1、效果
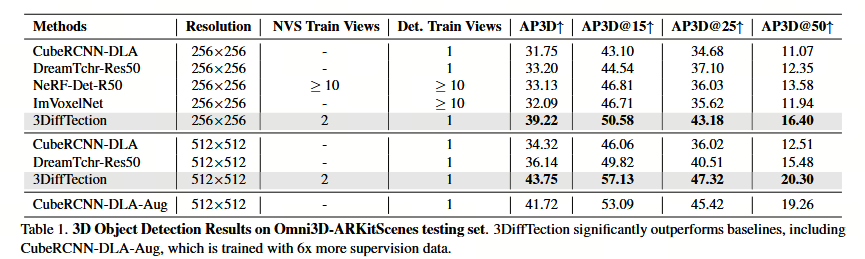
其实验结果(如大幅超越Cube-RCNN)也验证了这套方法的有效性。
2、主要贡献
通过视图合成增强具有3D感知的预训练2D扩散模型;将这些特征应用于3D检测任务和目标领域;进一步提高检测性能。
3、摘要
3DIFFTECTION是一个"先赋予几何感知,再进行检测微调" 的两阶段框架。它巧妙地利用无需3D标注的图片(如视频帧) 来教会一个扩散模型"理解3D几何",然后将这个拥有了3D"大脑"的模型变成一个强大的3D目标检测器。
4、思路
4.1 ControlNet
展示的 "Geometric ControlNet with Epipolar warp Operator" 正是其第一阶段(几何调优)的核心技术实现
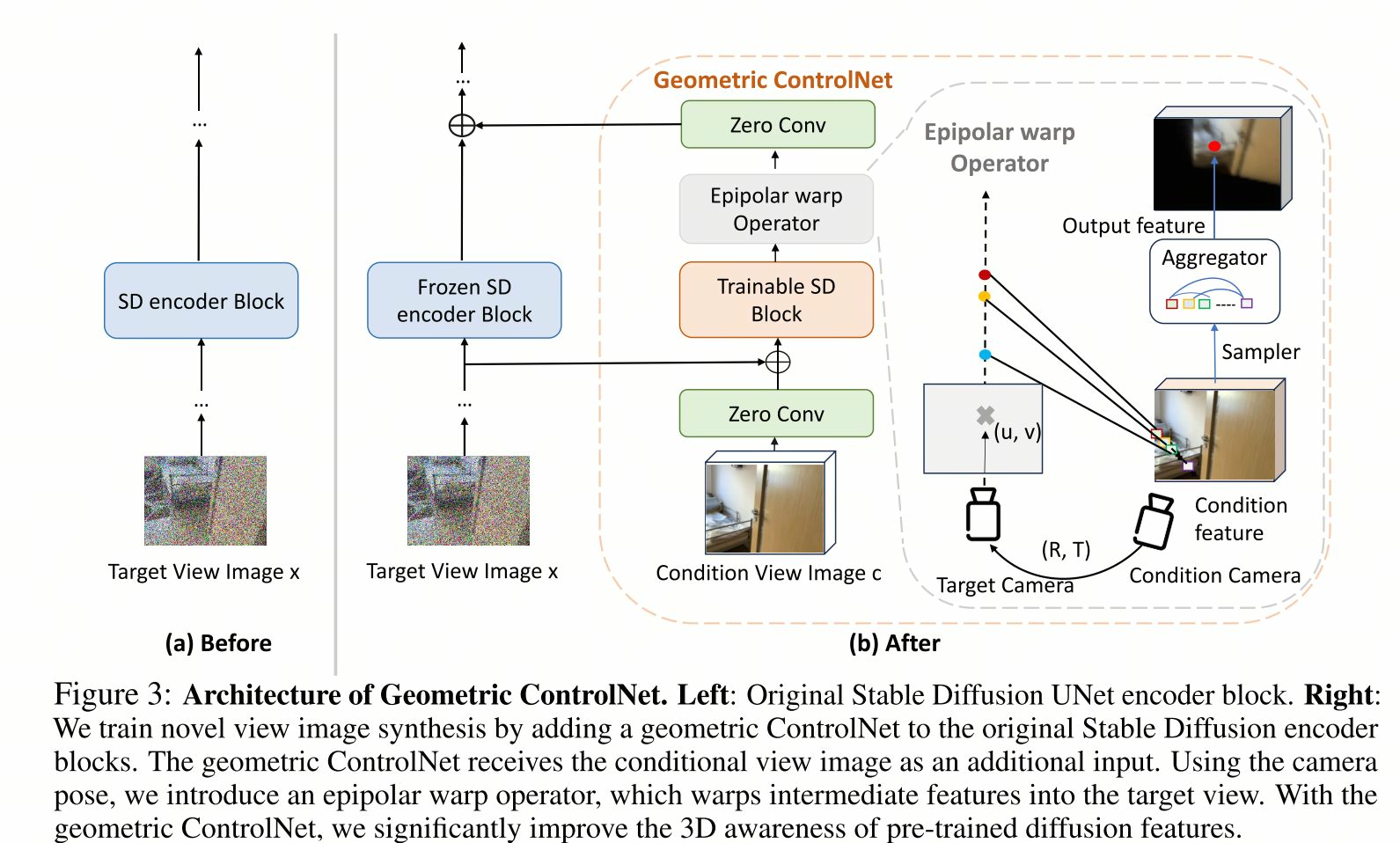
具体来说:
几何调优(对应图中的架构):
目标:不是为了生成漂亮的图片,而是为了让扩散模型的特征具备3D感知能力。
方法:在Stable Diffusion的编码器上,附加一个可训练的Geometric ControlNet(如图中橙色部分所示)。它接收一张条件图片 和目标相机位姿。
关键操作:通过极线扭曲算子,将条件图片的特征,根据两张图片之间的相机几何关系(极线几何),"扭曲"到目标视角。这个过程强制模型学习如何根据一张图推理另一视角下的场景内容,本质上是在学习3D结构。
优势:这个训练只需要有相机位姿的图片对(如视频帧),完全不需要3D框或点云标注,解决了数据标注瓶颈。
4.2 语义调优
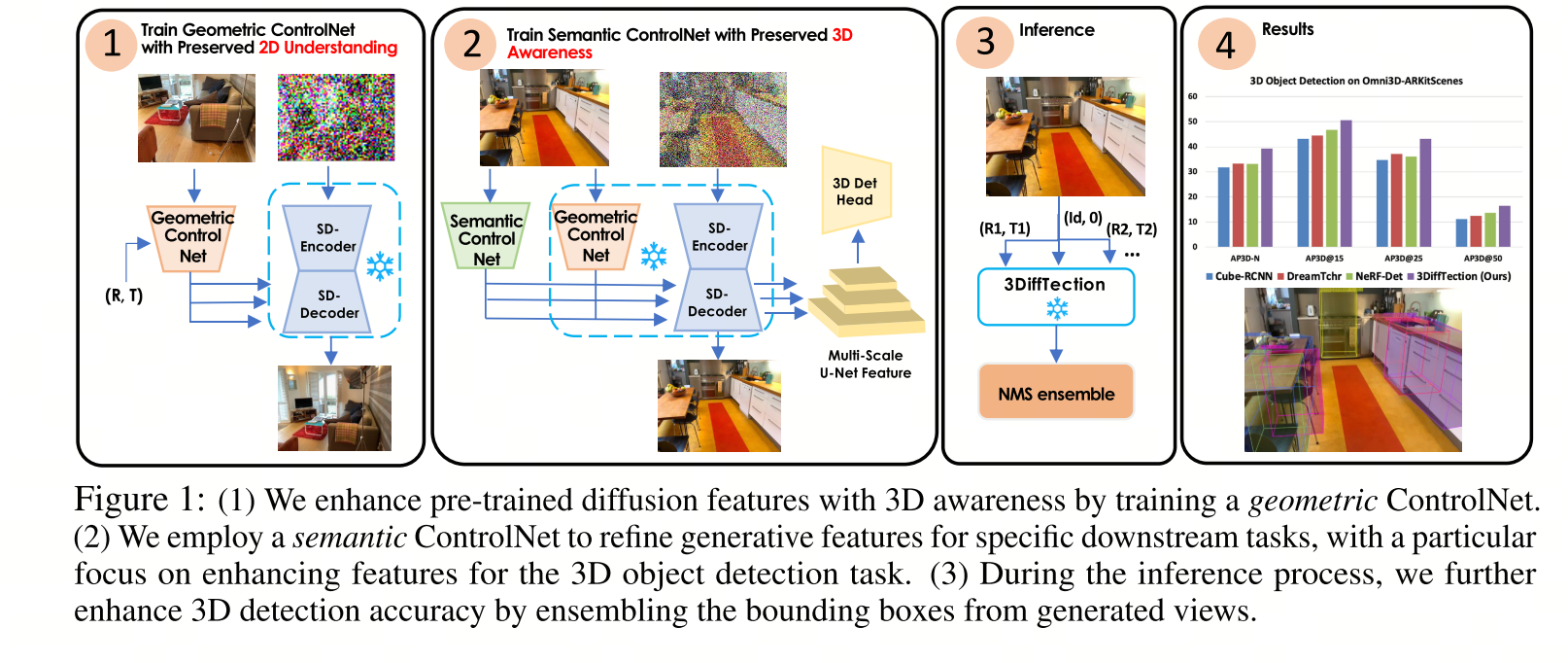
目标:将已经具备3D感知能力的模型特征,适配到具体的3D目标检测任务上。
方法:在几何调优后的模型基础上,使用带有3D检测标注的目标数据集 进行进一步训练。这里依然采用ControlNet架构,以保护并利用第一阶段学到的强大几何特征。
测试时集成:
推理策略:在最终检测时,模型不仅看输入的那一张图,还会在多个虚拟视角 上进行特征预测和集成。这相当于让模型"环视"这个物体,做出更准确的3D判断,充分释放了其3D感知能力的优势。
非常有趣的论文,很创新!