现有系统在比较相似图像时表现良好,但当视图差异显著------例如需要将街景照片与抽象的建筑平面图关联起来时,它们就会严重失效。
近期,一种能准确建立照片与平面图对应关系的新方法C3Po,构建了首个大规模交叉视角、交叉模态对应数据集C3。
最近3D计算机视觉领域取得了巨大进步,这让人想起几年前大型语言模型在语言识别方面取得的突破,我们现在拥有大型机器学习模型,它们可以接收2D图像------例如,几张建筑物的图像------并生成该建筑物的3D重建模型。但问题在于,这些模型只接受过照片的训练。当输入平面图这类抽象图像时,它们的表现就会急剧下降,因为它们从未见过这类数据。
问题背景:当照片遇上平面图
在日常生活中,我们经常需要将眼前所见与地图或平面图对应起来。比如在博物馆中根据平面图找到特定展厅,或在陌生建筑中定位自己的位置。这一过程对人类来说已具挑战,对AI而言更是难上加码。
难点在于: 照片是地面视角,充满纹理和细节;平面图是鸟瞰视角,抽象简洁,缺乏视觉特征。 这两种输入不仅在视角上截然不同,在模态上也存在根本差异。
此前的研究多集中于单一视角或单一模态的对应问题。例如,DUSt3R模型能处理"近乎相反"视角的照片对应,DINO等自监督特征表示能处理跨模态对应,但从未有模型被测试过同时处理视角和模态双重差异的极端情况。
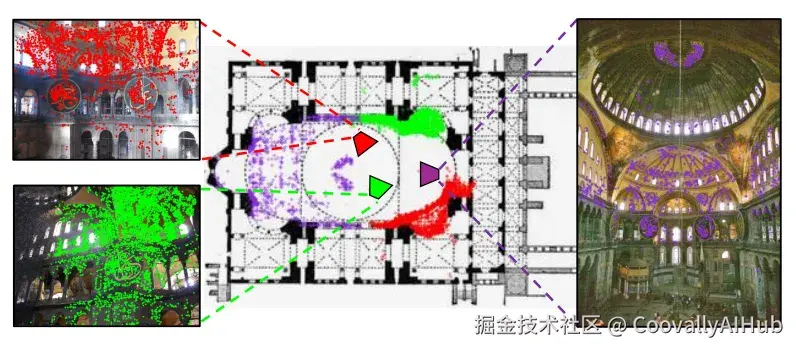
C3数据集:填补领域空白的关键资源
研究团队首先面临的挑战是缺乏训练和测试数据。"这个问题的一个重要因素是数据有限,"斯纳维利指出,"因此,我们希望创建一个将平面图与普通照片关联起来的数据集,这就是C3数据集的由来。"
数据集地址: huggingface.co/datasets/kw...
为了弥补这一空白,团队创建了首个交叉视角、交叉模态对应数据集C3,其构建流程巧妙而高效:
- 收集平面图: 从维基共享资源中筛选出10,842张建筑平面图,涵盖6,194个不同场景,包括教堂、城堡、博物馆等多种建筑类型。
- 匹配照片: 结合MegaScenes和YFCC100M数据集,获取与平面图对应的场景照片,最终得到1,474个场景的766K张照片。
- 建立对应关系: 使用COLMAP对每场景照片进行SfM重建,生成稀疏点云,然后手动将点云与平面图对齐。这种对齐方式实现了图像像素与平面图坐标之间的精确映射,是以往任何数据集都未能大规模实现的。
最终构建的C3数据集包含90K对平面图-照片组合,涉及597个场景,提供1.53亿个像素级对应点和85K个相机姿态。该资源对于训练计算机理解真实世界图像与简化地图之间的关系至关重要,将直接推动室内导航、机器人运动和空间数字化重建等技术的发展。
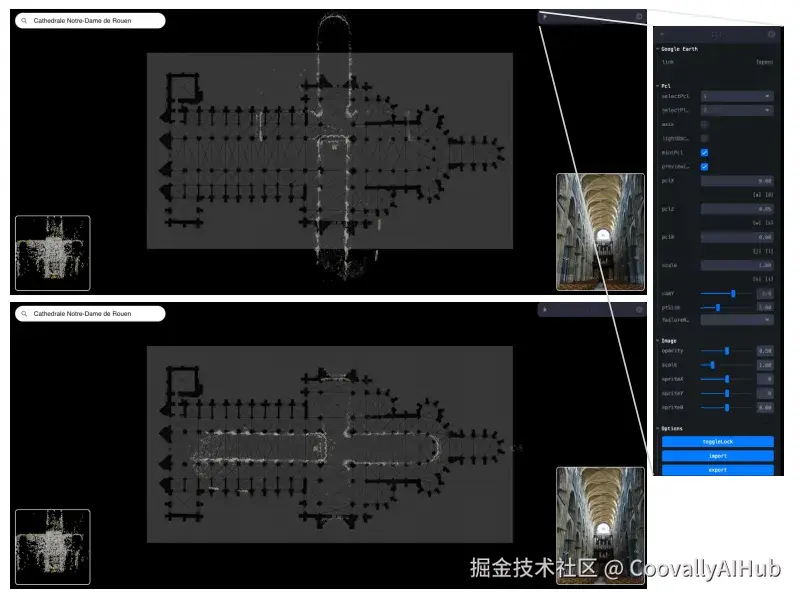
C3Po方法:点图预测实现算法突破
有了高质量数据集后,研究团队开始攻克算法难题。他们测试了当前最先进的对应方法,包括SuperGlue、LoFTR、DINOv2等,发现这些方法在交叉视角、交叉模态任务上表现不佳,错误率往往超过图像尺寸的10%。
研究的关键创新在于将问题重新定义为点图预测任务,并基于DUSt3R模型进行改进,新模型被昵称为C3Po------既是对其全称"基于点图预测的跨视图跨模态对应关系"的缩写,也是对《星球大战》中经典角色的戏谑致敬。
代码链接: github.com/c3po-corres...
C3Po的核心改进包括:
- 拆分孪生编码器: 由于平面图和照片来自不同域,团队将DUSt3R的孪生编码器拆分为两个独立编码器,分别学习各自域的特征分布。
- 点图到对应转换: 利用DUSt3R生成的点图(将图像像素映射到3D场景点),通过正交投影将3D点投影到平面图的2D坐标系中。
- 数据增强: 为防止过拟合,对平面图进行光度增强和几何增强,提高模型泛化能力。
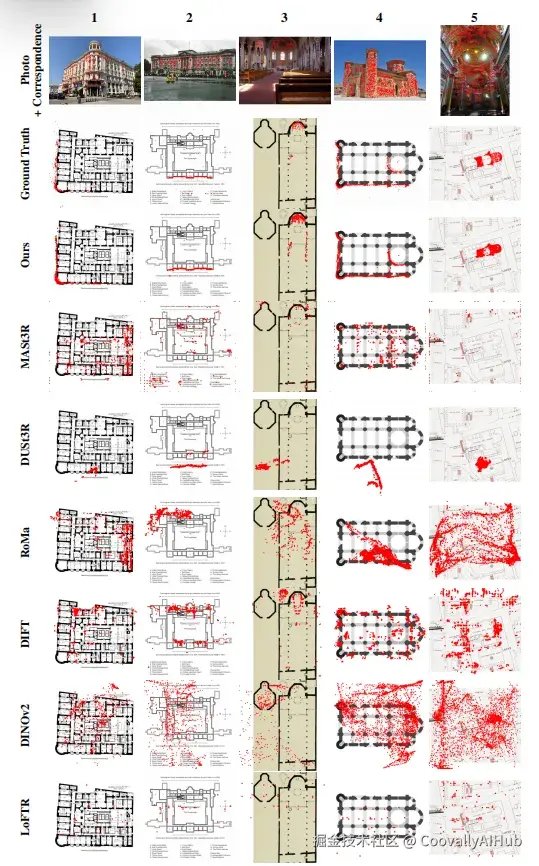
实验结果:显著优于现有方法
经过在C3数据集上的训练,C3Po方法取得了显著成果:
- 降低34%的RMSE误差: 相比最佳基线方法,C3Po在归一化坐标中的均方根误差降低了34%。
- 更高的准确率: 在PCK和精确率-召回率曲线上,C3Po均表现最优。
- 置信度与准确性相关: 研究表明,C3Po系统对其预测结果有信心时,能够提供更可靠的结果------正确预测通常伴随高置信度分数,而错误预测则置信度较低。
这些结果表明,针对特定任务设计的数据集和模型架构能显著提升跨模态视觉对应的性能,教会机器在照片和平面图之间找到像素级的匹配项,即使两者看起来完全不同。
挑战与未来方向
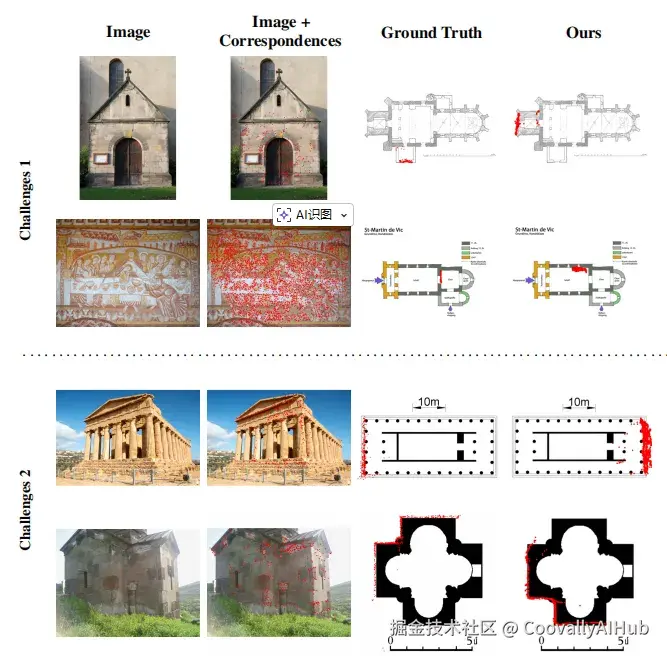
尽管C3Po取得了突破,研究团队也识别出两类仍然具有挑战性的情况:
- 上下文信息不足的照片:如门或艺术品的特写照片,缺乏全局场景信息,难以确定在平面图中的具体位置。
- 结构对称的场景:如对称的寺庙或教堂,从照片中难以区分左右或前后部分。
这些挑战提示未来的研究方向:或许需要预测对应关系的概率分布而非单一确定位置,使用扩散模型等生成式方法可能更为合适。
从机器人导航到3D重建
C3数据集和C3Po方法为多个领域开启了新的可能性:
- 机器人定位与导航:使机器人仅凭平面图和少量视觉输入就能在复杂建筑内自主定位与导航。
- 增强现实导览:将实时拍摄的照片与建筑平面图实时对齐,为游客提供沉浸式增强导览体验。
- 三维重建优化:为缺少重叠视角的稀疏图像集提供额外约束,显著改善重建质量与完整性。
- 跨模态生成:基于平面图生成逼真的室内场景图像,或从单张照片推理生成完整的建筑平面图。
"从长远来看,我们希望这能启发大型3D计算机视觉模型的发展,使其能够接收与场景相关的各种输入,"斯纳维利展望道,"3D计算机视觉研究领域在利用人工智能领域的最新趋势方面通常比其他领域落后几年,我个人认为,人工智能的这种多模态发展方向很快也将成为3D计算机视觉领域的新前沿。"
结语
这项研究通过构建首个交叉视角、交叉模态对应数据集C3,并提出创新的点图预测方法C3Po,在让AI理解抽象布局与具体视觉场景之间的对应关系上迈出了关键一步。该成果不仅解决了当前计算机视觉工具的一大缺陷,也为机器人技术、导航系统和3D建模等领域的进步提供了新的技术基础。
随着更多高质量数据的积累和算法的不断优化,我们有望看到计算机视觉系统在理解复杂空间关系方面取得更大突破,最终实现接近人类水平的跨模态空间推理能力。
研究团队已公开项目网站和数据集,期待这一工作能激发更多关于全局抽象结构与局部视觉信息联合推理的研究,推动3D计算机视觉走向真正的多模态新时代。