构建高效任务中心:CDC 数据同步的工程实践与架构权衡
在现代业务系统中,任务中心(Task Center)作为连接数据与行动的核心枢纽,其核心能力之一是从上游业务数据库中可靠、高效、低延迟地同步关键状态变更,并以此驱动任务生成、告警或自动化决策。然而,面对"百表千字段"的复杂数据模型,如何在保障实时性的同时控制资源消耗、确保一致性,并为后续的标签化、规则匹配与智能增强提供高质量输入,是工程落地的关键挑战。
本文系统梳理当前主流的数据同步方案,深入分析 CDC(Change Data Capture)的技术原理、部署模式与优化策略,并给出面向任务中心场景的分层架构设计建议。
一、同步需求的本质:SLA 驱动架构选型
并非所有数据都需要实时同步。任务中心的同步方案应由业务对时效性与一致性的实际需求(SLA)驱动:
| 同步场景 | 典型 SLA | 推荐方案 |
|---|---|---|
| 状态变更(如案件结案) | ≤1s | CDC(Debezium) |
| 主数据(如商品类目) | ≤1小时 | 增量 ETL(Airflow) |
| 日志/行为流 | ≤15分钟 | 消息队列(Kafka) |
核心原则:
用最经济的方式满足真实业务 SLA,避免"为同步而同步"。
二、CDC 的原理:为何能"零侵入"捕获变更?
CDC 的核心在于直接读取数据库的事务日志(Transaction Log),而非通过 SQL 轮询或业务代码埋点。
- MySQL :解析
binlog(需ROW格式) - PostgreSQL:通过逻辑复制槽(Logical Replication Slot)读取 WAL
- Oracle:解析 Redo Log(通过 LogMiner 或 XStream)
以 MySQL 为例,Debezium 伪装为从库 (Replica),通过标准复制协议请求 binlog 流。主库仅将其视为普通复制客户端,无需任何业务改造、不执行额外 SQL、不加锁,对主库性能影响通常 ❤️%。
关键前提:
- 开启 binlog/WAL
- 使用
ROW格式(记录行级变更)- 为 CDC 用户授予最小权限(
REPLICATION SLAVE等)
三、CDC vs 轮询 vs 主动推送:架构权衡
| 方案 | 实时性 | 一致性 | 资源消耗 | 侵入性 | 适用规模 |
|---|---|---|---|---|---|
| CDC | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 低 | 无 | 任意(推荐) |
| 主动推送 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 低 | 有 | 自研系统 |
| SQL 轮询 | ⭐⭐ | ⭐⭐ | 高 | 无 | <10 表 + 低频 |
- CDC 优势 :
- 毫秒级延迟
- 精确捕获每一行变更(含 DELETE)
- 天然支持 Exactly-Once(配合 Kafka 事务)
- 轮询局限 :
- 高频轮询导致 DB IO 打满
- 无法保证不丢变更(如两次轮询间多次更新)
- 无全局顺序保证
工程建议 :
对于 100 表规模,CDC 是唯一可扩展的实时方案;轮询仅适用于低频维表兜底。
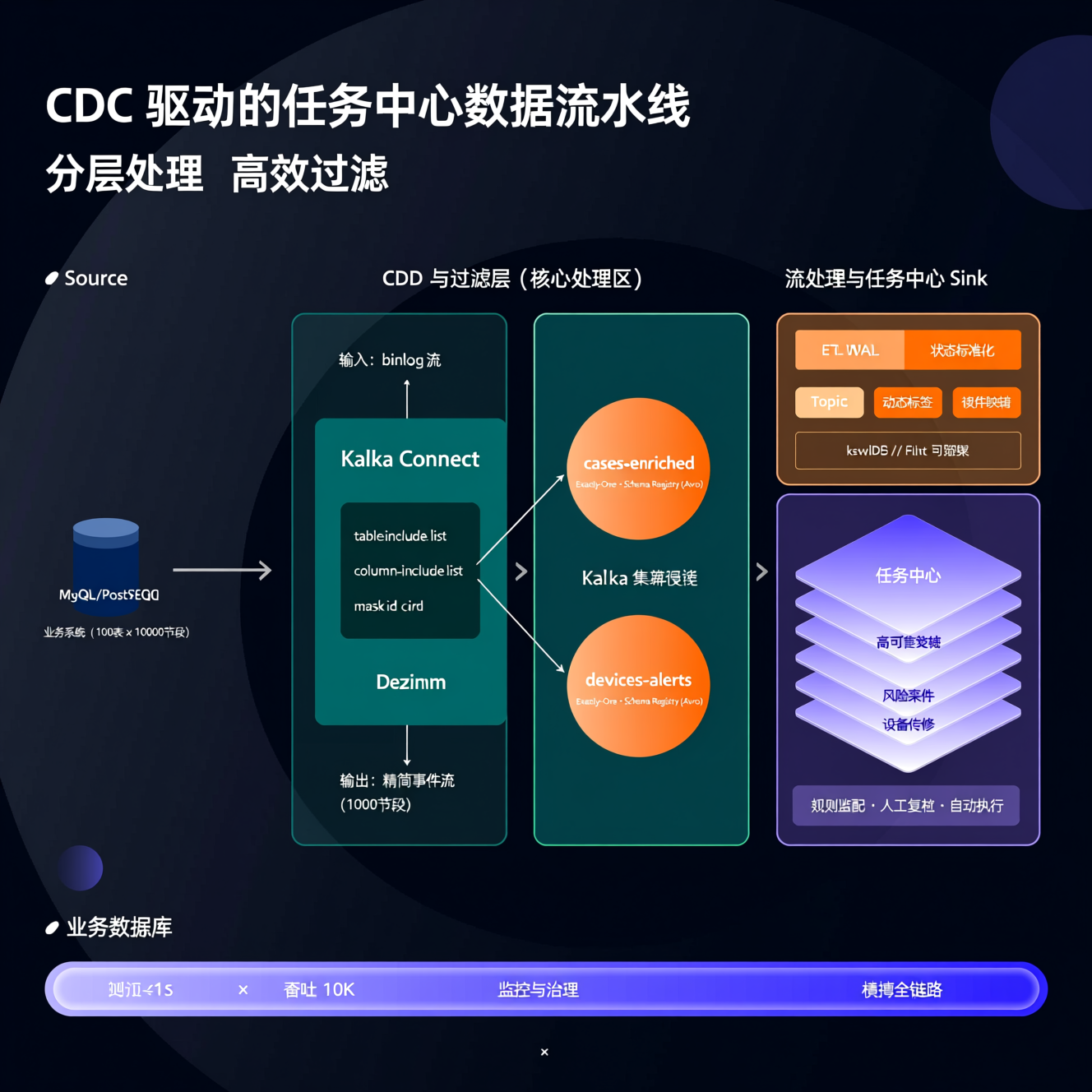
四、高效过滤与轻量 ETL:降低链路开销
同步 10000 字段中的 1000 个关键字段,需在数据源头完成裁剪,避免下游处理冗余数据。
1. Debezium 层:硬过滤
json
{
"table.include.list": "cases,devices",
"column.include.list": "cases.id,cases.status,cases.updated_at",
"column.mask.with.12.chars": "cases.id_card"
}- 表/字段级过滤,减少 90%+ 带宽
- 敏感字段脱敏,满足合规要求
2. 流处理层:轻量 ETL
使用 ksqlDB 或 Flink 对 CDC 流做标准化:
sql
-- ksqlDB: 状态映射
CREATE STREAM cases_enriched AS
SELECT id,
CASE status WHEN '1' THEN 'created' ELSE 'unknown' END AS norm_status
FROM cases_raw;- 字段映射、类型转换、简单 enrichment
- 输出结构化事件,供任务中心直接消费
五、生产级 CDC 架构关键实践
1. 部署模型
- Debezium 作为 Kafka Connect Source Connector 运行
- 无需单独服务,只需部署
debezium/connect镜像(含 Kafka Connect + Debezium 插件) - Kafka 集群独立部署,确保高可用
2. 可靠性保障
- Exactly-Once:Kafka 事务 + offset 持久化
- 全量+增量无缝切换:首次快照(MVCC 无锁)后自动切至增量流
- 监控指标 :同步延迟、吞吐量、位点滞后(
source.ts_ms - now())
3. Schema 演进
- 使用 Avro + Schema Registry
- 设置兼容性策略为
BACKWARD,支持新增可选字段 - 消费者自动适配表结构变更,无需停机
4. 删除语义处理
- 优先使用软删除 (
is_deleted=1) - 若物理删除不可避免,配置
tombstones.on.delete=false - 任务中心通过
op=d事件主动清理任务
六、总结:CDC 是任务中心的"数据基座"
CDC 不是"另一种同步工具",而是构建实时数据管道的基础设施 。它通过事务日志实现零侵入、高可靠、低延迟的变更捕获,为任务中心提供高质量输入。结合分层过滤、轻量 ETL 与流处理,可构建可扩展、可运维、可进化的智能任务系统。
最终目标 :
让数据同步成为"看不见的基础设施",而任务中心专注其核心价值------从数据中提炼行动。
注:本文不依赖特定厂商或项目背景,所有方案均基于开源技术栈(Debezium, Kafka, Flink, ksqlDB)验证,适用于金融、政务、工业、零售等高可靠场景。