Genie: Generative Interactive Environments
-
摘要
-
核心创新:首个无监督生成的交互环境
-
Genie定义: 它是第一个"生成式交互环境"。
-
训练方式: 无监督------使用未标注的互联网视频。
-
优势:
- 传统的游戏环境或模拟器通常需要代码编写,或者在训练AI时需要视频对应的动作标签(比如这一秒按了'跳跃'键)
- Genie不需要这些,它仅仅通过看海量的视频,就学会了世界是如何运作的。
-
-
功能:多类型输入均可变为虚拟世界
-
输入多样性: 输入可以为文字/合成图/真实照片/手绘草图。
-
输出结果: 这些静态输入会转化为一个动作可控的虚拟世界。
-
举例: 一个超级马里奥的草图,Genie可以把它变成一个可以实际操作并游玩的动态关卡。
-
-
定位:基础世界模型------Foundation World Model
- 定位: 11B 参数的基础世界模型。
- 就像GPT是文本领域的基础模型一样,Genie旨在成为构建虚拟世界和交互环境的通用底座。
- 定位: 11B 参数的基础世界模型。
-
技术架构
- Spatiotemporal Video Tokenizer------时空视频分词器
- 把视频在空间(画面)和时间(帧序列)上进行压缩和编码,转化成Token。
- Autoregressive Dynamics Model------自回归动力学模型
- 预测下一帧会发生什么,类似于NTP,决定了世界的物理规则和动态变化。
- 没有采用Diffusion的生成方式
- Latent Action Model------潜在动作模型
- 最关键的创新。因为没有真实的按键记录,模型必须自己推断出视频帧之间发生了什么潜在动作,从而把这种推断转化为用户的控制器。
- Spatiotemporal Video Tokenizer------时空视频分词器
-
突破点:无标签也能控制
-
实现: 用户可以逐帧控制环境。
-
难点: 它是在没有任何真实动作标签的情况下做到的。
-
对比: 以前的世界模型通常需要知道每一步对应什么动作(如Robot动作日志或游戏按键日志),且往往受限于特定领域。Genie打破了这些限制,具有极强的通用性。
-
-
研究展望:通往AGI
-
Genie学到的潜在动作空间非常有价值。
-
应用: 可以用这个环境来训练其他的AI Agent。让Agent去模仿那些它没见过的视频中的行为。
-
目标: 为训练未来的通用智能体开辟了道路。
- 因为有了Genie,我们就有了一个无限的、通用的训练场,而不需要为每个任务专门写模拟器。
-
-
1. Introduction
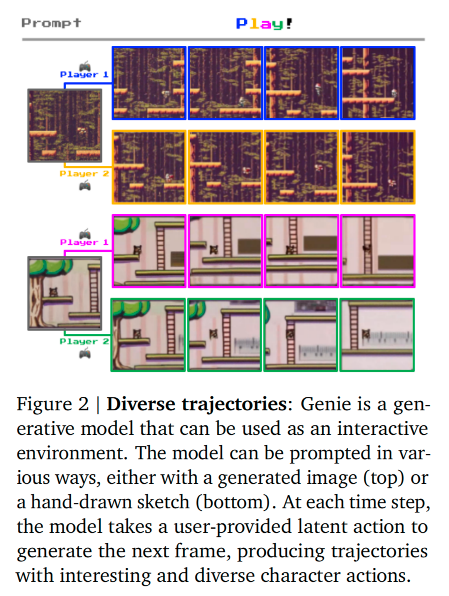
-
研究背景与痛点:从"生成"到"交互"的跨越
-
现状: 生成式 AI的爆发式增长。
- 文本: Transformer 的出现让 GPT 等模型能写出连贯的对话。
- 图像: 扩散模型能通过文字生成精美的图片。
- 视频: 视频生成是下一个前沿,虽然已有进展,但目前的视频模型主要是看的,缺乏像 ChatGPT 那样的交互性,更没有沉浸式体验。
-
提出的问题: "如果我们不仅仅生成视频,而是能生成完整的交互体验,会怎样?"
-
-
核心概念:Genie------Generative Interactive Environments
-
作者提出了一个新的范式------生成式交互环境。
- 定义: 这是一个通过单一的文本或图像提示,就能生成出来的、可交互的虚拟环境。
-
数据来源: 训练数据来自互联网上超过 200,000 小时 的公开游戏视频。
-
关键突破------Unsupervised: 这一点至关重要。通常训练游戏 AI 需要知道"这一帧按了什么键",但互联网视频只有画面,没有按键记录。
- Genie 在没有动作标签、没有文本标注 的情况下,学会了逐帧控制画面。
-
能力: 作为一个 11B参数的基础模型,它可以接受一张它从未见过的图片,然后生成一个完全想象出来的、可玩的虚拟世界。
-
-
技术架构:三大核心组件
-
基础架构: 所有的组件都基于 Spatiotemporal (ST) Transformers
-
流程:
- Video Tokenizer------视频分词器: 负责把视频压缩成Tokens。
- Causal Action Model------因果动作模型: 负责从视频中提取 Latent Actions 。
- 举例:虽然视频没告诉模型玩家按了跳跃,但模型通过观察画面变化,推断出了一个代表跳跃的latent。
- Dynamics Model------动力学模型: 这是一个预测模型--使用 MaskGIT 技术。
- 它接收当前的画面 Token 和推断出的动作,然后预测下一帧画面。
-
-
实验验证:Scaling Laws(缩放定律)
-
规模分析: 作者做了一系列从 40M 到 2.7B 再到最终 11B 参数的模型。
-
结论: 结果证明架构符合缩放定律------计算资源越多、模型越大,效果就越好。
-
具体训练集: 最终的 Genie 模型是在筛选后的 30,000 小时 的 2D 平台游戏视频上训练的。
-
-
泛化能力
-
为了证明这套方法不是只能玩游戏,作者还做了两个重要的扩展实验:
-
机器人领域:他们在 RT1 数据集(机器人操作视频)上训练了一个模型。
- 同样是没有动作标签,模型依然学会了生成连贯的机器人操作环境。
-
强化学习的未来:Genie 学到的潜在动作可以用来推断策略。
- 意义: 这意味着以后要训练机器人或 AI Agent,可能不再需要昂贵的模拟器或者人工采集数据,直接让 AI 看海量的视频,就能通过 Genie 这样的模型学会如何操作。
-
-
2. Methodology
-
任务定义
-
基础: Genie 的架构基于 Vision Transformer,这是目前图像处理的主流架构。
-
痛点: 标准 Transformer 的内存消耗是**二次方级(O(N2)O(N^2)O(N2))**的。
-
举例: 在处理文本时,Token 数量通常几百上千;但处理视频时,Token 数量会轻松达到上万级别。如果用标准 Transformer,每一个 Token 都要和所有其他 Token 算注意力,计算量就是 10000×1000010000 \times 1000010000×10000,内存会直接爆炸。
-
-
**解决方案:**ST-transformer 架构
-
对策: 采用了时空 Transformer(ST-transformer)。
-
应用范围: Genie 的所有组件(分词器、动作模型、预测模型)都用了这个架构。
-
-
**架构细节:**把空间和时间分开算
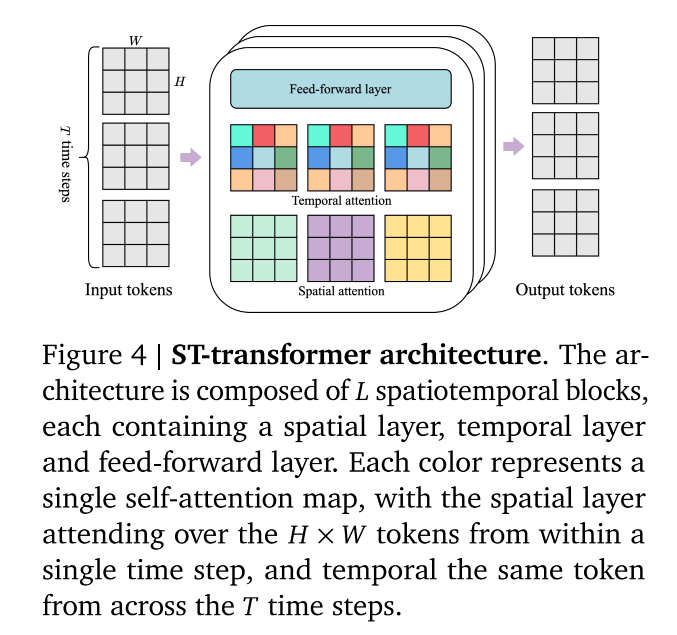
-
传统 vs. 新架构:
- 传统: 所有 Token(不管是在哪一帧、哪一个位置)混在一起算注意力。
- ST-transformer:
- 采用了 LLL 个层块,里面交替放置了空间注意力层和时间注意力层。
- 最后接一个前馈神经网络。
-
核心思想: 不再一次性算所有东西,而是先算画面内的关系,再算时间上的关系。
-
具体计算方式:
-
空间层: 锁定时间。在每一帧 内部,计算 H×WH \times WH×W 这些 Token 之间的关系。
-
时间层 :锁定空间位置。在同一个token 上,跨越 TTT 个时间步,计算这 TTT 个 Token 的关系。
-
-
关键特性:
-
因果掩码: 在时间层中,必须加上因果限制。
-
含义: 第 ttt 帧只能看到 ttt 之前的帧,不能看未来。
-
-
计算效率
- 传统 ViT: 复杂度随帧数 TTT 是二次方增长 (T2T^2T2)。
- ST-transformer: 计算量最大的部分是空间层,而空间层是每一帧单独算的。所以,当你增加帧数 TTT 时,计算量只是线性增长。
-
结果: 这让 Genie 能够生成长视频,并保持长时间的动态一致性,而不会因为视频变长导致计算量指数级爆炸。
-
-
**架构特点:**减少 FFW 层
-
标准做法: 通常的设计是 空间层 -\> FFW -\> 时间层 -\> FFW。
-
Genie 的改进: 空间层 -\> 时间层 -\> **一个 FFW**。他们砍掉了空间层后面的那个 FFW。
-
原因:
- 省下来的参数和计算量,让他们可以把模型的其他部分做得更大。
- 作者观察到,这种牺牲一个 FFW 换取更大模型规模的策略,实际上显著提高了最终效果。
-
2.1 Model Components
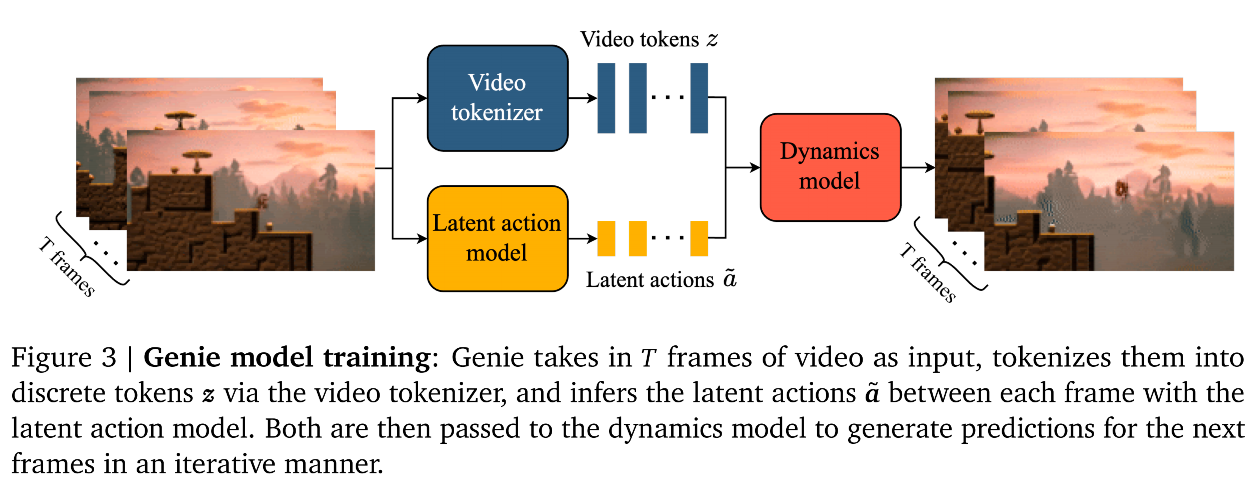
-
三大核心组件
-
Latent Action Mode
- 任务: 观察两帧画面,推断出它们之间发生了什么潜在动作 (Latent Action, aaa)。
-
Video Tokenizer
- 任务: 把庞大的原始视频画面压缩并转化为机器好处理的离散 Token (zzz)。
-
Dynamics Mode
- 任务: 接收过去的 Token 和推理出的动作,预测下一帧视频会是什么样------自回归的视频生成。
-
-
两阶段训练流程
-
第一阶段:先练分词器
- 操作: 单独训练 Video Tokenizer 。
- 第二阶段冻结
- 操作: 单独训练 Video Tokenizer 。
-
第二阶段:联合训练
- 操作: 同时训练 Latent Action Model 和 Dynamics Model。
- 关键差异:
- LAM 使用的是原始像素 (Pixels)------为了捕捉细微动作细节。
- Dynamics Model 使用的是视频 Token------为了高效学习宏观物理规律。
-
2.1.1 Latent Action Model
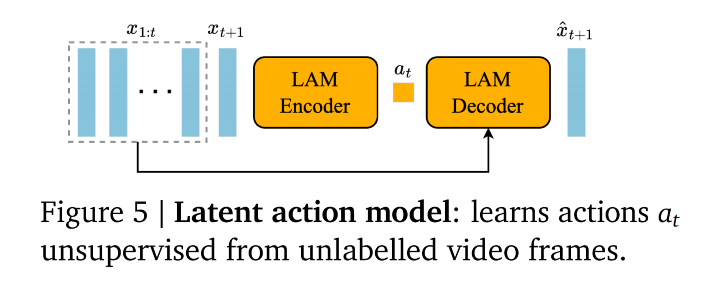
-
核心任务:无监督的动作提取
-
目标: 模型通过观察画面变化,定义什么是"动作"。
-
方法: 利用过去 和未来之间的差异来反推。
-
-
训练流程:Encoder-Decoder 架构
-
编码器
-
输入: 之前的帧序列 x1:t\mathbf{x}{1:t}x1:t 加上 下一帧 xt+1\mathbf{x}{t+1}xt+1。
-
逻辑: 编码器同时看到了现在和未来。
- 比如,现在马里奥在地上,未来马里奥在空中。
- 编码器就分析:"为了从状态 A 变到状态 B,中间一定发生了某种变化。"
-
输出: 一个连续的潜在动作向量序列 a~1:t\tilde{\mathbf{a}}_{1:t}a~1:t。
-
作用: 它的任务就是把前后两帧的差异提取出来,称之为"动作"。
-
-
量化瓶颈 ------ 强制归类(LAM 最关键的一步)
-
编码器输出的是连续向量,包含的信息太多太杂。
-
作者使用了 VQ-VAE 的技术,强制把这个连续向量映射到一个极小的离散码本中。
- 只有 8 个动作 (∣A∣=8|A|=8∣A∣=8)。
- 如果允许 1000 种动作,模型可能会把背景的风吹草动都当成动作。但如果只允许 8 种,模型就被迫只学习最重要、最显著的变化(比如:跳跃、左移、右移、开火等)。
- 为了 Human Playability。如果生成了过多按键,人类根本没法玩;8 个按键较为合适。
- 只有 8 个动作 (∣A∣=8|A|=8∣A∣=8)。
-
-
解码器
-
输入: 之前的帧 x1:t\mathbf{x}{1:t}x1:t 和 **提取出的动作序列 a~1:t\tilde{a}{1:t}a~1:t**。
- 注意: 解码器看不见 下一帧 xt+1\mathbf{x}_{t+1}xt+1。
-
任务: 预测下一帧 x^t+1\hat{x}_{t+1}x^t+1。
-
逻辑: 如果解码器能根据"历史"和"动作"完美画出"未来",那就证明这个"动作"提取对了。
- 这个过程迫使 a~\tilde{a}a~ 必须包含从过去通向未来的关键信息。
-
-
-
技术细节:ST-Transformer
-
LAM 同样使用了时空 Transformer。
-
Causal Mask :即使它可以一次性处理整个视频序列 x1:T\mathbf{x}_{1:T}x1:T,但在时间层上使用了因果掩码,确保它在提取第 ttt 步动作时,利用的是上下文的一致性,但逻辑上依然是基于帧间差异的。
-
-
训练与推理的区别
-
训练时:
- 我们要训练 LAM 识别动作。
- 我们要训练 Dynamics Model 理解这些动作。
-
推理时:
- LAM 被扔掉了:Encoder和Decoder全部舍弃。
- 保留 :VQ Codebook------动作词表。
- 推理时的动作 :人类用户提供。
- 按下"键 1",模型就去 Codebook 里查"动作 1"对应的向量,然后喂给 Dynamics Model。
-
-
总结
- 训练目标: 把视频帧之间的像素差异 ,压缩成 8个离散的代号。
- 手段: 用 Encoder 看未来帧,提取差异;用 Decoder 验证差异是否准确。
- 结果: 得到了一本动作字典(Codebook)。
- 最终应用: 玩游戏时,人类按键 →\to→ 查字典 →\to→ 输入给Dynamics Model生成画面。
2.1.2 Video Tokenizer
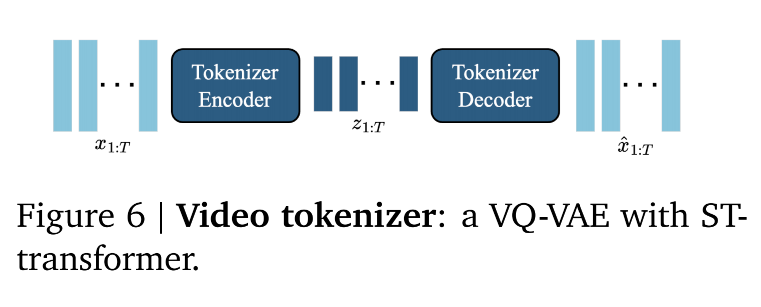
-
基础任务:压缩与离散化
-
手段: 使用 VQ-VAE。
-
过程:
-
输入: 原始视频帧 x1:Tx_{1:T}x1:T(比如 RGB 像素矩阵)。
-
处理: 通过编码器压缩。
-
量化: 这是关键。它不是压缩成连续的小数,而是压缩成离散的整数索引 z1:T∈IT×Dz_{1:T}\in \mathbb{I}^{T \times D}z1:T∈IT×D。
- DDD 表示每一帧被切成了 DDD 个token,存储时,存的是token在Code book中的索引。
-
-
结果: 每一帧画面不再是几百万个像素,而是变成了几百个来自代码本的数字编号。这大大降低了维度,让生成高质量视频成为可能。
-
-
核心创新:时空感知
-
旧方法------Spatial-only:
- 以前的方法通常是把视频切成一张张图,单独压缩。
- 缺点: 每一帧的 Token 只知道这一帧长什么样,不知道上一帧发生了什么。这就导致压缩后的代码丢失了"动作"和"连贯性"的信息,画面容易闪烁。
-
Genie 的方法------ST-Transformer:
- 它在 Encoder 和 Decoder 里都用了 ST-Transformer。
- 意义: 在生成第 ttt 帧的 Token ztz_tzt 时,模型不仅看了第 ttt 帧的画面,还回顾了之前的所有帧 x1:tx_{1:t}x1:t。
- 因果性: 这意味着,ztz_tzt 这个代码,实际上是一个**"包含了历史记忆的浓缩包"**。它不仅仅代表"这一刻的画面",还隐含了"这一刻是如何从过去演变而来的"动态信息。
-
-
效率突破:线性复杂度
-
竞争对手 (Phenaki / C-ViViT):
- 虽然也用了时间感知的分词器,但计算复杂度是 二次方级 (O(T2)O(T^2)O(T2))。
- 如果你把视频长度加倍,计算时间会变成 4 倍。这导致它很难处理长视频。
-
Genie (ST-ViViT):
- 得益于 ST-Transformer 的设计(空间和时间分开算),它的计算复杂度是 线性级 (O(T)O(T)O(T))。
- 如果你把视频长度加倍,计算时间也只加倍。
- 结论: 这使得 Genie 能够处理更长的视频序列,且训练效率更高。
-
2.1.3 Dynamics Model
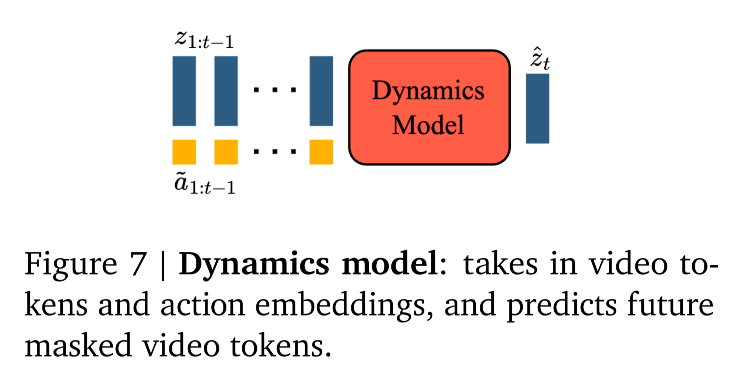
-
核心架构:Decoder-only MaskGIT Transformer
-
Decoder-only: 像 GPT 一样,这是一个单向生成的模型。
-
MaskGIT (Masked Generative Image Transformer):
- 传统 GPT: 是从左到右,自回归生成。这在生成图片/视频时非常慢。
- MaskGIT: 是一种并行生成策略。它允许模型一次性预测这一帧里多个被遮挡的 Token。
- 结合 ST-Transformer: 使用时空 Transformer,利用其因果掩码来处理时间维度,确保预测未来时不会看到未来。
-
-
输入与输出流
-
输入:
- 过去的视频 Token (z\mathbf{z}z): 来自Video Tokenizer。
- 过去的潜在动作 (a~\tilde{\mathbf{a}}a~): 来自LAM。
-
关键细节 ------ Stopgrad (停止梯度):
- 含义: 在训练 Dynamics Model 时,误差反向传播不会**传导回 Latent Action Model (LAM)。
- 原因: 断开连接是为了防止动力学模型作弊或干扰 LAM 的学习。
- LAM 必须专心学动作,Dynamics 必须专心学预测,两者虽然一起训,但在梯度流上是解耦的。
-
输出: 下一帧的 Token z^t\hat{z}_tz^t。
-
-
训练策略:伯努利掩码
-
Masking Rate (0.5 ~ 1.0): 在训练时,模型看到的下一帧并不是完整的
- 可能完全被遮住(Rate = 1),或者是被遮住了一大半(Rate = 0.5)。
-
目的: 强迫模型具备极强的上下文补全能力。如果模型能在遮住了 80% 的情况下依然猜出画面大概是什么样,那在推理时生成画面就会非常稳健。
-
损失函数: 标准的 Cross-Entropy Loss
- 即:预测出来的 Token ID 和真实的 Token ID 是否一致。
-
-
核心创新:Latent Action注入方式
-
常见做法------Concatenate:
- 以前的模型通常是把动作向量和图像 Token 向量拼起来
- 拼接在尾部或作为一个额外的 Token。
- 举例:把向右走这个标签贴在"马里奥"这个词后面。
- 以前的模型通常是把动作向量和图像 Token 向量拼起来
-
Genie 的做法------采用加性嵌入。
- 公式:Embeddingfinal=Embeddingimage+EmbeddingactionEmbedding_{final} = Embedding_{image} + Embedding_{action}Embeddingfinal=Embeddingimage+Embeddingaction
- 举例:把"向右走"这个信息,直接加 到"马里奥"的数值里去。
- 这有点像 Positional Embedding的处理方式。
-
效果: 作者发现,这种直接融合的方式,比简单的拼接更能提高可控性。
- 这意味着模型会更听指挥,按下跳跃键,角色跳起来的概率更大。
-
2.2 Inference
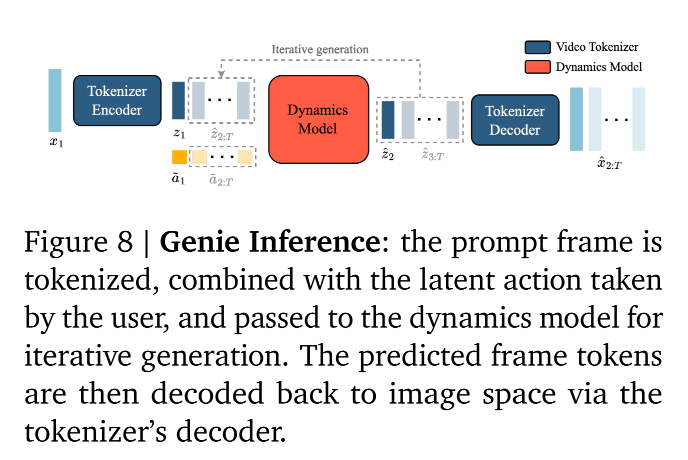
-
推理步骤
-
Step 1. 启动:
-
输入: 多种类型的prompt均可
-
**过程:**通过 Video Tokenizer Encoder ,压缩成第一组 Token (z1z_1z1)。此时,世界初始状态加载完毕。
-
-
Step 2. 交互:
- 方式 :用户按下一个键,这对应着范围 [0,∣A∣)[0, |A|)[0,∣A∣) 内的一个整数ID。
-
Step 3. 查表:
-
查表: 通过ID,去 LAM 训练的VQ Codebook 里查找对应的潜在动作向量。
-
注入: 这个向量通过加性嵌入 方式,加到当前的视频 Token z1z_1z1 里。
-
-
Step 4. 预测:
-
计算: Dynamics Model 接收当前画面 z1z_1z1 + 动作 a~1\tilde{a}_1a~1。
-
生成: 它运用学到的物理规律,预测出下一帧的 Token 代码 z^2\hat{z}_2z^2。
-
-
Step 5. 循环与显像:
-
内部循环: 刚刚生成的 z2z_2z2 变成了新的过去,你再输入下一个动作 a2a_2a2,模型生成 z3z_3z3......如此往复,生成整个序列。
-
显像: 每一个生成的 Token 序列 (z^\hat{z}z^),都会实时被送进 Video Tokenizer Decoder ,翻译回人类能看的 RGB 像素画面 (x^\hat{x}x^)。
-
-
-
核心亮点
-
**复现:**如果喂给它一段视频的第一帧,并且严格按照原视频的动作序列按键,它会重现原视频。
-
创造: 如果在某一步按下了和原视频不一样 的键,视频的时间线就会分叉。会创造出一个从未存在过的、全新的游戏进程。
-
3. Experimental Results
-
数据集
-
核心数据集:Platformers (2D 平台游戏)
-
来源
- 全部来自公开的互联网视频。
- 通过搜索与 "2D Platformer" 相关的关键词来收集。
-
筛选与清洗过程
- 海选: 最初通过关键词搜索,抓取了 55M 个视频片段。
- 精选: 经过过滤,最终留下 6.8M 个片段------大约 30,000 小时
- 附录B中有具体细节
-
视频格式
- 时长: 每个片段切成 16秒。
- 帧率: 10 FPS。
- 分辨率: 160x90。
-
-
通用性的验证数据集:Robotics (机器人操作)
-
来源
- 主要基于 RT-1 项目(Google 的一个机器人模型)的数据。
- 包含 ~13万 条 RT-1 的演示视频。
- 额外加上了 20.9万 条来自早期研究(Kalashnikov et al., 2018)的真实机器人操作视频。
- 还混合了一些模拟器生成的数据。
- 主要基于 RT-1 项目(Google 的一个机器人模型)的数据。
-
**数据处理:**剔除动作标签
-
-
-
衡量标准
-
视频保真度
-
**指标名称:**FVD (Unterthiner et al. (2019) )
-
计算方式:生成的视频分布和真实视频分布之间的距离。
-
**理解:**数值越低,说明生成的视频越像真实的互联网视频,画面越自然、流畅。
-
-
可控性
-
指标名称: ΔtPSNR\Delta_t \text{PSNR}ΔtPSNR (Delta-t Peak Signal-to-Noise Ratio)
- 分数越高,代表画面越相似
-
评价逻辑: 比较做模型做的动作和随机采样的动作对画面的影响差异。
ΔtPSNR=PSNR(xt,x^t)−PSNR(xt,x^t′) \Delta_t \text{PSNR} = \text{PSNR}(x_t, \hat{x}t) - \text{PSNR}(x_t, \hat{x}{t'}) ΔtPSNR=PSNR(xt,x^t)−PSNR(xt,x^t′)-
xtx_txt: 原始视频在第 ttt 帧的真实画面。
-
x^t\hat{x}_tx^t 模型使用从真值推断出的正确动作 (a~1:t\tilde{a}_{1:t}a~1:t) 生成的画面。
-
x^t′\hat{x}_{t'}x^t′ 模型使用了随机采样的动作 生成的画面。
-
-
-
-
训练细节
-
Video Tokenizer 的配置
-
参数量:200M
-
Patch Size:4
- 这意味着它把画面切得非常细。
- 图像分辨率是 160×90160 \times 90160×90,除以 4,得到 40×2240 \times 2240×22 的 Token 网格。
-
Codebook:1024 codes,32维
-
-
Latent Action Model 配置
-
参数量:300M
-
Patch Size:16
- 注意,这里切得很粗(是 Tokenizer 的 4 倍)。
- 动作通常是宏观的。模型不需要关注像素级的细节,切得粗一点反而更容易捕捉整体的物体移动趋势。
-
Codebook:8 codes,32维
-
-
通用设置 :模型一次只看和生成 16 帧,帧率为10FPS
-
训练稳定性设置
-
数据格式:bfloat16
-
使用QK Norm:
- 背景: 在训练超大模型(如 11B 参数)时,Transformer 里的 Attention 分数容易变得极大,导致梯度爆炸,模型训练直接崩盘。
- 作用: 在计算 Attention 之前,先对 Query 和 Key 向量做归一化。这就像给模型加了"稳压器",让大规模训练不仅可行,而且收敛更快。
-
-
推理时的采样策略
-
25 MaskGIT steps:迭代步数
- MaskGIT是迭代式 生成的:第一次可能只生成最有把握的 4% 的像素,然后把剩下的遮住;第二次再填补一部分......总共分 25 步 把一张图填满。
-
Temperature = 2:
- 通常温度设为 1.0。这里设为 2.0 是非常高的。
- **含义:**高温度会增加随机性,让生成的画面更多样化,不那么死板。
-
Random Sampling:不使用 Beam Search 或 Top-k 截断,而是直接根据概率随机抽样。这配合高温度,进一步保证了生成内容的丰富性。
-
-
3.1 Scaling Results
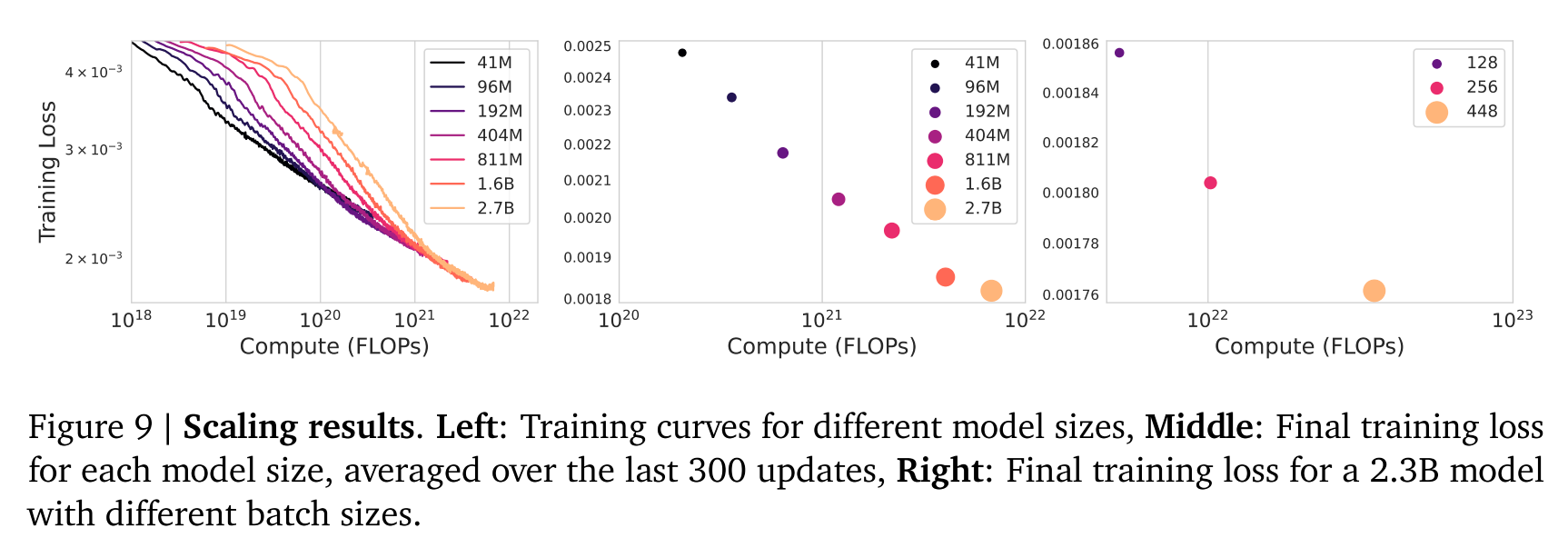
3.1.1 Scaling Model Size
- 控制变量: 保持Video Tokenizer和 LAM 不变。
- 自变量: 只改变 Dynamics Model 的大小。
- 范围: 尝试了从 40M (4000万) 到 2.7B (27亿) 参数的一系列模型。
- 结论 :Scales gracefully。
- 意思是:模型参数每增加一点,训练损失就稳定地下降一点。没有出现瓶颈,也没有出现收益递减。
- 意义: 这给了团队信心,说明只要把模型做得超级大,效果一定会更好。这也为最终的 11B 模型奠定了理论基础。
3.1.2 Scaling Batch Size
- 控制变量: 固定使用一个 2.3B 的模型。
- 自变量: 改变 Batch Size
- 测试了 128, 256, 448 三种大小。
- 换算成 Token 数量分别是 1.9M, 3.8M, 6.6M。
- 结论: 增大 Batch Size 同样带来了明显的性能提升。
- Batch Size 越大,意味着模型在每一次参数更新时看到的样本更多,梯度的方向更准确,训练收敛得更好。
3.1.3 Genie Model
- 核心配置:
- Dynamics Model: 10.1B 参数。
- Batch Size: 512。
- 总参数量:10.7B
- 10.1B (Dynamics Model) + 0.2B (分词器) + 0.3B (动作模型) ≈ 10.7B。
- 训练消耗:
- 数据量: 训练过程中一共看过了 942B 个 Token。
- 硬件: 使用了 256个 TPUv5p 芯片。
- 步数: 训练了 125k 步。
3.2 Qualitative Results
3.2.1 Platformers-trained Model

-
测试Genie 对 OOD数据 的处理能力。
-
**输入:**AI 生成的图、手绘草图、真实照片
-
结果: Genie 能看懂这些图片,并立刻把它们变成"可操作的游戏"。
-
结论: 这证明了 Genie 真的学会了通用的物理规则和交互逻辑。
-
-
涌现能力:理解3D 视差
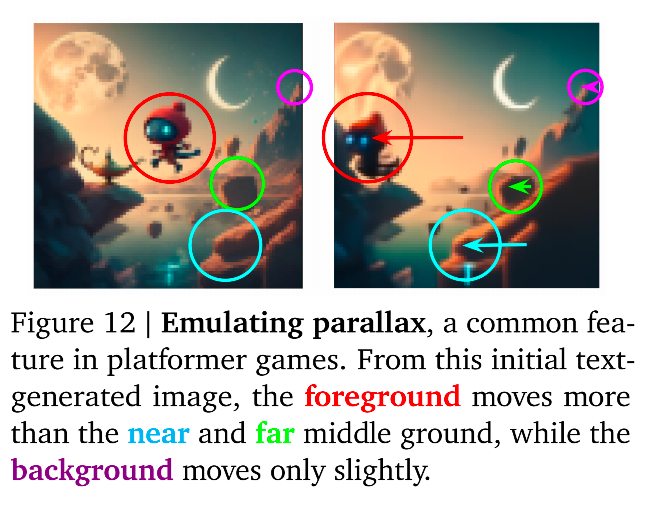
-
什么是视差 :当你在现实中移动时,近处的物体移动得快,远处的背景移动得慢。
-
Genie 的表现:
- Genie 训练的是 2D 游戏视频,并没有人教它 3D 几何学。
- 但在生成的视频中,当角色移动时,Genie 自动让前景层移动得比背景层快。
-
意义:这说明模型涌现出了深度感知能力。它理解画面不是一张平纸,而是有前后空间关系的。
-
3.2.2 Robotics-trained Model

论文展示了 2.5B 参数的机器人模型。
- 模型学习到的能力
- 控制: 它学会了机械臂怎么移动、抓取。
- 物理交互: 这是重点。它不仅知道机械臂怎么动,还知道**"物体被抓捏时会变形"**。
- 研究展望: 这意味着以后我们要训练机器人,不需要在实验室里采集带传感器的数据,直接把互联网上成千上万的机器人视频喂给 Genie,它就能构建出一个通用的机器人世界模拟器。
3.3 Training Agents
作者不再满足于让 Genie 能够被人玩,而是探讨 能否用 Genie 来训练 AI,让 AI 学会玩游戏。
这验证了 Genie 是否具备成为 通用智能体训练场 的潜力。
-
方法论:用潜在动作教 AI
-
作者设计了一个精巧的实验,测试 Genie 学到的 Latent Actions 是否具有通用的语义价值。
-
挑战:
- Genie 训练时学出了一套自己的动作语言(比如动作 ID 3 代表跳跃)。
- 但新的游戏环境(比如 CoinRun)有它自己的"真实按键"(比如按键 'Space' 代表跳跃)。
- 这两者语言不通。
-
解决方案
- 冻结 LAM:拿一个在互联网视频上训练好的 LAM,直接拿来用,参数不许变。
- 打标签 :找一段高手玩 CoinRun的视频。
- 让 LAM 看着视频,把每一帧的动作"翻译"成 Genie 的潜在动作 ID。
- 训练策略 :训练一个新的小 AI,让它学习:"看到这种画面,就应该输出动作 3"。
- 极简映射 :最后,我们需要一个翻译字典,把 Genie 的"动作 3"对应到游戏机的"Space 键"。
- 关键点: 作者发现,只需要极少量的真实数据(200个样本),就能学会这个映射。
-
-
实验结果:
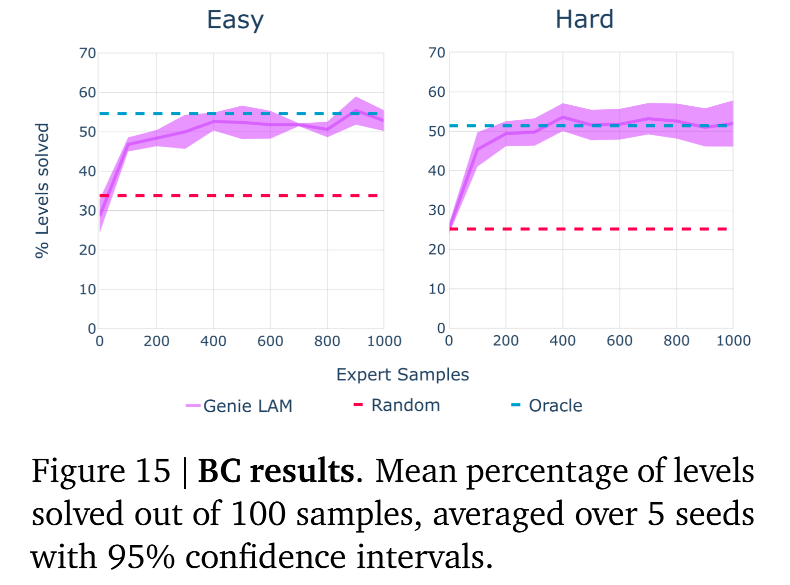
-
**Random Agent **:随机采样的AI
-
Oracle BC :全知行为克隆。这个 AI 在训练时直接使用了真实的按键记录。理论上它是最强的。
-
LAM-based Policy: 使用 Genie 猜出来的潜在动作训练的 AI。
-
3.4 Ablation Studies
3.4.1 Design choices for latent action model
-
核心问题: 训练 LAM 提取动作时,输入应该是原始像素 (xxx) 还是压缩后的 Token (zzz)?
-
方案一:Token-input Model
- 思路: 既然 Video Tokenizer 已经把画面压缩得很好了,直接用 zzz 作为 LAM 的输入,计算量会小很多,网络也能做得很轻量。
-
方案二:Pixel-input Model
- 思路: 直接把原始视频画面 xxx 喂给 LAM,虽然计算量大,但保留了所有细节。
-
-
结果
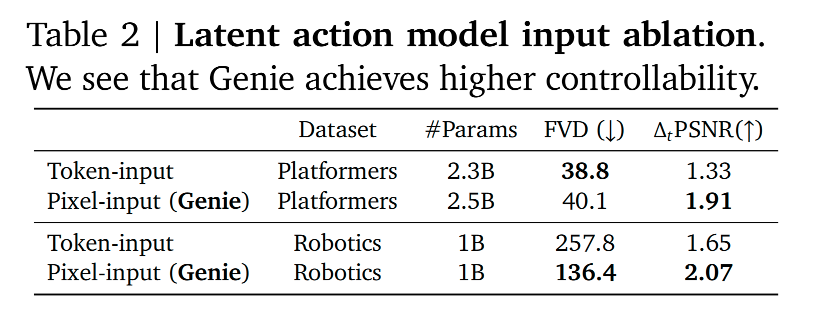
-
原因分析:作者认为,Tokenization的过程由于是有损压缩,不可避免地丢掉了一些"细微的动态信息"。
-
对于重建画面来说,这些丢失的信息可能无关紧要(比如背景的一点噪点)。
-
但对于推断动作来说,这些细微的像素变化(比如手指微微动了一下)可能恰恰是判断动作的关键线索。
-
结论: 为了动作提取的准确性,必须让 LAM 看原始像素,不能看 Token。
-
3.4.2 Tokenizer architecture ablations
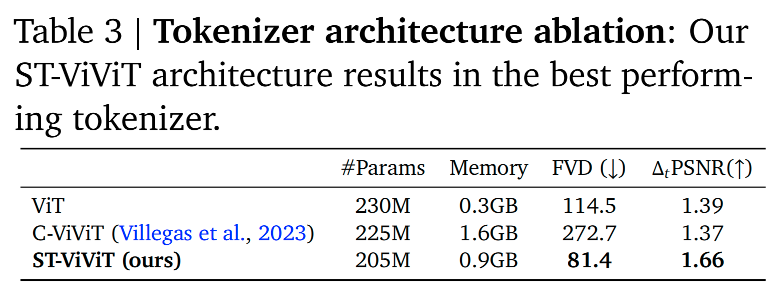
-
核心问题: 视频压缩到底是用传统的图像方法,还是复杂的视频方法,还是 Genie 提出的新方法?
-
方案一:Spatial-only ViT
-
原理: 只在空间上算注意力,把视频当成一堆独立的图片来处理。
-
缺点: 完全没有时间概念。它不知道这一帧和上一帧的关系,导致压缩出来的 Token 丢失了连贯性。
-
-
方案二:Spatial-temporal C-ViViT
-
原理: 它使用全时空注意力。
-
特点: 每一个 Token 都要和全视频所有时间、所有位置的 Token 算关系。
-
结果:
- 内存消耗极其巨大。
- 过拟合: 表现反而很差。因为它太复杂了,参数太灵活,导致在训练集上死记硬背,泛化能力不行,必须用很强的正则化手段才能勉强训练。
-
-
方案三:Spatial-temporal ST-ViViT
-
原理: 我们之前讲过的 ST-Transformer。先算空间,再算时间。
-
结果:
- 画质 (FVD): 最优。
- 可控性 (ΔtPSNR\Delta_t \text{PSNR}ΔtPSNR): 最优。
- 效率: 内存消耗适中(线性增长),是完美的平衡点 (Trade-off)。
-
-