在机器人操作领域,"通用性" 始终是难以攻克的难关------现有方案要么局限于 2D 视觉理解,无法适配物理世界的 3D 空间交互;要么依赖单一数据集训练,面对不同机器人、不同场景就 "水土不服"。
而美团团队提出的RoboTron-Mani ,以 "3D 感知增强 + 多模态融合架构" 为核心,搭配涵盖多平台数据的RoboData数据集,实现了 "跨数据集、跨机器人、跨场景" 的全能操作:既通过相机参数与占用率监督强化 3D 空间理解,又借助模态隔离掩码提升多模态融合精度,最终在模拟与真实场景中,成为首个超越专家模型的通用型机器人操作策略。
RoboTron-Mani 官方项目页:https://github.com/EmbodiedAI-RoboTron/RoboTron-Mani
为什么要重构机器人操作的模型与数据体系?
当前机器人操作方案陷入了 "双重瓶颈":要么模型缺乏 3D 感知能力,难以应对物理世界的空间交互;要么数据集存在模态缺失、空间错位问题,导致跨平台训练效果差,核心问题可归结为 "无法同时兼顾'3D 环境适配性'与'数据利用高效性'":
| 方案类型 | 代表思路 | 核心缺陷 |
|---|---|---|
| 传统多模态模型 | 基于 2D 图像的视觉 - 语言 - 动作映射 | 1. 聚焦 2D 图像理解,缺乏 3D 空间感知,物理世界交互精度低;2. 模态融合灵活性差,难以适配多源输入 |
| 单数据集训练模型 | 针对特定机器人 / 场景优化策略 | 1. 泛化能力弱,换机器人或场景需重新训练;2. 数据收集成本高,如 RT-1 数据集 13 万段数据耗时 17 个月 |
| 多数据集融合方案 | 简单拼接不同平台数据 | 1. 缺失多视角图像、深度图等关键模态;2. 空间坐标与动作表示不统一,导致训练冲突、性能下降 |
这些方案都忽略了一个关键:机器人操作是 "3D 空间感知" 与 "多源数据协同" 的结合------既需要模型能精准理解物理空间的物体位置、姿态关系,又需要高质量数据集提供统一的训练与评估标准。
RoboTron-Mani 与 RoboData 的协同设计,正是针对性解决这一问题:用 RoboTron-Mani 突破 3D 感知与模态融合瓶颈,用 RoboData 解决数据模态缺失与空间错位问题,最终实现 "从数据到模型" 的全链路优化。
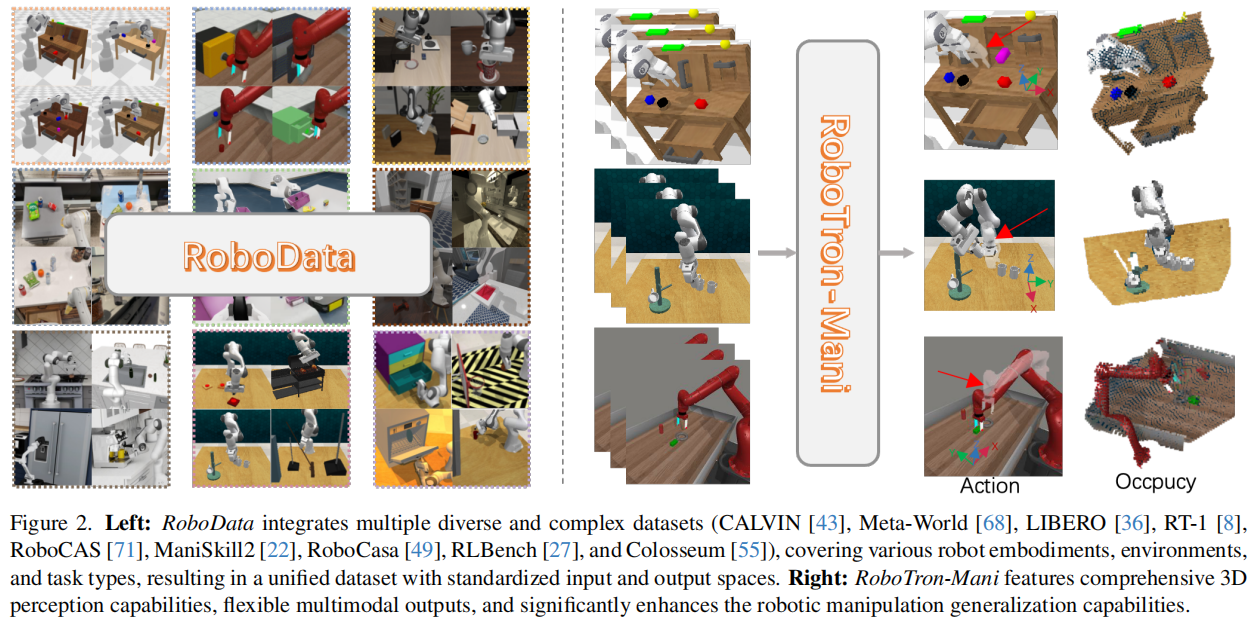
RoboTron-Mani + RoboData:如何实现通用机器人操作?
RoboTron-Mani 的核心设计可概括为 "以 3D 感知为基础,以多模态融合为核心,搭配统一数据集,实现跨场景、跨机器人的通用操作"。它既具备精准的空间理解能力,又能灵活处理多源输入,具体分为两大核心组件:
核心组件 1:RoboTron-Mani 模型------多模态融合的 "操作大脑"
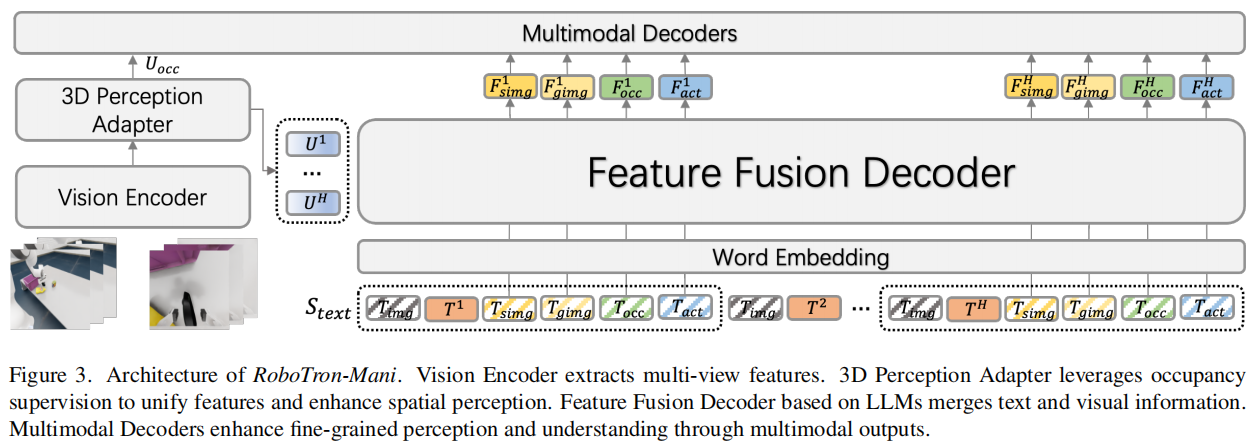
RoboTron-Mani 采用 "视觉编码器 + 3D 感知适配器 + 特征融合解码器 + 多模态解码器" 的四层架构,支持文本、图像、相机参数等多源输入,输出动作、图像、占用率等多模态结果,数学表达为:
( O A , O I , O O ) = RoboTron-Mani ( T , I , C a m ) \left(O_{A},\leftO_{I}, O_{O}\\right\right)= \text{RoboTron-Mani}(T, I, Cam) (OA,OI,OO)=RoboTron-Mani(T,I,Cam)
其中,T为文本指令,I为多视角图像序列,Cam为相机参数, O A O_A OA为机器人动作, O I O_I OI为预测图像, O O O_O OO为 3D 占用率,四大核心模块的设计逻辑如下:
视觉编码器:提取多视角时空特征
从H个时间步、N个视角的图像中提取特征 F I h , n F_{I}^{h, n} FIh,n,为后续 3D 感知与模态融合提供基础,适配机器人操作的多视角观测需求。
3D 感知适配器:强化空间理解能力
采用 UVFormer 模型,融合图像特征、相机参数与可学习查询,生成统一的 3D 视图表示,数学表达为:
U I h = UVFormer ( Q , X h , C a m h ) U_{I}^{h}=\text{UVFormer}\left(Q, X^{h}, Cam^{h}\right) UIh=UVFormer(Q,Xh,Camh)
其中,Q为查询的位置与特征信息, X h X^h Xh为图像特征, C a m h Cam^h Camh为相机参数, U I h U_I^h UIh包含 L × B × P L×B×P L×B×P 3D 网格的空间信息,让模型精准理解物体的三维位置与姿态关系。
特征融合解码器:灵活适配多模态输入
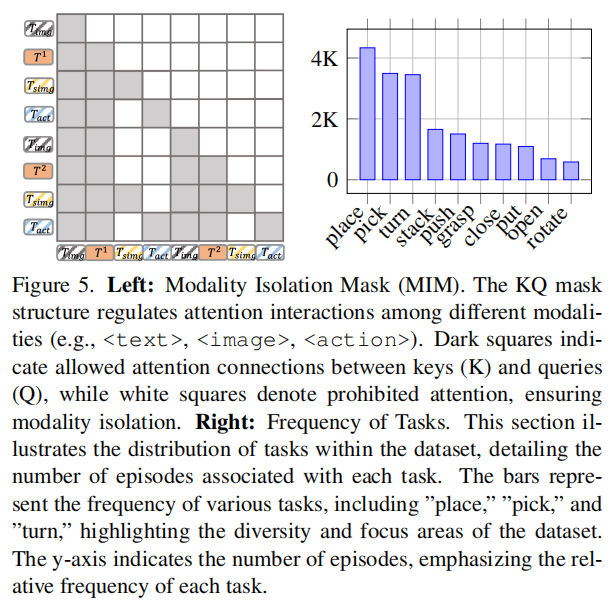
基于 OpenFlamingo 的交叉注意力机制,引入模态隔离掩码(MIM) ,实现多模态的灵活融合与监督。关键设计包括:
-
构建包含文本、图像、动作等模态的读取令牌序列 T ′ T' T′,通过词嵌入层生成文本特征 F T F_T FT;
-
以文本特征为查询,3D 视图表示为键值对,通过交叉注意力融合多模态信息;
-
MIM 机制可控制不同模态间的注意力交互,训练时支持辅助模态监督,推理时可省略不必要模态,大幅提升灵活性。
多模态解码器:精准输出操作结果
针对不同输出类型设计专用解码器,确保结果精准性:
- 图像解码器:通过注意力层与卷积网络,生成下一时间步的静态图像或手腕视角图像;
- 占用率解码器:通过 3D 卷积网络重建 3D 占用率,包含空间位置与 RGB 颜色信息,辅助空间感知;
- 动作解码器:采用 MLP 或 DiT 模块,输出机器人 6D 位姿增量与夹具动作,直接指导操作执行。
训练目标:多模态协同优化
设计综合损失函数,同时优化动作、图像、占用率输出,数学表达为:
l = l a + λ i m a g e ( l s i m g + l g i m g ) + λ o c c l o l=l_{a}+\lambda {image}\left( l{simg}+l_{gimg}\right) +\lambda {occ} l{o} l=la+λimage(lsimg+lgimg)+λocclo
其中, l a l_a la为动作损失(结合 MSE 与 BCE 损失), l s i m g l_{simg} lsimg与 l g i m g l_{gimg} lgimg为图像损失(L2 损失), l o l_o lo为占用率损失(位置与 RGB 颜色损失),支持模态缺失时灵活调整损失项。
核心组件 2:RoboData 数据集------统一标准的 "训练与评估基石"
RoboData 整合了 CALVIN、Meta-World、RT-1 等 9 个主流公开数据集,包含 7 万段任务序列、700 万个样本,涵盖拾取、放置、堆叠等多种任务,核心解决传统数据集的三大痛点:
模态补全:完善 3D 相关关键信息
针对多数数据集缺失深度图、相机参数的问题,通过重新渲染模拟环境、重建原始数据等方式,补充这些关键模态,为 3D 感知训练提供支撑。
空间与动作对齐:消除跨平台差异
- 3D 空间对齐:将所有数据集的坐标系统一为 "X 轴向右、Y 轴向前、Z 轴向上",并统一工作空间范围为 -0.5,-0.5,0 至 0.5,0.5,1;
- 动作表示对齐:采用复合旋转矩阵法(CRMM)统一不同数据集的动作表示,解决欧拉角差分、位姿组合等多种表示方式的冲突问题。
统一评估体系:支持跨数据集测试
提供标准化的输入输出接口,支持模型在多个数据集上同时评估,避免传统方案 "仅适配单一数据集" 的局限,为通用机器人操作模型提供公平的评估基准。
实验结果:通用型操作模型如何超越专家方案?
RoboTron-Mani 在 "模拟 + 真实" 数据集、"单任务 + 多任务" 场景下的实验,充分验证了其通用性与优越性,核心结论可概括为 "3D 感知强、跨场景泛化好、多数据集性能优":
核心性能:超越专家模型的通用能力
在 LIBERO、RoboCasa、CALVIN、Meta-World、RT-1 五大数据集上,RoboTron-Mani 作为首个通用型策略,实现了对专家模型的超越:
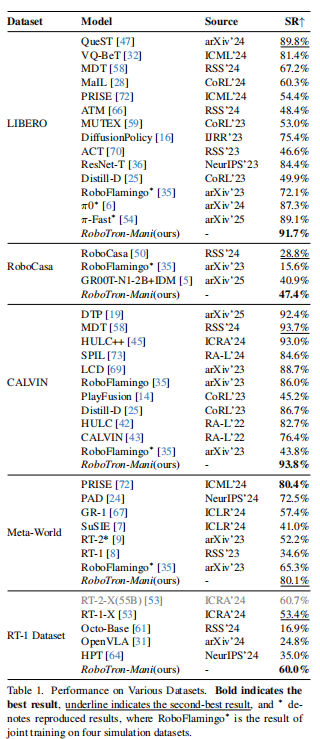
- LIBERO 数据集:成功率达 91.7%,超过当前最佳专家模型 QueST(89.8%);
- CALVIN 数据集:成功率 93.8%,任务平均序列长度从 1.7 提升至 3.5,大幅提升长序列任务能力;
- RT-1 数据集:平均成功率 60%,显著优于同参数规模的其他模型;
- 跨数据集泛化:在 4 个模拟数据集上,相较于通用模型 RoboFlamingo,成功率平均提升 14.8%-19.6%。
消融实验:关键模块的核心价值
通过禁用 RoboTron-Mani 的关键模块,验证各组件的必要性:
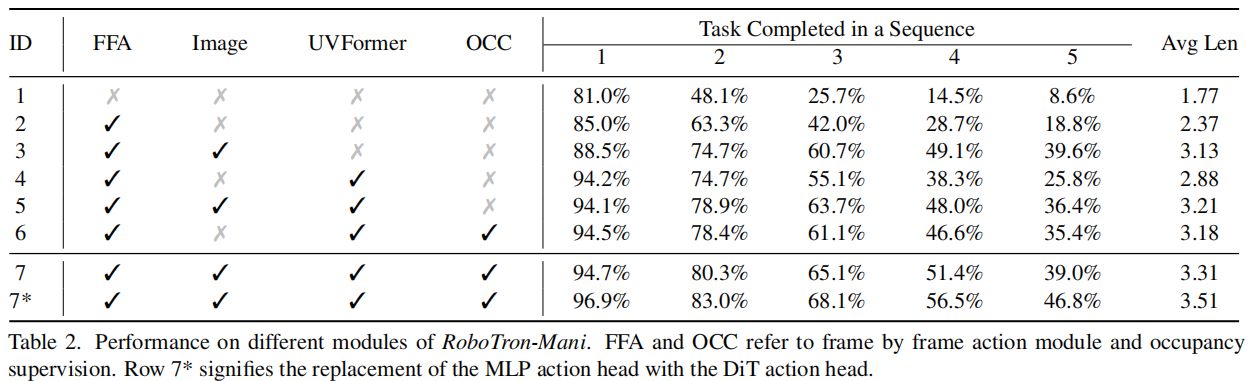
- 无 3D 感知适配器(UVFormer):CALVIN 数据集首任务成功率从 94.2% 降至 85.0%,空间感知精度显著下降;
- 无模态隔离掩码(MIM):多模态融合灵活性降低,跨数据集泛化性能下降 12%-15%;
- 无占用率监督(OCC):长序列任务成功率下降明显,后续任务成功率从 56.5% 降至 48.1%,证明 3D 空间信息对复杂操作的重要性。
数据对齐的影响:RoboData 的关键作用
对比 "对齐前" 与 "对齐后" 的数据训练效果,验证 RoboData 空间与动作对齐的价值:
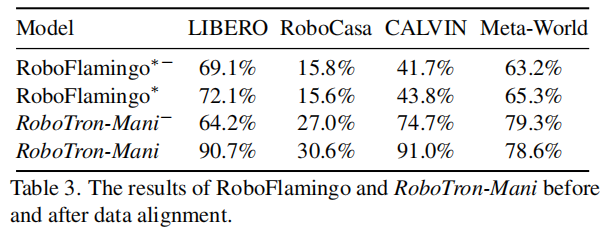
- RoboTron-Mani 在对齐数据上训练后,LIBERO 数据集成功率从 64.2% 提升至 90.7%,CALVIN 数据集从 74.7% 提升至 91.0%;
- 未对齐数据训练时,Meta-World 数据集因动作表示简单(仅 3 个位置变化),性能下降较小,但其他数据集成功率平均下降 25%-30%,证明数据对齐是跨平台训练的基础。
关键结论与未来方向
核心结论
- 3D 感知是物理世界交互的关键:通过相机参数与占用率监督,RoboTron-Mani 大幅提升空间理解能力,为精准操作提供基础;
- 统一数据集是通用模型的前提:RoboData 解决了模态缺失、空间错位问题,使跨平台、跨机器人训练成为可能;
- 多模态融合需兼顾灵活性与精准性:模态隔离掩码(MIM)让模型可灵活适配多源输入,专用解码器确保动作、图像等输出的精准性。
未来方向
- 多模态扩展:当前以视觉、文本、相机参数为主,未来可加入触觉、力反馈等模态,提升复杂场景适应性;
- 模型效率优化:当前 40 亿参数模型训练需 50 小时,未来可通过模型轻量化、量化等方式,适配边缘计算场景;
- 真实场景数据扩充:进一步整合更多真实世界数据集,减少模拟到真实场景的域迁移差距。
总结
RoboTron-Mani 与 RoboData 的协同创新,打破了 "机器人操作要么 3D 感知弱,要么泛化能力差" 的僵局。它没有局限于单一数据集或场景的局部优化,而是通过 "3D 感知增强 + 多模态融合 + 统一数据标准" 的全链路设计,实现了 "跨数据集、跨机器人、跨场景" 的通用操作。对于追求规模化落地的工业(如仓储分拣)、服务(如家庭保洁)场景,这种兼顾通用性与实用性的方案,为机器人操作技术的产业化提供了重要参考。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?