现)
- 六、算法选择指南
-
- [1. 选择标准](#1. 选择标准)
- [2. 场景建议](#2. 场景建议)
- [3. 性能权衡关系图](#3. 性能权衡关系图)
- 七、常见问题与解决方案
-
- [1. ORB特征点数量不足](#1. ORB特征点数量不足)
- [2. ORB实时性不够](#2. ORB实时性不够)
- [3. 特征匹配效果差](#3. 特征匹配效果差)
- 八、总结与最佳实践
-
- [1. ORB核心优势总结](#1. ORB核心优势总结)
- [2. 使用建议](#2. 使用建议)
- [3. 未来发展](#3. 未来发展)
- [8、OpenCV BF暴力特征匹配笔记](#8、OpenCV BF暴力特征匹配笔记)
-
- 一、特征匹配概述
-
- [1. 匹配方法分类](#1. 匹配方法分类)
- [2. 匹配流程](#2. 匹配流程)
- 二、BF暴力匹配原理
-
- [1. 工作原理](#1. 工作原理)
- [2. 数学表达](#2. 数学表达)
- [三、OpenCV BF匹配API详解](#三、OpenCV BF匹配API详解)
-
- [1. 匹配器创建](#1. 匹配器创建)
- [2. 距离测量类型详解](#2. 距离测量类型详解)
- [3. 匹配执行](#3. 匹配执行)
- [4. 绘制匹配结果](#4. 绘制匹配结果)
- 四、代码实现步骤
-
- [1. 基础BF匹配实现](#1. 基础BF匹配实现)
- [2. 完整的BF匹配代码(含错误处理)](#2. 完整的BF匹配代码(含错误处理))
- [3. 不同特征检测器的匹配示例](#3. 不同特征检测器的匹配示例)
- 五、匹配优化技术
-
- [1. 距离筛选](#1. 距离筛选)
- [2. 交叉检查(Cross-Check)](#2. 交叉检查(Cross-Check))
- [3. 匹配结果分析](#3. 匹配结果分析)
- 六、实际应用示例
-
- [1. 图像搜索(以图搜图)](#1. 图像搜索(以图搜图))
- [2. 对象识别与定位](#2. 对象识别与定位)
- 七、BF匹配的优缺点
-
- [1. 优点](#1. 优点)
- [2. 缺点](#2. 缺点)
- [3. 适用场景](#3. 适用场景)
- 八、总结与最佳实践
-
- [1. 关键步骤回顾](#1. 关键步骤回顾)
- [2. 参数选择建议](#2. 参数选择建议)
- [3. 性能优化技巧](#3. 性能优化技巧)
- [4. 下一步学习方向](#4. 下一步学习方向)
- [9、OpenCV FLANN特征匹配笔记](#9、OpenCV FLANN特征匹配笔记)
-
- 一、FLANN特征匹配概述
-
- [1. FLANN定义](#1. FLANN定义)
- [2. 适用场景对比](#2. 适用场景对比)
- 二、FLANN匹配步骤
-
- [1. 基本流程](#1. 基本流程)
- [2. 与BF匹配的步骤对比](#2. 与BF匹配的步骤对比)
- 三、FLANN匹配参数详解
-
- [1. 创建匹配器:`FlannBasedMatcher`](#1. 创建匹配器:
FlannBasedMatcher) -
- [1.1 `index_params`(索引参数)](#1.1
index_params(索引参数)) - [1.2 `search_params`(搜索参数)](#1.2
search_params(搜索参数))
- [1.1 `index_params`(索引参数)](#1.1
- [2. 执行匹配:`knnMatch()`](#2. 执行匹配:
knnMatch()) - [3. `DMatch`对象属性](#3.
DMatch对象属性) - [4. 绘制匹配结果:`drawMatchesKnn()`](#4. 绘制匹配结果:
drawMatchesKnn())
- [1. 创建匹配器:`FlannBasedMatcher`](#1. 创建匹配器:
- 四、代码实战
-
- [1. 完整代码示例(使用SIFT特征)](#1. 完整代码示例(使用SIFT特征))
- [2. 使用ORB特征的FLANN匹配](#2. 使用ORB特征的FLANN匹配)
- [3. 匹配过滤(Ratio Test)](#3. 匹配过滤(Ratio Test))
- 五、性能优化与注意事项
-
- [1. 参数调优建议](#1. 参数调优建议)
- [2. 特征描述子类型与算法选择](#2. 特征描述子类型与算法选择)
- [3. 错误匹配处理](#3. 错误匹配处理)
- 六、FLANN与BF匹配对比实验
-
- [1. 速度对比](#1. 速度对比)
- [2. 精度对比](#2. 精度对比)
- 七、常见问题与解决方案
-
- [1. 算法类型选择错误](#1. 算法类型选择错误)
- [2. 匹配结果过多或过少](#2. 匹配结果过多或过少)
- [3. 匹配速度慢](#3. 匹配速度慢)
- 八、总结
-
- [1. 核心要点](#1. 核心要点)
- [2. 选择建议](#2. 选择建议)
- [3. 扩展学习](#3. 扩展学习)
1、OpenCV 特征检测入门笔记
一、特征检测的应用场景
1. 图像搜索(以图搜图)
- 工作原理:提取图像的特征点(而非整张图片)进行匹配
- 优势:特征点数据量小(几KB或字节级别),大幅提升搜索效率
- 流程 :
- 搜索引擎预先提取并存储海量图片的特征点到数据库
- 用户提交图片时,检测该图片的特征点
- 在特征库中进行匹配搜索
2. 拼图游戏
- 通过识别图像中的特征区域(如头部、手部、特定物体)进行拼接
- 人类拼图时也是基于特征识别:先找显著特征点,再围绕组装
- 特征要求 :
- 唯一性(不能所有图都有相同特征)
- 可追踪性(能被持续识别)
- 可比较性(不同特征可区分)
3. 全景图像拼接
- 通过连续拍摄不同角度的照片,利用重叠区域的特征点进行拼接
- 使拍摄范围接近或超过人眼视野(180°/360°)
- 关键:相邻图片必须有重叠部分,以便特征匹配
二、什么是图像特征?
定义
- 有意义的图像区域 ,具有:
- 独特性
- 易识别性
- 可比较性
- 常见类型:角点、斑点、高密度区域
特征识别难度对比(通过拼图示例说明)
| 类型 | 识别难度 | 说明 |
|---|---|---|
| 平坦区域(如纯色块) | 困难 | 缺乏唯一性,无法定位 |
| 边缘 | 中等 | 可大致定位范围,但无法精确定位(边缘太长) |
| 角点 | 容易 | 特征显著,可精确定位 |
结论:角点是图像中最显著、最容易定位的特征。
三、角点(Corner)作为关键特征
什么是角点?
- 灰度梯度最大值对应的像素
- 两条线的交叉点
- 极值点(一阶导数最大,二阶导数为零)
为什么角点重要?
- 对人类:直观易辨认(如拼图中的角落、物体突出部分)
- 对计算机:可通过数学计算精确识别(灰度梯度、导数等)
四、总结与核心要点
-
特征检测的核心价值 :
将图像信息压缩为少量关键点,大幅提升处理效率。
-
角点是特征的典型代表 :
具有唯一性、易识别、可精确定位,是图像匹配、拼接、搜索的关键依据。
-
学习路径 :
理解基本概念 → 学习OpenCV相关API → 实践项目(如图像拼接)
下一步:基于这些概念,后续将学习OpenCV提供的特征检测API,并实现图像拼接等项目应用。
附注:理解"特征"是图像处理从像素级操作走向语义理解的关键一步,角点检测是其中最经典且基础的方法之一。
2、OpenCV Harris角点检测笔记
一、Harris角点检测原理
1. 基本思想
通过移动检测窗口,观察窗口内像素值的变化情况来判断是否为角点:
2. 三种检测情况
| 情况 | 窗口移动方向 | 像素变化 | 判断结果 | 示意图 |
|---|---|---|---|---|
| 平坦区域 | 任何方向移动 | 无变化 | 非角点 | 窗口在任何方向移动,像素值不变 |
| 边缘区域 | 沿边缘方向移动 | 无变化 | 边缘 | 沿边缘平行移动不变,垂直移动有变化 |
| 角点区域 | 任何方向移动 | 都有变化 | 角点 | 所有方向移动都会引起像素值变化 |
3. 数学原理简化
- 计算窗口内像素值变化量:
E(u,v) = Σ w(x,y)[I(x+u,y+v)-I(x,y)]² - 使用泰勒展开和矩阵运算,最终得到角点响应函数:
R = det(M) - k·(trace(M))²det(M):矩阵M的行列式trace(M):矩阵M的迹k:经验常数(0.02-0.04)
二、OpenCV Harris角点检测API
函数原型
python
dst = cv2.cornerHarris(src, blockSize, ksize, k[, dst[, borderType]])参数详解
| 参数 | 类型 | 说明 |
|---|---|---|
src |
输入图像 | 必须是灰度图(单通道8位或浮点型) |
blockSize |
int | 检测窗口大小(邻域大小) |
ksize |
int | Sobel算子的卷积核大小(必须为奇数) |
k |
float | 角点检测方程中的自由参数,经验值范围:0.02-0.04 |
dst |
输出图像 | 存储角点检测结果的图像(通常与输入图像同大小) |
borderType |
int | 边界填充类型(可选,默认cv2.BORDER_DEFAULT) |
关键点说明
- 输入图像必须为灰度图 :检测前需使用
cv2.cvtColor()转换 - blockSize大小影响:值越大,检测的角点越少但更显著
- ksize通常设为3:Sobel算子卷积核大小
- k值经验性:推荐0.04,可根据实际效果调整
三、代码实现步骤
1. 基本流程
python
import cv2
import numpy as np
# 1. 读取图像
img = cv2.imread('chess.png')
# 2. 转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 3. Harris角点检测
blockSize = 2 # 检测窗口大小
ksize = 3 # Sobel卷积核大小
k = 0.04 # 经验参数
dst = cv2.cornerHarris(gray, blockSize, ksize, k)
# 4. 标记角点(在原图上显示)
# 角点响应值大于最大响应值的1%时标记为红色
img[dst > 0.01 * dst.max()] = [0, 0, 255] # BGR格式:红色
# 5. 显示结果
cv2.imshow('Harris Corners', img)
cv2.waitKey(0)
cv2.destroyAllWindows()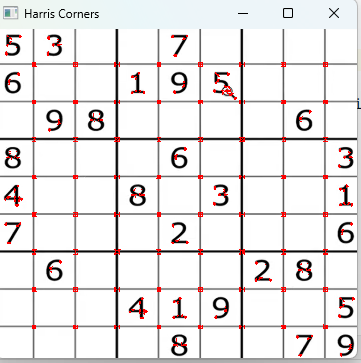
2. 参数调整技巧
- 增加blockSize:检测更显著的角点,但可能漏掉细节
- 调整k值 :
- 增大k值(接近0.04):减少角点数量
- 减小k值(接近0.02):增加角点数量
- 阈值调整 :
0.01 * dst.max()中的系数可调,影响角点数量
四、实际应用注意事项
1. 图像预处理
- 可先进行高斯模糊减少噪声干扰:
cv2.GaussianBlur() - 确保图像有足够对比度
2. Harris角点检测的优缺点
优点:
- 计算简单,实时性较好
- 对图像旋转、亮度变化具有一定不变性
- 对噪声有一定鲁棒性
缺点:
- 对尺度变化敏感(缩放后角点可能变化)
- k值为经验参数,需要调整
- 只能检测角点,不能获取角点描述符(无法用于匹配)
3. 与后续学习的关联
- Harris是基础角点检测方法
- 后续将学习更先进的SIFT、SURF、ORB等特征检测算法
- 理解Harris有助于理解更复杂算法的原理
五、总结要点
- Harris检测原理:通过检测窗口移动时像素值的变化模式判断角点
- 三种区域类型:平坦区域、边缘区域、角点区域
- API关键参数 :
blockSize:检测窗口大小ksize:Sobel卷积核大小(通常为3)k:经验参数(0.02-0.04,常用0.04)
- 必须步骤:输入图像需转换为灰度图
- 结果显示:通过阈值筛选显著角点并在原图标记
学习建议 :理解原理后,尝试调整参数观察角点检测效果的变化,特别是blockSize和k值对结果的影响,为后续学习更复杂的特征检测算法打下基础。
3、OpenCV Shi-Tomasi角点检测笔记
一、Shi-Tomasi角点检测概述
1. 与Harris的关系
- 联系:基于Harris角点检测算法改进而来,一脉相承
- 区别 :解决了Harris需要手动调整经验参数
k的问题 - 改进点 :自动确定角点质量,无需设置
k值(0.02-0.04)
2. 核心优势
- 对开发者更友好,参数设置更简单
- 检测效果与Harris相当或更好
- 一个API兼容两种检测方法(Shi-Tomasi和Harris)
二、OpenCV API详解
函数原型
python
corners = cv2.goodFeaturesToTrack(image, maxCorners, qualityLevel, minDistance[, corners[, mask[, blockSize[, useHarrisDetector[, k]]]]])参数详细说明
| 参数 | 类型 | 说明 | 默认值/建议值 |
|---|---|---|---|
image |
输入图像 | 必须是灰度图像(单通道8位或浮点型) | - |
maxCorners |
int | 返回的最大角点数量,0表示返回所有检测到的角点 | 0(全部返回) |
qualityLevel |
float | 角点质量水平(0-1之间),低于此阈值的角点被拒绝 | 0.01-0.1 |
minDistance |
int | 角点之间的最小欧式距离(像素单位) | 根据图像大小调整 |
mask |
可选 | 指定检测区域的掩码图像 | None |
blockSize |
int | 计算角点时考虑的邻域大小 | 3 |
useHarrisDetector |
bool | True:使用Harris角点检测,False:使用Shi-Tomasi | False |
k |
float | Harris检测器的自由参数,仅当useHarrisDetector=True时有效 | 0.04 |
三、各参数作用详解
1. qualityLevel(角点质量)
- 作用:过滤弱角点,只保留显著角点
- 原理 :计算所有角点的响应值,只保留大于
max(response) × qualityLevel的角点 - 类比 :类似Harris检测中的
dst > 0.01 * dst.max()判断
2. minDistance(最小距离)
- 作用:控制角点密度,避免在密集区域检测过多角点
- 原理 :以每个角点为中心,半径为
minDistance的区域内只保留一个最强角点 - 效果:值越大,角点越稀疏;值越小,角点越密集
3. useHarrisDetector(检测器选择)
- False(默认):使用Shi-Tomasi角点检测
- True :使用Harris角点检测(需设置
k值)
4. maxCorners(最大角点数)
- 0:返回所有符合条件的角点
- N:只返回响应最强的N个角点
四、代码实现步骤
1. 基本Shi-Tomasi角点检测
python
import cv2
import numpy as np
# 1. 读取图像并转换为灰度图
img = cv2.imread('chess.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 2. Shi-Tomasi角点检测参数设置
maxCorners = 1000 # 最大角点数量(0表示无限制)
qualityLevel = 0.01 # 角点质量水平(0.01-0.1)
minDistance = 10 # 角点间最小距离(像素)
# 3. 执行角点检测
corners = cv2.goodFeaturesToTrack(gray, maxCorners, qualityLevel, minDistance)
# 4. 转换角点坐标为整数类型
corners = np.int(corners) # 将浮点坐标转换为整数坐标
# 5. 在原图上绘制角点
for i in corners:
x, y = i.ravel() # 将多维数组转换为一维,获取x,y坐标
cv2.circle(img, (x, y), 3, ( 0, 0,255), -1) # 绘制红色实心圆
# 6. 显示结果
cv2.imshow('Shi-Tomasi Corners', img)
cv2.waitKey(0)
cv2.destroyAllWindows()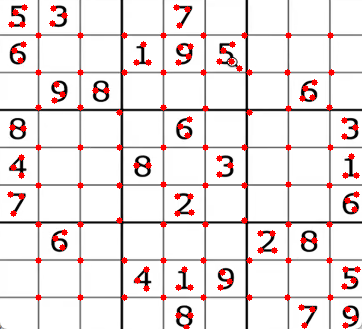
2. 使用Harris角点检测模式
python
# 使用Harris角点检测(通过useHarrisDetector参数切换)
corners = cv2.goodFeaturesToTrack(
gray,
maxCorners=1000,
qualityLevel=0.01,
minDistance=10,
useHarrisDetector=True, # 启用Harris检测器
k=0.04 # Harris的k参数
)五、参数调整效果对比
1. qualityLevel影响
- 增大(如0.1):只保留最显著的角点,数量减少
- 减小(如0.001):保留更多角点,包括较弱的角点
2. minDistance影响
- 增大(如20):角点分布更稀疏
- 减小(如5):角点分布更密集
3. maxCorners影响
- 设为0:返回所有检测到的角点
- 设为N:只返回响应最强的N个角点,控制检测数量
六、Shi-Tomasi vs Harris比较
| 特性 | Shi-Tomasi | Harris |
|---|---|---|
| 参数设置 | 简单,无需经验参数k |
需要调整经验参数k(0.02-0.04) |
| 检测原理 | 最小特征值法 | 角点响应函数R |
| 使用频率 | 更常用 | 较少直接使用 |
| API | goodFeaturesToTrack(默认) |
cornerHarris或goodFeaturesToTrack(useHarrisDetector=True) |
| 检测结果 | 通常检测到更多角点 | 角点数量相对较少 |
七、实际应用建议
1. 参数选择技巧
- 一般应用 :使用默认Shi-Tomasi检测(无需设置
k) - 角点数量控制 :
- 先设
maxCorners=0查看所有角点 - 根据需求调整
qualityLevel和minDistance - 最后可用
maxCorners限制总数
- 先设
- 密集区域 :增大
minDistance避免角点过密
2. 预处理优化
python
# 可先进行高斯模糊减少噪声
gray = cv2.GaussianBlur(gray, (5, 5), 0)
# 再进行角点检测
corners = cv2.goodFeaturesToTrack(gray, maxCorners, qualityLevel, minDistance)3. 性能考虑
- Shi-Tomasi计算效率高,适合实时应用
- 对于大图像,适当调整参数可提高处理速度
八、总结要点
- Shi-Tomasi是Harris的改进 :解决了需要手动调整
k值的问题 - 主要API :
cv2.goodFeaturesToTrack(),一个函数支持两种检测方法 - 关键参数 :
qualityLevel:控制角点质量阈值(0.01-0.1)minDistance:控制角点间最小距离,避免过密useHarrisDetector:True使用Harris,False使用Shi-Tomasi
- 坐标转换 :检测结果需用
np.int0()转换为整数坐标 - 绘制方法 :使用
cv2.circle()在原图上标记角点
实践建议 :通过调整qualityLevel和minDistance参数,观察不同设置下角点检测结果的变化,理解各参数对检测效果的影响。Shi-Tomasi因其简单易用,在实际项目中更常被采用。
4、OpenCV SIFT特征检测笔记
一、SIFT特征检测概述
1. SIFT定义
- SIFT:Scale-Invariant Feature Transform(尺度不变特征变换)
- 核心特性 :具有尺度不变性 和旋转不变性
- 主要目的:解决Harris角点检测在图像缩放后无法正确检测的问题
2. SIFT vs Harris对比
| 特性 | SIFT | Harris |
|---|---|---|
| 尺度不变性 | ✅ 优秀 | ❌ 较差 |
| 旋转不变性 | ✅ 优秀 | ✅ 良好 |
| 缩放影响 | 缩放后仍能检测相同特征点 | 缩放后可能无法检测原角点 |
| 应用场景 | 图像缩放、旋转、部分遮挡等复杂情况 | 固定尺度下的角点检测 |
3. Harris的局限性图示
原图(正常尺寸):窗口检测到角点
┌─────┐
│ • │ ← 角点
└─────┘
放大后:同一个区域
┌─────────────────┐
│ │
│ ───────────── │ ← 变成边缘
│ │
└─────────────────┘问题:放大后,原角点区域变成边缘,Harris无法检测为角点
二、SIFT工作原理简介
1. 尺度不变性实现
- 在不同尺度空间(高斯金字塔)中检测关键点
- 通过DOG(Difference of Gaussians)检测尺度空间极值点
- 自动确定特征点的最佳尺度
2. 关键步骤
- 尺度空间极值检测:在不同尺度寻找稳定特征点
- 关键点定位:精确定位关键点位置和尺度
- 方向分配:为每个关键点分配方向,实现旋转不变性
- 关键点描述:生成128维特征向量描述子
三、OpenCV SIFT API使用
1. SIFT在OpenCV中的位置
- 扩展模块 :
cv2.xfeatures2d - 原因:SIFT有专利问题,OpenCV将其放在扩展模块中
- 安装:确保安装了OpenCV的contrib版本
2. 基本使用流程
python
import cv2
import numpy as np
# 1. 读取图像并灰度化
img = cv2.imread('chess.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 2. 创建SIFT检测器对象
sift = cv2.xfeatures2d.SIFT_create()
# 3. 检测关键点
keypoints = sift.detect(gray, None)
# 4. 绘制关键点
# 方法1:只绘制关键点位置
img_kp = cv2.drawKeypoints(gray, keypoints, img)
# 方法2:绘制关键点位置和方向
img_kp = cv2.drawKeypoints(gray, keypoints, img,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# 5. 显示结果
cv2.imshow('SIFT Keypoints', img_kp)
cv2.waitKey(0)
cv2.destroyAllWindows()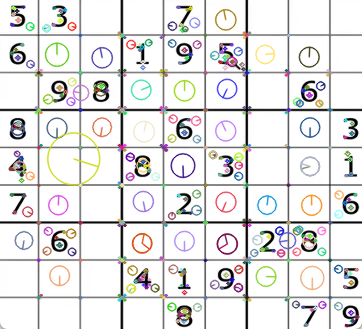
3. 关键API详解
3.1 创建SIFT检测器
可以直接调用了,不需要xfeatures2d
python
sift = cv2.xfeatures2d.SIFT_create([, nfeatures[, nOctaveLayers[, contrastThreshold[, edgeThreshold[, sigma]]]]])nfeatures:保留的最佳特征数量(默认0,表示保留所有)nOctaveLayers:金字塔每组层数(默认3)contrastThreshold:对比度阈值,过滤弱特征(默认0.04)edgeThreshold:边缘阈值,过滤边缘响应(默认10)sigma:高斯模糊初始值(默认1.6)
3.2 检测关键点
python
keypoints = sift.detect(image[, mask])image:输入图像(灰度图)mask:指定搜索区域的掩码(None表示全图)- 返回:
keypoints列表,每个关键点包含:pt:坐标(x, y)size:关键点邻域直径angle:方向(弧度)response:响应强度octave:金字塔层级class_id:对象ID
3.3 绘制关键点
python
outImage = cv2.drawKeypoints(image, keypoints, outImage[, color[, flags]])flags选项:cv2.DRAW_MATCHES_FLAGS_DEFAULT:只绘制关键点位置cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS:绘制关键点位置、尺度和方向cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS:不绘制单个关键点cv2.DRAW_MATCHES_FLAGS_DRAW_OVER_OUTIMG:不创建新图像,直接在输出图像上绘制
四、SIFT特征描述子
1. 获取特征描述子
python
keypoints, descriptors = sift.detectAndCompute(image, mask)- 一步完成:检测关键点并计算描述子
descriptors:128维特征向量,用于特征匹配- 每个关键点对应一个描述子向量
2. 完整示例(检测+描述)
python
import cv2
import numpy as np
# 读取图像
img = cv2.imread('chess.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建SIFT对象,可以直接调用
#sift = cv2.xfeatures2d.SIFT_create()
sift = cv2.SIFT_create()
# 检测关键点并计算描述子
keypoints, descriptors = sift.detectAndCompute(gray, None)
print(f"检测到 {len(keypoints)} 个关键点")
print(f"描述子维度: {descriptors.shape}") # (关键点数, 128)
# 绘制关键点
img_kp = cv2.drawKeypoints(img, keypoints, None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# 显示
cv2.imshow('SIFT Features', img_kp)
cv2.waitKey(0)
cv2.destroyAllWindows()五、SIFT特性与应用
1. SIFT关键特性
- 尺度不变性:对图像缩放鲁棒
- 旋转不变性:对图像旋转鲁棒
- 光照不变性:对光照变化有一定鲁棒性
- 视角不变性:对小视角变化有一定鲁棒性
2. 主要应用场景
- 图像匹配与识别:通过特征描述子匹配不同图像中的相同物体
- 三维重建:从多视角图像中重建三维结构
- 图像拼接:拼接全景图像
- 目标跟踪:跟踪视频序列中的目标
- 图像检索:基于内容的图像检索系统
3. SIFT优势
- 对尺度、旋转、光照变化鲁棒
- 特征描述子区分能力强
- 特征点数量适中,计算效率较高
4. SIFT局限性
- 计算复杂度较高,不适合实时应用
- 对模糊图像和边缘特征检测效果较差
- 专利问题(已过期,但某些版本仍有限制)
六、与后续学习关联
1. 特征匹配流程
图像A → SIFT检测 → 关键点 + 描述子 → 匹配器 → 匹配结果
图像B → SIFT检测 → 关键点 + 描述子 ↗2. 后续技术
- 特征匹配:使用FLANN或BFMatcher进行特征匹配
- 图像拼接:基于匹配的特征点进行图像配准和融合
- 目标识别:通过特征匹配识别特定物体
七、总结要点
- SIFT核心优势:尺度不变性,解决Harris在图像缩放后无法检测的问题
- OpenCV实现 :位于
cv2.xfeatures2d扩展模块 - 基本步骤 :
- 创建SIFT检测器:
sift = cv2.xfeatures2d.SIFT_create() - 检测关键点:
keypoints = sift.detect(gray, None) - 绘制关键点:
cv2.drawKeypoints()
- 创建SIFT检测器:
- 特征描述子 :使用
detectAndCompute()同时获取关键点和128维描述子 - 应用方向:图像匹配、三维重建、图像拼接等高级计算机视觉任务
学习建议:
- 比较SIFT和Harris在不同缩放比例图像上的检测效果
- 调整SIFT参数(如
contrastThreshold)观察关键点数量变化 - 为后续的特征匹配学习打下基础,理解描述子的重要性
5、OpenCV SIFT特征描述子笔记
一、关键点 vs 描述子:概念与区别
1. 关键点(Keypoints)
包含信息:
- 位置:坐标(x, y)
- 大小:关键点邻域直径(尺度信息)
- 方向:角度(弧度),用于旋转不变性
作用:
- 标识图像中具有显著特征的位置
- 用于定位特征位置
2. 描述子(Descriptors)
包含信息:
- 关键点周围像素的梯度方向统计信息
- 128维向量(SIFT描述子)
- 具有光照、旋转、尺度不变性
作用:
- 量化描述关键点周围的局部特征
- 用于特征匹配(计算两个特征点是否相似)
3. 两者关系
一个关键点 → 对应一个描述子
位置信息 → 周围特征信息
(在哪) → (长什么样)
↓
用于定位 → 用于匹配二、SIFT描述子计算原理
1. 生成过程
- 确定关键点区域:根据关键点的尺度和方向
- 划分子区域:将关键点邻域划分为4×4=16个子区域
- 计算方向直方图:每个子区域计算8个方向的梯度直方图
- 生成描述向量:16×8=128维特征向量
2. 关键特性
- 尺度不变性:基于关键点尺度调整邻域大小
- 旋转不变性:根据关键点方向旋转坐标
- 光照不变性:对梯度进行归一化处理
三、OpenCV SIFT描述子API
1. 三种计算方法
方法1:分别计算(两步)
python
# 第一步:检测关键点
keypoints = sift.detect(gray, None)
# 第二步:计算描述子
keypoints, descriptors = sift.compute(gray, keypoints)方法2:同时计算(一步,推荐)
python
keypoints, descriptors = sift.detectAndCompute(gray, None)方法对比
| 方法 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|
detect() + compute() |
分步操作,更灵活 | 效率较低,代码复杂 | 需要分步处理时 |
detectAndCompute() |
效率高,代码简洁 | 一次性获取所有信息 | 大多数场景(推荐) |
2. API参数说明
python
# detectAndCompute方法参数
keypoints, descriptors = sift.detectAndCompute(image, mask)image:输入灰度图像mask:感兴趣区域掩码(None表示全图)- 返回值:
keypoints:关键点列表descriptors:描述子矩阵,形状为(n_keypoints, 128)
四、代码实现与详解
1. 完整代码示例
python
import cv2
import numpy as np
# 1. 读取图像并灰度化
img = cv2.imread('chess.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 2. 创建SIFT检测器(兼容不同版本)
try:
sift = cv2.SIFT_create() # OpenCV 4.4.0+
except AttributeError:
sift = cv2.xfeatures2d.SIFT_create() # 旧版本
# 3. 同时检测关键点和计算描述子(推荐方法)
keypoints, descriptors = sift.detectAndCompute(gray, None)
# 4. 显示关键点和描述子信息
print(f"检测到 {len(keypoints)} 个关键点")
print(f"描述子矩阵形状: {descriptors.shape}") # (关键点数, 128)
# 查看第一个关键点的描述子
if len(descriptors) > 0:
print(f"第一个关键点描述子(前10个值): {descriptors[0][:10]}")
print(f"第一个关键点描述子维度: {len(descriptors[0])}")
# 5. 绘制关键点
img_kp = cv2.drawKeypoints(img, keypoints, None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# 6. 显示结果
cv2.imshow('SIFT Keypoints with Descriptors', img_kp)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 7. 可选:保存描述子到文件
np.save('sift_descriptors.npy', descriptors)
print("描述子已保存为 sift_descriptors.npy")

2. 描述子数据结构分析
python
# 查看描述子的详细信息
print("=== 描述子信息 ===")
print(f"类型: {type(descriptors)}")
print(f"数据类型: {descriptors.dtype}")
print(f"形状: {descriptors.shape}")
print(f"总元素数: {descriptors.size}")
# 分析描述子值范围
print(f"最小值: {descriptors.min():.4f}")
print(f"最大值: {descriptors.max():.4f}")
print(f"平均值: {descriptors.mean():.4f}")
print(f"标准差: {descriptors.std():.4f}")
# 查看前3个关键点的描述子(部分)
print("\n=== 前3个关键点描述子(前5个值) ===")
for i in range(min(3, len(descriptors))):
print(f"关键点 {i}: {descriptors[i][:5]}")3. 关键点详细信息
python
# 查看关键点的详细信息
print("\n=== 关键点信息 ===")
print(f"关键点数量: {len(keypoints)}")
# 查看前3个关键点的属性
for i, kp in enumerate(keypoints[:3]):
print(f"\n关键点 {i}:")
print(f" 位置: ({kp.pt[0]:.2f}, {kp.pt[1]:.2f})")
print(f" 大小: {kp.size:.2f}")
print(f" 角度: {kp.angle:.2f}°")
print(f" 响应值: {kp.response:.4f}")
print(f" 层级: {kp.octave}")五、描述子的应用
1. 特征匹配流程
图像A → SIFT检测 → 关键点A + 描述子A → 匹配器 → 匹配对
图像B → SIFT检测 → 关键点B + 描述子B ↗2. 匹配方法(后续课程)
- 暴力匹配器:Brute-Force Matcher
- FLANN匹配器:基于树的近似最近邻搜索
- 比率测试:过滤错误匹配
3. 实际应用场景
- 图像检索:通过描述子匹配查找相似图像
- 图像拼接:匹配相邻图像的特征进行拼接
- 目标识别:匹配模板与场景中的目标
- 三维重建:匹配多视图中的对应点
六、高级应用技巧
1. 描述子可视化
python
# 可视化描述子(热力图)
import matplotlib.pyplot as plt
# 将描述子重新形状为16x8的可视化形式
if len(descriptors) > 0:
desc_vis = descriptors[0].reshape(16, 8)
plt.figure(figsize=(10, 6))
plt.imshow(desc_vis, cmap='hot', interpolation='nearest')
plt.colorbar()
plt.title('SIFT描述子可视化(第一个关键点)')
plt.xlabel('方向箱(8个方向)')
plt.ylabel('空间箱(16个子区域)')
plt.show()2. 描述子匹配基础
python
# 两个图像的特征匹配示例框架
def match_features(img1_path, img2_path):
# 读取图像
img1 = cv2.imread(img1_path)
img2 = cv2.imread(img2_path)
# 转换为灰度
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 创建SIFT
sift = cv2.SIFT_create()
# 检测关键点和计算描述子
kp1, des1 = sift.detectAndCompute(gray1, None)
kp2, des2 = sift.detectAndCompute(gray2, None)
# 创建匹配器(后续课程详细讲解)
bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=True)
# 匹配描述子
matches = bf.match(des1, des2)
# 按距离排序
matches = sorted(matches, key=lambda x: x.distance)
# 绘制匹配结果
img_matches = cv2.drawMatches(img1, kp1, img2, kp2,
matches[:50], None, flags=2)
return img_matches七、常见问题与解决方案
1. 描述子维度问题
- 问题:不同关键点的描述子维度不一致
- 解决:SIFT固定为128维,确保使用正确版本
2. 内存占用问题
- 问题:大量关键点导致描述子内存占用大
- 解决 :
- 使用
maxCorners参数限制关键点数量 - 过滤低响应值的弱关键点
- 使用
3. 计算效率问题
- 问题:SIFT计算较慢
- 解决 :
- 使用
detectAndCompute()而不是分步计算 - 考虑使用ORB等更快算法(后续课程)
- 使用
八、总结要点
-
关键点与描述子关系:
- 关键点:位置、大小、方向(定位)
- 描述子:128维向量,描述局部特征(匹配)
-
SIFT描述子特性:
- 128维向量,具有尺度、旋转、光照不变性
- 基于关键点周围梯度方向统计
-
OpenCV API:
detectAndCompute():同时获取关键点和描述子(推荐)- 返回值:
keypoints列表和descriptors矩阵
-
后续应用:
- 描述子用于特征匹配
- 是图像拼接、目标识别等高级任务的基础
-
最佳实践:
- 使用一步法
detectAndCompute()提高效率 - 理解描述子数据结构便于后续处理
- 使用一步法
学习建议:
- 运行代码并观察描述子的数据结构和值
- 尝试修改图像,观察描述子的变化
- 为下一节的特征匹配做准备,理解描述子的匹配原理
- 比较不同图像上相同物体的描述子相似性
6、OpenCV SURF特征检测笔记
一、SURF概述
1. SURF定义
- SURF:Speeded Up Robust Features(加速鲁棒特征)
- 目标:在保持SIFT性能的同时,大幅提升计算速度
- 产生背景:为解决SIFT计算速度慢的问题而设计
2. SURF vs SIFT对比
| 特性 | SURF | SIFT |
|---|---|---|
| 计算速度 | ✅ 更快(约快3倍) | ❌ 较慢 |
| 准确性 | ✅ 良好,保留SIFT优点 | ✅ 优秀 |
| 特征检测 | 使用Hessian矩阵近似 | 使用DoG检测 |
| 描述子 | 基于Haar小波响应 | 基于梯度方向直方图 |
| 特征点数量 | 相对较少,避免冗余 | 相对较多 |
| 专利状态 | 有专利限制 | 有专利限制(已过期) |
3. SURF优势
- 计算效率高,适合实时应用
- 对旋转、尺度、光照变化具有鲁棒性
- 特征点数量适中,减少匹配计算量
二、SURF实现原理简析
1. 特征检测(加速原理)
- Hessian矩阵近似:使用积分图像加速Hessian矩阵计算
- 尺度空间构建:使用盒式滤波器(box filter)近似LoG
- 特征点定位:在不同尺度空间寻找Hessian矩阵极值
2. 描述子计算
- 基于Haar小波响应:统计特征点邻域的Haar小波响应
- 方向分配:计算x和y方向的Haar小波响应
- 描述向量:通常64维或128维(比SIFT的128维更紧凑)
三、OpenCV SURF API使用
1. 基本使用步骤
python
import cv2
import numpy as np
# 1. 读取图像并灰度化
img = cv2.imread('chess.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 2. 创建SURF检测器对象
surf = cv2.xfeatures2d.SURF_create([hessianThreshold[, nOctaves[, nOctaveLayers[, extended[, upright]]]]])
# 3. 检测关键点和计算描述子
keypoints, descriptors = surf.detectAndCompute(gray, None)
# 4. 绘制关键点
img_kp = cv2.drawKeypoints(img, keypoints, None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# 5. 显示结果
cv2.imshow('SURF Keypoints', img_kp)
cv2.waitKey(0)
cv2.destroyAllWindows()2. SURF_create参数详解
python
surf = cv2.xfeatures2d.SURF_create(hessianThreshold=100, # Hessian阈值,影响特征点数量
nOctaves=4, # 金字塔组数
nOctaveLayers=3, # 每组层数
extended=False, # 描述子维度:False=64维,True=128维
upright=False) # 是否计算方向:False=计算,True=不计算参数说明:
hessianThreshold:Hessian矩阵阈值,值越大检测到的特征点越少,但更显著nOctaves:金字塔组数(尺度空间层数)nOctaveLayers:每组中的层数extended:描述子维度扩展,False=64维,True=128维upright:是否计算特征点方向,False=计算方向(旋转不变),True=不计算方向(用于无旋转场景)
四、代码实现与比较
1. SURF完整示例
python
import cv2
import numpy as np
import time
def surf_feature_detection(image_path, hessian_threshold=100):
"""SURF特征检测"""
# 读取图像
img = cv2.imread(image_path)
if img is None:
print(f"无法读取图像: {image_path}")
return
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建SURF检测器
try:
surf = cv2.xfeatures2d.SURF_create(hessianThreshold=hessian_threshold)
except AttributeError:
print("错误:无法创建SURF检测器,请确保:")
print("1. 安装了opencv-contrib-python")
print("2. 使用OpenCV 3.x版本(4.x中SURF被移到nonfree模块)")
return
# 检测关键点和计算描述子
start_time = time.time()
keypoints, descriptors = surf.detectAndCompute(gray, None)
end_time = time.time()
print(f"SURF检测时间: {end_time - start_time:.4f}秒")
print(f"检测到 {len(keypoints)} 个关键点")
if descriptors is not None:
print(f"描述子维度: {descriptors.shape[1]}维")
# 绘制关键点
img_kp = cv2.drawKeypoints(img, keypoints, None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
return img_kp, keypoints, descriptors
# 使用示例
img_kp, keypoints, descriptors = surf_feature_detection('chess.png', hessian_threshold=100)
if img_kp is not None:
cv2.imshow('SURF Features', img_kp)
cv2.waitKey(0)
cv2.destroyAllWindows()2. SURF与SIFT对比代码
python
import cv2
import numpy as np
import time
def compare_sift_surf(image_path):
"""比较SIFT和SURF性能"""
img = cv2.imread(image_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
results = {}
# 测试SIFT
print("=== SIFT ===")
try:
sift = cv2.xfeatures2d.SIFT_create()
start = time.time()
kp_sift, des_sift = sift.detectAndCompute(gray, None)
sift_time = time.time() - start
results['SIFT'] = {'time': sift_time, 'keypoints': len(kp_sift)}
print(f"检测时间: {sift_time:.4f}秒")
print(f"关键点数量: {len(kp_sift)}")
except Exception as e:
print(f"SIFT错误: {e}")
# 测试SURF
print("\n=== SURF ===")
try:
surf = cv2.xfeatures2d.SURF_create(hessianThreshold=100)
start = time.time()
kp_surf, des_surf = surf.detectAndCompute(gray, None)
surf_time = time.time() - start
results['SURF'] = {'time': surf_time, 'keypoints': len(kp_surf)}
print(f"检测时间: {surf_time:.4f}秒")
print(f"关键点数量: {len(kp_surf)}")
if des_surf is not None:
print(f"描述子维度: {des_surf.shape[1]}维")
except Exception as e:
print(f"SURF错误: {e}")
# 性能对比
if 'SIFT' in results and 'SURF' in results:
print("\n=== 性能对比 ===")
speedup = results['SIFT']['time'] / results['SURF']['time']
print(f"速度提升: {speedup:.2f}倍")
print(f"SURF比SIFT快 {speedup-1:.2f}倍")
return results
# 运行对比
compare_sift_surf('chess.png')3. SURF参数调优示例
python
import cv2
import matplotlib.pyplot as plt
def test_surf_parameters(image_path):
"""测试不同SURF参数的效果"""
img = cv2.imread(image_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 测试不同Hessian阈值
thresholds = [50, 100, 200, 400]
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
axes = axes.ravel()
for i, thresh in enumerate(thresholds):
# 创建SURF检测器
surf = cv2.xfeatures2d.SURF_create(hessianThreshold=thresh)
# 检测关键点
keypoints, _ = surf.detectAndCompute(gray, None)
# 绘制关键点
img_kp = cv2.drawKeypoints(img, keypoints, None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# 显示
axes[i].imshow(cv2.cvtColor(img_kp, cv2.COLOR_BGR2RGB))
axes[i].set_title(f'Hessian Threshold = {thresh}\nKeypoints = {len(keypoints)}')
axes[i].axis('off')
plt.tight_layout()
plt.show()
# 测试不同参数
test_surf_parameters('chess.png')五、SURF在不同OpenCV版本中的使用
1. OpenCV 3.x版本
python
# 3.x版本(推荐3.4.2.16)
import cv2
# 需要安装opencv-contrib-python
surf = cv2.xfeatures2d.SURF_create(hessianThreshold=100)2. OpenCV 4.x版本
python
# 4.x版本,SURF被移到nonfree模块
# 需要编译OpenCV时开启nonfree选项
# 或者使用早期版本
# 检查是否可用
if cv2.__version__.startswith('4'):
print("OpenCV 4.x版本,SURF可能不可用")
print("建议安装opencv-contrib-python==3.4.2.16")3. 版本兼容性处理
python
def create_surf_detector(hessian_threshold=100):
"""创建SURF检测器(版本兼容)"""
try:
# 尝试OpenCV 3.x方式
surf = cv2.xfeatures2d.SURF_create(hessianThreshold=hessian_threshold)
return surf
except AttributeError:
try:
# 尝试OpenCV 4.x方式(如果编译时开启了nonfree)
surf = cv2.SURF_create(hessianThreshold=hessian_threshold)
return surf
except AttributeError:
print("错误:无法创建SURF检测器")
print("解决方案:")
print("1. 安装OpenCV 3.x: pip install opencv-contrib-python==3.4.2.16")
print("2. 或从源码编译OpenCV并开启nonfree模块")
return None六、SURF实际应用场景
1. 实时应用
- 移动设备上的图像识别
- 视频流中的目标跟踪
- 增强现实(AR)应用
2. 性能敏感场景
- 大规模图像检索系统
- 需要快速响应的工业检测
- 嵌入式视觉系统
3. 与SIFT选择建议
选择算法时考虑:
1. 实时性要求高 → 选择SURF
2. 准确度要求极高 → 选择SIFT
3. 资源有限(嵌入式) → 考虑ORB(后续课程)
4. 专利可接受性 → SURF和SIFT都有专利问题七、常见问题与解决方案
1. 无法创建SURF检测器
问题:
python
AttributeError: module 'cv2' has no attribute 'xfeatures2d'解决方案:
bash
# 安装正确版本
pip uninstall opencv-python opencv-contrib-python
pip install opencv-contrib-python==3.4.2.162. 特征点数量不合适
调整方法:
- 减少特征点:提高
hessianThreshold - 增加特征点:降低
hessianThreshold
3. 计算速度仍不够快
优化策略:
- 降低图像分辨率
- 使用ROI(感兴趣区域)限制检测范围
- 考虑使用更快的ORB算法
八、总结要点
- SURF核心优势:在保持SIFT性能的同时大幅提升计算速度
- 实现原理:基于Hessian矩阵和积分图像加速
- OpenCV API :
cv2.xfeatures2d.SURF_create() - 关键参数 :
hessianThreshold:控制特征点数量和质量extended:控制描述子维度(64维或128维)
- 版本兼容性:SURF在OpenCV 3.x中可用,4.x中可能受限
- 应用选择:实时性要求高的场景选择SURF,准确性要求高的场景选择SIFT
实践建议:
- 在不同图像上测试SURF参数,观察特征点数量变化
- 与SIFT进行性能对比,了解实际速度提升
- 根据应用场景选择合适的特征检测算法
- 为后续的特征匹配学习打好基础,理解不同描述子的特点
7、OpenCV ORB特征检测笔记
一、ORB概述
1. ORB定义
- ORB:Oriented FAST and Rotated BRIEF
- 组成 :
- oFAST:带方向的FAST特征点检测
- rBRIEF:旋转不变的BRIEF描述子
- 核心优势 :实时性,比SIFT/SURF快一个数量级
- 开源免费:无专利限制,可直接在OpenCV主库中使用
2. ORB vs SIFT vs SURF对比
| 特性 | ORB | SURF | SIFT |
|---|---|---|---|
| 计算速度 | ✅ 最快(实时性) | ✅ 较快 | ❌ 较慢 |
| 准确性 | 中等(速度与精度的平衡) | 良好 | ✅ 最准确 |
| 专利状态 | ✅ 免费开源 | ❌ 有专利 | ❌ 有专利 |
| 描述子维度 | 32/64维(二进制) | 64/128维 | 128维 |
| OpenCV位置 | 主库(cv2.ORB_create) | 扩展库(xfeatures2d) | 扩展库(xfeatures2d) |
| 内存占用 | 最少 | 中等 | 最多 |
3. ORB设计哲学
牺牲部分精度 → 换取极大速度提升 → 实现实时检测
↓
适用于大规模/实时场景4. ORB组成技术详解
| 技术 | 解决的问题 | 改进 |
|---|---|---|
| FAST | 快速特征点检测 | 检测速度快,但无方向 |
| oFAST | 增加方向信息 | 为FAST特征点计算主方向 |
| BRIEF | 快速描述子计算 | 二进制描述子,计算快 |
| rBRIEF | 旋转不变性 | 使BRIEF对旋转具有鲁棒性 |
二、ORB工作原理简析
1. 特征检测(oFAST)
- FAST检测:快速检测角点
- 方向计算:使用灰度质心法计算特征点方向
- 尺度不变性:构建图像金字塔进行多尺度检测
2. 描述子计算(rBRIEF)
- 旋转矫正:根据特征点方向旋转采样模式
- 二进制描述:比较采样点对生成二进制串
- 汉明距离:使用汉明距离进行快速匹配
三、OpenCV ORB API使用
1. 基本使用步骤
python
import cv2
import numpy as np
# 1. 读取图像并灰度化
img = cv2.imread('chess.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 2. 创建ORB检测器对象
orb = cv2.ORB_create([nfeatures[, scaleFactor[, nlevels[, edgeThreshold[, firstLevel[, WTA_K[, scoreType[, patchSize[, fastThreshold]]]]]]]]])
# 3. 检测关键点和计算描述子
keypoints, descriptors = orb.detectAndCompute(gray, None)
# 4. 绘制关键点
img_kp = cv2.drawKeypoints(img, keypoints, None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# 5. 显示结果
cv2.imshow('ORB Keypoints', img_kp)
cv2.waitKey(0)
cv2.destroyAllWindows()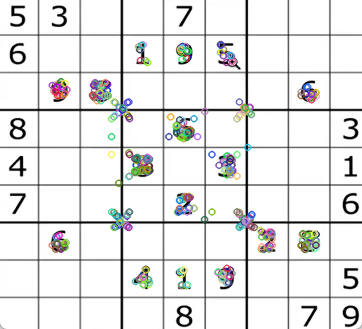
2. ORB_create参数详解
python
orb = cv2.ORB_create(nfeatures=500, # 最大特征点数
scaleFactor=1.2, # 金字塔缩放因子
nlevels=8, # 金字塔层数
edgeThreshold=31, # 边界阈值
firstLevel=0, # 第一层索引
WTA_K=2, # 生成描述子的测试点数
scoreType=cv2.ORB_HARRIS_SCORE, # 特征点评分类型
patchSize=31, # 描述子区域大小
fastThreshold=20) # FAST阈值重要参数说明:
nfeatures:返回的最大特征点数,ORB会自动选择最强的特征点scaleFactor:金字塔缩放因子,>1.0,值越小检测更多尺度但计算量增大WTA_K:生成描述子时使用的测试点数,2或4,影响描述子维度和计算复杂度scoreType:特征点评分类型,cv2.ORB_HARRIS_SCORE或cv2.ORB_FAST_SCORE
四、代码实现与对比
1. ORB完整示例
python
import cv2
import numpy as np
import time
def orb_feature_detection(image_path, nfeatures=500):
"""ORB特征检测"""
# 读取图像
img = cv2.imread(image_path)
if img is None:
print(f"无法读取图像: {image_path}")
return
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建ORB检测器
orb = cv2.ORB_create(nfeatures=nfeatures)
# 检测关键点和计算描述子
start_time = time.time()
keypoints, descriptors = orb.detectAndCompute(gray, None)
end_time = time.time()
print(f"ORB检测时间: {end_time - start_time:.4f}秒")
print(f"检测到 {len(keypoints)} 个关键点")
if descriptors is not None:
print(f"描述子维度: {descriptors.shape}")
print(f"描述子类型: {descriptors.dtype}") # ORB描述子是uint8类型
# 绘制关键点
img_kp = cv2.drawKeypoints(img, keypoints, None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
return img_kp, keypoints, descriptors
# 使用示例
img_kp, keypoints, descriptors = orb_feature_detection('chess.png', nfeatures=500)
if img_kp is not None:
cv2.imshow('ORB Features', img_kp)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 查看描述子(二进制)
if descriptors is not None and len(descriptors) > 0:
print(f"第一个描述子(前10个字节): {descriptors[0][:10]}")
print(f"描述子二进制表示: {[bin(byte) for byte in descriptors[0][:5]]}")2. 三种算法性能对比
python
import cv2
import numpy as np
import time
def compare_all_algorithms(image_path):
"""比较SIFT、SURF、ORB性能"""
img = cv2.imread(image_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
results = {}
algorithms = [
('ORB', lambda: cv2.ORB_create(nfeatures=500)),
('SURF', lambda: cv2.xfeatures2d.SURF_create(hessianThreshold=100) if hasattr(cv2, 'xfeatures2d') else None),
('SIFT', lambda: cv2.xfeatures2d.SIFT_create() if hasattr(cv2, 'xfeatures2d') else None)
]
for name, create_func in algorithms:
print(f"\n=== {name} ===")
# 创建检测器
try:
detector = create_func()
if detector is None:
print(f" {name}不可用(可能未安装相应模块)")
continue
except AttributeError as e:
print(f" {name}创建失败: {e}")
continue
# 检测特征
start_time = time.time()
keypoints, descriptors = detector.detectAndCompute(gray, None)
elapsed_time = time.time() - start_time
if keypoints is not None:
results[name] = {
'time': elapsed_time,
'keypoints': len(keypoints),
'descriptor_dim': descriptors.shape[1] if descriptors is not None else 0
}
print(f" 检测时间: {elapsed_time:.4f}秒")
print(f" 关键点数量: {len(keypoints)}")
if descriptors is not None:
print(f" 描述子维度: {descriptors.shape[1]}")
# 性能对比总结
if len(results) >= 2:
print("\n=== 性能对比总结 ===")
fastest = min(results.items(), key=lambda x: x[1]['time'])
print(f"最快的算法: {fastest[0]} ({fastest[1]['time']:.4f}秒)")
if 'ORB' in results and 'SIFT' in results:
speedup = results['SIFT']['time'] / results['ORB']['time']
print(f"ORB比SIFT快 {speedup:.1f}倍")
return results
# 运行对比
compare_all_algorithms('chess.png')3. ORB参数调优示例
python
import cv2
import matplotlib.pyplot as plt
def test_orb_parameters(image_path):
"""测试不同ORB参数的效果"""
img = cv2.imread(image_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 测试不同nfeatures参数
nfeatures_list = [100, 300, 500, 1000]
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
axes = axes.ravel()
for i, nfeatures in enumerate(nfeatures_list):
# 创建ORB检测器
orb = cv2.ORB_create(nfeatures=nfeatures)
# 检测关键点
keypoints, _ = orb.detectAndCompute(gray, None)
# 绘制关键点
img_kp = cv2.drawKeypoints(img, keypoints, None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# 显示
axes[i].imshow(cv2.cvtColor(img_kp, cv2.COLOR_BGR2RGB))
axes[i].set_title(f'nfeatures = {nfeatures}\nKeypoints = {len(keypoints)}')
axes[i].axis('off')
plt.tight_layout()
plt.show()
# 测试不同scaleFactor
print("测试不同scaleFactor:")
scale_factors = [1.1, 1.2, 1.5, 2.0]
for scale in scale_factors:
orb = cv2.ORB_create(nfeatures=500, scaleFactor=scale)
keypoints, _ = orb.detectAndCompute(gray, None)
print(f"scaleFactor={scale}: {len(keypoints)}个关键点")
# 测试不同参数
test_orb_parameters('chess.png')五、ORB在实际应用中的特点
1. 描述子特性
- 二进制描述子:使用0/1编码,计算和匹配速度快
- 汉明距离匹配:使用按位异或计算距离,效率极高
- 内存占用小:32/64字节 vs SIFT的512字节(128维×4字节)
2. 实时性表现
python
# 实时视频特征检测示例
def real_time_orb_detection():
cap = cv2.VideoCapture(0)
orb = cv2.ORB_create(nfeatures=300)
while True:
ret, frame = cap.read()
if not ret:
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 实时检测
keypoints, descriptors = orb.detectAndCompute(gray, None)
# 绘制关键点
frame_kp = cv2.drawKeypoints(frame, keypoints, None,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# 显示FPS
cv2.putText(frame_kp, f"Keypoints: {len(keypoints)}", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow('Real-time ORB Detection', frame_kp)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
# 运行实时检测(确保有摄像头)
# real_time_orb_detection()六、算法选择指南
1. 选择标准
需要考虑的因素:
1. 实时性要求? → 是 → 选择ORB
↓ 否
2. 精度要求极高? → 是 → 选择SIFT
↓ 否
3. 平衡速度与精度? → 是 → 选择SURF
↓
4. 专利限制? → 有 → 选择ORB
↓ 无
5. 根据具体场景测试选择2. 场景建议
| 应用场景 | 推荐算法 | 理由 |
|---|---|---|
| 实时视频处理 | ORB | 速度快,满足实时性 |
| 移动设备应用 | ORB | 计算资源有限,需要高效算法 |
| 高精度图像匹配 | SIFT | 准确性最高,特征描述好 |
| 大规模图像检索 | SURF/ORB | 需要平衡速度与准确性 |
| 学术研究 | SIFT | 作为基准算法,结果可复现 |
| 商业产品 | ORB | 无专利限制,成本低 |
3. 性能权衡关系图
准确性: SIFT > SURF > ORB
速度: ORB > SURF > SIFT
专利: ORB(免费) > SIFT(过期) > SURF(有专利)
实时性: ORB(✅) > SURF(部分) > SIFT(❌)七、常见问题与解决方案
1. ORB特征点数量不足
问题 :检测到的特征点太少
解决:
python
# 调整参数增加特征点
orb = cv2.ORB_create(nfeatures=1000, # 增加最大特征点数
fastThreshold=10, # 降低FAST阈值,检测更多点
scaleFactor=1.1) # 减小缩放因子,增加尺度层2. ORB实时性不够
问题 :在低性能设备上无法达到实时
解决:
python
# 降低计算负载
orb = cv2.ORB_create(nfeatures=200, # 减少特征点数
patchSize=31, # 使用默认大小
edgeThreshold=19) # 减小边界阈值3. 特征匹配效果差
问题 :ORB描述子匹配准确率低
解决:
python
# 改进匹配策略
# 1. 使用交叉检查过滤错误匹配
# 2. 使用比率测试保留高质量匹配
# 3. 考虑使用基于网格的特征检测,提高特征点分布均匀性八、总结与最佳实践
1. ORB核心优势总结
- 实时性:比SIFT/SURF快一个数量级
- 开源免费:无专利限制,适合商业应用
- 二进制描述子:匹配速度快,内存占用小
- 易于使用:OpenCV主库直接支持
2. 使用建议
- 参数调优 :根据应用场景调整
nfeatures和scaleFactor - 性能监控:实时应用中监控FPS和特征点数量
- 质量评估:定期评估特征检测和匹配质量
- 备选方案:在精度要求高的场景准备SIFT作为备选
3. 未来发展
- ORB2.0等改进版本持续优化
- 结合深度学习特征(如SuperPoint)
- 硬件加速(GPU、FPGA)进一步提升性能
最终建议:
- 初学者:从ORB开始,体验实时特征检测
- 实际项目:根据需求在ORB/SURF/SIFT间选择
- 性能关键:始终以ORB为基准测试其他算法
- 精度关键:优先考虑SIFT,再优化性能
通过学习三种特征检测算法(SIFT、SURF、ORB),现在可以根据具体应用场景选择合适的工具,在速度、精度和专利限制之间做出明智的权衡。
8、OpenCV BF暴力特征匹配笔记
一、特征匹配概述
1. 匹配方法分类
- BF匹配:Brute-Force(暴力匹配),枚举所有可能
- FLANN匹配:Fast Library for Approximate Nearest Neighbors(快速最近邻搜索)
2. 匹配流程
图像A → 特征检测 → 关键点A + 描述子A → 匹配器 → 匹配结果
图像B → 特征检测 → 关键点B + 描述子B ↗二、BF暴力匹配原理
1. 工作原理
- 遍历匹配:使用第一组(图像A)的每个特征的描述子
- 全量比较:与第二组(图像B)的所有特征描述子进行距离计算
- 返回最佳:返回距离最近(最相似)的匹配对
2. 数学表达
对于图像A的每个描述子A_i:
计算A_i与图像B所有描述子B_j的距离
找到最小距离min_distance = min(distance(A_i, B_j))
返回(B_j_index, min_distance)作为匹配结果三、OpenCV BF匹配API详解
1. 匹配器创建
python
bf = cv2.BFMatcher(normType, crossCheck=False)参数说明:
normType:距离测量类型cv2.NORM_L1:绝对值距离,用于SIFT/SURFcv2.NORM_L2:欧式距离(默认),用于SIFT/SURFcv2.NORM_HAMMING:汉明距离,用于ORB、BRIEF等二进制描述子cv2.NORM_HAMMING2:汉明距离变体,用于ORB(WTA_K=3或4时)
crossCheck:交叉检查(布尔值)False(默认):单向匹配True:双向验证,只有当A→B和B→A都匹配时才认为是有效匹配
2. 距离测量类型详解
| 距离类型 | 公式 | 适用描述子 | 特点 |
|---|---|---|---|
| L1距离 | Σ|x_i - y_i| | SIFT、SURF | 计算简单,对异常值不敏感 |
| L2距离 | √Σ(x_i - y_i)² | SIFT、SURF | 最常用的欧式距离,符合几何意义 |
| 汉明距离 | 不同位的数量 | ORB、BRIEF | 专为二进制描述子设计,效率高 |
3. 匹配执行
python
matches = bf.match(des1, des2)
# 或使用knn匹配
matches_knn = bf.knnMatch(des1, des2, k=2)匹配结果结构:
- 每个匹配是一个
DMatch对象,包含:queryIdx:查询图像(第一幅)中特征点的索引trainIdx:训练图像(第二幅)中特征点的索引distance:两个描述子之间的距离(越小越相似)
4. 绘制匹配结果
python
result_img = cv2.drawMatches(img1, kp1, img2, kp2, matches, None, flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)drawMatches参数:
img1:第一幅(查询)图像kp1:第一幅图像的关键点img2:第二幅(训练)图像kp2:第二幅图像的关键点matches:匹配结果列表outImg:输出图像(None表示创建新图像)flags:绘制标志cv2.DrawMatchesFlags_DEFAULT:默认绘制所有匹配cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS:不绘制未匹配的单个关键点cv2.DrawMatchesFlags_DRAW_RICH_KEYPOINTS:绘制带方向和尺度的关键点
四、代码实现步骤
1. 基础BF匹配实现
python
import cv2
import numpy as np
# 1. 读取两张图像
img1 = cv2.imread('opencv_search.png') # 查询图像(小图)
img2 = cv2.imread('opencv_orig.png') # 训练图像(大图)
# 2. 转换为灰度图
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 3. 创建特征检测器(这里以SIFT为例)
sift = cv2.SIFT_create()
# 4. 检测关键点并计算描述子
kp1, des1 = sift.detectAndCompute(gray1, None)
kp2, des2 = sift.detectAndCompute(gray2, None)
# 5. 创建BF匹配器(使用L2距离,SIFT描述子)
bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=False)
# 6. 执行匹配
matches = bf.match(des1, des2)
# 7. 按距离排序(距离越小越相似)
matches = sorted(matches, key=lambda x: x.distance)
# 8. 绘制最佳匹配(取前50个)
result = cv2.drawMatches(img1, kp1, img2, kp2, matches[:50], None,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
# 9. 显示结果
cv2.imshow('BF Matching Result', result)
cv2.waitKey(0)
cv2.destroyAllWindows()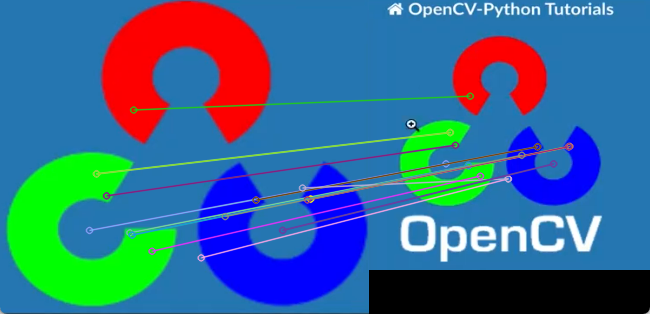
2. 完整的BF匹配代码(含错误处理)
python
import cv2
import numpy as np
def bf_feature_matching(img1_path, img2_path, detector_type='SIFT', norm_type=None, cross_check=False, top_matches=50):
"""
BF特征匹配函数
参数:
- img1_path: 查询图像路径
- img2_path: 训练图像路径
- detector_type: 特征检测器类型 ('SIFT', 'SURF', 'ORB')
- norm_type: 距离测量类型(None表示自动选择)
- cross_check: 是否启用交叉检查
- top_matches: 显示的最佳匹配数量
"""
# 1. 读取图像
img1 = cv2.imread(img1_path)
img2 = cv2.imread(img2_path)
if img1 is None or img2 is None:
print("错误:无法读取图像")
return None
# 2. 转换为灰度图
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 3. 创建特征检测器
if detector_type == 'SIFT':
try:
detector = cv2.SIFT_create()
except AttributeError:
detector = cv2.xfeatures2d.SIFT_create()
# 自动选择距离类型
if norm_type is None:
norm_type = cv2.NORM_L2
elif detector_type == 'SURF':
try:
detector = cv2.xfeatures2d.SURF_create()
except AttributeError:
print("SURF检测器不可用,请安装opencv-contrib-python")
return None
if norm_type is None:
norm_type = cv2.NORM_L2
elif detector_type == 'ORB':
detector = cv2.ORB_create()
if norm_type is None:
norm_type = cv2.NORM_HAMMING
else:
print("不支持的检测器类型")
return None
# 4. 检测关键点并计算描述子
kp1, des1 = detector.detectAndCompute(gray1, None)
kp2, des2 = detector.detectAndCompute(gray2, None)
if des1 is None or des2 is None:
print("错误:无法计算描述子")
return None
print(f"图像1: {len(kp1)} 个关键点")
print(f"图像2: {len(kp2)} 个关键点")
# 5. 创建BF匹配器
bf = cv2.BFMatcher(norm_type, crossCheck=cross_check)
# 6. 执行匹配
matches = bf.match(des1, des2)
# 7. 按距离排序
matches = sorted(matches, key=lambda x: x.distance)
print(f"找到 {len(matches)} 个匹配")
if len(matches) > 0:
print(f"最佳匹配距离: {matches[0].distance:.2f}")
print(f"最差匹配距离: {matches[-1].distance:.2f}")
# 8. 绘制匹配结果
result = cv2.drawMatches(img1, kp1, img2, kp2,
matches[:min(top_matches, len(matches))],
None,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
return result, matches
# 使用示例
result_img, matches = bf_feature_matching('opencv_search.png',
'opencv_orig.png',
detector_type='SIFT',
top_matches=30)
if result_img is not None:
cv2.imshow('BF Matching Result', result_img)
cv2.waitKey(0)
cv2.destroyAllWindows()3. 不同特征检测器的匹配示例
python
# 测试不同特征检测器的匹配效果
def compare_detectors(img1_path, img2_path):
detectors = ['SIFT', 'ORB']
for detector_name in detectors:
print(f"\n=== 使用 {detector_name} ===")
# 根据检测器类型设置参数
if detector_name == 'ORB':
norm_type = cv2.NORM_HAMMING
cross_check = True # ORB通常启用交叉检查提高准确性
else:
norm_type = cv2.NORM_L2
cross_check = False
# 执行匹配
result, matches = bf_feature_matching(img1_path, img2_path,
detector_type=detector_name,
norm_type=norm_type,
cross_check=cross_check,
top_matches=20)
if result is not None:
# 计算匹配质量指标
if len(matches) > 10:
avg_distance = np.mean([m.distance for m in matches[:10]])
print(f"前10个匹配的平均距离: {avg_distance:.2f}")
# 显示结果
cv2.imshow(f'BF Matching with {detector_name}', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 运行比较
compare_detectors('opencv_search.png', 'opencv_orig.png')五、匹配优化技术
1. 距离筛选
python
# 方法1:基于固定阈值筛选
good_matches = []
for match in matches:
if match.distance < 100: # 设置距离阈值
good_matches.append(match)
# 方法2:基于比率测试(Ratio Test)
# 使用knnMatch获取前k个最佳匹配
bf = cv2.BFMatcher(cv2.NORM_L2)
matches_knn = bf.knnMatch(des1, des2, k=2)
# 应用比率测试
good_matches = []
for m, n in matches_knn:
if m.distance < 0.75 * n.distance: # Lowe's ratio test
good_matches.append(m)2. 交叉检查(Cross-Check)
python
# 启用交叉检查(创建匹配器时设置)
bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=True)
matches = bf.match(des1, des2)
# 交叉检查确保双向匹配的一致性
# 即:des1[i]的最佳匹配是des2[j],且des2[j]的最佳匹配也是des1[i]3. 匹配结果分析
python
def analyze_matches(matches, kp1, kp2, img1_shape, img2_shape):
"""分析匹配结果的统计信息"""
if len(matches) == 0:
print("没有找到匹配")
return
# 提取匹配的距离值
distances = [m.distance for m in matches]
print("=== 匹配分析 ===")
print(f"匹配总数: {len(matches)}")
print(f"最小距离: {min(distances):.2f}")
print(f"最大距离: {max(distances):.2f}")
print(f"平均距离: {np.mean(distances):.2f}")
print(f"距离标准差: {np.std(distances):.2f}")
# 分析匹配点的位置分布
positions_img1 = []
positions_img2 = []
for match in matches:
# 获取关键点坐标
pt1 = kp1[match.queryIdx].pt
pt2 = kp2[match.trainIdx].pt
positions_img1.append(pt1)
positions_img2.append(pt2)
# 转换为numpy数组便于分析
positions_img1 = np.array(positions_img1)
positions_img2 = np.array(positions_img2)
print(f"\n图像1匹配点位置范围:")
print(f" X: [{positions_img1[:, 0].min():.1f}, {positions_img1[:, 0].max():.1f}]")
print(f" Y: [{positions_img1[:, 1].min():.1f}, {positions_img1[:, 1].max():.1f}]")
print(f"\n图像2匹配点位置范围:")
print(f" X: [{positions_img2[:, 0].min():.1f}, {positions_img2[:, 0].max():.1f}]")
print(f" Y: [{positions_img2[:, 1].min():.1f}, {positions_img2[:, 1].max():.1f}]")
return positions_img1, positions_img2六、实际应用示例
1. 图像搜索(以图搜图)
python
def image_search(query_img_path, database_dir):
"""
简单的图像搜索实现
查询图像在数据库图像中寻找最佳匹配
"""
import os
# 读取查询图像并提取特征
query_img = cv2.imread(query_img_path)
gray_query = cv2.cvtColor(query_img, cv2.COLOR_BGR2GRAY)
# 创建特征检测器
orb = cv2.ORB_create(nfeatures=1000)
kp_query, des_query = orb.detectAndCompute(gray_query, None)
# 创建BF匹配器
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
results = []
# 遍历数据库图像
for filename in os.listdir(database_dir):
if filename.endswith(('.jpg', '.png', '.jpeg')):
db_img_path = os.path.join(database_dir, filename)
db_img = cv2.imread(db_img_path)
# 提取数据库图像特征
gray_db = cv2.cvtColor(db_img, cv2.COLOR_BGR2GRAY)
kp_db, des_db = orb.detectAndCompute(gray_db, None)
if des_db is not None and des_query is not None:
# 执行匹配
matches = bf.match(des_query, des_db)
if len(matches) > 0:
# 计算匹配质量分数(平均距离的倒数,距离越小分数越高)
avg_distance = np.mean([m.distance for m in matches])
score = 1.0 / (avg_distance + 1e-6) # 避免除零
results.append({
'filename': filename,
'score': score,
'matches': len(matches),
'avg_distance': avg_distance
})
# 按分数排序
results.sort(key=lambda x: x['score'], reverse=True)
return results[:5] # 返回前5个最佳匹配2. 对象识别与定位
python
def locate_object_in_scene(obj_img_path, scene_img_path):
"""
在场景图像中定位目标对象
"""
# 读取图像
obj_img = cv2.imread(obj_img_path) # 目标对象
scene_img = cv2.imread(scene_img_path) # 场景
# 特征检测和描述子计算
sift = cv2.SIFT_create()
kp_obj, des_obj = sift.detectAndCompute(obj_img, None)
kp_scene, des_scene = sift.detectAndCompute(scene_img, None)
if des_obj is None or des_scene is None:
print("无法计算描述子")
return None
# BF匹配
bf = cv2.BFMatcher(cv2.NORM_L2)
matches = bf.knnMatch(des_obj, des_scene, k=2)
# 应用比率测试
good_matches = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good_matches.append(m)
print(f"找到 {len(good_matches)} 个良好匹配")
if len(good_matches) > 10:
# 绘制匹配结果
result = cv2.drawMatches(obj_img, kp_obj, scene_img, kp_scene,
good_matches, None,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
# 提取匹配点的位置
obj_pts = np.float32([kp_obj[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2)
scene_pts = np.float32([kp_scene[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2)
# 使用单应性矩阵找到目标位置(后续课程会详细讲解)
# M, mask = cv2.findHomography(obj_pts, scene_pts, cv2.RANSAC, 5.0)
return result
return None七、BF匹配的优缺点
1. 优点
- 实现简单:算法直观,易于理解和实现
- 精确度高:当特征点较少时,可以得到精确的最近邻匹配
- 适用性广:适用于各种特征描述子
2. 缺点
- 计算复杂度高:O(N²)复杂度,大数据集下效率低
- 内存消耗大:需要存储所有特征描述子进行全量比较
- 不适合实时应用:对大量特征点的匹配速度慢
3. 适用场景
- 小规模特征匹配(特征点数 < 1000)
- 精度要求高的匹配任务
- 离线图像处理
- 学习和原型开发
八、总结与最佳实践
1. 关键步骤回顾
- 特征提取:选择适合的特征检测器(SIFT/SURF/ORB)
- 匹配器创建:根据描述子类型选择合适的距离测量
- 执行匹配 :使用
match()或knnMatch()方法 - 结果筛选:使用距离阈值或比率测试过滤错误匹配
- 结果可视化 :使用
drawMatches()绘制匹配结果
2. 参数选择建议
- SIFT/SURF描述子 :使用
cv2.NORM_L2(欧式距离) - ORB/BRIEF描述子 :使用
cv2.NORM_HAMMING(汉明距离) - 交叉检查:对精度要求高时启用,但会减少匹配数量
- 比率测试:通常使用0.7-0.8的比率阈值
3. 性能优化技巧
- 限制特征点数量(使用
nfeatures参数) - 使用
knnMatch()结合比率测试提高匹配质量 - 对匹配结果进行几何一致性验证(如RANSAC)
- 对于大规模匹配,考虑使用FLANN匹配器
4. 下一步学习方向
- FLANN匹配:学习更高效的近似最近邻搜索
- 特征匹配优化:学习RANSAC等几何验证方法
- 应用开发:实现图像拼接、目标跟踪等实际应用
通过本节学习,你掌握了使用BF暴力匹配进行特征匹配的基本方法。虽然BF匹配计算复杂度较高,但它在小规模数据集和精度要求高的场景中非常有用。在实际应用中,需要根据具体需求选择合适的特征检测器和匹配策略。
9、OpenCV FLANN特征匹配笔记
一、FLANN特征匹配概述
1. FLANN定义
- FLANN:Fast Library for Approximate Nearest Neighbors(快速近似最近邻搜索库)
- 核心优势 :速度快,适合大规模特征匹配
- 缺点 :由于使用近似算法,精度相对较低
2. 适用场景对比
| 匹配方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| BF匹配 | 精确度高 | 速度慢,O(N²)复杂度 | 小规模、高精度匹配 |
| FLANN匹配 | 速度快 | 精度相对较低 | 大规模、实时性要求高的匹配 |
二、FLANN匹配步骤
1. 基本流程
- 创建匹配器 :
cv2.FlannBasedMatcher() - 执行匹配 :使用
knnMatch()方法 - 绘制匹配结果 :使用
drawMatchesKnn()方法
2. 与BF匹配的步骤对比
BF匹配步骤:
创建BFMatcher → match()或knnMatch() → drawMatches()或drawMatchesKnn()
FLANN匹配步骤:
创建FlannBasedMatcher → knnMatch() → drawMatchesKnn()注意:FLANN匹配通常使用knnMatch(),因为近似最近邻搜索可以返回前k个最佳匹配。
三、FLANN匹配参数详解
1. 创建匹配器:FlannBasedMatcher
python
flann = cv2.FlannBasedMatcher(index_params, search_params)参数说明:
1.1 index_params(索引参数)
-
用于指定匹配算法的字典,根据特征描述子的类型选择:
-
SIFT、SURF等浮点型描述子:使用KD树算法
pythonFLANN_INDEX_KDTREE = 1 index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5) -
ORB、BRIEF等二进制描述子:使用LSH算法
pythonFLANN_INDEX_LSH = 6 index_params = dict(algorithm=FLANN_INDEX_LSH, table_number=6, # 哈希表数量 key_size=12, # 键大小 multi_probe_level=1) # 多级探测级别
-
1.2 search_params(搜索参数)
-
控制搜索过程的字典,常用:
pythonsearch_params = dict(checks=50) # 指定递归遍历的次数checks:值越大,搜索越精确,但速度越慢;值越小,速度越快,但可能错过正确匹配。
2. 执行匹配:knnMatch()
python
matches = flann.knnMatch(des1, des2, k=2)des1:第一幅图像的特征描述子des2:第二幅图像的特征描述子k:每个查询描述子返回的最佳匹配个数(例如k=2返回前两个最佳匹配)
返回值 :matches是一个列表,每个元素是一个子列表,包含k个DMatch对象(按距离升序排列)。
3. DMatch对象属性
distance:两个描述子之间的距离(越小表示越相似)queryIdx:查询图像(第一幅)中描述子的索引trainIdx:训练图像(第二幅)中描述子的索引imgIdx:训练图像的索引(当多张图像时使用)
4. 绘制匹配结果:drawMatchesKnn()
python
result = cv2.drawMatchesKnn(img1, kp1, img2, kp2, matches, None, **kwargs)img1、kp1:查询图像及其关键点img2、kp2:训练图像及其关键点matches:knnMatch()返回的匹配结果flags:绘制标志,例如cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS
注意:由于knnMatch返回的是每个查询点的k个匹配,drawMatchesKnn会绘制所有k个匹配(用多条线连接同一个查询点)。
四、代码实战
1. 完整代码示例(使用SIFT特征)
python
import cv2
import numpy as np
# 1. 读取图像
img1 = cv2.imread('opencv_search.png') # 查询图像(小图)
img2 = cv2.imread('opencv_orig.png') # 训练图像(大图)
# 2. 转换为灰度图
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 3. 创建SIFT特征检测器
sift = cv2.SIFT_create()
# 4. 检测关键点并计算描述子
kp1, des1 = sift.detectAndCompute(gray1, None)
kp2, des2 = sift.detectAndCompute(gray2, None)
# 5. 创建FLANN匹配器
# 对于SIFT浮点型描述子,使用KD树算法
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50) # 递归遍历次数
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 6. 执行KNN匹配(每个查询点返回前2个最佳匹配)
matches = flann.knnMatch(des1, des2, k=2)
# 7. 过滤匹配:使用Lowe's ratio test
good_matches = []
for m, n in matches:
if m.distance < 0.7 * n.distance: # 比例阈值,通常0.7-0.8
good_matches.append(m)
print(f"原始匹配数量: {len(matches)}")
print(f"过滤后匹配数量: {len(good_matches)}")
# 8. 绘制匹配结果(只绘制过滤后的匹配)
# 注意:drawMatchesKnn需要传入一个列表的列表,所以将good_matches包装一下
matches_for_draw = [[m] for m in good_matches]
result = cv2.drawMatchesKnn(img1, kp1, img2, kp2, matches_for_draw, None,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
# 9. 显示结果
cv2.imshow('FLANN Matching Result', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
2. 使用ORB特征的FLANN匹配
python
# 创建ORB特征检测器
orb = cv2.ORB_create(nfeatures=1000)
# 检测关键点并计算描述子
kp1, des1 = orb.detectAndCompute(gray1, None)
kp2, des2 = orb.detectAndCompute(gray2, None)
# 对于ORB二进制描述子,使用LSH算法
FLANN_INDEX_LSH = 6
index_params = dict(algorithm=FLANN_INDEX_LSH,
table_number=6, # 哈希表数量
key_size=12, # 键大小
multi_probe_level=1) # 多级探测级别
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 后续步骤相同...3. 匹配过滤(Ratio Test)
-
目的:消除错误匹配,提高匹配质量
-
原理:对于每个查询点,如果最佳匹配与次佳匹配的距离比值小于阈值(如0.7),则保留最佳匹配,否则丢弃。
-
代码实现:
pythongood_matches = [] for m, n in matches: # matches是knnMatch返回的,每个元素包含k个DMatch if m.distance < ratio * n.distance: good_matches.append(m)
五、性能优化与注意事项
1. 参数调优建议
trees(KD树数量):增加树的数量可以提高搜索精度,但会降低速度。通常5-20之间。checks(搜索次数) :增加checks值可以提高搜索精度,但会线性增加搜索时间。根据实时性要求调整。k(返回的最佳匹配数):在Ratio Test中,通常k=2。如果需要更多匹配信息,可以增加k值。
2. 特征描述子类型与算法选择
| 描述子类型 | 推荐算法 | 说明 |
|---|---|---|
| SIFT、SURF(浮点型) | KD树(FLANN_INDEX_KDTREE) | 适用于连续特征向量 |
| ORB、BRIEF(二进制) | LSH(FLANN_INDEX_LSH) | 适用于汉明距离 |
3. 错误匹配处理
- Ratio Test:如上所述,过滤掉模棱两可的匹配。
- 交叉验证 :使用
crossCheck(但FLANN匹配器不支持,BF匹配器支持)。 - 几何一致性检查:使用RANSAC等算法进一步过滤(后续课程会介绍)。
六、FLANN与BF匹配对比实验
1. 速度对比
python
import time
# BF匹配
bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=False)
start = time.time()
bf_matches = bf.match(des1, des2)
bf_time = time.time() - start
# FLANN匹配
flann = cv2.FlannBasedMatcher(index_params, search_params)
start = time.time()
flann_matches = flann.knnMatch(des1, des2, k=2)
flann_time = time.time() - start
print(f"BF匹配时间: {bf_time:.4f}秒")
print(f"FLANN匹配时间: {flann_time:.4f}秒")
print(f"FLANN比BF快 {bf_time/flann_time:.2f}倍")2. 精度对比
- 主观评价:观察匹配结果图像,检查是否正确匹配。
- 客观评价:如果有真实匹配对应关系,可以计算准确率、召回率等指标。
七、常见问题与解决方案
1. 算法类型选择错误
问题 :使用SIFT描述子却选择了LSH算法,导致错误。
解决:根据描述子类型正确选择算法。
2. 匹配结果过多或过少
问题 :匹配数量不理想。
解决:
- 调整
knnMatch的k值。 - 调整Ratio Test的阈值(0.7-0.8之间调整)。
- 调整
search_params中的checks值。
3. 匹配速度慢
解决:
- 减少特征点数量(在特征检测时限制
nfeatures)。 - 减少
checks值。 - 使用更快的特征检测器(如ORB代替SIFT)。
八、总结
1. 核心要点
- FLANN匹配适用于大规模特征匹配,速度远快于BF匹配。
- 使用FLANN匹配时,需要根据特征描述子的类型选择合适的索引算法(浮点型用KD树,二进制用LSH)。
- 通过Ratio Test(Lowe's ratio test)可以过滤掉大部分错误匹配。
2. 选择建议
- 追求速度:使用FLANN匹配。
- 追求精度:使用BF匹配。
- 实时应用:FLANN匹配(结合ORB特征检测器)。
- 离线高精度匹配:BF匹配(结合SIFT特征检测器)。
3. 扩展学习
- 多图匹配:将一张查询图像与多张训练图像匹配。
- 图像检索系统:基于FLANN构建简单的图像检索系统。
- 特征匹配优化:学习RANSAC等几何验证方法,进一步提高匹配精度。
通过本节课的学习,你已经掌握了FLANN特征匹配的原理和实现方法,可以在实际项目中根据需求选择合适的匹配策略。