介绍一下这个项目
这是一个基于Spring Boot 3和Java 21构建的高并发点赞系统,专门设计用于点赞场景。该系统支持高并发、高可用和可观测性,采用了多级缓存和异步处理等架构设计,能够在大规模流量下保持稳定运行。
技术选型:
- 后端框架:Spring Boot 3 + Java 21虚拟线程
- 数据库:MySQL + MyBatis-Plus 和 TiDB分布式数据库
- 缓存系统:Redis多级缓存 + 本地热点缓存(HeavyKeeper算法)
- 消息队列:Apache Pulsar
- 监控和可观测性:Prometheus + Grafana
- 容器化部署:Docker
- 网关负载均衡:Nginx
核心功能:
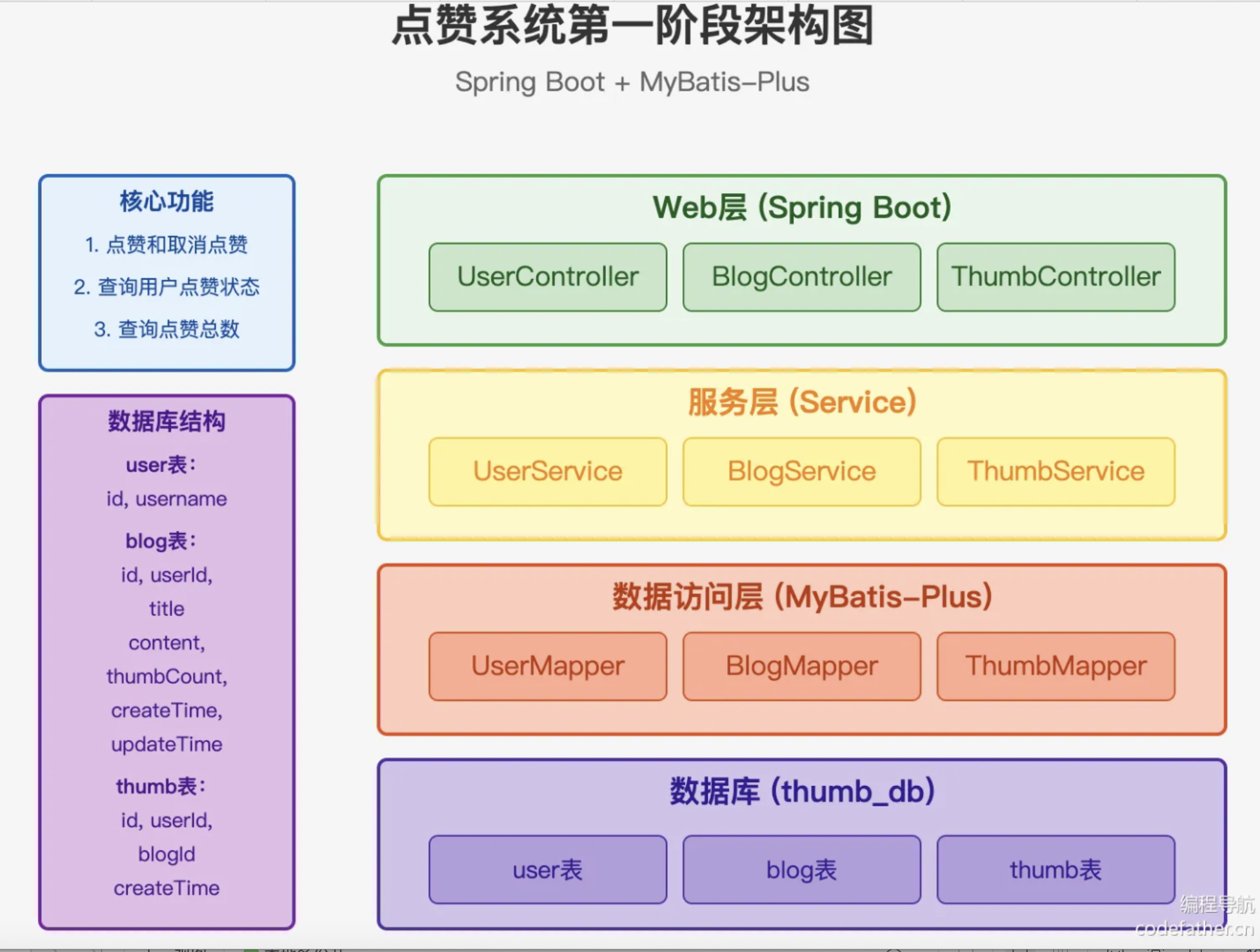
- 点赞/取消点赞
通过ThumbController接收操作请求
ThumbService处理业务逻辑:
• 校验用户/文章有效性
• 更新thumb表记录
• 同步更新blog表的thumbCount计数器
- 状态查询
采用组合查询方式:
• 检查thumb表是否存在对应记录
• 返回布尔型状态标识
- 统计功能
基于blog表的thumbCount字段
支持实时查询文章点赞总数


基础功能怎么实现的?
1. 登录
在后端,登录请求由 UserController 处理:
java
@RestController
@RequestMapping("user")
public class UserController {
@Resource
private UserService userService;
@GetMapping("/login")
public BaseResponse<User> login(long userId, HttpServletRequest request) {
User user = userService.getById(userId);
request.getSession().setAttribute(UserConstant.LOGIN_USER, user);
return ResultUtils.success(user);
}
}身份验证流程
- 用户在登录表单中输入 ID(无密码)
- 表单提交调用 handleLogin(),进而调用 userStore.login()
- store使用 userApi.login() 向 /api/user/login?userId={userId} 发出 GET 请求
- 后端 UserController.login() 方法:
- 使用 userService.getById() 从数据库获取用户
- 使用 request.getSession().setAttribute() 将用户存储在会话中
- 返回用户数据
响应成功后,前端:
- 更新 Pinia store状态(currentUser 和 isLoggedIn)
- 将 userId 保存到 localStorage 进行持久化
- 重定向到主页
2. 获取当前登录用户
在UserController下新建接口:
java
@GetMapping("/get/login")
public BaseResponse<User> getLoginUser(HttpServletRequest request) {
User loginUser = (User) request.getSession().getAttribute(UserConstant.LOGIN_USER);
return ResultUtils.success(loginUser);
}3. 获取博客(循环依赖)
在 model.vo 下新建 BlogVO 类,这是一个视图包装类,可以额外关联上传图片的点赞信息、用户信息
等。除此之外,还可以编写 Blog 实体类和该VO 类的转换方法,便于后续快速传值,不过本项目中没有必要。
在BlogService添加根据Blog id获取对应blog的方法:
java
BlogVO getBlogVOById(long blogId, HttpServletRequest request);实现:
java
@Resource
private UserService userService;
@Resource
@Lazy
private ThumbService thumbService;
@Override
public BlogVO getBlogVOById(long blogId, HttpServletRequest request) {
Blog blog = this.getById(blogId);
User loginUser = userService.getLoginUser(request);
return this.getBlogVO(blog, loginUser);
}
private BlogVO getBlogVO(Blog blog, User loginUser) {
BlogVO blogVO = new BlogVO();
BeanUtil.copyProperties(blog, blogVO);
if (loginUser == null) {
return blogVO;
}
Thumb thumb = thumbService.lambdaQuery()
.eq(Thumb::getUserId, loginUser.getId())
.eq(Thumb::getBlogId, blog.getId())
.one();
blogVO.setHasThumb(thumb != null);
return blogVO;
}getBlogVO会根据用户是否已登录(loginUser不为空),获取当前登录用户是否已经点赞该博客并设置到blogVO中。
注意:因为后续我们会在 thumbService 中引入 blogService,所以这里在引入 thumbService 时标注了 @lazy 注解,用来解决循环引用问题。当两个 Bean 相互依赖时,@Lazy 会让其中一个 Bean 的初始化推迟到第一次使用时,从而打破初始化阶段的死循环。
执行流程变化:
- 创建
Chicken时,发现需要Egg但被标记为@Lazy - Spring 会先创建一个
Egg的代理对象(不是真实对象) - 完成
Chicken的初始化 - 当
Chicken第一次调用egg的方法时:- 触发真实
Egg的创建 - 此时
Chicken已经存在 → 可以正常注入到Egg中
- 触发真实
换到这里,当我获取一篇博客时,我需要知道当前用户对该博客是否已经点赞;当我要看点赞数量或状态时,我必须知道我要看的是哪篇博客的点赞信息!!!这就是循环依赖。
BlogController添加接口:
java
@RestController
@RequestMapping("blog")
public class BlogController {
@Resource
private BlogService blogService;
@GetMapping("/get")
public BaseResponse<BlogVO> get(long blogId, HttpServletRequest request) {
BlogVO blogVO = blogService.getBlogVOById(blogId, request);
return ResultUtils.success(blogVO);
}
}4. 获取博客列表
java
@Override
public List<BlogVO> getBlogVOList(List<Blog> blogList, HttpServletRequest request) {
User loginUser = userService.getLoginUser(request);
Map<Long, Boolean> blogIdHasThumbMap = new HashMap<>();
if (ObjUtil.isNotEmpty(loginUser)) {
Set<Long> blogIdSet = blogList.stream().map(Blog::getId).collect(Collectors.toSet());
// 获取点赞
List<Thumb> thumbList = thumbService.lambdaQuery()
.eq(Thumb::getUserId, loginUser.getId())
.in(Thumb::getBlogId, blogIdSet)
.list();
thumbList.forEach(blogThumb -> blogIdHasThumbMap.put(blogThumb.getBlogId(), true));
}
return blogList.stream()
.map(blog -> {
BlogVO blogVO = BeanUtil.copyProperties(blog, BlogVO.class);
blogVO.setHasThumb(blogIdHasThumbMap.get(blog.getId()));
return blogVO;
})
.toList();
}先批量查出当前登录用户对这批博客的点赞记录,然后在内存中进行判断处理,避免循环查库
5. 点赞
java
@Service
@Slf4j
@RequiredArgsConstructor
public class ThumbServiceImpl extends ServiceImpl<ThumbMapper, Thumb> implements ThumbService {
private final UserService userService;
private final BlogService blogService;
private final TransactionTemplate transactionTemplate;
@Override
public Boolean doThumb(DoThumbRequest doThumbRequest, HttpServletRequest request) {
if (doThumbRequest == null || doThumbRequest.getBlogId() == null) {
throw new RuntimeException("参数错误");
}
User loginUser = userService.getLoginUser(request);
// 加锁
synchronized (loginUser.getId().toString().intern()) {
// 编程式事务
return transactionTemplate.execute(status -> {
Long blogId = doThumbRequest.getBlogId();
boolean exists = this.lambdaQuery()
.eq(Thumb::getUserId, loginUser.getId())
.eq(Thumb::getBlogId, blogId)
.exists();
if (exists) {
throw new RuntimeException("用户已点赞");
}
boolean update = blogService.lambdaUpdate()
.eq(Blog::getId, blogId)
.setSql("thumbCount = thumbCount + 1")
.update();
Thumb thumb = new Thumb();
thumb.setUserId(loginUser.getId());
thumb.setBlogId(blogId);
// 更新成功才执行
return update && this.save(thumb);
});
}
}
}-
继承MyBatis-Plus的ServiceImpl,获得基础CRUD能力
-
doThumbRequest:封装了blogId等请求参数;request:用于获取当前用户信息 -
使用MyBatis-Plus的Lambda查询
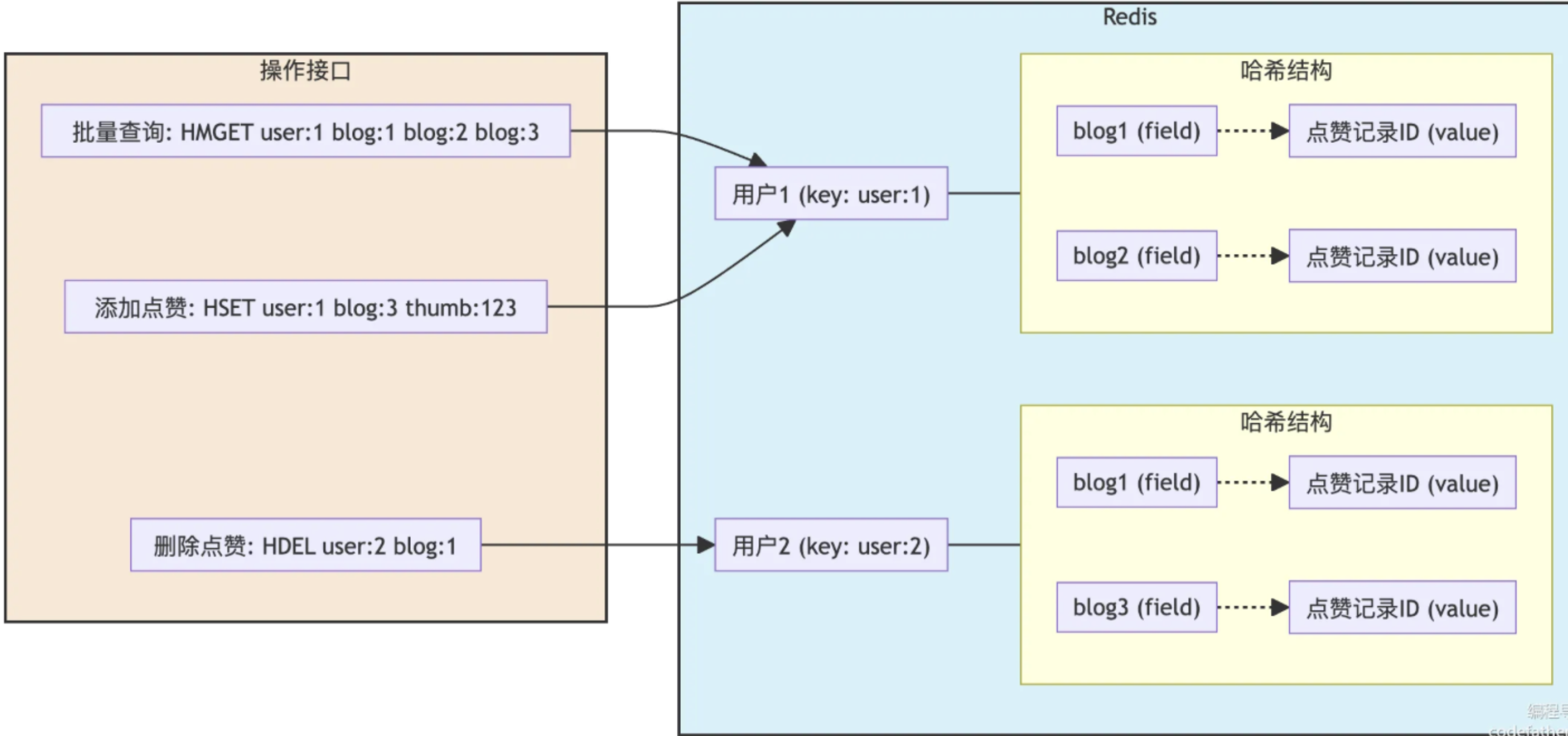
通过Redis的hMGet命令获取用户点赞状态优化(避免多次单条查询)
通过Redis的hMGet命令 实现批量获取用户点赞状态(批量是指当前登录用户对一批博客的点赞状态)
基于用户角度,选择hash结构存储(在redis中,哈希类型是指Redis键值对中的值本身又是一个键值对结构)。key 为用户 id,field为博客 id,value为 点赞记录 id。这样在批量查询时,能够通过 hMGet 命令获取用户的点赞数据,新点赞时用 HSet 命令添加。

是否已点赞接口:
java
private final RedisTemplate<String, Object> redisTemplate;
@Override
public Boolean hasThumb(Long blogId, Long userId) {
return redisTemplate.opsForHash().hasKey(ThumbConstant.USER_THUMB_KEY_PREFIX + userId, blogId.toString());
}原点赞服务中判断是否已点赞的逻辑修改:
java
Boolean exists = this.hasThumb(blogId, loginUser.getId());点赞成功后,还要将点赞记录存在redis中:
java
boolean success = update && this.save(thumb);
// 点赞记录存入 Redis
if (success) {
redisTemplate.opsForHash().put(ThumbConstant.USER_THUMB_KEY_PREFIX + loginUser.getId().toString(), blogId.toString(), thumb.getId());
}
// 更新成功才执行
return success;原批量获取博客的方法修改:
java
...
if (ObjUtil.isNotEmpty(loginUser)) {
List<Object> blogIdList = blogList.stream().map(blog -> blog.getId().toString()).collect(Collectors.toList());
// 获取点赞
List<Object> thumbList = redisTemplate.opsForHash().multiGet(ThumbConstant.USER_THUMB_KEY_PREFIX + loginUser.getId(), blogIdList);
for (int i = 0; i < thumbList.size(); i++) {
if (thumbList.get(i) == null) {
continue;
}
blogIdHasThumbMap.put(Long.valueOf(blogIdList.get(i).toString()), true);
}
}
...multiGet即是对hMGet命令的封装
注意:我们这里并没有设置过期时间,因为如果有过期时间,那就需要考虑缓存中不存在数据的情况,可能是因为过期、也可能是因为本来就没点赞,就必须要去数据库中查询。但是在正常的业务场景中,绝大部分的博客、内容应该都是未被用户点赞的,那就意味着这些数据都需要通过 Redis查一次,再去MySQL 查一次,结果还是未点赞。不仅没有降低MySQL的读压力,反而多请求了一次Redis,这就与我们引入缓存的初衷相悖了。
即使这样,在生产环境中保存大量不会过期且持续增加的数据还是不可取的,那我们该怎么办呢?
可以采用 冷热分离 的策略。比如我们认为最近一个月新发的内容是热数据,那么可以让 Redis 中点赞记录的存在时间是帖子的发布时间+1个月 ,如果点赞时该博客的发布时间不超过一个月,则查 Redis 校验是否已点赞;如果发布时间超过了一个月,则通过 MySQL 校验是否已点赞。
还可以引入布隆过滤器,布隆过滤器中存在再进行后续步骤,否则直接返回未点赞
但是还有一个问题,Redis 中是不支持针对 Hash 结构中的具体某个属性设置过期时间的!我们可以调整value 的数据结构,比如调整为:
bash
{
"thumbId":xxx,
"expireTime":xxx
}点赞实现1: 使用 Hash 结构存储用户点赞关系(读压力)

在Redis中,我们使用Hash结构存储用户点赞记录/状态,用于追踪用户点赞过的博客,键为用户ID,字段为博客ID,值为布尔值表示是否点赞。对于用户 123,键为 thumb:123,其中博客 ID 作为字段,值 1 表示对该博客点赞。
- Key:thumb:{userId}
- Field: {blogId}
- Value: 1: 点赞
同时,我们设计了临时点赞记录,按时间戳分片存储待同步的操作。这种时间分片策略有利于并行处理和问题追踪。
- Key:thumb:temp:{timeSlice}
- Field:{userId}:{blogId}
- Value:操作类型(1:点赞,-1:取消点赞,0:无变化)
简言之:每次点赞后会生成两种点赞记录,用户点赞记录是为了快速获取当前登录用户是否点赞,而临时点赞记录是为了将本次点赞同步到数据库中。
两种点赞记录的应用如下图所示:

编写 Lua 脚本保证多条 Redis 命令的原子性(点赞中的读写一致)
在上述点赞操作中,我们需要同时完成"记录点赞状态"和"写入临时记录"两个操作。如果分开执行这两个 Redis 操作,步骤 2执行结束 记录点赞状态之后系统宕机了,这里就会数据不一致。
Lua 脚本通过原子操作的特性,保证点赞状态和临时记录要么同时存在,要么同时不存在,不会因为系统宕机而导致数据不一致。
这是一个重要的优化点,因为在原来的实现中,我们需要使用synchronized 锁来保证同一用户的点赞操作串行执行,并且需要使用事务来保证数据库操作的一致性。而使用Lua 脚本后,锁和事务都可以去掉,提升系统性能 ,因为:
-
Lua 脚本在 Redis 中是原子执行的,不需要额外加锁
-
点赞操作被转移到 Redis 中,不需要事务,定时任务会将数据批量同步到数据库,避免了事务的开销。
java
@Service("thumbService")
@Slf4j
@RequiredArgsConstructor
public class ThumbServiceRedisImpl extends ServiceImpl<ThumbMapper, Thumb> implements ThumbService {
private final UserService userService;
private final RedisTemplate<String, Object> redisTemplate;
@Override
public Boolean doThumb(DoThumbRequest doThumbRequest, HttpServletRequest request) {
if (doThumbRequest == null || doThumbRequest.getBlogId() == null) {
throw new RuntimeException("参数错误");
}
User loginUser = userService.getLoginUser(request);
Long blogId = doThumbRequest.getBlogId();
String timeSlice = getTimeSlice();
// Redis Key
String tempThumbKey = RedisKeyUtil.getTempThumbKey(timeSlice);
String userThumbKey = RedisKeyUtil.getUserThumbKey(loginUser.getId());
// 执行 Lua 脚本
long result = redisTemplate.execute(
RedisLuaScriptConstant.THUMB_SCRIPT,
Arrays.asList(tempThumbKey, userThumbKey),
loginUser.getId(),
blogId
);
if (LuaStatusEnum.FAIL.getValue() == result) {
throw new RuntimeException("用户已点赞");
}
// 更新成功才执行
return LuaStatusEnum.SUCCESS.getValue() == result;
}
@Override
public Boolean undoThumb(DoThumbRequest doThumbRequest, HttpServletRequest request) {
if (doThumbRequest == null || doThumbRequest.getBlogId() == null) {
throw new RuntimeException("参数错误");
}
User loginUser = userService.getLoginUser(request);
Long blogId = doThumbRequest.getBlogId();
// 计算时间片
String timeSlice = getTimeSlice();
// Redis Key
String tempThumbKey = RedisKeyUtil.getTempThumbKey(timeSlice);
String userThumbKey = RedisKeyUtil.getUserThumbKey(loginUser.getId());
// 执行 Lua 脚本
long result = redisTemplate.execute(
RedisLuaScriptConstant.UNTHUMB_SCRIPT,
Arrays.asList(tempThumbKey, userThumbKey),
loginUser.getId(),
blogId
);
// 根据返回值处理结果
if (result == LuaStatusEnum.FAIL.getValue()) {
throw new RuntimeException("用户未点赞");
}
return LuaStatusEnum.SUCCESS.getValue() == result;
}
private String getTimeSlice() {
DateTime nowDate = DateUtil.date();
// 获取到当前时间前最近的整数秒,比如当前 11:20:23 ,获取到 11:20:20
return DateUtil.format(nowDate, "HH:mm:") + (DateUtil.second(nowDate) / 10) * 10;
}
@Override
public Boolean hasThumb(Long blogId, Long userId) {
return redisTemplate.opsForHash().hasKey(RedisKeyUtil.getUserThumbKey(userId), blogId.toString());
}
}lua脚本:
Lua
public class RedisLuaScriptConstant {
/**
* 点赞 Lua 脚本
* KEYS[1] -- 临时计数键
* KEYS[2] -- 用户点赞状态键
* ARGV[1] -- 用户 ID
* ARGV[2] -- 博客 ID
* 返回:
* -1: 已点赞
* 1: 操作成功
*/
public static final RedisScript<Long> THUMB_SCRIPT = new DefaultRedisScript<>("""
local tempThumbKey = KEYS[1] -- 临时计数键(如 thumb:temp:{timeSlice})
local userThumbKey = KEYS[2] -- 用户点赞状态键(如 thumb:{userId})
local userId = ARGV[1] -- 用户 ID
local blogId = ARGV[2] -- 博客 ID
-- 1. 检查是否已点赞(避免重复操作)
if redis.call('HEXISTS', userThumbKey, blogId) == 1 then
return -1 -- 已点赞,返回 -1 表示失败
end
-- 2. 获取旧值(不存在则默认为 0)
local hashKey = userId .. ':' .. blogId
local oldNumber = tonumber(redis.call('HGET', tempThumbKey, hashKey) or 0)
-- 3. 计算新值
local newNumber = oldNumber + 1
-- 4. 原子性更新:写入临时计数 + 标记用户已点赞
redis.call('HSET', tempThumbKey, hashKey, newNumber)
redis.call('HSET', userThumbKey, blogId, 1)
return 1 -- 返回 1 表示成功
""", Long.class);
/**
* 取消点赞 Lua 脚本
* 参数同上
* 返回:
* -1: 未点赞
* 1: 操作成功
*/
public static final RedisScript<Long> UNTHUMB_SCRIPT = new DefaultRedisScript<>("""
local tempThumbKey = KEYS[1] -- 临时计数键(如 thumb:temp:{timeSlice})
local userThumbKey = KEYS[2] -- 用户点赞状态键(如 thumb:{userId})
local userId = ARGV[1] -- 用户 ID
local blogId = ARGV[2] -- 博客 ID
-- 1. 检查用户是否已点赞(若未点赞,直接返回失败)
if redis.call('HEXISTS', userThumbKey, blogId) ~= 1 then
return -1 -- 未点赞,返回 -1 表示失败
end
-- 2. 获取当前临时计数(若不存在则默认为 0)
local hashKey = userId .. ':' .. blogId
local oldNumber = tonumber(redis.call('HGET', tempThumbKey, hashKey) or 0)
-- 3. 计算新值并更新
local newNumber = oldNumber - 1
-- 4. 原子性操作:更新临时计数 + 删除用户点赞标记
redis.call('HSET', tempThumbKey, hashKey, newNumber)
redis.call('HDEL', userThumbKey, blogId)
return 1 -- 返回 1 表示成功
""", Long.class);
}点赞后,记录点赞状态,同时定时任务将临时点赞记录同步到数据库中:
java
/**
* 定时将 Redis 中的临时点赞数据同步到数据库
*
*/
@Component
@Slf4j
public class SyncThumb2DBJob {
@Resource
private ThumbService thumbService;
@Resource
private BlogMapper blogMapper;
@Resource
private RedisTemplate<String, Object> redisTemplate;
@Scheduled(fixedRate = 10000)
@Transactional(rollbackFor = Exception.class)
public void run() {
log.info("开始执行");
DateTime nowDate = DateUtil.date();
// 如果秒数为0~9 则回到上一分钟的50秒
int second = (DateUtil.second(nowDate) / 10 - 1) * 10;
if (second == -10) {
second = 50;
// 回到上一分钟
nowDate = DateUtil.offsetMinute(nowDate, -1);
}
String date = DateUtil.format(nowDate, "HH:mm:") + second;
syncThumb2DBByDate(date);
log.info("临时数据同步完成");
}
public void syncThumb2DBByDate(String date) {
// 获取到临时点赞和取消点赞数据
String tempThumbKey = RedisKeyUtil.getTempThumbKey(date);
Map<Object, Object> allTempThumbMap = redisTemplate.opsForHash().entries(tempThumbKey);
boolean thumbMapEmpty = CollUtil.isEmpty(allTempThumbMap);
// 同步 点赞 到数据库
// 构建插入列表并收集blogId
Map<Long, Long> blogThumbCountMap = new HashMap<>();
if (thumbMapEmpty) {
return;
}
ArrayList<Thumb> thumbList = new ArrayList<>();
LambdaQueryWrapper<Thumb> wrapper = new LambdaQueryWrapper<>();
boolean needRemove = false;
for (Object userIdBlogIdObj : allTempThumbMap.keySet()) {
String userIdBlogId = (String) userIdBlogIdObj;
String[] userIdAndBlogId = userIdBlogId.split(StrPool.COLON);
Long userId = Long.valueOf(userIdAndBlogId[0]);
Long blogId = Long.valueOf(userIdAndBlogId[1]);
// -1 取消点赞,1 点赞
Integer thumbType = Integer.valueOf(allTempThumbMap.get(userIdBlogId).toString());
if (thumbType == ThumbTypeEnum.INCR.getValue()) {
Thumb thumb = new Thumb();
thumb.setUserId(userId);
thumb.setBlogId(blogId);
thumbList.add(thumb);
} else if (thumbType == ThumbTypeEnum.DECR.getValue()) {
// 拼接查询条件,批量删除
needRemove = true;
wrapper.or().eq(Thumb::getUserId, userId).eq(Thumb::getBlogId, blogId);
} else {
if (thumbType != ThumbTypeEnum.NON.getValue()) {
log.warn("数据异常:{}", userId + "," + blogId + "," + thumbType);
}
continue;
}
// 计算点赞增量
blogThumbCountMap.put(blogId, blogThumbCountMap.getOrDefault(blogId, 0L) + thumbType);
}
// 批量插入
thumbService.saveBatch(thumbList);
// 批量删除
if (needRemove) {
thumbService.remove(wrapper);
}
// 批量更新博客点赞量
if (!blogThumbCountMap.isEmpty()) {
blogMapper.batchUpdateThumbCount(blogThumbCountMap);
}
// 异步删除
Thread.startVirtualThread(() -> {
redisTemplate.delete(tempThumbKey);
});
}
}在这个定时任务中,我们按照时间戳从Redis中获取临时点赞数据,分别处理点赞和取消点赞操作后再将数据批量入库,最后使用虚拟线程异步删除已处理的临时数据。
不过由于把临时点赞数据存入Redis 的时候,我们没有记录用户的操作时间,所以将写入数据库的时间作为点赞记录的创建时间,跟用户实际点赞时间就会有一点误差(我们的定时任务10s执行一次,所以误差一般会在10s内) 。因为在本项目里其他地方没有用到这个数据,而且误差不大,所以一般是可以容忍的。不过大家在做的时候也可以考虑优化下这里,很简单,将点赞时间也存到临时记录里,在批量将数据写入数据库的时候使用实际点赞时间即可。
还有一点需要注意,在数据量较大、定时任务执行时间超过10s 时,这个任务就会影响后续的定时任务
执行,可能导致部分临时点赞记录没有及时被处理,需要等到补偿任务执行数据才恢复一致。
补偿任务:
java
/**
* 定时将 Redis 中的临时点赞数据同步到数据库的补偿措施
*
*/
@Component
@Slf4j
public class SyncThumb2DBCompensatoryJob {
@Resource
private RedisTemplate<String, Object> redisTemplate;
@Resource
private SyncThumb2DBJob syncThumb2DBJob;
@Scheduled(cron = "0 0 2 * * *")
public void run() {
log.info("开始补偿数据");
Set<String> thumbKeys = redisTemplate.keys(RedisKeyUtil.getTempThumbKey("") + "*");
Set<String> needHandleDataSet = new HashSet<>();
thumbKeys.stream().filter(ObjUtil::isNotNull).forEach(thumbKey -> needHandleDataSet.add(thumbKey.replace(ThumbConstant.TEMP_THUMB_KEY_PREFIX.formatted(""), "")));
if (CollUtil.isEmpty(needHandleDataSet)) {
log.info("没有需要补偿的临时数据");
return;
}
// 补偿数据
for (String date : needHandleDataSet) {
syncThumb2DBJob.syncThumb2DBByDate(date);
}
log.info("临时数据补偿完成");
}
}基于 Redis Hash 结构和 Caffeine 构建两级缓存(HotKey)
为了解决超级热点问题,我们可以采用多级缓存策略引入本地缓存,不过考虑到本地缓存的成本问题,肯定不能将所有的数据存起来,所以还需要结合热点检测机制

本地缓存的框架我们选择 caffeine,它比较适合数据量有限的小型数据集以及高频、低延迟的短期热点数据。
Caffeine 是一款基于 Java 的高性能本地缓存库,由 Google Guava 缓存改进而来,并被 Spring Framework 5+ 选为默认本地缓存实现:
1. 高性能与线程安全
- 底层采用
ConcurrentHashMap实现,支持并发读写和 O(1) 时间复杂度操作 - 通过减少锁竞争和优化内存分配,实现高吞吐量(单节点 QPS 可达 10 万+)
- 智能淘汰策略
- W-TinyLFU:结合 LRU(最近最少使用)和 LFU(最不经常使用)算法,通过频率统计实现接近理论最优的缓存命中率
- 容量控制 :支持基于条目数(
maximumSize)或权重(maximumWeight)的淘汰机制 - 时间策略 :提供写入后过期(
expireAfterWrite)、访问后过期(expireAfterAccess)和定时刷新(refreshAfterWrite)
引入 HeavyKeeper 算法识别热点内容(HotKey)

HeavyKeeper是一种用于高流速数据流中快速识别Top-K高频元素 的算法,由B站技术团队优化并应用。其核心是通过哈希指纹+概率衰减的设计,在有限内存中高效筛选出高频元素,尤其适合互联网场景下符合"二八定律"的数据分布。
算法所需的数据结构:
- 一个二维数组,它有d行w列(通过d个哈希函数映射到每行的某个位置,类似于布隆过滤器)
python
# 示例结构(d=3行,w=5列)
[
[ {指纹:123, 计数:5}, {指纹:456, 计数:3}, ... ], # 第1行
[ {指纹:789, 计数:7}, {指纹:123, 计数:2}, ... ], # 第2行
[ {指纹:456, 计数:9}, {指纹:000, 计数:0}, ... ] # 第3行
]2. 计数衰减机制,当发生哈希冲突时,不是简单覆盖,而是通过概率衰减原有计数
- 一个大小为k的最小堆,用于记录当前观测到的topK项
算法过程:
-
当一个key到达时,对这个key应用d个哈希函数,映射到d个数组中的桶
-
对每个映射到的桶:
- 如果桶为空 或 已存储的哈希指纹与当前的哈希指纹相同,增加计数
- 如果发生冲突,以概率P(decay) = 1 / (b^C)衰减原有计数,生成一个随机数与decay概率相比较,若比P(decay)小则衰减。若归零则替换为新元素
- 最小堆维护:
- 最小堆辅助:实时维护当前Top-K元素及最小阈值
- 淘汰机制:新元素计数需超过堆最小值才能入选
有了Caffeine + redis + mysql的多级缓存架构和HotKey检测后,缓存的访问流程为:
-
先查询本地缓存,命中后直接返回
-
本地缓存未命中,查询redis
-
每次访问都记录key的访问频率
-
对于访问频率高的key,将数据缓存到本地
点赞实现2: 集成 Pulsar 消息队列,将点赞操作异步化处理(写压力)

Apache Pulsar 是一款云原生的分布式消息流平台,由 Yahoo 开发并于 2016 年开源,现为 Apache 顶级项目。它集消息队列、流处理和持久化存储于一体,专为高吞吐、低延迟的大规模实时场景设计。以下是其核心特性及技术实现的深度解析:
Pulsar 采用 分层架构,将计算层(Broker)与存储层(BookKeeper)解耦
- Broker:无状态节点,负责消息路由、负载均衡和协议处理。通过 ZooKeeper 协调元数据,支持动态扩缩容
- BookKeeper:分布式预写日志(WAL)系统,由多个 Bookie 节点组成,每个分片(Ledger)以追加写入方式存储,确保数据强一致性和高吞吐(每秒百万级消息)
- ZooKeeper:管理集群元数据,未来计划逐步减少依赖
灵活的订阅模式
- 独占(Exclusive):单消费者独占 Topic,一个 Subscription 只能与一个 Consumer 关联,只有这个 Consumer 可以接收到 Topic 的全部消息,如果该 Consumer 出现故障了就会停止消费。适合严格有序场景。
- 灾备(Failover):主备消费者自动切换,保障高可用。当存在多个 consumer 时,将会按字典顺序排序,第一个 consumer 被初始化为唯一接受消息的消费者。当第一个 consumer 断开时,所有的消息(未被确认和后续进入的)将会被分发给队列中的下一个 consumer。
- 共享(Shared):多消费者并行消费,提升吞吐(如电商秒杀场景)。消息通过 round robin 轮询机制(也可以自定义)分发给不同的消费者,并且每个消息仅会被分发给一个消费者。当消费者断开连接,所有被发送给他,但没有被确认的消息将被重新安排,分发给其它存活的消费者。
流处理一体化
- Pulsar Functions:轻量级无服务器计算框架,支持在 Broker 端直接处理消息(如过滤、聚合)
- Pulsar IO:内置 Connector 生态,无缝对接 MySQL、Elasticsearch 等数据源
分层存储与数据生命周期
- 热存储:消息默认缓存在 Broker 内存,加速消费。
- 冷存储:老化数据自动迁移至 S3/GCS,降低存储成本
引入pulsar后,点赞流程改为:
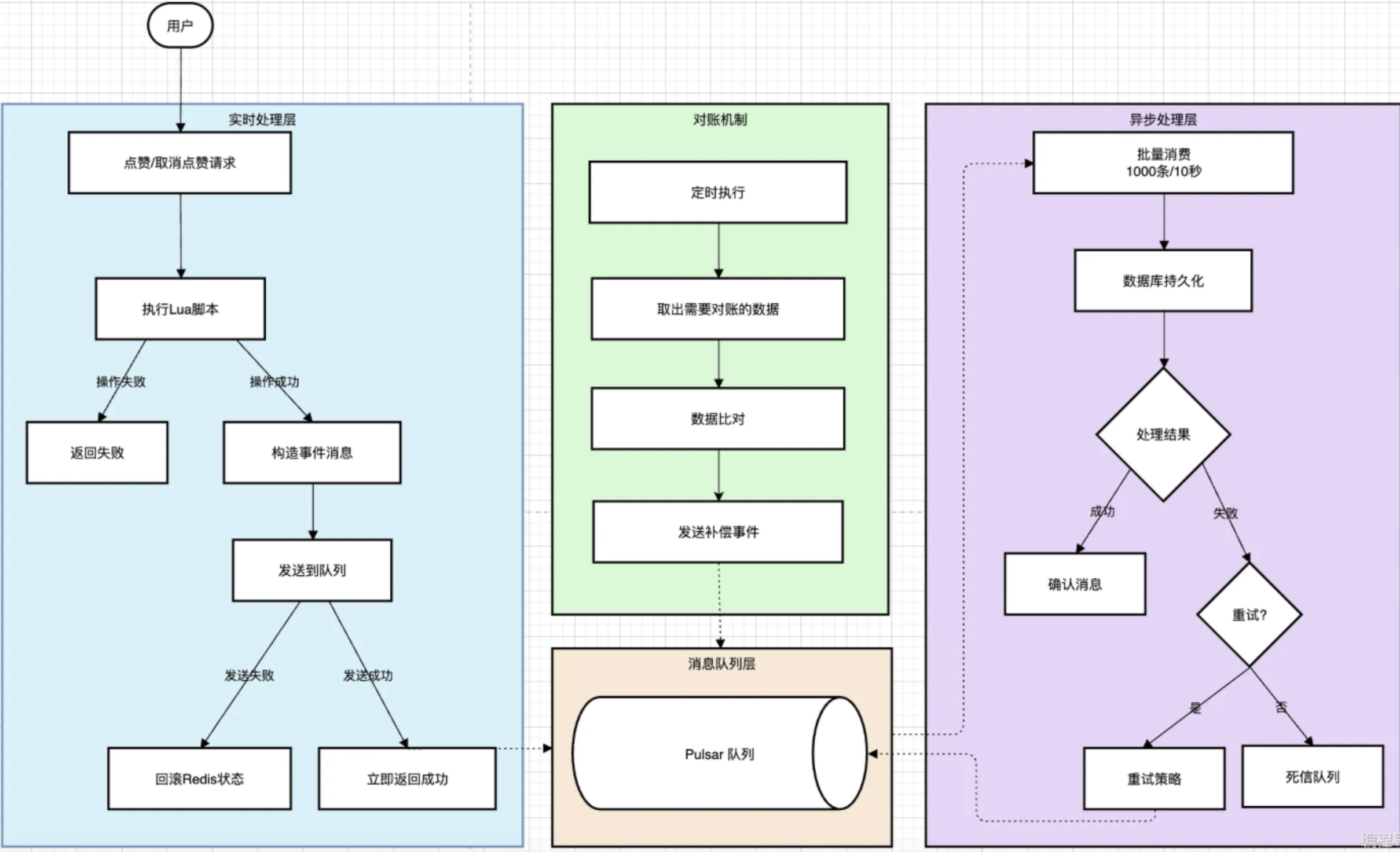
这里与第一种方法的主要区别是:不再使用定时任务持久化数据库,而是构造点赞事件发送给消息队列,消息队列异步处理队列中的点赞事件并将数据持久化到数据库。
点赞消息包括:

-
当用户发出点赞请求时,服务端首先在redis验证该用户是否已点赞。如果用户未点赞,立即更新redis中的点赞状态,然后构造点赞事件给消息队列。
-
消费者异步处理队列中的点赞事件,将数据持久化到数据库。
-
消费者批量处理模式,配置为每批次处理1000条消息或等待10s
-
消息消费失败后,进行消息重试,重试多次仍失败则进入死信队列
从单机MySQL开移到TiDB分布式教据库

TiDB是PingCAP公司开发的开源分布式关系型数据库,
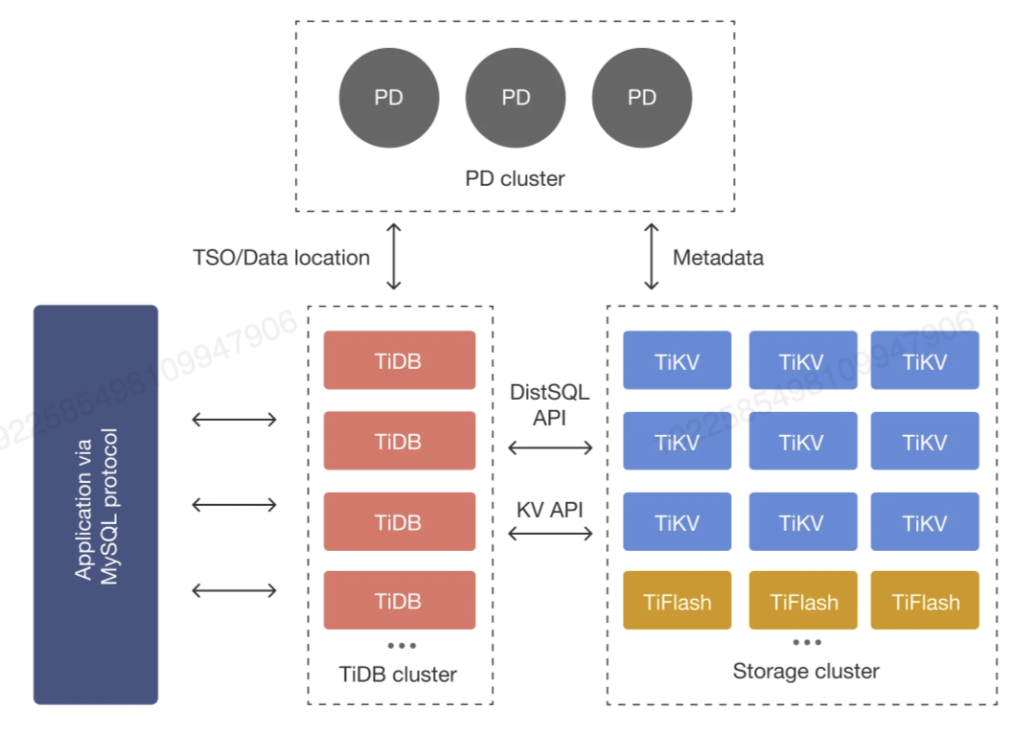
TiDB核心组件:
1)TiDB Server: SQL 层,对外暴露MySQL 协议的连接 接口,负责接受客户端的连接,执行 SQL解析和优化,最终生成分布式执行计划 。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 TiProxy、LVS、HAProxy、ProxySQL 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash) 。
2) PD (Placement Driver) Server:整个 TiDB集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务ID。 PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的TiKV 节点 ,可以说是整个集群的"大脑"。此外,PD 本身也是由至少3个节点构成,拥有高可用的能力 。建议部署奇数个 PD 节点。
3)存储节点
- TiKV Server:负责存储数据 ,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation)的隔离级别,这也是 TiDB在SQL层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL的执行计划转换为对 TiKVAPI 的实际调用。所以,数据都存储在 TiKV中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
- TiFlash:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
五大核心特性:
- 一键水平扩缩容:得益于 TiDB 存储计算分离的架构的设计,可按需对计算、存储分别进行在线扩容或者缩容,扩容或者缩容过程中对应用运维人员透明。
- 金融级高可用:数据采用多副本存储,数据副本通过 Multi-Raft 协议同步事务日志,多数派写入成功事务才能提交,确保数据强一致性且少数副本发生故障时不影响数据的可用性。可按需配置副本地理位置、副本数量等策略,满足不同容灾级别的要求。
- 实时 HTAP:提供行存储引擎 TiKV、列存储引擎 TiFlash 两款存储引擎,TiFlash 通过Multi-Raft Learner 协议实时从 TiKV 复制数据,确保行存储引擎 TiKV 和列存储引擎 TiFlash 之间的数据强一致。TiKV、TiFlash 可按需部署在不同的机器,解决 HTAP 资源隔离的问题。
- 云原生的分布式数据库:专为云而设计的分布式数据库,通过 TiDB Operator 可在公有云、私有云、混合云中实现部署工具化、自动化。
- 兼容 MySQL 协议和 MySQL生态:兼容MySQL 协议、MySQL常用的功能、MySQL 生态,应用无需或者修改少量代码即可从MySQL 迁移到 TiDB。提供丰富的数据迁移工具帮助应用便捷完成数据迁移。
本文档总体介绍可用于 TiDB 的数据迁移方案。数据迁移方案如下:
-
- 全量数据迁移。
- 数据导入:使用 TiDB Lightning 将 Aurora Snapshot,CSV 文件或 SQL dump 文件的数据全量导入到 TiDB 集群。
- 数据导出:使用 Dumpling 将 TiDB 集群的数据全量导出为 CSV 文件或 SQL dump 文件,从而更好地配合从 MySQL 数据库或 MariaDB 数据库进行数据迁移。
- TiDB DM (Data migration) 也提供了适合小规模数据量数据库(例如小于 1 TiB)的全量数据迁移功能。
-
- 快速初始化 TiDB 集群:TiDB Lightning 提供的快速导入功能可以实现快速初始化 TiDB 集群的指定表的效果。请注意,使用快速初始化 TiDB 集群的功能对 TiDB 集群的影响极大,在进行初始化的过程中,TiDB 集群不支持对外访问。
-
- 增量数据迁移:使用 TiDB DM 从 MySQL,MariaDB 或 Aurora 同步 Binlog 到 TiDB,该功能可以极大降低业务迁移过程中停机窗口时间。
-
- TiDB 集群复制:TiDB 支持备份恢复功能,该功能可以实现将 TiDB 的某个快照初始化到另一个全新的 TiDB 集群。
-
- TiDB 集群增量数据同步:TiCDC 支持同构数据库之间的灾备场景,能够在灾难发生时保证主备集群数据的最终一致性。目前该场景仅支持 TiDB 作为主备集群。
本项目目前的数据量远达不到TB级别,同时只需要一次全量同步即可。因此直接用SQL文件的方式迁移数据。
场景:在保证线上服务平稳运行的前提下,如何迁移数据?
在实际生产中,官方建议TiDB DM + TiDB Lightning,过程如下:
-
全量数据同步:使用mydumper导出mysql中的数据,通过TiDB Lightning并行导入,禁止用TiKV写入保护
-
增量数据同步:配置 DM-worker 监听 MySQL Binlog ,通过 Sharding DDL 协调器 合并分库分表 DDL(如拆分的用户表合并)
-
双写验证阶段:在应用层同时写入 MySQL 和 TiDB,通过 分布式事务 保证双写一致性
-
切换读流量:将读请求切换到TiDB
-
切换写流量:确认无误后,将写请求切换到TiDB
-
下线旧MySQL:完成迁移后,逐步下线MySQL实例
基于 Prometheus + Grafana 构建全方位监控体系
Prometheus
Prometheus 是一款开源的云原生系统监控和告警工具包,由 SoundCloud 工程师于 2012 年开发,2016 年成为 CNCF 第二个毕业项目。
Prometheus 收集并将其指标存储为 时间序列 数据,即指标信息与记录时的时间戳一起存储,还可以带有称为标签的可选键值对。
Prometheus 的主要特性包括:
• 具有多维数据模型的时间序列数据 ,通过指标名称和键值对来识别,指标由 <metric_name>{label1="value1",...} 唯一标识,例如 http_requests_total{method="POST", path="/api"}
• 使用灵活的查询语言 PromQL
• 不依赖分布式存储;单个服务器节点是自主的
• 通过 HTTP的拉取模型进行时间序列数据收集
• 通过中间网关支持推送时间序列数据
• 目标通过服务发现或静态配置来发现
• 支持多种图形和仪表盘显示模式
简单来说,指标是数值测量。时间序列这个术语指的是随时间变化的记录。用户想要测量的内容因应用程序而异。对于 web 服务器,可能是请求时间;对于数据库,可能是活动连接数或活动查询数等。
指标类型
- Counter(计数器) :单调递增计数器(如请求总数),适合速率计算
rate(http_requests_total[5m])。一种累积型指标,代表单调递增的计数值。应用场景为记录服务请求数量、完成的任务数或者发生的错误数等,不适合用于可能会减少的值,比如当前运行的进程线程数量。 - Gauge(仪表):瞬时值测量(如内存使用量),支持直接加减操作。一个可以任意上下波动的单一数值,适合用于测量类数据,如温度、当前内存使用量、并发请求的数量。
- **Histogram(直方图):**用于测量数值分布情况的指标类型,适用于测量请求持续时间、响应大小等。工作原理是把观测值放进预先定义的多个区间(桶)中计数,同时计算所有观测值的总和与计数。当用户请求这些数据时,Prometheus可以使用histogram_quantile()函数计算出分位数,比如找出95%的请求响应时间在什么范围内。Histogram 的特点是在服务器端计算分位数,支持跨多个实例的聚合计算,但精确度相对较低。
- **Summary(摘要):**与Histogram类似,都可以用于观察数值的分布情况,但是原理不同,Summary会直接在客户端计算并存储分位数。Summary不支持跨多个实例的分位数聚合,但是提供的计算结果更精确。
在实际应用场景中,Histogram多用于服务监控场景,Summary适用于需要精确分位数的场景。
架构
• Prometheus 主服务器 ,用于抓取和存储时间序列数据。 通过 PromQL 定义告警阈值规则(如 100 - (avg(node_cpu_seconds_total{mode="idle"}) * 100) > 80),触发后推送至 Alertmanage
• 用于检测应用程序代码的客户端库
• 支持短期作业的推送网关(Pushgateway) ,为短期作业(如批处理脚本)提供 Push 通道,数据暂存后由 Prometheus Server 拉取
• 用于 HAProxy、StatsD、Graphite 等服务的特殊用途导出器
• 处理告警的告警管理器(Alertmanager) ,支持分组、去重、静默和路由策略,集成邮件、Slack、Webhook 等通知渠道。动态抑制:例如当集群级故障触发时,自动屏蔽相关实例的重复告警
· Exporters 指标转换器:将第三方系统数据转为 Prometheus 格式,覆盖硬件(Node Exporter)、数据库(MySQL Exporter)、中间件(Nginx Exporter)等 200+ 生态
• 各种支持工具
为了易于构建和部署为静态二进制文件,大多数 Prometheus 组件都是用Go语言编写的。
Prometheus 从已检测的jobs 中抓取指标,可以直接抓取,也可以通过中间推送网关为短期jobs 抓
取。它将所有抓取的样本本地存储,并在这些数据上执行一些运算,这样就能从现有数据中聚合并记录新的时间序列数据或生成告警,之后可以使用Grafana 或其他 API 消费者可视化收集的数据。
适用场景
Prometheus 适用于记录任何纯数值时间序列,比如服务器中心的监控、高度动态的面向服务的架构、
微服务的监控 。Prometheus 注重可靠性,在系统发生故障时,能够快速判断出问题。每个Prometheus 服务器都是独立的,不依赖网络存储或其他远程服务,所以即使底层设施的其他部分出现问题,Prometheus 仍然可用。
不适用场景
Prometheus 重视可靠性,即使在故障条件下,也始终可以查看系统的可用统计信息。如果需要100%的准确性,例如按请求计费,Prometheus就不太合适,因为它收集的数据可能不够详细和完整。在这种情况下,最好使用其他系统来收集和分析计费数据,将 Prometheus 用于其余的监控
PromQL 基础语法
PromQL(Prometheus Query Language)是 Prometheus 提供的强大查询语言,用于查询和分析存储在 Prometheus 时序数据库中的监控数据。支持灵活的查询和计算,能够提取、过滤、聚合和转换时间序列数据,经常结合 Grafana 进行可视化展示、告警设置和数据分析。为了方便后续使用,我们需要先对 PromQL 有一些基础的了解。
特点
1. 支持多维数据查询:
• 通过 标签(Label)进行筛选,如{job="node",instance="localhost:9100"}。
2. 支持多种数据类型:
• 瞬时向量 (Instant Vector):某一时间点的多个时间序列数据(如 cpu_usage{instance="
localhost:9100"})。
。区间向量(Range Vector):一段时间内的数据集合(如 cpu_usage[5m])。
。标量(Scalar):单个浮点数值(如 5*60)。
• 字符串(String):很少使用,目前主要用于 labe1_replace()等函数的匹配操作。
- 丰富的运算支持:
◎ 算术运算(+-*/%^)
◎ 比较运算(==!=><>=<=)
• 逻辑运算(and or unless)
。 聚合操作(如 sum(),avg(),max(),min(),count(),rate()等)
- 内置监控指标查询:
。例如 up 指标可用于检查 Prometheus 目标 (target)的运行状态:uptjob="node"}
。 rate()函数用于计算指标的变化速率,如计算过去 5分钟内 HTTP 请求的速率:rate(httP_requests_total[5m])
- 支持高级函数:
。时间序列处理(rate(),irate(),increase())
。 标签操作(label_replace(),label_join())
。 直方图计算(histogram_quantile()
基本的查询指标:
python
metric_name{label1="value1", label2="value2"}其中:
• metric_name 是指标名称
• 花括号内是标签过滤条件,支持多种匹配操作符:
• =:精确匹配
• !=:不等于
• =~:正则表达式匹配
• !~:正则表达式不匹配
python
1. 查询当前CPU使用率
cpu_usage{instance="localhost:9100"}
2. 计算HTTP请求速率(过去五分钟)
rate(http_requests_total[5m])
3. 计算所有实例CPU使用率的平均数
avg(rate(cpu_usage[5m]))
4. 统计所有目标的存活情况
count(up == 1)
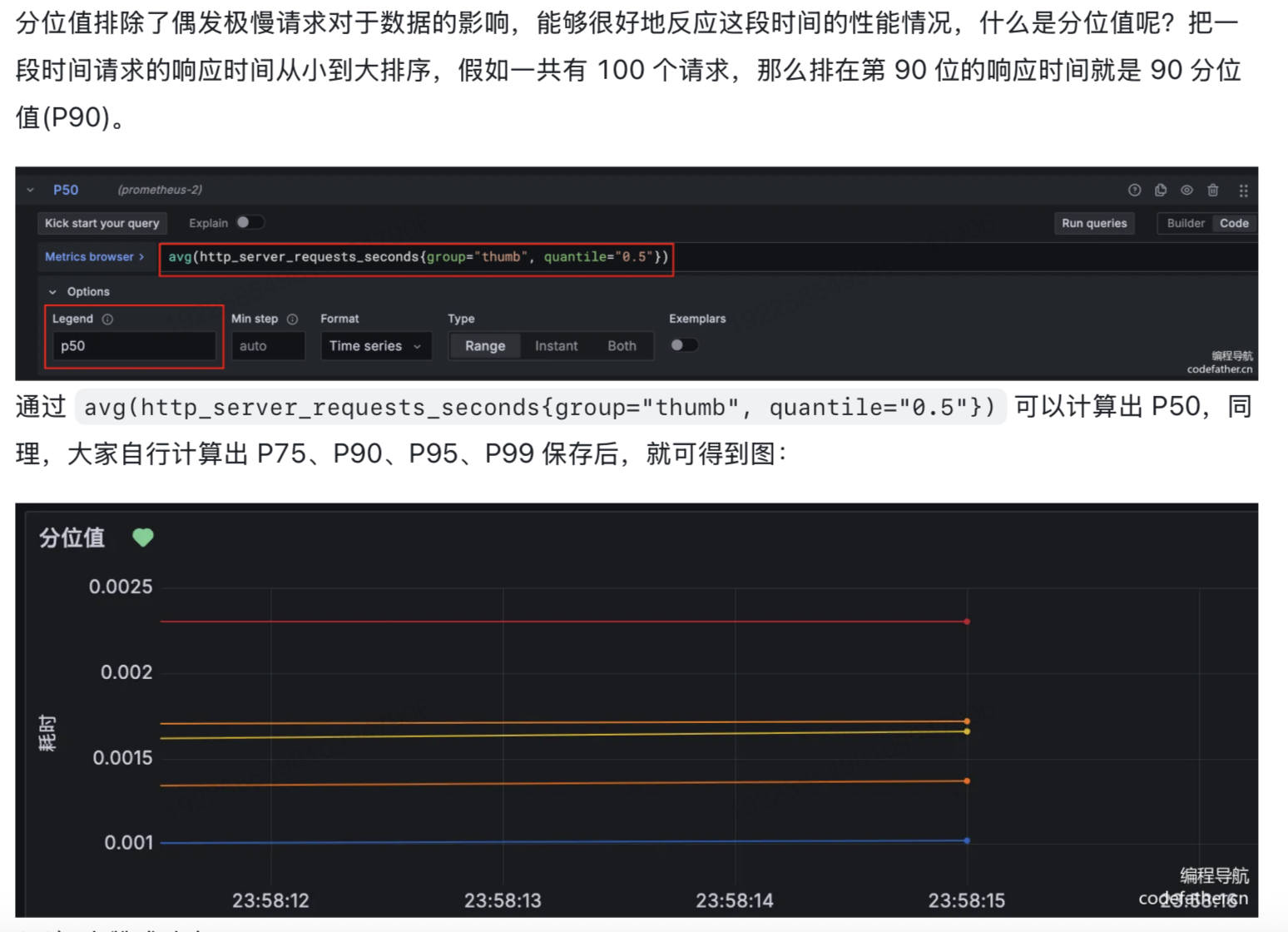
5. 计算95%线(P95)请求延迟
histogram_quantile(0.95, rate(http_requests_duration_seconds_bucket[5m]))
histogram_quantile(0.95, ...)基于直方图数据计算95%分位数,即找出一个时间值,使得95%的请求持续时间≤该值,5%的请求超过该值
rate(http_request_duration_seconds_bucket[5m])计算每个桶在过去5分钟内的每秒增长率,由于直方图的桶是累积计数器(Counter),rate()会将原始计数转换为每秒增量,反映时间窗口内各桶的实际增长速率Grafana
Grafana 是一款开源的跨平台数据可视化和监控工具,支持通过实时、交互式仪表板监控和分析各类数据,能够对存储在任何位置的指标进行查询、可视化和告警。
数据可视化
- 多源支持:支持 Prometheus、InfluxDB、Elasticsearch、MySQL 等 50+ 数据源,通过统一界面展示异构数据。
- 图表类型:提供折线图、热力图、仪表盘等多种可视化形式,支持自定义样式和动态交互。
- 动态仪表盘:用户可通过拖放组件(如 Panel、Row)灵活构建仪表盘,实时展示多维度指标。
监控告警
- 阈值告警 :基于 PromQL 或 SQL 定义告警规则,触发后通过邮件、Slack、Webhook 等渠道通知。
- 智能分组:Alertmanager 支持告警去重和路由策略,避免信息过载。
本项目使用
整体架构包括四个关键部分:
• 应用侧的指标埋点与暴露
• Prometheus 的指标采集与存储
• Grafana 的指标可视化
• Alertmanager 的告警管理
在应用层,利用 Spring Boot Actuator 和 Micrometer 框架进行指标埋点,过"/actuator/prometheu
s"端点(默认端点)暴露监控数据。Prometheus 服务器定期从各个应用实例(后端服务、Redis、TiDB)抓取指标数据并进行存储。Grafana 连接 Prometheus 数据源,提供丰富的可视化面板。当监控指标触发预设的告警规则时,Alertmanager 将通过邮件、钉钉或企业微信等渠道通知到我们。
Prometheus 会通过 HTTP 协议定期抓取应用暴露的指标。配置 Prometheus 以适当的频率(比如15
秒)从各个服务实例拉取数据,同时设置合理的数据保留周期。
可视化设计:用 Grafana 构建多层次的监控面板,覆盖从业务到基础设施的各个方面:
1.业务概览面板:展示点赞系统的核心业务指标,如点赞成功率等
-
服务性能面板:监控接口响应时间分布等
-
存储监控面板:监控 TiDB、Redis 等存储系统的性能指标
-
消息队列面板:展示 Pulsar 的消息处理状况、积压情况等
面板需要注重信息的 层次感和可读性,避免过多冗余信息干扰判断。对于核心指标,可以添加同环比分析功能,快速识别异常变化。
告警策略:一个合格的可观测性系统必须要有相应的告警措施,围绕"及时、准确、有效"的原则设计的告警策略。
基于 AlertManager,可以实现多渠道、分级的告警机制:
-
告警分级:按照 P0(严重)、P1(重要)、P2(一般)三级划分告警优先级
-
告警渠道:工作群(钉钉、企微)、邮件
-
告警抑制:避免告警风暴,合理设置告警间隔和聚合规则
关键监控指标的告警阈值可以根据历史数据和业务重要性设定,例如:
• PO级告警:服务接口成功率低于 99.5%、核心接口 P99 延迟超过 1S
• P1 级告警:服务接口成功率低于 99.9%、核心接口 P95 延迟超过 500ms
• P2级告警:缓存命中率低于 80%、消息积压量持续增长等
在本项目中,我们会重点监控以下关键指标:
1 业务指标:
• QPS->反映系统负载情况
• 点赞成功率->直接关系用户体验
2) 性能指标:
• P95/P99 响应时间->反映系统性能稳定性
• Redis 缓存命中率->影响系统整体性能
• Pulsar 消息处理延迟->反映异步处理效率
3)资源指标:
• JVM 内存使用率
• 垃圾回收频率和持续时间->影响服务稳定性
• 虚拟线程
4)依赖服务指标:
• Redis 连接数和请求延迟
• TiDB 查询延迟和错误率
• Pulsar 消息积压量
在ThumbController中集成计数器指标:
java
private final Counter successCounter;
private final Counter failureCounter;
public ThumbController(MeterRegistry registry) {
this.successCounter = Counter.builder("thumb.success.count")
.description("Total successful thumb")
.register(registry);
this.failureCounter = Counter.builder("thumb.failure.count")
.description("Total failed thumb")
.register(registry);
}统计成功/失败数,用于计算点赞成功率:
java
@PostMapping("/do")
public BaseResponse<Boolean> doThumb(@RequestBody ThumbAddRequest thumbAddRequest,
HttpServletRequest request) {
try {
boolean result = thumbService.doThumb(thumbAddRequest, request);
if (result) {
// 记录成功计数
successCounter.increment();
return ResultUtils.success(true);
} else {
// 记录失败计数
failureCounter.increment();
return ResultUtils.error(ErrorCode.SYSTEM_ERROR);
}
} catch (Exception e) {
// 记录失败计数
failureCounter.increment();
return ResultUtils.error(e.getMessage());
}
}为了监控 Redis 的性能和缓存命中率,我们需要添加 Redis Exporter。使用 Docker运行 Redis Exporter:
bash
docker run --name redis-exporter \
-p 9121:9121 \
oliver006/redis_exporter \
--redis.addr=redis://host.docker.internal:6379 \
--redis.password=xxxGrafana配置各项指标面板
- QPS:输入查询语句 sum(rate(http_server_requests_seconds_count1m))
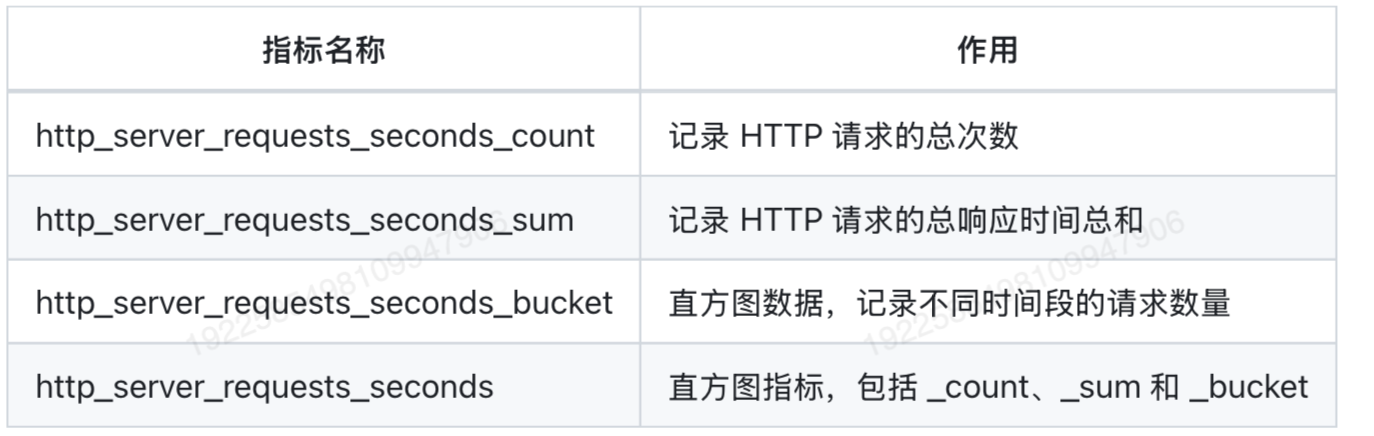
http_server_requests_seconds_count 是 Spring Boot Actuator Micrometer 生成的 HTTP 请求总数相关的指标,经常用于分析请求频率。如果我们在 Prometheus 的控制台(localhost:9090)查询这个指标,会得到类似数据:

• exception="None":是否有异常
• outcome="SUCCESS":请求结果
· method="GET":表示 HTTP 方法
• status="200":HTTP 状态码
• uri="/actuator/prometheus":请求路径
• 299:表示该接口累计被请求299次

- 分位数
- 点赞成功率
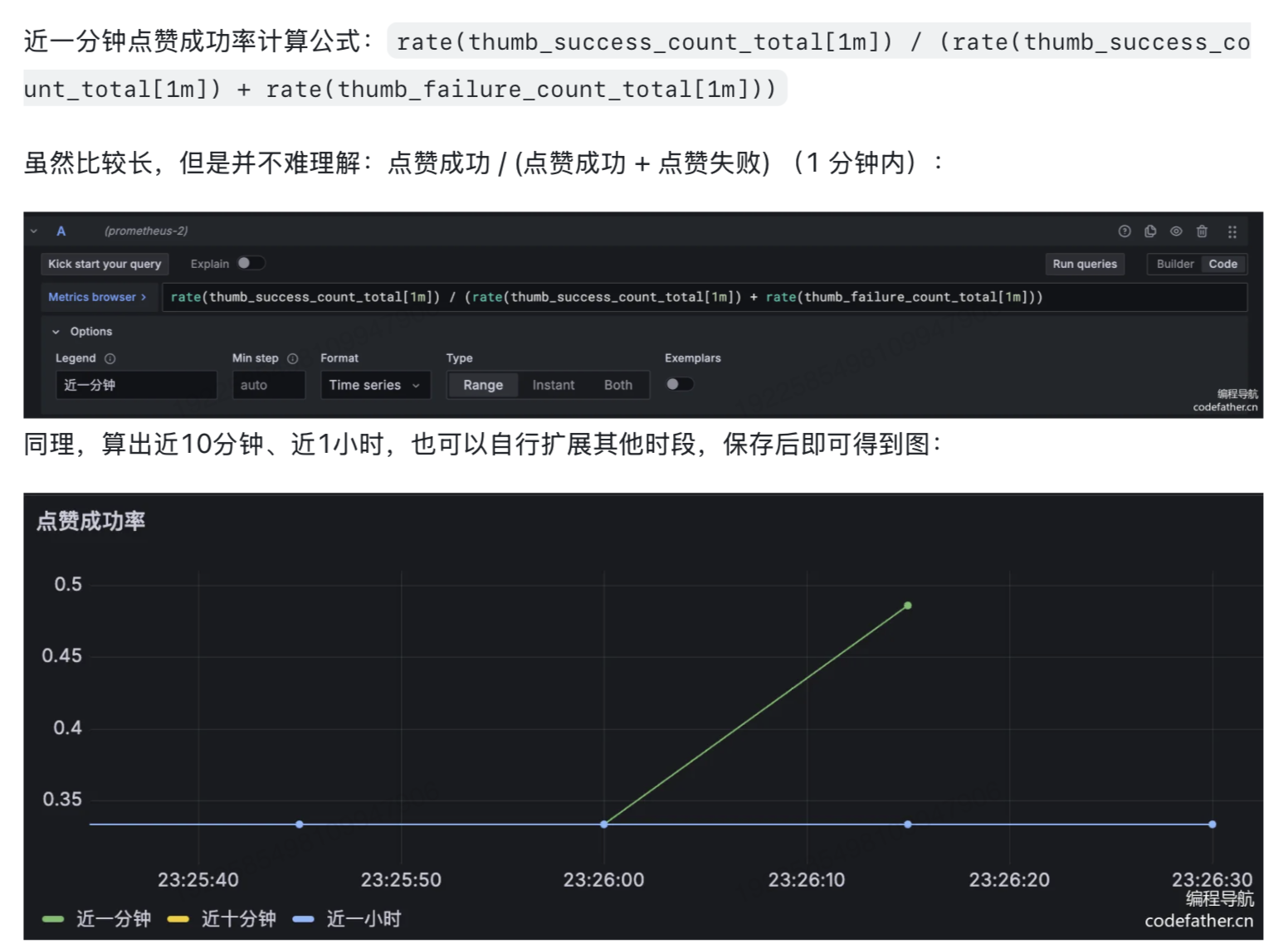
- 缓存命中率
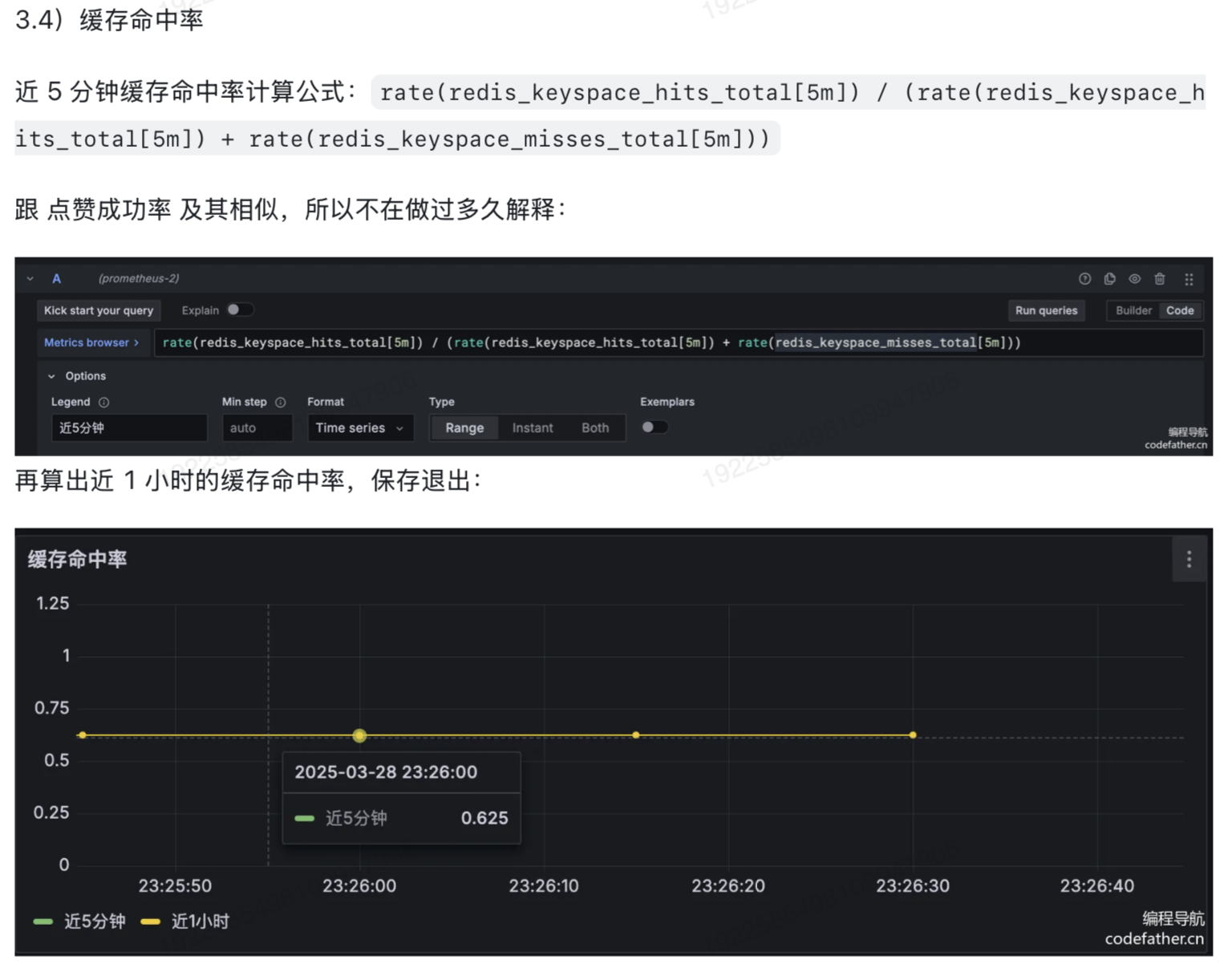
- 请求失败数

配置Alertmanager
使用Apache JMeter压力测试

压测配置
1)创建线程组
线程组(Thread Group):定义虚拟用户数(并发量)、Ramp-Up 时间(加压速率)和循环次数,模拟真实用户行为。
先创建一个线程组,主要是填写线程数、启动时间、循环次数3个值。
- 线程数 * 循环次数 = 要测试的请求总数
- 启动时间的作用是控制线程的启动速率,从而控制请求速率。例如,10秒启动100个线程,那么每秒启动10个线程,相当于最开始每秒10个请求。
注意,每秒启动的线程数要大于接口的QPS(每秒请求数),才能测试到极限,不能因为请求速度不够影响测试结果。
这里统一性能测试标准:
- 线程数:5010个 / 组
- 启动时间(Ramp-Up):5秒
- 循环次数:10组
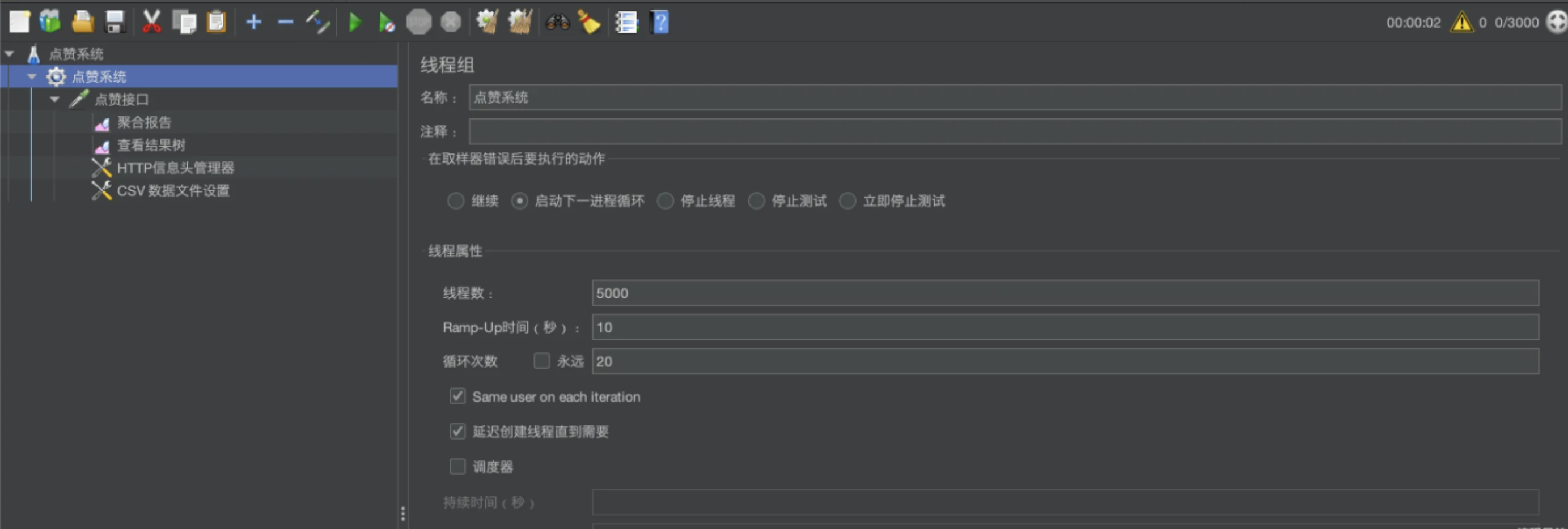

也就是说,我们模拟了5010个用户,每个用户在5s内请求10次, 相当于每秒5000 * (10 / 5) = 1w个请求,一共5w个请求。

2)创建HTTP信息头管理
可以自主添加请求头,比如设置请求头Content-Type为application/json,和我们要测试的接口保持一致。
还可以添加Cookie,存储登录态:
3)新建HTTP请求
填写要测试的接口路径、请求类型、请求参数等。
请求参数和前端进入主页时发送的请求一致
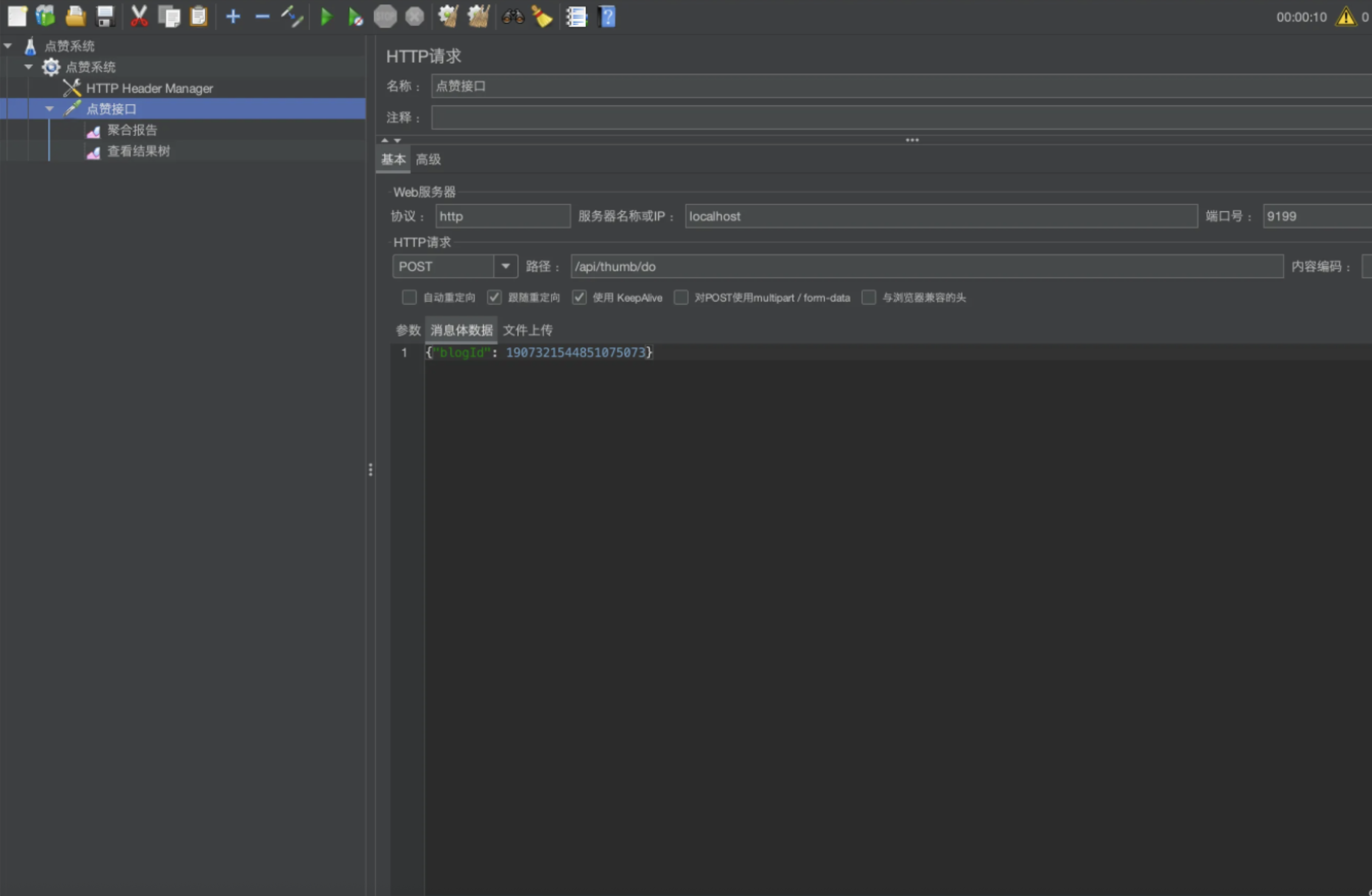
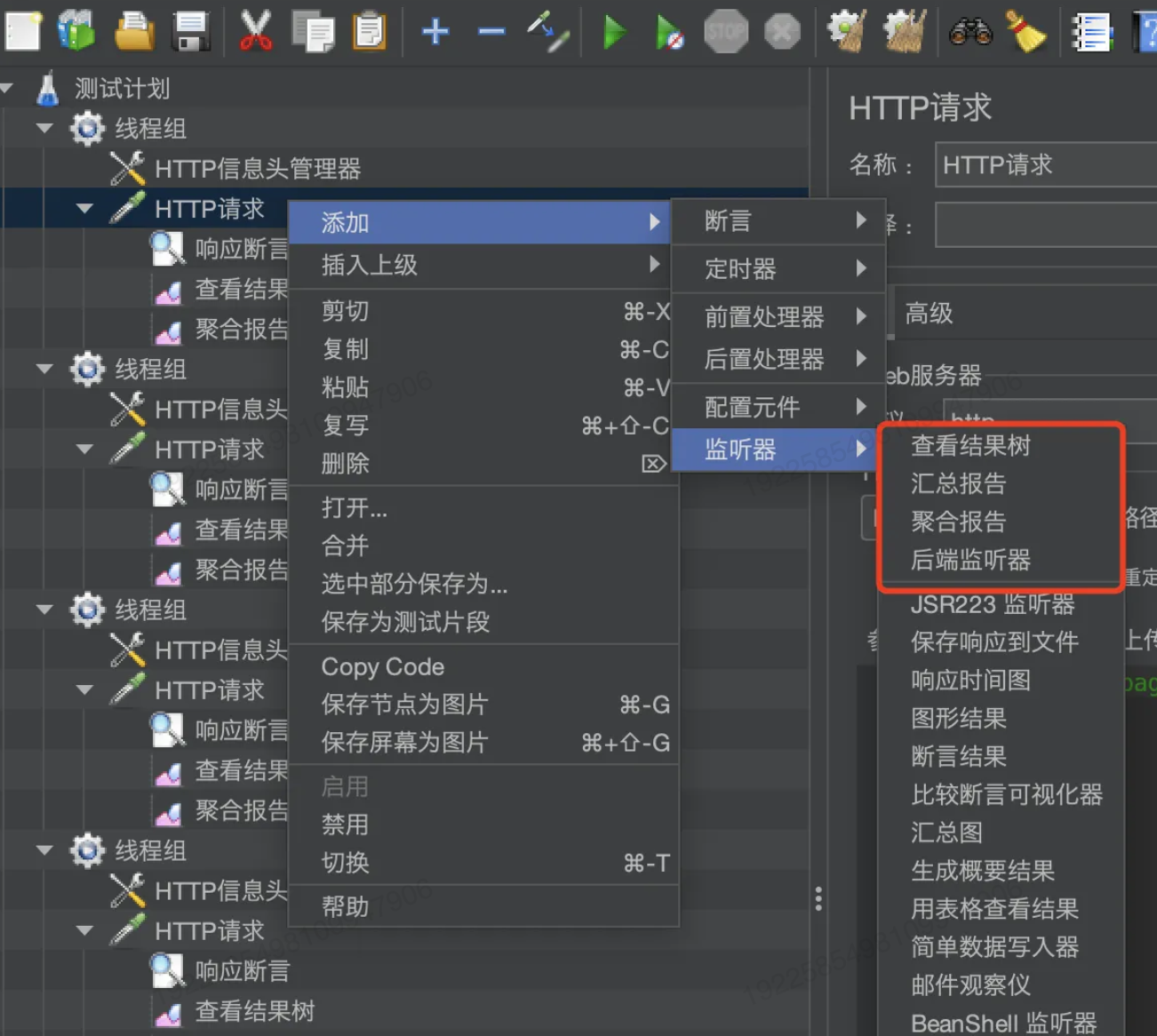
4)配置压测结果展示
添加查看结果树、聚合报告:
获取多用户的登录态
为了测试更真实的场景,要模拟多用户并发请求点赞接口, 那请求头中的Cookie就不能写死,而是要通过某种方式动态读取,这里我们采用读取CSV文件的形式来实现。
先通过脚本模拟登录,然后记录相应头中的Session到CSV文件中,最后使用JMeter读取CSV文件中的Session。
1)通过脚本获取Session
java
// Spring Boot测试注解(加载完整上下文)
@SpringBootTest
// 自动配置MockMvc(模拟HTTP请求)
@AutoConfigureMockMvc
class ThumbBackendApplicationTests {
@Resource
private ThumbService thumbService;
@Resource
private UserService userService;
@Resource
private BlogService blogService;
@Test
void contextLoads() {
// 打印各服务的数据列表(用于验证服务是否正常注入)
System.out.println(thumbService.list());
System.out.println(userService.list());
System.out.println(blogService.list());
}
// 批量创建用户测试
@Test
void addUser() {
for (int i = 0; i < 50000; i++) { // 创建5万个测试用户
User user = new User();
// 生成6位随机用户名(Hutool工具)
user.setUsername(RandomUtil.randomString(6));
userService.save(user);
}
}
// 注入MockMvc用于模拟HTTP请求
@Resource
private MockMvc mockMvc;
// 登录测试并导出Session到CSV
@Test
void testLoginAndExportSessionToCsv() throws Exception {
List<User> list = userService.list();
// 使用try-with-resources自动关闭文件流
try (PrintWriter writer = new PrintWriter(new FileWriter("session_output.csv", true))) {
// 写入CSV表头(仅在文件首次创建时写入)
writer.println("userId,sessionId,timestamp");
for (User user : list) {
long testUserId = user.getId();
// 模拟发送GET登录请求(实际项目建议用POST)
MvcResult result = mockMvc.perform(get("/user/login")
// 添加请求参数
.param("userId", String.valueOf(testUserId))
.contentType(MediaType.APPLICATION_JSON))
.andReturn(); // 获取完整响应
// 验证响应头包含Set-Cookie
List<String> setCookieHeaders = result.getResponse().getHeaders("Set-Cookie");
assertThat(setCookieHeaders).isNotEmpty();
// 提取Spring Session ID(格式示例:SESSION=abc123; Path=/; ...)
String sessionId = setCookieHeaders.stream()
.filter(cookie -> cookie.startsWith("SESSION")) // 过滤目标Cookie
.map(cookie -> cookie.split(";")[0]) // 取第一个分段(SESSION=xxx)
.findFirst()
.orElseThrow(() -> new RuntimeException("No SESSION found in response"));
// 解析Session值(SESSION=后的部分)
String sessionValue = sessionId.split("=")[1];
// 写入CSV文件(格式:用户ID,Session值,当前时间)
writer.printf("%d,%s,%s%n", testUserId, sessionValue, LocalDateTime.now());
System.out.println("✅ 写入 CSV:" + testUserId + " -> " + sessionValue);
}
}
}
}执行成功后,在项目根目录会生成一个CSV文件:

2)将CSV文件导入到 JMeter中

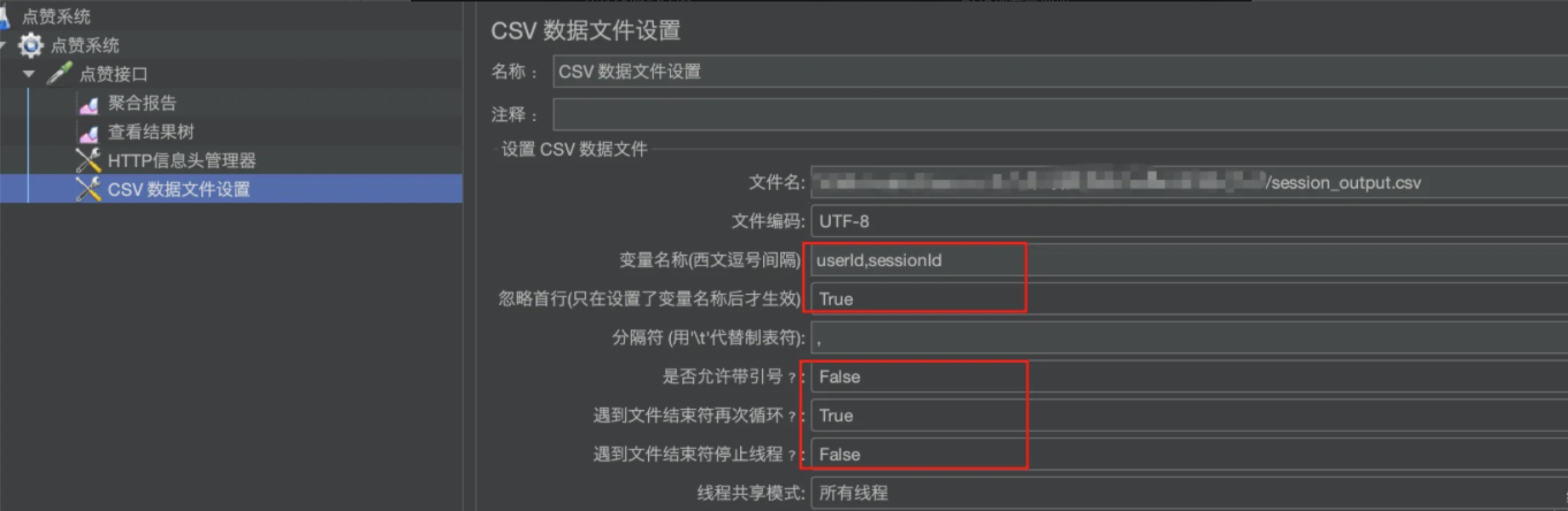
注意:
- 变量名称中,第二个变量名称为sessionId对应的是Session,与我们的CSV文件对应
- "遇到文件结束符再次循环"一定为True,"遇到文件结束符停止线程"一定为False, 否则会影响模拟请求的次数。
3)修改HTTP信息头管理器,动态从CSV文件中读取

使用${}方式读取变量,注意要与上一步中定义的变量名称一致。
测试基础实现

这种情况下,接口响应的平均值为12.6s左右,最慢的是在26.1s左右才会返回响应,吞吐量TPS(每秒事务处理的数量,一个事务表示客户端向服务器发送请求,然后响应)为358.8/s,最重要的是出现了异常!
测试 引入Redis校验是否已点赞 的实现

发现性能几乎没变化,依然有异常,响应时间也依然较长。因为这里主要针对的是对读操作的优化,而目前的性能瓶颈不是在读上,而是两次数据库的写操作,特别是博客点赞量的更新还有热点行问题。
测试 使用Redis + 定时任务更新数据库 的实现

测试使用Pulsar消息队列


后续优化

使用空接口测试最大性能
java
@RestController
@RequestMapping("index")
public class IndexController {
@GetMapping
public String index() {
return "hello world";
}
}

场景与面试问题
两级缓存之间的"一致性"如何保证?
Caffeine 缓存中存储的数据
Caffeine 缓存作为本地内存缓存,用于存储热键数据,其特点如下:
存储容量:最多 1000 条记录,有效期 5 分钟 CacheManager.java:49-52
数据格式:采用"hashKey:key"格式的复合键,用于存储点赞关系数据 CacheManager.java:56-58
内容:被标识为热键的频繁访问点赞记录(用户与博客点赞关系)
Redis 缓存中存储的数据
Redis 作为分布式缓存层,主要包含两种数据类型:
用户点赞键:格式为"thumb:{userId}",用于存储每个用户点赞过的博客 ThumbConstant.java:11
临时点赞键:格式为"thumb:temp:{timeSlice}",用于存储用于批处理的临时点赞操作 ThumbConstant.java:18
临时键使用向下取整到最接近的 10 秒间隔计算的时间片
- 多级缓存策略
系统实现了分层缓存查找:首先检查本地 Caffeine 缓存,如果本地缓存未命中,则查找 Redis CacheManager.java:64-77
- 热键检测和选择性缓存
使用 HeavyKeeper 算法检测热键,并仅将频繁访问的数据缓存在本地 CacheManager.java:32-44 。仅当数据被识别为热键时,才会将其提升到本地缓存 CacheManager.java:82-85
java
// 4. 如果是热 Key 且不在本地缓存,则缓存数据
if (addResult.isHotKey()) {
localCache.put(compositeKey, redisValue);
}- 条件缓存更新
系统使用 putIfPresent 方法,仅在键已存在时才更新本地缓存,从而防止缓存污染,同时保持热键的一致性 CacheManager.java:90-97
- 更新的直写模式
当 Thumb 操作发生时,系统会同时更新 Redis 数据,并使用直写模式有条件地更新本地缓存 ThumbServiceImpl.java:68-74
- 定期缓存清理
系统会运行计划清理任务以保持缓存的新鲜度,包括每 20 秒淡化一次热键检测器数据 CacheManager.java:100-103
- 数据库同步
Redis 临时数据会通过计划作业定期同步到数据库,确保缓存和持久存储之间的最终一致性 SyncThumb2DBJob.java:40-48
Redis缓存与数据库之间的数据一致性问题如何解决?
最终一致性。
- 基于时间片的批量同步(单redis无消息队列)
本项目采用时间片方法,将 Redis 操作批量处理并定期同步到数据库。系统使用基于时间的键将临时的点赞数据存储在 Redis 中,并进行批量处理(ThumbServiceRedisImpl.java:45-48)。
每 10 秒运行一次定时作业,将这些临时数据从 Redis 同步到数据库(SyncThumb2DBJob.java:40-48)。同步过程同时处理"点赞"和"取消点赞"操作,在更新博客点赞计数的同时执行批量插入和删除(SyncThumb2DBJob.java:94-103)
- 基于消息队列的异步更新
该项目还提供了一种使用 Apache Pulsar 消息队列进行异步处理的替代实现。在这种方法中,Redis 会立即更新,而数据库更新则通过消息事件 ThumbServiceMQImpl.java:48-68 异步处理。
Pulsar 消费者会批量处理这些事件,并通过为每个用户-博客对保留最新事件 ThumbConsumer.java:76-91 来处理重复和冲突的操作。这确保了高效的批处理,同时保持了数据完整性。
原子操作和数据完整性
系统使用 Lua 脚本确保 Redis 操作的原子性,防止并发 like/unlike 操作期间出现竞争条件 (RedisLuaScriptConstant.java:21-44)。这些脚本会以原子方式检查现有状态、更新计数器并维护用户 like 状态 (RedisLuaScriptConstant.java:39-41)。
- 协调与恢复机制
为了确保即使在故障情况下也能保持最终一致性,该项目实施了多种恢复机制:
每日协调:每日运行计划作业,比较 Redis 和数据库数据,识别不一致之处并生成补偿事件(pulsar版)
补偿同步:通过处理 Redis 中剩余的临时点赞数据来处理丢失的同步(单redis版)
一致性模型是最终一致性,而非强一致性。这种设计选择适用于点赞系统,因为:
性能优先:Redis 作为读取操作的直接数据源,提供快速响应时间
可接受的不一致窗口:对于点赞等社交功能,数据库更新的暂时延迟是可以接受的
高可用性:即使数据库同步暂时失败,系统也能继续运行
可扩展性:异步处理使系统能够处理高吞吐量场景
项目中的消息队列Pulsar
消息不丢失
- 当消息在最大重试次数后仍失败时,它们将被发送到死信队列以防止消息丢失。DLQ 有一个专用的消费者,用于记录失败的消息并通知管理员
- 生产者发送消息后,需等待 Broker 的写入确认(ACK)。若未收到确认,生产者自动重试
- 消息确认(ACK) :消费者成功处理消息后需显式发送 ACK,Broker 收到后才会标记消息可清理。未确认的消息会被保留并重投。
- 否定应答(NACK) :消费者处理失败时可发送 NACK,触发消息立即重投。
- ACK 超时机制:若消费者未在指定时间(如 30 秒)内确认,消息自动重新加入投递队列
- 生产者发送消息时,Broker 将消息写入 BookKeeper 集群,每条消息需持久化到多个 Bookie 节点(默认 2 副本)。仅当多数副本(Quorum)成功写入磁盘后,Broker 才向生产者返回确认。例如配置
ackQuorum=2时,需至少 2 个 Bookie 确认写入成功。即使节点故障也能通过剩余副本恢复数据。
处理重复消息
ThumbConsumer.processBatch 中,消费者会根据 (userId, blogId) 对 对所有传入事件进行分组,并且只处理每个唯一对 中的最新事件。这确保即使同一用户-博客组合收到多个"喜欢/不喜欢"事件,也只处理最新的事件。
- 每个生产者(Producer)为消息分配严格递增的
sequenceId。Broker 为每个 Producer 维护一个哈希表,记录当前接收到的最大sequenceId;若新消息的sequenceId≤ Broker 记录的sequenceId,视为重复消息,直接丢弃 并返回确认。若sequenceId更大,则持久化消息并更新哈希表。 - 当消息需写入多个分区(如分库分表场景),基础去重无法保证原子性。
- 实现 :
- 事务协调器(TC):由 Broker 担任,管理全局事务状态。
- 事务生产者 :
生产者开启事务后,发送到不同分区的消息先预提交到事务缓冲区,待全局事务提交时才真正可见。 - 原子提交 :
若事务回滚,所有预提交消息标记为Aborted,消费者不可见;提交后消息才持久化并释放
消息有序性
- 生产者发送消息时指定业务 Key(如订单 ID),Pulsar 根据 Key 的哈希值将消息固定路由到同一分区 (Partition)。同一分区内消息严格按追加顺序存储,天然保证分区内有序。
- 每个分区对应 BookKeeper 中的一个 Ledger(分段日志) ,消息以追加写入(Append-Only)方式存储,物理存储顺序即消息顺序。
该项目并不依赖 Pulsar 内置的 thumb 事件消息排序保证。相反,它实现了应用程序级排序逻辑来处理潜在的乱序消息传递。
消息生产者配置
Thumb 事件无需任何排序键配置即可发送到 Pulsar。 生产者使用简单的异步发送,无需指定分区键或排序键。
消息消费者配置
消费者配置为共享订阅类型,允许多个消费者同时处理消息,但不保证消息的排序。
消息排序的关键在于消费者的批处理逻辑:
- 消息分组:消息按 (userId, blogId) 对分组,以确保对同一用户-博客组合的操作一起处理。
- 基于时间的排序:在每个组中,事件按事件时间排序,以建立正确的时间顺序。
- 重复数据删除逻辑:系统仅处理包含奇数个事件的组,从而有效地消除点赞/取消点赞的操作对。
- 最新事件处理:只有每个组中的最新事件决定最终操作(增加或减少)。
消息堆积
该项目实现了批处理,以高效处理消息累积。消费者配置为单批最多处理 1000 条消息,超时时间为 10 秒(ThumbConsumerConfig.java:23-30)。这种方法有助于更高效地处理累积消息,而无需逐条处理。
消费者使用共享订阅类型,允许多个消费者实例分担工作负载,有助于在水平扩展时更快地处理积压消息
前端


本项目借助cursor使用ai来帮助我们编写前端代码。
cursor的几种交互模式:
- ask:
- 这是一个"只读"模式,主要用于提问和探索代码库,AI被动响应问题。
- 理解当前文件或选中代码,不会对代码进行修改。
- 适合询问特定代码段的问题、获取复杂函数的解释、查找代码模式和示例等。
- agent:
- AI主动协助,全程参与项目开发。
- 理解整体项目结构和依赖关系,生成项目骨架。
- 适合从零搭建新功能模块、重构代码库。
- manual:
- 用户完全控制代码编写,AI仅作为参考。
- 不主动理解上下文。
- 适合熟悉的技术栈、简单任务、代码审查等。
后端所有代码实现
com.blue.thumb
.common(项目的公共模块,用于存放通用组件)
BaseResponse
通用返回类:
1. Lombok 注解 :@Data 自动生成 getter/setter、equals、hashCode 和 toString 方法,减少样板代码。
- 字段
- 状态码 :
code是 HTTP 状态码的扩展,通常与业务错误码结合使用(参考ErrorCode参数构造器)。 - 数据主体 :
data通过泛型T动态承载响应内容,例如 API 返回的 JSON 数据体。 - 消息 :
message用于补充说明操作结果(如错误详情),增强接口可读性。
-
初始化所有字段,适合需要完整信息的场景(如自定义业务状态码)
-
成功响应无需额外消息时使用(如
code=200且data有效) -
错误 :通过
ErrorCode枚举(enum)统一管理错误码和消息,提升代码可维护性;data=null表示操作失败时无有效数据返回
java
public BaseResponse(int code, T data) {
this(code, data, "");
}
public BaseResponse(ErrorCode errorCode) {
this(errorCode.getCode(), null, errorCode.getMessage());
}ErrorCode
错误码:
- 分段结构 :采用5位数字编码(如
40100),通常前3位关联 HTTP 状态码类别,后2位表示具体错误类型 - 语义关联 :
401xx表示认证/授权问题,404xx表示资源问题,500xx表示服务端错误
java
SUCCESS(0, "ok"),
PARAMS_ERROR(40000, "请求参数错误"),
NOT_LOGIN_ERROR(40100, "未登录"),
NO_AUTH_ERROR(40101, "无权限"),
NOT_FOUND_ERROR(40400, "请求数据不存在"),
FORBIDDEN_ERROR(40300, "禁止访问"),
OPERATION_ERROR(50001, "操作失败"),private final int code; // 错误码(不可变) private final String message; // 错误描述(不可变)
final修饰确保枚举实例的不可变性,线程安全code用于程序逻辑判断,message用于前端展示或日志记录
ResultUtils
作为全局响应构建工具,集中管理成功/失败响应的创建逻辑,避免代码重复。
成功:
java
public static <T> BaseResponse<T> success(T data) {
return new BaseResponse<>(0, data, "ok");
}
User user = userService.getById(1);
return ResultUtils.success(user);- 泛型设计 :
<T>支持动态返回数据类型(如String、List<User>)。 - 参数解析 :
code=0:与ErrorCode.SUCCESS的状态码一致,表示操作成功。data:业务数据主体(如查询结果)。message="ok":固定成功提示,与ErrorCode.SUCCESS的默认消息匹配。
失败:
java
public static BaseResponse<?> error(ErrorCode errorCode) {
return new BaseResponse<>(errorCode);
}errorCode:预定义的错误码枚举(如ErrorCode.PARAMS_ERROR)。- 底层调用
BaseResponse的ErrorCode构造函数,自动填充code和默认message。
.config(存放 Spring Boot 的配置类)
CorsConfig(全局跨域配置)
-
@Configuration:标记为配置类,Spring 容器启动时自动加载。 WebMvcConfigurer :通过实现此接口,重写addCorsMappings方法实现全局 CORS 配置- registry.
addMapping("/**") :匹配所有接口路径(如/api/**),实现全局跨域控制-
allowCredentials(true):允许跨域请求携带认证信息(如 Cookie) -
allowedOriginPatterns("*") :使用通配符允许所有域名(*) allowedMethods:包含 GET、POST等 方法以支持预检请求(Preflight)allowedHeaders("*") :允许所有自定义请求头(如Authorization)exposedHeaders("*") :允许客户端读取所有响应头(如Set-Cookie),但应仅暴露必要头
JsonConfig(Spring MVC Json 配置)
@JsonComponent :Spring Boot 专用注解,标记该类为 Jackson 的扩展组件,自动注册到 Spring 容器中,无需手动配置;作用等价于@Configuration+@Bean,但更专注于 Jackson 的定制化。Jackson2ObjectMapperBuilder :Spring Boot 提供的构建器,用于简化ObjectMapper的配置,支持 Fluent API 链式调用- ObjectMapper 初始化 :ObjectMapper是Jackson 的核心序列化工具,负责 JSON 与 Java 对象的转换。
createXmlMapper(false):禁用 XML 序列化功能,仅支持 JSON-
build() :基于构建器的默认配置(如日期格式、空值处理)创建ObjectMapper实例
- 自定义序列化模块:
SimpleModule:Jackson 提供的模块化扩展机制,用于添加自定义序列化/反序列化器ToStringSerializer :将Long和long类型序列化为字符串,避免 JavaScript 因Number类型精度限制(2^53-1)导致的数据丢失;示例:Java 中的1234567890123456789L序列化为"1234567890123456789"而非1234567890123456800。
RedisConfig(Spring Data Redis 的序列化机制和最佳实践)
- 初始化模版与连接工厂
-
RedisConnectionFactory :由 Spring Boot 自动注入,管理 Redis 连接池。 - 模板初始化 :创建
RedisTemplate实例并绑定连接工厂。
- 配置Jackson序列化器,使用 Jackson2JsonRedisSerializer 序列化值
- 类型安全处理 :
activateDefaultTyping:启用默认类型信息嵌入,支持反序列化时识别多态类型。LaissezFaireSubTypeValidator:允许所有子类反序列化,需注意潜在的安全风险。
- 序列化器定义 :使用
Jackson2JsonRedisSerializer处理值对象,支持复杂类型序列化JSON。
- 序列化策略配置,Key使用String序列化
- 键序列化 :
StringRedisSerializer:将键序列化为 UTF-8 字符串,避免二进制乱码。
- 值序列化 :
Jackson2JsonRedisSerializer:将对象序列化为 JSON,保留类型信息(如@class字段)。
- Hash 结构 :对 Hash 的键值采用相同策略,保持一致性。
- 属性生效 :
afterPropertiesSet()确保配置参数正确初始化。
- Spring Session序列化器配置
- 覆盖 Spring Session 默认的 JDK 序列化,使用 JSON 存储会话数据。
-
GenericJackson2JsonRedisSerializer :相比Jackson2JsonRedisSerializer,无需指定具体类型,自动处理泛型
ThumbConsumerConfig(集成Pulsar的自定义消费者配置代码)
PulsarListenerConsumerBuilderCustomizer :Spring Pulsar 提供的接口,允许通过customize方法深度定制消费者行为。- 批量接收策略配置。
BatchReceivePolicy:控制批量消息接收策略- maxNumMessages:单次批量拉取多少条信息
- timeout:超时后触发批量处理。
- NACK重试策略
- 当消费者调用
negativeAcknowledge()时触发重试。 RedeliveryBackoff:消息重投递的退避策略接口。- .minDelayMs(1000) // 初始延迟 1 秒 .maxDelayMs(60000) // 最大延迟 60 秒 .multiplier(2) // 指数退避倍数。首次失败后 1 秒重试,后续每次延迟时间翻倍(1s → 2s → 4s...),上限 60 秒
- 当消费者调用
- ACK超时重试策略
- 消费者未在指定时间内确认消息(默认 ACK 超时 30 秒)触发。
- .minDelayMs(5000) // 初始延迟 5 秒 .maxDelayMs(300_000) // 最大延迟 300 秒(5分钟) .multiplier(3) // 指数退避倍数。首次超时后 5 秒重试,后续延迟按 3 倍递增(5s → 15s → 45s...),上限 5 分钟
- 死信队列策略
DeadLetterPolicy:定义消息失败后的死信队列处理规则- .maxRedeliverCount(3) // 最大重试 3 次 .deadLetterTopic("thumb-dlq-topic") // 死信主题名称
- 消息重试 3 次失败后,自动路由到
thumb-dlq-topic,避免无限重试导致资源浪费
.constant(常量类)
RedisLuaScriptConstant(点赞Lua脚本)
定义了四个Lua脚本:THUMB_SCRIPT、UNTHUMB_SCRIPT、THUMB_SCRIPT_MQ和UNTHUMB_SCRIPT_MQ。这些脚本处理点赞和取消点赞的逻辑,涉及原子操作和防止重复操作。通过 RedisScript 接口封装脚本,支持 Spring Data Redis 的 execute 方法调用
java
public class RedisLuaScriptConstant {
public static final RedisScript<Long> THUMB_SCRIPT = new DefaultRedisScript<>("""
// Lua脚本内容
""", Long.class);
}THUMB_SCRIPT
tempThumbKey:临时哈希表,按时间分片(thumb:temp:202305),用于批量更新数据库。userThumbKey:永久哈希表(thumb:userId),记录用户对哪些博客点过赞。
Lua
local tempThumbKey = KEYS[1] -- 临时计数键(如 thumb:temp:{timeSlice})
local userThumbKey = KEYS[2] -- 用户点赞状态键(如 thumb:{userId})
local userId = ARGV[1] -- 用户 ID
local blogId = ARGV[2] -- 博客 ID
-- 1. 检查是否已点赞(避免重复操作)
if redis.call('HEXISTS', userThumbKey, blogId) == 1 then
return -1 -- 已点赞,返回 -1 表示失败
end
-- 2. 获取旧值(不存在则默认为 0)
local hashKey = userId .. ':' .. blogId
local oldNumber = tonumber(redis.call('HGET', tempThumbKey, hashKey) or 0)
-- 3. 计算新值
local newNumber = oldNumber + 1
-- 4. 原子性更新:写入临时计数 + 标记用户已点赞
redis.call('HSET', tempThumbKey, hashKey, newNumber)
redis.call('HSET', userThumbKey, blogId, 1)
return 1 -- 返回 1 表示成功UNTHUMB_SCRIPT
- 检查已点赞改为检查是否未点赞,如果未点赞则返回失败(~= 1)
- 计算新值改为-1
轻量级消息队列版本(THUMB_SCRIPT_MQ/UNTHUMB_SCRIPT_MQ)
Lua
-- 仅操作用户状态键,计数交由消息队列异步处理
if redis.call("HEXISTS", userThumbKey, blogId) == 1 then
return -1
end
redis.call("HSET", userThumbKey, blogId, 1)
return 1在这种实现中,lua脚本不处理点赞计数,由pulsar消息队列批量处理
ThumbConstant(点赞记录中的模板常量)
String USER_THUMB_KEY_PREFIX = "thumb:"; // 用户点赞状态键前缀(如:thumb:user:123)
Long UN_THUMB_CONSTANT = 0L; // 取消点赞的操作标识(如:0表示取消)
String TEMP_THUMB_KEY_PREFIX = "thumb:temp:%s"; // 临时计数键模板(如:thumb:temp:202305)
UserConstant
用于会话管理,如在 Redis 中存储登录用户信息(键如 login_user:123)或在 HTTP 请求属性中标识当前用户
java
package com.yuyuan.thumb.constant;
public interface UserConstant {
public static final String LOGIN_USER = "login_user";
}.controller(Spring MVC控制器类)

BlogController
Blog和BlogVO:实体类与视图对象,实现数据层与展示层解耦。@Resource:Jakarta EE 的依赖注入注解,按名称自动装配 BeanHttpServletRequest:用于获取请求信息(如 Session、IP 等)-
@RestController :标识为 RESTful 控制器,自动将返回值序列化为 JSON。 -
@RequestMapping("blog") :定义基础路径为/blog,所有方法 URL 以该路径为前缀 @Resource :注入BlogService实现类,优先按名称匹配 Bean(等效于@Autowired + @Qualifier)
获取单个博客
java
@GetMapping("/get")
public BaseResponse<BlogVO> get(long blogId, HttpServletRequest request) {
BlogVO blogVO = blogService.getBlogVOById(blogId, request);
return ResultUtils.success(blogVO);
}获取博客列表
java
@GetMapping("/list")
public BaseResponse<List<BlogVO>> list(HttpServletRequest request) {
List<Blog> blogList = blogService.list();
List<BlogVO> blogVOList = blogService.getBlogVOList(blogList, request);
return ResultUtils.success(blogVOList);
}业务逻辑:
- 调用
blogService.list()获取原始数据列表。 - 转换为视图对象
BlogVO列表,可能包含权限过滤或数据脱敏
ThumbController
-
@RestController:声明为 RESTful 控制器,自动将返回值序列化为 JSON @RequestMapping("thumb") :基础路径映射为/thumb,所有方法 URL 以该路径为前缀。
java
private final Counter successCounter;
private final Counter failureCounter;
public ThumbController(MeterRegistry registry) {
this.successCounter = Counter.builder("thumb.success.count")
.description("Total successful thumb").register(registry);
this.failureCounter = Counter.builder("thumb.failure.count")
.description("Total failed thumb").register(registry);
}- Micrometer 计数器 :通过构造函数初始化两个计数器,用于统计成功和失败次数。
thumb.success.count:成功点赞的累计次数。thumb.failure.count:失败操作的累计次数(包括异常和业务逻辑失败)。
- 设计意图:提供监控指标,便于集成 Prometheus + Grafana 监控系统。
java
@PostMapping("/do")
public BaseResponse<Boolean> doThumb(@RequestBody DoThumbRequest request, HttpServletRequest httpRequest) {
Boolean success;
try {
success = thumbService.doThumb(request, httpRequest);
if (success) {
successCounter.increment(); // 成功计数
} else {
failureCounter.increment(); // 业务逻辑失败计数
}
} catch (Exception e) {
failureCounter.increment(); // 异常失败计数
throw e; // 抛出异常由全局异常处理器处理[6,7,8](@ref)
}
return ResultUtils.success(success);
}@PostMapping("/do") :处理 POST 请求/thumb/do。- 参数解析 :
@RequestBody DoThumbRequest:接收 JSON 格式的请求体,自动反序列化为 DTO 对象。HttpServletRequest:获取请求上下文(如用户 Session、IP 等)。
- 业务逻辑 :
- 调用
thumbService.doThumb执行点赞操作。 - 根据结果更新监控计数器。
- 异常捕获后统一计数,并通过
throw e触发全局异常处理
- 调用
UserController
-
@RestController :声明为 RESTful 控制器,自动将返回值序列化为 JSON。 -
@RequestMapping("user") :定义基础路径为/user,所有方法 URL 前缀为此路径
java
@GetMapping("/login")
public BaseResponse<User> login(long userId, HttpServletRequest request) {
User user = userService.getById(userId);
request.getSession().setAttribute(UserConstant.LOGIN_USER, user);
return ResultUtils.success(user);
}@GetMapping("/login") :映射 GET 请求到/user/login,接收userId参数。- 参数解析 :
long userId:通过 URL 查询参数获取(如/user/login?userId=1)。HttpServletRequest:获取会话对象,用于存储登录态。
- 业务逻辑 :
- 调用
userService.getById查询用户信息。 - 将用户对象存入会话,键名为常量
LOGIN_USER。 - 返回用户信息,响应体格式为
BaseResponse<User>
- 调用
.exception(全局异常处理)
GlobalExceptionHandler
java
@RestControllerAdvice
@Slf4j
// 在接口文档中隐藏
@Hidden
public class GlobalExceptionHandler {
@ExceptionHandler(RuntimeException.class)
public BaseResponse<?> runtimeExceptionHandler(RuntimeException e) {
log.error(e.getMessage(), e);
return ResultUtils.error(ErrorCode.OPERATION_ERROR, e.getMessage());
}
}-
@RestControllerAdvice :组合了@ControllerAdvice和@ResponseBody,表示这是一个全局异常处理器,所有异常响应自动转换为 JSON 格式。 -
@Slf4j :自动生成日志对象,用于记录异常信息。 -
@Hidden:在 Swagger/OpenAPI 文档中隐藏此控制器,避免暴露异常处理端点 @ExceptionHandler(RuntimeException.class) :捕获所有RuntimeException及其子类异常(如NullPointerException、IllegalArgumentException)- 参数 :
RuntimeException e接收抛出的异常对象。 log.error(e.getMessage(), e)记录错误消息和完整堆栈跟踪,便于排查问题- 调用
ResultUtils.error()构建标准化错误响应,包含预定义的错误码ErrorCode.OPERATION_ERROR和异常消息
java
{
"code": 50002,
"message": "操作失败",
"data": null
}.job(定时、持久化、补偿任务)
SyncThumb2DBCompensatoryJob
定时将 Redis 中的临时点赞数据同步到数据库的补偿措施。当数据在 Redis 中,由于不可控因素停机导致没有成功同步到数据库时,通过该任务补偿。
- RedisTemplate :用于操作 Redis 键值,支持模糊查询 (
keys方法) 和数据结构管理。 - SyncThumb2DBJob:封装具体的数据同步逻辑,实现业务解耦
java
@Scheduled(cron = "0 0 2 * * *")
public void run() {
log.info("开始补偿数据");
Set<String> thumbKeys = redisTemplate.keys(RedisKeyUtil.getTempThumbKey("") + "*");
Set<String> needHandleDataSet = new HashSet<>();
thumbKeys.stream().filter(ObjUtil::isNotNull).forEach(thumbKey -> needHandleDataSet.add(thumbKey.replace(ThumbConstant.TEMP_THUMB_KEY_PREFIX.formatted(""), "")));
if (CollUtil.isEmpty(needHandleDataSet)) {
log.info("没有需要补偿的临时数据");
return;
}
// 补偿数据
for (String date : needHandleDataSet) {
syncThumb2DBJob.syncThumb2DBByDate(date);
}
log.info("临时数据补偿完成");
}Cron 表达式 :0 0 2 * * * 表示每天凌晨2点执行,用于低峰期处理补偿任务
- 模糊查询 :
redisTemplate.keys通过通配符*匹配所有临时点赞数据键,例如temp:thumb:20240520。 - 数据存储 :使用
HashSet存储待处理日期集合,避免重复 - Hutool 判空 :
ObjUtil.isNotNull过滤无效键值,防止 NPE。 - 键名处理 :通过字符串替换提取日期部分(如
20240520),剥离前缀temp:thumb: - Hutool 集合工具 :
CollUtil.isEmpty替代原生Collection.isEmpty,增强可读性 - 职责分离 :调用
syncThumb2DBJob实现具体同步逻辑,符合单一职责原则。 - 补偿机制:针对 Redis 中残留的临时数据(可能因服务宕机未同步),确保数据最终一致性
SyncThumb2DBJob
定时将 Redis 中的临时点赞数据同步到数据库
java
@Resource
private ThumbService thumbService; // 点赞业务服务
@Resource
private BlogMapper blogMapper; // 博客数据库操作
@Resource
private RedisTemplate<String, Object> redisTemplate; // Redis 操作模板定时任务配置
java
@Scheduled(fixedRate = 10000)
@Transactional(rollbackFor = Exception.class)
public void run() {
DateTime nowDate = DateUtil.date();
String date = DateUtil.format(nowDate, "HH:mm:") + (DateUtil.second(nowDate) / 10 - 1) * 10;
syncThumb2DBByDate(date);
}@Scheduled :每 10 秒执行一次同步任务,fixedRate表示从任务开始时间计算间隔。- 时间窗口计算 :按 10 秒时间窗口生成 Redis 键名(如
12:34:20对应12:34:10),实现数据分片存储。 -
@Transactional:启用事务管理,确保数据库操作的原子性
数据同步核心逻辑
java
public void syncThumb2DBByDate(String date) {
// 使用 temp:thumb:{date} 作为键,字段为 userID:blogID,值为点赞类型(+1/-1)
String tempThumbKey = RedisKeyUtil.getTempThumbKey(date);
// entries() 获取指定键的所有字段和值,数据格式为 用户ID:博客ID -> 操作类型(1/-1)
Map<Object, Object> allTempThumbMap = redisTemplate.opsForHash().entries(tempThumbKey);
// Hutool工具类数据判空
if (CollUtil.isEmpty(allTempThumbMap)) return;
// 初始化数据结构
ArrayList<Thumb> thumbList = new ArrayList<>();
// 动态构建删除条件(userId 和 blogId 组合),支持批量删除取消的点赞记录
LambdaQueryWrapper<Thumb> wrapper = new LambdaQueryWrapper<>();
// 键是博客ID(blogId),值是该博客的点赞增量(累计的 thumbType 值)
Map<Long, Long> blogThumbCountMap = new HashMap<>();
boolean needRemove = false;
// 遍历 Redis 数据
for (Object userIdBlogIdObj : allTempThumbMap.keySet()) {
String userIdBlogId = (String) userIdBlogIdObj;
// 根据:拆分userID与blogID
String[] userIdAndBlogId = userIdBlogId.split(StrPool.COLON);
Long userId = Long.parseLong(userIdAndBlogId[0]);
Long blogId = Long.parseLong(userIdAndBlogId[1]);
Integer thumbType = Integer.valueOf(allTempThumbMap.get(userIdBlogId).toString());
// 处理点赞(1)和取消点赞(-1)
if (thumbType == ThumbTypeEnum.INCR.getValue()) {
Thumb thumb = new Thumb().setUserId(userId).setBlogId(blogId);
thumbList.add(thumb);
} else if (thumbType == ThumbTypeEnum.DECR.getValue()) {
// or()声明后续条件与前一个条件通过 OR 逻辑连接
// .eq()添加等值条件,相当于SQL中的=
// .eq(Thumb::getUserId, userId):匹配 user_id 字段等于参数 userId
// WHERE (user_id = ? OR blog_id = ?)
wrapper.or().eq(Thumb::getUserId, userId).eq(Thumb::getBlogId, blogId);
needRemove = true;
}
// 统计博客点赞增量
// getOrDefault(blogId, 0L):若 blogId 已存在,则返回其当前值;若不存在,则返回默认值 0L(避免 NullPointerException)
blogThumbCountMap.put(blogId, blogThumbCountMap.getOrDefault(blogId, 0L) + thumbType);
}
// 批量插入新点赞
thumbService.saveBatch(thumbList);
// 批量删除取消点赞
if (needRemove) thumbService.remove(wrapper);
// 批量更新博客点赞量
if (!blogThumbCountMap.isEmpty()) {
blogMapper.batchUpdateThumbCount(blogThumbCountMap);
}
// 使用虚拟线程异步删除 Redis 数据
Thread.startVirtualThread(() -> redisTemplate.delete(tempThumbKey));
}ThumbReconcileJob (集成pulsar)
一个定时任务,用于点赞数据的对账,检查Redis和MySQL之间的数据一致性,并发送补偿事件。
- RedisTemplate:用于操作 Redis 键值,支持 SCAN 分页查询
- ThumbService:MyBatis Plus 的 Service 层,处理数据库操作。
- PulsarTemplate:Apache Pulsar 的消息发送模板,实现异步事件补偿
@Scheduled :Cron 表达式触发定时任务;低峰期执行:选择凌晨2点避免业务高峰期影响
获取该分片下的所有用户ID
java
// 存储从 Redis 中提取的用户 ID
Set<Long> userIds = new HashSet<>();
// * 是通配符,匹配所有以该前缀开头的键
String pattern = ThumbConstant.USER_THUMB_KEY_PREFIX + "*";
// 执行 SCAN 命令分页遍历键
try (Cursor<String> cursor = redisTemplate.scan(
// ScanOptions配置扫描参数,包括匹配模式和分页数量。
// .match(pattern):设置键的匹配模式
// .count(1000):提示 Redis 单次返回约 1000 个键
ScanOptions.scanOptions().match(pattern).count(1000).build())) {
// 遍历游标获取键
while (cursor.hasNext()) {
String key = cursor.next();
// key.replace():去除键名前缀
Long userId = Long.valueOf(key.replace(ThumbConstant.USER_THUMB_KEY_PREFIX, ""));
userIds.add(userId);
}
}从 Redis 获取用户点赞的博客 ID、从 MySQL 获取持久化的博客 ID、计算数据差异(Redis中有但是MySQL中没有的数据)
java
// 遍历用户 ID 集合 userIds,逐个处理每个用户的点赞数据对账
// Lambda 表达式:Java 8 的 forEach 语法,替代传统循环
userIds.forEach(userId -> {
// 从 Redis 获取该用户userId点赞的博客 blogID
Set<Long> redisBlogIds = redisTemplate.opsForHash()
// opsForHash().keys():获取指定 Redis 键的所有字段(即博客 ID),返回 Set<Object>
.keys(ThumbConstant.USER_THUMB_KEY_PREFIX + userId)
// stream().map():将字段值(Object 类型)转换为 Long 类型
.stream().map(obj -> Long.valueOf(obj.toString()))
// Collectors.toSet():收集为 Set<Long> 集合,自动去重
.collect(Collectors.toSet());
// 从 MySQL 获取已持久化的博客 ID
// 通过 MyBatis Plus 的 Lambda 表达式构建查询条件,筛选 Thumb 表中 userId 字段等于参数 userId 的所有记录
// 将查询结果包装为 Optional 对象,允许接受 null 值
Set<Long> mysqlBlogIds = Optional.ofNullable(thumbService.lambdaQuery()
// 添加 WHERE user_id = userId 条件
.eq(Thumb::getUserId, userId).list())
// 若查询结果为 null,返回空列表作为默认值
.orElse(new ArrayList<>())
// 将 List<Thumb> 转换为 Stream<Thumb>,并通过 map 操作提取每个 Thumb 对象的 blogId 字段
.stream().map(Thumb::getBlogId)
// 将 Stream<Long> 收集为 Set<Long>,自动去重 blogId
.collect(Collectors.toSet());
// 最终 mysqlBlogIds 是用户 userId 在 MySQL 中所有点赞的博客 ID 集合。
// 计算差异(Redis 有但 MySQL 无)
// 包含所有在集合 redis 中存在但集合 mysql 中不存在的元素
Set<Long> diffBlogIds = Sets.difference(redisBlogIds, mysqlBlogIds);
// 4. 发送补偿事件
sendCompensationEvents(userId, diffBlogIds);
});发送补偿事件到Pulsar
- 作用:定义私有方法,用于发送点赞补偿事件。
- 参数 :
userId:触发补偿操作的用户 ID。blogIds:需补偿的博客 ID 集合(Redis 中存在但 MySQL 缺失的数据)。
java
private void sendCompensationEvents(Long userId, Set<Long> blogIds) {
blogIds.forEach(blogId -> {
ThumbEvent thumbEvent = new ThumbEvent(userId, blogId, ThumbEvent.EventType.INCR, LocalDateTime.now());
pulsarTemplate.sendAsync("thumb-topic", thumbEvent)
.exceptionally(ex -> {
log.error("补偿事件发送失败: userId={}, blogId={}", userId, blogId, ex);
return null;
});
});
}- 逻辑 :使用
forEach遍历blogIds集合,逐个处理需要补偿的博客 ID。 - 参数解析 :
userId和blogId:标识具体用户和博客的补偿操作。EventType.INCR:表示点赞增量事件(对应 Redis 的点赞计数恢复)。LocalDateTime.now():记录事件触发时间,用于后续审计或延迟处理
- Pulsar 异步发送 :
-
sendAsync() :非阻塞发送消息,提升吞吐量。 - Topic 名称 :
thumb-topic是预定义的 Pulsar 主题,需确保与消费者订阅匹配 - 异常捕获 :
exceptionally()捕获异步发送中的异常(如网络故障、Topic 不存在),避免因单条消息失败导致整个补偿流程中断。 - 日志记录 :记录详细的错误信息(包括
userId和blogId),便于后续人工干预或自动化重试
-
.listener.thumb(点赞事件监听)
.msg ThumbEvent(定义点赞事件)
@Data功能:组合注解,自动生成以下方法:
- Getter/Setter:所有字段的访问器和修改器。
- toString():返回包含所有字段的字符串表示。
- equals()/hashCode():基于所有非静态字段生成对象相等性判断和哈希值。
@Builder功能:生成建造者模式代码,支持链式调用:
- 创建
ThumbEventBuilder内部类,提供字段的链式设置方法(如.userId(1L).blogId(2L))。 - 通过
ThumbEvent.builder().build()构造对象。
@NoArgsConstructor :生成无参构造函数(public ThumbEvent() {})。
@AllArgsConstructor :生成包含所有字段的全参构造函数(public ThumbEvent(Long userId, Long blogId, ...))
字段类型:
Long:用户和博客的唯一标识符,支持高并发场景的 ID 生成。EventType:自定义枚举,表示操作类型(如点赞INCR或取消点赞DECR)。LocalDateTime:记录事件发生时间,支持精确到纳秒的时间处理。
java
private Long userId;
private Long blogId;
// INCR/DECR
private EventType type;
private LocalDateTime eventTime;
public enum EventType {
INCR,
DECR
}ThumbConsumer(处理点赞事件的消费者)
-
@Service:声明为 Spring 服务组件,由容器管理生命周期。 -
@RequiredArgsConstructor :Lombok 生成基于final字段的构造函数,自动注入BlogMapper和ThumbService。 -
@Slf4j :自动生成日志对象log,用于记录操作日志。
死信队列监听器
java
@PulsarListener(topics = "thumb-dlq-topic")
public void consumerDlq(Message<ThumbEvent> message) {
MessageId messageId = message.getMessageId();
log.info("dlq message = {}", messageId);
log.info("消息 {} 已入库", messageId);
log.info("已通知相关人员 {} 处理消息 {}", "坤哥", messageId);
}死信队列主题 :当消息在常规队列中达到最大重试次数(通过 deadLetterPolicy 配置,本项目为3次)后,会被自动路由到此主题
Message<ThumbEvent> :封装了消息内容(ThumbEvent 对象)和元数据(如消息 ID、生产者信息、投递时间戳等)
功能解析:
- 记录死信消息:将消息 ID 写入日志,便于后续审计。
- 数据持久化:将消息内容存储至数据库(如 MySQL 或 Elasticsearch),防止数据丢失。
- 人工干预通知:通过日志触发告警(如邮件、短信)通知运维人员(如"坤哥")介入处理
java
@PulsarListener(
subscriptionName = "thumb-subscription", // 订阅名称,用于标识消费者组
topics = "thumb-topic", // 监听的 Pulsar 主题
schemaType = SchemaType.JSON, // 消息序列化方式(JSON 格式)
batch = true, // 启用批量消费模式
subscriptionType = SubscriptionType.Shared, // 共享订阅模式(允许多消费者并行)
negativeAckRedeliveryBackoff = "negativeAckRedeliveryBackoff", // NACK 重试策略
ackTimeoutRedeliveryBackoff = "ackTimeoutRedeliveryBackoff", // ACK 超时重试策略
deadLetterPolicy = "deadLetterPolicy" // 死信队列策略
)
// 将消息处理与数据库操作绑定到同一事务,任一环节异常触发整体回滚
// 若消息处理或数据库更新失败,Pulsar 消息不会被确认(ACK),触发重试机制
@Transactional(rollbackFor = Exception.class)
public void processBatch(List<Message<ThumbEvent>> messages) {
// 记录当前批次处理的消息数量
log.info("ThumbConsumer processBatch: {}", messages.size());
// 存储每个博客(blogId)的点赞数变化量
// 键(Key):Long 类型,表示博客 ID;
// 值(Value):Long 类型,表示该博客的点赞数累计变化量。
Map<Long, Long> countMap = new ConcurrentHashMap<>();
// 收集需要批量插入数据库的新增点赞记录(Thumb 实体对象)
List<Thumb> thumbs = new ArrayList<>();
// 并行处理消息
// 动态构建删除条件,用于批量删除取消点赞(DECR 事件)对应的记录。
LambdaQueryWrapper<Thumb> wrapper = new LambdaQueryWrapper<>();
// 标记是否需要执行删除操作。当至少存在一个 DECR 事件时,设置为 true
AtomicReference<Boolean> needRemove = new AtomicReference<>(false);
// 提取有效事件
List<ThumbEvent> events = messages.stream()
.map(Message::getValue) // 从消息中提取事件对象
.filter(Objects::nonNull) // 过滤掉 value 为 null 的无效消息(如反序列化失败的消息)
.toList(); // 转换为不可变列表
// 按(userId, blogId)分组,并获取每个分组的最新事件
// 使用 Pair<Long, Long> 组合用户 ID 和博客 ID
Map<Pair<Long, Long>, ThumbEvent> latestEvents = events.stream()
.collect(Collectors.groupingBy( // groupingBy 根据键将事件分组到不同列表中
e -> Pair.of(e.getUserId(), e.getBlogId()), // 分组键:用户ID + 博客ID组合
Collectors.collectingAndThen( // 分组后的聚合处理
Collectors.toList(), // 先收集为列表
list -> {
// 按时间升序排序
list.sort(Comparator.comparing(ThumbEvent::getEventTime));
// 若分组事件数量为偶数,返回 null 丢弃该分组(可能用于过滤重复操作,如点赞后取消)
if (list.size() % 2 == 0) return null;
// 取最新事件(排序后最后一个
return list.get(list.size() - 1);
}
)
));
latestEvents.forEach((userBlogPair, event) -> { // 遍历按(userId,blogId)分组后的最新事件集合
if (event == null) return; // 过滤空事件(如偶数次操作被业务规则排除)
ThumbEvent.EventType finalAction = event.getType(); // 获取事件类型(INCR/DECR)
if (finalAction == ThumbEvent.EventType.INCR) { // 处理点赞逻辑
countMap.merge(event.getBlogId(), 1L, Long::sum); // 原子性更新博客点赞计数
Thumb thumb = new Thumb(); // 创建点赞记录实体
thumb.setBlogId(event.getBlogId());
thumb.setUserId(event.getUserId());
thumbs.add(thumb); // 收集待插入的点赞记录
} else { // 处理取消点赞逻辑
needRemove.set(true); // 标记为 需要删除
wrapper.or().eq(Thumb::getUserId, event.getUserId())
.eq(Thumb::getBlogId, event.getBlogId());
// Key:博客ID(blogId)Value:增量(+1或-1)函数:Long::sum 实现累加/累减
countMap.merge(event.getBlogId(), -1L, Long::sum); // 原子性减少博客点赞计数
}
});
// 批量更新数据库
if (needRemove.get()) {
thumbService.remove(wrapper);
}
batchUpdateBlogs(countMap);
batchInsertThumbs(thumbs);
}批量更新博客的点赞计数
java
public void batchUpdateBlogs(Map<Long, Long> countMap) {
if (!countMap.isEmpty()) {
blogMapper.batchUpdateThumbCount(countMap);
}
}批量向数据库插入点赞记录
java
public void batchInsertThumbs(List<Thumb> thumbs) {
if (!thumbs.isEmpty()) {
// 分批次插入
thumbService.saveBatch(thumbs, 500);
}
}.manager.cache
CacheManager
多级缓存架构 + 初始化HeavyKeeper
java
@Component
@Slf4j
public class CacheManager {
private TopK hotKeyDetector; // 热点Key检测器(基于HeavyKeeper算法)
private Cache<String, Object> localCache; // Caffeine本地缓存实例
@Resource
private RedisTemplate<String, Object> redisTemplate; // Redis操作模板
@Bean
public TopK getHotKeyDetector() {
hotKeyDetector = new HeavyKeeper(
100, // 监控Top 100 Key
100000, // 哈希表宽度(降低哈希冲突)
5, // 哈希表深度(桶的层级)
0.92, // 衰减系数(定期减少历史计数,防止旧数据堆积)
10 // 最小出现次数(阈值,超过才视为热点)
);
return hotKeyDetector;
}
@Bean
public Cache<String, Object> localCache() {
return localCache = Caffeine.newBuilder()
.maximumSize(1000) // 最大缓存条目数
.expireAfterWrite(5, TimeUnit.MINUTES) // 写入5分钟后过期
.build();
}
// 缓存键构造方法
private String buildCacheKey(String hashKey, String key) {
return hashKey + ":" + key; // 构造复合键(如"user:123")
}检索数据与预热
java
public Object get(String hashKey, String key) {
String compositeKey = buildCacheKey(hashKey, key);
// 1. 先查本地缓存
// 查询Caffeine本地缓存,命中则直接返回
Object value = localCache.getIfPresent(compositeKey);
if (value != null) {
log.info("本地缓存命中: {} = {}", compositeKey, value);
hotKeyDetector.add(key, 1); // 记录访问频率,更新热点检测器中的访问计数
return value;
}
// 2. 查询Redis
// 通过Spring Data Redis访问Redis哈希结构数据
Object redisValue = redisTemplate.opsForHash().get(hashKey, key);
if (redisValue == null) return null;
// 累计访问次数并判断是否达到阈值
// 3. 检测是否为热点Key
AddResult addResult = hotKeyDetector.add(key, 1);
// 4. 热点Key则写入本地缓存
if (addResult.isHotKey()) {
localCache.put(compositeKey, redisValue);
}
return redisValue;
}条件性更新本地缓存,仅当缓存中已存在指定键时更新其值。
参数:
hashKey:thumb : useID。key:blogID。- compositeKey:thumb : userID : blogID
value:点赞 / 取消点赞
java
public void putIfPresent(String hashKey, String key, Object value) {
String compositeKey = buildCacheKey(hashKey, key);
// 查询 Caffeine 本地缓存,若键存在则返回旧值,否则返回 null
Object object = localCache.getIfPresent(compositeKey);
// 若缓存未命中(object == null),直接终止方法,避免插入新键值对
if (object == null) {
return;
}
localCache.put(compositeKey, value);
}定时任务:清理过期的热Key检测数据
java
// 定时清理过期的热 Key 检测数据
// 表示每20s执行一次方法
@Scheduled(fixedRate = 20, timeUnit = TimeUnit.SECONDS)
public void cleanHotKeys() {
hotKeyDetector.fading(); // 对统计的Key访问计数进行指数衰减(乘以0.92系数)
}固定速率模式(fixedRate特性):
- 每20秒触发一次,不考虑前次任务执行时长
- 若任务执行时间超过20秒,会立即启动新线程执行(需配置线程池)
HeavyKeeper
java
public class HeavyKeeper implements TopK {
private static final int LOOKUP_TABLE_SIZE = 256;
private final int k; // 维护的 Top-K 数量
private final int width; // 哈希表每行的桶数量
private final int depth; // 哈希表的行数(哈希函数数量)
private final double[] lookupTable; // 预计算的衰减概率表
private final Bucket[][] buckets; // 二维哈希桶数组
private final PriorityQueue<Node> minHeap; // 最小堆维护 Top-K
private final BlockingQueue<Item> expelledQueue; // 被移出 Top-K 的队列
private final Random random; // 用于概率衰减
private long total; // 总访问次数
private final int minCount; // 进入 Top-K 的最小阈值
// 构造函数
public HeavyKeeper(int k, int width, int depth, double decay, int minCount) {
// 初始化参数
this.lookupTable = new double[LOOKUP_TABLE_SIZE];
for (int i = 0; i < LOOKUP_TABLE_SIZE; i++) {
lookupTable[i] = Math.pow(decay, i); // 预计算衰减概率,生成衰减概率表
}
// 初始化二维哈希桶
this.buckets = new Bucket[depth][width];
for (int i = 0; i < depth; i++) {
for (int j = 0; j < width; j++) {
buckets[i][j] = new Bucket(); // 每个桶存储指纹和计数
}
}
// 初始化最小堆和队列
this.minHeap = new PriorityQueue<>(Comparator.comparingInt(n -> n.count));
this.expelledQueue = new LinkedBlockingQueue<>();
this.random = new Random();
this.total = 0;
}
}lookupTable 是一个预计算的概率衰减表
存储内容 :每个元素对应 decay^i,即 i 次方的衰减概率值。例如:
lookupTable[0] = 1(decay^0)lookupTable[1] = decay(decay^1)lookupTable[2] = decay^2,依此类推
在 HeavyKeeper 处理哈希冲突时,lookupTable 用于动态调整低频键的计数:
- 冲突处理 :当两个不同键哈希到同一桶(Bucket)时,根据当前桶的计数值
count,从lookupTable中获取对应的衰减概率decay^count。 - 概率衰减 :通过
random.nextDouble() < decay判断是否减少该桶的计数值。高频键因计数高(decay^count值小),衰减概率低;低频键则更可能被衰减淘汰。 - 性能优化 :预计算替代实时计算
Math.pow(decay, count),减少 CPU 开销(类似网页2提到的查表加速原理)
add方法处理数据流中的元素并更新TopK
java
@Override
public AddResult add(String key, int increment) {
byte[] keyBytes = key.getBytes(); // 将键转换为字节数组 keyBytes(用于哈希计算)
long itemFingerprint = hash(keyBytes); // 计算键的指纹
int maxCount = 0; //maxCount 用于记录该键在所有哈希层中的最大计数值(最终用于判断是否进入 TopK)
// 遍历所有哈希层(depth 行),通过多个哈希函数(h1, h2, ..., hd)映射到不同行的桶
for (int i = 0; i < depth; i++) {
// bucketNumber 通过哈希计算确定当前行的桶位置,% width 保证不越界
int bucketNumber = Math.abs(hash(keyBytes)) % width; // 哈希到当前行的桶
Bucket bucket = buckets[i][bucketNumber];
synchronized (bucket) { // 线程安全
if (bucket.count == 0) { // Case 1: 桶为空
// 直接占用空桶,记录指纹和初始计数值。
bucket.fingerprint = itemFingerprint;
bucket.count = increment;
} else if (bucket.fingerprint == itemFingerprint) { // Case 2: 指纹匹配
// 指纹一致时直接增加计数
bucket.count += increment;
} else { // Case 3: 冲突,概率衰减
for (int j = 0; j < increment; j++) {
// 通过预计算的 lookupTable(存储 decay^count 概率)决定是否衰减冲突桶的计数
double decay = (bucket.count < LOOKUP_TABLE_SIZE)
? lookupTable[bucket.count]
: lookupTable[LOOKUP_TABLE_SIZE - 1];
if (random.nextDouble() < decay) { // 按概率衰减
bucket.count--;
if (bucket.count == 0) { // 桶清空后重新占用
bucket.fingerprint = itemFingerprint;
bucket.count = increment - j;
maxCount = Math.max(maxCount, bucket.count); // 取各层的最大计数
break;
}
}
}
}
}
}
// total 记录所有键的总访问量(用于监控)
total += increment;
// minCount 是进入 TopK 的最低频率阈值,未达标直接返回。
if (maxCount < minCount) {
return new AddResult(null, false, null);
}
// 更新最小堆
// 以 minHeap 对象为锁,所有对 minHeap 的操作(增、删、查)在并发场景下互斥执行,避免数据不一致。
synchronized (minHeap) {
// 标记当前Key是否进入Top-K
boolean isHot = false;
// 记录被挤出Top-K的Key
String expelled = null;
// 遍历最小堆,检查当前Key是否已存在于堆中
Optional<Node> existing = minHeap.stream().filter(n -> n.key.equals(key)).findFirst();
if (existing.isPresent()) { // 键已存在堆中
// 删除堆中已有的相同Key节点(旧计数可能已过时)
minHeap.remove(existing.get());
// 用当前最新的 maxCount 创建新节点加入堆
minHeap.add(new Node(key, maxCount)); // 更新计数
// 更新操作后Key仍留在Top-K中,标记为热点
isHot = true;
} else { // 新键尝试加入堆
// 堆未满 || 堆已满但新计数 >= 堆顶
if (minHeap.size() < k || maxCount >= minHeap.peek().count) {
if (minHeap.size() >= k) { // 堆满时挤出堆顶
// poll() 移除堆顶元素(最小计数项)
expelled = minHeap.poll().key;
// 将被淘汰的Key加入 expelledQueue,供外部监控(
expelledQueue.offer(new Item(expelled, maxCount));
}
minHeap.add(new Node(key, maxCount));
isHot = true;
}
}
return new AddResult(expelled, isHot, key);
}
}获取当前Top-K列表:最小堆内部按计数升序排列,但对外提供降序列表,便于用户直接获取热点排名。
java
@Override
public List<Item> list() {
synchronized (minHeap) { // 线程安全:锁定最小堆对象
List<Item> result = new ArrayList<>(minHeap.size());
for (Node node : minHeap) { // 遍历最小堆中的节点
result.add(new Item(node.key, node.count)); // 将节点转换为 Item 对象
}
result.sort((a, b) -> Integer.compare(b.count(), a.count())); // 按计数降序排序
return result;
}
}expelled() 方法:获取被移出 Top-K 的队列
java
@Override
public BlockingQueue<Item> expelled() {
return expelledQueue; // 直接返回被淘汰项的阻塞队列
}fading()方法:调用来定期清理历史热点数据
java
@Override
public void fading() {
for (Bucket[] row : buckets) {
for (Bucket bucket : row) {
synchronized (bucket) { // 锁定单个桶对象
bucket.count = bucket.count >> 1; // 计数值右移一位(等价于除以2)
}
}
}
synchronized (minHeap) {
PriorityQueue<Node> newHeap = new PriorityQueue<>(Comparator.comparingInt(n -> n.count));
for (Node node : minHeap) {
newHeap.add(new Node(node.key, node.count >> 1)); // 重建新堆并衰减计数
}
minHeap.clear();
minHeap.addAll(newHeap);
}
total = total >> 1; // 全局总访问量右移一位(等价于总数减半)
}total()方法:获取系统中所有Key的历史访问总数
java
@Override
public long total() {
return total; // 返回全局总访问量(如所有键的累计计数)
}Bucket类:每个 Bucket 是二维哈希表中的一个桶,存储:
fingerprint:通过hash(byte[] data)计算的64位哈希值,用于区分相同位置的不同键。count:记录该键在当前桶的累计访问次数。
java
private static class Bucket {
long fingerprint; // 哈希指纹,用于唯一标识一个键
int count; // 当前键在此桶中的计数值
}Node类:作为最小堆(PriorityQueue)中的元素,用于维护 Top-K 高频键
java
private static class Node {
final String key; // 键名
final int count; // 当前键的计数值(在堆中的排序依据)
Node(String key, int count) {
this.key = key; // 不允许键名修改(防御性编程)
this.count = count; // 不可变计数,保障一致性
}
}hash函数:为输入数据生成快速且低冲突的哈希值
- 选择MurmurHash的原因 :
- 高效性:优化后的位运算,性能优于 MD5、SHA 等加密算法。
- 扩散性:良好的雪崩效应,相似输入生成差异巨大的哈希值。
- 实现简单:无需外部依赖,适用于内存受限场景。
- 应用场景 :在 HeavyKeeper 的每一层哈希表(
depth层)中生成不同的桶索引(int bucketNumber = ...)
java
private static int hash(byte[] data) {
return HashUtil.murmur32(data); // 使用MurmurHash算法生成32位哈希值
}新增返回结果类AddResult
java
// 新增返回结果类
@Data
class AddResult {
// 被挤出Top-K的 key
private final String expelledKey;
// 当前 key 是否进入/保留 TopK
private final boolean isHotKey;
// 当前操作的 key
private final String currentKey;
public AddResult(String expelledKey, boolean isHotKey, String currentKey) {
this.expelledKey = expelledKey;
this.isHotKey = isHotKey;
this.currentKey = currentKey;
}
}@Data 注解:Lombok 注解,自动生成以下方法:
getter方法:用于访问所有字段。equals()和hashCode():基于所有字段的相等性判断。toString():生成包含所有字段的字符串表示。- 注意 :由于字段为
final,Lombok 不会生成setter方法,确保对象不可变性(线程安全)
参数说明:
expelledKey:由HeavyKeeper.add()方法在淘汰旧键时传递(例如minHeap.poll().key)。isHotKey:根据新键是否成功加入 Top-K 确定(例如堆未满或计数超过堆顶)。currentKey:直接传递调用add()方法时传入的键名。
不可变设计:构造函数一次性初始化所有字段,后续无法修改,符合函数式编程理念。
Item
java
package com.yuyuan.thumb.manager.cache;
// Item.java
public record Item(String key, int count) {}记录类(Record)的基本特性
- 不可变性 :
Item类是一个记录类(Java 14+特性),其所有字段(key和count)默认是final的,即不可变。一旦对象被创建,无法修改其状态。 - 自动生成方法 :编译器会自动生成以下内容:
- 全参构造函数:
public Item(String key, int count) - 字段访问方法:
key()和count()(没有get前缀) equals()和hashCode():基于所有字段的相等性和哈希值toString():返回类似Item[key=..., count=...]的字符串
- 全参构造函数:
- 数据载体 :
Item类用于表示一个简单的数据对象,包含两个属性:key:标识某个缓存项(Key ID)。count:与key关联的数值(访问次数)。
在HeavyKeeper等算法中,用Item存储热点键及其计数,用于排序和淘汰逻辑。
TopK
java
package com.yuyuan.thumb.manager.cache;// TopK.java
import java.util.List;
import java.util.concurrent.BlockingQueue;
public interface TopK {
AddResult add(String key, int increment); // 向 TopK 结构中添加一个键及其增量计数,返回操作结果(是否成为热点、被挤出的键等)。
List<Item> list(); // 返回当前 TopK 列表(按计数降序排列)
BlockingQueue<Item> expelled(); // 返回被移出 TopK 的队
void fading(); // 对所有计数进行衰减
long total(); // 返回全局总访问量
}.mapper(Spring 数据访问层)
BlogMapper
java
public interface BlogMapper extends BaseMapper<Blog> {
// 批量更新博客点赞数,接收 Map<Long, Long> 参数,键为博客 ID (blogId),值为点赞增量(正负均可)
void batchUpdateThumbCount(@Param("countMap") Map<Long, Long> countMap);
}继承 BaseMapper<Blog>:
- 功能扩展 :自动获得 17 种基础 CRUD 方法(如
selectList、updateById),无需手动实现。 - 泛型参数
Blog:指定实体类型,MyBatis-Plus 自动关联实体与数据库表(默认按驼峰转下划线规则映射表名)
注解 @Param("countMap"):
- 参数绑定 :将 Java 参数
countMap映射到 XML SQL 中的同名变量,避免动态 SQL 解析错误。 - XML 引用 :在 XML 映射文件中通过
#{countMap.key}或${countMap.value}访问参数
ThumbMappper
java
public interface ThumbMapper extends BaseMapper<Thumb> {
}继承 BaseMapper<Thumb>:
-
泛型参数 :指定实体类型为
Thumb,MyBatis-Plus 自动关联该实体与数据库表(默认按驼峰转下划线规则映射表名,如Thumb→thumb表)。 -
功能扩展 :继承后自动获得以下核心方法(部分示例):
javaint insert(Thumb entity); // 插入一条记录 int deleteById(Serializable id); // 按主键删除 Thumb selectById(Serializable id); // 按主键查询 List<Thumb> selectList(Wrapper<Thumb> queryWrapper); // 条件查询列表动态代理机制 :
MyBatis-Plus 通过 JDK 动态代理 生成
ThumbMapper的代理类,拦截接口方法调用并关联到预定义的 CRUD 操作。 -
示例 :调用
thumbMapper.selectById(1L)会触发代理逻辑,生成SELECT * FROM thumb WHERE id = 1并执行。
UserMapper
java
package com.yuyuan.thumb.mapper;
import com.yuyuan.thumb.model.entity.User;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
/**
* @author pine
*/
public interface UserMapper extends BaseMapper<User> {
}.model
.dto.thumb.DoThumbRequest
执行点赞操作的请求对象。
model.dto.thumb 路径表明这是一个 数据传输对象 (DTO) ,专门用于点赞业务模块(thumb)的请求参数封装。
java
package com.yuyuan.thumb.model.dto.thumb;
import lombok.Data;
@Data
public class DoThumbRequest {
// 标识被点赞的博客 ID,用于服务端处理点赞逻辑
private Long blogId;
}- 引入 Lombok 的
@Data注解。 - Lombok 功能 :
- 自动生成
getter、setter、toString()、equals()和hashCode()方法,避免手动编写样板代码。 - 编译时通过操作抽象语法树(AST)修改字节码,保持源码简洁
- 自动生成
.entity.Blog
java
/**
*
* @TableName blog
*/
@TableName(value ="blog")
@Data
public class Blog {
/**
*
*/
@TableId(type = IdType.ASSIGN_ID)
private Long id;
private Long userId;
/**
* 标题
*/
private String title;
/**
* 封面
*/
private String coverImg;
/**
* 内容
*/
private String content;
/**
* 点赞数
*/
private Integer thumbCount;
/**
* 创建时间
*/
private Date createTime;
/**
* 更新时间
*/
private Date updateTime;
}@TableName("blog"):
- 作用 :显式声明实体类对应的数据库表名为
blog(默认类名小写为blog,但显式声明更安全)。 - 适用场景 :当表名与类名不一致时(如
Blog类对应tb_blog表),需通过value属性指定
@Data:
- 功能 :Lombok 自动生成
getThumbCount()、setCreateTime()等方法,并覆盖toString()、equals()等
@TableId:
- 作用 :标识主键字段,并指定主键生成策略。
-
type = IdType.ASSIGN_ID :- 策略说明 :使用分布式 ID 生成算法(如雪花算法)自动生成主键值。
- 适用场景 :适用于分布式系统,避免主键冲突(相比自增主键
AUTO更灵活)。 - 在分布式系统中,传统自增主键(如 MySQL 的
AUTO_INCREMENT)会导致分库分表时主键冲突,而 UUID 虽然唯一但无序且存储效率低 - 时间戳 + 机器 ID + 序列号
- 默认映射 :若数据库主键列名为
id,则无需通过value属性指定字段名 - 隐式映射规则 :
- MyBatis-Plus 默认将驼峰命名的字段(如
coverImg)映射为下划线格式的列名(如cover_img)。 - 若字段名与列名一致(如
title),无需使用@TableField注解
- MyBatis-Plus 默认将驼峰命名的字段(如
.entity.Thumb
java
/**
*
* @TableName thumb
*/
@TableName(value ="thumb")
@Data
public class Thumb {
/**
*
*/
@TableId(type = IdType.ASSIGN_ID)
private Long id;
/**
*
*/
private Long userId;
/**
*
*/
private Long blogId;
/**
* 创建时间
*/
private Date createTime;
}.entity.User
java
/**
*
* @TableName user
*/
@TableName(value ="user")
@Data
public class User implements Serializable {
/**
*
*/
@TableId(type = IdType.ASSIGN_ID)
private Long id;
/**
*
*/
private String username;
}implements Serializable :
使 User 对象支持序列化,确保其可在网络传输、缓存(如 Redis)或持久化存储时保持状态一致性
.enums.LuaStatusEnum
java
/**
* lua 脚本执行结果类型
*
*/
@Getter
public enum LuaStatusEnum {
// 成功
SUCCESS(1L),
// 失败
FAIL(-1L),
;
private final long value;
LuaStatusEnum(long value) {
this.value = value;
}
}此枚举用于表示 Lua 脚本的执行结果类型。
@Getter 自动生成所有字段的 getter 方法
.enums.ThumbTypeEnum
java
package com.yuyuan.thumb.model.enums;
import lombok.Getter;
/**
* 点赞类型
*
*/
@Getter
public enum ThumbTypeEnum {
// 点赞
INCR(1),
// 取消点赞
DECR(-1),
// 不发生改变
NON(0),
;
private final int value;
ThumbTypeEnum(int value) {
this.value = value;
}
}.vo.BlogVO
java
package com.yuyuan.thumb.model.vo;
import lombok.Data;
import java.util.Date;
/**
*
* @TableName blog
*/
@Data
public class BlogVO {
/**
*
*/
private Long id;
/**
* 标题
*/
private String title;
/**
* 封面
*/
private String coverImg;
/**
* 内容
*/
private String content;
/**
* 点赞数
*/
private Integer thumbCount;
/**
* 创建时间
*/
private Date createTime;
/**
* 是否已点赞
*/
private Boolean hasThumb;
}model.vo 表示这是一个 视图对象(View Object) ,用于封装前端展示数据,与 model.entity.Blog(数据库实体类)分层隔离。
相比 Blog.java,增加了 hasThumb 字段表示"是否已点赞" ,这是视图层特有的状态信息,无需持久化到数据库。hasThumb 是典型 业务逻辑字段,通过后端计算当前用户是否点赞,动态注入 VO 中。
- Blog.java :数据库交互的实体,关注 数据持久化 (如 ORM 注解、全字段映射)。
- BlogVO :前后端交互的载体,关注 业务展示(如状态字段、数据脱敏)
.service
BlogService
java
package com.yuyuan.thumb.service;
import com.yuyuan.thumb.model.entity.Blog;
import com.baomidou.mybatisplus.extension.service.IService;
import com.yuyuan.thumb.model.entity.User;
import com.yuyuan.thumb.model.vo.BlogVO;
import jakarta.servlet.http.HttpServletRequest;
import java.util.List;
public interface BlogService extends IService<Blog> {
// 根据 blogId 查询博客详情,并转换为包含业务状态的 BlogVO 对象
// request:用于获取当前用户信息(如通过 request.getSession() 获取登录用户 ID)
BlogVO getBlogVOById(long blogId, HttpServletRequest request);
// 根据 loginUser 的 ID,查询该用户是否对当前博客点赞、收藏等。
BlogVO getBlogVO(Blog blog, User loginUser);
// 批量将 Blog 实体列表转换为 BlogVO 列表
// 批量查询所有博客的点赞状态
List<BlogVO> getBlogVOList(List<Blog> blogList, HttpServletRequest request);
}继承 IService<Blog> :
继承 MyBatis-Plus 的通用服务接口,自动获得 20+ 个 CRUD 方法 (MyBatis-Plus 提供的通用 CRUD 接口,如 save(), update() , getById(), list() 等),无需手动实现基础操作
Impl:
java
@Service
public class BlogServiceImpl extends ServiceImpl<BlogMapper, Blog>
implements BlogService {
@Resource
private UserService userService;
@Resource
@Lazy // 延迟加载避免循环依赖
private ThumbService thumbService;
@Resource
private RedisTemplate<String, Object> redisTemplate;
// 通过 getById() 查询数据库中的 Blog 实体
@Override
public BlogVO getBlogVOById(long blogId, HttpServletRequest request) {
Blog blog = this.getById(blogId); // 调用 MyBatis-Plus 的 getById 方法
User loginUser = userService.getLoginUser(request); // 获取当前登录用户
return this.getBlogVO(blog, loginUser); // 转换实体为 VO
}
// 实体转视图对象
@Override
public BlogVO getBlogVO(Blog blog, User loginUser) {
BlogVO blogVO = new BlogVO();
BeanUtil.copyProperties(blog, blogVO); // 将 Blog 实体属性复制到 BlogVO,要求字段名一致
if (loginUser != null) {
// 查询用户是否点赞该博客
Boolean exist = thumbService.hasThumb(blog.getId(), loginUser.getId());
// 通过 ThumbService 查询用户点赞记录,设置 hasThumb 字段
blogVO.setHasThumb(exist);
}
return blogVO;
}
@Override
public List<BlogVO> getBlogVOList(List<Blog> blogList, HttpServletRequest request) {
User loginUser = userService.getLoginUser(request);
// 存储博客 ID 与用户是否点赞的映射关系(Key: 博客 ID,Value: 是否点赞)
Map<Long, Boolean> blogIdHasThumbMap = new HashMap<>();
if (ObjUtil.isNotEmpty(loginUser)) {
// 使用 stream().map() 将 Blog 列表转换为博客 ID 字符串列表,便于 Redis 查询
List<Object> blogIdList = blogList.stream().map(blog -> blog.getId().toString()).collect(Collectors.toList());
// 通过 RedisKeyUtil 生成用户点赞记录的 Hash 键
// 批量查询 Redis:通过 multiGet 一次性获取所有博客的点赞状态,减少网络开销(对比循环单次查询)。
List<Object> thumbList = redisTemplate.opsForHash().multiGet(RedisKeyUtil.getUserThumbKey(loginUser.getId()), blogIdList);
for (int i = 0; i < thumbList.size(); i++) {
if (thumbList.get(i) == null) {
continue;
}
blogIdHasThumbMap.put(Long.valueOf(blogIdList.get(i).toString()), true);
}
}
return blogList.stream()
.map(blog -> {
// 使用 BeanUtil.copyProperties 复制 Blog 属性到 BlogVO(需字段名一致)
BlogVO blogVO = BeanUtil.copyProperties(blog, BlogVO.class);
// 从 blogIdHasThumbMap 获取当前博客的点赞状态
blogVO.setHasThumb(blogIdHasThumbMap.get(blog.getId()));
return blogVO;
})
.toList(); //.toList() 代替 .collect(Collectors.toList()),返回不可变列表(Java 16+ 支持)
}
}@Lazy:解决 ThumbService 与 BlogService 的循环依赖问题。在我们的代码中,ThumbService中需要注入BlogService,反之BlogService中也要注入ThumbService。
三级缓存仅适用于字段/Setter 注入 ,对构造器注入无效。此时需借助 @Lazy 生成代理对象,避免直接触发初始化
- 当
@Lazy修饰一个 Bean 的依赖时,Spring 不会在启动时立即初始化该 Bean,而是创建一个代理对象 占位。 - Spring 先初始化
BlogService,注入ThumbService的代理对象。 - 当
ThumbService需要注入BlogService时,由于BlogService已存在(尽管可能未完全初始化),依赖关系得以满足 ThumbService完成初始化后,代理对象会在实际调用时委托给真实实例
ThumbService
java
public interface ThumbService extends IService<Thumb> {
// 处理用户点赞请求
Boolean doThumb(DoThumbRequest doThumbRequest, HttpServletRequest request);
// 处理用户取消点赞请求,逻辑与 doThumb 对称
Boolean undoThumb(DoThumbRequest doThumbRequest, HttpServletRequest request);
// 查询指定用户(一般是目前的已登录用户)是否对某篇博客点赞
Boolean hasThumb(Long blogId, Long userId);
}- Impl(普通实现)
java
@Service("thumbServiceLocalCache") // 自定义Bean名称,支持多实现类按名称注入
@Slf4j // Lombok日志注解
@RequiredArgsConstructor // 自动生成final字段的构造函数
public class ThumbServiceImpl extends ServiceImpl<ThumbMapper, Thumb>
implements ThumbService {
private final UserService userService; // 用户服务
private final BlogService blogService; // 博客服务
private final TransactionTemplate transactionTemplate; // 编程式事务模板
private final RedisTemplate<String, Object> redisTemplate; // Redis操作模板
private final CacheManager cacheManager; // 自定义缓存管理器(封装多级缓存)
}@Service("thumbServiceLocalCache"):指定 Bean 名称,便于其他组件按名称注入(如 A/B 测试不同实现)
点赞逻辑
java
@Override
public Boolean doThumb(DoThumbRequest request, HttpServletRequest httpRequest) {
// 参数校验
if (request == null || request.getBlogId() == null) {
throw new RuntimeException("参数错误");
}
User loginUser = userService.getLoginUser(httpRequest); // 获取当前用户
// 用户级锁(防止同一用户并发重复点赞)
synchronized (loginUser.getId().toString().intern()) {
// 编程式事务模板执行
return transactionTemplate.execute(status -> {
Long blogId = request.getBlogId();
// 检查是否已点赞
Boolean exists = this.hasThumb(blogId, loginUser.getId());
if (exists) {
throw new RuntimeException("用户已点赞");
}
// 更新博客点赞数(MyBatis-Plus的Lambda更新)
boolean updateBlog = blogService.lambdaUpdate()
.eq(Blog::getId, blogId)
.setSql("thumbCount = thumbCount + 1")
.update();
// 插入点赞记录
Thumb thumb = new Thumb();
thumb.setUserId(loginUser.getId());
thumb.setBlogId(blogId);
boolean saveThumb = this.save(thumb);
// 事务性操作:数据库更新与缓存更新
if (updateBlog && saveThumb) {
String hashKey = ThumbConstant.USER_THUMB_KEY_PREFIX + loginUser.getId();
String fieldKey = blogId.toString();
Long thumbId = thumb.getId();
// hashkey:fieldKey -> thumbId
// 更新Redis缓存
redisTemplate.opsForHash().put(hashKey, fieldKey, thumbId);
// 更新本地缓存(Caffeine)
cacheManager.putIfPresent(hashKey, fieldKey, thumbId);
}
return updateBlog && saveThumb; // 事务提交
});
}
}取消点赞
java
@Override
public Boolean undoThumb(DoThumbRequest request, HttpServletRequest httpRequest) {
// 参数校验(同上)
User loginUser = userService.getLoginUser(httpRequest);
synchronized (loginUser.getId().toString().intern()) {
return transactionTemplate.execute(status -> {
Long blogId = request.getBlogId();
// 从缓存(caffeine + redis)获取点赞记录ID
Object thumbIdObj = cacheManager.get(
ThumbConstant.USER_THUMB_KEY_PREFIX + loginUser.getId(),
blogId.toString()
);
if (thumbIdObj == null || thumbIdObj.equals(ThumbConstant.UN_THUMB_CONSTANT)) {
throw new RuntimeException("用户未点赞");
}
// 更新博客点赞数
boolean updateBlog = blogService.lambdaUpdate()
.eq(Blog::getId, blogId)
.setSql("thumbCount = thumbCount - 1")
.update();
// 删除点赞记录
boolean deleteThumb = this.removeById((Long) thumbIdObj);
if (updateBlog && deleteThumb) {
String hashKey = ThumbConstant.USER_THUMB_KEY_PREFIX + loginUser.getId();
String fieldKey = blogId.toString();
// 删除Redis记录
redisTemplate.opsForHash().delete(hashKey, fieldKey);
// 标记本地缓存为未点赞状态(避免缓存穿透)
cacheManager.putIfPresent(hashKey, fieldKey, ThumbConstant.UN_THUMB_CONSTANT);
}
return updateBlog && deleteThumb;
});
}
}检查点赞状态
java
@Override
public Boolean hasThumb(Long blogId, Long userId) {
// 先查询本地缓存(Caffeine),未命中则查 Redis
Object thumbIdObj = cacheManager.get(
ThumbConstant.USER_THUMB_KEY_PREFIX + userId,
blogId.toString()
);
// 缓存未命中或标记为未点赞时返回false
return thumbIdObj != null &&
!thumbIdObj.equals(ThumbConstant.UN_THUMB_CONSTANT);
}- Redis临时点赞记录 + 定时任务持久化实现
java
@Service("thumbServiceRedis") // 通过Bean名称区分不同实现(与本地缓存版本区分)
@Slf4j
@RequiredArgsConstructor // Lombok自动生成构造器,注入final修饰的依赖
public class ThumbServiceRedisImpl extends ServiceImpl<ThumbMapper, Thumb>
implements ThumbService {
private final UserService userService; // 用户服务(用于获取登录用户)
private final RedisTemplate<String, Object> redisTemplate; // Redis操作模板
}点赞逻辑
java
@Override
public Boolean doThumb(DoThumbRequest request, HttpServletRequest httpRequest) {
// 参数校验
if (request == null || request.getBlogId() == null) {
throw new RuntimeException("参数错误");
}
User loginUser = userService.getLoginUser(httpRequest); // 获取当前用户
Long blogId = request.getBlogId();
// 生成时间片(如"11:20:20")
String timeSlice = getTimeSlice();
// 构造Redis键:临时点赞记录 & 用户点赞记录
String tempThumbKey = RedisKeyUtil.getTempThumbKey(timeSlice);
String userThumbKey = RedisKeyUtil.getUserThumbKey(loginUser.getId());
// 执行Lua脚本(原子操作)
long result = redisTemplate.execute(
RedisLuaScriptConstant.THUMB_SCRIPT, // 预加载的Lua脚本
Arrays.asList(tempThumbKey, userThumbKey), // KEYS参数
loginUser.getId(), blogId // ARGV参数
);
// 处理结果
if (result == LuaStatusEnum.FAIL.getValue()) {
throw new RuntimeException("用户已点赞");
}
return result == LuaStatusEnum.SUCCESS.getValue();
}取消点赞
java
@Override
public Boolean undoThumb(DoThumbRequest request, HttpServletRequest httpRequest) {
// 参数校验(同上)
User loginUser = userService.getLoginUser(httpRequest);
Long blogId = request.getBlogId();
// 构造Redis键(同上)
String timeSlice = getTimeSlice();
String tempThumbKey = RedisKeyUtil.getTempThumbKey(timeSlice);
String userThumbKey = RedisKeyUtil.getUserThumbKey(loginUser.getId());
// 执行取消点赞的Lua脚本
long result = redisTemplate.execute(
RedisLuaScriptConstant.UNTHUMB_SCRIPT, // 反向操作脚本
Arrays.asList(tempThumbKey, userThumbKey), // KEYS参数
loginUser.getId(), blogId // ARGV参数
);
// 处理结果
if (result == LuaStatusEnum.FAIL.getValue()) {
throw new RuntimeException("用户未点赞");
}
return result == LuaStatusEnum.SUCCESS.getValue();
}时间片生成
java
private String getTimeSlice() {
DateTime nowDate = DateUtil.date();
// 计算当前时间前最近的10秒整数(如23秒→20秒)
return DateUtil.format(nowDate, "HH:mm:") + (DateUtil.second(nowDate) / 10) * 10;
}检测点赞状态
java
@Override
public Boolean hasThumb(Long blogId, Long userId) {
// 检查指定 Redis Hash 的键(Key)下是否存在某个字段(Field)
// 直接查询用户点赞记录(Redis Hash)的thumb:userId(Key)中是否存在该博客ID(field)
return redisTemplate.opsForHash().hasKey(
RedisKeyUtil.getUserThumbKey(userId),
blogId.toString()
);
}- Pulsar消息队列异步处理点赞事件
java
@Service("thumbService") // 声明为Spring服务层组件,bean名称为thumbService
@Slf4j // 启用Lombok日志功能,自动生成Logger实例
@RequiredArgsConstructor // Lombok生成包含final字段的构造方法
public class ThumbServiceMQImpl extends ServiceImpl<ThumbMapper, Thumb>
implements ThumbService { // 遵循服务层实现规范
// 通过构造器注入依赖
private final UserService userService;
private final RedisTemplate<String, Object> redisTemplate;
private final PulsarTemplate<ThumbEvent> pulsarTemplate;点赞逻辑
java
/**
* 执行点赞操作
* @param doThumbRequest 点赞请求DTO
* @param request HTTP请求对象
* @return 操作结果
*/
@Override
public Boolean doThumb(DoThumbRequest doThumbRequest, HttpServletRequest request) {
// 参数校验(第34-36行)
if (doThumbRequest == null || doThumbRequest.getBlogId() == null) {
throw new RuntimeException("参数错误"); // 抛出运行时异常
}
// 获取登录用户(第38行)
User loginUser = userService.getLoginUser(request); // 调用用户服务获取当前用户
Long loginUserId = loginUser.getId(); // 提取用户ID
Long blogId = doThumbRequest.getBlogId(); // 提取博客ID
// 生成Redis键(第41行)
String userThumbKey = RedisKeyUtil.getUserThumbKey(loginUserId); // 格式如:thumb:123
// 执行Lua脚本(第43-47行)
long result = redisTemplate.execute(
RedisLuaScriptConstant.THUMB_SCRIPT_MQ, // 预定义的Lua脚本
List.of(userThumbKey), // 键列表(这里只有一个键)
blogId // 参数:博客ID
);
// 处理Lua脚本返回结果(第49-51行)
if (LuaStatusEnum.FAIL.getValue() == result) { // 判断是否操作失败
throw new RuntimeException("用户已点赞"); // 已点赞则抛出异常
}
// 构建点赞事件(第53-57行)
ThumbEvent thumbEvent = ThumbEvent.builder()
.blogId(blogId) // 设置博客ID
.userId(loginUserId) // 设置用户ID
.type(ThumbEvent.EventType.INCR) // 事件类型为增加
.eventTime(LocalDateTime.now()) // 记录事件时间
.build();
// 异步发送消息(第59-64行)
pulsarTemplate.sendAsync("thumb-topic", thumbEvent) // 发送到指定主题
.exceptionally(ex -> { // 异常回调处理
// 补偿操作:删除Redis中的点赞记录
redisTemplate.opsForHash().delete(userThumbKey, blogId.toString(), true);
log.error("点赞事件发送失败: userId={}, blogId={}", loginUserId, blogId, ex);
return null;
});
return true; // 返回操作成功
}取消点赞
java
/**
* 取消点赞操作(结构与点赞方法对称)
*/
@Override
public Boolean undoThumb(DoThumbRequest doThumbRequest, HttpServletRequest request) {
// ...(参数校验与点赞方法相同)...
// 执行取消点赞的Lua脚本
long result = redisTemplate.execute(
RedisLuaScriptConstant.UNTHUMB_SCRIPT_MQ, // 不同的Lua脚本
List.of(userThumbKey),
blogId
);
// ...(结果处理与点赞方法类似)...
// 构建取消点赞事件
ThumbEvent thumbEvent = ThumbEvent.builder()
.type(ThumbEvent.EventType.DECR) // 事件类型为减少
// ...其他字段相同...
.build();
// 异步发送消息的补偿逻辑不同
pulsarTemplate.sendAsync(...).exceptionally(ex -> {
redisTemplate.opsForHash().put(...); // 补偿操作:恢复Redis记录
// ...日志记录...
});
return true;
}检查登录用户是否已对该博客点赞
java
/**
* 检查是否已点赞
* @param blogId 博客ID
* @param userId 用户ID
* @return 是否已点赞
*/
@Override
public Boolean hasThumb(Long blogId, Long userId) {
// 直接查询Redis Hash结构
return redisTemplate.opsForHash()
.hasKey(RedisKeyUtil.getUserThumbKey(userId), blogId.toString());
}.util
RedisKeyUtil
java
package com.yuyuan.thumb.util;
import com.yuyuan.thumb.constant.ThumbConstant;
public class RedisKeyUtil {
public static String getUserThumbKey(Long userId) {
// 生成用户点赞记录的Redis key
return ThumbConstant.USER_THUMB_KEY_PREFIX + userId;
}
/**
* 获取 临时点赞记录 key
*/
public static String getTempThumbKey(String time) {
// TEMP_THUMB_KEY_PREFIX定义为"temp:thumb:%s"的格式字符串,动态插入时间值
return ThumbConstant.TEMP_THUMB_KEY_PREFIX.formatted(time);
}
}