
项目地址:botaoye.github.io/yonosplat/
本篇基于之前ETH本校的Noposplat做了进一步增强,主要解决Feedforward 3dgs中的pose与高斯训练耦合以及训练模型尺度模糊的问题。
abstract
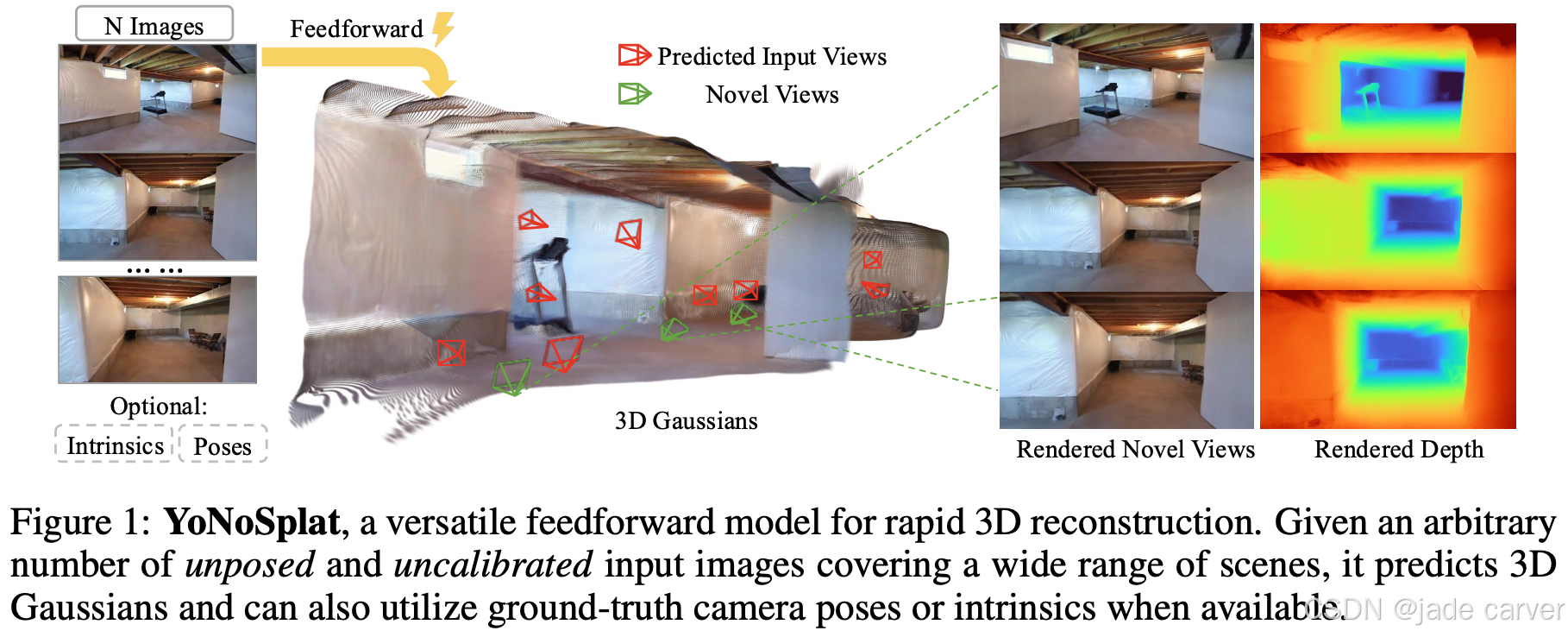
从非结构化图像集合中进行快速、灵活的3D场景重建仍是一项重大挑战。我们提出了YoNoSplat------一种前馈模型,能够从任意数量的图像中重建高质量的3D高斯泼溅表示。该模型具备高度通用性,无论是具有位姿信息还是无位姿信息、经过标定或未标定的输入,均能高效运行。YoNoSplat为每个视角预测局部高斯与相机位姿,并通过预测或提供的位姿将这些局部信息聚合为全局表示。为克服联合学习3D高斯与相机参数的内在困难,我们引入了一种新颖的混合训练策略:该方法通过初始阶段使用真实位姿聚合局部高斯,逐步过渡至混合使用预测位姿与真实位姿,从而有效缓解两项任务间的耦合问题,避免训练不稳定性和曝光偏差。此外,我们通过创新的成对相机距离归一化方案,并将相机内参嵌入网络,解决了尺度模糊性问题。YoNoSplat还能预测相机内参,使其能够处理未标定的输入。该模型展现出卓越的效率,在NVIDIA GH200 GPU上仅需2.69秒即可从100张视角图像(分辨率280×518)重建完整场景。在标准基准测试中,无论是无位姿设定还是依赖位姿的设定,YoNoSplat均实现了最先进的性能表现。
1 INTRODUCTION
前馈式高斯泼溅(Charatan 等人,2024;Zhang 等人,2025a)已成为加速三维场景重建的一个前景广阔的方向,它能够直接从输入图像预测三维高斯参数。这种方法绕过了如神经辐射场(NeRF)(Mildenhall 等人,2020)和原始三维高斯泼溅(3DGS)(Kerbl 等人,2023)等方法所需的对每个场景进行耗时的优化过程。然而,现有前馈模型的实际应用往往受到诸多限制性假设的制约,例如需要精确的相机位姿(Charatan 等人,2024;Xu 等人, 2025)、标定的相机内参(Ye 等人,2025;Zhang 等人, 2025b),或固定且有限的输入视角数量(Ye 等人,2025;Chen 等人,2024)。在实践中,场景重建需要在灵活且无约束的条件下进行:相机位姿可能无法获取或存在噪声,相机内参未知,且图像数量可能差异巨大。设计一个能在这些多样化的设置下------视角数量可变、有无位姿信息、有无标定信息------均能泛化的单一模型,仍是一个开放的挑战。
java
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelsplat: 3d gaus
sian splats from image pairs for scalable generalizable 3d reconstruction. In CVPR, 2024.
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, and Zexiang Xu.
Gs-lrm: Large reconstruction model for 3d gaussian splatting. In ECCV, 2025a.
Haofei Xu, Songyou Peng, Fangjinhua Wang, Hermann Blum, Daniel Barath, Andreas Geiger, and
Marc Pollefeys. Depthsplat: Connecting gaussian splatting and depth. In CVPR, 2025.
Botao Ye, Sifei Liu, Haofei Xu, Xueting Li, Marc Pollefeys, Ming-Hsuan Yang, and Songyou Peng.
No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images. In
ICLR, 2025.
Shangzhan Zhang, Jianyuan Wang, Yinghao Xu, Nan Xue, Christian Rupprecht, Xiaowei Zhou,
Yujun Shen, and Gordon Wetzstein. Flare: Feed-forward geometry, appearance and camera esti-
mation from uncalibrated sparse views. In CVPR, 2025b.
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-
Jen Cham, and Jianfei Cai. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view
images. arXiv preprint arXiv:2403.14627, 2024.本文中,我们提出了 YoNoSplat,一种前馈模型,能够从任意数量的、无位姿且未标定的图像中重建三维场景,同时也能在有可用信息时无缝整合真实相机数据。近期的一些无位姿方法(Ye 等人,2025;Smart 等人,2024)通过将高斯分布直接预测到统一的规范空间中,在稀疏输入(2-4个视角)上展示了令人印象深刻的结果。
1.1 前馈高斯方法的位姿与几何训练耦合
然而,这种方法难以扩展到更多数量的视角。为了确保可扩展性和多功能性,YoNoSplat 采用了一种不同的范式:它首先预测每个视角的局部高斯分布及其对应的相机位姿,然后将它们聚合到一个全局坐标系中。问题在于,这种由局部到全局的设计引入了一个显著的训练挑战:相机位姿与三维几何结构的联合学习是高度耦合的。位姿估计的误差会损害高斯分布的学习信号,反之亦然。
一种朴素的方法是使用模型自身预测的位姿来聚合高斯分布,这被称为"自我强制Self-forcing"机制(Huang 等人,2025),但这会导致训练不稳定和性能低下(图 2a)。相反,完全依赖真实位姿进行聚合的"教师强制"方法虽然解耦了任务,却引入了曝光偏差(Ranzato 等人,2015)。在这种情况下,模型从未在其自身不完美的位姿预测上进行训练,导致在推理时必须依赖这些预测时性能下降(图 2b)。为了解决这一困境,我们提出了一种新颖的"混合强制"训练策略。训练开始时采用纯"教师强制",以建立稳定的几何基础。随着训练的进行,我们逐渐将模型自身预测的位姿引入聚合步骤。这种课程式学习在稳定性和鲁棒性之间取得了平衡,使得 YoNoSplat 在测试时无论使用真实位姿还是预测位姿都能有效运行(图 2c)。

1.2尺度模糊
第二个基本挑战是尺度模糊性,这在没有真实深度信息时尤为突出。
- 很多数据集(如COLMAP处理得到的)的相机轨迹和场景模型,其绝对尺度是任意的(比如,一个房间的深度被重建为"10个单位",但这个单位是米、分米还是任意值,是未知的)。这本身就是尺度模糊的体现。
这种模糊性源于两个方面:训练数据的位姿通常只定义在任意尺度下;以及在没有一致尺度参考的情况下,联合估计内参和外参是一个不适定问题(参数量大而约束不够)。受 NoPoSplat(Ye 等人,2025)的启发(通过引入关于相机内参的先验知识 和设计一个巧妙的、基于相对几何的归一化方案,为这个问题添加了足够的约束),我们开发了一套流程,不仅使用内参信息,还能预测它,从而实现对未标定图像的重建。为了应对数据层面的模糊性,我们系统地评估了几种场景归一化策略,发现基于最大成对相机距离进行归一化最为有效,因为这与训练中使用的相对位姿监督(Wang 等人,2025c)相一致。
- 将相机内参(焦距、主点)明确地嵌入到网络的学习过程中。通过学习,网络会形成一个关于"合理焦距"的先验(例如,对于常见的手机相机,焦距大概在什么像素范围)。这个先验作为一个"锚点",可以帮助固定整个场景的尺度。
大量的实验表明,即使在没有真实相机输入的情况下,我们的模型也超越了先前依赖位姿的方法,这突显了通过我们的训练策略学习到的强大几何和外观先验。该方法能够在不同数据集和不同数量的视角上泛化,并且仅需 2.69 秒即可从 100 张图像中重建出完整的三维场景。
java
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiang-
miao Pang, Chunhua Shen, and Tong He. π3: Scalable permutation-equivariant visual geometry
learning. arXiv preprint arXiv:2507.13347, 2025c.3 METHOD
给定 V 张未提供位姿的输入图像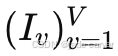 ,其中
,其中 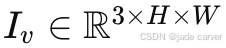 ,我们的目标是学习一个前向网络 θ,用于预测表示底层场景的 3D 高斯。
,我们的目标是学习一个前向网络 θ,用于预测表示底层场景的 3D 高斯。
通过从训练数据中学习几何与外观先验信息,我们的方法能够在无需耗时优化的情况下,直接重建新的场景。YoNoSplat 的做法是:首先在每个视角中预测局部的 3D 高斯表示,然后利用给定或预测的相机位姿 pvpv,将这些局部表示转换为全局场景表示。
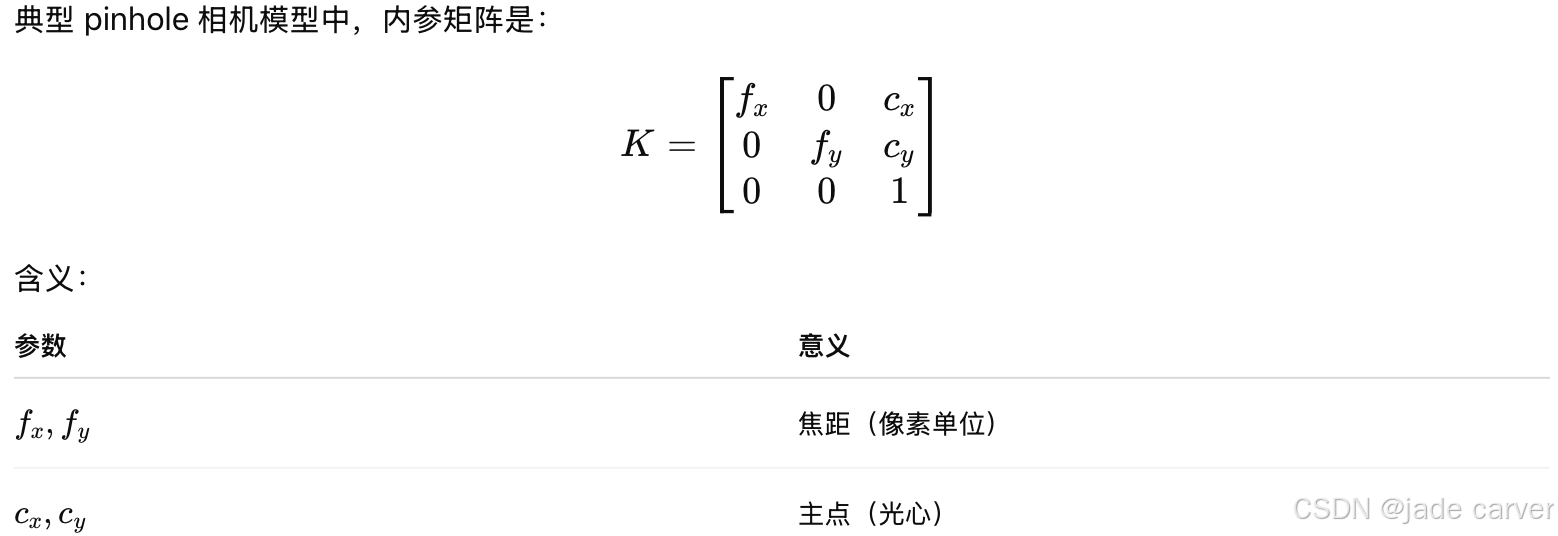
具体而言,相机位姿参数定义为:
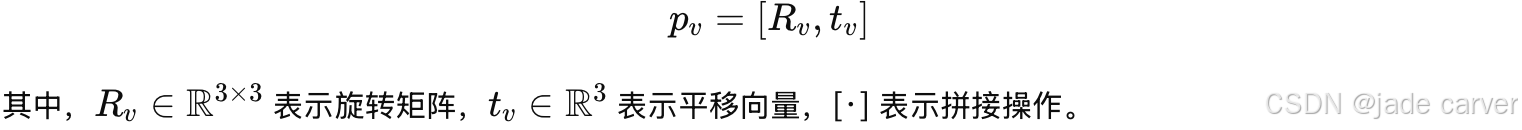
此外,如第 3.2 节所述,我们的网络还能预测相机内参 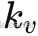 ,从而消除了对相机标定的依赖。
,从而消除了对相机标定的依赖。
因此,我们希望学习如下映射关系:

所有参数最初都是在各自的输入相机视角下预测得到的,随后可以通过预测的或给定的相机位姿转换到统一的全局坐标系中。
3.1 ANALYSIS OF THE GAUSSIAN OUTPUT SPACE AND TRAINING STRATEGY
3.1.1输出空间:局部预测 vs. 规范空间预测
对于前向重建模型而言,一个根本性的设计选择是其输出空间。现有方法主要分为两类。
无位姿(pose-free)方法 ,例如 NoPoSplat(Ye et al., 2025)和 Flare(Zhang et al., 2025b),直接在统一的规范空间 (canonical space)中预测高斯,从而自然地将来自不同视角的输出对齐到同一坐标系中。
相比之下,依赖位姿的方法 ,如 pixelSplat(Charatan et al., 2024)和 MVSplat(Chen et al., 2024),是在每个视角的局部空间中预测高斯,并依赖真实的相机位姿将其转换到全局世界坐标系中。
尽管规范空间预测在视角数量较少时效果良好,但随着视角数量的增加,其性能会明显下降(见表 7),这一现象也与相关的前向点云预测模型中的观察结果一致(Wang et al., 2025a)。我们采用了局部预测范式 。我们将模型设计为同时预测每个视角下的局部高斯 及其对应的相机位姿 。这种设计使得我们能够利用预测位姿完成聚合,从而实现无位姿重建;同时,它也完全兼容依赖位姿的工作流程,在此类场景中可以直接使用真实相机位姿。这种灵活性对于实际应用至关重要,例如在地图重建任务中,往往需要与已有且精确的位姿分布进行对齐。
3.1.2训练策略:缓解位姿耦合问题
联合预测 3D 高斯和相机参数是一项具有挑战性的任务,因为其中一方的误差会直接干扰另一方。若仅使用预测的位姿进行聚合(即 self-forcing,Huang et al., 2025),会使两项任务高度耦合,从而导致训练不稳定并降低性能(见图 2、表 5)。而如果仅使用真实位姿(即 teacher-forcing,Williams & Zipser, 1989),虽然可以提供稳定的训练信号,但会引入暴露偏差(exposure bias)(Ranzato et al., 2015),因为模型在训练过程中从未接触自身的不完美预测。
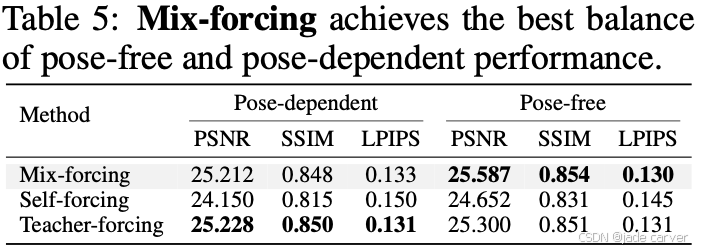
为了解决这一矛盾,我们提出了一种新的 mix-forcing 训练策略 ,结合了上述两种方法的优势。训练初期,模型仅使用真实位姿(teacher-forcing),以学习稳定的几何结构基础 ;在达到预设的训练步数 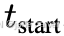 后,逐步线性增加使用模型预测位姿进行聚合的概率,并在
后,逐步线性增加使用模型预测位姿进行聚合的概率,并在 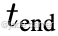 时达到最终的混合比例 r。该策略通过先建立稳健的三维结构先验,再逐渐适应模型自身预测分布与真实位姿分布,从而有效缓解了任务耦合问题,同时避免了训练不稳定和暴露偏差。
时达到最终的混合比例 r。该策略通过先建立稳健的三维结构先验,再逐渐适应模型自身预测分布与真实位姿分布,从而有效缓解了任务耦合问题,同时避免了训练不稳定和暴露偏差。
3.2 MODEL ARCHITECTURE
我们基于 Vision Transformer(ViT)(Dosovitskiy et al., 2021)作为主干网络,并采用与 VGGT(Wang et al., 2025a)相同的局部--全局注意力机制进行多视角特征融合。相比以往工作中使用的跨视角注意力机制(Ye et al., 2025),该设计在面对大量输入帧时具有更好的扩展性。
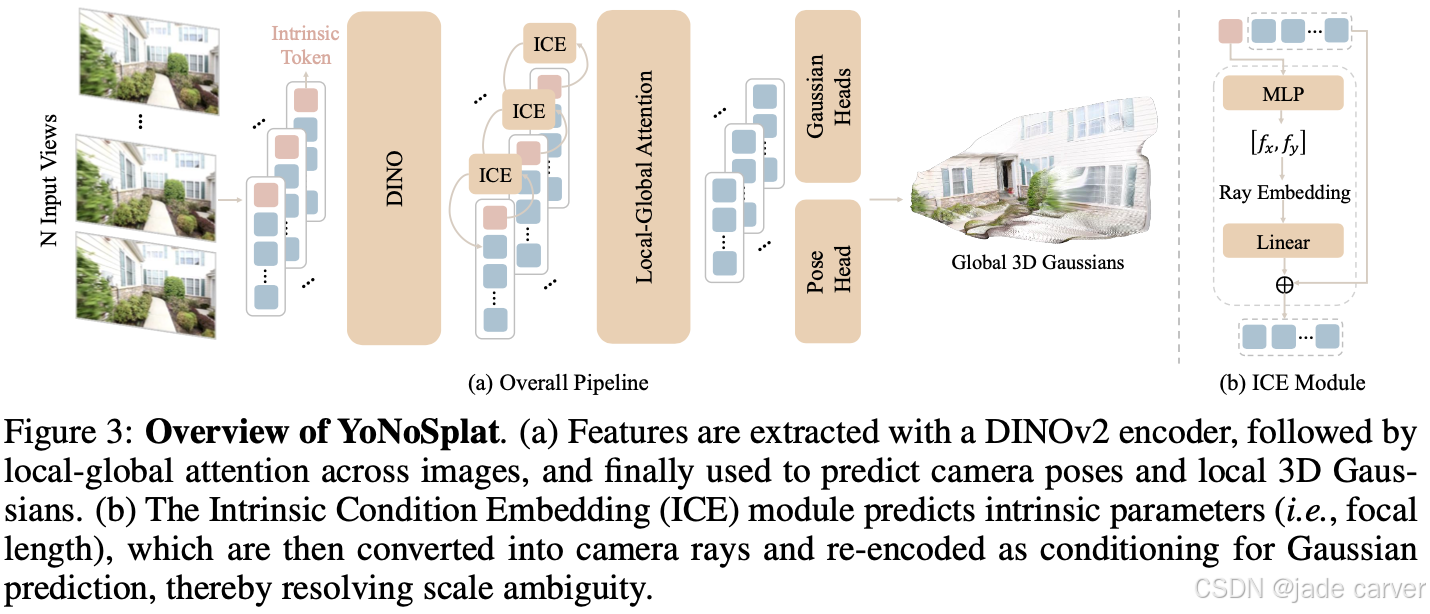
3.2.1Backbone

3.2.2Gaussian Heads
我们使用两个独立的预测头分别用于:
- 高斯中心的预测;
- 其余高斯参数的预测。
每个预测头均由 M 个自注意力层和一个最终的线性层构成。为了捕获更加精细的局部细节,在输入到预测头之前,我们将主干网络输出的特征进行 2 倍上采样,并从输入图像引入一条跳跃连接(skip connection),以缓解 ViT 下采样造成的信息损失。
3.2.3Pose Head
如第 3.1 节所述,YoNoSplat 首先预测局部高斯参数,然后利用给定或预测的相机位姿将其转换到统一的全局坐标系中。
相机位姿预测头由一个 MLP 层开始,随后进行平均池化,再接一个 MLP,用于预测一个 12 维相机向量(参照 Dong et al., 2025;Wang et al., 2025c)。该向量包含相机平移 tv 以及一个 9 维的旋转表示(Levinson et al., 2020),随后通过 SVD 正交化转换为旋转矩阵 Rv。
在训练过程中,我们遵循 π³(Wang et al., 2025c)的做法,使用成对相对位姿损失(pairwise relative transformation loss)来监督相机位姿预测(见第 3.4 节),从而保证模型对输入图像顺序保持不变性。
3.2.4Intrinsic Head
相机位姿的预测需要跨视角的信息,因此在解码器阶段完成;而相机内参可以仅根据单张图像推断。因此,我们在编码器阶段进行内参预测。
我们将一个相机内参 token与输入图像 token 拼接,并共同送入编码器,使该 token 能够聚合图像信息。随后,该 token 通过一个 MLP 层来预测相机内参。
3.3 RESOLVING SCALE AMBIGUITY
3.3.1尺度歧义
SfM 的位姿只在「相对意义」上是正确的,而不是绝对的。也就是相机之间的相对位置 / 方向 是对的,场景在现实世界的真实尺度是不确定的。
SfM 的位姿其实是:
R_i ✅ 方向是对的
t_i ❌ 只有方向和相对比例,没真实单位
它只保证:ci - cj 是正确的方向和比例关系,但不保证:|ci - cj| = 真实物理距离在纯视觉几何里,尺度歧义是指从多视图图像中,无法恢复绝对尺度
比如:
如果把整个场景放大 10 倍
同时把相机平移也放大 10 倍
所有投影结果 完全一样!从视频数据中学习预测高斯时,会遇到尺度歧义问题,其主要来源于两个方面:(1)训练数据集通常提供由 SfM 估计得到的相机位姿。而这些位姿仅在一个任意尺度值下定义;(2)同时学习相机内参和外参本身是一个病态问题。我们针对这两个因素分别进行了处理。
3.3.2Scene Normalization
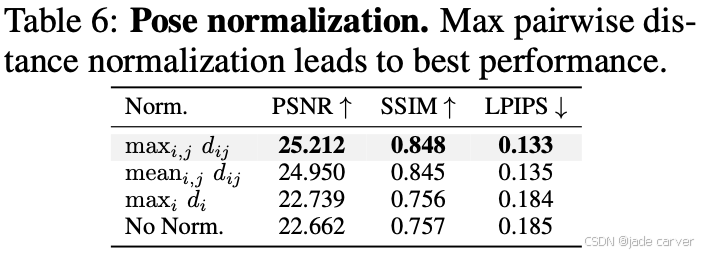
我们训练所使用的数据集中的真实相机位姿均通过 SfM 方法(Schonberger & Frahm, 2016)获得,而 SfM 的结果只在尺度上是确定的。为了避免尺度歧义对模型学习造成不利影响,有必要在训练过程中对场景进行归一化。
一些点云预测方法使用真实深度对场景进行归一化,但对于不提供深度标注的数据集而言,这是不可行的。为此,我们提出并评估了以下三种归一化策略:

如表 6 所示,最大两两距离归一化 的效果最好,并且对模型的成功至关重要。由于我们采用的是相对相机位姿,使用最大两两距离进行归一化可以在训练过程中为相机平移提供一致的尺度。
3.3.3Intrinsic Condition Embedding, ICE
如 Ye et al. (2025) 所示,相机内参信息对于解决尺度歧义至关重要。然而,先前的方法在推理阶段仍然依赖真实相机内参。为了消除这一依赖,我们提出了内参条件嵌入(ICE)模块(见图 3b)。
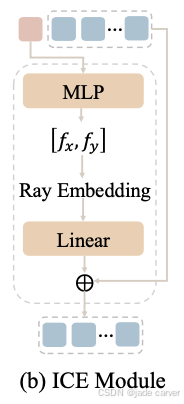
内参参数首先在编码器阶段、通过初始的内参 token 进行预测(详见第 3.2 节)。随后,为了实现内参条件化(intrinsic conditioning),我们将预测得到的内参参数转换为相机射线(camera rays)(Ye et al., 2025),再通过一个线性层映射为嵌入特征,并将其加到原始图像特征上。
当真实内参可用时,我们直接使用其进行条件化,以获得更优性能;而当真实内参不可用时,则使用预测的内参进行网络条件化。需要注意的是,在训练过程中,我们始终使用真实内参对网络进行条件约束,而不是使用预测内参。我们也曾尝试使用编码器预测的内参来条件化解码器,但该方式会导致训练不稳定,最终失败。
1.camera rays-光心到图片像素的射线

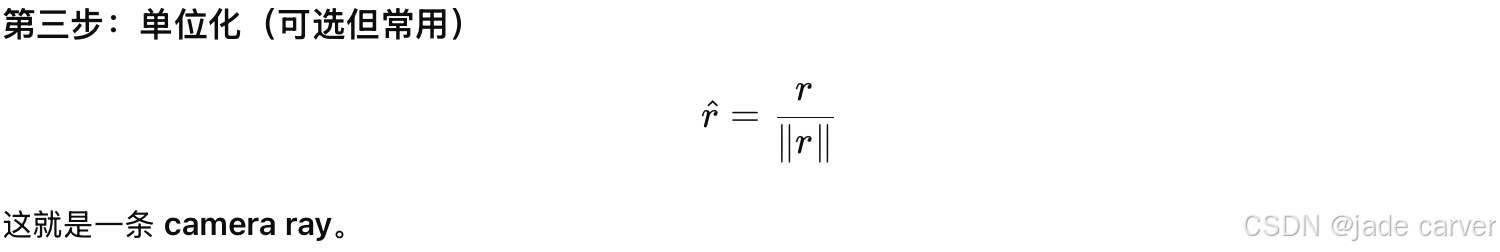
这里论文中,不是直接用 K,而是把 K → rays → embedding
2.为什么这能解决尺度歧义
相机射线 =(内参 × 成像几何),如果不知道内参:
同一个物体:
- 是远 + 大焦距?
- 还是近 + 小焦距?加了射线以后:方向明确了→ 物体大小就有物理约束
3.4 MODEL TRAINING
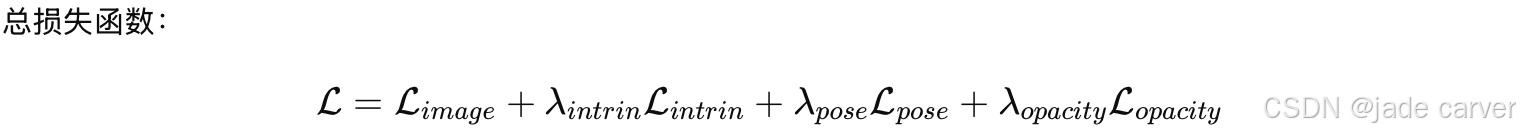
| 模块 | 学什么 | 目标任务 |
|---|---|---|
| L_image | 图像能不能渲染对 | 主任务 |
| L_intrin | 相机内参 | 解决尺度歧义 |
| L_pose | 相机位姿(相对) | 统一坐标系 |
| L_opacity | 高斯是否该存在 | 控制复杂度 |
3.4.1Rendering Loss

| Loss | 作用 |
|---|---|
| MSE | 像素级精确(颜色、亮度) |
| LPIPS | 感知相似(结构、纹理) |
3.4.2Intrinsic Loss
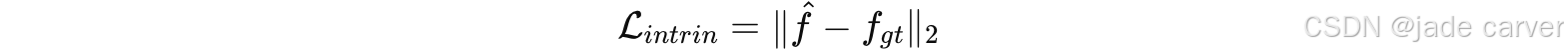
3.4.3Pose Loss
对任意两帧(i,j) ,预测它们各自的 pose:
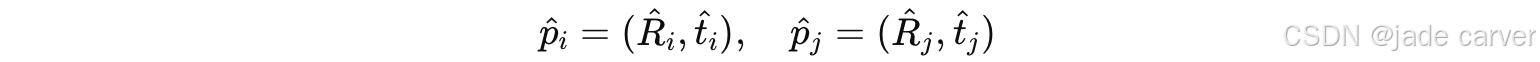
然后计算相对位姿:
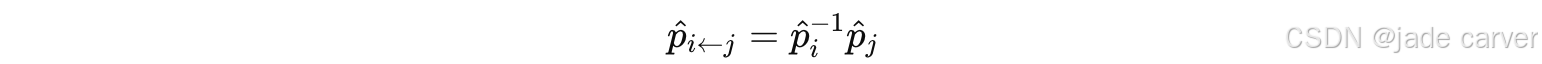
前面我们提到,绝对位姿是指在现实世界中的具体数值位姿,但是这里需要注意,这个预测的pose是规范坐标系下的绝对位姿!然后计算在规范坐标系下的相对位姿。

其中:
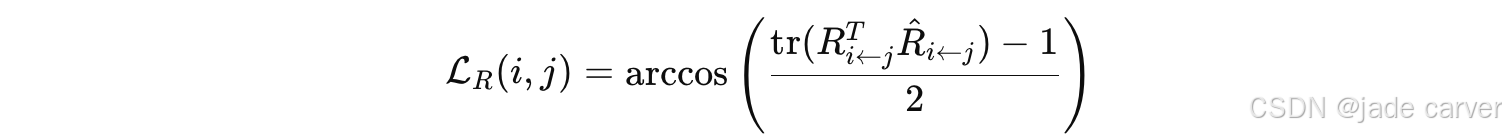
是两个旋转矩阵之间的角度误差,等价于 SO(3) 上的 geodesic distance。
平移损失:
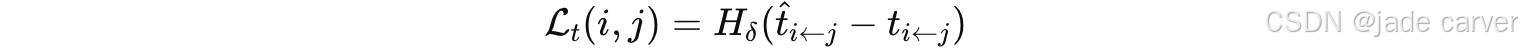
3.4.4Opacity Loss
每个像素一个 Gaussian,如果图多了会导致Gaussian 数量爆炸

类似 L1 稀疏正则,先随着图片增长,但是鼓励 opacity 变小,训练后删除opacity<0.005 的高斯,渲染更快、稳定。
3.5 EVALUATION
在 pose-dependent 评估中,直接使用数据集中提供的 真实相机位姿(SfM pose) 来渲染图像,从而只评估高斯重建质量;而在 pose-free 设定下,由于模型预测的高斯位于一个与 SfM 不一致的坐标系中,不能直接使用真实位姿,否则会产生错位,因此需要先预测目标视角的相机位姿,再用该预测位姿进行渲染评估。为保证公平性,这种做法已被多项工作采用。进一步地,作者还提供了一个可选的后优化步骤,在固定部分高斯参数的情况下,对相机位姿和高斯中心/颜色进行轻量级优化,从而在合理的时间成本下进一步提升重建质量。
4 EXPERIMENTS
4.1 EXPERIMENTAL SETUP
| 类别 | 内容 |
|---|---|
| 训练数据集 | RE10K : 67,477 train / 7,289 test, 室内视频 DL3DV: 10,000室外视频, 140 test |
| 测试设置 | RE10K : 保留 ≥200 帧的序列(1,580 sequences),6 个输入视角 DL3DV : 输入 6 / 12 / 24 视角,最大帧间隔 50 / 100 / 150 泛化测试: ScanNet++,输入 32 / 64 / 128 视角,固定目标视角,随机保留 8 视角用于验证 |
| 视角采样策略 | 基于相机中心的最远点采样(FPS) |
| 网络架构 | Encoder : DINOv2-Large, 24 层注意力 Decoder: 18 层交替注意力 Gaussian center head & camera pose head 参数初始化自 π³,其余随机初始化 |
| 训练策略 | 输入视角随机选 2--32,目标视角随机采 4 个 分辨率: 224×224 & 280×518 224×224:16 GH200 GPU, batch 2, 150k steps 280×518:32 GH200 GPU, batch 1, 150k steps, 初始化自 224×224 预训练权重 |
| 评估指标 | Novel view synthesis : PSNR / SSIM / LPIPS Pose estimation: 相对角度误差 AUC @5°/10°/20° |
| 对比方法 | Optimization-based : InstantSplat Pose-dependent : MVSplat, DepthSplat Pose-free : NoPoSplat, AnySplat Relative pose estimation: MASt3R, VGGT, π³ |
4.2 EXPERIMENTAL RESULTS AND ANALYSIS
| 实验类别 | 数据集 / 设置 | 对比方法 | 主要结论 |
|---|---|---|---|
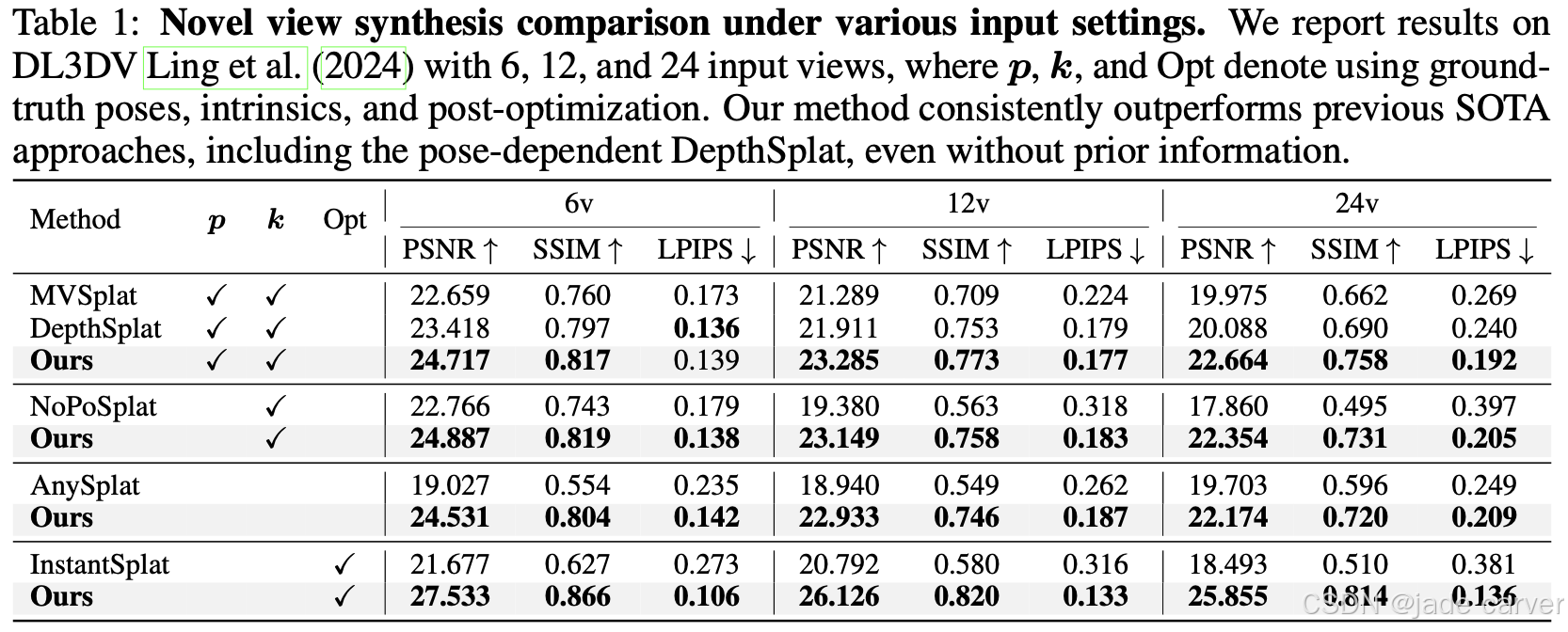
| Novel View Synthesis | DL3DV,输入视角 6 / 12 / 24,pose-dependent / pose-free / intrinsic-free | NoPoSplat, AnySplat, DepthSplat | - YoNoSplat 一直超越 SOTA 方法- 即使在最难的 pose-free / intrinsic-free 设置,也超过 DepthSplat- 随输入视角和场景规模增加,使用 GT pose 可进一步提升- 快速可选后优化 (post-opt) 可进一步提升性能- 定性结果显示更好的跨视角一致性,避免伪影与几何错误 |
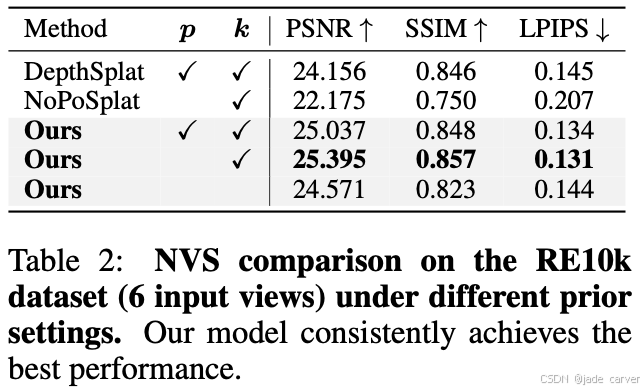
| Novel View Synthesis | RealEstate10K,输入视角 6 | Pose-free / Pose-dependent baselines | - 继续优于所有 SOTA 方法- 定性效果更好,重建细节清晰且跨视角一致 |
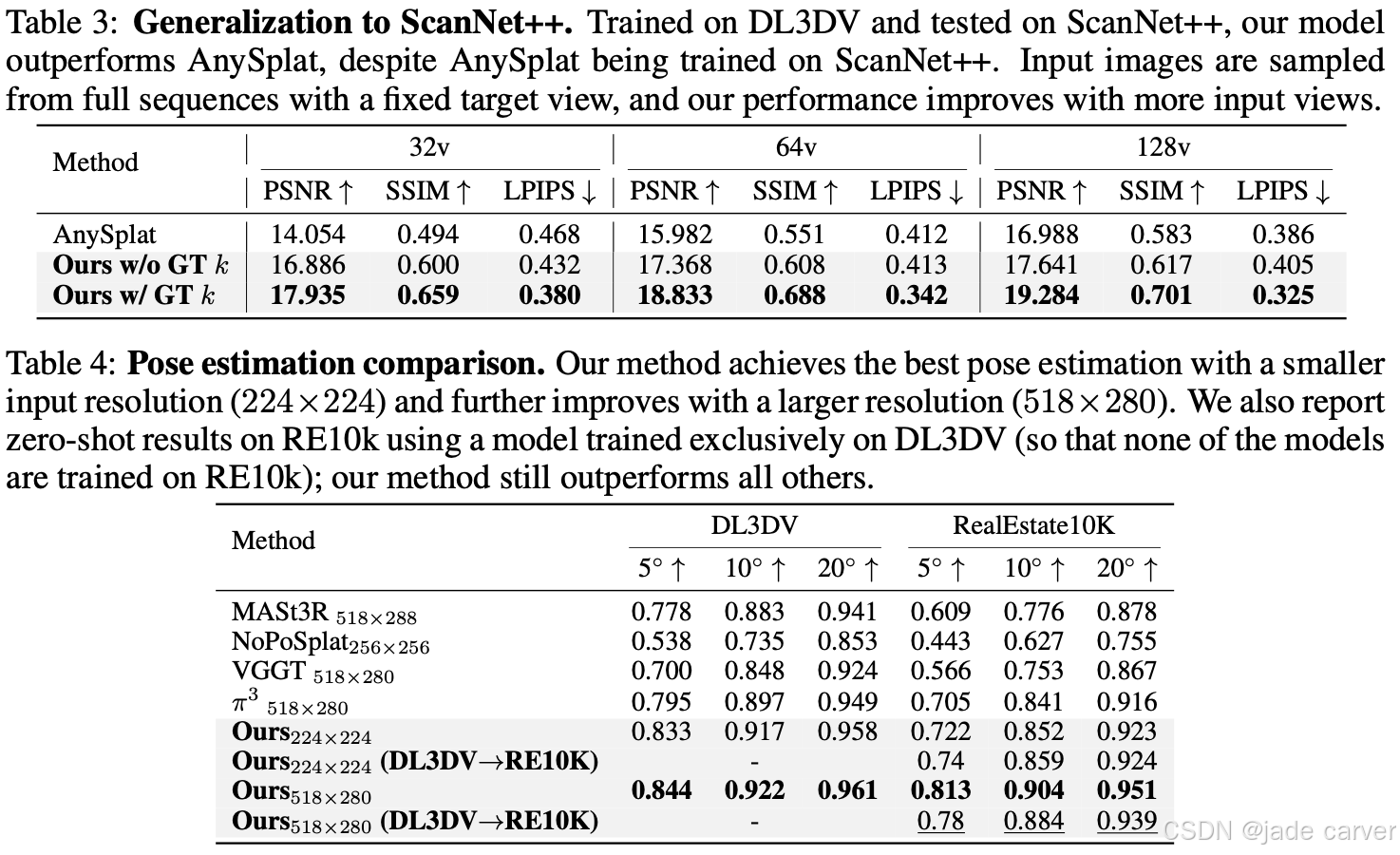
| Cross-Dataset Generalization | 模型训练: DL3DV → 测试: ScanNet++ | AnySplat (训练在 ScanNet++) | - YoNoSplat 显著优于 AnySplat,即使对方有训练域优势- 输入视角增加时性能持续提升- 定性效果更清晰、更连贯,信息融合更好- AnySplat 渲染较模糊且伪影明显 |
| Camera Pose Estimation | DL3DV,小分辨率 224×224 / 大分辨率 518×280 | MASt3R, VGGT, π³ 等 SOTA 方法 | - 小分辨率下已优于 SOTA- 大分辨率下进一步提升性能- DL3DV → RE10K 测试也优于所有基线,说明模型泛化能力强- 渲染损失训练也能提升位姿估计精度 |



5 CONCLUSION
YoNoSplat 该模型独特地支持在 无位姿/有位姿 以及 已校准/未校准 的设置下工作。我们针对两个关键挑战提出了解决方案:几何与位姿学习的纠缠问题,以及尺度歧义问题。为解决前者,我们提出了创新的 mix-forcing 训练策略 ,在保证训练稳定性的同时有效减轻了曝光偏差;为解决后者,我们结合了稳健的 最大成对距离归一化 与 Intrinsic Condition Embedding (ICE) 模块,使得模型能够在未校准输入下进行重建。这些贡献显著提升了前馈式 3D 重建的灵活性和鲁棒性。