项目介绍:
会基于ShareGPT数据,使⽤QLoRA微调Qwen2 7B模型,并且在微调过程中使⽤Flash Attention技术。 最终实现⼀个简单的对⻬后模型。
QLoRA微调是什么?
Flash Attention技术是什么?
一,如何为⼀个⼤模型微调项⽬制定解决⽅案
需求分析
- 了解的是下游任务所属的领域,从⽽为微调任务选择合适的基座模型。
- 了解模型所要具备的能⼒,确定微调技术方案。
- 收集微调数据,确定应该使⽤什么类型的评测数据。
模型选择
- 语言:中文还是英文。如果需要应对的是英⽂任务,可以考虑选择llama系列的模型。如果需要考虑中⽂场景,则可以考虑通义千问系列。或者直接⽆脑选择Qwen。
- base模型还是chat模型 :选择base模型还是chat模型主要由你⼿头的数据量所决定。
- 如果微调阶段可以获取的数据量较⼤(如10B以上的token),或者有很多专业知识要注⼊,那么可以考虑使⽤base模型,通过⼆阶段预训练先注⼊相关知识,然后使⽤微调数据激发模型的指令微调能⼒。
- 如果⼿头上只有较少的指令微调数据,那么chat模型是⼀个不错的选择。
数据准备
- 准备数据:包括寻找开源数据,构造领域专有数据。开源数据:Huggingface,modelscope,github等
- 数据清洗
- 数据预处理
模型训练和评估
- 模型微调的方法:大模型微调(学习笔记一)
- 模型评估方法(待补充)
使⽤QLoRA⽅法和Flash Attention微调Qwen系列模型
python
#用pytorch实现了一个self-attention函数
import torch
def torch_attention(q, k, v, mask=None):
'''
PyTorch implementation of the scaled dot-product attention mechanism.
Parameters:
q: query tensor, [batch_size, n_heads, seq_len, hidden_size]
k: key tensor, [batch_size, n_heads, seq_len, hidden_size]
v: value tensor, [batch_size, n_heads, seq_len, hidden_size]
mask: mask tensor, [batch_size, n_heads, seq_len, seq_len]
Returns:
attention output: output tensor, [batch_size, n_heads, seq_len, hidden_size]
'''
hidden_size = q.size(-1)
scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(hidden_size, dtype=torch.float16)) # [batch_size, n_heads, seq_len, seq_len]
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
weights = torch.nn.functional.softmax(scores, dim=-1)
return torch.matmul(weights, v) # [batch_size, n_heads, seq_len, hidden_size]
#设置随机变量
import torch
batch_size = 4
n_heads = 2
seq_len = [2, 3, 8, 4]
hidden_size = 32
q = torch.randn(batch_size, n_heads, max(seq_len), hidden_size, dtype=torch.float16, device='cuda')
k = torch.randn(batch_size, n_heads, max(seq_len), hidden_size, dtype=torch.float16, device='cuda')
v = torch.randn(batch_size, n_heads, max(seq_len), hidden_size, dtype=torch.float16, device='cuda')
#分别使用pytorch实现和`flash_attn`库中所提供的attention实现计算注意力机制的输出。并且比较两个输出的结果
import torch
from flash_attn import flash_attn_func
torch_attention_output = torch_attention(q, k, v)
flash_attn_output = flash_attn_func(
q.transpose(1, 2),
k.transpose(1, 2),
v.transpose(1, 2)).transpose(1, 2)
def compare_tensors(t1, t2):
return torch.allclose(t1, t2, atol=1e-3)
print(compare_tensors(torch_attention_output, flash_attn_output))
print(torch_attention_output[0][0][0])
print(flash_attn_output[0][0][0])二、代码实现流程
1.下载模型
可以在在Huggingface的模型仓库或者在ModelScope下载Qwen模型(Qwen2.5-3B-Instruct)
AutoDL可以开启学术加速
source /etc/network_turbo
取消学术加速
unset http_proxy && unset https_proxy
方式,优点,缺点,推荐场景
ModelScope,国内速度最快,中文支持好,模型库相对 HF 略小,国内微调首选
Hugging Face,模型最全,更新最快,国内网络受限,需配置镜像,找最新/冷门医疗模型
Git LFS,纯命令行工具,不依赖 Python,无法断点续传,易报错,仅需简单拉取少量代码
| 方式 | 优点 | 缺点 |
|---|---|---|
| ModelScope | 国内速度最快,中文支持好 | 模型库相对 HF 略小 |
| Hugging Face | 模型最全,更新最快 | 国内网络受限,需配置镜像 |
| Git | 纯命令行工具,不依赖 Python | 无法断点续传,易报错 |
方法1:
- 安装huggingface_hub: pip install -U "huggingface_hub"
- 安装hf-cli (huggingface-cli改名为hf-cli): pip install hf-cli
- 输入:huggingface-cli login。连接到自己huggingface,输入自己的token
- 下载模型:hf download Qwen/Qwen2.5-3B-Instruct --local-dir ./Qwen2.5-3B-Instruct

方法2:
- 安装包:pip install modelscope
- 下载模型
modelscope download --model 'qwen/Qwen2.5-3B-Instruct' --local_dir './Qwen2.5-3B-Instruct'
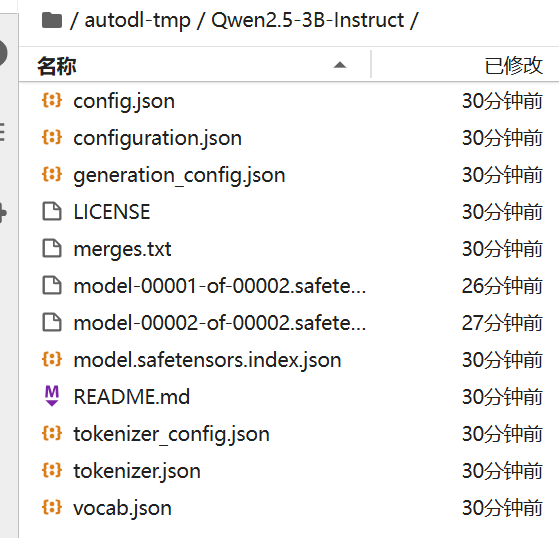
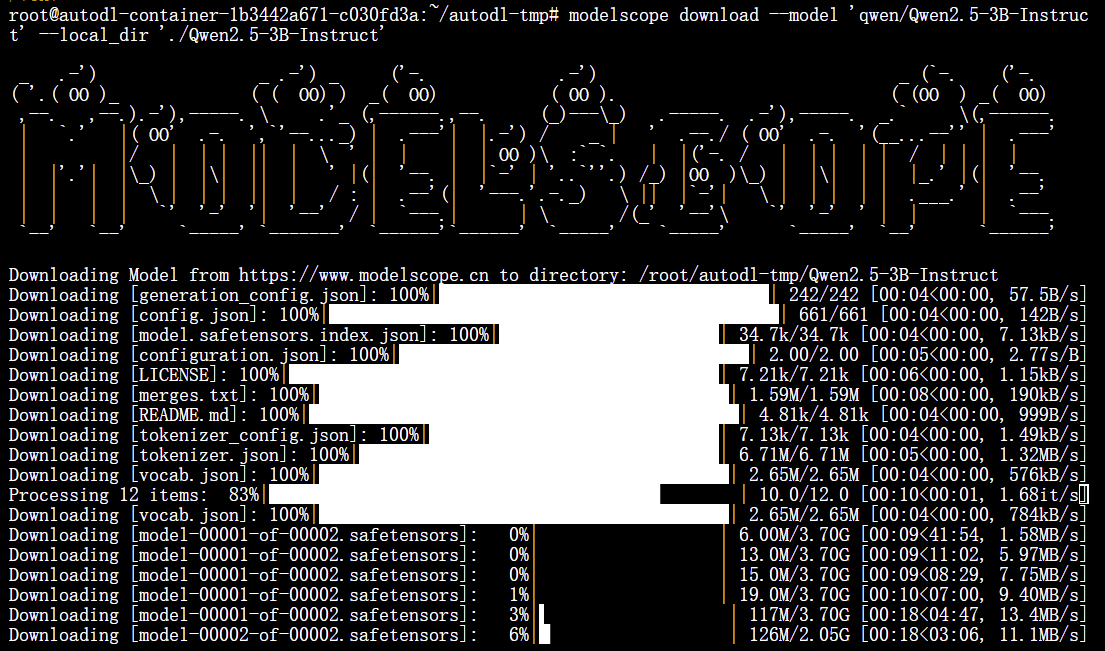 下载后的文件目录结构:
下载后的文件目录结构:
2. 配置环境
pip install transformers=='4.45.2' peft=='0.13.1' accelerate=='1.0.0'
tiktoken=='0.8.0' bitsandbytes=='0.44.1'
- transformers: 这个库提供了常⻅预训练模型的实现,并且基本上已经成为了⾃然语⾔处理任务的标准库。被⼴泛地应⽤在各类NLP相关应⽤中。
- peft: 这个库和transformers⼀样,都是由huggingface这个组织所维护和开发的。它的主要功能是提供了各类低参数量微调算法的实现,⽐如Lora等。
- bitsandbytes: 这个库提供了很多⾼效的位操作和字节级别的处理能⼒,⾮常适合深度学习任务中对于性能要求⽐较⾼的场景,并且集成了各类低⽐特量化算法的实现。
- accelerate: 这个库也是由huggingface这个组织所维护和开发的,是huggingface全家桶中的重要⼀员。它提供了多种并⾏训练功能,并且⽀持多GPU训练。这个库已经被深度集成在huggingface全家桶中。
3. 数据集准备
4. 配置模型
python
compute_dtype = getattr(torch, "float16")
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=True,
)5.模型微调
完整代码
python
#导入需要使用的各个库
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # 这里设置使用哪块GPU
from torch.utils.data import Dataset # 用于自定义数据集
from transformers import (
AutoModelForCausalLM, # 用于加载预训练模型
AutoTokenizer, # 用于加载分词器
BitsAndBytesConfig, # 用于加载配置文件
TrainingArguments, # 用于加载训练参数
Trainer, # 用于训练
DataCollatorForLanguageModeling, # 用于处理数据
)
import torch
import time
import json
import random
#加载数据集
import csv
import pprint
def load_dataset(filename):
data_list = []
# read csv
with open(filename, "rb") as f:
raw = f.read(50000)
print(chardet.detect(raw))
with open(filename, "r", encoding="utf-8") as f: # 这里使用utf-8编码,你可以更换编码
reader = csv.DictReader(f) # 使用csv.DictReader读取csv文件
for row in reader:
data_list.append(
{
'department': row['department'],
'input': row['ask'],
'output': row['answer']
}
)
return data_list
dataset = load_dataset("数据_utf8.csv") # 读取数据
print('len(dataset):', len(dataset))
pprint.pprint(dataset[0])
#准备可以用来模型训练的数据集,包括医疗对话数据和自我认知数据
def prepare_message(data_list):
new_list = []
for i, data in enumerate(data_list):
_id = f"identity_{i}"
new_list.append(
{
"id": _id,
"conversations": [ # 将所输入的对话转换成conversations的形式
{
"from": "user",
"value": data["input"]
},
{
"from": "assistant",
"value": data["output"]
}
]
})
return new_list
def replace_name(s):
s = s.replace('<NAME>', '智能医生客服机器人小D')
s = s.replace('<AUTHOR>', 'Greedy AI')
return s
def load_self_cong_data(filename):
data_list = []
id = 0
for d in json.load(open(filename, "r", encoding="utf-8")):
d["instruction"] = replace_name(d["instruction"]) # 将instruction中的<NAME>和<AUTHOR>替换成智能医生客服机器人小D和Greedy AI
d["output"] = replace_name(d["output"])
data_list.append({
"id": id,
"conversations": [
{
"from": "user",
"value": d["instruction"]
},
{
"from": "assistant",
"value": d["output"]
}
]
})
id += 1
return data_list
self_cong_data = load_self_cong_data("self_cognition.json") # 读取自我认知数据
format_data_list = prepare_message(dataset[:1000]) # 将数据转换成conversations的形式
format_data_list = self_cong_data + format_data_list
random.shuffle(format_data_list) # 打乱数据
print(format_data_list[0])
#设置LoRA参数和量化参数
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
output_dir = 'checkpoints_self_cong/'
# 设置LoRA参数
config = LoraConfig(
r=32, # LoRA所使用的Rank,r 越大:可学习能力越强,参数越多;r 越小:更省显存,但可能欠拟合
lora_alpha=16, # LoRA的Alpha 缩放因子
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # LoRA所作用的模块,告诉 LoRA:只在注意力层改动。
bias="none", # LoRA的Bias,这里设置为none,表示不使用Bias
lora_dropout=0.05, # LoRA的Dropout,这里设置为0.05
task_type="CAUSAL_LM", #告诉 PEFT:这是一个"自回归语言模型"任务
)
compute_dtype = getattr(torch, "float16")
quant_config = BitsAndBytesConfig(
load_in_4bit=True, # 加载4bit量化模型 基座模型用 4-bit 加载
bnb_4bit_quant_type="nf4", # 量化类型,这里使用nf4
bnb_4bit_compute_dtype=compute_dtype, # 计算精度,这里使用float16
bnb_4bit_use_double_quant=True, # 使用双量化
)
peft_training_args = TrainingArguments(
output_dir = output_dir, # 输出目录
warmup_steps=1, # warmup步数,一般在训练模型时,都会将学习率从0逐渐增加到一个较大的值,这个过程就是warmup
per_device_train_batch_size=1, # 每个设备的训练batch_size
gradient_accumulation_steps=1, # 梯度累积步数
learning_rate=2e-4, # 学习率
optim="paged_adamw_8bit", # 优化器,这里使用paged_adamw_8bit
logging_steps=100, # 多少步打印一次日志
logging_dir="./logs", # 日志目录
save_strategy="steps", # 保存策略,按照步数保存
max_steps=1000, # 要训练多少步
save_steps=500, # 多少步保存一次
gradient_checkpointing=True, # 是否使用gradient_checkpointing功能,这个功能可以节省显存
report_to="none", # 不输出报告,这里可以设置成向tensorboard和wandb输出报告
overwrite_output_dir = True, # 是否覆盖输出目录
group_by_length=True, # 是否根据长度分组,这个参数可以加速训练,其原理是将长度相近的数据放在一起
)
#加载模型并且开始训练
# 加载预训练模型
original_model = AutoModelForCausalLM.from_pretrained(
model_path, # 预训练模型所存放的路径
quantization_config=quant_config, # 使用什么样的量化配置
attn_implementation="flash_attention_2", # 是否要使用flash attention,这里的设置是使用flash attention
)
# 1 - Enabling gradient checkpointing to reduce memory usage during fine-tuning
original_model.gradient_checkpointing_enable()
# 2 - Using the prepare_model_for_kbit_training method from PEFT
original_model = prepare_model_for_kbit_training(original_model)
peft_model = get_peft_model(original_model, config) # 基于LoRA的配置获取PEFT模型
peft_model.config.use_cache = False
peft_trainer = Trainer( # 定义Trainer
model=peft_model,
train_dataset=train_dataset,
args=peft_training_args,
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
torch.cuda.empty_cache()
start_time = time.time()
peft_trainer.train() # 开始训练
end_time = time.time()
print(f"Training time: {end_time - start_time} seconds")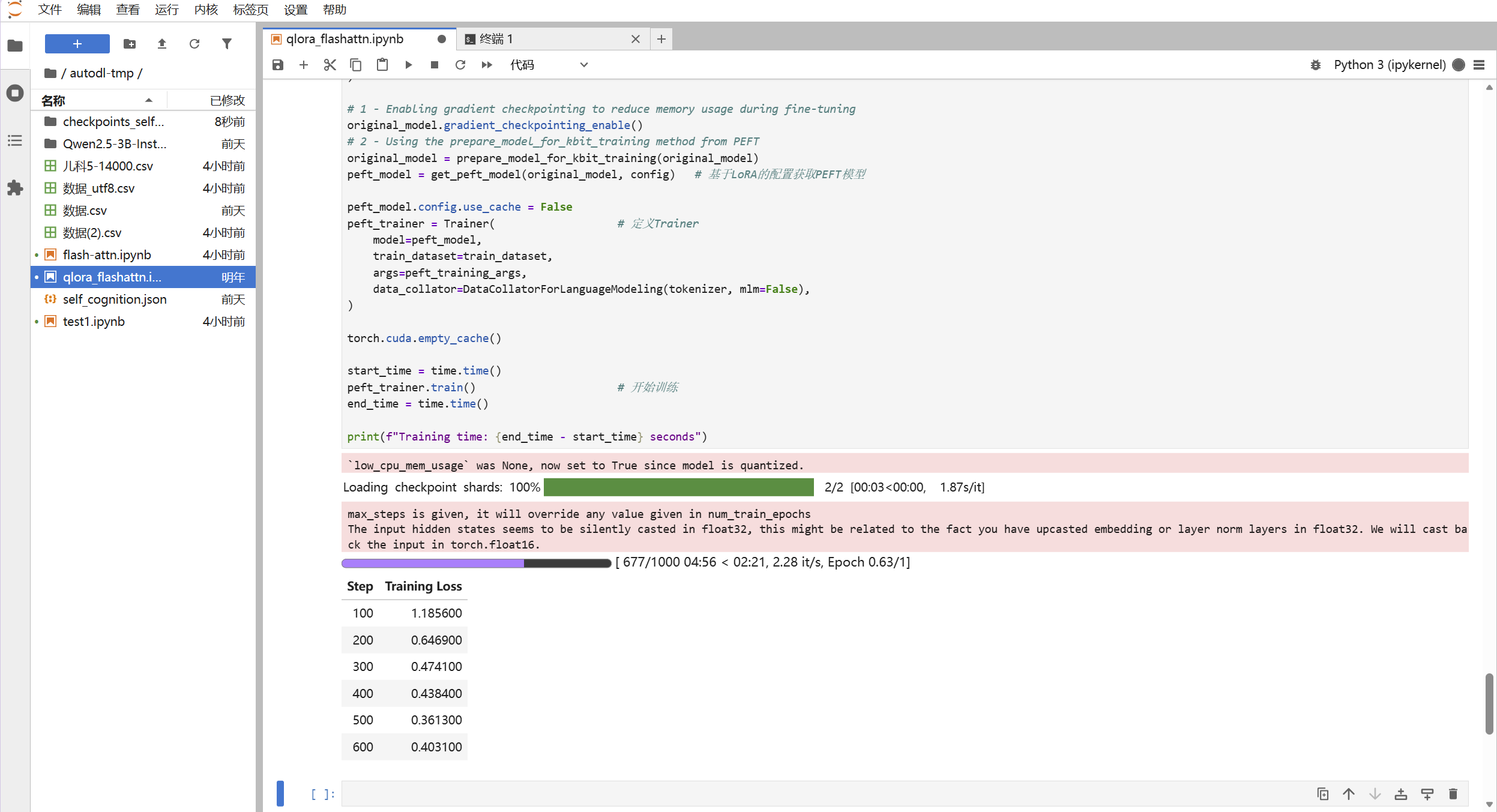
补充
- 在 qlora 环境里注册 Jupyter kernel,并立即可在 Notebook 使用:
激活 qlora 环境
conda activate qlora
安装 ipykernel(如果尚未安装)
pip install ipykernel
在 Jupyter 中注册 kernel
python -m ipykernel install --user --name qlora --display-name "Python (qlora)"
确认 kernel 已注册
jupyter kernelspec list