在 Qwen3 的训练 / 微调过程中,loss 变为 NaN(Not a Number,非数字) 是数值计算完全失效的核心标志,意味着模型在损失函数计算、梯度传播环节出现了无法被计算机解析的无效数值运算------ 这不是 "模型学不好(loss 高)",而是 "训练流程本身崩溃",继续训练会导致参数更新完全失效(参数也会变成 NaN),必须立即停止并排查问题。
一、先明确:loss NaN 的字面与本质含义

二、Qwen3 中 loss NaN 的核心触发逻辑(结合模型特性)
Qwen3 是大参数量 Transformer 模型(7B/14B/72B),基于自回归架构和混合精度训练,loss NaN 的触发有明确的模型相关逻辑:
1.梯度爆炸→Inf→NaN
Qwen3 预训练参数已接近最优解,微调时若学习率过高 / 未开梯度裁剪,参数更新幅度过大,梯度值会飙升到超出浮点数范围(变成 Inf,无穷大);而 Inf 参与后续运算(如 Inf - Inf、Inf/Inf)会直接生成 NaN,这是 Qwen3 微调中最常见的原因。
2.输入 / 标签异常→非法运算→NaN
Qwen3 的 Tokenizer 对脏数据(乱码、特殊字符、格式错误)敏感,若输入文本编码出无效 token,或标签中混入非 - 100 / 非负整数的无效值,会导致 CrossEntropyLoss 计算时出现 "0 除""对数输入负数" 等非法操作,直接输出 NaN。
3.混合精度训练的数值溢出
Qwen3 常用 FP16/BF16 混合精度训练:
- FP16 数值范围窄(±65504),Qwen3 的 LayerNorm 层、注意力分数计算容易出现 "上溢"(值超过 65504)或 "下溢"(值太小接近 0),导致运算结果 NaN;
- 若硬件不支持 BF16 却强行使用,也会触发数值异常。
4.模型 / Tokenizer 配置错误
比如强行将pad_token_id设为 - 100(不在词汇表中)、模型权重加载不全(部分权重是 NaN)、思考模式标记与 padding 标记冲突,都会导致前向计算时输入维度 / 数值异常,进而 loss NaN。
三、loss NaN vs 其他异常值(别混淆)
新手容易把 NaN 和 Inf、高 loss 混淆,三者完全不同:
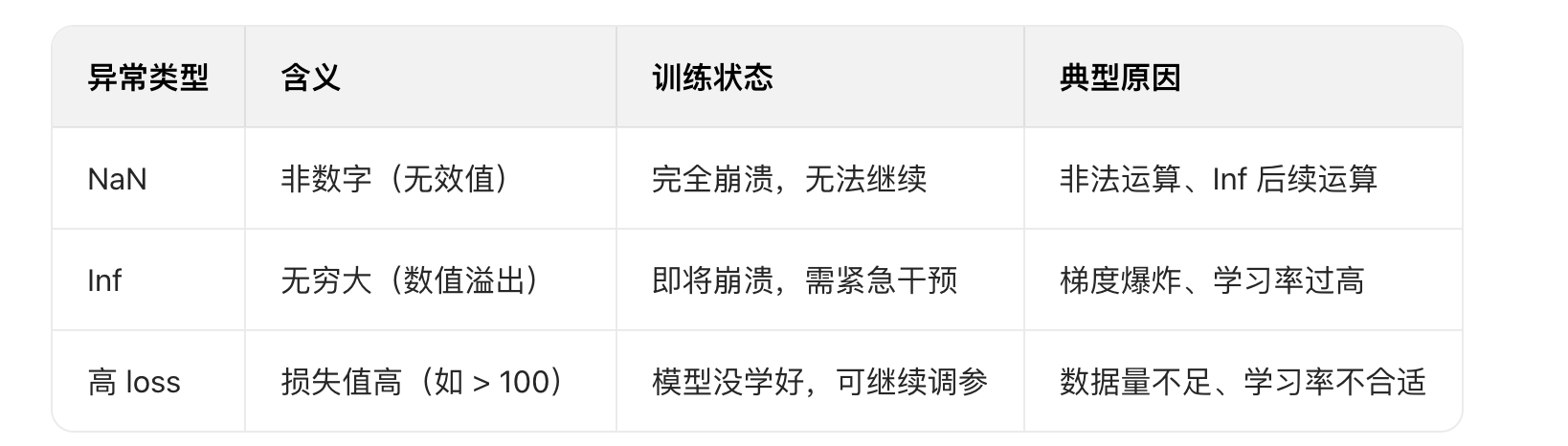
四、Qwen3 中 loss NaN 的典型表现(快速识别)
- 训练初期(前 100 步)突然出现 NaN:大概率是学习率过高、未开梯度裁剪,或数据 / 标签格式错误;
- 训练中偶尔出现 NaN:大概率是混合精度训练的数值溢出,或批次中混入个别脏数据;
- 小批量(batch_size=1)也出现 NaN:排除显存问题,大概率是数据 / Tokenizer 配置错误;
- FP16 训练 NaN,FP32 训练正常:纯混合精度的数值溢出问题。
五、核心结论
Qwen3 的 loss NaN 是训练数值稳定性彻底崩溃的信号,代表:
- 不是 "模型学不会业务知识",而是 "训练的基础计算流程出了致命错误";
- 根源几乎都能追溯到:数据 / 标签脏、学习率 / 梯度裁剪配置错误、混合精度训练适配问题、Tokenizer / 模型加载异常;
- 解决后需重启训练(无法从 NaN 状态恢复),且建议先用小批量(batch_size=1)、低学习率(1e-7)、FP32 精度验证,确认 loss 稳定后再恢复正常配置。
如果需要快速定位你的 Qwen3 微调中 loss NaN 的具体原因,可以补充:
- 出现 NaN 的训练步数(初期 / 中期);
- 是否使用混合精度(FP16/BF16);
- 学习率、梯度裁剪、batch size 等核心参数;
- 数据 / 标签的预处理逻辑(如 padding、label 设置)。