前言
目前的大型预训练语言模型的处境:
(1)大型预训练语言模型已被证明可以在其参数中存储事实知识,并在对下游NLP任务进行微调时实现最先进的结果。然而,它们访问和精确操纵知识的能力仍然有限,因此在知识密集型任务中,它们的性能落后于特定任务的架构;
(2)此外,模型的可解释性以及更新他们的世界知识仍然是悬而未决的研究问题。
基于以上两个问题,作者探索了一种基于检索增强生成(RAG)的通用微调方案------将预训练的参数和非参数记忆结合起来用于语言生成的模型。
(1)参数记忆是预训练的seq2seq模型;
(2)非参数记忆是维基百科的密集向量索引,可以通过预训练的神经检索器访问。
一、RAG的模型架构
将参数记忆与非参数(即基于检索)记忆相结合的混合模型,可以做到知识的直接修改和扩展,并且可以检查和解释访问的知识。
1.1 系统架构
系统的架构如下图所示:
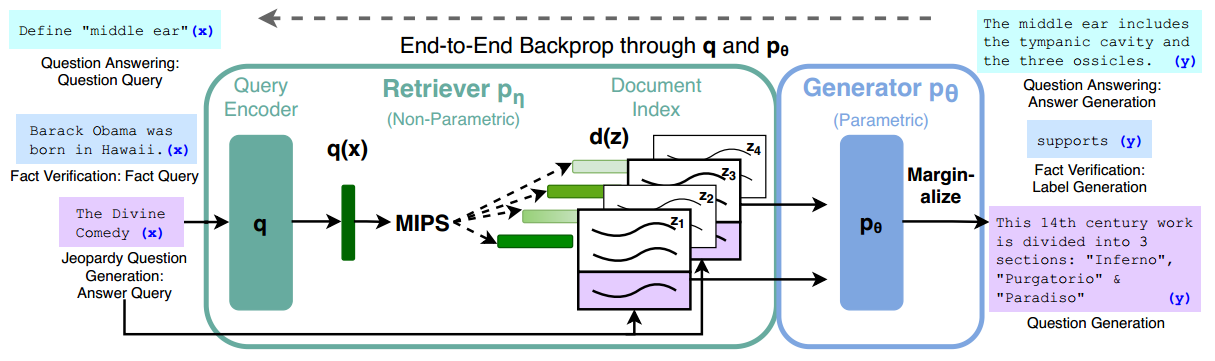
可以看出,主要由以下两个模块组成:
(1)检索器。检索得到以输入查询为条件的潜在文档;
(2)生成器。生成输出。
整体的工作流程如下:
(1)检索器首先对输入进行编码,得到编码后的向量,然后使用最大内积搜索(MIPS)策略,得到top-K(即前K)个文档,作为检索得到的潜在文档;
(2)生成器根据这些潜在文档,输入的查询以及先前的输出,整合后生成当前时刻的输出。
1.2 检索器Retriever
检索器基于DPR(Dense Passage Retrieval,密集段落检索器)。DPR遵循双编码器结构:
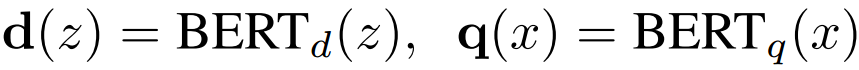
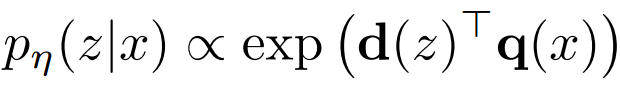
其中是
文档编码器编码后的文档的向量表示,
是同样基于
的查询编码器编码的查询的向量表示。
计算,即具有最高先验概率
的
个文档的列表
,是一个最大内积搜索(MIPS)问题,可以在亚线性时间内近似求解。
1.3 生成器Generator
生成器组件可以使用任何编码器-解码器进行建模。本工作使用BERT-large,一个具有400M参数的预训练seq2seq Transformer模型。
将输入x和检索到的内容z通过concat操作拼接起来,再输入BERT,进行内容的生成。
二、两种模型
在 RAG 框架中,RAG-Sequence 模型和 RAG-Token 模型是两种不同的生成模型变体,它们都基于"检索增强"思想,但在如何利用检索到的文档上有所不同。
2.1 RAG-Sequence模型
2.1.1 核心思想
在生成整个目标序列(一句话或一个答案)时,只使用同一个检索文档。
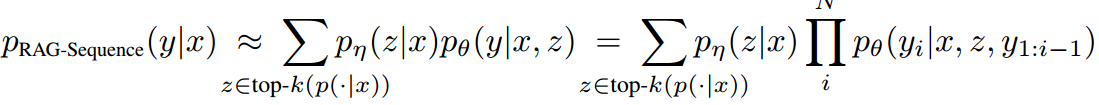
2.1.2 流程
(1)检索出前 K 个相关文档;
(2)为每个文档独立生成完整的目标序列;
(3)对所有文档的生成结果进行加权求和(基于检索概率)。
2.1.3 举例说明
输入:"海明威写了哪两本著名小说?"
(1)检索到文档1(关于《永别了,武器》)和文档2(关于《太阳照常升起》)。
(2)若选择文档1,则生成完整问题可能围绕《永别了,武器》;若选择文档2,则问题围绕《太阳照常升起》。
(3)最终输出是两个文档生成结果的加权融合。
输出 :"《太阳照常升起》 "。可能遗漏另一本。
2.1.4 结合实例的公式拆解
(1)检索阶段
输入问题 x 后,检索器(DPR)给出前 K 个相关文档的概率分布 。例如 K=2:
-
文档 z₁ 的概率
可能较高(比如 0.6);
-
文档 z₂ 的概率
(2)生成阶段(每个文档独立)
对每个文档 z,生成器(BART)基于该文档生成整个答案序列 y 的概率,即:
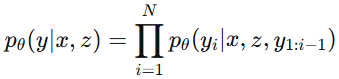
这是一个标准的自回归生成过程:从第一个词开始,基于文档 z 和已生成的部分,逐步预测下一个词。
-
对于 z₁:生成完整答案的概率
-
对于 z₂:生成完整答案的概率
(3)边缘化求和(融合多个文档)
将每个文档的生成概率乘以它的检索概率,然后求和:
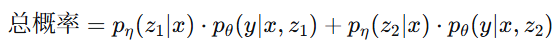
2.2 RAG-Token模型
2.2.1 核心思想
在生成每个目标 token 时,可以基于不同的文档。
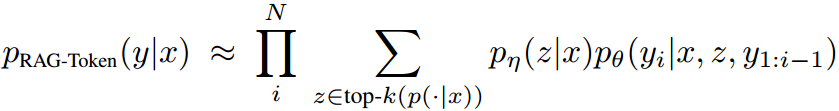
2.2.2 流程
(1)检索出前 K 个相关文档;
(2)生成每个 token 时,重新计算每个文档对该 token 的贡献;
(3)逐 token 边缘化,允许不同 token 来自不同文档。
2.2.3 举例说明
输入:"海明威写了哪两本著名小说?"
(1)检索到文档1(关于《永别了,武器》)和文档2(关于《太阳照常升起》)。
(2)生成"《太阳照常升起》"时,后验概率偏向文档2;
(3)生成"《永别了,武器》"时,后验概率偏向文档1;
(4)一个句子中可以融合来自两个文档的信息,更灵活。
输出:"《太阳照常升起》 《永别了,武器》"。输出了完整的信息。
2.2.4 结合实例的公式拆解
(1)检索阶段
输入问题 x 后,检索器(DPR)给出前 K 个相关文档的概率分布 。例如 K=2:
-
文档 z₁ 的概率
-
文档 z₂ 的概率
(2)生成阶段(每个 token 独立融合文档)
生成第一个 token (例如《太阳照常升起》) 时,对每个文档 z,计算在该文档下生成
的概率
,加权求和
。
-
在 z₁ 下生成该词的概率
-
在 z₂ 下生成该词的概率
-
边缘概率 =
生成第二个 token 时,此时已生成
,对每个文档 z,计算
,加权求和
。
-
在 z₁ 下生成该词的概率
-
在 z₂ 下生成该词的概率
-
边缘概率 =
(3)连乘得到序列概率
将所有 token 的边缘概率相乘:
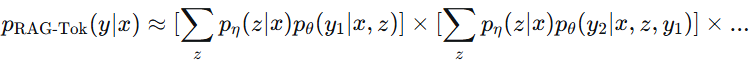
总概率= 0.58 * 0.44 = 0.2552
三、模型的训练与推理
3.1 训练
给定具有输入/输出对的微调训练语料库,端到端训练检索器和生成器:
(1)微调的部分:a)查询编码器;b)生成器
。
(2)损失函数:最小化每个目标的负边际对数似然性。其中:
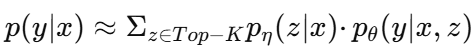
整个过程用一句话来概括,就是**"给一个题目(x),需要你写出答案(y),但我不告诉你该查哪本书(z),你自己决定查什么书,但你必须把最终答案写对(y)。"**
3.2 推理
两种模型不同,推理方式也有所区别。
3.2.1 RAG-Token(推荐,常用)
(1)核心思想:每一个 token 都可以"动态选择"不同的文档,它是Token级的计算。对于第 t 个token:
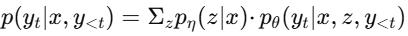
(2)解码方式:
-
直接用标准的束搜索(Beam Search);
-
和普通 seq2seq 几乎一样,只是 token 概率是"加权和"。
(3)生成过程:
a)得到当前时间步 t 输出 token 的概率分布后,取 top-K 个概率,提取出它们的 token id,先通过解码算法(本工作是 beam search,给概率取对数,得到 top-B(K>B)个 token 的概率及其对应的 token id),然后通过 tokenizer decode,得到最终的输出单词(B个)。
b)然后计算下一时间步t+1输出 token 的概率分布,得到 token id 后先 top-K,再取对数,再 top-B,通过 tokenizer decode,得到输出的单词(B个);
c)时间步t+1生成的B个单词合并到时间步t生成的B个单词后面(总共条序列),然后取top-B个对数概率和最大的序列;
d)重复 **"RAG-Token 概率计算 → beam 扩展",**直到<EOS>。最终将对数概率最大的序列作为最终生成的序列。
(4)示例:
python
The → middle → ear → includes → the → tympanic → cavity → and → the → three → ossicles3.2.2 RAG-Sequence(论文中更复杂)
(1)核心思想:整个序列由"同一篇文章"负责。
(2)解码方式:
-
对每个 z_i 单独跑一次 Beam Search
-
得到候选序列集合 Y
-
再计算:
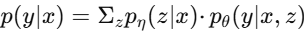
3.3 训练与推理的比较
极简总结:
(1)训练阶段,RAG 优化的是边缘概率,不涉及解码;
(2)推理阶段,RAG 构造的是逐 token 的可解码分布,用于近似求解 。

四、总结
这项工作提出了可以访问参数和非参数存储器的混合生成模型,为检索增强生成(RAG)奠定基础。
(1)之前有大量的工作提出了用非参数存储器丰富系统的架构,这些存储器是为特定任务从头开始训练的,例如存储器网络、堆栈增强网络和存储器层;
(2)相比之下,这项工作探索了一种环境,在这种环境中,参数和非参数存储组件都经过预训练,并预先加载了大量知识。至关重要的是,通过使用预先训练的访问机制,无需额外培训即可访问知识。