一、集成学习
1、含义
集成学习就是将多个基学习器进行组合,来实现比单一学习器显著优越的学习性能
2、代表
.bagging方法:典型的是随机森林
.boosting方法:典型的是Xgboost
.stacking方法:堆叠模型
3、应用
1、分类问题集成
2、回归问题集成
3、特征选取集成
4、Bagging之随机森林
随机森林:
1.什么是随机森林?
随机森林(Random Forest)是一种集成学习(Ensemble Learning) 算法,属于机器学习中的监督学习方法。它通过构建多个决策树并将它们的预测结果结合起来,以提高模型的准确性和稳定性。
2.随机森林的特点?
(1)数据采样随机
(2)特征选取随机
(3)森林
(4)基学习器为决策树
3.为什么使用随机森林?
使用随机森林的主要原因可以总结为它在准确性、稳定性和易用性方面的卓越表现
4、随机森林的优点
1.具有极高的准确率。
2.随机性的引入,使得随机森林的抗噪声能力很强。
3.随机性的引入,使得随机森林不容易过拟合。
4.能够处理很高维度的数据,不用做特征选择。
5.容易实现并行化计算。
5、随机森林缺点
1.当随机森林中的决策树个数很多时,训练时需要的空间和时间会较大。
2.随机森林模型还有许多不好解释的地方,有点算个黑盒模型。
5、随机森林相关参数
class sklearn.ensemble.RandomForestClassifier(n_estimators='warn' , criterion='gini' , max_depth=None , min_samples_split=2 , min_samples_leaf=1)
随机森林重要的一些参数:
1)n_estimators :(随机森林独有)
随机森林中决策树的个数。
在0.20版本中默认是10个决策树;
在0.22版本中默认是100个决策树;
2)criterion :(同决策树)
节点分割依据,默认为基尼系数。
可选【entropy:信息增益】
3)max_depth:(同决策树)【重要】
default=(None)设置决策树的最大深度,默认为None。
【(1)数据少或者特征少的时候,可以不用管这个参数,按照默认的不限制生长即可
(2)如果数据比较多特征也比较多的情况下,可以限制这个参数,范围在10~100之间比较好】
4)min_samples_split : (同决策树)【重要】
这个值限制了子树继续划分的条件,如果某节点的样本数少于设定值,则不会再继续分裂。默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则建议增大这个值。
5)min_samples_leaf :(同决策树)【重要】
这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
【叶是决策树的末端节点。 较小的叶子使模型更容易捕捉训练数据中的噪声。 一般来说,我更偏向于将最小叶子节点数目设置为大于50。在你自己的情况中,你应该尽量尝试多种叶子大小种类,以找到最优的那个。】
【比如,设定为50,此时,上一个节点(100个样本)进行分裂,分裂为两个节点,其中一个节点的样本数小于50个,那么这两个节点都会被剪枝】
6、案例
垃圾邮件的识别
通过网盘分享的文件:spambase.csv
链接: https://pan.baidu.com/s/1Kb7X4jsvQH91TGqzM3uDug 提取码: 6ksn
python
import pandas as pd
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x), horizontalalignment='center',
verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
datas = pd.read_csv("spambase.csv")
# 将变量与结果划分开
x = datas.iloc[:, :-1]
y = datas.iloc[:, -1]
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test =train_test_split(x,y, test_size=0.2, random_state=50)
from sklearn.ensemble import RandomForestClassifier
dtr=RandomForestClassifier(n_estimators=100,max_features=0.8,random_state=0)
dtr.fit(x_train, y_train)
"""
训练集混淆矩阵
"""
# 训练集预测值
train_predicted = dtr.predict(x_train)
from sklearn import metrics
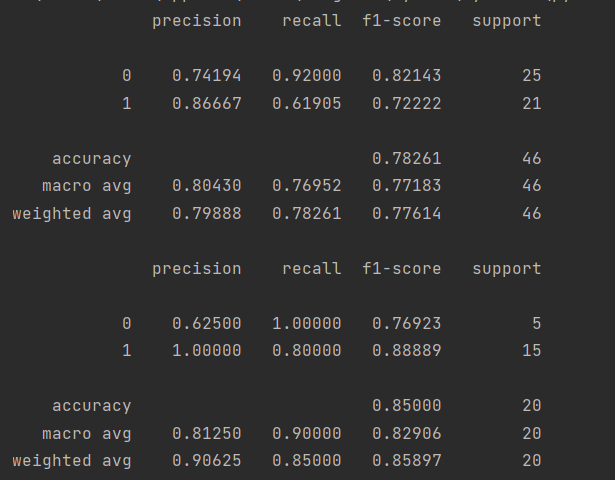
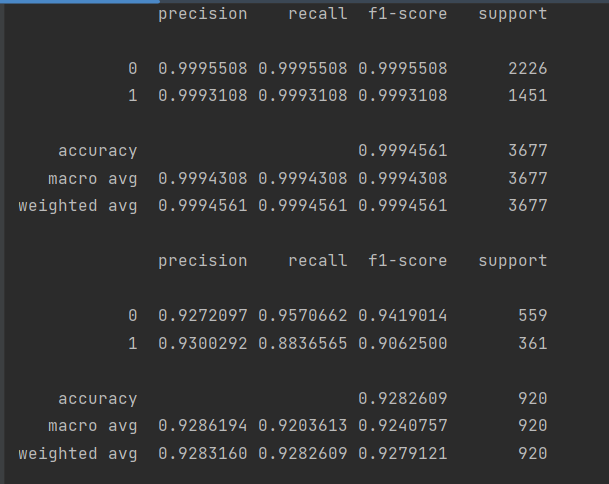
print(metrics.classification_report(y_train, train_predicted,digits=7))
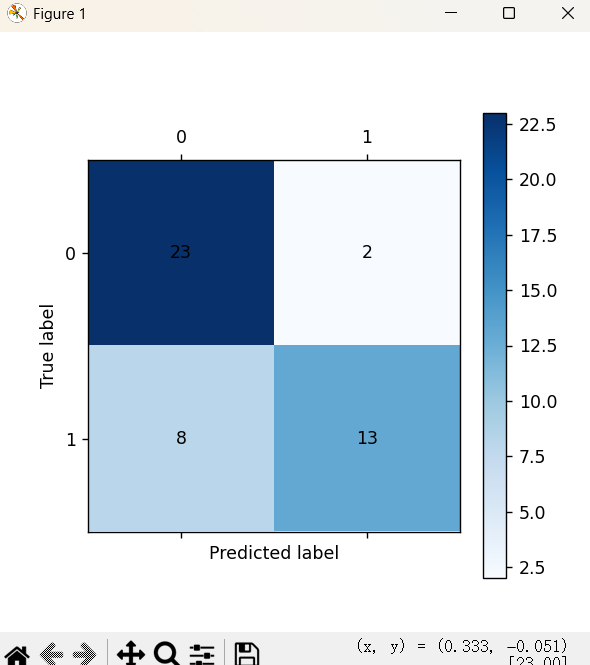
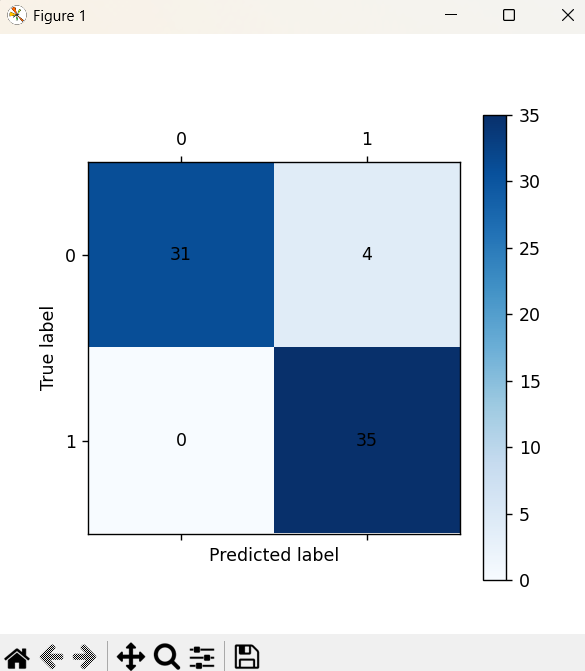
cm_plot(y_train, train_predicted).show()
"""
测试集混淆矩阵
"""
test_predicted = dtr.predict(x_test)
print(metrics.classification_report(y_test, test_predicted,digits=7))
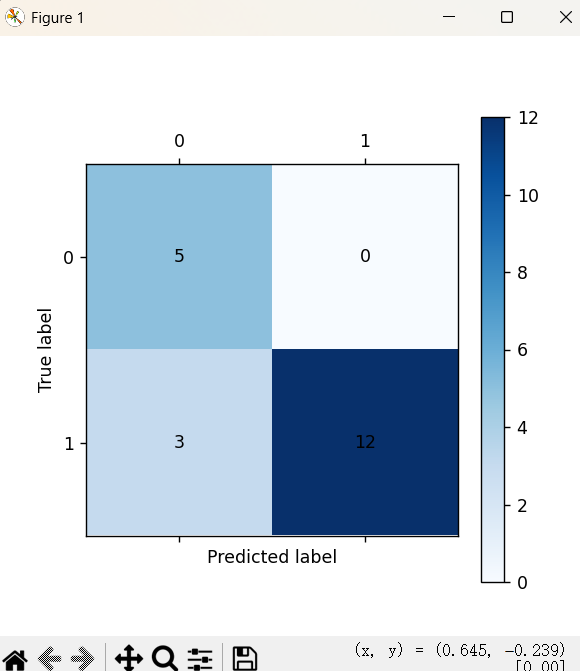
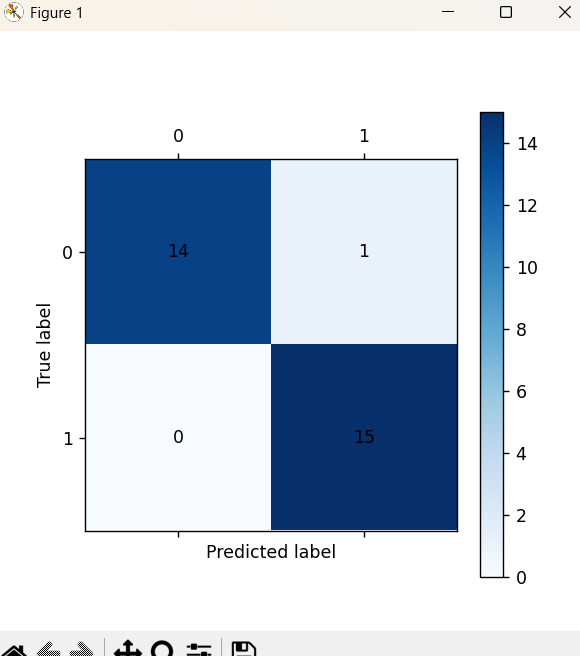
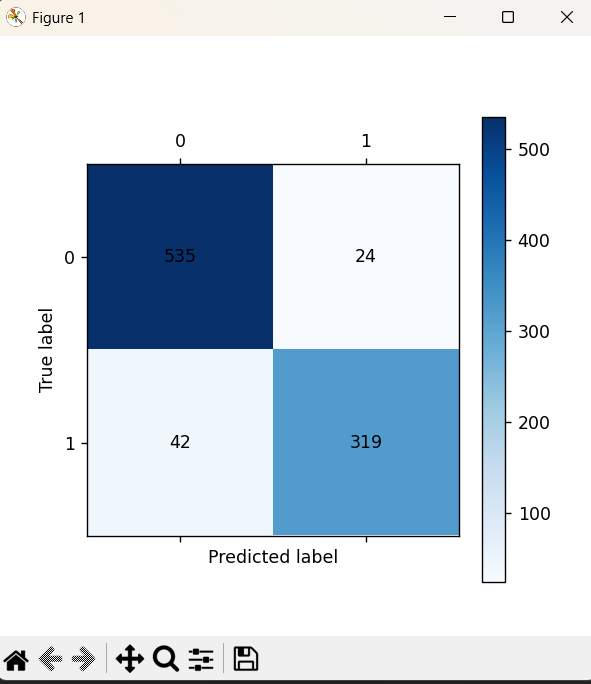
cm_plot(y_test, test_predicted).show()
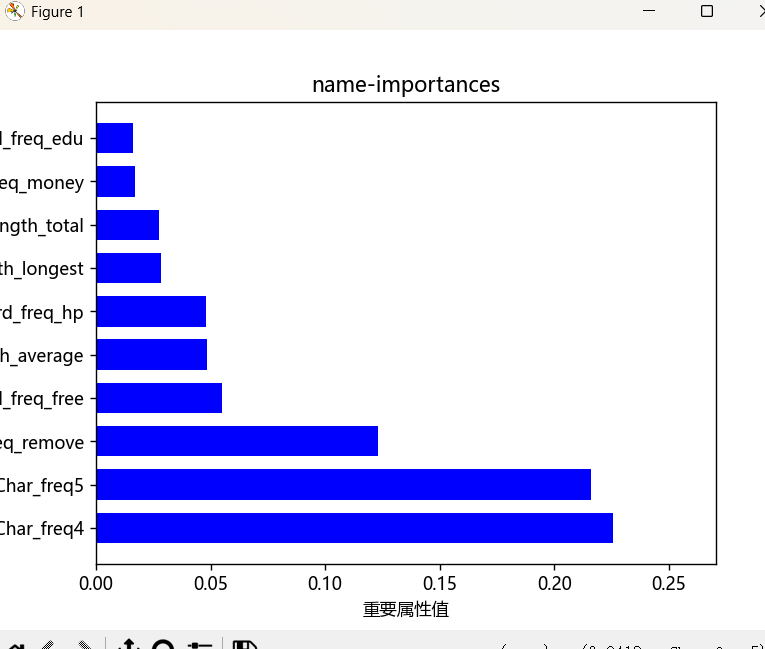
'''重要特征'''
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif']=['Microsoft YaHei']
mpl.rcParams['axes.unicode_minus']=False
importances=dtr.feature_importances_#这个属性保存了模型中特征的重要性
im=pd.DataFrame(importances,columns=["importances"])
name=x.columns
# 2. 创建包含特征名和重要性值的DataFrame
a=pd.DataFrame({'name':name,'importances':importances
})
# 3. 按重要性降序排序
feature_importance_sorted = a.sort_values(
by='importances',
ascending=False
).reset_index(drop=True)
# 4、取出最大的10个特征
max_10 = feature_importance_sorted.head(10)
# 5、进行可视化处理
fig=plt.figure()
plt.barh(max_10['name'], max_10['importances'],
color='b', height=0.7)
a=max_10['importances'].max()
plt.xlim(0,a*1.2)
plt.xlabel('重要属性值')
plt.ylabel('特征名称')
plt.title('name-importances')
plt.show()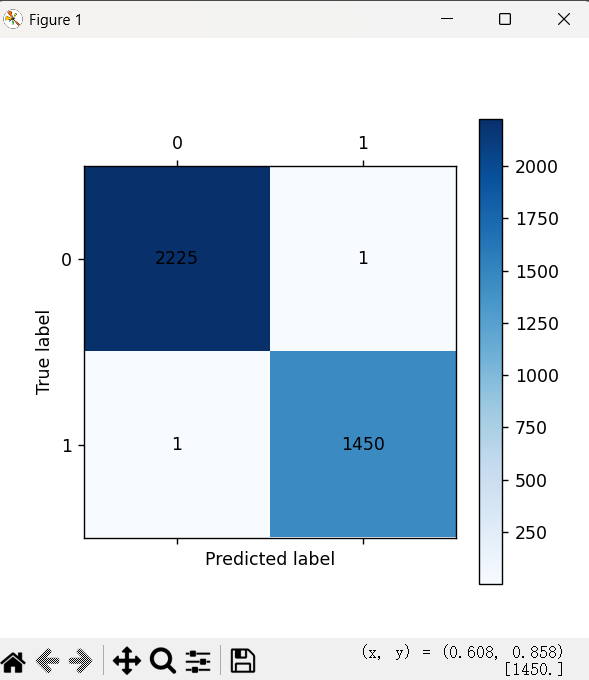
二、贝叶斯算法
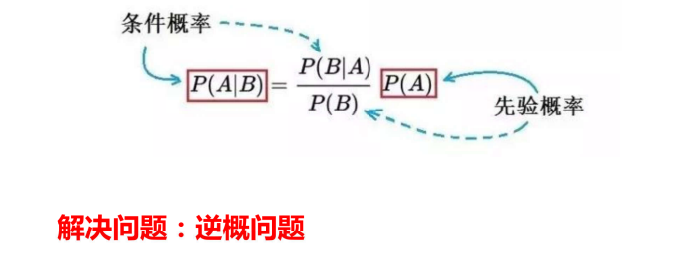
1、核心
思考方式的转变,"逆概"问题
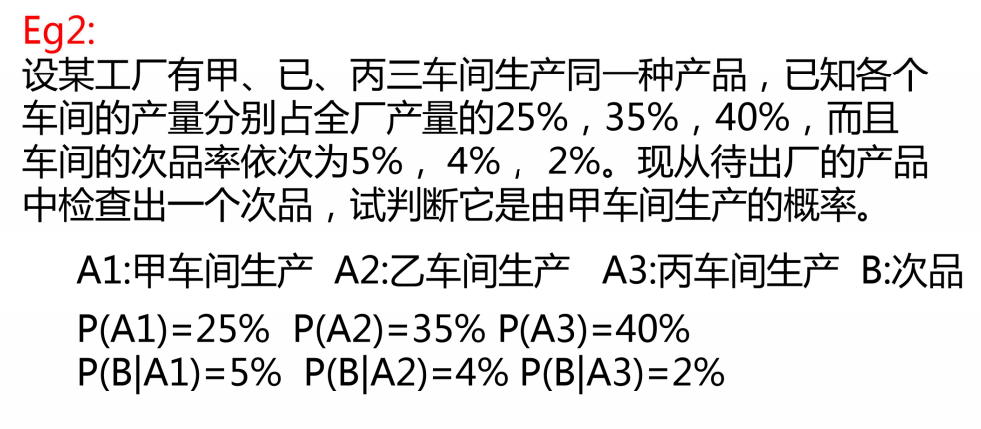
2、定理






3、贝叶斯算法相关参数
贝叶斯分类器的代码使用: 朴素贝叶斯算法,中文处理
class sklearn.naive_bayes.MultinomialNB (alpha=1.0 , fit_prior=True , class_prior=None )
参数:
1) MultinomialNB:多项式分布的朴素贝叶斯。
2)alpha: 控制模型拟合时的平滑度.
定义:alpha是一个浮点数,表示添加剂(拉普拉斯/Lidstone)平滑参数。它控制了模型估计概率中的平滑程度。
作用:平滑是一种防止过拟合的技术,特别是在处理稀疏数据集或未出现在训练集中的特征时。当alpha设置为0时,表示不进行平滑;alpha设置为1时,称为Laplace平滑;当0<alpha<1时,称为Lidstone平滑。
影响:alpha值的大小会影响模型的复杂度。如果alpha值过大,模型估计出来的概率会减少,可能导致分类器更加稳定但准确率降低;反之,如果alpha值被设置的过低,会导致准确率提升,但可能会引起模型的过拟合问题。
3)fit_prior: 是否去学习类的先验概率。
当fit_prior设置为True时,模型会根据训练数据集计算出每个类的先验概率。如果训练数据集中某个类的样本数量较少,计算出的先验概率可能非常小,这可能导致该类样本在分类时被忽略,从而影响模型的分类效果。
使用建议:在有样本不均衡的情况下,建议谨慎使用fit_prior参数,以避免分类效果变差。
4)class_prior: 各个类别的先验概率,
如果没有指定,则模型会根据数据自动学习, 每个类别的先验概率相同,等于类标记总个数N分之一。
4、案例
python
import pandas as pd
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x), horizontalalignment='center',
verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
datas=pd.read_excel('鸢尾花训练数据.xlsx')
x=datas.iloc[:,:-1]
y=datas.iloc[:,-1]
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=0)
from sklearn.naive_bayes import MultinomialNB
ml=MultinomialNB(alpha=1.0)
ml.fit(x_train,y_train)
train_predict=ml.predict(x_train)
from sklearn import metrics
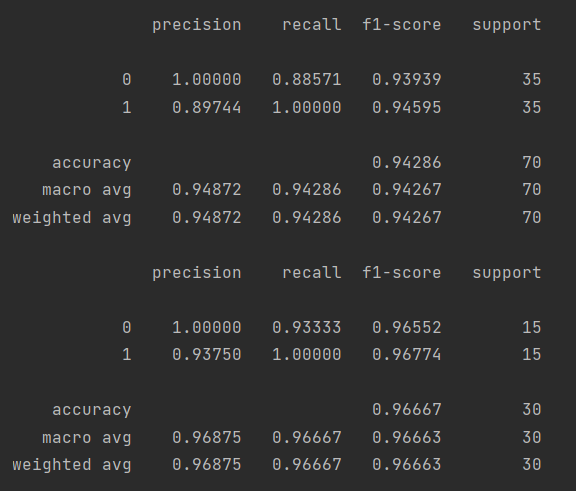
print(metrics.classification_report(y_train,train_predict,digits=5))
cm_plot(y_train,train_predict).show()
test_predict=ml.predict(x_test)
print(metrics.classification_report(y_test,test_predict,digits=5))
cm_plot(y_test,test_predict).show()
data=pd.read_csv('../集成学习之随机森林/iris.csv', header=None)
x1=data.iloc[:,:-1]
y1=data.iloc[:,-1]
from sklearn.model_selection import train_test_split
x1_train,x1_test,y1_train,y1_test=train_test_split(x1,y1,test_size=0.3,random_state=0)
from sklearn.naive_bayes import MultinomialNB
ml1=MultinomialNB(alpha=1)
ml1.fit(x1_train,y1_train)
from sklearn import metrics
train1_predict=ml1.predict(x1_train)
print(metrics.classification_report(y1_train,train1_predict,digits=5))
cm_plot(y1_train,train1_predict).show()
test1_predict=ml1.predict(x1_test)
print(metrics.classification_report(y1_test,test1_predict,digits=5))
cm_plot(y1_test,test1_predict).show()