文章目录
-
- 为什么会出现线程不安全?
- [C# 实现线程安全的常用手段](# 实现线程安全的常用手段)
-
- [1. 排它锁/互斥锁(Lock)](#1. 排它锁/互斥锁(Lock))
- [2. 原子操作(Interlocked)](#2. 原子操作(Interlocked))
- [3. 读写锁 (ReaderWriterLockSlim)](#3. 读写锁 (ReaderWriterLockSlim))
- [4. 线程安全集合](#4. 线程安全集合)
-
- [4.1. 线程安全集合的类型与特点](#4.1. 线程安全集合的类型与特点)
-
- [4.1.1. `System.Collections.Concurrent` 命名空间](#4.1.1.
System.Collections.Concurrent命名空间) - [4.1.2. 其他线程安全容器](#4.1.2. 其他线程安全容器)
- [4.1.1. `System.Collections.Concurrent` 命名空间](#4.1.1.
- [4.2. **线程安全集合的实现原理**](#4.2. 线程安全集合的实现原理)
-
- [1. 无锁算法(Lock-Free)](#1. 无锁算法(Lock-Free))
- [2. 分片设计(Partitioning)](#2. 分片设计(Partitioning))
- [3. 细粒度锁(Fine-Grained Locking)](#3. 细粒度锁(Fine-Grained Locking))
- [4. 阻塞同步](#4. 阻塞同步)
- [4.3. **示例与性能对比**](#4.3. 示例与性能对比)
-
- [1. `ConcurrentQueue` 生产者-消费者模型](#1.
ConcurrentQueue生产者-消费者模型) - [2. `ConcurrentDictionary` 高频计数](#2.
ConcurrentDictionary高频计数) - [3. 性能对比(普通集合 vs 线程安全集合)](#3. 性能对比(普通集合 vs 线程安全集合))
- [1. `ConcurrentQueue` 生产者-消费者模型](#1.
- [4.4. 线程安全集合的局限性](#4.4. 线程安全集合的局限性)
- 4.5.如何选择线程安全集合
- [4.6. 总结](#4.6. 总结)
- 易混淆
在软件工程中,处理并发就像管理一个繁忙的十字路口。如果没有任何规则,必然发生碰撞(数据损坏)。
在多线程环境下,多个线程同时访问同一块内存区域(比如一个变量或对象),如果最终的结果符合预期且程序没有崩溃或数据错乱,这就是线程安全。
通俗点说,线程安全就是给共享资源加了"红绿灯"或"排队机制",防止大家一哄而上把数据写乱。
为什么会出现线程不安全?
最经典的情况是 读-改-写 操作。假设一个变量 count = 0,两个线程同时执行 count++:
- 线程 A 读取
count为 0。 - 线程 B 读取
count为 0。 - 线程 A 计算 0 + 1 = 1,写入内存。
- 线程 B 计算 0 + 1 = 1,写入内存。结果本该是 2,现在变成了 1。这就是典型的"竞态条件"。
C# 实现线程安全的常用手段
1. 排它锁/互斥锁(Lock)
这是最常用、最简单的办法。它确保同一时刻只有一个线程能进入代码块。
lock 关键字是 Monitor 类的语法糖。它会在对象头中设置一个标记,强制其他线程排队。
- 注意 :永远不要 lock 一个
string或this。必须声明一个私有的readonly object。
csharp
private readonly object _locker = new object();
private int _count = 0;
public void Increment()
{
// 只有拿到 _locker 的线程才能进去
lock (_locker)
{
_count++;
}
}2. 原子操作(Interlocked)
如果你只是想做简单的加减法或替换lock太重了。底层 CPU 指令可以直接保证这些操作的原子性。
确保对共享变量的读写操作是线程安全的。
使用 Interlocked 类 避免竞争条件,可以在不阻塞线程(lock、Monitor)的情况下,对目标对象做修改。
| 方法 | 作用 |
|---|---|
| CompareExchange() | 比较两个数是否相等,如果相等,则替换第一个值。 |
| Decrement() | 以原子操作的形式递减指定变量的值并存储结果。 |
| Exchange() | 以原子操作的形式,设置为指定的值并返回原始值。 |
| Increment() | 以原子操作的形式递增指定变量的值并存储结果。 |
| Add() | 对两个数进行求和并用和替换第一个整数,上述操作作为一个原子操作完成。 |
| Read() | 返回一个以原子操作形式加载的值。 |
csharp
using System.Threading;
private int _count = 0;
public void Increment()
{
// 性能极高,直接在硬件层面保证一次性完成
Interlocked.Increment(ref _count);
}这是性能最高的方案。它不涉及内核对象的上下文切换,而是利用 CPU 的特殊指令(如 Compare-Exchange)直接完成操作。
适用场景:简单的计数器、状态标记。
csharp
private int _isRunning = 0; // 0: 停止, 1: 运行中
public void Start()
{
// 如果原值是 0,则改为 1。整个过程是原子的。
if (Interlocked.CompareExchange(ref _isRunning, 1, 0) == 0)
{
// 执行启动逻辑
}
}
ref _isStopping 目标位置,你想要修改的那个变量。必须用 ref,因为要直接修改内存。
1 (value) 期望写入的值 如果条件满足,你想把变量改成什么。
0 (comparand) 对比值 你认为这个变量现在应该是多少。
// 如果返回 0:说明在你修改之前,它的确是 0,你成功把它改成了 1。你是第一个抢到执行权的线程。
// 如果返回 1:说明在你尝试修改时,已经有别的线程把它改成 1 了。你"抢占"失败。
//或者比如这样
if (Interlocked.Exchange(ref _isExecuting, 1) == 1) return;
try
{
if (sender != null && sender is ListViewItem)
{
if (_studyHistoryItem.ExamCommand.CanExecute(null))
{
_logger.Debug($"HandleDoubleClick Source = {e.Source}");
_studyHistoryItem.ExamCommand.Execute(null);
}
}
}
finally
{
Interlocked.Exchange(ref _isExecuting, 0);
}3. 读写锁 (ReaderWriterLockSlim)
当你的场景是"多读少写"时,lock 会限制性能。可以使用 ReaderWriterLockSlim,它允许多个线程同时读,但在写的时候会排斥所有读写请求。
当你的数据被频繁读取,但很少修改时,用 lock 会导致读取操作也必须排队,效率极低。读写锁允许多个"读者"同时进入,但"写者"进入时会独占。
csharp
private ReaderWriterLockSlim _rwLock = new ReaderWriterLockSlim();
private List<string> _data = new List<string>();
public void ReadData()
{
_rwLock.EnterReadLock();
try { /* 执行读取 */ }
finally { _rwLock.ExitReadLock(); }
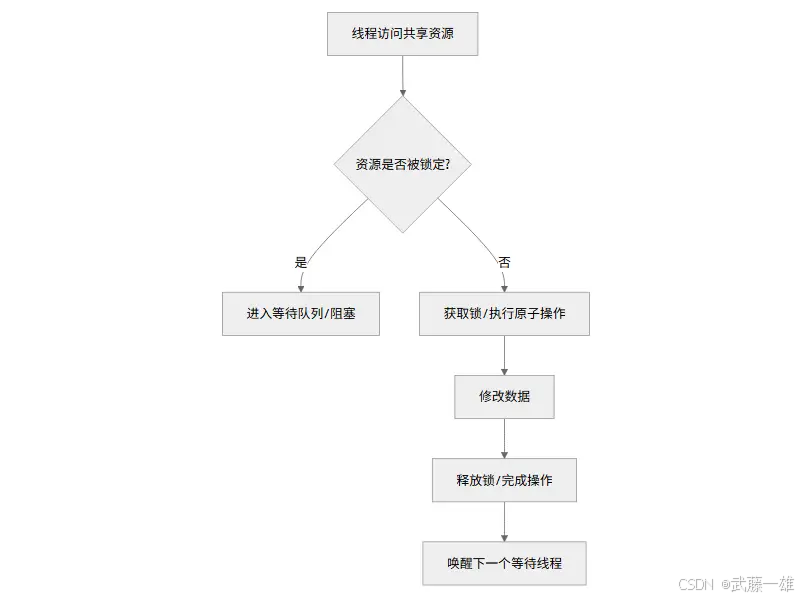
}4. 线程安全集合
不要在多线程里直接用 List 或 Dictionary<K, V> 。请使用 System.Collections.Concurrent 命名空间下的类。标准集合(如 List)在多线程下执行 Add 或 Foreach 极易抛出异常。并发集合内部通过分段锁或无锁算法(Lock-Free)解决了这个问题
- ConcurrentDictionary: 线程安全字典。
- ConcurrentQueue: 线程安全队列(无锁编程实现)。
4.1. 线程安全集合的类型与特点
4.1.1. System.Collections.Concurrent 命名空间
| 集合类型 | 数据结构 | 适用场景 | 核心特性 |
|---|---|---|---|
| ConcurrentQueue | 先进先出队列 | 生产者-消费者模型 | 无锁算法(CAS 操作) |
| ConcurrentStack | 后进先出栈 | 临时任务缓存 | 无锁(Treiber 栈) |
| ConcurrentBag | 无序集合 | 线程本地存储 + 全局共享 | 基于线程本地存储的分片设计 |
| ConcurrentDictionary<K,V> | 哈希表 | 高频键值读写 | 细粒度锁(桶级别锁) |
| BlockingCollection | 阻塞式集合 | 有界/无界队列 + 阻塞操作 | 封装 ConcurrentQueue 并提供阻塞语义 |
4.1.2. 其他线程安全容器
ImmutableCollections(不可变集合):每次修改返回新实例,天然线程安全(适合读多写极少场景)。Channel(.NET Core+):基于异步消息传递的高性能生产者-消费者模型。
4.2. 线程安全集合的实现原理
1. 无锁算法(Lock-Free)
ConcurrentQueue和ConcurrentStack:- 使用
Interlocked原子操作(如CompareExchange)更新头尾指针。 - 优点:高并发下性能优异(减少上下文切换)。
- 缺点:复杂的内存管理(ABA 问题需处理)。
- 使用
2. 分片设计(Partitioning)
ConcurrentBag:- 每个线程维护自己的本地队列,减少竞争。
- 当其他线程窃取任务时,访问其他线程的队列。
- 适用场景:任务分配不均匀的高并发环境。
3. 细粒度锁(Fine-Grained Locking)
ConcurrentDictionary:- 哈希表按桶(Bucket)划分,每个桶独立加锁。
- 读操作无锁(
volatile读),写操作桶锁。 - 优化点:桶数量与并发度的平衡(默认桶数 = CPU 核数 × 2)。
4. 阻塞同步
BlockingCollection:- 封装底层集合(如
ConcurrentQueue)并提供阻塞方法(Take、Add)。 - 使用
ManualResetEventSlim或SemaphoreSlim实现等待通知机制。
- 封装底层集合(如
4.3. 示例与性能对比
1. ConcurrentQueue 生产者-消费者模型
csharp
ConcurrentQueue<int> queue = new ConcurrentQueue<int>();
// 生产者
Task.Run(() => {
for (int i = 0; i < 1000; i++) {
queue.Enqueue(i);
}
});
// 消费者
Task.Run(() => {
while (queue.TryDequeue(out int item)) {
Console.WriteLine($"处理: {item}");
}
});2. ConcurrentDictionary 高频计数
csharp
ConcurrentDictionary<string, int> wordCounts = new ConcurrentDictionary<string, int>();
Parallel.ForEach(GetTextLines(), line => {
foreach (string word in line.Split()) {
wordCounts.AddOrUpdate(word, 1, (key, oldValue) => oldValue + 1);
}
});| 特性 | Dictionary | ConcurrentDictionary |
|---|---|---|
| 线程安全 | ❌ 需要手动加锁 | ✅ 内置线程安全 |
| 读性能 | 高 | 非常高(无锁读取) |
| 写性能 | 高 | 较高(细粒度锁) |
| 并发支持 | 需要同步机制 | 原生支持并发 |
| 内存开销 | 较低 | 稍高(维护内部结构) |
1. TryAdd()
csharp
bool success = concurrentDict.TryAdd("task3", 25);
// 成功添加返回 true,键已存在返回 false2. TryUpdate()
csharp
int currentValue;
do {
currentValue = concurrentDict["task1"];
} while (!concurrentDict.TryUpdate("task1", currentValue + 10, currentValue));
// 原子性更新:只有当前值等于 expectedValue 时才更新3. AddOrUpdate()
csharp
// 添加或更新(原子操作)
int newValue = concurrentDict.AddOrUpdate(
"task1",
key => 50, // 添加时的工厂函数
(key, oldValue) => oldValue + 10 // 更新时的函数
);4. GetOrAdd()
csharp
// 获取或添加(原子操作)
int value = concurrentDict.GetOrAdd("task4", key => 0);
// 如果 task4 不存在,初始化为 05. TryRemove()
csharp
if (concurrentDict.TryRemove("task2", out int removedValue))
{
Console.WriteLine($"已删除 task2,原值: {removedValue}");
}优先使用原子方法
csharp
// ✅ 推荐
dict.AddOrUpdate(key, 1, (k, v) => v + 1);
// ❌ 避免(非原子操作)
if (dict.ContainsKey(key)) {
dict[key] = dict[key] + 1;
}处理工厂函数副作用
csharp
// 工厂函数应简单无副作用
var value = dict.GetOrAdd(key, k => {
// 避免耗时操作
return CalculateInitialValue(k);
});迭代时处理并发修改
csharp
foreach (var pair in concurrentDict)
{
// 注意:迭代期间字典可能被修改
Process(pair.Value);
}值类型注意事项
csharp
// 值类型更新需特殊处理
var dict = new ConcurrentDictionary<string, (int, DateTime)>();
dict.AddOrUpdate("task",
k => (0, DateTime.UtcNow),
(k, v) => (v.Item1 + 1, DateTime.UtcNow)
);性能考量
- 读取密集型场景:性能接近无锁读取
- 写入密集型场景:比锁+Dictionary 性能高 2-3 倍
- 混合工作负载:在高并发下表现最佳
使用场景
- 缓存系统
- 实时监控/统计
- 并行计算中间结果
- 高并发计数器
- 任务调度系统(如所述进度监控)
总结
ConcurrentDictionary 是 .NET 中处理并发字典操作的首选方案,它:
- 提供线程安全的原子操作
- 比手动锁实现更高效
- 简化多线程编程模型
- 特别适合高频读写的场景
在任务进度监控系统中,使用 ConcurrentDictionary 可以安全高效地管理多个任务的进度状态,确保在高并发环境下数据的一致性和实时性。
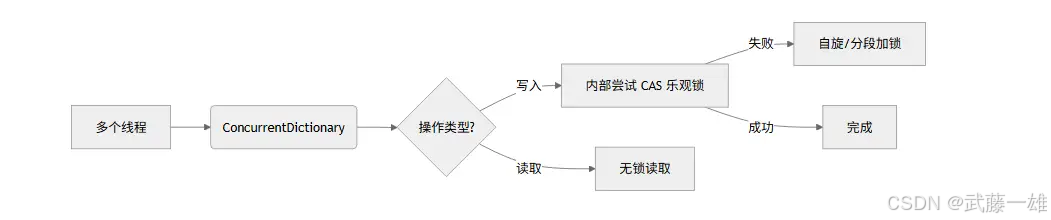
CAS (Compare-And-Swap): 比较并交换。一种乐观锁技术,检查内存值是否没变,没变才更新。
自旋 (Spin): 线程不进入阻塞挂起状态,而是循环检查锁是否释放,减少上下文切换开销。
3. 性能对比(普通集合 vs 线程安全集合)
| 操作 | List + lock | ConcurrentBag | 性能差异(百万次操作) |
|---|---|---|---|
| 添加元素 | ~1200 ms | ~450 ms | 2.6 倍更快 |
| 遍历元素 | ~200 ms | ~180 ms | 接近 |
4.4. 线程安全集合的局限性
1.复合操作非原子性:
// 非原子操作:先检查是否存在,再添加
if (!concurrentDict.ContainsKey(key)) {
concurrentDict.TryAdd(key, value); // 可能已被其他线程插入
}- 解决方案 :使用原子方法(如
GetOrAdd)。 - 内存开销 :
- 无锁结构和分片设计会增加内存占用(如
ConcurrentBag的线程本地存储)。
- 无锁结构和分片设计会增加内存占用(如
- 顺序性牺牲 :
ConcurrentQueue保证先进先出,但并行消费者可能乱序处理。
4.5.如何选择线程安全集合
| 场景 | 推荐集合 | 理由 |
|---|---|---|
| 高频生产者-消费者(无阻塞) | ConcurrentQueue | 无锁设计,吞吐量高 |
| 线程本地任务缓存 | ConcurrentBag | 分片减少竞争,适合线程本地存储 + 全局窃取 |
| 高频键值读写 | ConcurrentDictionary | 细粒度锁,避免全局锁竞争 |
| 异步消息管道 | Channel | 零拷贝、异步友好,适合高性能 IPC |
| 读多写少(数据几乎不变) | ImmutableDictionary | 无锁读,写操作返回新实例 |
4.6. 总结
- 优先使用标准库集合 :
ConcurrentCollections和ImmutableCollections覆盖绝大多数场景。 - 性能关键路径:根据读写模式选择无锁或细粒度锁结构。
- 避免重复造轮子:自定义实现需谨慎处理内存可见性、ABA 问题等底层细节。
- 复合操作:即使集合本身线程安全,多个操作的组合仍需额外同步(如事务性操作)。
易混淆
async / await 本身不保证线程安全
这是一个非常普遍的误区。async / await 解决的是异步 问题(不阻塞当前线程),而不是同步问题(保护共享资源)。
- 线程切换 :
await之后的代码可能会在不同的线程上运行(取决于SynchronizationContext)。 - 并发依然存在 :如果你在一个
async方法里修改全局变量,而这个方法被同时调用了两次,依然会发生数据错乱。 - 不能在 lock 块内使用 await :编译器不允许在
lock块里使用await,因为lock是基于线程标识的,而异步方法在await之后可能换了线程,导致无法释放锁。
解决方案 :如果需要在异步环境加锁,请使用 SemaphoreSlim(1, 1)。
csharp
private SemaphoreSlim _semaphore = new SemaphoreSlim(1, 1);
public async Task AccessResourceAsync()
{
await _semaphore.WaitAsync(); // 异步等待进入
try
{
// 这里可以安全地执行异步操作
await Task.Delay(100);
}
finally
{
_semaphore.Release();
}
}volatile
在 C# 中,volatile 是一个非常底层且容易被误导的关键字。它解决的不是"多个线程同时修改"的问题,而是解决**"内存可见性"和"指令重排"**的问题。
为什么需要 volatile?
在现代计算机架构中,为了提升性能,CPU 和编译器会对代码做两件事:
- 缓存变量:CPU 每一核都有自己的 L1/L2 缓存。线程 A 修改了一个变量,可能只写到了自己的缓存里,而线程 B 从主内存读到的还是旧值。
- 指令重排:编译器或 CPU 为了优化速度,可能会调整代码的执行顺序。
volatile 告诉编译器:不要对我做任何优化,每次读写都必须直接操作主内存(Main Memory)。
核心作用
- 保证可见性
当一个线程修改了 volatile 变量,其他线程能立即看到最新值。
- 禁止指令重排
它会在读写操作前后插入"内存屏障"(Memory Barrier),防止编译器把原本应该在它之后的指令挪到它前面。
典型场景:单标记停止(Stop Flag)
这是 volatile 最常见的用法。如果不用 volatile,线程 B 可能会因为编译器优化(认为 _stop 在循环中没变过)而永远死循环。
csharp
public class Worker
{
// 必须加 volatile,确保线程 B 能看到线程 A 的修改
private volatile bool _stop = false;
public void Run()
{
// 线程 B 执行
while (!_stop)
{
// 执行任务
}
Console.WriteLine("线程已停止");
}
public void RequestStop()
{
// 线程 A 执行
_stop = true;
}
}关键区别:volatile vs lock
很多初学者会混淆两者,看下表对比:
| 特性 | volatile | lock / Interlocked |
|---|---|---|
| 原子性 | 不保证(不能保证 i++ 安全) | 保证原子操作 |
| 阻塞 | 非阻塞(无锁) | 会导致线程阻塞(挂起) |
| 开销 | 极低(仅禁止缓存优化) | 较高(涉及线程上下文切换) |
| 适用场景 | 单个简单变量的读写、状态标记 | 复杂的逻辑块、复合操作(如读-改-写) |
volatile 的局限性
它不能替代锁。
如果你执行 volatileVariable++,这实际上包含三步:取值、加一、写回。volatile 只能保证取值和写回时内存是同步的,但在加一的过程中,如果有其他线程介入,数据依然会错乱。这种场景必须用 Interlocked.Increment 或 lock。
内存可见性 (Memory Visibility): 指当一个线程修改了共享变量的值,其他线程能够立即得知这个修改。
指令重排 (Instruction Reordering): 编译器或处理器为了提高性能,在不影响单线程执行结果的前提下,对指令执行顺序进行调整。
内存屏障 (Memory Barrier): 一种 CPU 指令,用于同步内存访问,确保屏障前后的指令不会被乱序执行。