Seq2Seq
Seq2Seq(Sequence-to-Sequence)模型是一种用于将一个序列转换为另一个序列的深度学习架构。在自然语言生成的任务中,大部分是基于seq2seq模型实现的(除此之外,还有语言模型,GAN等也能做文本生成),广泛应用于机器翻译、文本摘要、对话系统等自然语言处理任务。seq2seq模型是由encoder,decoder两部分组成的,其标准结构如下:

原则上encoder,decoder可以由CNN,RNN,Transformer三种结构中的任意一种组合。但实际的应用过程中,encoder,decnoder的结构选择基本是一样的(即encoder选择CNN,decoder也选择CNN,如facebook的conv2conv)。
Seq2Seq的原理
参考链接:https://www.cnblogs.com/liuxiaochong/p/14399416.html
Seq2Seq模型的核心思想是处理长度可变的输入序列并生成长度可变的输出序列。Encoder 中将一个可变长度的信号序列变为固定长度的向量表达,Decoder 将这个固定长度的向量变成可变长度的目标的信号序列。编码器使用循环神经网络将输入序列转换为固定长度的上下文向量,而解码器则利用这个向量和另一个循环神经网络逐步生成输出序列。
编码器(Encoder):通常采用循环神经网络(RNN)如LSTM或GRU,逐步处理输入序列,最终生成代表整个序列信息的上下文向量。
解码器(Decoder):接收上下文向量,通过自回归方式逐词生成输出序列。每个时间步的预测依赖于前一步的输出和上下文信息。
上下文向量
- 输入的数据(文本序列)中的每个元素(词)通常会被编码成一个稠密的向量,这个过程叫做word embedding
- 经过循环神经网络(RNN),将最后一层的隐层输出作为上下文向量
- encoder和decoder都会借助于循环神经网络(RNN)这类特殊的神经网络完成,循环神经网络会接受每个位置(时间点)上的输入,同时经过处理进行信息融合,并可能会在某些位置(时间点)上输出。
关键技术与改进
参考链接:https://cloud.tencent.com/developer/article/2398361
注意力机制(Attention)
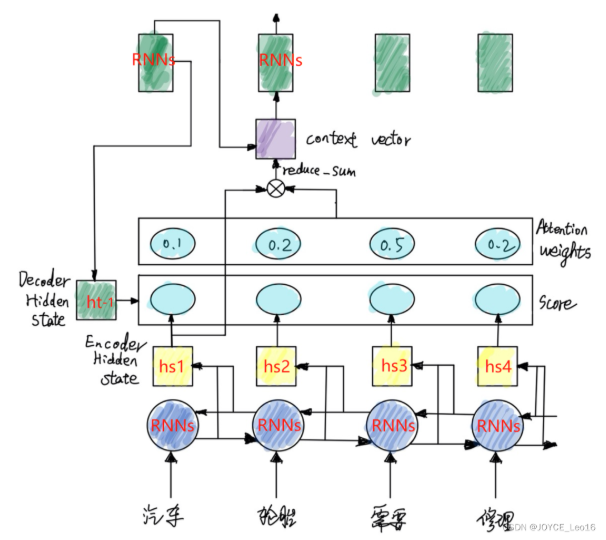
提升效果,不会寄希望于把所有的内容都放到一个上下文向量(context vector)中,而是会采用一个叫做注意力模型的模型来动态处理和解码,最初引入注意力机制是为了解决机器翻译中遇到的长句子(超过50字)性能下降问题。解决固定长度上下文向量的信息瓶颈,通过动态计算输入序列各部分的权重,使解码器能聚焦于相关部分,显著提升长序列处理能力。可以粗略地理解为是一种对于输入的信息,根据重要程度进行不同权重的加权处理(通常加权的权重来源于softmax后的结果)的机制,如下图所示,是一个在解码阶段,简单地对编码器中的hidden states进行不同权重的加权处理的过程。

核心逻辑:从关注全部到关注重点
- Attention机制处理长文本时,能从中抓住重点,不丢失重要信息。
- Attention机制像人类看图片的逻辑,当我们看一张图片的时候,我们并没有看清图片的全部内容,而是将注意力集中在了图片的焦点上。
- 我们的视觉系统就是一种Attention机制,将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。
通过计算Decoder的隐藏状态与Encoder输出的每个词的隐藏状态的相似度(Score),进而得到每个词的Attention Weight,再将这些Weight与Encoder的隐藏状态加权求和,生成一个Context Vector。
Transformer架构
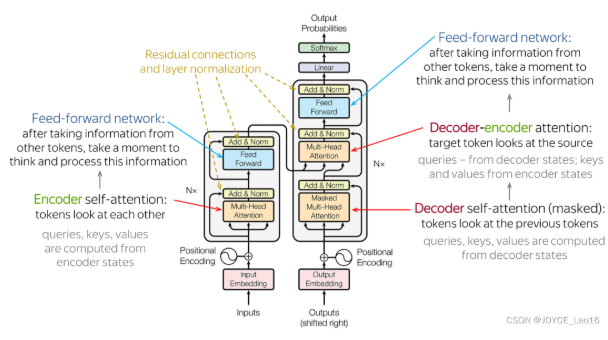
Transformer:通常Attention会与传统的模型配合起来使用,但Google的一篇论文《Attention Is All You Need》中提出只需要注意力就可以完成传统模型所能完成的任务,从而摆脱传统模型对于长程依赖无能为力的问题并使得模型可以并行化,并基于此提出Transformer模型。完全基于自注意力机制(Self-Attention),摆脱RNN的时序依赖,实现并行计算,在翻译等任务中达到SOTA水平。
该模型通过编码器-解码器框架和持续创新(如注意力机制),已成为序列转换任务的核心工具。
主要由输入部分(输入输出嵌入与位置编码)、多层编码器、多层解码器以及输出部分(输出线性层与Softmax)四大部分组成。
输入部分:
- 源文本嵌入层:将源文本中的词汇数字表示转换为向量表示,捕捉词汇间的关系。
- 位置编码器:为输入序列的每个位置生成位置向量,以便模型能够理解序列中的位置信息。
- 目标文本嵌入层(在解码器中使用):将目标文本中的词汇数字表示转换为向量表示。
编码器部分:
- 由N个编码器堆叠而成。
- 每个编码器层由两个子层连接结构组成:第一个子层是一个多头注意力子层,第二个子层是一个前馈全连接子层。每个子层后都接有一个规范化层和一个残差连接。
解码器部分:
- 由N个解码器层堆叠而成。
- 每个解码器层由三个子层连接结构组成:第一个子层是一个带掩码的多头自注意力子层,第二个子层是一个多头注意力子层(编码器到解码器),第三个子层是一个前馈全连接子层。每个子层后都接有一个规范化层和一个残差连接。
输出部分:
- 线性层:将解码器输出的向量转换为最终的输出维度。
- Softmax层:将线性层的输出转换为概率分布,以便进行最终的预测。
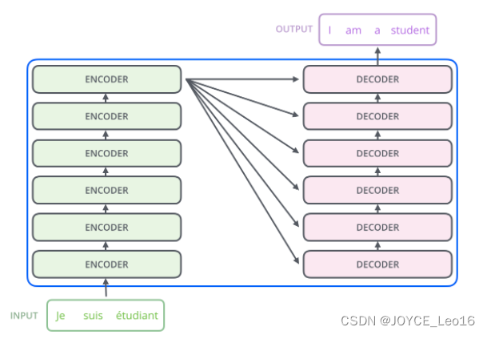
Transformer工作原理
边是N个编码器,右边是N个解码器,图中Transformer的N为6。
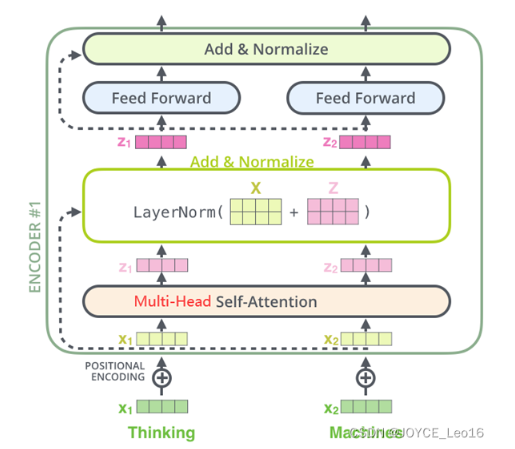
Encoder(编码器)
- 图中的Transformer的编码器部分一共6个相同的编码器层组成。
- 每个编码器层都有两个子层,即多头自注意力机层(Multi-Head Attention)层和逐位置的前馈神经网络(Position-wise Feed-Forward Network)。
- 在每个子层后面都有残差连接(图中的虚线)和层归一化(LayerNorm)操作,二者合起来称为Add&Norm操作。
Decoder(解码器) - 图中Transformer的解码器部分同样一共6个相同的解码器层组成。
- 每个解码器层都有三个子层,掩蔽自注意力层(Masked Self-Attention)、Encoder-Decoder注意力层、逐位置的前馈神经网络。
- 同样,在每个子层后面都有残差连接(图中的虚线)和层归一化(LayerNorm)操作,二者合起来称为Add&Norm操作。

Seq2Seq与Transformer关系
Seq2Seq(序列到序列)和Transformer是序列转换任务中的两种重要模型架构,它们在神经网络发展史中体现了从循环结构到纯注意力机制的演进。
Seq2Seq模型是序列转换的基础架构, 它通常基于循环神经网络(RNN),采用编码器-解码器框架:编码器逐步读取输入序列并压缩为固定维度的上下文向量,解码器则基于该向量逐个生成输出序列元素,这种设计通过端到端训练简化了传统特征工程,但存在长距离依赖建模困难和训练难以并行化的问题。
Transformer模型在Seq2Seq基础上进行了根本性改进, 它完全摒弃了循环结构,转而依赖自注意力机制实现序列处理,核心变化包括:
- 并行化处理:通过自注意力机制直接计算序列中任意位置间的依赖关系,无需顺序计算,显著提升训练效率。
- 长距离依赖建模:自注意力能捕捉全局上下文,缓解了RNN中的梯度消失问题。
- 架构增强:引入多头注意力、位置编码和残差连接,使模型更易扩展到多任务场景。
两者关系可概括为演进与替代, Transformer最初可视为Seq2Seq的增强版本,但后续发展使其成为更通用的架构,不仅替代Seq2Seq在多数任务中的主导地位,还扩展至计算机视觉等领域,体现了从循环依赖到纯注意力机制的范式转变。
teacher forcing
Teacher Forcing 是一种在训练序列生成模型(如RNN、Transformer)时常用的技术,其核心思想是在训练过程中,模型的输入不是来自上一步的预测输出,而是使用真实的历史数据(即教师信号或目标序列)。这种做法有助于模型在训练阶段更稳定地学习序列模式,减少训练时的误差累积。
在 Transformer 中,Teacher Forcing 的具体应用如下:
- 训练阶段:在训练过程中,模型的输入 x_t 是真实的历史数据(即教师信号),而不是模型自身预测的输出。这样可以确保模型在训练初期更准确地学习序列模式。
- 推理阶段:在推理阶段,模型会根据自身预测的输出继续生成后续的序列。这种做法虽然可能导致误差累积,但通过训练时的 Teacher Forcing 可以减少这种影响。
在Transformer中,Teacher Forcing 通过因果注意力掩码实现,确保每个位置仅关注其过去信息,维持序列生成的时序约束。
Teacher Forcing 的主要优点是提高训练稳定性和加速收敛,因为模型始终接收正确上下文,尤其适用于机器翻译、文本生成等任务;但缺点是引入训练-推理不一致(暴露偏差),即训练时依赖真实数据,而推理时完全依赖自身预测,可能导致模型对自身错误缺乏鲁棒性。
为缓解这一问题,改进方法如Scheduled Sampling 被提出,在训练中逐步降低使用真实输出的比例,让模型渐进式适应自回归生成环境。
Greedy search与Beam search
贪心搜索(Greedy Search)和束搜索(Beam Search)是序列生成模型中的两种核心解码策略,主要用于自然语言处理任务如机器翻译或语音识别。
贪心搜索在每一步生成中选择概率最高的词元,其算法简单高效,时间复杂度低,但容易陷入局部最优,因为每一步仅基于当前状态选择最优词元,忽略了后续词元的全局影响,导致生成序列的整体概率可能并非最大。
束搜索通过维护一组最可能的序列候选来改进贪心搜索,其关键超参数束宽(beam size)控制每一步保留的序列数量;例如,在每一步基于当前最佳序列扩展并保留概率最高的beam size个新序列,从而在局部搜索中逼近全局最优。
束搜索的计算开销高于贪心搜索,但通常能生成更高质量的序列,且可通过长度归一化等技术缓解对短序列的偏好问题。
束搜索可视为贪心搜索的泛化形式,当束宽为1时退化为贪心搜索;在实际应用中,束搜索在精度和计算成本之间提供可调的权衡,而贪心搜索因高效性仍适用于实时性要求高的场景。
Seq2Seq采样方法Sampling Methods
Seq2Seq模型中的采样方法主要涉及解码阶段,用于从概率分布中生成目标序列,核心目标是在生成质量(如连贯性)和多样性之间取得平衡。
贪婪搜索(Greedy Search)是一种确定性方法,在每个时间步选择概率最高的词元作为输出,其优点是计算高效且生成速度快,但容易陷入局部最优,导致重复或缺乏多样性的输出,尤其在处理罕见词或复杂上下文时表现不佳。
束搜索(Beam Search)是一种启发式搜索算法,维护多个候选序列(束宽b),在每个时间步扩展并保留最有可能的b个序列,最终选择整体概率最高的序列。它比贪婪搜索更优,能探索多个路径,但计算开销较大,且可能生成过于保守或重复的输出。
Top-k采样通过限制候选词范围来提升多样性,具体做法是:在每个时间步,从概率分布中选取前k个最高概率的词元,并重新归一化其概率,然后从这个子集中进行采样。这种方法能避免低概率词元的干扰,减少奇怪词汇的生成,但若k值过小可能导致输出连贯性下降,而k值过大则无法有效提升多样性。
核采样(Nucleus Sampling,或Top-p采样)是另一种动态截断策略,它不固定词元数量,而是累积概率分布直至达到阈值p(例如p=0.9),仅从这些词元中采样。该方法能自适应调整候选集大小,更适合处理长尾分布,在保持输出质量的同时增强多样性。
这些采样方法可根据任务需求调整超参数(如k、p或束宽),以权衡生成效率与质量。在实际应用中,Top-k或核采样常用于开放域生成,而束搜索更适合对确定性要求较高的场景。
评价方法BLEU、ROUGE、METEOR
在序列到序列(Seq2Seq)模型的评估中,BLEU、ROUGE和METEOR是三种广泛使用的基于重叠的指标,它们通过计算生成文本与参考文本之间的词汇或序列匹配程度来评估质量,但侧重点和计算方式各有不同。
BLEU(Bilingual Evaluation Understudy) 主要用于机器翻译任务,核心思想是计算生成文本与参考文本之间N-gram(连续词序列)的精确率。它通过几何平均数结合不同阶数的N-gram精确率(如BLEU-1到BLEU-4),并引入简洁性惩罚(brevity penalty)来惩罚过短的生成文本。例如,BLEU-1关注单个词的匹配,而BLEU-4要求更长的连续词组匹配,分数随N增加而下降。
ROUGE(Recall-Oriented Understudy for Gisting Evaluation) 系列指标侧重于召回率,衡量生成文本覆盖参考文本信息的程度,常用于摘要任务。其主要变体包括:
- ROUGE-N:计算参考文本和生成文本共有的N-gram数量与参考文本N-gram总数的比值。
- ROUGE-L:基于最长公共子序列(LCS),不强制词的连续性,只保持相对顺序,更适合捕捉整体结构相似性。
- ROUGE-W:对ROUGE-L的改进,通过加权LCS增强对连续匹配的重视。
ROUGE-S:使用skip-bigram(允许间隔的词对)统计共现,以捕捉非连续但有序的词汇关系。
METEOR 是对BLEU的改进,旨在解决精确匹配的局限性。它同时考虑精确率和召回率,并引入词干匹配、同义词和释义匹配等语义相似性,例如将"running"和"run"视为相关。METEOR还通过chunk概念评估生成文本的流畅性,即对齐的连续词块。然而,其计算复杂度较高,需要外部资源(如同义词词典),且超参数较多,应用范围相对有限。
这些指标各有优缺点:BLEU计算高效但对词序敏感且忽略召回率;ROUGE系列更注重召回率,适合摘要等任务,但可能忽略语义;METEOR更智能地处理语义相似性,但实现复杂且依赖外部数据。在实际应用中,常结合多个指标进行综合评估。