本文是对RAG技术全栈指南的学习笔记, 未完待续, 持续更新. 如果感兴趣, 可以多多交流.
RAG 是什么?
引用 Langchain 官方文档对 RAG 技术的定义, Retrieval Augmented Generation(RAG) is a technique that enhances Large Model(LLMs) by providing them with relevant external knowledge.(RAG技术是一个通过检索为大模型提供精确外部知识来实现模型能力增强的技术范式) 它核心面向的问题是如何解决LLM一本正经胡说八道的问题, 即模型幻觉问题. 由于模型内部学习到的参数化知识是静态与有限的(训练语料库无论有多庞大, 都是有边界和时效性的),当对于一些不懂的领域问题强行进行回答时, LLM 就会开启胡编乱造的模式, 此时 LLM 空有一身强大的推理能力, 但由于缺乏数据或知识,导致 LLM 陷入巧妇难为无米之炊(有推理能力但缺少数据)的窘境. 此时则需要通过检索机制来实现对大模型的知识边界补偿, 将模型内在参数化的知识与来自外部知识库中非参数化知识进行融合, 从而实现大模型的上下文感知特性.
这也就是为什么在大部分资料中, 通常将 RAG 比喻成开卷考试的原因, RAG 为 LLM 配备了一个实时更新的知识库, 让其在答题之前先去查阅资料, 参考资料来作答, 而非仅仅依靠做题经验和记住的知识.
通常意义说, RAG 主要包含两个步骤("2-step RAG"):
- Retrieval: 检索, 理解用户意图, 从
外挂知识库中茫茫文档精确捕捞出关键的信息碎片, 实现上下文的感知(Context-Aware). - Generation: 生成, 在上下文感知的基础上, 基于大模型强大的推理生成能力, 将外部非参数知识和内部的逻辑常识(参数化知识)进行融合, 最终输出
更知情的答案(Informed Response), 让回答建立在一定的知识来源之上(grounded in your data), 从而减缓模型的幻觉问题.
在构建RAG 系统中, 遇到的核心壁垒同时也是其最大挑战主要在于两点:如何构建高质量的知识库,以及如何精准地找到关键信息。
通常引入 RAG 搭建 AI 应用,通常是为了解决两大核心痛点:
- 打破时空限制:增强知识的实时性,解决模型"胡说八道"的幻觉问题。
- 补偿知识边界 :注入私域数据,填补模型的认知空白,实现可信的引用溯源。
正因如此,输入数据的质量在很大程度上决定了系统回答质量的高低------"Garbage In, Garbage Out"(垃圾进,垃圾出)。想要大模型输出高质量的回答,就必须精心组装喂给它的上下文内容。尽管当下的 RAG 技术栈看似眼花缭乱,但万变不离其宗,这些系统工程优化方向始终围绕着三个核心命题展开: - 怎么高效地存(索引优化)
- 怎么精准地找(检索优化)
- 怎么让模型更好地去理解知识(上下文组装与对齐)
那我们接下来就看一看有那些技术.
RAG (Retrieval-Augmented Generation) 架构演进图
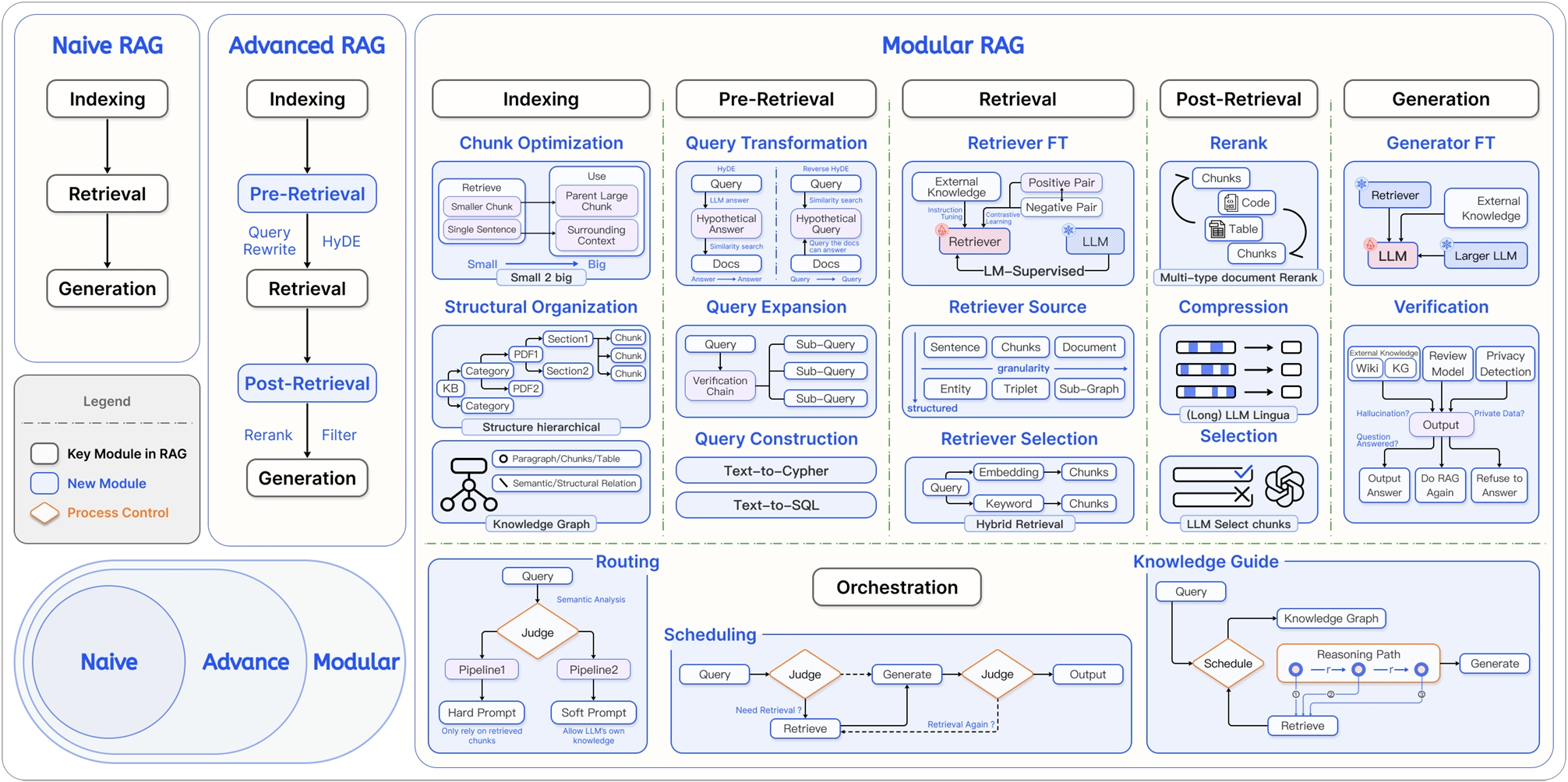
在上图中, RAG 的发展被分为了三个主要阶段,从简单逐渐演变的愈来愈复杂。
1. Naive RAG(朴素 RAG, 3阶段)
这是 RAG 最早期的形态,也就是之前讨论的"2-step RAG",流程非常直接线性, 组件也只有三个:
- Indexing(索引):把文档切片存进向量数据库。
- Retrieval(检索):用户问什么,直接去库里搜什么。
- Generation(生成) :把搜到的东西丢给 LLM 生成答案。
这种方式只能用于搭建系统的原型框架, 实现最最基础的流程, 但其回答效果难以保障, 可能会出现搜不到就瞎编的情况,也有可能搜到了也不一定相关。
2. Advanced RAG(进阶 RAG- 5 阶段)
在初级 RAG 系统的基础上, 针对检索组件, 增加了两个特定的环节, 检索前优化与检索后优化:
- Pre-Retrieval(检索前优化) :
- Query Rewrite/Transformation:不再直接用用户的原始 query去检索,而是对query语句(比如把用户含糊的问题改写得更清晰与具体)进行改写。
- HyDE:假设性文档嵌入,先让 LLM 生成一个"假答案", 相当于是用 LLM 对原始 query 进行理解和回答,用生成的假答案去检索真文档。
- Post-Retrieval(检索后优化) :
- Rerank(重排序):检索回来的前50个 相似的文档,用更精准的Reranker模型进行相关性重新打分,筛选最好的 Top 5。
- Filter(过滤):对检索的文档进行检查, 去掉重复的或低质量的文档。
3. Modular RAG(模块化 RAG, 5 阶段, 组件化)------ 图中最核心、最复杂的部分
相比与高级 RAG 呢, 我们可以明显看出, 在5 阶段 RAG 框架下, 每个阶段中, 内部的实现方式更加的组件化以及可插排化, 所谓的组件化, 就是针对一个问题比如如何构建索引如何
ModularRAG 是一个高度灵活、组件化的RAG架构,在 Advanced RAG 系统中的整个流程中的五大核心环节进行进一步的细化, 将每个模块内部的处理逻辑进行组件化, 从而实现可插拔可替换, 通过组件之间的组装实现带有自我修正/多路路由/混合搜索的高精度 RAG 系统。
1. Indexing(索引优化)
- Chunk Optimization:秉承"小块搜索,大块生成"的基础 RAG 思路, 不仅切小块,还要保留"父文档"的大上下文(Small-to-Big),或者按层级结构(Structural Organization)来切。
- Knowledge Graph:引入知识图谱,不仅存文本,还存实体之间的关系, 一般引入了知识图谱, 整个 RAG 系统的复杂度将会上升一个台阶。
B. Pre-Retrieval(检索前 - 查询处理)
- Query Transformation:包括 HyDE(假设回答)、Query Rewrite(重写)。
- Query Expansion:把一个问题拆解成多个子问题(Sub-Query)分别去搜。
- Query Construction:把自然语言转成 SQL 或 Cypher(图查询语言),用于查数据库或图谱。
C. Retrieval(检索优化)
- Retriever FT (Fine-tuning):微调检索模型,让它更懂你的业务数据。
- Hybrid Retrieval:混合检索,同时使用"全文检索"(BM25)和"向量检索"(Embedding), 混合检索,综合多种检索的结果。
D. Post-Retrieval(检索后处理)
- Rerank:重排序,RAG 的标配。
- Compression:上下文压缩(如 LLMLingua),把冗长的文档压缩成精华,节省 Token 并减少噪音。
- Selection:让 LLM 自己挑选最有用的片段。
E. Generation(生成优化)
- Generator FT:微调生成模型(LLM)本身。
- Verification:验证机制,检查生成的答案是不是在瞎编(Hallucination Detection),或者有没有泄露隐私。
4. Orchestration & Routing(编排与路由)
底部的部分展示了更高级的 Agentic RAG(代理式 RAG) 思想:
- Routing(路由):根据问题的不同,决定去查哪个库,或者用哪种检索策略。
- Scheduling(调度):动态决定"要不要查"、"查几次"。比如先生成,发现不够好,再回头去查(Self-Correction)。
一句话总结这张图:
这张图展示了 RAG 技术从**"简单的查库回答"进化为 "精密的知识加工流水线"的过程。现在的 RAG 系统不再是一个简单的脚本,而是一个包含意图识别、混合检索、多级精排、动态编排**的复杂智能系统。
动手实践:
3-step RAG: Naive RAG 系统的实现.
四步构建RAG 的 MVP 系统(Naive RAG 系统).
- PrepareStep : 数据加载与分块, 将准备好的知识库数据, 最简单的就是 markdown 文档集. 然后对文档进行分块, 目的是为了提升检索的精度,
小块检索, 大块生成. - Indexing Step: 文本向量化与索引构建, 文本向量化通过调用嵌入模型(通常是 Sentence EMbedding)将普通文本一段话/一个句子转换成一个向量, 并存入向量库中, 如 milvus.
- Retrieval Step: Query 检索, 最简单的方式, 直接将原生 query 文本转换成向量, 丢给向量库完成, 实现与策略优化, 使用全文搜索和向量搜索的混合检索方式提升文档召回的数量, 同时引入 Rerank机制和相似度阈值过滤机制对检索结果进行二次筛选, 若出现无结果的情况, 可进一步调用 web 搜索工具, 从网络中搜索搜索相关主题词, 确保知识上下文的召回.
- Generation Step: 基于上下文知识, 让大模型生成问题答案.
- RAGAS评估: 这一步对于构成 RAG 系统是不必要的, 我们在前四步已经完成了一个最小型的 RAG 系统了, 但这个最简单的RAG 系统的检索质量肯定是还有优化空间的. 如何评估一个RAG 系统的质量高低? 系统中影响检索质量的问题是什么? 如何找到后续最有收益的迭代方向?这些都是一个 RAG 系统长期维护中最需要去关注的问题. 此外, 用户不仅仅关注效果, 性能也是也是影响用户体验的重要因素. 当系统变得越来越庞大臃肿, 组件的交互越来越复杂, 就需要对系统进行剪枝, 在保证效果的前提下, 去掉一些不必要的步骤, 缩短上下文的长度, 实现系统性能的提升以及成本的优化.
那么我们进入实战环节, 以一个我参与的魔塔社区答疑 Agent 作为 demo 案例, 看如何搭建一个最最简单的 Naive RAG 应用程序.
魔塔社区答疑 Agent
这个答疑 Agent 本质就是一个 RAG 系统, 是我参加魔塔的社区智能答疑Agent开源挑战赛的一个作品( 比赛链接). 这个比赛的内容很简单, 基于魔塔平台的文档, 构建一个答疑机器人, 具体怎么实现以及数据来源全靠自己去发挥,同时官方也给了一些标准问答的示范案例, 这样后面加入 RAGAS 模块对模型回答效果进行评价时, 就无需自己再去构造一些评测集了.
现在的 RAG 系统虽然越来越复杂, 但其流程越来越标准化, 类似于做菜一样, 构建 RAG 系统也有明确的步骤与流程, 在这份RAG 指南中, 我也采用菜谱的方式来讲解如何构建一个完整的 NaiveRAG 系统.
菜品信息:
菜品名称:ModelScope 社区答疑 Agent(Naive RAG 版)
菜品类型:智能问答系统
预估难度:★(容易)
所需时间:
- 环境准备:30 分钟
- 数据准备:1 小时
- 系统构建:2 小时
- 效果评测:0.5 小时
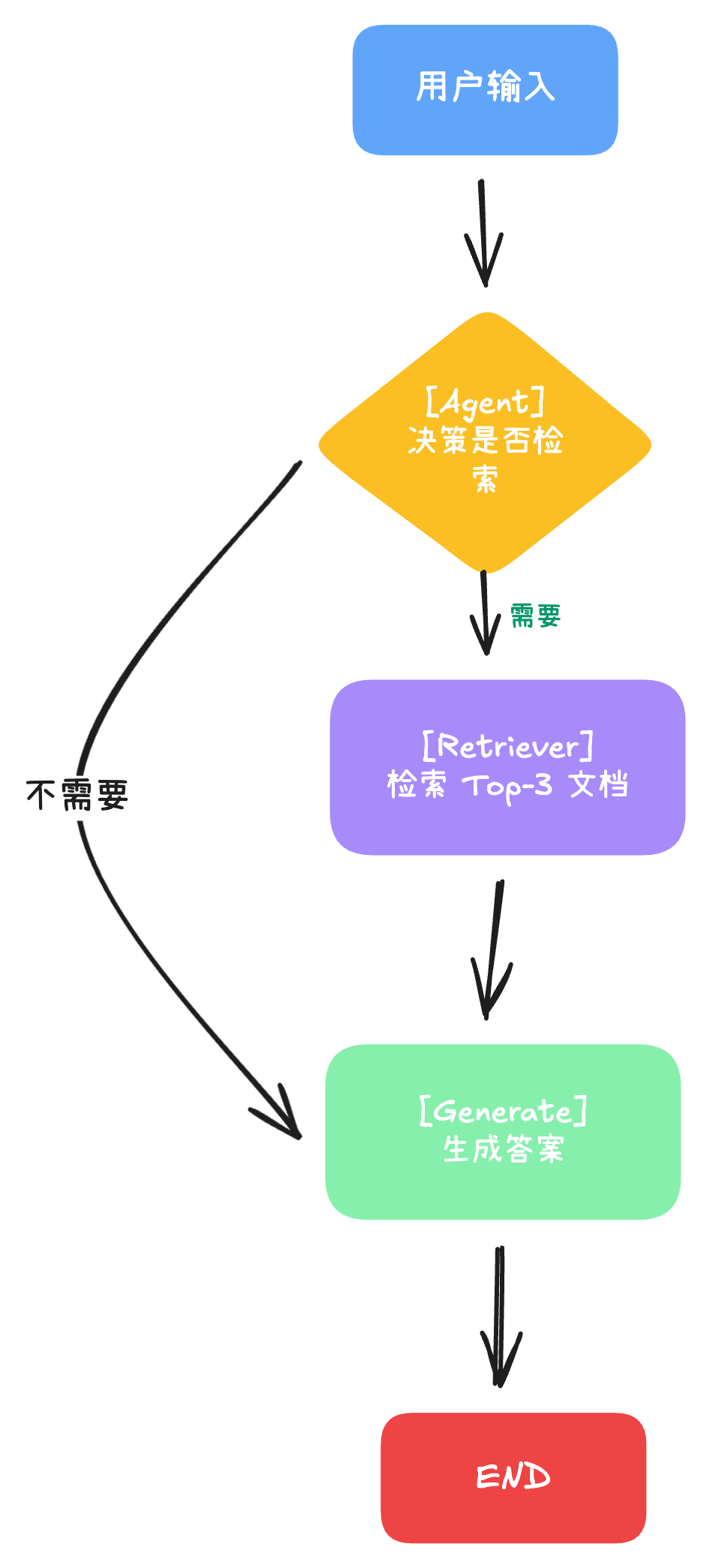
RAG 烹饪流程图
菜谱原料和工具
🥘 食材准备
| 原料名 | 规格 | 用量 | 说明 |
|---|---|---|---|
| Qwen3-8B | 8B 参数 LLM | 1 个 | 问答生成、问题改写、相关性评估 |
| text-embedding-v4 | 1024 维向量 | 1 个 | 文本向量化 |
| Milvus | 向量数据库 | 1 个 | 向量存储和检索 |
| Markdown 文档 | 知识库 | 354 份 | 原始数据 |
🔨 厨房设备(框架库)
| 调味料名 | 版本 | 用量 | 说明 |
|---|---|---|---|
langchain |
1.1.2 | 1 份 | LLM 应用框架 |
langgraph |
1.0.4 | 1 份 | 图执行引擎 |
langchain-openai |
1.1.0 | 1 份 | OpenAI 兼容接口 |
langchain-milvus |
0.3.1 | 1 份 | Milvus 集成 |
langchain-text-splitters |
1.0.0 | 1 份 | 文本分块 |
pymilvus |
2.6.5 | 1 份 | Milvus 客户端 |
gradio |
5.49.1 | 1 份 | Web UI 框架 |
🔧 做菜工具
| 工具名 | 用途 |
|---|---|
| Python 3.8+ | 编程环境 |
| .env 文件 | 环境变量配置 |
厨房环境(.env 环境变量 )
bash
# 阿里云通义 API 配置
QWEN_API_KEY=sk-xxxxxxxxxxxx
QWEN_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
QWEN_CHAT_MODEL=qwen3-8b
QWEN_EMBEDDING_MODEL=text-embedding-v4
# Milvus 配置
MILVUS_URI=http://localhost:19530
MILVUS_COLLECTION_NAME=modelscope_docs烹饪参数(系统参数)
| 参数 | 值 | 菜谱对应 | 说明 |
|---|---|---|---|
| 🧂 向量维度 | 1024 | 盐度/咸淡 | 控制 Embedding 的精度和表现力 |
| 🥄 检索数量 | Top-3 | 分量 | 每次检索取 3 份相关文档 |
| 🌡️ 相似度阈值 | 0.1 | 火候 | 控制文档相关性的严格程度 |
| ⏱️ 最大重写次数 | 3 | 翻炒次数 | Query Rewrite 最多执行 3 次 |
| ✂️ 分块粒度 | 按 Markdown 标题 | 切割大小 | 按一级、二级、三级标题分块 |
烹饪流程图
整个答疑 Agent的系统分成在线部分和离线部分, 在线部分就是去实现用户 query 的知识检索与答案生成, 而离线部分就是知识库的爬取与向量化构建.
| 步骤 | 菜谱对应 | 技术操作 |
|---|---|---|
| 第 0 步 | 准备食材 | 爬取 Markdown 文档(crawl 操作) |
| 第 1 步 | 搭建厨房 | 安装依赖、配置环境、启动 Milvus |
| 第 2 步 | 切菜 | 数据加载与分块 |
| 第 3 步 | 腌制 | 向量化 |
| 第 4 步 | 入锅 | 索引构建与存储 |
| 第 5 步 | 炒菜 | 构建 RAG 图 |
| 第 6 步 | 调味 | 流式生成 |
| 第 7 步 | 盛盘 | Gradio 前端 |
| 第 8 步 | 品尝 | 测试和优化 |
📦 离线部分(知识库构建)
这部分在系统启动前完成,用于构建知识库和向量索引
第 0 步:准备食材(爬取 Markdown 文档)
0.1 爬取 ModelScope 文档
python
# 使用爬虫脚本爬取 ModelScope 官方文档
# 存放到 modelscope_docs/ 目录
from crawl.modelscope_crawler import crawl_docs
docs = crawl_docs(
url="https://modelscope.cn/docs/",
output_dir="modelscope_docs/"
)
print(f"爬取了 {len(docs)} 个文档")食材输出, 获得原始 Markdown 文档集合
第 1 步:烹饪环境搭建(环境和依赖安装)
1.1 创建虚拟环境
bash
# 使用 conda
conda create -n rag-cook python=3.10
conda activate rag-cook1.2 安装核心依赖
bash
# 安装 LangChain 生态
pip install langchain==1.1.2
pip install langchain-core==1.1.1
pip install langchain-openai==1.1.0
pip install langchain-milvus==0.3.1
pip install langchain-text-splitters==1.0.0
# 安装 LangGraph
pip install langgraph==1.0.4
pip install langgraph-checkpoint==3.0.1
pip install langgraph-prebuilt==1.0.5
# 安装向量库
pip install pymilvus==2.6.5
# 安装前端
pip install gradio==5.49.1
# 安装其他依赖
pip install openai==2.9.0
pip install python-dotenv==1.2.1
pip install loguru==0.7.3
pip install tenacity==9.1.21.3 配置环境变量
bash
# 创建 .env 文件
QWEN_API_KEY=your-api-key-here
QWEN_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
QWEN_CHAT_MODEL=qwen3-8b
QWEN_EMBEDDING_MODEL=text-embedding-v4
MILVUS_URI=http://localhost:19530
MILVUS_COLLECTION_NAME=modelscope_docs1.4 启动 Milvus 服务
Milvus 是阿里云远程部署的话, 可参考这份文章: 【大模型杂货铺】 阿里云服务器 Milvus 极简安装教程
bash
# 使用 Docker 启动 Milvus
docker run -d --name milvus \
-p 19530:19530 \
-p 9091:9091 \
milvusdb/milvus:v2.6.5
# 或使用 Docker Compose
docker-compose up -d第 2 步:切菜(数据准备与分块)
2.1 加载 Markdown 文档
python
from utils import get_all_files
folder_path = "md"
path_list = get_all_files(folder_path)
docs = []
for path in path_list:
with open(path, "r", encoding="utf-8") as f:
text = f.read()
docs.append(text)
print(f"加载了 {len(docs)} 个文档")预期结果:加载所有 Markdown 源文件
2.2 按 Markdown 标题分块
python
from langchain_text_splitters import MarkdownHeaderTextSplitter
# 定义分块规则
headers_to_split_on = [
("#", "一级标题"),
("##", "二级标题"),
("###", "三级标题"),
]
# 执行分块
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on,
return_each_line=True
)
split_docs = []
for doc in docs:
split_docs.extend(markdown_splitter.split_text(doc))
print(f"分块后得到 {len(split_docs)} 个文档片段")预期结果:切换后的文档片段结果
第 3 步:腌制(向量化)
3.1 初始化 Embedding 模型
python
from llm.openllm import OpenLlm
from dotenv import load_dotenv
load_dotenv()
llm = OpenLlm()
# 验证连接
test_emb = llm.emb(
model="text-embedding-v4",
text="测试文本"
)
print(f"Embedding 维度:{len(test_emb)}") # 应该是 1024预期结果:成功连接到 Qwen Embedding API,维度为 1024
3.2 批量向量化
python
# 准备文本
md_texts = [text.page_content[:8192] for text in split_docs]
# 批量 Embedding
embs = llm.emb_batch(
model="text-embedding-v4",
texts=md_texts,
batch_size=10
)
print(f"向量化完成,共 {len(embs)} 个向量")预期结果:354 个向量,每个 1024 维
第 4 步:入锅(索引构建与存储)
4.1 创建 Milvus 集合
python
from pymilvus import MilvusClient, IndexType
from pymilvus.client.types import DataType, MetricType
client = MilvusClient(uri="http://localhost:19530")
# 创建 Schema
schema = client.create_schema()
schema.add_field(field_name="id", datatype=DataType.INT64,
is_primary=True, auto_id=True)
schema.add_field(field_name="text", datatype=DataType.VARCHAR,
max_length=65535)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR,
dim=1024)
schema.add_field(field_name="filename", datatype=DataType.VARCHAR,
max_length=1000)
# 创建索引
index_param = client.prepare_index_params()
index_param.add_index(
field_name="vector",
index_name="vector_index",
index_type=IndexType.HNSW,
metric_type=MetricType.IP,
params={"M": 16, "efConstruction": 200}
)
# 创建集合
client.create_collection(
collection_name="modelscope_docs",
schema=schema,
index_params=index_param
)预期结果:成功创建 Milvus 集合
4.2 插入向量和元数据
python
from vectordb.faiss_vector_store import FaissVectorStore
import faiss
# 创建本地 FAISS 索引(或使用 Milvus)
index = faiss.IndexFlatL2(1024)
vector_db = FaissVectorStore(index=index)
# 准备文档数据
docs_data = [{"text": text} for text in md_texts]
# 添加向量
vector_db.add(
embedding=embs,
doc=docs_data
)
# 持久化
vector_db.persist(
index_path="kb/index",
kb_path="kb/docs"
)
print("向量索引已保存")预期结果:向量索引和文档已保存
🌐 在线部分(实时问答服务)
这部分在系统运行时执行,用于处理用户查询和生成答案
第 5 步:炒菜(构建 Naive RAG 图)
5.1 定义图状态
python
from typing import TypedDict, Annotated
from langchain_core.messages import BaseMessage
from langgraph.graph import add_messages
class AgentState(TypedDict):
messages: Annotated[list[BaseMessage], add_messages]5.2 定义图节点
Agent 节点(决策是否检索)
python
def agent_node(state: AgentState):
"""Agent 决策是否需要检索"""
messages = state['messages']
model = chat_model.bind_tools([retriever_tool])
resp = model.invoke([messages[-1]])
return {"messages": [resp]}Retriever 工具(检索文档)
python
from langchain_core.tools import tool
@tool("rag_retriever")
def retriever_tool(query: str):
"""搜索 ModelScope 相关知识"""
docs = retriever.invoke(query)
results = []
for i, doc in enumerate(docs, 1):
result = f"【文档 {i}】\n"
result += f"📄 文件: {doc.metadata.get('filename', '未知')}\n"
result += f"📝 内容:\n{doc.page_content}"
results.append(result)
return "\n\n".join(results) if results else "未找到相关文档"Generate 节点(生成答案)
python
def generate(state: AgentState) -> dict:
"""基于检索文档生成答案"""
messages = state["messages"]
# 获取最后一条用户消息
last_human_msg = None
for msg in reversed(messages):
if isinstance(msg, HumanMessage):
last_human_msg = msg
break
# 获取最后一条消息(检索结果)
last_msg = messages[-1]
prompt = PromptTemplate(
template="""你是 ModelScope 魔搭社区的知识问答助手。
请根据以下检索到的上下文内容来回答问题。
确保答案来源于上下文,不要编造新内容。
如果上下文中没有答案,请直接回复'不知道'。
问题: {question}
上下文: {context}
""",
input_variables=["question", "context"]
)
chain = prompt | chat_model | StrOutputParser()
response = chain.invoke({
"question": last_human_msg.content,
"context": last_msg.content
})
return {"messages": [AIMessage(content=response)]}5.3 构建完整的图
python
from langgraph.graph import StateGraph, START, END
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.checkpoint.memory import MemorySaver
def build_rag_graph():
builder = StateGraph(AgentState)
# 添加节点
builder.add_node("agent", agent_node)
builder.add_node('retrieve', ToolNode([retriever_tool]))
builder.add_node('generate', generate)
# 定义流程
builder.add_edge(START, 'agent')
builder.add_conditional_edges('agent', tools_condition,
{'tools': 'retrieve', END: END})
builder.add_edge('retrieve', 'generate')
builder.add_edge('generate', END)
# 编译
memory = MemorySaver()
return builder.compile(checkpointer=memory)
rag_graph = build_rag_graph()预期结果:成功构建 Naive RAG 图
第 6 步:调味(流式生成)
6.1 实现流式响应
python
from datetime import datetime
from typing import Generator
def chat_response(message: str) -> Generator[str, None, None]:
"""流式生成 RAG 响应"""
config = {"configurable": {"thread_id": str(uuid.uuid4())}}
inputs = {"messages": [HumanMessage(message)]}
start_time = datetime.now()
doc_count = 0
yield "🔍 分析中..."
result = None
for event in rag_graph.stream(inputs, config=config,
stream_mode="values"):
result = event
if "messages" in event:
for msg in event["messages"]:
if isinstance(msg, ToolMessage) and msg.content:
doc_count = msg.content.count("【文档")
duration = (datetime.now() - start_time).seconds
yield f"📚 检索到 {doc_count} 篇文档 ({duration}s)..."
# 提取答案
answer = ""
if result and "messages" in result:
for msg in reversed(result["messages"]):
if isinstance(msg, AIMessage) and msg.content:
answer = msg.content
break
# 流式输出
prefix = f"📚 参考了 {doc_count} 篇文档\n\n---\n\n" if doc_count > 0 else ""
current_text = prefix
for char in answer:
current_text += char
yield current_text预期结果:能够逐字流式输出答案
第 7 步:盛盘(Gradio 前端)
7.1 构建 Web 界面
python
import gradio as gr
custom_css = """
.gradio-container {
font-family: system-ui, -apple-system, sans-serif !important;
background: #fff !important;
max-width: 70% !important;
}
"""
with gr.Blocks(css=custom_css, title="ModelScope 助手") as demo:
# 标题
gr.HTML("""
<div class="header">
<h1>ModelScope 社区助手</h1>
</div>
""")
# 聊天框
chatbot = gr.Chatbot(
label="",
type="messages",
show_label=False,
render_markdown=True,
)
# 输入区域
with gr.Column(elem_classes="input-container"):
msg = gr.Textbox(
placeholder="发消息或输入 / 选择技能",
show_label=False,
container=False,
autofocus=True,
lines=2
)
# 快捷按钮
with gr.Row():
btn1 = gr.Button("🔍 模型推理", size="sm")
btn2 = gr.Button("📥 模型下载", size="sm")
btn3 = gr.Button("📋 模型类型", size="sm")
btn4 = gr.Button("🔌 API调用", size="sm")
submit_btn = gr.Button("➤", size="sm")
# 事件处理
def user_input(user_message, history):
if not user_message:
return "", history
history.append({"role": "user", "content": user_message})
return "", history
def bot_output(history):
if not history:
return history
user_message = history[-1]["content"]
history.append({"role": "assistant", "content": ""})
for chunk in chat_response(user_message):
history[-1]["content"] = chunk
yield history
# 绑定事件
msg.submit(user_input, [msg, chatbot], [msg, chatbot]).then(
bot_output, [chatbot], [chatbot]
)
submit_btn.click(user_input, [msg, chatbot], [msg, chatbot]).then(
bot_output, [chatbot], [chatbot]
)
if __name__ == "__main__":
demo.launch(server_name="0.0.0.0", server_port=7860)7.2 启动服务
bash
python app.py
# 访问 http://localhost:7860预期结果:Web UI 成功启动,可以进行对话
第 8 步:品尝(测试和优化)
8.1 测试查询(人工测试)
python
# 测试问题
test_queries = [
"魔搭平台是做什么的?",
"如何在 ModelScope 上下载模型?",
"ModelScope 支持哪些模型类型?",
"如何使用 ModelScope 进行模型推理?",
]
for query in test_queries:
print(f"\n问题:{query}")
print("=" * 50)
for response in chat_response(query):
pass # 流式输出
print(response)8.2 评估系统质量(工具测试)
这步非必须, 下一讲里, 我们将介绍如何构建评估集, 然后基于 RAGAS 进行效果评测
python
# 使用 RAGAS 评估
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_relevancy,
context_recall
)
# 评估指标
evaluation_result = evaluate(
dataset=test_dataset,
metrics=[
faithfulness,
answer_relevancy,
context_relevancy,
context_recall
]
)
print(evaluation_result)RagAgent 烹饪每一步输出整理
- 环境配置完成,所有依赖安装成功
- 354 个文档片段成功分块
- 向量索引成功构建和存储
- RAG 图成功构建和编译
- Web UI 成功启动
- 能够正确回答测试问题
- 系统评估指标达到预期
常见烹饪问题排查
| 问题 | 原因 | 解决方案 |
|---|---|---|
| API 连接失败 | API Key 错误或网络问题 | 检查 .env 文件,测试网络连接 |
| Milvus 连接失败 | 服务未启动 | 检查 Docker 容器状态 |
| 向量维度不匹配 | Embedding 模型输出维度不对 | 确认使用 text-embedding-v4 |
| 检索结果为空 | 索引未构建或查询不相关 | 重新构建索引,调整查询 |
| 生成答案缓慢 | LLM 推理耗时 | 检查网络延迟,考虑优化 Prompt |
总结
这个 RAG 系统就像做菜一样:
- 准备食材 → 安装依赖、配置环境
- 切菜 → 数据加载和分块
- 腌制 → 向量化
- 入锅 → 索引构建
- 炒菜 → 构建 RAG 图
- 调味 → 流式生成
- 盛盘 → Web UI 展示
- 品尝 → 测试和优化
每一步都很关键,缺一不可。按照这个步骤一步步来,就能做出一道美味的 RAG 系统!
🎉 祝你烹饪愉快!