1. 引言:计算机视觉的范式转移
在计算机视觉的发展历程中,目标检测(Object Detection)始终占据着核心地位。长久以来,该领域被基于卷积神经网络(CNN)的密集预测范式所主导。无论是"两阶段(Two-Stage)"的代表 Faster R-CNN,还是"单阶段(One-Stage)"的标杆 YOLO 和 SSD 系列,它们在设计哲学上都共享着同一套归纳偏置(Inductive Bias):将目标检测视为在密集网格上的分类与回归问题。为了解决尺度变化和重叠问题,这些方法不得不依赖于大量手工设计的组件,如锚框(Anchor Boxes)生成的先验几何约束,以及非极大值抑制(NMS)来去除冗余预测。尽管这些方法在工业界取得了巨大的成功,但其复杂的超参数调整(如锚框的尺寸、比例、IoU 阈值)和非端到端(End-to-End)的特性,始终限制了检测系统的灵活性与极简性。
2020年5月,Carion 等人提出的 DETR (End-to-End Object Detection with Transformers) 横空出世,彻底打破了这一局面。DETR 并没有试图在 CNN 的框架内修补,而是从根本上重构了目标检测的定义:将其视为一个**集合预测(Set Prediction)**问题。利用 Transformer 架构本身具有的全局感受野(Global Receptive Field)和置换不变性(Permutation Invariance),DETR 摒弃了锚框和 NMS,直接并行预测一组物体,并通过二分图匹配(Bipartite Matching)实现预测框与真实框的一一对应。
这一变革不仅简化了检测流水线,更引入了全新的数学视角。然而,初代的 DETR 并非完美,它面临着收敛极慢(需要 500 个 Epoch)、小目标检测性能差以及计算复杂度高等严峻挑战。随后的三年间,学术界与工业界围绕 DETR 进行了密集的迭代与优化,诞生了 Deformable DETR、DAB-DETR、DN-DETR 以及最终挑战 YOLO 实时性地位的 RT-DETR。
本报告旨在对 DETR 及其衍生家族进行详尽的深度调研。我们将从其理论基础出发,深入剖析其架构细节、数学原理及演进逻辑,对比其与传统 CNN 检测器的优劣,并重点探讨其在实时性优化、小目标检测及工业部署方面的最新进展。
2. 传统检测范式的局限与 DETR 的理论重构
要深刻理解 DETR 的革新意义,必须首先审视传统目标检测方法的痛点。
2.1 密集预测与手工先验的桎梏
在 DETR 出现之前,主流检测器(如 Faster R-CNN, RetinaNet, YOLOv3)的工作流大致如下:
-
特征提取:通过 CNN 主干(Backbone)提取图像特征。
-
先验生成:在特征图的每个像素位置生成多个不同尺度和长宽比的锚框(Anchors)。例如,RetinaNet 可能在每个位置生成 9 个锚框。对于一张 800 \\times 800 的图像,这可能导致产生数万甚至数十万个候选框。
-
分类与回归:预测每个锚框属于某个类别的概率以及相对于预设锚框的坐标偏移量。
-
后处理(NMS):由于一个物体可能被多个锚框同时检测到,必须使用非极大值抑制(NMS)来过滤重叠框。
这种范式存在显著的缺陷:
-
非端到端可微:NMS 是一个启发式的后处理步骤,通常不可微,阻断了梯度反向传播,使得网络无法直接优化最终的评价指标(如 mAP)。
-
超参数敏感:锚框的设计(大小、比例)和 NMS 的阈值需要根据数据集的物体分布进行精细调节。例如,检测行人和检测车辆可能需要完全不同的锚框设置。
-
标签分配(Label Assignment)的复杂性:在训练过程中,如何将成千上万个锚框分配给几个真实物体(Ground Truth)是一个复杂的问题(正负样本分配),涉及 IoU 阈值筛选等启发式规则。
2.2 DETR 的集合预测哲学
DETR 提出了一种全新的视角:直接预测物体的集合。假设图像中有 N 个物体,模型直接输出 N 个预测结果。由于图像中物体的数量是变化的,而神经网络通常输出固定维度的张量,DETR 设定了一个固定的预测集合大小 N(通常远大于图像中实际物体的最大数量,如 N=100)。
2.2.1 二分图匹配(Bipartite Matching)
为了实现端到端的训练,DETR 必须解决"哪个预测对应哪个真实物体"的问题。在密集预测中,这是通过空间位置对齐来解决的。而在 DETR 中,预测结果是无序的集合。因此,DETR 引入了基于**匈牙利算法(Hungarian Algorithm)**的最优二分图匹配。

2.2.2 匈牙利损失(Hungarian Loss)
一旦确定了最优匹配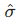 ,模型就使用匈牙利损失函数进行训练。该损失函数由分类损失和回归损失组成:
,模型就使用匈牙利损失函数进行训练。该损失函数由分类损失和回归损失组成:
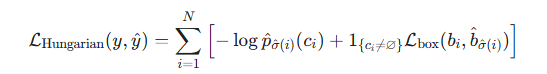
-
分类损失:通常使用交叉熵损失。由于大部分预测目标是 \\varnothing(背景),类别不平衡问题依然存在,因此在 DETR 的后续变体中常结合 Focal Loss。
-
回归损失 :传统 CNN 检测器多使用
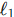 损失或 Smooth
损失或 Smooth 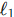 损失。然而,
损失。然而,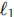 损失对物体尺度敏感(大物体的相同像素误差带来的损失值更大)。为了解决这个问题,DETR 引入了 GIoU (Generalized Intersection over Union) 损失与
损失对物体尺度敏感(大物体的相同像素误差带来的损失值更大)。为了解决这个问题,DETR 引入了 GIoU (Generalized Intersection over Union) 损失与 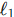 损失的线性组合:
损失的线性组合: -
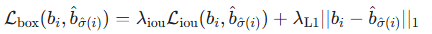
这种组合确保了损失函数既具有尺度不变性(通过 GIoU),又能快速收敛(通过 )。
3. 原始 DETR 架构深度剖析
DETR 的架构设计以极简主义著称,主要由三个部分组成:CNN 主干、Transformer 编解码器、前馈预测网络(FFN)。
3.1 CNN 主干与位置编码
3.4 预测头(Prediction Heads)
-
主干网络(Backbone) :输入图像
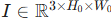 首先通过一个标准的 CNN(如 ResNet-50 或 ResNet-101)。通常提取最后一个阶段(C5)的特征图,其分辨率为原图的 1/32,通道数为 2048。即特征图
首先通过一个标准的 CNN(如 ResNet-50 或 ResNet-101)。通常提取最后一个阶段(C5)的特征图,其分辨率为原图的 1/32,通道数为 2048。即特征图 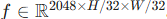 。
。 -
降维投影:由于 Transformer 的计算复杂度较高,通常通过一个 1 \\times 1 的卷积层将通道数从 2048 压缩至 d(例如 256)。此时特征图被展平为序列,长度为 (HW)/32^2。
-
位置编码(Positional Encodings):Transformer 架构具有置换不变性,无法感知像素的空间位置。DETR 采用了固定的正弦位置编码(Sinusoidal Positional Encoding),将其直接加到输入的特征序列上。值得注意的是,DETR 在编码器的每一层输入都加入了位置编码,而不仅仅是在第一层,这强化了模型对空间几何的感知能力。
3.2 Transformer 编码器:全局上下文建模
编码器(Encoder)由多层标准的 Transformer Encoder Layer 组成。每一层包含多头自注意力机制(Multi-Head Self-Attention, MHSA)和前馈网络(FFN)。
深度洞察:
CNN 的卷积核感受野是局部的,虽然通过堆叠层数可以扩大理论感受野,但在实际中,有效感受野往往局限于物体中心附近。相反,Transformer 的自注意力机制允许特征图上的每一个像素(Token)都能直接与图像中其他所有像素交互。这意味着,在编码器的第一层,模型就能利用全图的上下文信息(例如,利用环境背景来辅助识别物体)。这种**非局部(Non-local)**计算能力是 DETR 处理大物体和遮挡场景表现优异的关键原因。
3.3 Transformer 解码器与物体查询(Object Queries)
解码器(Decoder)是 DETR 最具创新性的部分。它不直接处理图像特征,而是处理一组固定的、可学习的嵌入向量,称为物体查询(Object Queries)。
-
物体查询的本质:这些查询向量(通常 N=100)在训练开始时随机初始化,并作为模型参数进行学习。它们可以被视为"可学习的锚点"或"提问者"。每个查询在通过解码器时,会通过自注意力机制相互通信(解决共现关系,如"人骑车"),并通过交叉注意力机制(Cross-Attention)从编码器的图像特征中聚合信息。
-
并行解码:与 NLP 中 Transformer 的自回归(Auto-regressive)解码不同,DETR 的解码器是并行输出的。所有 N 个查询同时通过解码器层,最终输出 N 个预测结果。
解码器的输出通过共享的前馈网络(FFN)进行处理。FFN 包含两个分支:
类别分支:输出 N 个类别的概率分布(包括"无物体"类)。
边界框分支:输出归一化的中心坐标和宽高 (x, y, w, h)。
3.5 原始 DETR 的局限性分析
尽管概念优美,原始 DETR 在实际应用中暴露出两个严重问题:
-
收敛极慢:在 COCO 数据集上,Faster R-CNN 仅需训练约 36 个 Epoch 即可收敛,而 DETR 需要 500 个 Epoch 才能达到相当的性能。这主要归因于交叉注意力机制的稀疏梯度问题------在训练初期,物体查询在全图范围内盲目搜索,注意力权重接近均匀分布,导致优化困难。
-
小目标检测性能差:由于计算复杂度的限制(自注意力是 O(L^2) 复杂度),DETR 只能在 1/32的低分辨率特征图上运行。对于小物体,其在特征图上可能仅占据不到一个像素,导致信息严重丢失。相比之下,CNN 检测器利用 FPN(特征金字塔网络)融合多尺度特征,能有效检测小物体。
4. 演进之路:从收敛优化到机制完善(2021-2022)
为了解决上述问题,学术界在 2021 至 2022 年间涌现了大量 DETR 变体,主要围绕"加速收敛"和"多尺度特征融合"展开。
4.1 Deformable DETR:解决分辨率与复杂度的矛盾
Deformable DETR 是 DETR 发展史上的最重要里程碑之一。Zhu 等人指出,Transformer 的全图注意力是极其低效的,因为对于特定的物体,只需要关注其周围的一小部分关键区域。

4.2 显式空间先验:Conditional DETR 与 Anchor DETR
研究者发现,原始 DETR 收敛慢的原因之一是物体查询(Object Queries)的语义含糊不清。
-
Conditional DETR:将查询分解为"内容查询"和"空间查询"。通过显式地将空间查询映射为注意力图的条件,缩小了查询的搜索范围,从而加速收敛。
-
Anchor DETR:更进一步,借鉴 CNN 中的锚点概念,将每个查询初始化为一个显式的 2D 锚点 (x, y)。查询不再是抽象的向量,而是与图像中的具体位置绑定。这使得注意力机制可以基于距离进行加权,极大地减少了搜索空间。
4.3 DAB-DETR:动态锚框的极致
DAB-DETR (Dynamic Anchor Boxes DETR) 将 Anchor DETR 的思想推向极致。它提出查询不仅是一个位置点,而应该是一个 4D 的锚框 (x, y, w, h)。
-
层级细化:在解码器的每一层,模型预测相对于当前锚框的偏移量 ( \Delta x, \Delta y, \Delta w, \Delta h ),并逐层更新锚框参数。这意味着锚框在解码过程中是动态变化的,逐渐逼近真实物体。
-
宽度与高度调制:利用锚框的宽高信息来调制注意力图的范围(例如,宽高比大的锚框,其注意力范围也应在对应方向拉伸)。
-
成效:DAB-DETR 不仅收敛更快,而且证明了纯粹的 DETR 架构(不依赖 Deformable 注意力)也能达到极高的精度。
5. 训练稳定性的突破:DN-DETR 与 DINO
尽管引入了空间先验,二分图匹配的不稳定性依然困扰着训练过程。
5.1 DN-DETR:去噪训练
DN-DETR (Denoising DETR) 揭示了一个关键洞察:在训练早期,由于预测结果不仅在位置上偏差大,而且在二分图匹配中经常发生跳变(即同一个查询在不同 Iteration 匹配到不同的真实物体),导致梯度方向极其不稳定。
为了解决这个问题,DN-DETR 引入了**去噪任务(Denoising Task)**作为辅助损失:
-
将真实的边界框(Ground Truth Bounding Boxes)加上噪声(如随机偏移、缩放)。
-
将这些加噪的框作为特殊的查询输入解码器。
-
要求模型重构出原始的真实框。
-
由于输入是基于真实框的,这里不需要二分图匹配,直接计算回归损失。
这种"去噪"训练为模型提供了一个稳定的梯度信号,类似于"Teacher Forcing",极大地加速了特征学习。
5.2 DINO:集大成者
DINO (DETR with Improved DeNoising Anchor Boxes) 是目前的学术界标杆(非实时类)。它结合了 DAB-DETR 的动态锚框和 DN-DETR 的去噪训练,并进一步引入了对比去噪(Contrastive DeNoising),即不仅教模型正样本(加噪的 GT),还教模型识别负样本(加了过大噪声的框应预测为背景)。DINO 是第一个在 COCO 数据集上超越 Swin-Transformer 等 SOTA 检测器的端到端 Transformer 模型,标志着 DETR 范式的完全成熟。
6. 实时性革命:RT-DETR 挑战 YOLO
尽管 DINO 精度极高,但其计算量巨大,难以满足工业界对实时性(Real-Time)的要求。长期以来,实时检测领域被 YOLO 系列(YOLOv5, v7, v8)垄断。YOLO 利用高效的 CNN 架构和高度优化的后处理,在速度与精度之间取得了极佳的平衡。
2023年,百度提出了 RT-DETR (Real-Time DETR),旨在打破 YOLO 的统治。
6.1 瓶颈分析与混合编码器
RT-DETR 团队分析发现,多尺度 Transformer 编码器是计算瓶颈。虽然 Deformable Attention 降低了复杂度,但在高分辨率特征图上处理序列交互依然耗时。
为此,RT-DETR 设计了高效混合编码器(Efficient Hybrid Encoder):
-
AIFI (Attention-based Intra-scale Feature Interaction):仅在最低分辨率(S5,语义最强)的特征图上使用 Transformer 自注意力。这大大减少了计算量,同时保留了全局语义建模能力。
-
CCFF (CNN-based Cross-scale Feature Fusion):对于多尺度特征(S3, S4, S5)的融合,放弃了 Transformer,转而采用基于 CNN 的融合模块(类似 PANet)。利用 1 * 1 和 3 * 3 卷积进行跨尺度特征聚合。
这种设计巧妙地结合了 Transformer 的语义优势和 CNN 的处理速度。
6.2 最小不确定性查询选择
在初始化物体查询时,RT-DETR 改进了以往的策略。它不是随机初始化,也不是仅根据分类分数选择 Top-K 特征,而是提出了最小不确定性查询选择(Uncertainty-Minimal Query Selection)。
它定义不确定性为分类分布与定位质量(如 IoU)的不一致性。选择那些分类置信度高且预测框质量大概率也高的特征作为初始查询。这确保了解码器从高质量的假设开始迭代,减少了解码层的压力(允许减少解码层数以提升速度)。
6.3 性能对比:RT-DETR vs. YOLO
下表展示了 RT-DETR 与主流 YOLO 模型在 COCO val2017 数据集上的对比(基于 T4 GPU):
| 模型 | 骨干网络 (Backbone) | 输入尺寸 | AP (COCO) | 延迟 (ms) | FPS | 参数量 (M) |
|---|---|---|---|---|---|---|
| YOLOv8-L | CSP-Darknet | 640 | 52.9% | 14.1 | 71 | 43.7 |
| YOLOv8-X | CSP-Darknet | 640 | 53.9% | 20.0 | 50 | 68.2 |
| RT-DETR-L | HGNetv2-L | 640 | 53.0% | 8.8 | 114 | 32 |
| RT-DETR-X | HGNetv2-X | 640 | 54.2% | 13.5 | 74 | 67 |
深度洞察:
RT-DETR 在同等精度下,速度显著快于 YOLOv8。更重要的是,RT-DETR 不需要 NMS。
在密集人群或复杂遮挡场景中,YOLO 依赖 NMS 过滤框,但这往往会导致误删(遮挡严重时,两个物体 IoU 高,NMS 会抑制其中一个)。而 RT-DETR 由于端到端的一对一匹配,能够自然地区分重叠物体,保持稳定的检测率。这使得 RT-DETR 在实际工业场景(如拥挤人群检测、密集货物计数)中具有天然优势。
7. 工程实践与部署细节
对于研究人员和工程师而言,理解架构只是第一步,如何在实际数据上训练和部署 DETR 才是关键。
7.1 训练策略与微调(Fine-tuning)
由于 Transformer 缺乏 CNN 的归纳偏置(如平移不变性),它通常需要更多的数据来学习这些特性。
-
数据增强:DETR 极其依赖强数据增强,如大尺度的随机裁剪(Random Crop)和多尺度训练(Multi-scale Training)。这有助于模型学习尺度不变性。
-
学习率设置:微调时,主干网络(Backbone)通常需要使用较小的学习率(如 10\^{-5}),而 Transformer 部分使用较大的学习率(如 10\^{-4})。这是为了防止破坏预训练的主干特征,同时让随机初始化的 Transformer 快速收敛。
-
优化器:AdamW 是标配,这与 CNN 常用 SGD 不同。Transformer 对梯度裁剪(Gradient Clipping)也比较敏感。
-
显存管理:由于注意力矩阵极其消耗显存,训练 DETR 往往只能使用很小的 Batch Size(如单卡 2-4 张图)。为了模拟大 Batch 的效果,**梯度累积(Gradient Accumulation)**是必不可少的技巧。
7.2 针对小目标的优化
尽管 Deformable DETR 和 RT-DETR 改善了小目标性能,但在极端场景(如无人机航拍、PCB 缺陷检测)下仍需特殊处理。
-
切片推理(SAHI):对于高分辨率图像,直接缩放输入会导致小物体像素过少。SAHI (Slicing Aided Hyper Inference) 技术将图像切成重叠的切片,分别进行推理,然后合并结果。由于 DETR 不需要 NMS,合并过程比 YOLO 更为直接和准确。
-
增大分辨率:DETR 对分辨率敏感,适当增大输入分辨率(如从 640 增至 1280)能显著提升 AP_S,但需权衡推理速度。
7.3 边缘端部署(Edge Deployment)
早期 DETR 难以部署在 TensorRT 或移动端,因为标准 Transformer 中的某些算子(如 Gather, Scatter, 动态 Shape)支持不佳。
-
RT-DETR 的部署优势:RT-DETR 特意避免了特殊的 CUDA 算子(如 Deformable DETR 中的自定义 CUDA 核),使用了更通用的 Gather/Scatter 操作,并且支持导出为 ONNX 和 TensorRT 引擎。
-
量化(Quantization):RT-DETRv2 进一步优化了量化支持,通过离散采样(Discrete Sampling)替代双线性插值,使其更容易进行 INT8 量化,从而在 Jetson Orin 等边缘设备上实现极高的推理帧率。
7.4 框架选择
目前主流的 DETR 开发框架包括:
-
Facebook DETR (Official): 适合学术研究,代码最原始,但功能较少。
-
mmdetection: 提供了最全的 DETR 变体实现(从原始 DETR 到 DINO),适合横向对比和学术复现。
-
Hugging Face Transformers : API 极其友好,适合快速 Demo 和微调,提供了
AutoModelForObjectDetection接口,但在自定义底层逻辑时不如 mmdetection 灵活。 -
Ultralytics (YOLO): 最新版已集成 RT-DETR。对于习惯 YOLO 生态的工程师,这是从 YOLO 迁移到 DETR 门槛最低的路径,支持一行代码训练和导出。
8. 未来展望:从检测到通用感知
DETR 的意义远不止于一个检测器,它开启了"序列即感知"的时代。
-
开放词汇检测(Open-Vocabulary Detection) :Grounding DINO 将 DETR 的物体查询与文本嵌入(Text Embeddings)对齐。用户可以输入"戴红色帽子的男人",模型将其转化为查询向量,在图像中搜索目标。这种能力使 DETR 成为多模态大模型(如 GPT-4V)视觉感知层的重要候选者。
-
全景分割(Panoptic Segmentation) :DETR 的原始论文就展示了通过在解码器后添加掩码头(Mask Head)来实现分割。Mask2Former 进一步发展了这一理念,统一了语义分割、实例分割和全景分割,证明了 Mask Classification 优于传统的 Per-pixel Classification。
-
视频目标检测 :DETR 天然适合视频处理。物体查询可以在帧与帧之间传递,自然地形成物体追踪(Tracking)轨迹,无需复杂的关联算法(如 Kalman Filter)。TrackFormer 和 MeMOT 等工作正是基于此展开。
9. 结论
DETR 并非对 CNN 的简单替代,它是计算机视觉底层逻辑的一次重构。它用数学上的集合预测和二分图匹配,替换了工程上的锚框和 NMS。
虽然诞生之初饱受非议(慢、重、难训练),但经过 Deformable Attention 的空间优化、DAB/DN 的查询优化以及 RT-DETR 的架构优化,DETR 家族已经完成了从"学术玩具"到"工业利器"的蜕变。在实时性要求极高、场景复杂度大(遮挡、密集)以及需要多模态扩展的应用中,DETR 及其变体正在逐渐取代 YOLO,成为新一代的目标检测首选方案。对于任何致力于计算机视觉前沿的研究者或工程师,深入掌握 DETR 范式已不再是可选项,而是必修课。