
文章目录
-
- [一、先搞懂:为什么需要 "创建进程"?](#一、先搞懂:为什么需要 “创建进程”?)
- [二、fork 函数:创建进程的 "魔法指令"](#二、fork 函数:创建进程的 “魔法指令”)
-
- [2.1 fork 函数的基本用法](#2.1 fork 函数的基本用法)
- [2.2 深入内核:fork 时系统到底在做什么?](#2.2 深入内核:fork 时系统到底在做什么?)
-
- [步骤 1:为子进程分配内核数据结构](#步骤 1:为子进程分配内核数据结构)
- [步骤 2:拷贝父进程的核心数据结构](#步骤 2:拷贝父进程的核心数据结构)
- [步骤 3:将子进程加入系统进程列表](#步骤 3:将子进程加入系统进程列表)
- [步骤 4:返回并触发调度](#步骤 4:返回并触发调度)
- [2.3 fork 调用失败:什么时候会出问题?](#2.3 fork 调用失败:什么时候会出问题?)
- [三、写时拷贝(COW):让进程创建更高效的 "黑科技"](#三、写时拷贝(COW):让进程创建更高效的 “黑科技”)
-
- [3.1 先理解:为什么需要写时拷贝?](#3.1 先理解:为什么需要写时拷贝?)
- [3.2 写时拷贝的完整流程:从共享到独立](#3.2 写时拷贝的完整流程:从共享到独立)
-
- [步骤 1:初始共享(标记为 "只读")](#步骤 1:初始共享(标记为 “只读”))
- [步骤 2:写操作触发 "页错误"](#步骤 2:写操作触发 “页错误”)
- [步骤 3:内核执行 "按需拷贝"](#步骤 3:内核执行 “按需拷贝”)
- [步骤 4:恢复子进程执行](#步骤 4:恢复子进程执行)
- [3.3 写时拷贝的核心价值:效率 + 内存双优化](#3.3 写时拷贝的核心价值:效率 + 内存双优化)
-
- [优化 1:提升进程创建效率](#优化 1:提升进程创建效率)
- [优化 2:减少内存浪费](#优化 2:减少内存浪费)
- [四、fork 的典型应用场景:不止 "分叉" 这么简单](#四、fork 的典型应用场景:不止 “分叉” 这么简单)
-
- [场景 1:父子进程分工协作](#场景 1:父子进程分工协作)
- [场景 2:子进程执行全新程序(Shell 的核心逻辑)](#场景 2:子进程执行全新程序(Shell 的核心逻辑))
- [五、扩展:fork 与 vfork 的区别(避免踩坑)](#五、扩展:fork 与 vfork 的区别(避免踩坑))
- 六、总结与下一篇预告
在 Linux 进程控制系统中,进程创建 是一切并发任务的起点 ------ 小到 Shell 执行ls命令,大到服务器同时处理上千个客户端请求,背后都依赖进程创建机制实现 "多任务并行"。而这一切的核心,就是fork函数与写时拷贝(Copy-On-Write,COW)机制。本篇文章会从 "为什么需要创建进程" 出发,一步步拆解fork函数的工作原理,用通俗的类比和实战代码揭开写时拷贝的神秘面纱,让你彻底搞懂 Linux 如何高效创建新进程。
一、先搞懂:为什么需要 "创建进程"?
在理解fork函数之前,我们先明确一个核心问题:为什么要创建新进程?
想象两个场景:
- 你在终端输入
ls命令时,Shell(比如 bash)需要启动一个专门的 "小任务" 去执行ls的逻辑,自己则继续等待你输入下一条命令 ------ 这就需要创建新进程来隔离 "Shell 等待" 和 "ls 执行" 两个任务。 - 一个 Web 服务器需要同时处理 100 个用户的请求,如果只用一个进程,用户 A 的请求没处理完,用户 B 就得一直等 ------ 这时候就需要为每个请求创建新进程(或线程),实现 "并发响应"。
简单说,进程创建的本质是 "拆分任务、实现并发" ,让多个执行流独立运行且互不干扰。而 Linux 中实现这一功能的核心工具,就是fork函数。
二、fork 函数:创建进程的 "魔法指令"
fork函数的名字来源于 "分叉"------ 调用它之后,原本的一个进程会 "分叉" 成两个几乎完全相同的进程:父进程 (原来的进程)和子进程 (新创建的进程)。这两个进程拥有独立的执行流,从fork调用后的代码开始分别执行。
2.1 fork 函数的基本用法
先看fork的 "身份信息",这是调用它的基础:
c
#include <unistd.h> // 头文件
pid_t fork(void); // 函数原型- 返回值 :
pid_t类型(本质是整数),但它有 3 种可能的结果,这是fork最特殊的地方:- 对父进程:返回新创建的子进程的 PID(进程 ID)------ 父进程需要通过 PID 管理子进程。
- 对子进程 :返回 0------ 子进程不需要自己的 PID 来标识自己,若要找父进程,可调用
getppid()。 - 出错时:返回 - 1------ 比如系统中进程数量太多,或当前用户的进程数超过了系统限制。
举个最简单的例子,感受fork的 "分叉" 效果:
c
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h> // 后面waitpid会用到
int main() {
printf("fork前:当前进程PID = %d\n", getpid()); // getpid()获取当前进程PID
pid_t pid = fork(); // 调用fork,创建子进程
if (pid == -1) { // 出错处理
perror("fork失败"); // 打印错误原因,比如"fork失败: Resource temporarily unavailable"
return 1;
}
// fork后:父进程和子进程都会执行下面的代码
if (pid == 0) {
// 子进程:fork返回0
printf("我是子进程,我的PID = %d,父进程PID = %d\n", getpid(), getppid());
sleep(1); // 让子进程多活1秒,避免父进程先退出
} else {
// 父进程:fork返回子进程PID
printf("我是父进程,我的PID = %d,子进程PID = %d\n", getpid(), pid);
waitpid(pid, NULL, 0); // 父进程等待子进程退出,避免子进程变成僵尸进程
}
return 0;
}编译运行(gcc fork_demo.c -o fork_demo && ./fork_demo),会看到类似输出:

注意一个关键细节:fork前的打印只执行了 1 次,而fork后的打印执行了 2 次 ------ 这就是 "分叉" 的本质:fork调用前只有 1 个进程,调用后变成 2 个进程,分别执行fork之后的代码。
2.2 深入内核:fork 时系统到底在做什么?
当你调用fork时,Linux 内核会悄悄完成一系列复杂操作,确保子进程能独立运行且不干扰父进程。我们把这些操作拆解成 4 步,帮你 "看透" 内核的工作:
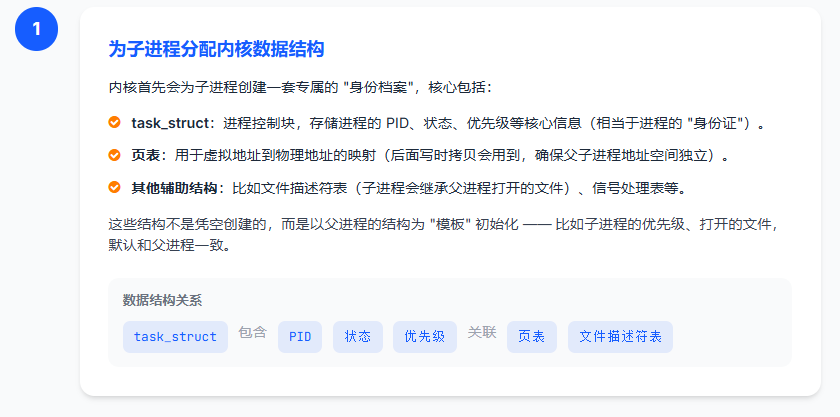
步骤 1:为子进程分配内核数据结构
内核首先会为子进程创建一套专属的 "身份档案",核心包括:
- task_struct:进程控制块,存储进程的 PID、状态、优先级等核心信息(相当于进程的 "身份证")。
- 页表:用于虚拟地址到物理地址的映射(后面写时拷贝会用到,确保父子进程地址空间独立)。
- 其他辅助结构:比如文件描述符表(子进程会继承父进程打开的文件)、信号处理表等。
这些结构不是凭空创建的,而是以父进程的结构为 "模板" 初始化 ------ 比如子进程的优先级、打开的文件,默认和父进程一致。
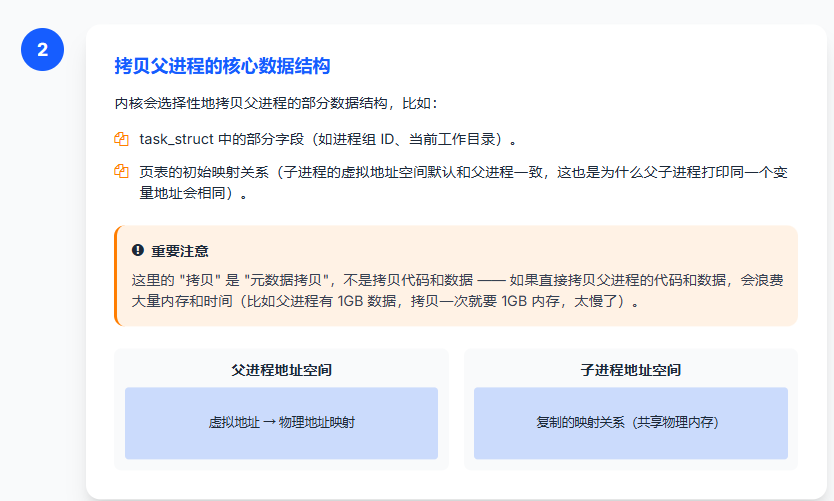
步骤 2:拷贝父进程的核心数据结构
内核会选择性地拷贝父进程的部分数据结构,比如:
- task_struct 中的部分字段(如进程组 ID、当前工作目录)。
- 页表的初始映射关系(子进程的虚拟地址空间默认和父进程一致,这也是为什么父子进程打印同一个变量地址会相同)。
注意:这里的 "拷贝" 是 "元数据拷贝",不是拷贝代码和数据 ------ 如果直接拷贝父进程的代码和数据,会浪费大量内存和时间(比如父进程有 1GB 数据,拷贝一次就要 1GB 内存,太慢了)。
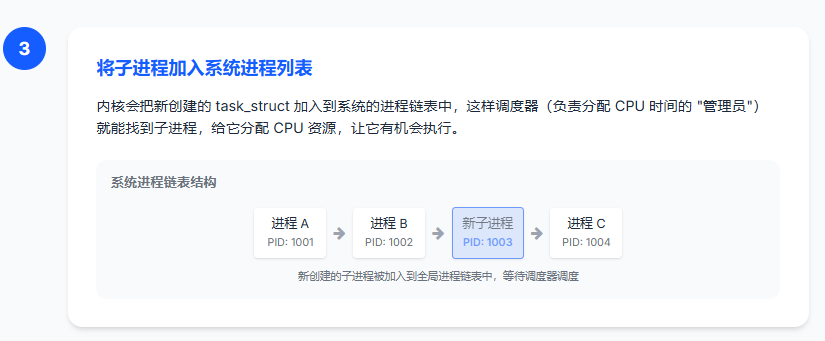
步骤 3:将子进程加入系统进程列表
内核会把新创建的 task_struct 加入到系统的进程链表中,这样调度器(负责分配 CPU 时间的 "管理员")就能找到子进程,给它分配 CPU 资源,让它有机会执行。
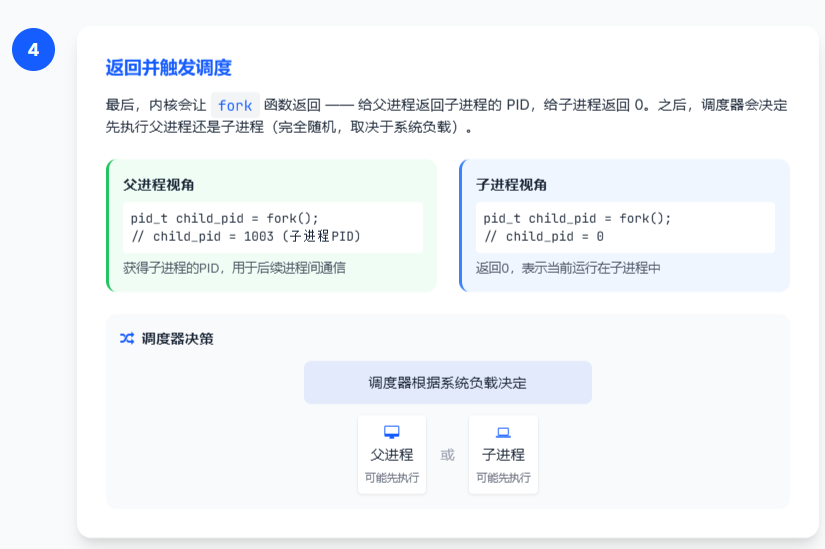
步骤 4:返回并触发调度
最后,内核会让fork函数返回 ------ 给父进程返回子进程的 PID,给子进程返回 0。之后,调度器会决定先执行父进程还是子进程(完全随机,取决于系统负载)。
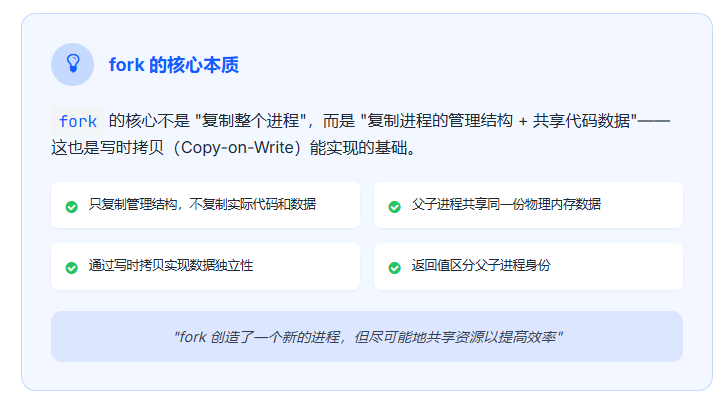
总结一下:fork的核心不是 "复制整个进程",而是 "复制进程的管理结构 + 共享代码数据"------ 这也是写时拷贝能实现的基础。
2.3 fork 调用失败:什么时候会出问题?
虽然fork很常用,但它也可能失败,主要有两种场景:
- 系统进程数量超过上限 :Linux 系统对最大进程数有全局限制(可通过
cat /proc/sys/kernel/pid_max查看,默认一般是 32768),如果当前系统进程数已经达到这个值,fork会失败。 - 当前用户的进程数超过限制 :系统也会限制单个用户的最大进程数(可通过
ulimit -u查看,默认一般是 1024),比如普通用户最多创建 1024 个进程,超过后fork会失败。
如果fork失败,一定要用perror打印错误原因,它会帮你定位是 "资源不足" 还是 "权限问题"。
三、写时拷贝(COW):让进程创建更高效的 "黑科技"
前面我们提到:fork不会直接拷贝父进程的代码和数据 ------ 那父子进程是如何共享代码数据,又如何保证独立修改不干扰的?答案就是写时拷贝(Copy-On-Write,COW) 机制 ------ 这是 Linux 优化进程创建效率的核心 "黑科技"。
3.1 先理解:为什么需要写时拷贝?
在写时拷贝出现之前,Linux 用 "直接拷贝" 的方式创建子进程:父进程有多少代码和数据,子进程就拷贝多少。这种方式有两个严重问题:
- 效率低:如果父进程有 1GB 数据,拷贝一次需要几百毫秒,创建进程太慢。
- 内存浪费 :如果子进程创建后只是执行
exec(替换成新程序,后面文章会讲),那之前拷贝的 1GB 数据完全没用,白浪费内存。
写时拷贝的思路很简单:"能不拷贝就不拷贝,非要拷贝再拷贝"------ 父子进程先共享同一块物理内存,只有当某一方要修改内存中的数据时,才拷贝对应的内存页(通常是 4KB),实现 "按需拷贝"。
我们用一个类比帮你理解:你和同事共享一份 "项目文档"(物理内存),平时你们都只读,不需要各自抄一份;如果同事要修改文档中的某一页,他会把这一页抄下来修改,你手里的原文档不变 ------ 这样既不影响共享,又避免了整份文档拷贝的浪费。
3.2 写时拷贝的完整流程:从共享到独立
写时拷贝的工作过程可以分为 4 步,结合前面的fork例子,帮你彻底搞懂:
步骤 1:初始共享(标记为 "只读")
fork创建子进程后,内核会做两件关键操作:
- 让父子进程的页表指向同一块物理内存(代码段、数据段、堆、栈都共享)。
- 把共享的物理内存页标记为 "只读"(通过修改页表项的权限位)------ 不管是父进程还是子进程,想修改这些内存页,都会触发 "页错误"(CPU 发现对只读内存的写操作,会告诉内核 "有人违规写内存了")。
这时候,父子进程的代码和数据完全共享 ------ 比如父进程有一个全局变量g_val = 10,子进程访问g_val时,和父进程访问的是同一块物理内存,所以看到的值都是 10。
步骤 2:写操作触发 "页错误"
假设子进程要修改g_val的值(比如g_val = 20),当它执行这个写操作时:
- CPU 检查内存页的权限(发现是 "只读"),立刻触发 "页错误"(Page Fault),暂停子进程的执行,把控制权交给内核。
步骤 3:内核执行 "按需拷贝"
内核收到 "页错误" 后,会判断这是 "写时拷贝触发的错误",然后做 3 件事:
- 分配新的物理内存页:内核会找一块空闲的物理内存(比如 4KB 大小)。
- 拷贝原内存页的数据 :把
g_val所在的原物理内存页的数据,拷贝到新分配的物理内存页(比如原页有g_val=10,拷贝后新页也有g_val=10)。 - 更新子进程的页表 :把子进程页表中 "
g_val对应的虚拟地址" 的映射,从 "原物理页" 改成 "新物理页",并把新物理页的权限改成 "可写"。
步骤 4:恢复子进程执行
内核做完上述操作后,会让子进程继续执行 ------ 这时候子进程修改g_val,实际上修改的是新物理页中的数据,父进程访问的还是原物理页,所以父子进程的g_val就变成了不同的值,实现了 "数据独立"。

我们用一个代码例子验证写时拷贝的效果:
c
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int g_val = 10; // 全局变量,父子进程初始共享
int main() {
pid_t pid = fork();
if (pid == -1) {
perror("fork失败");
return 1;
}
if (pid == 0) {
// 子进程:修改g_val
g_val = 20;
printf("子进程:g_val = %d,g_val地址 = %p\n", g_val, &g_val);
sleep(1);
} else {
// 父进程:不修改g_val
waitpid(pid, NULL, 0); // 等子进程修改完再打印
printf("父进程:g_val = %d,g_val地址 = %p\n", g_val, &g_val);
}
return 0;
}运行结果:

神奇的现象:父子进程打印的g_val地址完全相同,但值不同 ------ 这就是写时拷贝的功劳:地址是虚拟地址,父子进程虚拟地址相同,但映射到不同的物理地址,所以值不同。
3.3 写时拷贝的核心价值:效率 + 内存双优化
写时拷贝之所以被称为 "黑科技",是因为它完美解决了 "直接拷贝" 的两大问题,带来了双重优化:
优化 1:提升进程创建效率
fork时不需要拷贝代码和数据,只需要创建内核结构和初始化页表 ------ 这个过程只需要几微秒到几毫秒,比直接拷贝快几个数量级(比如父进程有 1GB 数据,直接拷贝要几百毫秒,写时拷贝只需 1 毫秒)。
这对 Shell、服务器等需要频繁创建进程的场景至关重要 ------ 比如 Shell 执行一条命令,fork+exec总共只需几毫秒,用户几乎感觉不到延迟。
优化 2:减少内存浪费
父子进程共享未修改的代码和数据,不需要为子进程分配额外内存 ------ 比如父进程有 1GB 数据,子进程只修改了 4KB,那子进程只需额外占用 4KB 内存,而不是 1GB。
更关键的是:如果子进程创建后立刻调用exec(替换成新程序),那么子进程根本不会修改父进程的代码和数据,写时拷贝一次都不会触发 ------ 这样就完全避免了内存浪费,这也是 Shell 执行命令的核心优化。
四、fork 的典型应用场景:不止 "分叉" 这么简单
学会fork之后,你可能会问:实际开发中,fork到底用来做什么?我们总结了两个最典型的场景,帮你把知识和实际应用结合起来。
场景 1:父子进程分工协作
父进程和子进程执行不同的代码段,实现 "分工协作"------ 比如服务器程序:
- 父进程:监听客户端的连接请求(比如在 80 端口等待浏览器连接)。
- 子进程:一旦有客户端连接,父进程就
fork一个子进程,让子进程负责处理这个客户端的请求(比如传输网页数据),父进程继续监听下一个连接。
这种模式能实现 "并发处理多个客户端",是 Web 服务器(如 Nginx 早期版本)的核心工作原理。
我们用一个简化的代码示例,展示这种分工:
c
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
void handle_client(int client_fd) {
// 子进程:处理客户端请求(这里简化为打印信息)
printf("子进程%d:开始处理客户端请求\n", getpid());
sleep(3); // 模拟处理请求的耗时
printf("子进程%d:处理完客户端请求\n", getpid());
}
int main() {
int client_fd = 0; // 简化:假设客户端连接的文件描述符为0
while (1) {
// 父进程:监听客户端连接(这里简化为循环)
printf("父进程%d:等待客户端连接...\n", getpid());
sleep(2); // 模拟等待连接的耗时
pid_t pid = fork();
if (pid == -1) {
perror("fork失败");
continue;
}
if (pid == 0) {
// 子进程:处理客户端请求
handle_client(client_fd);
return 0; // 子进程处理完后退出
} else {
// 父进程:继续监听,同时回收已退出的子进程(避免僵尸进程)
waitpid(-1, NULL, WNOHANG); // 非阻塞回收,不影响监听
}
}
return 0;
}场景 2:子进程执行全新程序(Shell 的核心逻辑)
fork创建的子进程默认执行和父进程相同的代码,但实际中,我们常让子进程执行全新的程序 (比如 Shell 执行ls、cd命令)------ 这需要结合exec系列函数(后面文章会讲),但fork是基础。
比如你在 Shell 中输入ls时,Shell 的工作流程是:
- Shell(父进程)调用
fork,创建一个子进程。 - 子进程调用
exec,把自己的代码和数据替换成ls程序的代码和数据。 - 父进程调用
wait,等待子进程执行完ls,然后继续等待你输入下一条命令。
这个流程中,fork的作用是 "创建一个空白的执行载体",exec的作用是 "给载体填充新程序"------ 两者结合,就是 Shell 执行命令的核心逻辑。
五、扩展:fork 与 vfork 的区别(避免踩坑)
除了fork,Linux 还有一个创建进程的函数vfork------ 很多初学者会把它和fork混淆,甚至踩坑。我们用一个表格,帮你清晰区分两者的核心差异:
| 对比维度 | fork | vfork |
|---|---|---|
| 地址空间 | 父子进程独立(通过页表和写时拷贝实现) | 父子进程共享地址空间(子进程修改数据会影响父进程) |
| 执行顺序 | 父进程和子进程执行顺序随机 | 子进程必须先执行,子进程退出或exec后父进程才执行 |
| 用途 | 通用进程创建(大部分场景) | 仅用于创建子进程后立刻exec(如早期 Shell) |
| 风险 | 低(地址空间独立,不干扰) | 高(共享地址空间,子进程修改父进程数据会导致崩溃) |
警告 :除非你明确知道自己在做什么,否则不要用vfork------ 它的 "共享地址空间" 特性很容易导致 bug,比如子进程修改了父进程的变量,父进程后续执行就会出错。现在fork+ 写时拷贝的效率已经很高,vfork几乎被淘汰,只在一些极端场景(如嵌入式系统)中偶尔使用。
六、总结与下一篇预告
本篇文章我们从 "为什么需要创建进程" 出发,深入讲解了fork函数的用法、内核工作原理,以及写时拷贝如何优化进程创建效率。核心要点可以总结为 3 句话:
fork的本质是 "分叉":调用前 1 个进程,调用后 2 个进程,分别执行fork之后的代码。- 写时拷贝是 "按需拷贝":父子进程共享代码数据,修改时才拷贝对应内存页,兼顾效率和独立性。
fork的核心用途是 "分工协作" 和 "执行新程序":是 Shell、服务器等并发场景的基础。
下一篇文章,我们会讲解进程的 "终点"------进程终止 :当进程执行完任务后,如何优雅地退出?退出码是什么?exit和_exit有什么区别?这些问题都会在《进程终止 ------ 退出场景、方法与退出码详解》中为你解答。