作为一名科研人员,你是否已经厌倦了这样的日常?
为了撰写文献综述或开题报告,你需要在PubMed、Google Scholar、百度学术等多个平台间反复切换,精心构思和组合关键词。搜索的结果是成百上千篇文献列表,你需要逐一点开,阅读摘要,判断相关性,手动摘录关键信息,再在脑中或笔记里费力地拼凑出一个领域的知识图谱。这个过程动辄耗费数天甚至数周,而最终可能发现关键信息仍有遗漏,或研究方向早已有人涉足。
这就是传统科研信息获取模式的典型困境:过程高度碎片化,效率低下,且严重依赖研究者个人的信息加工能力。我们使用的工具,本质上仍是"文献仓储"和"链接索引",它们只负责"呈现",不负责"理解"和"整合"。
而今天,以MedPeer平台中的 Deep Search 为代表的下一代AI检索工具,正在从根本上改变这一模式。它所带来的,并非简单的功能增强,而是一场从底层逻辑到用户体验的"代际"革新。
核心代差:从"关键词匹配"到"语义理解与任务完成"
要理解Deep Search的本质不同,我们可以从信息处理的三个核心环节进行对比:
1. 输入:从"精确指令"到"自然表达"
- 传统工具(PubMed/Google Scholar等):你必须像一个程序员,将你的信息需求"翻译"成系统能识别的"机器语言"------即关键词及其逻辑组合(AND, OR, NOT)。这要求你对领域术语非常熟悉,且需要不断试错调整策略。
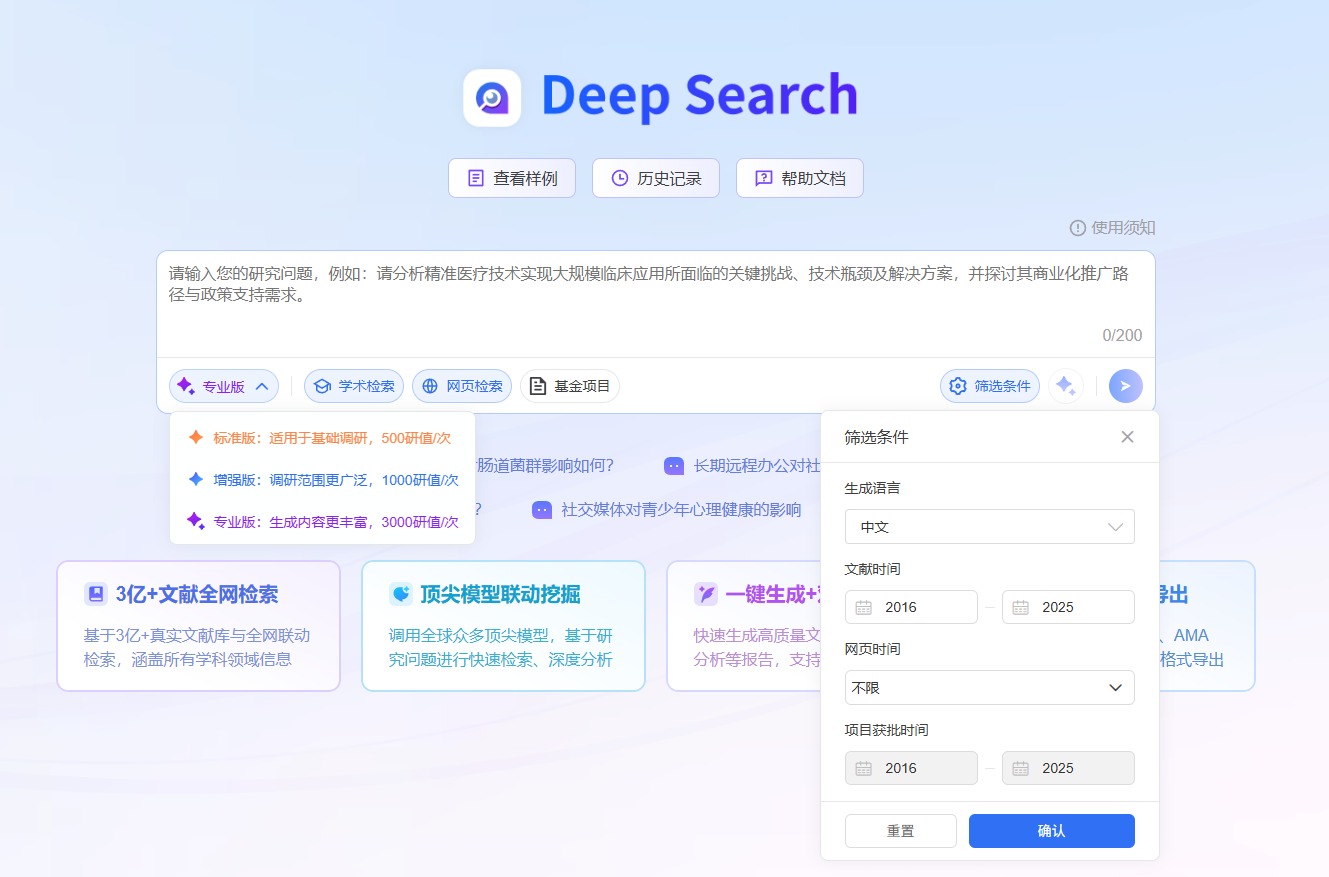
- Deep Search :你可以像请教一位资深同行一样,直接用自然语言提出完整、复杂的问题 。例如:
- 传统输入:(CRISPR AND gene therapy) AND (cancer)
- Deep Search输入:"请系统梳理2025年人工智能在科研领域的关键应用场景、技术突破及实际成效,重点分析其对不同学科研究范式的变革性影响 "
后者直接包含了你的研究意图、范围限定和期望的输出结构,工具需要先"理解"问题,再执行任务。
2. 过程:从"文献检索"到"智能研究助理"
- 传统工具 :过程是线性的、被动的。系统基于关键词匹配返回一个相关性排序的文献列表。所有的信息提取、比对、归纳、推理工作,全部由研究者本人完成。工具只是一个"图书管理员"。
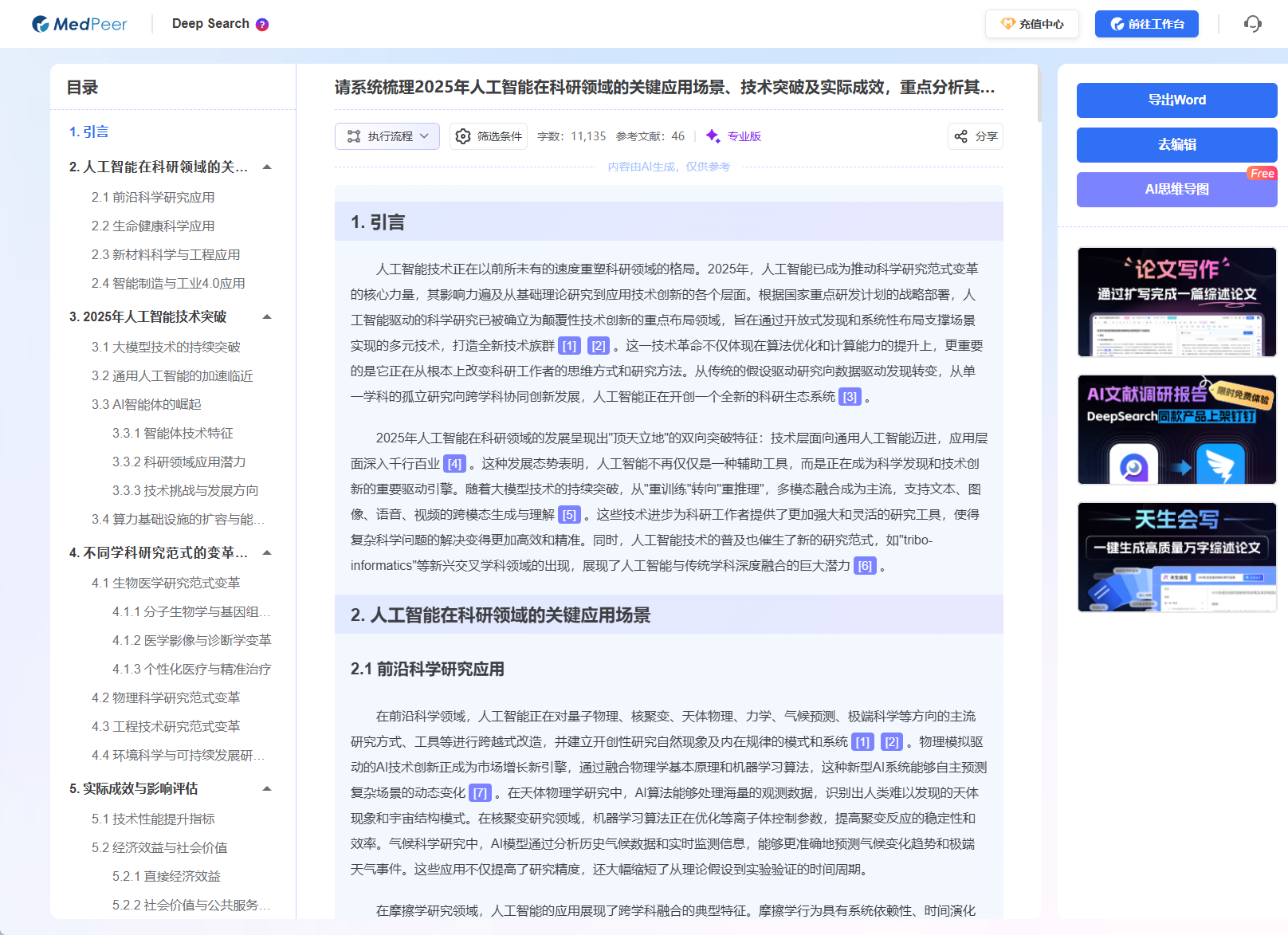
- Deep Search:过程是并行的、主动的。基于检索增强生成(RAG)等前沿AI技术,它扮演了一个"智能研究助理"的角色。其内部过程大致为:
1. 理解与拆解:深度解析你的自然语言问题,明确核心需求、子问题和所需信息类型。
2. 精准检索与抓取:根据理解后的意图,在其集成的3亿+学术文献数据库和可信网络资源中进行多源、并发检索,抓取最相关的文本信息。
3. 深度加工与整合 :这不是简单的摘要拼接。AI会对抓取的多源、多篇信息进行交叉验证、去重、提炼核心观点、识别矛盾与共识、梳理发展脉络。
4. 结构化生成:基于你的问题框架,将加工后的信息组织成逻辑严谨、证据支撑的答案或报告。
3. 输出:从"原材料"到"半成品/成品"
- 传统工具 :输出是一份文献清单(原材料)。你得到的是未经加工的"矿石",需要自己冶炼、提纯、锻造。
- Deep Search :输出是结构化的答案、多角度的分析总结或一份完整的调研报告(半成品/成品)。例如,针对上面的问题,它可能生成一个包含"技术路线概览"、"代表性研究案例"、"挑战分析"、"新兴解决方案"等章节的文档,并且关键结论都附有可跳转核查的原文引用。
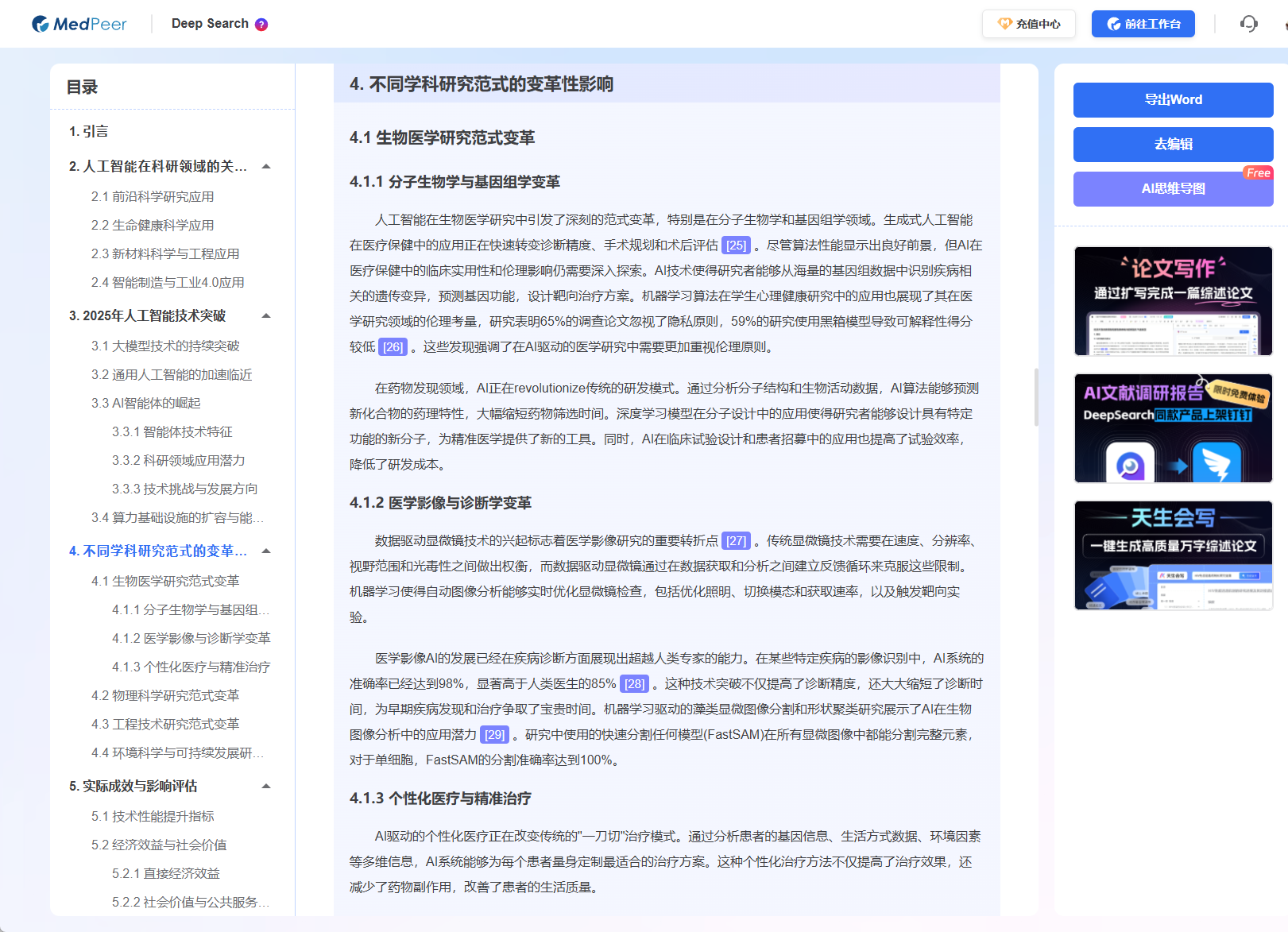

你获得的是一份已经过深度加工的"合金坯料"甚至"零件",可以直接用于完善你的思维框架,或经过小幅修改融入你的论文。这极大地降低了信息转化的心智负担。
体验升维:从"人找信息"到"信息为人服务"
这种底层逻辑的代差,最终体现为研究者体验的根本性变革:
- 传统模式(人找信息):研究者是"矿工"和"冶炼工",大部分时间和精力消耗在挖掘、搬运和初加工环节。思维过程时常被繁琐的重复劳动打断。
- Deep Search模式(信息为人服务) :研究者是"工程师"和"架构师"。你可以将机械性、重复性的信息搜集与整合工作委托给AI助理,从而将最宝贵的时间和认知资源集中在更高层级的任务上:提出更深刻的研究问题、设计更巧妙的实验方案、进行更富创见的学术思考。
我们正在经历科研范式的又一次演变。如果说互联网和数据库的普及,解决了"信息可得性"的问题,那么以Deep Search为代表的AI驱动深度检索工具,正在解决"信息可理解、可整合、可高效利用"的下一阶段难题。
对于每一位仍在与海量文献"搏斗"的科研人员而言,理解和拥抱这一代际工具,或许是在这个加速时代保持竞争力的关键一步。未来已来,它正以一种更智能、更高效的方式,为我们的研究赋能。