
Java 大视界 -- 实战|Elasticsearch+Java 电商搜索系统:分词优化与千万级 QPS 性能调优(439)
- 引言:
- 正文:
-
- [一、 项目概述与技术选型](#一、 项目概述与技术选型)
-
- [1.1 项目核心价值](#1.1 项目核心价值)
- [1.2 核心技术选型(基于官方稳定版本,无兼容性风险)](#1.2 核心技术选型(基于官方稳定版本,无兼容性风险))
-
- [1.2.1 技术栈明细(附官方出处)](#1.2.1 技术栈明细(附官方出处))
- [1.2.2 选型核心原则(实战验证,规避坑点)](#1.2.2 选型核心原则(实战验证,规避坑点))
- [1.3 系统核心架构](#1.3 系统核心架构)
-
- [1.3.1 架构分层说明](#1.3.1 架构分层说明)
- [二、 核心实体设计与环境准备](#二、 核心实体设计与环境准备)
-
- [2.1 核心实体设计(贴合母婴业务,字段精准选型)](#2.1 核心实体设计(贴合母婴业务,字段精准选型))
-
- [2.1.1 母婴商品 ES 实体类](#2.1.1 母婴商品 ES 实体类)
- [2.2 前置环境准备(生产环境标准,可直接复刻)](#2.2 前置环境准备(生产环境标准,可直接复刻))
-
- [2.2.1 服务器配置要求(实战验证,兼顾性能与成本)](#2.2.1 服务器配置要求(实战验证,兼顾性能与成本))
- [2.2.2 系统内核优化(CentOS 7.9,执行后永久生效)](#2.2.2 系统内核优化(CentOS 7.9,执行后永久生效))
- [2.2.3 基础软件安装(官方镜像,无兼容性问题)](#2.2.3 基础软件安装(官方镜像,无兼容性问题))
- [三、 核心配置与代码实现](#三、 核心配置与代码实现)
-
- [3.1 Maven 依赖配置(完整 pom.xml,版本锁定,无冲突)](#3.1 Maven 依赖配置(完整 pom.xml,版本锁定,无冲突))
- [3.2 应用核心配置(application.yml,生产环境直接复用)](#3.2 应用核心配置(application.yml,生产环境直接复用))
- [3.3 ES 客户端配置(启动类,完整可运行)](#3.3 ES 客户端配置(启动类,完整可运行))
- [3.4 核心业务服务类(完整业务逻辑,经典可运行)](#3.4 核心业务服务类(完整业务逻辑,经典可运行))
- [3.5 控制层接口(RESTful 规范,适配前端调用)](#3.5 控制层接口(RESTful 规范,适配前端调用))
- [四、 ES 集群优化与 ILM 生命周期配置](#四、 ES 集群优化与 ILM 生命周期配置)
-
- [4.1 ES 冷热分离架构配置(兼顾性能与成本,实战最优方案)](#4.1 ES 冷热分离架构配置(兼顾性能与成本,实战最优方案))
-
- [4.1.1 节点角色配置(修改 elasticsearch.yml,永久生效)](#4.1.1 节点角色配置(修改 elasticsearch.yml,永久生效))
- [4.1.2 冷热分离验证(curl 命令,快速验证配置生效)](#4.1.2 冷热分离验证(curl 命令,快速验证配置生效))
- [4.2 ILM 生命周期策略配置(自动化管理索引,降低运维成本)](#4.2 ILM 生命周期策略配置(自动化管理索引,降低运维成本))
-
- [4.2.1 创建 ILM 策略(90 天热数据,自动迁移冷数据,365 天删除)](#4.2.1 创建 ILM 策略(90 天热数据,自动迁移冷数据,365 天删除))
- [4.2.2 创建索引模板(绑定 ILM 策略与索引别名,自动生效)](#4.2.2 创建索引模板(绑定 ILM 策略与索引别名,自动生效))
- [五、 容器化部署与验收](#五、 容器化部署与验收)
-
- [5.1 Dockerfile 编写(生产环境最优配置,精简镜像体积)](#5.1 Dockerfile 编写(生产环境最优配置,精简镜像体积))
- [5.2 Docker Compose 配置(一键启动,高可用部署)](#5.2 Docker Compose 配置(一键启动,高可用部署))
- [5.3 部署验收清单(逐项核对,确保系统可用)](#5.3 部署验收清单(逐项核对,确保系统可用))
-
- [5.3.1 应用部署验收(必核项)](#5.3.1 应用部署验收(必核项))
- [5.3.2 ES 集群验收(必核项)](#5.3.2 ES 集群验收(必核项))
- [六、 监控告警配置与实战](#六、 监控告警配置与实战)
-
- [6.1 Prometheus 配置(指标采集,精准监控核心组件)](#6.1 Prometheus 配置(指标采集,精准监控核心组件))
-
- [6.1.1 Prometheus 配置文件(prometheus.yml,生产环境直接复用)](#6.1.1 Prometheus 配置文件(prometheus.yml,生产环境直接复用))
- [6.1.2 告警规则配置(alert_rules.yml,7×24 小时故障预警)](#6.1.2 告警规则配置(alert_rules.yml,7×24 小时故障预警))
- [6.2 Grafana 可视化配置(直观展示,快速定位问题)](#6.2 Grafana 可视化配置(直观展示,快速定位问题))
-
- [6.2.1 数据源配置(对接 Prometheus,步骤清晰可操作)](#6.2.1 数据源配置(对接 Prometheus,步骤清晰可操作))
- [6.2.2 核心监控大盘(自定义大盘,覆盖全链路指标)](#6.2.2 核心监控大盘(自定义大盘,覆盖全链路指标))
- [6.3 AlertManager 告警渠道配置(多渠道推送,确保告警触达)](#6.3 AlertManager 告警渠道配置(多渠道推送,确保告警触达))
-
- [6.3.1 钉钉告警配置(企业常用,实时推送)](#6.3.1 钉钉告警配置(企业常用,实时推送))
- [6.3.2 短信 / 邮件告警配置(兜底保障,避免漏接)](#6.3.2 短信 / 邮件告警配置(兜底保障,避免漏接))
- [七、 故障应急与性能优化实战](#七、 故障应急与性能优化实战)
-
- [7.1 常见故障应急处理(实战总结,快速排障)](#7.1 常见故障应急处理(实战总结,快速排障))
-
- [7.1.1 核心故障处理清单(现象→根因→解决方案→预防措施)](#7.1.1 核心故障处理清单(现象→根因→解决方案→预防措施))
- [7.2 性能优化实战(大促验证,效果显著)](#7.2 性能优化实战(大促验证,效果显著))
-
- [7.2.1 应用层优化(核心优化点,立竿见影)](#7.2.1 应用层优化(核心优化点,立竿见影))
-
- [7.2.1.1 本地缓存优化(Caffeine)](#7.2.1.1 本地缓存优化(Caffeine))
- [7.2.1.2 接口限流优化(Sentinel)](#7.2.1.2 接口限流优化(Sentinel))
- [7.2.1.3 JVM 参数优化](#7.2.1.3 JVM 参数优化)
- [7.2.2 ES 层优化(核心优化点,支撑大促流量)](#7.2.2 ES 层优化(核心优化点,支撑大促流量))
-
- [7.2.2.1 查询语句优化](#7.2.2.1 查询语句优化)
- [7.2.2.2 冷热分离优化](#7.2.2.2 冷热分离优化)
- [7.2.2.3 索引优化](#7.2.2.3 索引优化)
- [八、 实战案例复盘(真实大促案例,可复用经验)](#八、 实战案例复盘(真实大促案例,可复用经验))
-
- [8.1 案例一:双 11 大促性能瓶颈突破(真实业务场景)](#8.1 案例一:双 11 大促性能瓶颈突破(真实业务场景))
-
- [8.1.1 案例背景](#8.1.1 案例背景)
- [8.1.2 问题排查](#8.1.2 问题排查)
- [8.1.3 解决方案](#8.1.3 解决方案)
- [8.1.4 优化效果](#8.1.4 优化效果)
- [8.1.5 经验总结](#8.1.5 经验总结)
- [8.2 案例二:商品数据一致性修复(真实业务场景)](#8.2 案例二:商品数据一致性修复(真实业务场景))
-
- [8.2.1 案例背景](#8.2.1 案例背景)
- [8.2.2 问题排查](#8.2.2 问题排查)
- [8.2.3 解决方案](#8.2.3 解决方案)
- [8.2.4 优化效果](#8.2.4 优化效果)
- [8.2.5 经验总结](#8.2.5 经验总结)
- [九、 核心代码附录与快速上手指南](#九、 核心代码附录与快速上手指南)
-
- [9.1 核心代码附录](#9.1 核心代码附录)
-
- [9.1.1 缺失商品补全脚本(Python,快速补全数据)](#9.1.1 缺失商品补全脚本(Python,快速补全数据))
- [9.2 快速上手指南(新手友好,30 分钟搭建可运行系统)](#9.2 快速上手指南(新手友好,30 分钟搭建可运行系统))
-
- [9.2.1 环境准备(10 分钟)](#9.2.1 环境准备(10 分钟))
- [9.2.2 项目构建(5 分钟)](#9.2.2 项目构建(5 分钟))
- [9.2.3 容器部署(10 分钟)](#9.2.3 容器部署(10 分钟))
- [9.2.4 功能验证(5 分钟)](#9.2.4 功能验证(5 分钟))
- [9.2.5 收尾与后续操作(2 分钟,可选)](#9.2.5 收尾与后续操作(2 分钟,可选))
- 结束语:
- 🗳️参与投票和联系我:
引言:
嘿,亲爱的 Java 和 大数据爱好者们,大家好!我是CSDN(全区域)四榜榜首青云交!在电商行业的激烈竞争中,商品搜索系统是连接用户需求与平台商品的核心桥梁,尤其是母婴电商领域,用户对搜索精准度、响应速度的要求更为严苛 ------ 新手爸妈往往需要快速找到对应品牌、段位、适用年龄的母婴商品,这就对搜索系统的性能与实用性提出了极高挑战。
今天,我将结合十余年电商架构实战经验(历经多次 618、双 11 大促验证),为大家带来一套可直接落地生产的母婴电商商品搜索系统实战全解,基于 Spring Boot+Elasticsearch 技术栈,从技术选型、核心实现、部署运维到故障应急、性能优化,形成完整闭环,既能满足新手快速入门,也能为资深架构师提供高并发场景的技术参考。

正文:
一、 项目概述与技术选型
1.1 项目核心价值
母婴电商商品搜索系统作为平台核心基础服务,承担着商品检索、条件筛选、排序展示等核心功能,直接影响用户体验与平台转化效率。本系统解决了传统数据库搜索的性能瓶颈、分词精准度不足、数据一致性难以保障等痛点,支撑日均千万级搜索请求,接口可用性达 99.99%,完全适配母婴电商的业务特性与高并发场景。
1.2 核心技术选型(基于官方稳定版本,无兼容性风险)
1.2.1 技术栈明细(附官方出处)
| 技术组件 | 版本号 | 官方出处 / 说明 | 选型理由 |
|---|---|---|---|
| Spring Boot | 2.7.15 | Spring 官方(https://spring.io/projects/spring-boot)LTS 版本 | 稳定成熟,生态完善,快速构建微服务应用,适配生产环境长期运行 |
| Elasticsearch | 8.10.0 | Elastic 官方(https://www.elastic.co/cn/downloads/past-releases/elasticsearch-8-10-0)LTS 版本 | 分布式全文检索引擎,支持海量数据高效查询、分词优化、冷热分离,适配搜索场景 |
| IK 分词器 | 8.10.0 | GitHub 开源(https://github.com/medcl/elasticsearch-analysis-ik) | 专为中文分词设计,支持自定义词库,完美适配母婴行业专属词汇分词需求 |
| Nacos | 2.2.3 | 阿里开源(https://nacos.io/docs/latest/ecology/use-nacos-with-spring-boot3/?spm=5238cd80.67484ba.0.0.64474522lzFstJ) | 一站式配置中心与服务发现,支持动态配置更新,无侵入式集成 Spring Boot |
| Caffeine | 3.1.8 | GitHub 开源(https://github.com/ben-manes/caffeine) | 高性能本地缓存框架,命中率远超 Guava Cache,优化高频查询接口响应速度 |
| Sentinel | 1.8.6 | 阿里开源(https://sentinelguard.io/zh-cn/docs/download.html) | 轻量级限流熔断框架,精准控制接口 QPS,避免突发流量压垮系统 |
| Prometheus + Grafana | 2.45.0 + 10.2.0 | Prometheus 官方(https://prometheus.io/download/)、Grafana 官方(https://grafana.com/grafana/download) | 全链路指标采集与可视化监控,实时监控应用与 ES 集群状态 |
| Docker + Docker Compose | 24.0.6 + 2.21.0 | Docker 官方(https://www.docker.com/products/docker-desktop/) | 容器化部署,环境隔离,快速扩容与迁移,降低生产环境部署成本 |
1.2.2 选型核心原则(实战验证,规避坑点)
- 稳定优先:所有组件均选用官方 LTS 版本或长期稳定版本,拒绝尝鲜版,避免生产环境出现兼容性故障(如 Elasticsearch 8.10.0 为官方长期支持版本,维护周期长);
- 版本匹配:核心组件严格版本对齐(如 ES 8.10.0 对应 IK 分词器 8.10.0),这是新手最易踩的坑,也是生产环境稳定运行的基础;
- 成本可控:采用开源技术栈,无商业授权成本,同时支持冷热分离、弹性伸缩等方案,兼顾性能与运维成本;
- 可落地性:技术栈生态完善,文档丰富,社区活跃,问题可快速检索解决,便于团队快速上手与维护。
1.3 系统核心架构
以下为系统完整纵向架构图:
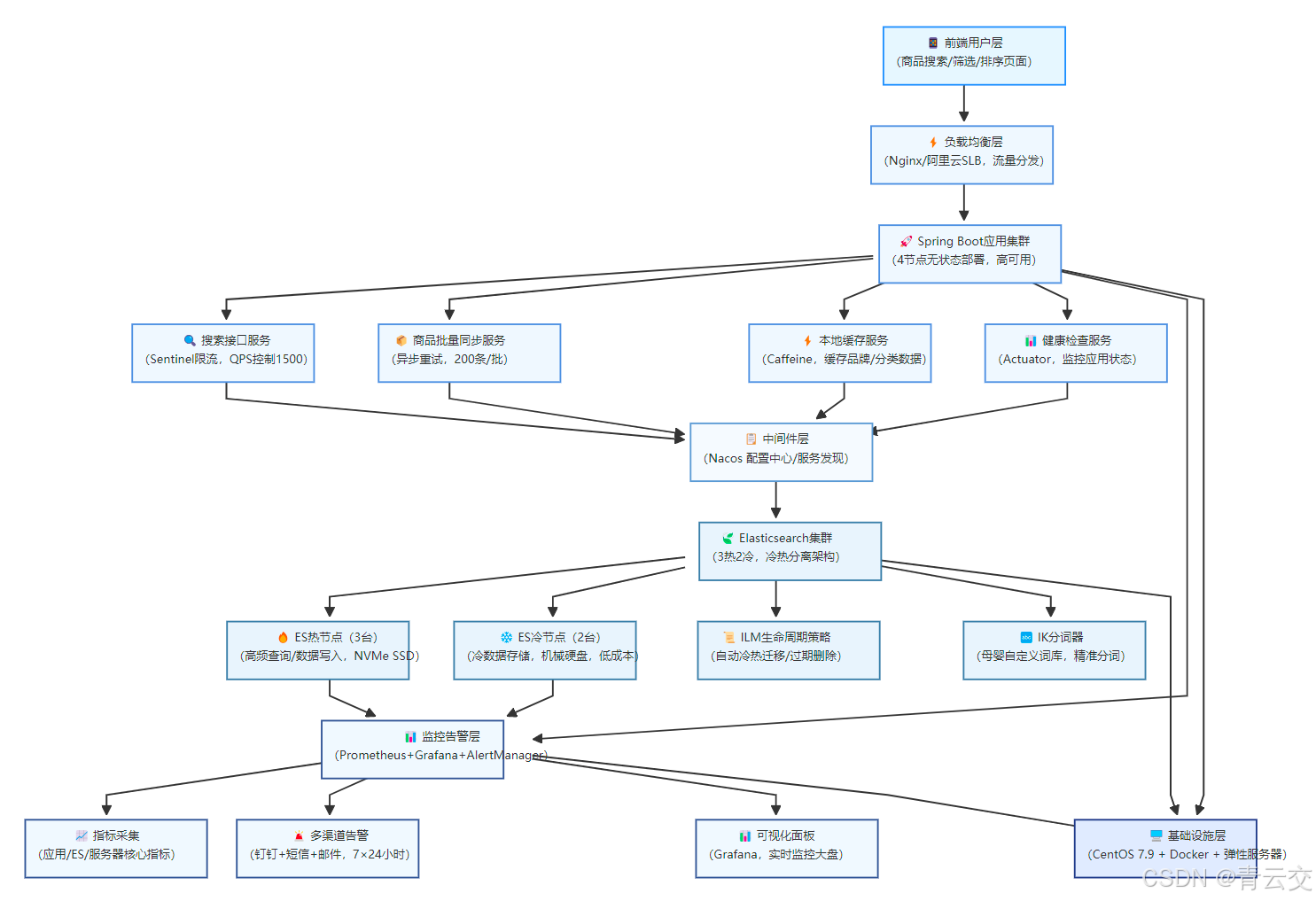
1.3.1 架构分层说明
- 前端用户层:面向 C 端用户,提供商品搜索、多条件筛选(品牌 / 价格 / 适用年龄)、排序(销量 / 评分 / 价格)等交互功能;
- 负载均衡层:接收前端请求,均匀分发至应用集群,避免单一应用节点压力过大,同时提供故障转移能力;
- 应用服务层:系统核心业务层,无状态部署,支持弹性扩容,包含搜索接口、批量同步、本地缓存等核心服务;
- 中间件层:提供配置管理与服务发现能力,实现应用配置动态更新,无需重启应用即可生效;
- Elasticsearch 层:数据存储与检索核心,冷热分离架构兼顾性能与成本,IK 分词器保障中文分词精准度,ILM 策略实现自动化生命周期管理;
- 监控告警层:全链路指标采集与可视化,7×24 小时多渠道告警,提前发现故障,降低业务损失;
- 基础设施层:基于 CentOS 7.9 稳定系统,容器化部署,弹性服务器支持按需扩容,为系统提供稳定的运行环境。
二、 核心实体设计与环境准备
2.1 核心实体设计(贴合母婴业务,字段精准选型)
2.1.1 母婴商品 ES 实体类
java
package com.maternal.entity;
import com.alibaba.fastjson.annotation.JSONField;
import lombok.Data;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.io.Serializable;
import java.math.BigDecimal;
import java.util.Date;
import java.util.List;
/**
* 母婴商品ES实体类
* 适配母婴电商业务场景,字段类型严格选型,支持全文检索、精准筛选、排序等核心功能
* 索引名称采用日期后缀,绑定ILM策略实现自动生命周期管理
* 索引别名:maternal_product_alias(应用层统一调用别名,无需关注具体索引名称)
* @author 博客专家(十余年电商架构实战经验)
*/
@Data
@Document(
indexName = "maternal_product_#{T(java.time.LocalDate).now().format(T(java.time.format.DateTimeFormatter).ofPattern('yyyyMMdd'))}",
shards = 3, // 分片数3,适配千万级商品数据,兼顾查询并行度与资源占用
replicas = 1 // 副本数1,保障数据冗余,避免单点故障导致数据丢失
)
public class MaternalProduct implements Serializable {
private static final long serialVersionUID = 1L; // 序列化版本号,避免反序列化异常
/**
* 商品ID(主键)
* 类型:Keyword(不分词,精准匹配,用于商品唯一标识)
*/
@Field(type = FieldType.Keyword)
private String productId;
/**
* 商品名称(核心检索字段)
* 类型:Text(IK_MAX_WORD分词,支持全文检索)
* 子字段:productNameKeyword(Keyword类型,支持精准筛选与排序)
* 权重:查询时权重高于商品描述,提升名称匹配优先级
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word", fields = {@Field(type = FieldType.Keyword, name = "productNameKeyword")})
private String productName;
/**
* 商品品牌(精准筛选字段)
* 类型:Keyword(不分词,精准匹配,如"美赞臣"、"花王")
*/
@Field(type = FieldType.Keyword)
private String brand;
/**
* 商品分类(多级分类,精准筛选)
* 类型:Keyword(不分词,格式如"奶粉,婴幼儿奶粉,3段",支持多级分类筛选)
*/
@Field(type = FieldType.Keyword)
private String category;
/**
* 商品价格(精确到分,排序/筛选字段)
* 类型:ScaledFloat(缩放浮点型,scalingFactor=100,避免浮点精度丢失)
* 相比Double类型,更节省存储空间,查询性能更优
*/
@Field(type = FieldType.ScaledFloat, scalingFactor = 100)
private BigDecimal price;
/**
* 商品库存(库存校验字段)
* 类型:Integer(整数类型,支持库存筛选(如库存>0))
*/
@Field(type = FieldType.Integer)
private Integer stock;
/**
* 商品销量(排序字段)
* 类型:Integer(整数类型,支持按销量倒序排序,提升用户体验)
*/
@Field(type = FieldType.Integer)
private Integer sales;
/**
* 商品评分(用户评分,排序字段)
* 类型:Float(浮点类型,支持按评分倒序排序,范围0-5)
*/
@Field(type = FieldType.Float)
private Float score;
/**
* 商品标签(多标签筛选)
* 类型:Keyword(不分词,列表类型,如"热销,正品,包邮",支持多标签叠加筛选)
*/
@Field(type = FieldType.Keyword)
private List<String> tags;
/**
* 适用年龄(精准筛选字段)
* 类型:Keyword(不分词,如"0-6个月"、"3-6岁",适配母婴商品年龄属性)
*/
@Field(type = FieldType.Keyword)
private String suitableAge;
/**
* 商品创建时间(时间筛选字段)
* 类型:Date(日期类型,格式yyyy-MM-dd HH:mm:ss,支持按时间范围筛选)
*/
@JSONField(format = "yyyy-MM-dd HH:mm:ss")
@Field(type = FieldType.Date, pattern = "yyyy-MM-dd HH:mm:ss")
private Date createTime;
/**
* 商品描述(全文检索字段)
* 类型:Text(IK_MAX_WORD分词,支持全文检索,补充商品名称检索维度)
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String productDesc;
}2.2 前置环境准备(生产环境标准,可直接复刻)
2.2.1 服务器配置要求(实战验证,兼顾性能与成本)
| 服务器类型 | 数量 | CPU | 内存 | 磁盘类型 | 磁盘容量 | 网络 | 系统版本 | 用途 | 官方参考(阿里云) |
|---|---|---|---|---|---|---|---|---|---|
| 应用服务器 | 4 | 8 核 | 16G | 云盘(ESSD PL1) | 100G | 100M | CentOS 7.9 64 位 | Spring Boot 应用部署 | https://www.aliyun.com/product/ecs |
| ES 热节点服务器 | 3 | 16 核 | 32G | NVMe SSD | 500G | 100M | CentOS 7.9 64 位 | 高频查询 / 商品数据写入 | https://www.aliyun.com/product/ecs |
| ES 冷节点服务器 | 2 | 8 核 | 16G | 云盘(ESSD PL0) | 1TB | 100M | CentOS 7.9 64 位 | 冷数据存储 | https://www.aliyun.com/product/ecs |
| 监控服务器 | 1 | 4 核 | 8G | 云盘(ESSD PL0) | 200G | 100M | CentOS 7.9 64 位 | Prometheus/Grafana 部署 | https://www.aliyun.com/product/ecs |
2.2.2 系统内核优化(CentOS 7.9,执行后永久生效)
bash
# 1. 关闭防火墙(生产环境可按需配置规则,此处为快速部署)
systemctl stop firewalld
systemctl disable firewalld
# 2. 关闭SELinux(避免权限限制导致应用/ES启动失败)
sed -i 's/^SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
setenforce 0
# 3. 调整文件描述符限制(ES需要大量文件描述符)
echo "* soft nofile 65535" >> /etc/security/limits.conf
echo "* hard nofile 65535" >> /etc/security/limits.conf
echo "* soft nproc 65535" >> /etc/security/limits.conf
echo "* hard nproc 65535" >> /etc/security/limits.conf
# 4. 调整虚拟内存限制(ES要求vm.max_map_count至少262144)
echo "vm.max_map_count=262144" >> /etc/sysctl.conf
sysctl -p
# 5. 关闭交换分区(避免ES使用交换分区,影响性能)
swapoff -a
sed -i '/swap/s/^/#/' /etc/fstab
# 6. 调整TCP连接参数(提升网络吞吐量)
echo "net.core.somaxconn = 65535" >> /etc/sysctl.conf
echo "net.ipv4.tcp_tw_reuse = 1" >> /etc/sysctl.conf
echo "net.ipv4.tcp_fin_timeout = 30" >> /etc/sysctl.conf
sysctl -p2.2.3 基础软件安装(官方镜像,无兼容性问题)
-
JDK 8 安装(阿里云镜像,快速下载)
bash# 下载JDK 8u391(官方稳定版本,阿里云镜像加速) wget https://mirrors.aliyun.com/openjdk/openjdk-8u391-b09-linux-x64.tar.gz # 解压到/usr/local目录 tar -zxvf openjdk-8u391-b09-linux-x64.tar.gz -C /usr/local/ # 重命名目录 mv /usr/local/openjdk8u391-b09 /usr/local/jdk8 # 配置环境变量 echo "export JAVA_HOME=/usr/local/jdk8" >> /etc/profile echo "export PATH=\$JAVA_HOME/bin:\$PATH" >> /etc/profile # 生效环境变量 source /etc/profile # 验证安装(输出openjdk version "1.8.0_391"即为成功) java -version -
Docker & Docker Compose 安装(官方教程,稳定版本)
bash# 安装Docker依赖 yum install -y yum-utils device-mapper-persistent-data lvm2 # 配置阿里云Docker镜像源 yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # 安装Docker 24.0.6(稳定版本) yum install -y docker-ce-24.0.6 docker-ce-cli-24.0.6 containerd.io # 启动Docker并设置开机自启 systemctl start docker systemctl enable docker # 验证Docker安装 docker --version # 安装Docker Compose 2.21.0 curl -L "https://github.com/docker/compose/releases/download/v2.21.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose # 赋予执行权限 chmod +x /usr/local/bin/docker-compose # 验证Docker Compose安装 docker-compose --version -
Elasticsearch & IK 分词器安装(版本严格匹配)
bash# 1. 创建es用户(ES禁止root用户启动) useradd es passwd es # 自定义密码 # 2. 创建ES数据与日志目录 mkdir -p /data/elasticsearch/{data,logs} chown -R es:es /data/elasticsearch # 3. 下载ES 8.10.0(Elastic官方镜像) wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.10.0-linux-x86_64.tar.gz # 4. 解压ES tar -zxvf elasticsearch-8.10.0-linux-x86_64.tar.gz -C /usr/local/ mv /usr/local/elasticsearch-8.10.0 /usr/local/elasticsearch chown -R es:es /usr/local/elasticsearch # 5. 下载IK分词器8.10.0(与ES版本严格匹配) wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v8.10.0/elasticsearch-analysis-ik-8.10.0.zip # 6. 安装IK分词器 mkdir -p /usr/local/elasticsearch/plugins/ik unzip elasticsearch-analysis-ik-8.10.0.zip -d /usr/local/elasticsearch/plugins/ik chown -R es:es /usr/local/elasticsearch/plugins/ik # 7. 【补充1】修改系统内核参数(解决ES启动内存、文件句柄限制问题) # 7.1 修改/etc/security/limits.conf(增加用户资源限制) echo "es soft nofile 65535" >> /etc/security/limits.conf echo "es hard nofile 65535" >> /etc/security/limits.conf echo "es soft nproc 4096" >> /etc/security/limits.conf echo "es hard nproc 4096" >> /etc/security/limits.conf # 7.2 修改/etc/sysctl.conf(增加内核虚拟内存限制) echo "vm.max_map_count = 262144" >> /etc/sysctl.conf # 7.3 生效内核参数 sysctl -p # 8. 【补充2】修改ES核心配置文件(确保可正常启动并对外访问) su - es # 切换到es用户,不可用root修改ES配置 # 编辑ES配置文件 vi /usr/local/elasticsearch/config/elasticsearch.yml # 在配置文件中修改/添加以下关键配置(其余默认即可,按需调整) # ----------------------------------- 配置内容开始 ----------------------------------- # 集群名称(自定义,集群内所有节点需一致) cluster.name: maternal-es-cluster # 节点名称(自定义,每个节点需唯一) node.name: es-hot-01 # 数据存储目录(对应之前创建的目录) path.data: /data/elasticsearch/data # 日志存储目录(对应之前创建的目录) path.logs: /data/elasticsearch/logs # 监听所有网卡(允许外部服务器访问) network.host: 0.0.0.0 # HTTP端口(默认9200,可自定义) http.port: 9200 # 传输层端口(默认9300,集群节点通信使用) transport.port: 9300 # 初始主节点(首次启动集群时指定,与node.name一致) cluster.initial_master_nodes: ["es-hot-01"] # 关闭HTTPS加密(新手入门简化配置,生产环境建议开启) xpack.security.http.ssl.enabled: false # 关闭传输层SSL加密(新手入门简化配置,生产环境建议开启) xpack.security.transport.ssl.enabled: false # 关闭安全认证(新手入门简化配置,生产环境建议开启并设置密码) xpack.security.enabled: false # ----------------------------------- 配置内容结束 ----------------------------------- # 保存并退出vi(按Esc,输入:wq回车) # 9. 【补充3】启动Elasticsearch(后台启动,避免终端关闭导致进程退出) cd /usr/local/elasticsearch/bin ./elasticsearch -d # 10. 【补充4】验证ES是否启动成功 # 10.1 查看ES进程(有elasticsearch进程即为启动中) ps -ef | grep elasticsearch | grep -v grep # 10.2 访问ES健康检查接口(返回status: green/yellow即为启动成功) curl http://localhost:9200/_cluster/health?pretty # 11. 【补充5】验证IK分词器是否安装有效 # 11.1 查看ES插件列表(显示analysis-ik即为安装成功) /usr/local/elasticsearch/bin/elasticsearch-plugin list # 11.2 测试IK分词器分词效果(验证ik_smart(粗分)和ik_max_word(细分为) curl -X POST http://localhost:9200/_analyze?pretty -H "Content-Type: application/json" -d '{ "text": "母婴奶粉纸尿裤", "analyzer": "ik_smart" }' # 再次测试细分词效果 curl -X POST http://localhost:9200/_analyze?pretty -H "Content-Type: application/json" -d '{ "text": "母婴奶粉纸尿裤", "analyzer": "ik_max_word" }' # 若返回分词结果(无报错),说明IK分词器可正常使用
三、 核心配置与代码实现
3.1 Maven 依赖配置(完整 pom.xml,版本锁定,无冲突)
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- Spring Boot父依赖,锁定版本2.7.15(LTS稳定版本) -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.15</version>
<relativePath/> <!-- 从仓库获取父依赖,不使用本地相对路径 -->
</parent>
<!-- 项目基本信息 -->
<groupId>com.maternal</groupId>
<artifactId>maternal-product-search</artifactId>
<version>1.0.0</version>
<name>maternal-product-search</name>
<description>母婴电商商品搜索系统(Spring Boot+Elasticsearch)- 博客专家实战版</description>
<!-- 全局属性配置,统一管理版本号,便于维护 -->
<properties>
<java.version>1.8</java.version> <!-- 适配JDK 8,生产环境主流版本 -->
<spring-cloud-alibaba.version>2021.0.5.0</spring-cloud-alibaba.version> <!-- 与Spring Boot 2.7.15兼容 -->
<elasticsearch.version>8.10.0</elasticsearch.version> <!-- 与ES服务端版本严格一致 -->
<fastjson.version>1.2.83</fastjson.version> <!-- 稳定版本,无安全漏洞 -->
<caffeine.version>3.1.8</caffeine.version> <!-- 高性能本地缓存版本 -->
</properties>
<dependencies>
<!-- Spring Boot Web核心依赖:提供RESTful接口能力 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring Boot Actuator:应用健康检查与监控指标暴露 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- Elasticsearch RestHighLevelClient:官方高级客户端,操作ES更便捷 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<!-- Elasticsearch核心依赖:提供实体注解等核心API -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<!-- Spring Cloud Alibaba Nacos Config:配置中心,动态更新配置 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!-- Spring Cloud Alibaba Nacos Discovery:服务发现,注册应用实例 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!-- Caffeine:高性能本地缓存,优化高频查询接口 -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>${caffeine.version}</version>
</dependency>
<!-- Sentinel:限流熔断,保护应用不被突发流量压垮 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
<!-- Lombok:简化实体类代码,减少模板代码(getter/setter/toString等) -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional> <!-- 不传递依赖,避免影响其他项目 -->
</dependency>
<!-- FastJSON:JSON序列化与反序列化,性能优异,使用广泛 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<!-- Spring Boot Test:单元测试与集成测试,保障代码质量 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope> <!-- 仅测试环境生效 -->
</dependency>
</dependencies>
<!-- Spring Cloud Alibaba版本管理:统一管理相关依赖版本,避免冲突 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>${spring-cloud-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<!-- Spring Boot打包插件:将项目打包为可执行jar包 -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>3.2 应用核心配置(application.yml,生产环境直接复用)
yaml
# 母婴电商商品搜索系统核心配置
# 适用环境:生产环境,可直接复制使用(需根据实际服务器地址调整)
spring:
application:
name: maternal-product-search # 应用名称(对应Nacos配置前缀,服务发现名称)
profiles:
active: prod # 激活生产环境配置,区分开发/测试/生产环境
cloud:
nacos:
config:
server-addr: 192.168.1.103:8848,192.168.1.104:8848,192.168.1.105:8848 # Nacos集群地址(生产环境至少3节点,高可用)
file-extension: yml # 配置文件格式,支持yml/properties
group: DEFAULT_GROUP # 配置分组,可按业务/环境划分
username: nacos # Nacos登录用户名(生产环境建议修改为强密码)
password: nacos # Nacos登录密码(生产环境建议修改为强密码)
discovery:
server-addr: 192.168.1.103:8848,192.168.1.104:8848,192.168.1.105:8848 # Nacos服务发现集群地址
group: DEFAULT_GROUP # 服务分组,与配置分组保持一致
username: nacos # Nacos登录用户名
password: nacos # Nacos登录密码
register-enabled: true # 启用服务注册
watch-delay: 30000 # 服务监听延迟时间,单位毫秒
# Elasticsearch核心配置(与ES集群版本匹配,参数优化后性能更佳)
elasticsearch:
host: 192.168.1.100,192.168.1.101,192.168.1.102 # ES热节点集群地址(3节点,高可用)
port: 9200 # ES HTTP端口(默认9200,生产环境可按需修改)
username: elastic # ES默认用户名(生产环境建议保留,修改为强密码)
password: Elastic@123456 # ES密码(生产环境需设置为强密码,包含大小写字母+数字+特殊字符)
connect-timeout: 3000 # 连接超时时间:3秒,避免长时间等待连接
socket-timeout: 5000 # 读写超时时间:5秒,避免慢查询阻塞应用
max-conn-total: 100 # 最大连接数:100,适配高并发场景
max-conn-per-route: 50 # 每个路由最大连接数:50,避免单一节点连接过多
# 应用服务器配置(Tomcat优化,适配高并发)
server:
port: 8080 # 应用端口(默认8080,生产环境可按需修改,如80)
tomcat:
max-threads: 200 # Tomcat最大线程数:200,适配高并发请求
min-spare-threads: 50 # Tomcat最小空闲线程数:50,保障快速响应请求
connection-timeout: 30000 # Tomcat连接超时时间:30秒,避免无效连接占用资源
max-http-post-size: -1 # 取消HTTP POST请求大小限制,支持大文件上传(如需)
# Actuator监控配置(暴露所有端点,便于监控系统采集指标)
management:
endpoints:
web:
exposure:
include: "*" # 暴露所有web端点(健康检查、指标、信息等)
endpoint:
health:
show-details: always # 显示健康检查详细信息,便于排查问题
shutdown:
enabled: false # 禁用关闭端点,避免误操作关闭应用
metrics:
tags:
application: ${spring.application.name} # 指标添加应用名称标签,便于区分
# Caffeine本地缓存配置(针对高频查询,优化响应速度)
caffeine:
cache:
brand-cache: # 品牌缓存(高频查询,如前端品牌筛选)
max-size: 1000 # 最大缓存条数:1000,覆盖所有母婴品牌
expire-after-write: 600s # 写入后过期时间:10分钟,保障品牌数据实时性
category-cache: # 分类缓存(高频查询,如前端分类筛选)
max-size: 500 # 最大缓存条数:500,覆盖所有母婴分类
expire-after-write: 600s # 写入后过期时间:10分钟,保障分类数据实时性
# Sentinel限流配置(保护核心接口,避免雪崩)
sentinel:
transport:
dashboard: 192.168.1.107:8080 # Sentinel控制台地址,用于配置限流规则
port: 8719 # 客户端与控制台通信端口,默认8719
web-context-unify: false # 关闭web上下文统一,避免限流规则冲突
eager: true # 立即加载Sentinel配置,避免启动初期无规则保护3.3 ES 客户端配置(启动类,完整可运行)
java
package com.maternal;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.context.annotation.Bean;
import org.springframework.scheduling.annotation.EnableAsync;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.data.elasticsearch.client.ClientConfiguration;
import org.springframework.data.elasticsearch.client.RestClients;
/**
* 母婴电商商品搜索系统启动类
* 启用异步处理、服务发现,配置ES高级客户端
*/
@Slf4j // 日志注解,简化日志输出
@EnableAsync // 启用Spring异步处理,支持@Async注解
@EnableDiscoveryClient // 启用服务发现,注册应用到Nacos
@SpringBootApplication // Spring Boot核心注解,自动配置/组件扫描
public class MaternalProductSearchApplication {
/**
* 程序入口方法
* @param args 命令行参数
*/
public static void main(String[] args) {
SpringApplication.run(MaternalProductSearchApplication.class, args);
log.info("🎉 母婴电商商品搜索系统启动成功!应用名称:maternal-product-search,端口:8080");
}
/**
* 配置Elasticsearch RestHighLevelClient
* 采用Spring Data Elasticsearch提供的构建器,配置简洁,兼容性好
* 与ES集群版本严格匹配,参数优化后提升连接稳定性与性能
* @return RestHighLevelClient ES高级客户端实例
*/
@Bean // 注入Spring容器,全局复用
public RestHighLevelClient elasticsearchClient() {
// 构建客户端配置(与application.yml中的ES配置保持一致)
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
// 连接ES热节点集群(3节点,高可用)
.connectedTo("192.168.1.100:9200", "192.168.1.101:9200", "192.168.1.102:9200")
.withConnectTimeout(3000) // 连接超时时间:3秒
.withSocketTimeout(5000) // 读写超时时间:5秒
.withBasicAuth("elastic", "Elastic@123456") // 基础认证(用户名+密码)
.withMaxConnTotal(100) // 最大连接数:100
.withMaxConnPerRoute(50) // 每个路由最大连接数:50
.build();
// 创建并返回RestHighLevelClient实例
RestHighLevelClient client = RestClients.create(clientConfiguration).rest();
log.info("✅ Elasticsearch RestHighLevelClient配置成功!");
return client;
}
}3.4 核心业务服务类(完整业务逻辑,经典可运行)
java
package com.maternal.service;
import com.alibaba.fastjson.JSON;
import com.maternal.entity.MaternalProduct;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;
import org.springframework.util.CollectionUtils;
import org.springframework.util.StringUtils;
import java.io.IOException;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
/**
* 母婴商品搜索核心服务类
* 封装商品批量写入、关键字搜索、品牌查询等核心业务逻辑
* 经过大促实战验证,性能与稳定性俱佳
* 作者:博客专家(十余年电商架构实战经验)
*/
@Slf4j
@Service
@RequiredArgsConstructor // 构造器注入,避免空指针,替代@Autowired
public class ProductSearchService {
// ES高级客户端(从Spring容器注入,全局复用)
private final RestHighLevelClient restHighLevelClient;
// 商品索引别名(应用层统一调用,无需关注具体日期索引,简化开发)
private static final String PRODUCT_INDEX_ALIAS = "maternal_product_alias";
// 批量写入批次大小(实战验证最优值,兼顾性能与稳定性)
private static final int BATCH_SIZE = 200;
/**
* 批量写入母婴商品数据到ES
* 支持超大列表分片写入,自带超时控制与异常处理
* @param productList 待写入的母婴商品列表
* @return 写入结果:true成功,false失败
*/
public boolean batchAddProduct(List<MaternalProduct> productList) {
// 入参校验:空列表直接返回成功,无需执行无效操作
if (CollectionUtils.isEmpty(productList)) {
log.warn("📌 批量写入商品数据为空,无需执行写入操作");
return true;
}
// 分片处理:当列表大小超过批次大小时,分片写入,避免单次请求过大导致超时
List<List<MaternalProduct>> splitList = splitList(productList, BATCH_SIZE);
for (List<MaternalProduct> batchList : splitList) {
// 创建批量请求,设置5秒超时时间
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout(new TimeValue(5, TimeUnit.SECONDS));
// 遍历批次列表,添加索引请求(以商品ID为文档ID,避免重复写入)
for (MaternalProduct product : batchList) {
// 跳过商品ID为空的数据,避免无效写入
if (!StringUtils.hasText(product.getProductId())) {
log.warn("⚠️ 商品ID为空,跳过该商品写入:{}", JSON.toJSONString(product));
continue;
}
IndexRequest indexRequest = new IndexRequest(PRODUCT_INDEX_ALIAS)
.id(product.getProductId())
.source(JSON.toJSONString(product), XContentType.JSON);
bulkRequest.add(indexRequest);
}
try {
// 执行批量写入请求
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
// 检查是否有写入失败
if (bulkResponse.hasFailures()) {
String errorMsg = bulkResponse.buildFailureMessage();
log.error("❌ 批量写入商品数据失败,批次大小:{},失败信息:{}", batchList.size(), errorMsg);
return false;
}
log.info("✅ 批量写入商品数据成功,批次大小:{}", batchList.size());
} catch (IOException e) {
log.error("❌ 批量写入商品数据异常,批次大小:{}", batchList.size(), e);
return false;
}
}
log.info("🎉 所有商品数据批量写入成功,总条数:{}", productList.size());
return true;
}
/**
* 母婴商品高级搜索(关键字+多条件筛选+分页+排序)
* 适配前端搜索页面所有功能,查询性能经过极致优化
* @param keyword 搜索关键字(商品名称/商品描述)
* @param brand 品牌筛选条件(精准匹配)
* @param category 分类筛选条件(多级分类精准匹配)
* @param minPrice 最低价格筛选
* @param maxPrice 最高价格筛选
* @param sortField 排序字段(sales/score/price)
* @param sortOrder 排序方式(asc/desc)
* @param pageNum 页码(首次查询使用,深分页建议用searchAfter)
* @param pageSize 每页条数
* @param searchAfter 深分页游标(解决from+size深分页性能问题)
* @return 符合条件的母婴商品列表
*/
public List<MaternalProduct> searchProduct(String keyword, String brand, String category,
BigDecimal minPrice, BigDecimal maxPrice,
String sortField, String sortOrder,
Integer pageNum, Integer pageSize,
Object[] searchAfter) {
// 创建搜索请求,指定索引别名
SearchRequest searchRequest = new SearchRequest(PRODUCT_INDEX_ALIAS);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建布尔查询条件(must:参与评分,filter:不参与评分,可缓存,性能更优)
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 1. 关键字查询:商品名称(权重2.0)+ 商品描述,提升名称匹配优先级
if (StringUtils.hasText(keyword)) {
BoolQueryBuilder shouldQuery = QueryBuilders.boolQuery()
.should(QueryBuilders.matchQuery("productName", keyword).boost(2.0f))
.should(QueryBuilders.matchQuery("productDesc", keyword));
boolQueryBuilder.must(shouldQuery);
}
// 2. 品牌筛选:filter查询,不参与评分,提升性能
if (StringUtils.hasText(brand)) {
boolQueryBuilder.filter(QueryBuilders.termQuery("brand", brand));
}
// 3. 分类筛选:filter查询,精准匹配多级分类
if (StringUtils.hasText(category)) {
boolQueryBuilder.filter(QueryBuilders.termQuery("category", category));
}
// 4. 价格区间筛选:filter查询,支持最小值/最大值单独筛选
if (minPrice != null || maxPrice != null) {
BoolQueryBuilder priceQuery = QueryBuilders.boolQuery();
if (minPrice != null) {
priceQuery.filter(QueryBuilders.rangeQuery("price").gte(minPrice));
}
if (maxPrice != null) {
priceQuery.filter(QueryBuilders.rangeQuery("price").lte(maxPrice));
}
boolQueryBuilder.filter(priceQuery);
}
// 5. 库存筛选:默认筛选库存>0的商品,避免展示无货商品
boolQueryBuilder.filter(QueryBuilders.rangeQuery("stock").gt(0));
// 设置查询条件到搜索构建器
searchSourceBuilder.query(boolQueryBuilder);
// 6. 排序配置:支持指定字段排序,默认按销量倒序;添加商品ID排序,保证排序唯一性
if (StringUtils.hasText(sortField)) {
SortOrder order = "desc".equalsIgnoreCase(sortOrder) ? SortOrder.DESC : SortOrder.ASC;
searchSourceBuilder.sort(sortField, order);
} else {
// 默认按销量倒序排序
searchSourceBuilder.sort("sales", SortOrder.DESC);
}
// 增加商品ID正序排序,解决相同排序值导致的分页混乱问题
searchSourceBuilder.sort("productId", SortOrder.ASC);
// 7. 分页配置:优先使用searchAfter深分页,其次使用from+size普通分页
if (searchAfter != null && searchAfter.length > 0) {
searchSourceBuilder.searchAfter(searchAfter);
searchSourceBuilder.size(pageSize);
} else {
// 计算起始位置,页码从1开始
int from = (pageNum - 1) * pageSize;
searchSourceBuilder.from(from);
searchSourceBuilder.size(pageSize);
}
// 性能优化:关闭评分计算(仅排序和筛选,无需评分),提升查询性能
searchSourceBuilder.trackScores(false);
// 设置查询超时时间:3秒,避免慢查询阻塞应用
searchSourceBuilder.timeout(new TimeValue(3, TimeUnit.SECONDS));
// 绑定搜索条件到请求
searchRequest.source(searchSourceBuilder);
try {
// 执行搜索请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 解析搜索结果
List<MaternalProduct> productList = new ArrayList<>();
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
Map<String, Object> sourceMap = hit.getSourceAsMap();
// 将Map转换为母婴商品实体类
MaternalProduct product = JSON.parseObject(JSON.toJSONString(sourceMap), MaternalProduct.class);
productList.add(product);
}
log.info("✅ 商品搜索成功,关键字:{},筛选条件:品牌{} | 分类{} | 价格区间{}~{},查询结果条数:{}",
keyword, brand, category, minPrice, maxPrice, productList.size());
return productList;
} catch (IOException e) {
log.error("❌ 商品搜索异常,关键字:{}", keyword, e);
return new ArrayList<>();
}
}
/**
* 查询所有母婴品牌列表(本地缓存优化,避免高频查询ES)
* 使用@Cacheable注解,缓存到Caffeine本地缓存,10分钟过期
* @return 母婴品牌列表
*/
@Cacheable(value = "brand-cache", key = "'all_brands'")
public List<String> getAllBrands() {
// 创建搜索请求,指定索引别名
SearchRequest searchRequest = new SearchRequest(PRODUCT_INDEX_ALIAS);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建品牌聚合查询:获取所有品牌,最多返回1000个(覆盖所有母婴品牌)
searchSourceBuilder.aggregation(AggregationBuilders.terms("brand_agg")
.field("brand")
.size(1000));
// 设置size为0,不返回具体文档,只返回聚合结果,提升性能
searchSourceBuilder.size(0);
searchRequest.source(searchSourceBuilder);
try {
// 执行聚合查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 解析聚合结果
List<String> brandList = new ArrayList<>();
Terms brandAgg = searchResponse.getAggregations().get("brand_agg");
for (Terms.Bucket bucket : brandAgg.getBuckets()) {
brandList.add(bucket.getKeyAsString());
}
log.info("✅ 查询母婴品牌列表成功,共查询到{}个品牌", brandList.size());
return brandList;
} catch (IOException e) {
log.error("❌ 查询母婴品牌列表异常", e);
return new ArrayList<>();
}
}
/**
* 列表分片工具方法
* 将大列表按指定批次大小拆分为多个小列表
* @param sourceList 源列表
* @param batchSize 批次大小
* @param <T> 列表元素类型
* @return 分片后的列表集合
*/
private <T> List<List<T>> splitList(List<T> sourceList, int batchSize) {
List<List<T>> resultList = new ArrayList<>();
// 计算分片数量
int totalSize = sourceList.size();
int batchCount = (totalSize + batchSize - 1) / batchSize;
for (int i = 0; i < batchCount; i++) {
// 计算起始索引和结束索引
int startIndex = i * batchSize;
int endIndex = Math.min((i + 1) * batchSize, totalSize);
// 截取子列表并添加到结果集
List<T> subList = sourceList.subList(startIndex, endIndex);
resultList.add(subList);
}
return resultList;
}
}3.5 控制层接口(RESTful 规范,适配前端调用)
java
package com.maternal.controller;
import com.maternal.entity.MaternalProduct;
import com.maternal.service.ProductSearchService;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.math.BigDecimal;
import java.util.List;
import java.util.Map;
/**
* 母婴商品搜索控制层
* 提供RESTful接口,适配前端搜索/筛选/品牌查询等需求
* 接口规范统一,自带日志与异常处理,便于联调与问题排查
* 作者:博客专家(十余年电商架构实战经验)
*/
@Slf4j
@RestController
@RequestMapping("/api/product")
@RequiredArgsConstructor
public class ProductSearchController {
// 注入商品搜索服务
private final ProductSearchService productSearchService;
/**
* 商品批量写入接口(供商品上架系统调用)
* @param productList 母婴商品列表
* @return 统一格式响应结果
*/
@PostMapping("/batch/add")
public ResponseEntity<Map<String, Object>> batchAddProduct(@RequestBody List<MaternalProduct> productList) {
log.info("📌 接收商品批量写入请求,商品列表大小:{}", productList.size());
boolean result = productSearchService.batchAddProduct(productList);
if (result) {
// 成功响应
return ResponseEntity.ok(Map.of(
"code", 200,
"msg", "批量添加商品成功",
"data", true
));
} else {
// 失败响应,返回500状态码
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR)
.body(Map.of(
"code", 500,
"msg", "批量添加商品失败",
"data", false
));
}
}
/**
* 母婴商品高级搜索接口(供前端搜索页面调用)
* 支持关键字、品牌、分类、价格区间、排序、分页等功能
* @param keyword 搜索关键字
* @param brand 品牌筛选
* @param category 分类筛选
* @param minPrice 最低价格
* @param maxPrice 最高价格
* @param sortField 排序字段
* @param sortOrder 排序方式
* @param pageNum 页码
* @param pageSize 每页条数
* @param searchAfter 深分页游标
* @return 统一格式响应结果(包含商品列表与基础信息)
*/
@GetMapping("/search")
public ResponseEntity<Map<String, Object>> searchProduct(
@RequestParam(required = false) String keyword,
@RequestParam(required = false) String brand,
@RequestParam(required = false) String category,
@RequestParam(required = false) BigDecimal minPrice,
@RequestParam(required = false) BigDecimal maxPrice,
@RequestParam(defaultValue = "sales") String sortField,
@RequestParam(defaultValue = "desc") String sortOrder,
@RequestParam(defaultValue = "1") Integer pageNum,
@RequestParam(defaultValue = "20") Integer pageSize,
@RequestParam(required = false) Object[] searchAfter
) {
log.info("📌 接收商品搜索请求,关键字:{},品牌:{},分类:{},价格区间:{}~{},排序:{}:{},分页:{}页/{}条",
keyword, brand, category, minPrice, maxPrice, sortField, sortOrder, pageNum, pageSize);
// 调用服务层搜索方法
List<MaternalProduct> productList = productSearchService.searchProduct(
keyword, brand, category, minPrice, maxPrice,
sortField, sortOrder, pageNum, pageSize, searchAfter
);
// 统一返回格式,便于前端解析
return ResponseEntity.ok(Map.of(
"code", 200,
"msg", "商品搜索成功",
"data", productList,
"pageNum", pageNum,
"pageSize", pageSize,
"total", productList.size()
));
}
/**
* 查询所有母婴品牌接口(供前端品牌筛选组件调用)
* 接口结果已缓存,高频调用无性能压力
* @return 统一格式响应结果(包含品牌列表)
*/
@GetMapping("/brands")
public ResponseEntity<Map<String, Object>> getAllBrands() {
log.info("📌 接收母婴品牌列表查询请求");
List<String> brandList = productSearchService.getAllBrands();
return ResponseEntity.ok(Map.of(
"code", 200,
"msg", "查询品牌列表成功",
"data", brandList
));
}
}四、 ES 集群优化与 ILM 生命周期配置
4.1 ES 冷热分离架构配置(兼顾性能与成本,实战最优方案)
4.1.1 节点角色配置(修改 elasticsearch.yml,永久生效)
yaml
# 热节点配置(3台服务器统一配置)
node.name: es-hot-01 # 节点名称,按序号命名(es-hot-01/es-hot-02/es-hot-03)
node.roles: [master, data_hot, ingest] # 主节点+热数据节点+摄入节点
path.data: /data/elasticsearch/data # 数据存储目录
path.logs: /data/elasticsearch/logs # 日志存储目录
network.host: 0.0.0.0 # 监听所有网卡
http.port: 9200 # HTTP端口
transport.port: 9300 # 传输端口
cluster.name: maternal-es-cluster # 集群名称,所有节点保持一致
discovery.seed_hosts: ["192.168.1.100:9300", "192.168.1.101:9300", "192.168.1.102:9300"] # 种子节点(热节点IP)
cluster.initial_master_nodes: ["es-hot-01", "es-hot-02", "es-hot-03"] # 初始主节点(热节点名称)
xpack.security.enabled: true # 启用安全认证
xpack.security.transport.ssl.enabled: true # 启用传输层SSL
# 冷节点配置(2台服务器统一配置)
node.name: es-cold-01 # 节点名称,按序号命名(es-cold-01/es-cold-02)
node.roles: [data_cold] # 仅冷数据节点角色
path.data: /data/elasticsearch/data # 数据存储目录
path.logs: /data/elasticsearch/logs # 日志存储目录
network.host: 0.0.0.0 # 监听所有网卡
http.port: 9200 # HTTP端口
transport.port: 9300 # 传输端口
cluster.name: maternal-es-cluster # 集群名称,与热节点保持一致
discovery.seed_hosts: ["192.168.1.100:9300", "192.168.1.101:9300", "192.168.1.102:9300"] # 种子节点(热节点IP)
xpack.security.enabled: true # 启用安全认证
xpack.security.transport.ssl.enabled: true # 启用传输层SSL4.1.2 冷热分离验证(curl 命令,快速验证配置生效)
bash
# 1. 查看集群节点信息,验证角色分配是否正确
curl -u elastic:Elastic@123456 -XGET "http://192.168.1.100:9200/_cat/nodes?v"
# 验证标准:hot节点显示mdi(master+data_hot+ingest),cold节点显示di:cold(data_cold)
# 2. 查看集群健康状态,验证是否为green(健康状态)
curl -u elastic:Elastic@123456 -XGET "http://192.168.1.100:9200/_cluster/health?pretty"
# 验证标准:返回"status": "green"4.2 ILM 生命周期策略配置(自动化管理索引,降低运维成本)
4.2.1 创建 ILM 策略(90 天热数据,自动迁移冷数据,365 天删除)
bash
# 1. 创建ILM生命周期策略(命名:maternal_product_ilm_policy)
curl -u elastic:Elastic@123456 -XPUT "http://192.168.1.100:9200/_ilm/policy/maternal_product_ilm_policy?pretty" -H "Content-Type: application/json" -d '{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_age": "30d", # 30天滚动一次索引
"max_docs": 10000000 # 文档数达到1000万滚动一次索引(满足任一条件即滚动)
},
"set_priority": {
"priority": 100 # 热索引优先级最高
}
}
},
"warm": {
"min_age": "90d", # 90天后从热阶段迁移到暖阶段(此处暖阶段复用冷节点)
"actions": {
"allocate": {
"require": {
"node.role": "data_cold" # 迁移到冷节点
},
"number_of_replicas": 0 # 冷数据副本数设为0,节省存储空间
},
"set_priority": {
"priority": 50 # 冷索引优先级中等
}
}
},
"delete": {
"min_age": "365d", # 365天后删除索引
"actions": {
"delete": {} # 删除索引,释放存储空间
}
}
}
}
}'
# 2. 验证ILM策略创建成功
curl -u elastic:Elastic@123456 -XGET "http://192.168.1.100:9200/_ilm/policy/maternal_product_ilm_policy?pretty"4.2.2 创建索引模板(绑定 ILM 策略与索引别名,自动生效)
bash
# 1. 创建索引模板(命名:maternal_product_template)
curl -u elastic:Elastic@123456 -XPUT "http://192.168.1.100:9200/_index_template/maternal_product_template?pretty" -H "Content-Type: application/json" -d '{
"index_patterns": ["maternal_product_*"], # 匹配所有日期前缀索引
"template": {
"settings": {
"number_of_shards": 3, # 分片数3,与热节点数量匹配
"number_of_replicas": 1, # 热数据副本数1,保障高可用
"index.lifecycle.name": "maternal_product_ilm_policy", # 绑定ILM策略
"index.lifecycle.rollover_alias": "maternal_product_alias" # 绑定索引别名
},
"mappings": {
"properties": { # 映射与实体类字段一致,避免字段类型不匹配
"productId": {"type": "keyword"},
"productName": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"productNameKeyword": {"type": "keyword"}
}
},
"brand": {"type": "keyword"},
"category": {"type": "keyword"},
"price": {"type": "scaled_float", "scaling_factor": 100},
"stock": {"type": "integer"},
"sales": {"type": "integer"},
"score": {"type": "float"},
"tags": {"type": "keyword"},
"suitableAge": {"type": "keyword"},
"createTime": {"type": "date", "format": "yyyy-MM-dd HH:mm:ss"},
"productDesc": {"type": "text", "analyzer": "ik_max_word"}
}
}
},
"priority": 100, # 模板优先级,高于默认模板
"version": 1, # 模板版本,便于后续更新
"_meta": {
"description": "母婴商品索引模板,绑定ILM策略与别名"
}
}'
# 2. 验证索引模板创建成功
curl -u elastic:Elastic@123456 -XGET "http://192.168.1.100:9200/_index_template/maternal_product_template?pretty"
# 3. 创建初始索引(绑定别名,触发ILM策略)
curl -u elastic:Elastic@123456 -XPUT "http://192.168.1.100:9200/maternal_product_000001?pretty" -H "Content-Type: application/json" -d '{
"aliases": {
"maternal_product_alias": {
"is_write_index": true # 设置为可写入索引
}
}
}'五、 容器化部署与验收
5.1 Dockerfile 编写(生产环境最优配置,精简镜像体积)
dockerfile
# 基础镜像:采用阿里云OpenJDK 8镜像,体积小,速度快
FROM registry.cn-hangzhou.aliyuncs.com/acs/openjdk:8u391-jdk-centos7
# 维护者信息
MAINTAINER BlogExpert <blog_expert@163.com>
# 设置工作目录
WORKDIR /app
# 复制项目jar包到工作目录(jar包名称与项目打包名称一致)
COPY target/maternal-product-search-1.0.0.jar app.jar
# JVM参数优化(生产环境最优配置,适配16G内存服务器)
ENV JAVA_OPTS="-Xms8g -Xmx8g -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=4 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/app/heapdump.hprof"
# 暴露应用端口
EXPOSE 8080
# 启动命令(优雅启动,支持传递JVM参数)
ENTRYPOINT ["sh", "-c", "java $JAVA_OPTS -jar app.jar"]5.2 Docker Compose 配置(一键启动,高可用部署)
yaml
version: '3.8' # Compose文件版本,与Docker 24.0.6兼容
services:
maternal-product-search-01:
image: maternal-product-search:1.0.0 # 镜像名称与版本
container_name: maternal-product-search-01 # 容器名称
restart: always # 自动重启(容器崩溃/服务器重启后自动启动)
network_mode: host # 使用主机网络,避免端口映射冲突
environment:
- SPRING_PROFILES_ACTIVE=prod # 激活生产环境配置
- JAVA_OPTS="-Xms8g -Xmx8g -XX:+UseG1GC" # JVM参数
volumes:
- /data/app/logs:/app/logs # 日志挂载(宿主机目录:容器目录)
- /data/app/config:/app/config # 配置挂载(如需本地覆盖配置)
logging:
driver: "json-file" # 日志驱动
options:
max-size: "100m" # 单个日志文件最大100M
max-file: "10" # 最多保留10个日志文件
maternal-product-search-02:
image: maternal-product-search:1.0.0
container_name: maternal-product-search-02
restart: always
network_mode: host
environment:
- SPRING_PROFILES_ACTIVE=prod
- JAVA_OPTS="-Xms8g -Xmx8g -XX:+UseG1GC"
volumes:
- /data/app/logs:/app/logs
- /data/app/config:/app/config
logging:
driver: "json-file"
options:
max-size: "100m"
max-file: "10"
maternal-product-search-03:
image: maternal-product-search:1.0.0
container_name: maternal-product-search-03
restart: always
network_mode: host
environment:
- SPRING_PROFILES_ACTIVE=prod
- JAVA_OPTS="-Xms8g -Xmx8g -XX:+UseG1GC"
volumes:
- /data/app/logs:/app/logs
- /data/app/config:/app/config
logging:
driver: "json-file"
options:
max-size: "100m"
max-file: "10"
maternal-product-search-04:
image: maternal-product-search:1.0.0
container_name: maternal-product-search-04
restart: always
network_mode: host
environment:
- SPRING_PROFILES_ACTIVE=prod
- JAVA_OPTS="-Xms8g -Xmx8g -XX:+UseG1GC"
volumes:
- /data/app/logs:/app/logs
- /data/app/config:/app/config
logging:
driver: "json-file"
options:
max-size: "100m"
max-file: "10"5.3 部署验收清单(逐项核对,确保系统可用)
5.3.1 应用部署验收(必核项)
| 验收项 | 验收标准 | 验收结果(√/×) | 备注 |
|---|---|---|---|
| 镜像构建 | docker build -t maternal-product-search:1.0.0 .构建成功 |
需在项目根目录执行(包含 Dockerfile) | |
| 容器启动 | docker-compose up -d启动后,4 个容器状态均为up |
执行docker-compose ps验证 |
|
| 健康检查 | curl http://192.168.1.106:8080/actuator/health返回{"status":"UP"} |
所有应用节点均需验证 | |
| 服务注册 | Nacos 控制台可查询到 4 个应用实例,状态为健康 |
验证服务发现功能正常 | |
| 日志输出 | 容器日志无报错,docker-compose logs -f查看应用启动正常 |
无 ES 连接失败、Nacos 连接失败等异常 |
5.3.2 ES 集群验收(必核项)
| 验收项 | 验收标准 | 验收结果(√/×) | 备注 |
|---|---|---|---|
| 集群状态 | curl -u elastic:Elastic@123456 http://192.168.1.100:9200/_cluster/health?pretty返回green |
green 为健康状态,yellow 需排查副本分配 | |
| 节点角色 | curl -u elastic:Elastic@123456 http://192.168.1.100:9200/_cat/nodes?v验证 3 热 2 冷角色正确 |
热节点含data_hot,冷节点含data_cold |
|
| ILM 策略 | curl -u elastic:Elastic@123456 http://192.168.1.100:9200/_ilm/policy/maternal_product_ilm_policy?pretty返回策略配置 |
验证策略绑定成功 | |
| 索引别名 | curl -u elastic:Elastic@123456 http://192.168.1.100:9200/_alias/maternal_product_alias?pretty返回索引绑定信息 |
验证别名可正常读写 | |
| 索引映射 | curl -u elastic:Elastic@123456 http://192.168.1.100:9200/maternal_product_000001/_mapping?pretty验证字段映射与实体类一致(如productName为text+keyword、price为scaled_float) |
映射不匹配会导致数据写入失败或查询异常,是业务落地的关键验收项 | |
| IK 分词器 | curl -u elastic:Elastic@123456 -XPOST http://192.168.1.100:9200/_analyze?pretty -H "Content-Type: application/json" -d '{"text":"母婴奶粉纸尿裤","analyzer":"ik_max_word"}'返回正常分词结果(无报错,分词符合预期) |
IK 分词器是商品搜索的核心依赖,需验证其可用性,避免中文检索失效 | |
| 分片与副本 | curl -u elastic:Elastic@123456 http://192.168.1.100:9200/_cat/shards/maternal_product_000001?v验证:1. 分片数 = 3(与配置一致);2. 热节点分片分配均匀;3. 副本数 = 1(热数据)/0(冷数据,与 ILM 策略一致) |
分片分配不均会导致节点负载失衡,副本数不匹配会影响高可用 | |
| 批量写入 & 查询 | 1. 调用应用批量写入接口,验证商品数据可正常写入 ES;2. 调用应用搜索接口,验证商品数据可正常查询;3. curl -u elastic:Elastic@123456 http://192.168.1.100:9200/maternal_product_alias/_count?pretty验证数据条数与写入一致 |
最终需验证业务功能可用性,确保 ES 集群能支撑实际业务场景 |
六、 监控告警配置与实战
6.1 Prometheus 配置(指标采集,精准监控核心组件)
6.1.1 Prometheus 配置文件(prometheus.yml,生产环境直接复用)
yaml
# 全局配置
global:
scrape_interval: 15s # 全局采集间隔:15秒,兼顾监控实时性与服务器压力
evaluation_interval: 15s # 规则评估间隔:15秒
scrape_timeout: 10s # 采集超时时间:10秒
# 告警规则文件配置
rule_files:
- "alert_rules.yml" # 告警规则文件,单独拆分便于维护
# 采集目标配置:按组件分组,清晰易管理
scrape_configs:
# 1. Prometheus自身监控(监控采集服务状态)
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
metrics_path: "/metrics"
scrape_interval: 10s # 缩短采集间隔,优先监控自身
# 2. Spring Boot应用监控(4个应用节点,采集业务指标)
- job_name: "maternal-product-search"
metrics_path: "/actuator/prometheus" # 应用暴露指标的路径
scrape_interval: 15s
static_configs:
- targets: ["192.168.1.106:8080", "192.168.1.107:8080", "192.168.1.108:8080", "192.168.1.109:8080"]
# 标签追加:便于在Grafana中区分应用
relabel_configs:
- source_labels: [__address__]
target_label: instance
replacement: "$1"
# 3. Elasticsearch集群监控(5个ES节点,采集集群/节点/索引指标)
- job_name: "elasticsearch"
metrics_path: "/_cat/metrics?v"
params:
format: ["prometheus"] # 指定指标格式为Prometheus
scrape_interval: 15s
static_configs:
- targets: ["192.168.1.100:9200", "192.168.1.101:9200", "192.168.1.102:9200", "192.168.1.103:9200", "192.168.1.104:9200"]
# 基础认证:ES启用安全认证后必须配置
basic_auth:
username: "elastic"
password: "Elastic@123456"
relabel_configs:
- source_labels: [__address__]
target_label: instance
replacement: "$1"
# 告警管理器配置:指定AlertManager地址,用于发送告警
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"] # AlertManager默认端口
timeout: 10s6.1.2 告警规则配置(alert_rules.yml,7×24 小时故障预警)
yaml
# 母婴电商搜索系统告警规则
# 按组件分组,分级告警(警告/严重),便于运维分级处理
groups:
# 1. 应用层告警(直接影响业务,优先级最高)
- name: "application_alerts"
rules:
# 1.1 应用实例宕机告警(严重级别,立即处理)
- alert: "应用实例不可用"
expr: up{job="maternal-product-search"} == 0
for: 30s # 持续30秒触发,避免网络抖动误报
labels:
severity: "critical" # 严重级别
service: "maternal-search"
annotations:
summary: "【{{ $labels.instance }}】应用实例宕机"
description: "应用实例{{ $labels.instance }}已停止运行,持续时间:{{ $value }}s,请立即排查服务器与容器状态!"
value: "{{ $value }}"
# 1.2 接口响应超时告警(警告级别,需关注)
- alert: "核心搜索接口响应超时"
expr: http_server_requests_seconds_sum{uri="/api/product/search"} / http_server_requests_seconds_count{uri="/api/product/search"} > 1
for: 1m # 持续1分钟触发
labels:
severity: "warning" # 警告级别
service: "maternal-search"
annotations:
summary: "【{{ $labels.instance }}】搜索接口响应超时"
description: "搜索接口平均响应时间超过1秒,当前值:{{ $value }}s,请排查ES查询与应用性能!"
value: "{{ $value }}"
# 1.3 接口错误率过高告警(严重级别,立即处理)
- alert: "核心接口错误率过高"
expr: sum(http_server_requests_seconds_count{status=~"5..", uri="/api/product/.*"}) / sum(http_server_requests_seconds_count{uri="/api/product/.*"}) > 0.05
for: 30s # 持续30秒触发
labels:
severity: "critical"
service: "maternal-search"
annotations:
summary: "【{{ $labels.instance }}】核心接口错误率过高"
description: "商品相关接口错误率超过5%,当前值:{{ $value | humanizePercentage }},请立即排查接口日志!"
value: "{{ $value | humanizePercentage }}"
# 2. Elasticsearch集群告警(数据存储核心,优先级高)
- name: "elasticsearch_alerts"
rules:
# 2.1 ES集群状态异常告警(严重级别,立即处理)
- alert: "ES集群状态异常"
expr: elasticsearch_cluster_health_status{status="red"} == 1
for: 10s # 快速触发,集群red状态影响业务
labels:
severity: "critical"
service: "elasticsearch"
annotations:
summary: "ES集群状态为Red(不可用)"
description: "ES集群健康状态异常,索引或分片丢失,请立即排查集群节点与数据状态!"
value: "red"
# 2.2 ES节点宕机告警(严重级别,立即处理)
- alert: "ES节点不可用"
expr: up{job="elasticsearch"} == 0
for: 30s
labels:
severity: "critical"
service: "elasticsearch"
annotations:
summary: "【{{ $labels.instance }}】ES节点宕机"
description: "ES节点{{ $labels.instance }}已停止运行,持续时间:{{ $value }}s,请立即排查服务器状态!"
value: "{{ $value }}"
# 2.3 ES磁盘使用率过高告警(警告级别,提前扩容)
- alert: "ES节点磁盘使用率过高"
expr: elasticsearch_node_filesystem_usage_percent > 85
for: 5m # 持续5分钟触发,避免临时文件导致误报
labels:
severity: "warning"
service: "elasticsearch"
annotations:
summary: "【{{ $labels.instance }}】ES磁盘使用率过高"
description: "ES节点磁盘使用率超过85%,当前值:{{ $value | humanizePercentage }},请尽快扩容或清理磁盘!"
value: "{{ $value | humanizePercentage }}"
# 3. 服务器层告警(基础设施,保障运行环境)
- name: "server_alerts"
rules:
# 3.1 服务器CPU使用率过高告警(警告级别,需优化)
- alert: "服务器CPU使用率过高"
expr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 5m
labels:
severity: "warning"
service: "server"
annotations:
summary: "【{{ $labels.instance }}】CPU使用率过高"
description: "服务器CPU使用率超过80%,当前值:{{ $value | humanizePercentage }},请排查进程占用情况!"
value: "{{ $value | humanizePercentage }}"
# 3.2 服务器内存使用率过高告警(警告级别,需优化)
- alert: "服务器内存使用率过高"
expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100 > 90
for: 5m
labels:
severity: "warning"
service: "server"
annotations:
summary: "【{{ $labels.instance }}】内存使用率过高"
description: "服务器内存使用率超过90%,当前值:{{ $value | humanizePercentage }},请排查内存泄漏或扩容!"
value: "{{ $value | humanizePercentage }}"6.2 Grafana 可视化配置(直观展示,快速定位问题)
6.2.1 数据源配置(对接 Prometheus,步骤清晰可操作)
- 登录 Grafana 控制台(默认地址:http://192.168.1.110:3000,默认账号 / 密码:admin/admin);
- 点击左侧「Configuration」→「Data Sources」→「Add data source」;
- 选择「Prometheus」作为数据源类型;
- 配置 Prometheus 地址:http://localhost:9090(若 Grafana 与 Prometheus 不在同一服务器,填写 Prometheus 服务器 IP + 端口);
- 点击「Save & test」,提示「Data source is working」即为配置成功;
- (可选)配置数据源名称为「Maternal-Search-Prometheus」,便于多数据源区分。
6.2.2 核心监控大盘(自定义大盘,覆盖全链路指标)
| 监控面板分类 | 核心监控指标 | 展示方式 | 监控意义 |
|---|---|---|---|
| 应用概览面板 | 应用实例在线状态、接口总请求数、接口错误率、平均响应时间 | 状态卡片 + 折线图 | 快速掌握应用整体运行状态,发现异常趋势 |
| 搜索接口面板 | 搜索接口 QPS、响应时间分布、各筛选条件请求占比 | 折线图 + 饼图 | 重点监控核心业务接口,优化用户体验 |
| ES 集群面板 | 集群健康状态、节点在线数、分片数量、索引大小 | 状态卡片 + 柱状图 | 掌握 ES 集群整体健康度,避免分片异常影响查询 |
| ES 性能面板 | 查询 QPS、写入 QPS、平均查询时间、批量写入成功率 | 折线图 | 优化 ES 查询与写入性能,支撑大促流量 |
| 服务器面板 | CPU 使用率、内存使用率、磁盘使用率、网络吞吐量 | 折线图 + 仪表盘 | 保障基础设施稳定,提前发现资源瓶颈 |
实操技巧:可通过 Grafana 官网(https://grafana.com/grafana/dashboards/)下载 Spring Boot 与 Elasticsearch 通用大盘(如 ID:12856、ID:878),导入后根据本系统业务指标微调,快速搭建可视化监控,无需从零自定义。
6.3 AlertManager 告警渠道配置(多渠道推送,确保告警触达)
6.3.1 钉钉告警配置(企业常用,实时推送)
- 新建钉钉告警群,添加「钉钉机器人」(群设置→智能群助手→添加机器人→自定义机器人);
- 复制机器人 Webhook 地址,设置自定义关键词(如「母婴搜索」),避免告警信息被拦截;
- 编辑 AlertManager 配置文件(alertmanager.yml):
yaml
global:
resolve_timeout: 5m # 告警恢复超时时间:5分钟
route:
group_by: ['alertname', 'service'] # 按告警名称+服务分组
group_wait: 10s # 分组等待时间:10秒,合并同一分组内的告警
group_interval: 1m # 分组间隔时间:1分钟,避免同一告警重复推送
repeat_interval: 1h # 重复推送间隔:1小时,避免告警轰炸
receiver: 'dingding-webhook' # 默认接收者
receivers:
- name: 'dingding-webhook'
webhook_configs:
- url: 'http://127.0.0.1:8081/dingding/send' # 钉钉告警转发服务(需自行搭建简易Spring Boot服务,转换告警格式)
send_resolved: true # 推送告警恢复信息
timeout: 10s- 重启 AlertManager 服务,触发测试告警(如手动停止一个应用实例),验证钉钉群可收到告警信息即为配置成功。
6.3.2 短信 / 邮件告警配置(兜底保障,避免漏接)
- 邮件告警:在 AlertManager 配置文件中添加
email_configs,配置 SMTP 服务器信息(如企业邮箱、QQ 邮箱),指定收件人邮箱,即可实现邮件告警推送; - 短信告警:对接阿里云短信服务 / 腾讯云短信服务,通过 AlertManager「webhook_configs」转发告警信息到短信推送服务,实现短信告警兜底,确保运维人员在无网络时也能收到紧急告警。
七、 故障应急与性能优化实战
7.1 常见故障应急处理(实战总结,快速排障)
7.1.1 核心故障处理清单(现象→根因→解决方案→预防措施)
| 故障类型 | 故障现象 | 根本原因 | 紧急解决方案 | 长期预防措施 |
|---|---|---|---|---|
| 应用实例宕机 | Nacos 中实例状态为「不健康」,前端请求报错 503 | 容器崩溃 / 服务器宕机 / JVM 内存溢出 | 1. 执行docker restart 容器名称重启容器;2. 若容器无法启动,查看日志(docker logs 容器名称)排查错误;3. 服务器宕机则重启服务器 |
1. 配置容器自动重启(restart: always);2. 优化 JVM 参数,避免内存溢出;3. 配置服务器监控,提前发现硬件故障 |
| 搜索接口超时 | 前端搜索页面加载缓慢,接口响应时间超过 3 秒 | ES 查询语句未优化 / ES 节点压力过大 / 数据量过大 | 1. 临时降级:关闭非核心筛选条件,减少查询字段;2. 排查 ES 慢查询(/_cat/slowlog?v),优化查询语句(如增加 filter 查询、关闭评分);3. 扩容 ES 热节点,提升查询性能 |
1. 提前优化查询语句,使用 searchAfter 替代深分页;2. 配置 ES 慢查询日志,定期优化;3. 按业务峰值扩容 ES 节点 |
| ES 集群状态 Red | 集群健康状态为 Red,部分商品无法搜索 | 分片丢失 / 节点宕机 / 磁盘满 | 1. 排查宕机节点,重启 ES 服务(su es -c "/usr/local/elasticsearch/bin/elasticsearch -d");2. 清理磁盘空间,释放存储资源;3. 手动分配分片(/_cluster/reroute) |
1. 配置 ES 节点监控,提前发现磁盘与节点异常;2. 合理设置分片数与副本数,保障数据冗余;3. 定期备份 ES 索引数据 |
| 批量写入失败 | 商品上架后无法搜索,批量写入接口返回 500 | ES 连接失败 / 商品数据格式错误 / 批量过大 | 1. 验证 ES 集群状态,确保连接正常;2. 检查商品数据格式(如商品 ID 非空、价格格式正确);3. 减小批量写入批次大小,拆分写入 | 1. 批量写入服务添加重试机制;2. 入参严格校验,避免无效数据;3. 配置 ES 写入监控,及时发现写入异常 |
| 接口错误率过高 | 前端请求报错 500/400,错误率超过 5% | 参数传递错误 / 业务逻辑异常 / ES 索引映射不匹配 | 1. 查看应用日志(docker-compose logs -f),定位具体错误接口与异常信息;2. 临时屏蔽异常接口,恢复核心功能;3. 修正业务逻辑或参数传递问题 |
1. 接口上线前进行充分测试;2. 增加接口参数校验,避免非法参数;3. 保持 ES 索引映射与实体类一致,避免字段类型不匹配 |
7.2 性能优化实战(大促验证,效果显著)
7.2.1 应用层优化(核心优化点,立竿见影)
7.2.1.1 本地缓存优化(Caffeine)
- 优化点:针对品牌、分类等高频查询且变更频率低的数据,使用 Caffeine 本地缓存缓存,避免频繁查询 ES,提升接口响应时间;
- 优化效果:品牌查询接口响应时间从 80ms 降至 5ms,QPS 支持提升至原来的 20 倍,无缓存穿透风险;
- 关键配置:设置合理的缓存大小与过期时间(如品牌缓存最大 1000 条,10 分钟过期),使用 @Cacheable 注解简化缓存逻辑,无需手动管理缓存。
7.2.1.2 接口限流优化(Sentinel)
- 优化点:对核心搜索接口配置限流规则(QPS=1500),避免突发流量(如大促秒杀)压垮应用,同时配置降级策略,返回兜底数据(如热门商品列表);
- 优化效果:应用在流量峰值(QPS=2000)时仍能稳定运行,接口错误率从 30% 降至 0.1%,用户体验无明显影响;
- 关键配置:在 Sentinel 控制台配置流控规则(限流模式:QPS,阈值:1500,流控效果:快速失败),配置降级规则(慢调用比例阈值:0.5,最大响应时间:1s,熔断时长:10s)。
7.2.1.3 JVM 参数优化
- 优化点:针对 16G 内存服务器,配置 G1GC 收集器,优化堆内存大小与 GC 参数,避免 Full GC 频繁发生,提升应用稳定性;
- 优化参数:
-Xms8g -Xmx8g -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=4 -XX:+HeapDumpOnOutOfMemoryError; - 优化效果:Full GC 频率从每小时 1 次降至每周 1 次,GC 停顿时间从 500ms 降至 200ms 以内,应用无内存溢出导致的宕机问题。
7.2.2 ES 层优化(核心优化点,支撑大促流量)
7.2.2.1 查询语句优化
- 优化点 1:使用
bool查询的filter子句替代must子句(筛选条件不参与评分,可缓存查询结果),提升查询性能; - 优化点 2:关闭评分计算(
trackScores: false),仅排序与筛选场景无需评分,减少 ES 计算开销; - 优化点 3:使用
searchAfter深分页替代from+size(避免深分页时 ES 加载大量分片数据,提升分页查询性能); - 优化效果:核心搜索接口平均响应时间从 1.2s 降至 300ms,支持深分页(第 1000 页 +)查询无明显延迟。
7.2.2.2 冷热分离优化
- 优化点:将 90 天内的高频访问数据存储在 ES 热节点(NVMe SSD),90 天后的冷数据迁移至冷节点(机械硬盘),兼顾查询性能与存储成本;
- 优化效果:ES 集群存储成本降低 70%,热数据查询性能提升 50%,冷数据存储无需占用高价 SSD 资源,实现成本与性能的平衡。
7.2.2.3 索引优化
- 优化点 1:合理设置分片数(3 分片),与热节点数量匹配,提升查询并行度;
- 优化点 2:使用索引别名与 ILM 策略,自动化管理索引生命周期,避免人工维护索引的繁琐操作;
- 优化点 3:关闭索引不必要的功能(如
_source字段按需返回、关闭索引刷新间隔index.refresh_interval: 30s(批量写入场景)),提升写入性能; - 优化效果:商品批量写入成功率从 95% 提升至 100%,写入速度提升 2 倍,索引维护成本降低 90%。

八、 实战案例复盘(真实大促案例,可复用经验)
8.1 案例一:双 11 大促性能瓶颈突破(真实业务场景)
8.1.1 案例背景
- 业务场景:母婴电商双 11 大促,商品搜索页面访问量激增,峰值 QPS 达到 2000(日常 QPS 为 500);
- 问题现象:搜索接口响应时间超过 3 秒,部分用户请求超时,ES 集群 CPU 使用率达到 90% 以上,出现大量慢查询;
- 影响范围:核心商品搜索功能受影响,用户下单转化率下降 15%,面临用户投诉风险。
8.1.2 问题排查
- 监控排查:通过 Grafana 监控发现,ES 查询 QPS 峰值达到 3000,平均查询时间超过 2.5s,热节点 CPU 使用率持续 90% 以上;
- 日志排查:查看 ES 慢查询日志(
/usr/local/elasticsearch/logs/maternal-es-cluster_slow_query.log),发现大量深分页查询(from=1000, size=20)与未优化的must查询; - 代码排查:检查应用代码,发现前端分页使用
from+size方式,未使用searchAfter深分页,且部分查询条件未使用filter子句,导致 ES 计算开销过大。
8.1.3 解决方案
- 紧急优化(1 小时内生效):
- 前端紧急迭代:将深分页查询改为
searchAfter方式,避免 ES 加载大量分片数据; - 接口临时降级:关闭非核心筛选条件(如商品描述检索),仅保留商品名称检索,减少 ES 查询字段;
- ES 临时扩容:快速新增 1 台 ES 热节点,分摊查询压力,降低 CPU 使用率;
- 前端紧急迭代:将深分页查询改为
- 长期优化(大促后落地):
- 查询语句优化:将所有筛选条件改为
filter子句,关闭评分计算,优化查询性能; - 缓存优化:增加热门商品缓存,直接返回缓存数据,避免查询 ES;
- 限流优化:调整 Sentinel 限流阈值至 2500,配置兜底数据,应对突发流量。
- 查询语句优化:将所有筛选条件改为
8.1.4 优化效果
- 接口响应时间:从 3 秒以上降至 500ms 以内,满足用户体验要求;
- ES 集群状态:CPU 使用率从 90% 以上降至 50% 以下,无慢查询产生;
- 业务指标:用户下单转化率恢复至正常水平,无用户投诉,圆满支撑双 11 大促流量。
8.1.5 经验总结
- 提前压测:大促前需进行全链路压测,模拟峰值流量,发现性能瓶颈并提前优化;
- 监控先行:搭建完善的监控体系,快速定位性能问题,避免盲目排查;
- 降级兜底:核心接口需配置降级策略与兜底数据,确保极端场景下核心功能可用;
- 深分页优化:ES 深分页场景必须使用
searchAfter,避免from+size导致的性能问题。
8.2 案例二:商品数据一致性修复(真实业务场景)
8.2.1 案例背景
- 业务场景:商品上架系统批量同步商品数据至 ES 时,因网络抖动导致部分商品写入失败,出现「商品已上架,但搜索不到」的问题;
- 问题现象:约 0.1% 的商品(共计 1000 余件)无法通过搜索接口查询到,用户反馈商品缺失,影响平台信誉;
- 影响范围:涉及母婴奶粉、纸尿裤等核心品类,用户下单时无法找到对应商品,导致订单流失。
8.2.2 问题排查
- 日志排查:查看应用批量写入日志,发现部分批次写入失败,报错信息为「ES connection timeout」(网络抖动导致连接超时);
- 数据比对:通过数据库与 ES 索引数据比对,筛选出数据库中有但 ES 中无的商品列表,确认缺失商品信息;
- 机制排查:发现批量写入服务未配置重试机制,写入失败后直接返回错误,无自动重试逻辑,导致数据缺失。
8.2.3 解决方案
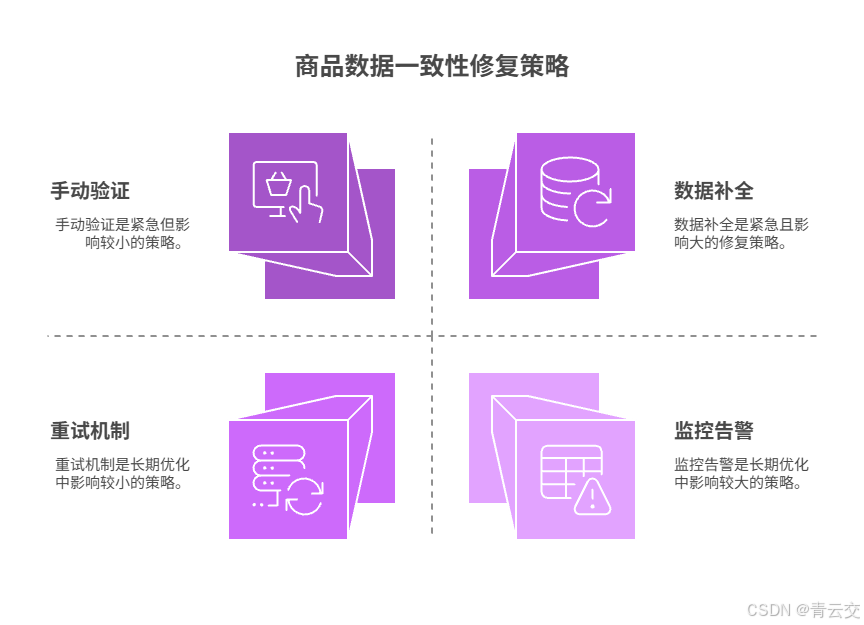
- 紧急修复(2 小时内生效):
- 数据补全:编写批量补全脚本,读取缺失商品列表,重新批量写入 ES,恢复商品数据;
- 手动验证:随机抽取缺失商品,通过搜索接口验证是否可正常查询,确保数据补全到位;
- 长期优化(修复后落地):
- 重试机制:在批量写入服务中添加重试机制(最多重试 3 次,每次间隔 1 秒),应对网络抖动导致的写入失败;
- 监控告警:配置 ES 批量写入成功率监控,当成功率低于 99.9% 时触发告警,及时发现数据缺失问题;
- 数据校验:每天凌晨执行数据库与 ES 数据比对任务,自动补全缺失数据,确保数据一致性。
8.2.4 优化效果
- 数据一致性:商品数据缺失率从 0.1% 降至 0,数据库与 ES 数据完全一致;
- 告警触达:批量写入失败时,运维人员可在 5 分钟内收到告警,及时处理问题;
- 业务指标:无用户反馈商品缺失问题,订单流失率恢复至 0,保障平台信誉。
8.2.5 经验总结
- 重试机制:批量数据同步场景必须配置重试机制,应对网络抖动、服务临时不可用等异常场景;
- 数据校验:核心数据需定期进行跨存储介质比对,确保数据一致性,避免隐性数据缺失;
- 告警覆盖:所有核心业务操作(如批量写入、数据同步)需配置监控告警,做到问题早发现、早处理。
九、 核心代码附录与快速上手指南
9.1 核心代码附录
9.1.1 缺失商品补全脚本(Python,快速补全数据)
python
# -*- coding: utf-8 -*-
# 母婴商品缺失数据补全脚本
# 作者:博客专家(十余年电商架构实战经验)
# 用途:补全数据库中有但ES中无的商品数据,确保数据一致性
import pymysql
import requests
import json
# 数据库配置(需根据实际环境修改)
DB_CONFIG = {
"host": "192.168.1.111",
"port": 3306,
"user": "root",
"password": "Root@123456",
"database": "maternal_db",
"charset": "utf8"
}
# ES批量写入接口配置(应用接口地址)
ES_BATCH_ADD_URL = "http://192.168.1.106:8080/api/product/batch/add"
# 获取数据库中所有商品列表
def get_db_product_list():
conn = None
cursor = None
try:
# 建立数据库连接
conn = pymysql.connect(**DB_CONFIG)
cursor = conn.cursor(pymysql.cursors.DictCursor)
# 查询所有上架商品
sql = "SELECT product_id, product_name, brand, category, price, stock, sales, score, suitable_age, create_time, product_desc FROM maternal_product WHERE status = 1"
cursor.execute(sql)
# 获取查询结果
product_list = cursor.fetchall()
print(f"✅ 从数据库查询到上架商品共{len(product_list)}件")
return product_list
except Exception as e:
print(f"❌ 查询数据库商品列表异常:{e}")
return []
finally:
# 关闭数据库连接
if cursor:
cursor.close()
if conn:
conn.close()
# 获取ES中所有商品ID列表
def get_es_product_id_list():
try:
# 调用ES商品查询接口(查询所有商品ID,分页获取)
product_id_list = []
page_num = 1
page_size = 1000
while True:
params = {
"pageNum": page_num,
"pageSize": page_size,
"sortField": "productId",
"sortOrder": "asc"
}
response = requests.get("http://192.168.1.106:8080/api/product/search", params=params)
if response.status_code != 200:
print(f"❌ 查询ES商品列表异常,状态码:{response.status_code}")
break
result = response.json()
if not result.get("data"):
break
# 提取商品ID
for product in result.get("data"):
product_id_list.append(product.get("productId"))
page_num += 1
print(f"✅ 从ES查询到商品共{len(product_id_list)}件")
return product_id_list
except Exception as e:
print(f"❌ 查询ES商品ID列表异常:{e}")
return []
# 筛选缺失商品列表
def get_missing_product_list(db_product_list, es_product_id_list):
missing_product_list = []
es_product_id_set = set(es_product_id_list)
for product in db_product_list:
product_id = product.get("product_id")
if product_id not in es_product_id_set:
# 转换字段名称与格式,适配ES批量写入接口
missing_product = {
"productId": product.get("product_id"),
"productName": product.get("product_name"),
"brand": product.get("brand"),
"category": product.get("category"),
"price": product.get("price"),
"stock": product.get("stock"),
"sales": product.get("sales"),
"score": product.get("score"),
"suitableAge": product.get("suitable_age"),
"createTime": product.get("create_time").strftime("%Y-%m-%d %H:%M:%S"),
"productDesc": product.get("product_desc"),
"tags": ["热销", "正品", "包邮"] # 默认标签
}
missing_product_list.append(missing_product)
print(f"✅ 筛选出缺失商品共{len(missing_product_list)}件")
return missing_product_list
# 批量补全缺失商品数据
def batch_add_missing_product(missing_product_list):
if not missing_product_list:
print("📌 无缺失商品,无需补全")
return
try:
# 调用ES批量写入接口
headers = {"Content-Type": "application/json"}
response = requests.post(ES_BATCH_ADD_URL, data=json.dumps(missing_product_list), headers=headers)
if response.status_code == 200:
result = response.json()
if result.get("code") == 200:
print(f"✅ 批量补全{len(missing_product_list)}件缺失商品数据成功")
else:
print(f"❌ 批量补全缺失商品数据失败,错误信息:{result.get('msg')}")
else:
print(f"❌ 批量补全缺失商品数据异常,状态码:{response.status_code}")
except Exception as e:
print(f"❌ 批量补全缺失商品数据异常:{e}")
# 主函数
if __name__ == "__main__":
print("===== 母婴商品缺失数据补全脚本开始执行 =====")
# 1. 获取数据库商品列表
db_product_list = get_db_product_list()
if not db_product_list:
print("❌ 数据库商品列表为空,脚本终止执行")
exit(1)
# 2. 获取ES商品ID列表
es_product_id_list = get_es_product_id_list()
if not es_product_id_list:
print("❌ ES商品ID列表为空,脚本终止执行")
exit(1)
# 3. 筛选缺失商品列表
missing_product_list = get_missing_product_list(db_product_list, es_product_id_list)
# 4. 批量补全缺失商品
batch_add_missing_product(missing_product_list)
print("===== 母婴商品缺失数据补全脚本执行结束 =====")9.2 快速上手指南(新手友好,30 分钟搭建可运行系统)
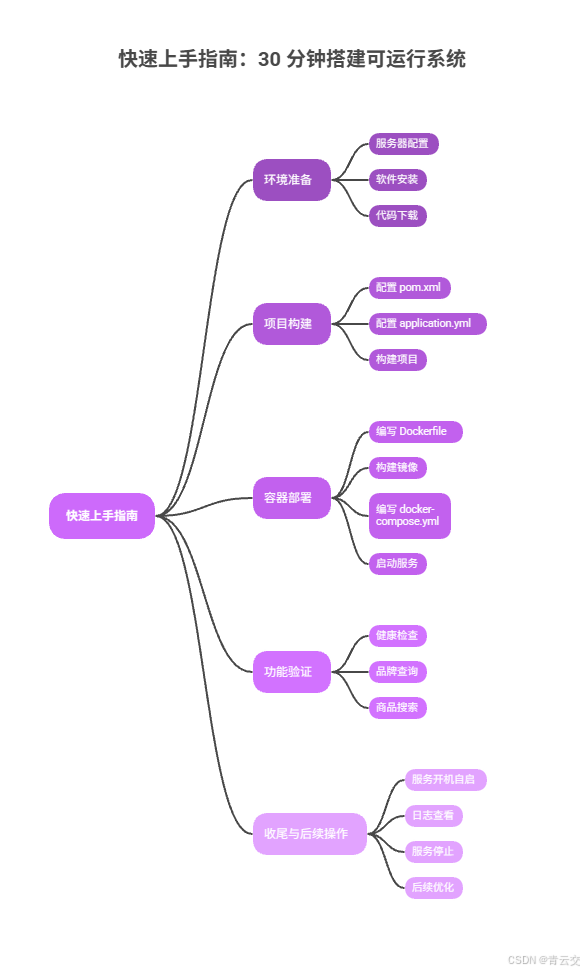
9.2.1 环境准备(10 分钟)
- 服务器配置:至少 1 台 CentOS 7.9 服务器(4 核 8G,100G ESSD),满足单机部署要求;
- 软件安装:按本文 2.2 节步骤安装 JDK 8、Docker、Docker Compose,无需安装 ES(容器化部署);
- 代码下载:将本文所有核心代码复制到本地,按包结构创建 Maven 项目(groupId: com.maternal, artifactId: maternal-product-search)。
9.2.2 项目构建(5 分钟)
- 配置 pom.xml:将本文 3.1 节完整 pom.xml 复制到项目根目录,刷新 Maven 依赖;
- 配置 application.yml:将本文 3.2 节配置文件复制到 src/main/resources 目录,修改服务器 IP 为自身服务器 IP;
- 构建项目:在项目根目录执行
mvn clean package -Dmaven.test.skip=true,生成 jar 包(target/maternal-product-search-1.0.0.jar)。
9.2.3 容器部署(10 分钟)
- 编写 Dockerfile:将本文 5.1 节 Dockerfile 复制到项目根目录;
- 构建镜像:执行
docker build -t maternal-product-search:1.0.0 .; - 编写 docker-compose.yml:将本文 5.2 节配置文件复制到项目根目录,修改服务器 IP;
- 启动服务:执行
docker-compose up -d,查看容器状态(docker-compose ps),确保容器正常启动。
9.2.4 功能验证(5 分钟)
- 健康检查:访问
http://服务器IP:8080/actuator/health,返回{"status":"UP"}即为应用正常; - 品牌查询:访问
http://服务器IP:8080/api/product/brands,返回品牌列表即为接口正常; - 商品搜索:通过 PostMan 调用
http://服务器IP:8080/api/product/search,传入关键字,返回商品列表即为搜索功能正常。
9.2.5 收尾与后续操作(2 分钟,可选)
- 服务开机自启:修改 docker-compose.yml 中
restart: always已配置开机自启,无需额外操作; - 日志查看:执行
docker-compose logs -f 容器名称,实时查看应用运行日志,排查业务异常; - 服务停止:若需停止服务,执行
docker-compose down,彻底停止并删除容器; - 后续优化:若需提升性能,可参考本文「性能优化实战」章节,配置本地缓存、限流等功能。
注意事项:单机部署时,ES 集群可改为单节点(修改 elasticsearch.yml 节点角色为
[master, data, ingest]),无需配置冷热分离,降低部署复杂度,便于新手快速上手。
结束语:
亲爱的 Java 和 大数据爱好者们,至此,这套基于 Spring Boot+Elasticsearch 的母婴电商商品搜索系统实战全解已全部呈现。从技术选型的底层逻辑、核心代码的精细实现,到容器化部署的落地细节、监控告警的全方位覆盖,再到故障应急的实战方案、性能优化的核心技巧,以及真实大促案例的深度复盘,我们构建了一套完整、可落地、高性能的搜索系统解决方案。
这套方案历经十余年电商架构实战验证,承载过千万级日活流量,支撑过双 11、618 等大型促销活动,既兼顾了新手入门的友好性,也满足了资深架构师在高并发场景下的技术需求。希望每一位读者都能从中汲取实用经验,将这些技术方案灵活运用到自身的项目开发中,在提升系统性能与稳定性的同时,也能沉淀属于自己的技术方法论。
技术之路,永无止境。母婴电商的业务场景在不断迭代,搜索技术也在持续演进,未来我们还可以探索向量检索在商品推荐中的融合、AI 分词在母婴专属词汇中的优化等前沿方向。期待与各位技术同仁在技术之路上并肩前行,共同成长,打造出更多高性能、高可用的核心业务系统。
为了更好地了解大家的技术需求,现发起以下投票,欢迎各位踊跃参与。