目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
** 选题指导:**
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于图像处理与原型网络的小样本手语骨骼动作识别研究
选题意义背景
手语作为军队作战中的重要交流方式,具备无声传递信息的独特优势。在现代信息化战争背景下,如何实现高效准确的手语自动识别成为提升作战指挥效率的关键环节。传统通信方式在特定作战环境下存在易被敌方截获、干扰或暴露位置的风险,而手语通过肢体动作传递信息,能够有效规避这些问题,确保作战命令的安全传递。随着计算机视觉和深度学习技术的快速发展,手势识别领域取得了显著进展。然而,手语识别相比普通手势识别具有特殊性,主要体现在以下几个方面:手语动作具有严格的规范性和准确性要求;作战环境复杂多变,可能存在光线不足、背景干扰等问题;手语词汇量大,动作细节差异小,增加了识别难度。这些特点使得通用手势识别方法难以直接应用于手语识别任务。
当前,手语识别研究仍面临诸多挑战。首先,手语数据集的缺乏限制了深度学习模型的训练和优化。公开的大规模手语数据集较少,而自建数据集需要耗费大量人力物力。其次,现有识别算法在实时性和准确性之间难以取得平衡。复杂的深度学习模型虽然能够提高识别准确率,但计算开销大,难以满足战场实时应用需求;而轻量级模型虽然计算高效,但识别准确率往往不够理想。此外,在小样本学习场景下,如何利用有限的训练数据实现高质量的手语识别也是一个亟待解决的问题。
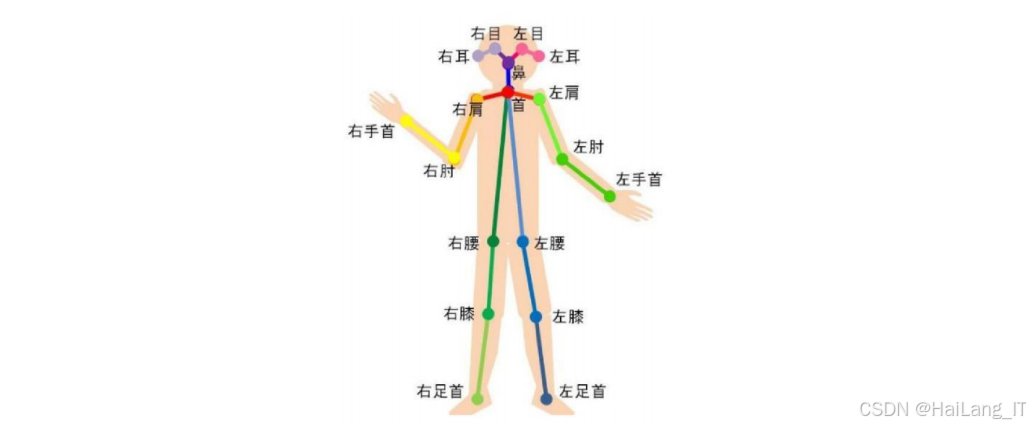
本选题旨在探索基于深度学习的手语识别技术,通过构建轻量级时空特征提取网络和基于原型网络的小样本学习方法,实现高效准确的手语识别。研究成果不仅能够为作战中的信息传递提供技术支持,还能够推动计算机视觉、深度学习等技术在领域的应用和发展。同时,研究中积累的数据集和算法模型也可以为相关领域的学术研究和工程实践提供参考。
数据集
本研究构建了一个大规模手语数据集,用于训练和测试手语识别模型。数据集的建立过程严格遵循科学规范,确保数据的多样性、准确性和实用性。
数据采集方式
手语数据通过实地采集的方式获取。为了模拟真实作战环境,采集人员身穿迷彩服,手上佩戴手套,在不同的环境条件下进行动作演示。数据采集使用专业级相机设备,确保视频质量。相机参数设置为×720分辨率、6400万像素、f/1.8光圈和90°视角,能够清晰捕捉手部动作细节。采集过程中,确保光线条件适中,避免过暗或过曝情况影响数据质量。
数据规模与格式
数据集包含种不同的手语动作,每种动作由12名实验者进行演示。每位实验者对每种动作进行多次重复演示,最终形成了3240个视频样本。视频数据以标准MP4格式存储,帧率为30fps,确保动作的连贯性和流畅性。数据集中包含的种手语动作均为实际作战中常用的指挥手势,具有重要的应用价值。主要包括"不用理会"、"敌人接近"、"过来"、"前方危险"、"守住这里"、"集合"、"狙击手"、"人质"、"收到"、"肃静"、"停止"、"无线电通讯"、"隐蔽"、"侦察"、"看见"、"方向"、"我"等动作。每个动作都有明确的定义和标准的执行规范,确保数据的一致性和准确性。
数据分割策略
为了有效评估模型性能,数据集采用科学的数据分割策略。将数据集按:2:1的比例划分为训练集、验证集和测试集。训练集包含2268个视频样本,用于模型的训练和参数优化;验证集包含648个视频样本,用于调整模型超参数和监控训练过程;测试集包含324个视频样本,用于最终评估模型性能。数据分割过程中,确保每个动作类别的样本在三个集合中均匀分布,避免类别不平衡问题影响模型训练效果。
数据预处理
原始视频数据需要经过一系列预处理步骤,才能输入到深度学习模型中进行训练和测试。数据预处理主要包括以下几个环节:
数据增强:为了扩大数据集规模,减少过拟合风险,采用了多种数据增强技术。主要包括水平翻转、添加随机噪声和中心旋转等操作。水平翻转可以有效增加训练样本的多样性;随机噪声能够提高模型对噪声的鲁棒性;中心旋转模拟不同拍摄角度的影响,增强模型的泛化能力。
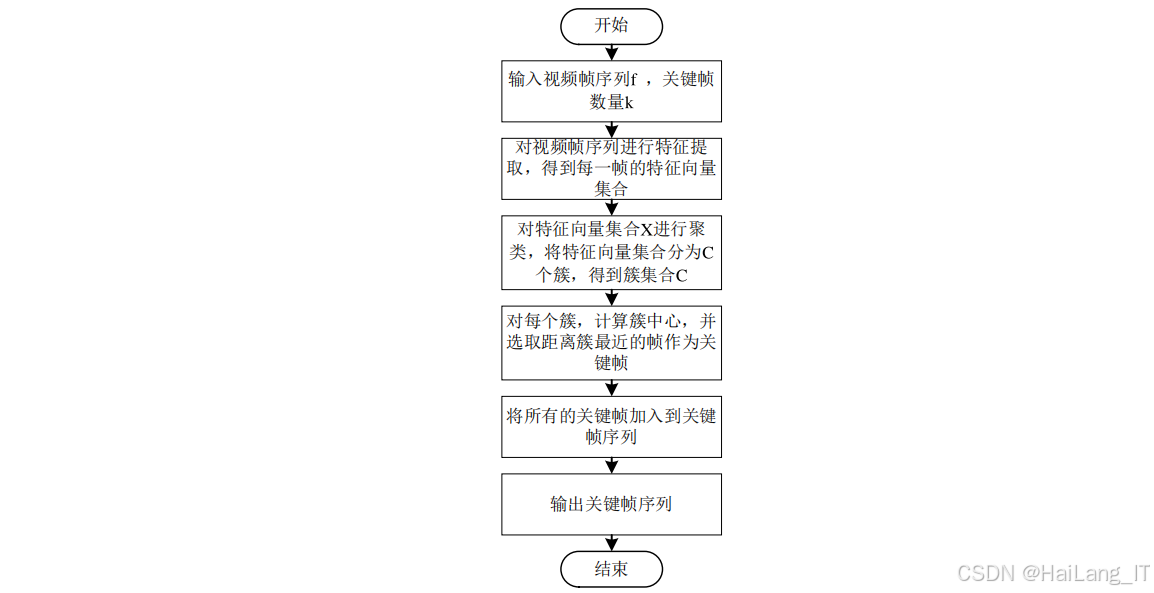
关键帧提取 :手语视频通常包含冗余帧,为了减少计算开销,提高识别效率,采用基于K均值聚类的关键帧提取方法。该方法能够自动识别视频中最具代表性的帧,保留动作的关键信息。具体来说,首先计算视频中相邻帧之间的差异,然后使用K均值聚类算法将帧分组,最后从每个聚类中选择一帧作为关键帧。
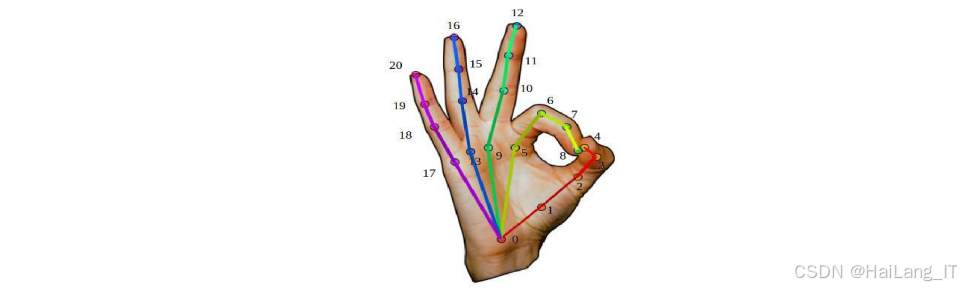
骨架序列生成:使用OpenPose姿态估计算法从视频帧中提取手部骨骼关键点信息。OpenPose能够准确识别个手部关键点,包括手指关节和手掌位置等信息。提取的关键点坐标数据用于生成骨骼序列,为基于骨架的识别方法提供输入数据。
通过上述数据集建立和预处理步骤,成功构建了一个高质量的手语数据集,为后续的算法研究和模型训练提供了坚实的数据基础。
功能模块介绍
手语视频流识别模块
该模块负责处理视频流数据,通过提取视频中的时空特征实现手语识别。主要技术思路和流程如下:
视频数据输入:模块接收预处理后的视频数据,包括关键帧提取后的帧序列。视频数据经过归一化处理,确保像素值在合适的范围内,便于模型处理。
轻量级三维残差网络:该网络是视频流识别模块的核心组件,负责提取视频的短期时空特征。网络采用D-ShuffleNet残差块作为基本单元,通过堆叠多个残差块形成深度网络结构。为了增强特征复用,在残差块之间引入密集连接机制,使得网络能够更充分地利用低级特征。此外,网络中还集成了CBAM注意力模块,通过通道注意力和空间注意力机制,提高模型对重要特征的关注度,增强在复杂背景下的识别能力。
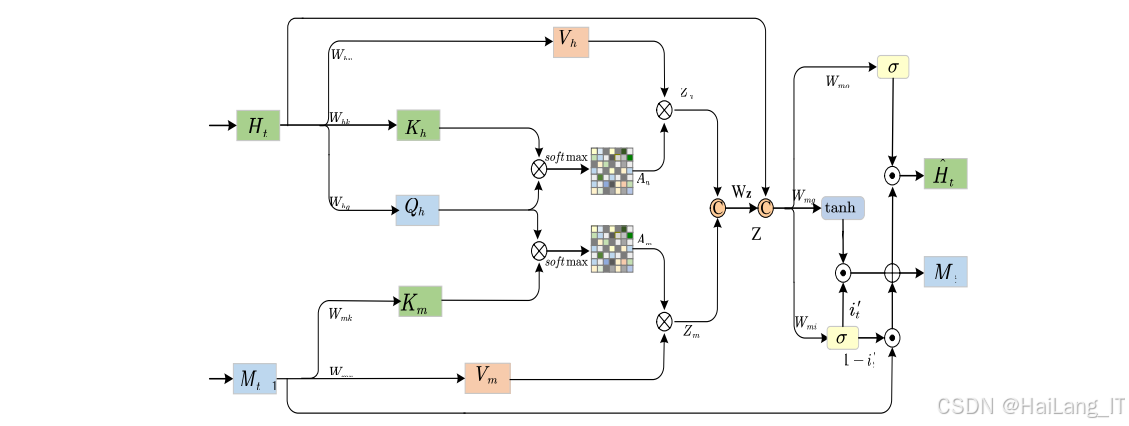
自注意力记忆ConvLSTM :为了建模视频的长期依赖关系,模块使用自注意力记忆ConvLSTM网络。该网络结合了卷积LSTM和自注意力机制的优点,能够有效捕捉视频中的时序信息。自注意力记忆模块通过门控机制动态更新记忆单元,选择性地聚合全局特征信息,提高对长时间序列特征的建模能力。
高层次特征提取:为了进一步提升特征表达能力,使用MobileNet网络提取高层次特征。MobileNet基于深度可分离卷积构建,参数量小且计算效率高,适合实时应用场景。通过4层基本单元的深度可分离卷积结构,能够有效提取更抽象的特征信息。
分类与识别:最后通过全连接层和softmax激活函数输出分类结果。分类层包含18个神经元,对应18种手语动作类别。模型在训练过程中使用交叉熵损失函数和随机梯度下降优化算法,不断调整网络参数,提高识别准确率。
手语骨骼流识别模块
该模块基于骨骼序列数据进行手语识别,特别适用于小样本学习场景。主要技术思路和流程如下:
骨骼数据输入:模块接收由OpenPose提取的手部骨骼关键点序列。骨骼数据包含个关键点的坐标信息,能够有效描述手部的姿态和运动轨迹。
时空图卷积网络 :为了有效建模骨骼数据的图结构特性,采用时空图卷积网络提取骨骼特征。网络由9层ST-GCN单元组成,每个单元包含空间图卷积和时间图卷积两部分。空间图卷积负责提取骨骼点之间的空间关系特征;时间图卷积则捕捉骨骼序列的时序演化规律。为了充分利用时间信息,时间图卷积采用膨胀因果卷积结构,能够有效扩大感受野,捕捉更长时间范围内的依赖关系。
原型网络:针对小样本学习场景,模块采用原型网络进行分类。原型网络通过元学习的思想,使模型具备从少量样本中学习的能力。在训练过程中,网络将支持集中的样本映射到嵌入空间,计算每个类别的原型表示(即嵌入向量的平均值)。对于查询样本,计算其嵌入向量与各个类别原型之间的距离,将其分类到距离最近的类别中。
距离度量与分类:使用欧几里得距离作为度量标准,计算查询样本与各类别原型之间的相似度。通过softmax函数将距离转换为概率分布,输出最终的分类结果。原型网络的损失函数基于支持集和查询集的分类结果计算,通过端到端训练优化网络参数。
手语识别系统界面模块
为了便于实际应用和展示,开发了基于PyQt和OpenCV的手语识别系统界面。该模块提供了友好的用户交互体验,支持实时识别和离线识别两种功能模式。
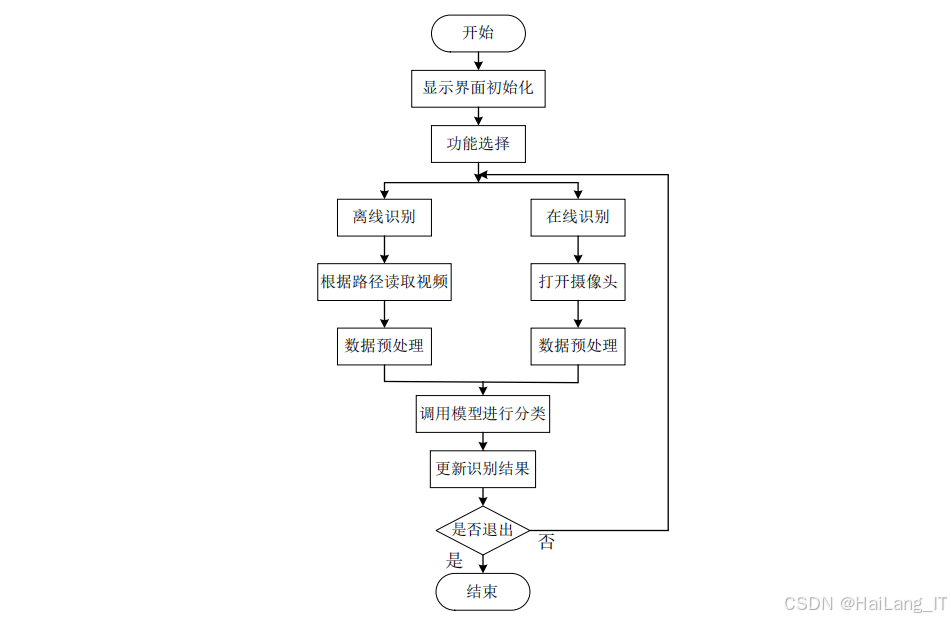
系统初始化:界面启动时,初始化摄像头设备、加载预训练模型,并设置相关参数。系统采用多线程架构,确保视频处理和界面更新互不干扰,提高响应速度。
功能选择:界面提供了明确的功能选择按钮,用户可以根据需求选择实时识别或离线识别功能。实时识别模式通过摄像头采集视频流进行实时处理和识别;离线识别模式则读取本地视频文件进行分析。
数据导入与导出:离线识别模式支持视频文件的导入和导出功能。用户可以通过文件对话框选择本地视频文件,系统自动读取并进行处理。识别结果可以保存为文本文件或导出为处理后的视频文件。
实时显示:界面左侧区域显示原始视频画面,右侧区域实时显示识别结果。在实时识别模式下,识别结果每2秒更新一次,确保信息的及时性和准确性。识别结果以文本形式展示,清晰直观。
系统控制:界面提供了启动识别、停止识别和退出系统等控制按钮,用户可以方便地操作和控制整个识别过程。系统还包含错误处理机制,当出现异常情况时能够给出友好的提示信息。
通过以上三个功能模块的协同工作,系统实现了高效准确的手语识别功能,能够满足不同应用场景的需求。
算法理论
轻量级时空特征提取网络
轻量级时空特征提取网络是针对视频流数据设计的深度学习模型,旨在高效提取视频中的时空特征信息。该网络的核心理论基础包括三维卷积神经网络、残差学习、密集连接、注意力机制等。
三维卷积神经网络 :三维卷积相比二维卷积增加了时间维度,能够同时提取视频的空间特征和时间特征。传统的三维卷积计算量巨大,不适合实时应用。为了解决这个问题,本研究采用了基于D-ShuffleNet的轻量级三维卷积结构,通过深度可分离卷积和通道混洗操作,大幅减少计算量和参数量。
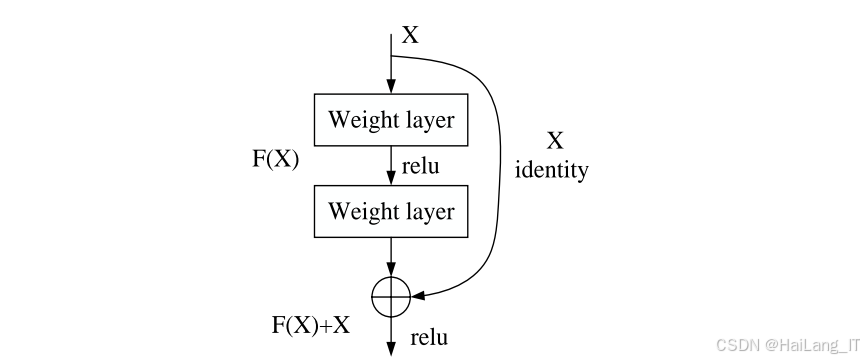
残差学习与密集连接:残差网络通过引入跳跃连接,有效缓解了深度网络的梯度消失问题。本研究在残差块之间引入密集连接机制,使得每个残差块的输出都能够传递到后续所有层,增强了特征复用能力。这种设计不仅提高了网络的特征表达能力,还减少了网络参数数量,提高了训练效率。
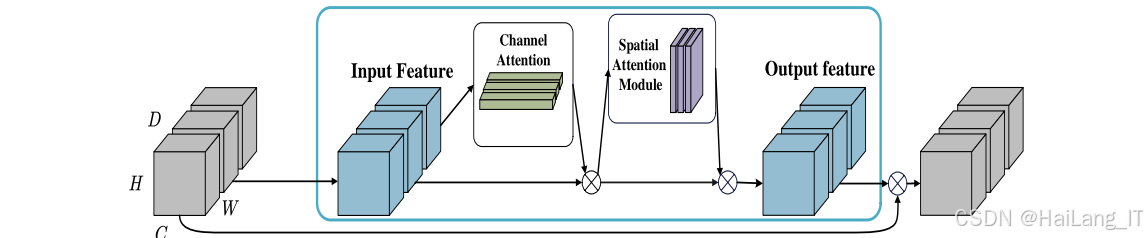
CBAM注意力机制 :CBAM(Convolutional Block Attention Module)是一种轻量级的注意力模块,包含通道注意力和空间注意力两个部分。在三维卷积网络中,CBAM通过对通道维度和空间维度同时建模,提高模型对重要特征的关注度。通道注意力模块通过全局池化操作聚合空间信息,生成通道级别的注意力权重;空间注意力模块则通过沿着通道维度的池化操作,生成空间级别的注意力权重。这种双重注意力机制能够有效提升模型在复杂背景下的识别性能。
自注意力记忆ConvLSTM:ConvLSTM结合了卷积神经网络和长短期记忆网络的优点,能够有效处理时空序列数据。传统的ConvLSTM在建模长期依赖关系时存在一定局限性。本研究引入自注意力记忆模块,通过门控机制动态更新记忆单元,选择性地聚合全局特征信息。自注意力记忆模块能够有效捕捉视频中的长距离依赖关系,提高模型对时序信息的建模能力。
MobileNet高层次特征提取:MobileNet是一种专为移动设备设计的轻量级卷积神经网络。它基于深度可分离卷积构建,将标准卷积分解为深度卷积和逐点卷积两个步骤,大幅减少计算量和参数量。本研究使用MobileNet提取视频特征的高层次表示,通过4层基本单元的深度可分离卷积结构,有效提取更抽象的特征信息,为最终的分类任务提供强大的特征支持。
基于原型网络的小样本识别
基于原型网络的小样本识别方法是针对骨骼流数据设计的学习框架,旨在解决小样本学习场景下的手语识别问题。该方法的核心理论基础包括图卷积神经网络、时空建模、原型学习等。
图卷积神经网络 :骨骼数据天然具有图结构特性,图卷积神经网络是处理这种非欧几里得数据的有效工具。图卷积通过在图结构上定义卷积操作,能够有效提取节点之间的关系特征。在本研究中,采用了空间配置划分策略进行图节点分区,将邻居节点分为根节点、向心群和离心群三类,提高了图卷积的表达能力。
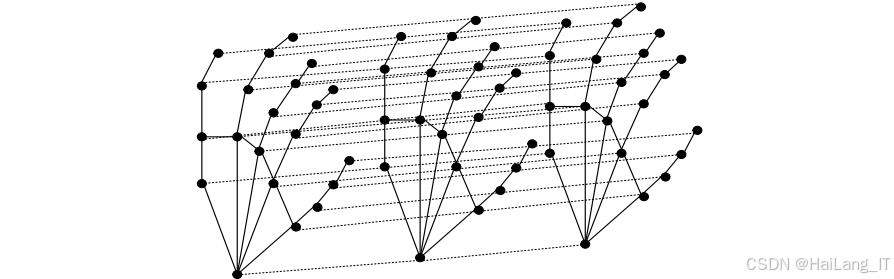
时空图卷积建模:时空图卷积网络通过在空间和时间两个维度同时进行卷积操作,能够有效捕捉骨骼序列的时空动态特征。空间图卷积负责提取同一帧内骨骼点之间的空间关系;时间图卷积则捕捉不同帧之间骨骼点的时序演化规律。本研究采用膨胀因果卷积作为时间图卷积的实现方式,通过增加卷积核的膨胀率,有效扩大感受野,捕捉更长时间范围内的依赖关系。
原型网络原理 :原型网络是一种基于度量学习的小样本学习方法,其核心思想是为每个类别在嵌入空间中学习一个原型表示。在训练过程中,原型网络通过元学习的方式,在多个小样本任务上进行训练,使模型能够快速适应新的类别。原型网络的训练过程包括支持集和查询集两个部分,支持集用于计算类别原型,查询集用于评估模型性能并更新参数。
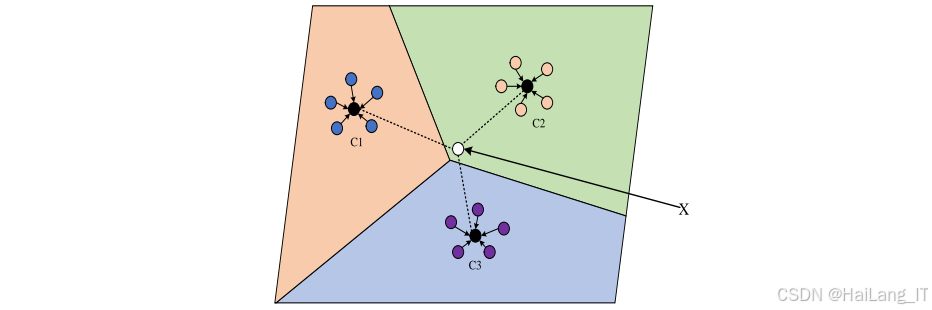
嵌入网络设计:嵌入网络是原型网络的核心组件,负责将输入数据映射到高维嵌入空间。在本研究中,嵌入网络采用层时空图卷积网络,通过逐层提取特征,将骨骼序列转换为高维嵌入向量。为了提高嵌入网络的表达能力,每个ST-GCN层都添加了可学习的边重要性权重和残差连接,有效缓解了过平滑问题,增强了特征区分度。
距离度量与分类:在原型网络中,距离度量是决定分类性能的关键因素。本研究通过实验比较了欧氏距离、曼哈顿距离、马氏距离、余弦距离和相关距离等多种度量方法,最终选择欧氏距离作为度量标准。欧氏距离能够有效衡量嵌入空间中向量之间的相似度,为分类决策提供可靠依据。
通过以上算法理论的综合应用,实现了高效准确的手语识别功能,能够满足实时应用和小样本学习场景的需求。
核心代码介绍
轻量级三维残差网络实现
python
def shufflenet_unit(x, in_channels, out_channels, stride):
# D-ShuffleNet基本单元实现
branch_channels = out_channels // 2
shortcut = x
# 主分支
x = Conv3D(branch_channels, kernel_size=1, strides=1, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 通道混洗
x = channel_shuffle(x)
# 3D深度可分离卷积
x = DepthwiseConv3D(kernel_size=3, strides=stride, padding='same')(x)
x = BatchNormalization()(x)
x = Conv3D(branch_channels, kernel_size=1, strides=1, padding='same')(x)
x = BatchNormalization()(x)
# 跳跃连接
if stride == 1 and in_channels == out_channels:
x = Add()([x, shortcut])
else:
shortcut = Conv3D(branch_channels, kernel_size=1, strides=stride, padding='same')(shortcut)
shortcut = BatchNormalization()(shortcut)
x = Concatenate()([x, shortcut])
return Activation('relu')(x)
def dense_block(x, blocks, growth_rate):
# 密集连接块实现
for i in range(blocks):
x = shufflenet_unit(x, x.shape[-1], growth_rate, stride=1)
return x轻量级三维残差网络的核心组件,包括3D-ShuffleNet基本单元和密集连接块。3D-ShuffleNet单元采用深度可分离卷积结构,大幅减少计算量;通过通道混洗操作增强信息流动;使用跳跃连接缓解梯度消失问题。密集连接块则将多个ShuffleNet单元连接起来,实现特征的充分复用。这种设计使得网络在保持较高识别精度的同时,参数量和计算量大幅降低,适合实时应用场景。
CBAM注意力模块实现
python
def channel_attention(x):
# 通道注意力模块
avg_pool = GlobalAveragePoolingD()(x)
max_pool = GlobalMaxPooling3D()(x)
shared = Dense(x.shape[-1] // 8, activation='relu')
avg_attention = shared(avg_pool)
max_attention = shared(max_pool)
avg_attention = Dense(x.shape[-1], activation='relu')(avg_attention)
max_attention = Dense(x.shape[-1], activation='relu')(max_attention)
attention = Add()([avg_attention, max_attention])
attention = Activation('sigmoid')(attention)
return Multiply()([x, attention])
def spatial_attention(x):
# 空间注意力模块
avg_pool = Lambda(lambda x: K.mean(x, axis=-1, keepdims=True))(x)
max_pool = Lambda(lambda x: K.max(x, axis=-1, keepdims=True))(x)
attention = Concatenate(axis=-1)([avg_pool, max_pool])
attention = Conv3D(1, kernel_size=3, padding='same', activation='sigmoid')(attention)
return Multiply()([x, attention])
def cbam_block(x):
# CBAM模块组合
x = channel_attention(x)
x = spatial_attention(x)
return xCBAM注意力模块,包括通道注意力和空间注意力两个部分。通道注意力模块通过全局平均池化和全局最大池化操作聚合空间信息,然后通过共享的全连接网络生成通道级别的注意力权重。空间注意力模块则通过沿着通道维度的平均池化和最大池化操作,生成空间级别的注意力权重。最后,将生成的注意力权重与输入特征图相乘,实现特征的自适应加权。CBAM模块能够有效提高模型对重要特征的关注度,增强在复杂背景下的识别能力。
原型网络实现
python
class PrototypeNetwork(tfkeras.Model):
def __init__(self, embedding_model, num_classes, num_support, num_query):
super(PrototypeNetwork, self).__init__()
self.embedding_model = embedding_model
self.num_classes = num_classes
self.num_support = num_support
self.num_query = num_query
def compute_prototypes(self, support_images, support_labels):
# 计算类别原型
embeddings = self.embedding_model(support_images)
prototypes = []
for c in range(self.num_classes):
class_mask = tf.equal(support_labels, c)
class_embeddings = tf.boolean_mask(embeddings, class_mask)
prototype = tf.reduce_mean(class_embeddings, axis=0)
prototypes.append(prototype)
return tf.stack(prototypes)
def call(self, inputs):
support_images, support_labels, query_images = inputs
# 计算原型
prototypes = self.compute_prototypes(support_images, support_labels)
# 提取查询样本特征
query_embeddings = self.embedding_model(query_images)
# 计算距离并分类
distances = []
for i in range(self.num_classes):
prototype = tf.expand_dims(prototypes[i], axis=0)
distance = tf.reduce_sum(tf.square(query_embeddings - prototype), axis=1)
distances.append(distance)
distances = tf.stack(distances, axis=1)
return tf.nn.softmax(-distances)原型网络的核心功能。原型网络继承自tf.keras.Model,包含嵌入网络、类别数、支持集样本数和查询集样本数等参数。compute_prototypes方法负责计算每个类别的原型表示,通过提取支持集样本的特征并计算平均值实现。call方法是模型的前向传播函数,首先计算支持集的类别原型,然后提取查询样本的特征,计算查询样本与各个原型之间的欧氏距离,最后通过softmax函数输出分类概率。原型网络通过这种方式实现了从小样本中学习的能力,能够有效解决训练数据不足的问题。
重难点和创新点
研究重点
本研究的重点在于设计高效准确的手语识别算法,主要集中在以下几个方面:
轻量级模型设计:如何在保证识别准确率的前提下,设计参数量小、计算效率高的轻量级模型,是实现实时手语识别的关键。本研究通过采用深度可分离卷积、残差学习、密集连接等技术,成功构建了轻量级时空特征提取网络,有效平衡了模型性能和计算效率。
时空特征融合:手语包含丰富的空间信息和时间信息,如何有效融合这两种信息是提高识别准确率的重要环节。本研究通过三维卷积提取短期时空特征,通过自注意力记忆ConvLSTM捕捉长期依赖关系,实现了时空特征的有效融合。
小样本学习:在实际应用中,可能面临训练数据不足的情况。如何利用有限的训练样本实现高质量的手语识别,是研究的难点之一。本研究基于原型网络构建了小样本学习框架,通过元学习的方式,使模型能够快速适应新的类别。
多模态信息利用:视频流和骨骼流包含不同类型的信息,如何充分利用这两种模态的信息,实现互补优势,是提高识别性能的重要途径。本研究分别设计了针对视频流和骨骼流的识别模块,为多模态融合提供了基础。
创新点
本研究的创新点主要体现在以下几个方面:
轻量级级联式网络架构:提出了轻量级级联式DCNN-ConvLSTM-MobileNet网络架构,通过将三维残差网络、自注意力记忆ConvLSTM和MobileNet级联,实现了对视频时空特征的高效提取。该架构在保持高识别率(95.3%)的同时,大幅减少了模型参数量和计算量,适合实时应用场景。
CBAM注意力机制扩展:将二维CBAM注意力机制扩展到三维,通过在三维卷积网络中集成通道注意力和空间注意力模块,提高了模型对重要特征的关注度。CBAM模块能够有效提升模型在复杂背景下的识别性能,增强了系统的鲁棒性。
基于原型网络的小样本骨架分类:提出了基于时空图卷积网络的原型学习方法,通过在嵌入空间中为每个类别学习原型表示,实现了小样本条件下的骨骼动作分类。该方法在仅有少量训练样本的情况下,仍然能够达到较高的识别准确率。
因果时间图卷积设计:设计了基于膨胀因果卷积的时间图卷积结构,通过增大卷积核的膨胀率,有效扩大感受野,捕捉更长时间范围内的依赖关系。这种设计提高了模型对时序信息的建模能力,增强了对复杂动作的识别效果。
多模态识别系统:构建了支持视频流和骨骼流双模态输入的手语识别系统,通过设计不同的特征提取和分类方法,充分利用了两种模态的互补优势。系统界面支持实时识别和离线识别两种功能模式,具有良好的用户交互体验。
总结
本研究针对手语识别这一重要应用场景,系统地研究了基于深度学习的手语识别方法。通过构建高质量的手语数据集,设计轻量级时空特征提取网络和基于原型网络的小样本学习框架,实现了高效准确的手语识别功能。
研究成果主要包括以下几个方面:首先,成功构建了包含18种手语动作、3240个视频样本的数据集,并通过数据增强、关键帧提取和骨骼序列生成等预处理步骤,为后续的算法研究提供了坚实的数据基础。其次,提出了轻量级级联式3DCNN-ConvLSTM-MobileNet网络架构,通过集成三维残差网络、自注意力记忆ConvLSTM和MobileNet,实现了对视频时空特征的高效提取,识别准确率达到95.3%。第三,针对小样本学习场景,提出了基于时空图卷积网络的原型学习方法,通过在嵌入空间中学习类别原型表示,实现了小样本条件下的骨骼动作分类,在6way-5shot任务中识别准确率达到97.07%。第四,开发了基于PyQt5和OpenCV的手语识别系统界面,支持实时识别和离线识别两种功能模式,具有良好的用户交互体验。
研究成果不仅为作战中的信息传递提供了技术支持,还能够推动计算机视觉、深度学习等技术在领域的应用和发展。同时,研究中积累的数据集和算法模型也可以为相关领域的学术研究和工程实践提供参考。
参考文献
1 Al-Hammadi M, Muhammad G, Abdul W, et al. Hand Gesture Recognition for Sign Language Using 3DCNNJ. IEEE Access, 2020, 8: 79491-79509.
2 Xu W, Wu M, Zhu J, et al. Multi-scale skeleton adaptive weighted GCN for skeleton-based human action recognition in IoTJ. Applied Soft Computing, 2021, 104: 107236.
3 Dong M, Fang Z, Li Y, et al. AR3D: attention residual 3D network for human action recognitionJ. Sensors, 2021, 21(5): 1656.
4 Hua Z, et al. An effective PoseC3D model for typical action recognition of dairy cows based on skeleton featuresJ. Computers and Electronics in Agriculture, 2023, 212: 108152.
5 Liu J, Shahroudy A, Perez M, et al. NTU RGB+D 120: A large-scale benchmark for 3D human activity understandingJ. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(10): 2684-2701.
6 Li M, Chen S, Chen X, et al. Actional-structural graph convolutional networks for skeleton-based action recognitionC. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 3595-3603.
7 Shi L, Zhang Y, Cheng J, et al. Two-stream adaptive graph convolutional networks for skeleton-based action recognitionC. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 12026-12035.