1)是什么
🔍 定义:
Attention(注意力机制)是一种让模型在处理信息时,能"动态地关注输入中不同部分"的技术。
它不像传统模型那样"一视同仁",而是像人眼一样:
👉 看到"猫"时,会自动聚焦在"耳朵""胡须"等关键部位;
👉 生成"天气"这个词时,就去回顾输入里的"晴天""下雨"这些词。
🧠 想象一下:
你在写作文,老师说:"第三段要围绕'环保'展开。"
于是你翻书、找关键词、重点标记------这就是"注意力"。
AI 的 Attention 就是这个"自动划重点"的过程。
💡 核心思想:
"输出每一个词时,都问一句:我该看输入的哪一部分?"
比如翻译句子:
输入:"我喜欢吃苹果。"
输出:"I like eating apples."
当生成 "apples" 时,Attention 会发现:"苹果"在输入中非常重要,所以给"苹果"打高分,其他词打低分。
2)为什么
❌ 老方法的问题:Seq2Seq 的"记忆瓶颈"
我们先回顾一下 Seq2Seq(序列到序列)模型:
- 编码器读完整句 → 压缩成一个"上下文向量"(context vector)
- 解码器靠这个向量生成输出
⚠️ 问题来了:
如果输入很长(比如100个词),压缩成一个向量,信息就会丢失、模糊、混淆!
就像你把一本《红楼梦》压缩成一句话:"贾宝玉爱林黛玉。"
然后让你根据这句话写一部小说......太难了!
✅ Attention 的解决方案:
不再依赖"单一摘要",而是每一步都回头看,动态决定"现在该关注哪里"。
🎯 所以,Attention 的诞生是为了:
✅ 解决长序列信息丢失问题
✅ 提升生成质量(更准确、更连贯)
✅ 让模型具备"可解释性"(我们可以看到它"看了哪里")
🧠 类比:
以前是"背诵全文",现在是"边查资料边写论文"------效率更高,也更靠谱。
3)什么时候用
✅ 适用任务(必须用 Attention 的场景):
| 场景 | 说明 |
|---|---|
| 🌐 机器翻译 | 中文→英文,每个词都要对齐原文 |
| 📄 文本摘要 | 从长文章中提取关键信息生成摘要 |
| 💬 对话系统 | 回答用户问题时,关注相关句子 |
| 🔊 语音合成 | 把文字变成语音,需要对齐音素和文本 |
| ❤️ 推荐系统 | "你看了A,可能喜欢B" → 关注用户历史行为中的关键项 |
✅ 具体例子:
- Google Translate 用的是 Transformer + Attention
- BERT、GPT 都基于 Attention 构建
- 任何需要"跨位置关联"的任务,都是它的主场
✅ 总结:只要你的任务涉及"序列生成"且需要"灵活关注",就用 Attention!
4)什么时候不用
| 情况 | 原因 |
|---|---|
| ❌ 单词分类任务 | 比如判断"狗"是动物 → 不需要关注上下文 |
| ❌ 固定模板生成 | 如"您好,您的订单已发货" → 结构固定,无需动态调整 |
| ⏳ 计算资源紧张 | Attention 计算量大,尤其是长序列(O(n²)复杂度) |
| 🌱 数据量小 | 小数据集上容易过拟合,不如简单模型稳定 |
⚠️ 注意事项:
- Attention 可能产生"幻觉":过度关注无关内容,导致错误输出
- 需要大量标注数据训练(比如对齐关系)
- 不适合实时性要求极高的场景(如自动驾驶)
🛑 所以:不要为了用 Attention 而用 Attention!
5)总结
Attention 不是一种"万能魔法",而是一种"智能聚焦"的机制------它让模型学会在正确的时间,看正确的信息。
- ✅ 它是为了解决"信息压缩瓶颈"而生:不再把整句塞进一个向量,而是动态查阅原始输入。
- ✅ 它的核心是"相关性计算":通过 Query-Key 匹配,给 Value 加权,形成上下文感知的表示。
- ✅ 它推动了 NLP 的革命:从 Seq2Seq 到 Transformer,再到 BERT、GPT,Attention 是现代大模型的基石。
- ⚠️ 但它不是银弹:计算开销大、需要大量数据、在简单任务上可能"杀鸡用牛刀"。
🧭 使用建议:
| 你面对的问题 | 是否用 Attention? |
|---|---|
| 长序列生成、跨词依赖强(如翻译、摘要) | ✅ 强烈推荐 |
| 短文本分类、关键词匹配 | ❌ 可能过度设计 |
| 资源有限但需快速推理 | ⚠️ 考虑轻量替代(如 CNN、R以 + 局部注意力) |
| 想理解模型"为什么这么输出" | ✅ Attention 权重可可视化,提供可 |
概念
1. Seq2Seq
回顾之前RNN模型的分类,我们按照输入和输出的结构进行分类时可以分为4类:

seq2seq(序列到序列)的核心是 "输入和输出序列长度不固定",而 N vs M-RNN 的结构正好满足这一点:它由编码器(处理输入序列)和解码器(生成输出序列)组成,能处理像文本翻译这类输入输出不等长的任务,因此被直接称为 seq2seq 架构。
而另外三个:
- N vs N-RNN 是等长序列任务;
- N vs 1-RNN 是多对一的分类任务;
- 1 vs N-RNN 是一对多的生成任务;
它们都不满足 seq2seq "输入输出长度不固定" 的核心特点。
在认识注意力之前,我们先简单了解下机器翻译任务:
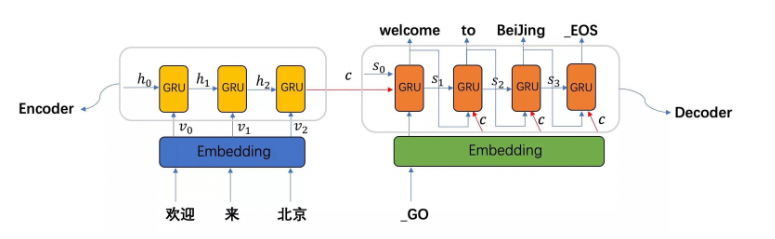
- seq2seq模型架构包括了三部分,分别是Encoder(编码器)、decoder(解码器)、中间语义张量c
- 图中表示的是一个中文到英文的翻译:欢迎 来 北京 → welcome to BeiJing。编码器首先处理中文输入"欢迎 来 北京",通过GRU模型获得每个时间步的输出张量,最后将它们拼接成一个中间语义张量c;接着解码器将使用这个中间语义张量c以及每一个时间步的隐层张量, 逐个生成对应的翻译语言
- 早期在解决机器翻译这一类seq2seq问题时,通常采用的做法是利用一个编码器(Encoder)和一个解码器(Decoder)构建端到端的神经网络模型,但是基于编码解码的神经网络存在两个问题:
- 问题1:如果翻译的句子很长很复杂,比如直接一篇文章输进去,模型的计算量很大,并且模型的准确率下降严重。
- 问题2:在翻译时,可能在不同的语境下,同一个词具有不同的含义,但是网络对这些词向量并没有区分度,没有考虑词与词之间的相关性,导致翻译效果比较差。
2. Attention机制
注意力机制早在上世纪九十年代就有研究,最早的注意力机制应用在视觉领域,后来伴随着2017年Transformer模型结构的提出,注意力机制在NLP,CV相关问题的模型网络设计上被广泛应用。注意力机制实际上就是将人的感知方式、注意力的行为应用到机器上,让机器学会去感知数据中的重要和不重要的部分
2.1 Encoder和Decoder
这里的"编码器(Encoder)"和"解码器(Decoder)"不是指 Python 中的字符串编解码(如 UTF-8 编码),也不是单纯"向量化",而是指神经网络中两个具有特定功能的子模块。
✅ 正确理解:Encoder-Decoder 是一种模型架构
"编码" ≠ 字符串编码(如 encode/decode in Python)
- Python 中的 str.encode('utf-8') 是把字符串转成字节,属于字符级数据格式转换。
- 而 NLP 中的 Encoder 是一个神经网络(如 RNN、GRU、Transformer),它的作用是:
将输入序列(如词序列)转换为富含语义的连续向量表示(即上下文感知的向量序列)
✅"向量化"只是第一步,Encoder 做得更多
- 确实,输入首先要 词嵌入(Word Embedding) → 把词变成向量(这一步可叫"向量化")
- 但 Encoder 的核心工作是:
- 接收这些初始向量
- 通过 GRU/RNN/Transformer 等结构 建模词与词之间的依赖关系
- 输出 上下文相关的隐藏状态(比如 "Apple" 在 "fruit" 和 "company" 语境下向量不同)
🔸 所以:Encoder = 向量化 + 上下文建模 → 生成语义表示
✅Decoder 也不是"解码回字符串"
- Decoder 同样是一个神经网络
- 它的任务是:根据 Encoder 的输出 + 已生成的部分目标序列,逐步预测下一个词的概率分布
- 最终通过采样或贪心选择得到词 ID,再通过 词汇表映射 变成真实词语(这才是最后的"解码")
✅总结:
| 术语 | 实际含义 | 不是 |
|---|---|---|
| Encoder(编码器) | 神经网络,将输入序列转化为上下文感知的语义向量序列 | Python 的 encode() 或单纯词向量 |
| Decoder(解码器) | 神经网络,根据语义向量逐步生成目标序列 | Python 的 decode() |
| "编解码" | 指 Encoder-Decoder 架构,一种端到端序列建模范式 | 字符编码/解码(如 UTF-8, Base64) |
🌟 所以:
这里的"编解码"是深度学习中的模型组件名称,强调"信息压缩→信息重建"的思想,与编程语言层面的编解码无关。
2.2 工作原理
注意力机制的核心思想,是解码器在生成目标序列的每一步时,动态地从编码器的各个时间步的隐藏状态中提取当前所需的信息,而不再只依赖一个固定的上下文向量。
这一机制通常通过以下 4 个关键步骤实现:
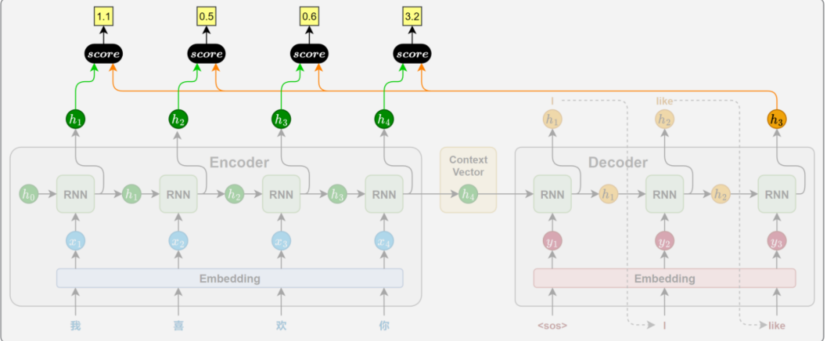
2.2.1 相关性计算
每当 Decoder 要生成一个新词时,它都会回头看看输入句子(比如中文)里的每个词,然后判断:"现在这个要生成的词,跟原文里哪个词最相关?"
比如翻译到英文单词 "apple" 时,它会发现中文里的"苹果"最重要,于是就多"看"一眼"苹果",少管"我"和"吃"。
这个"看多看少"的程度,就是注意力分配------让模型在对的时候,关注对的地方。
相关性的计算依赖于特定的函数,通常被称为注意力评分函数
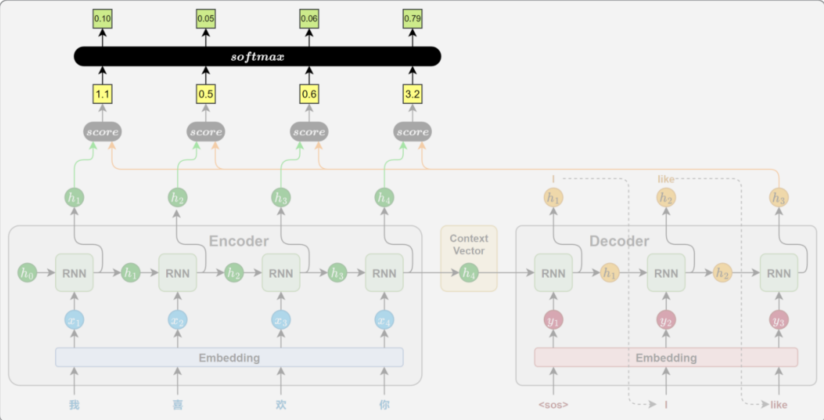
2.2.2 注意力权重计算
在拿到注意力评分后,使用SoftMax激活函数将其归一化为概率分布,并且将其作为注意力权重。
2.2.3 上下文向量计算
将所有Encoder输出按照注意力权重进行加权求和,得到上下文向量。这个向量就表示了当前时间步的模型从源头句子中提取出的关键信息
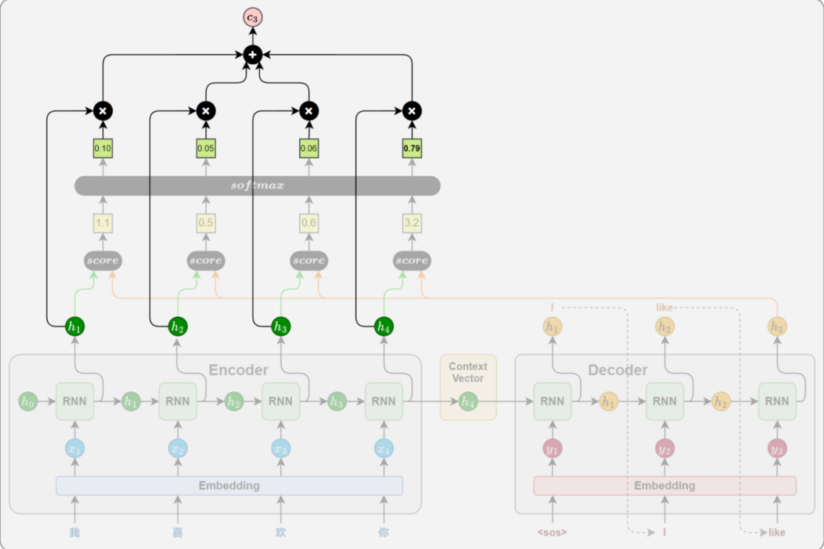
2.2.4 解码信息融合
上下文向量获取成功后,Decoder将其与当前时间步的隐藏状态 h 进行拼接,来融合两者的信息,最终通过线性变换和SoftMax生成当前时间步的目标词的概率分布

2.2 注意力评分函数
2.2.1 点积评分(Dot)
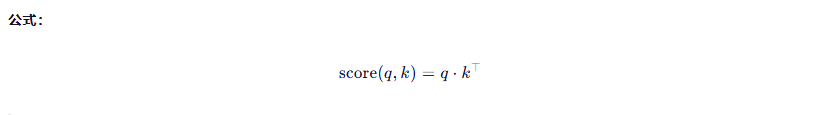
就是两个向量直接做内积。
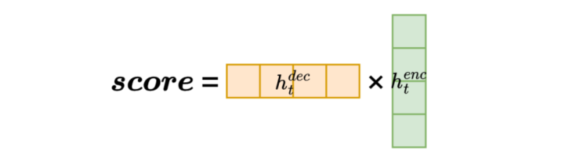
生动解释:
想象你是个美食博主,想评价一道菜是否合你口味。
你有一套"味觉偏好向量"(比如:酸=0.8,甜=0.6,辣=0.9......)
这道菜也有一个"味道向量"。
你把两者相乘加总 → 得到一个"匹配度分数"。
- 如果你喜欢甜,这道菜很甜 → 分数高 ✅
- 如果你讨厌辣,这道菜超辣 → 分数低 ❌
这就是点积评分:越相似,得分越高。
📌 总结:最朴素、最快,适合小维度;大维度要小心数值爆炸。但要求:Query 和 Key 维度必须相同
2.2.2 通用点积评分(General)
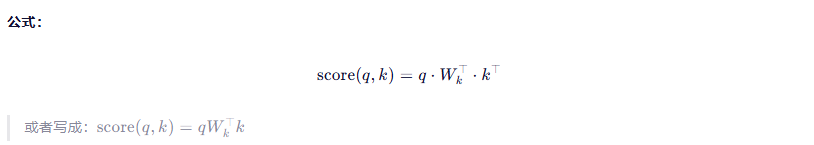
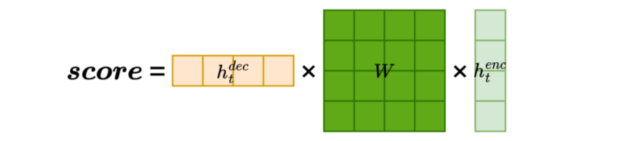
生动解释:
还是那个美食博主,这次你不仅看味道,还考虑了餐厅环境、价格、服务态度......
于是你不再直接比对味道,而是先把菜的味道通过一个"滤镜"处理一下(比如:我只关心"香不香"、"有没有油"),再跟你的偏好对比。
这里的 WkW_kWk
就是这个"滤镜矩阵",专门用来调整 Key 的表示。
特点:
更灵活,可以学习如何"看重"哪些特征
需要训练一个额外的权重矩阵 WkW_kWk
比点积多了一层变换,能捕捉更复杂的模式
📌 总结:像加了个"智能滤镜",比点积更聪明,但稍慢一点。
2.2.3 拼接评分(Concat)


生动解释 :
你现在不是光看菜的味道,而是把"我的口味"和"这道菜"的信息拼成一张完整的卡片,然后交给一位"高级评委"去打分。
比如:
- 我喜欢清淡 → 但今天这道菜很重口 → 可是我今天很饿 → 那么可能还是吃!
- 评委综合判断后给出最终分数。
这里 MLP 就是那位"评委",它可以学到非常复杂的交互规则。
特点:
- 表达能力强,能建模复杂关系
- 计算成本高(因为要拼接+MLP)
- 参数更多,容易过拟合
📌 总结:像请了个AI评审团,能力最强,代价也最大。
| 方法 | 公式 | 是否可学 | 速度 | 表达能力 |
|---|---|---|---|---|
| 点积 (Dot) | q⋅k⊤q \cdot k^\topq⋅k⊤ | 否 | 🔥🔥🔥🔥 | ✅ |
| 通用 (General) | qWk⊤kqW_k^\top kqWk⊤k | 是 | 🔥🔥🔥 | ✅✅ |
| 拼接 (Concat) | MLP(q,k)\text{MLP}(q, k)MLP(q,k) | 是 | 🔥🔥 | ✅✅✅ |
2.1 硬注意(了解)
🔍 定义:
硬注意是一种离散型的注意力机制。
它在所有候选中只选一个最相关的,其余全部忽略。
想象你在看一场演讲,突然听到一句:"这锅我背了!"
你瞬间聚焦到这句话上,其他内容全当背景噪音 ------ 这就是硬注意。
✅ 特点:
- 输出是二值选择:要么选,要么不选
- 类似于"投票制":谁得分最高,就选谁
- 不可微分 → 不能用梯度下降训练(❌)
- 通常用强化学习来优化(比如 REINFORCE)
📌 举个例子 :
假设我们有三个词:猫, 跑, 树
Query 是 跑,模型发现 猫 和 跑 最相关,于是直接跳过 树,只关注 猫。
👉 但问题来了:如果 树 其实也有关联呢?(比如"猫从树上跑下来")
→ 那么硬注意就可能错过重要信息。
📌 总结:像"单选题",效率高但容易丢信息;训练难,一般不用在主流模型里。
2.2 软注意(Soft Attention)
🔍 定义:
软注意是连续型的注意力机制。
它会给每个候选分配一个权重(概率) ,然后进行加权求和。
想象你在听一首歌,虽然主旋律最响亮,但你也隐约能听到伴奏、鼓点、和声......
你不是只听一个音符,而是整体感知,但重点落在主旋律上 ------ 这就是软注意。
✅ 特点:
- 输出是一个概率分布(权重之和 = 1)
- 可微分 → 支持反向传播(✅)
- 使用 softmax 函数归一化得分
- 是 Transformer、BERT 等模型的核心!
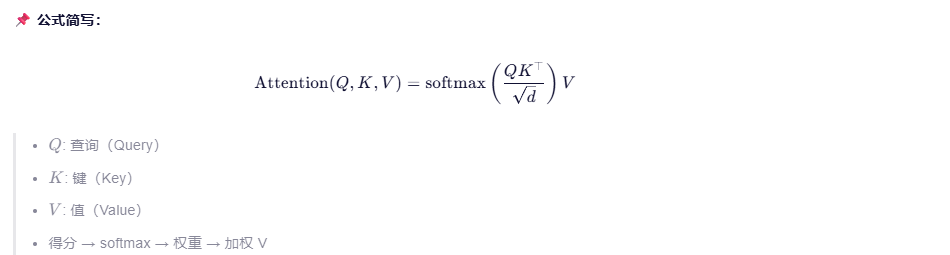
🎯 举个例子:
句子:"小猫从树上跳下来。"
你想理解"跳"的含义时:
"猫" → 0.6 分
"树" → 0.3 分
"下" → 0.1 分
最终结果是:
0.6 × vec_cat + 0.3 × vec_tree + 0.1 × vec_down
👉 所有信息都参与了,只是轻重不同。
📌 总结:像"多选题+打分",灵活、可训练、信息保留完整,是现代 NLP 的主力选手!
2.3 自注意(Self Attention)
🔍 定义:
自注意是指:序列中的每一个元素,都去关注序列中其他元素(包括自己)。
想象你读一句话:"她看到了他。"
你脑子里会自动问:"'她'指的是谁?"、"'他'是谁?"
这个过程,就是你自己在"对这句话内部进行分析" ------ 就是自注意!
✅ 核心思想:
- Query、Key、Value 都来自同一个输入序列
- 每个位置都可以"回头看"整个上下文
- 不依赖顺序,适合并行计算
📌 举个例子:
句子:我,爱,你
对"爱"这个字来说:
- 它会问:"我"和"你"哪个更相关?
- 计算出:我 → 0.8,你 → 0.9
- 然后把"我"和"你"的表示加权融合,得到"爱"的新表示
这样,"爱"就不只是"动词",而是包含了"谁爱谁"的语义!
💡 关键点:
❗️ 自注意力的本质就是软注意力的一种特殊形式!
因为它是用软注意的方式,让每个 token 关注其他 token。
| 类型 | 是否可微 | 是否使用 softmax | 是否共享参数 | 应用场景 |
|---|---|---|---|---|
| 硬注意 | ❌ | ❌ | ✅ | 强化学习、特定任务 |
| 软注意 | ✅ | ✅ | ✅ | 大多数现代模型 |
| 自注意 | ✅ | ✅ | ✅ | Transformer、BERT、GPT 等 |
2.6 QKV机制规则
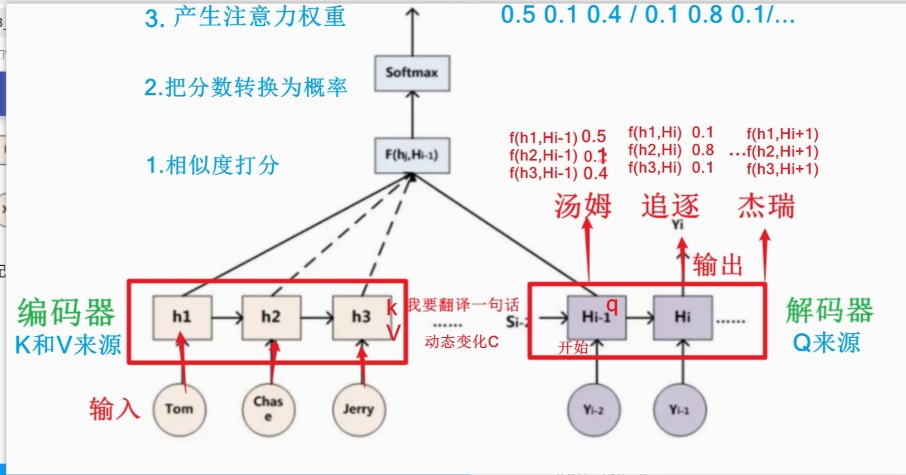
这张图里面,谁是Attention Score (Q1),谁是注意力权重 (Q2),谁是上下文向量(Q3)?
Q1:谁是Attention Score
**Attention Score(相似度打分)**是 Query 与每个 Key 的相似性得分
- 在图中:
- 函数 F(hj, Hi-1) 表示计算编码器第 j 个隐藏状态 hj 与解码器当前隐状态 Hi-1 的相似度。
- 示例值如:f(h1, Hi-1) = 0.5, f(h2, Hi-1) = 0.1, f(h3, Hi-1) = 0.4
- 这些数值就是 Attention Score(也叫 raw attention scores)
✅ 所以:
👉 Attention Score = f(h1, Hi-1), f(h2, Hi-1), f(h3, Hi-1)
👉 即图中标注的 0.5 / 0.1 / 0.4
Q2:谁是注意力权重
是将 Attention Score 经过 Softmax 归一化 后的概率分布
- 图中显示:
- Softmax 操作将原始分数 0.5, 0.1, 0.4 转换为概率分布
- 结果是:0.5, 0.1, 0.4 → 0.5, 0.1, 0.4(此处可能已归一化或示意)
- 实际上应为:softmax(0.5, 0.1, 0.4) ≈ 0.5, 0.1, 0.4(若总和为 1,则已是权重)
✅ 所以:
👉 注意力权重 = Softmax(Attention Score)
👉 图中上方标注的 0.5 0.1 0.4 / 0.1 0.8 0.1... 就是不同时间步下的注意力权重(注意:后面一组可能是下一个词的权重)
Q3:谁是上下文向量
上下文向量 是对编码器所有隐藏状态(Value)按注意力权重进行加权求和的结果

✅ 所以:
👉 上下文向量 = 加权后的 h1 + h2 + h3
👉 图中红色框内的 "动态变化 C" 就是上下文向量
💡 类比理解(通俗版)
想象你在翻译"杰瑞"这个词:
- 你问自己:"哪个英文词最相关?"(Query = 当前解码状态)
- 看看三个词:"Tom"、"Chase"、"Jerry"(Key = h1,h2,h3)
- 给它们打分:Jerry 最相关 → 得分高(Attention Score)
- 把得分变成概率:Jerry 占 50%,其他占少(注意力权重)
- 最终只重点关注 Jerry 的信息(加权平均)→ 得到上下文向量 C
- 再用 C 帮助生成中文"杰瑞
✅ 一句话总结:
- Attention Score 是原始得分,注意力权重是归一化后的概率,上下文向量是加权融合后的关键信息。
- 计算注意力值的三大步:
~1.相似度打分
~2.分通过softmax转率,率即为权重
~3.加权求和求注意力值
补充内容:
余弦相似度
张量API回顾
transpose
contiguous
reshape
view
cat
randint
stack
bmm