1. 研究背景
图像生成模型已成为现代人工智能的核心组成部分,涵盖文本到图像生成 (T2I)和图像编辑(TI2I)两大核心任务,能够基于文本提示合成或修改视觉连贯、语义一致的内容。扩散模型架构的出现推动了高分辨率图像生成技术的发展,使其能够捕捉细粒度的语义细节。
然而当前技术仍面临两大关键挑战:在文本到图像生成任务中,现有模型难以精准对齐复杂多维度提示,尤其是在多行文本书写、非字母语言(如中文)渲染、局部文本插入以及文本与视觉元素无缝融合等场景中表现不佳;在图像编辑任务中,需同时满足视觉一致性(仅修改目标区域,保留其他视觉细节)和语义连贯性(结构变化时维持全局语义)的双重要求,现有方案难以平衡二者关系。
为解决上述问题,Qwen-Image 作为 Qwen 系列的图像生成基础模型应运而生,通过数据工程优化 、渐进式学习策略 、增强型多任务训练范式和可扩展基础设施优化,实现复杂文本渲染与精准图像编辑能力的突破。
2. 核心工作
Qwen-Image 的核心目标是攻克复杂文本渲染与精准图像编辑的技术瓶颈,构建兼具通用生成能力与专项任务优势的图像生成基础模型,其核心工作主要包括三方面:
-
构建鲁棒的数据 pipeline,通过大规模数据收集、标注、过滤、合成增强和类别平衡,结合渐进式课程学习策略,从基础文本渲染逐步过渡到段落级和布局敏感描述,大幅提升模型对多语言(尤其是汉字等表意文字)的文本渲染能力。
-
提出增强型多任务学习框架,将 T2I、I2I 和 TI2I 任务无缝集成到共享 latent 空间,通过双编码机制提取语义特征(Qwen-VL)和重建特征(VAE 编码器),实现语义连贯性与视觉一致性的平衡。
-
设计高效的训练架构与优化策略,包括基于 TensorPipe 的 Producer-Consumer 分布式数据处理框架、混合并行训练策略以及多阶段预训练与后训练流程,确保模型在大规模训练中的效率与稳定性。
该模型的核心贡献体现在:复杂文本渲染能力突出,支持多语言、多行文本书写和精细布局;图像编辑一致性优异,在语义保留与视觉保真方面表现出色;跨基准测试性能领先,在各类生成与编辑任务中均超越现有模型。

3. 研究方法
3.1 模型架构
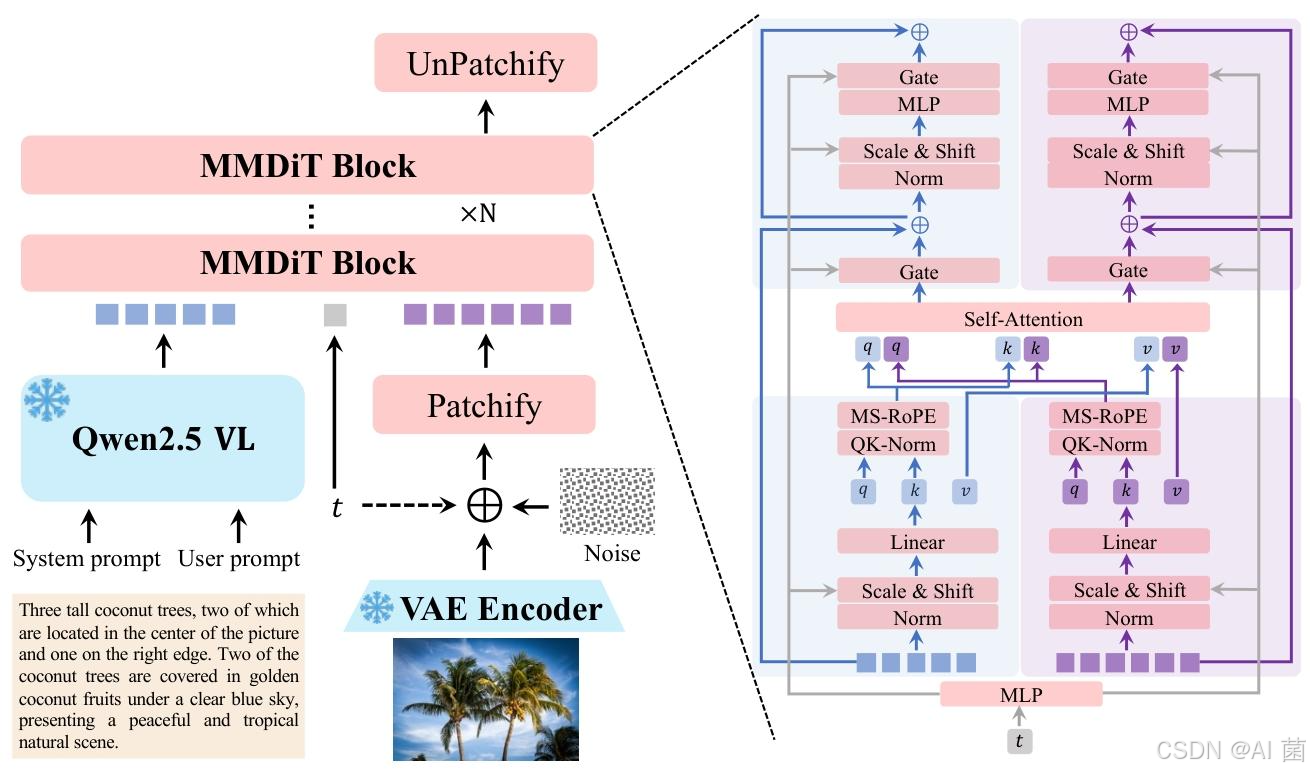
Qwen-Image 采用双流 MMDiT 架构,由三大核心组件构成:
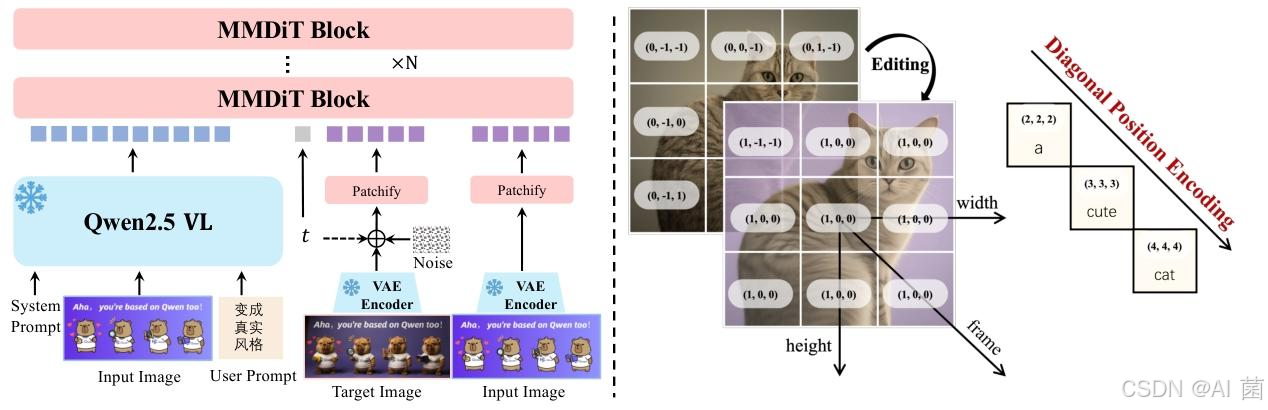
- 多模态大型语言模型(MLLM) :采用 Qwen2.5-VL 作为文本输入特征提取模块,针对 纯文本输入 和 文本 - 图像输入设计专用系统提示,输出最后一层隐藏状态作为用户输入表示。
- 变分自编码器(VAE) :采用单编码器双解码器架构,冻结 Wan-2.1-VAE 的编码器,仅微调图像解码器,通过文本丰富图像数据集训练,提升小文本和细粒度细节的重建保真度。
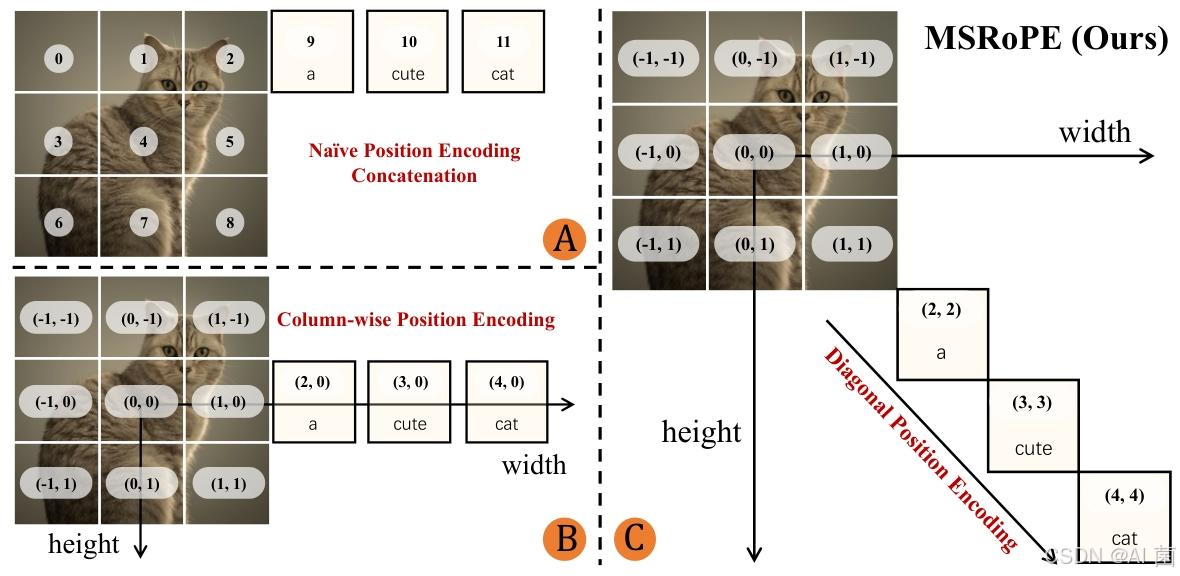
- 多模态扩散 Transformer(MMDiT):作为骨干扩散模型,引入多模态可扩展 RoPE(MSRoPE)位置编码方法,将文本视为沿图像对角线拼接的 2D 张量,同时兼顾图像分辨率缩放优势和文本 1D-RoPE 功能等价性。
3.2 数据处理
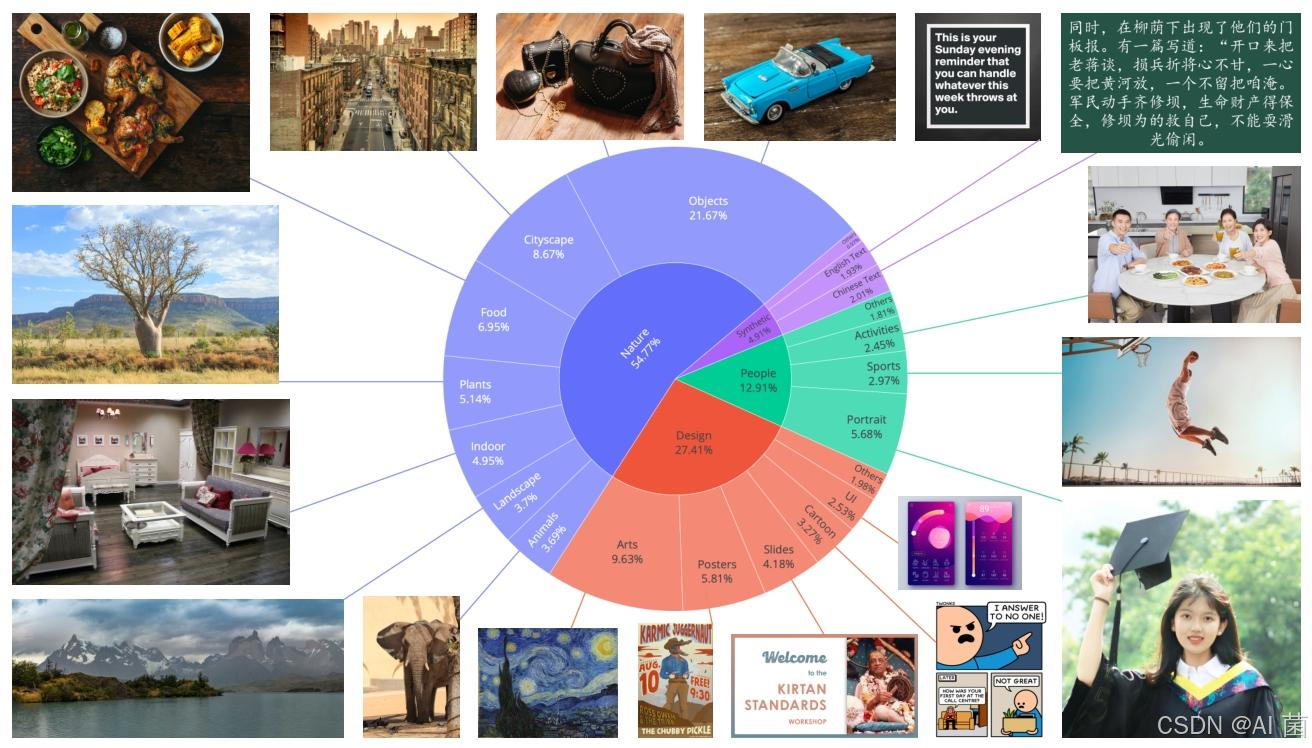
- 数据收集:构建包含自然场景、设计内容、人物相关和合成数据四大类别的数据集,分别占比 55%、27%、13% 和 5%,确保数据多样性与质量平衡。
- 数据过滤:采用七阶段过滤流水线,从初始数据筛选、图像质量增强、图文对齐优化、文本渲染增强,到高分辨率精炼、类别平衡与肖像增强、多尺度平衡训练,逐步提升数据质量。
- 数据标注:通过 Qwen2.5-VL 同时生成详细图像描述和结构化元数据,捕获对象属性、空间关系、可见文本等关键信息,结合专家规则和轻量级分类模型优化标注结果。
- 数据合成:设计纯渲染、组合渲染和复杂渲染三种策略,分别生成纯文本数据、上下文文本数据和复杂布局数据,解决文本内容稀缺与分布不平衡问题。

3.3 训练策略
- 预训练:采用流匹配训练目标,通过 ODE 实现稳定学习,设计 Producer-Consumer 框架解耦数据预处理与模型训练,采用数据并行与张量并行结合的混合并行策略,优化分布式训练效率。
- 多阶段训练:遵循从低分辨率到高分辨率(256p→640p→1328p)、从无文本到文本、从海量数据到精炼数据、从非平衡到平衡分布、从真实数据到合成数据的渐进式训练策略。
- 后训练:包含监督微调(SFT)和强化学习(RL)两个阶段,SFT 采用分层语义类别数据集和人工标注优化生成质量;RL 结合直接偏好优化(DPO)和组相对策略优化(GRPO),分别用于大规模偏好学习和细粒度微调。
- 多任务扩展:通过扩展 MSRoPE 引入帧维度,支持图像编辑、新视角合成、深度估计等多模态任务,统一纳入 TI2I 框架进行训练。
4. 实验设计
4.1 评估基准
- 通用图像生成:采用 GenEval、DPG、OneIG-Bench、TIIF 等公共基准,涵盖对象中心生成、密集提示遵循、多维度细粒度评估等场景。
- 文本渲染:使用 LongText-Bench 评估长文本渲染能力,CVTG-2K 评估英文文本渲染可读性,新增 ChineseWord 基准评估汉字渲染性能,覆盖不同难度等级的汉字集合。
- 图像编辑:基于 GEdit、ImgEdit 基准评估通用指令编辑能力,采用 GSO 数据集评估新视角合成性能,通过 NYUv2、KITTI 等五大数据集评估深度估计能力。
- 人类评估:构建 AI Arena 平台,基于 Elo 评分系统,通过 5000 个多样化提示和 200 余名专业评估者的 pairwise 比较,评估模型与主流闭源 API 的综合性能。
4.2 对比模型
选取当前主流的图像生成与编辑模型作为对比对象,包括闭源模型 Imagen 4 Ultra Preview 0606、Seedream 3.0、GPT Image 1 High、FLUX.1 Kontext Pro、Ideogram 3.0 等,以及开源模型 SD v1.5、SDXL、PixArt-α、Hunyuan-DiT 等,覆盖不同参数规模和技术路线。
4.3 评估指标
- 定量指标:包括 PSNR(峰值信噪比)、SSIM(结构相似性指数)用于评估重建质量;Word Accuracy、NED、CLIPScore 用于文本渲染准确性;Semantic Consistency(SQ)、Perceptual Quality(PQ)用于图像编辑评估;以及各基准自带的专项评估指标。
- 定性指标:通过视觉对比分析文本渲染的准确性、布局合理性、字体一致性,图像编辑的目标区域修改精度、背景保留效果、语义连贯性等。
5. 实验分析
5.1 人类评估结果
在 AI Arena 平台的评估中,Qwen-Image 作为唯一开源模型排名第三,虽落后于 Imagen 4 Ultra Preview 0606 约 30 个 Elo 点,但较 GPT Image 1 High、FLUX.1 Kontext Pro 等模型领先超过 30 个 Elo 点,证明其在通用图像生成能力上已达到闭源模型水平。
5.2 定量结果分析
- VAE 重建:Qwen-Image-VAE 在 ImageNet-256x256 和文本丰富图像数据集上均实现 SOTA 性能,PSNR 分别达到 33.42 和 36.63,SSIM 分别为 0.9159 和 0.9839,且仅激活 19M 编码器参数和 25M 解码器参数,兼顾重建质量与计算效率。
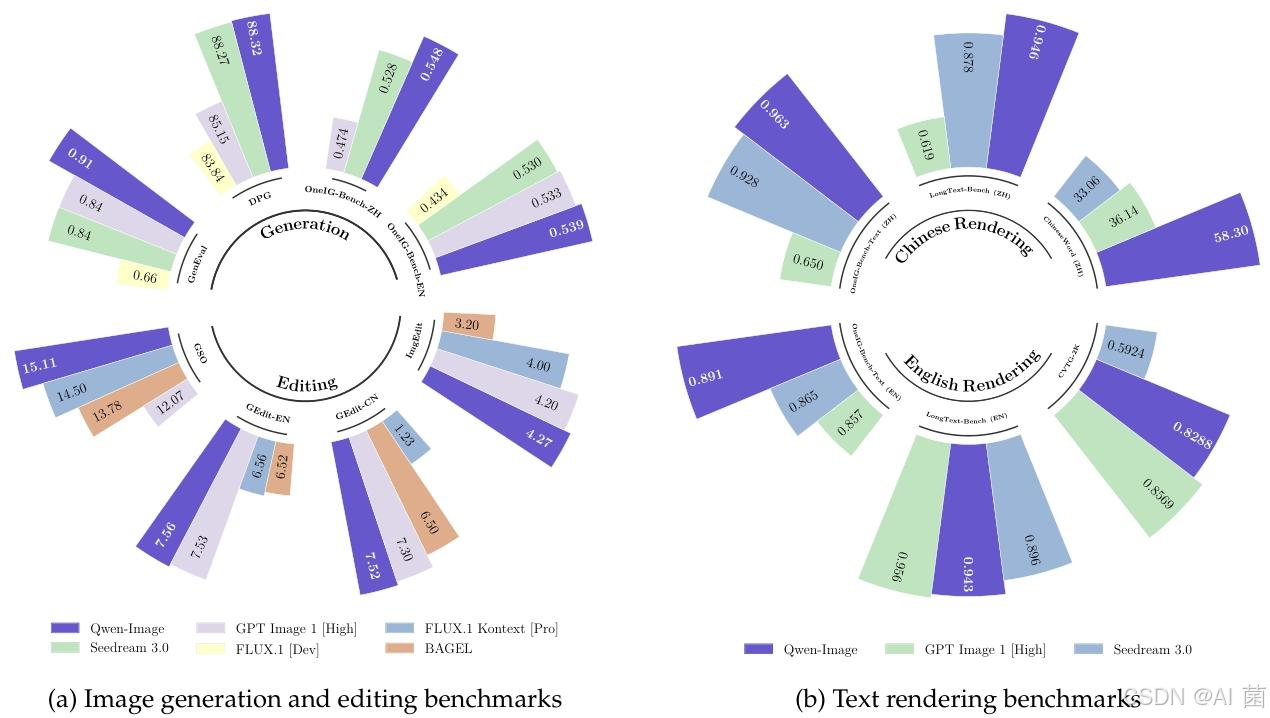
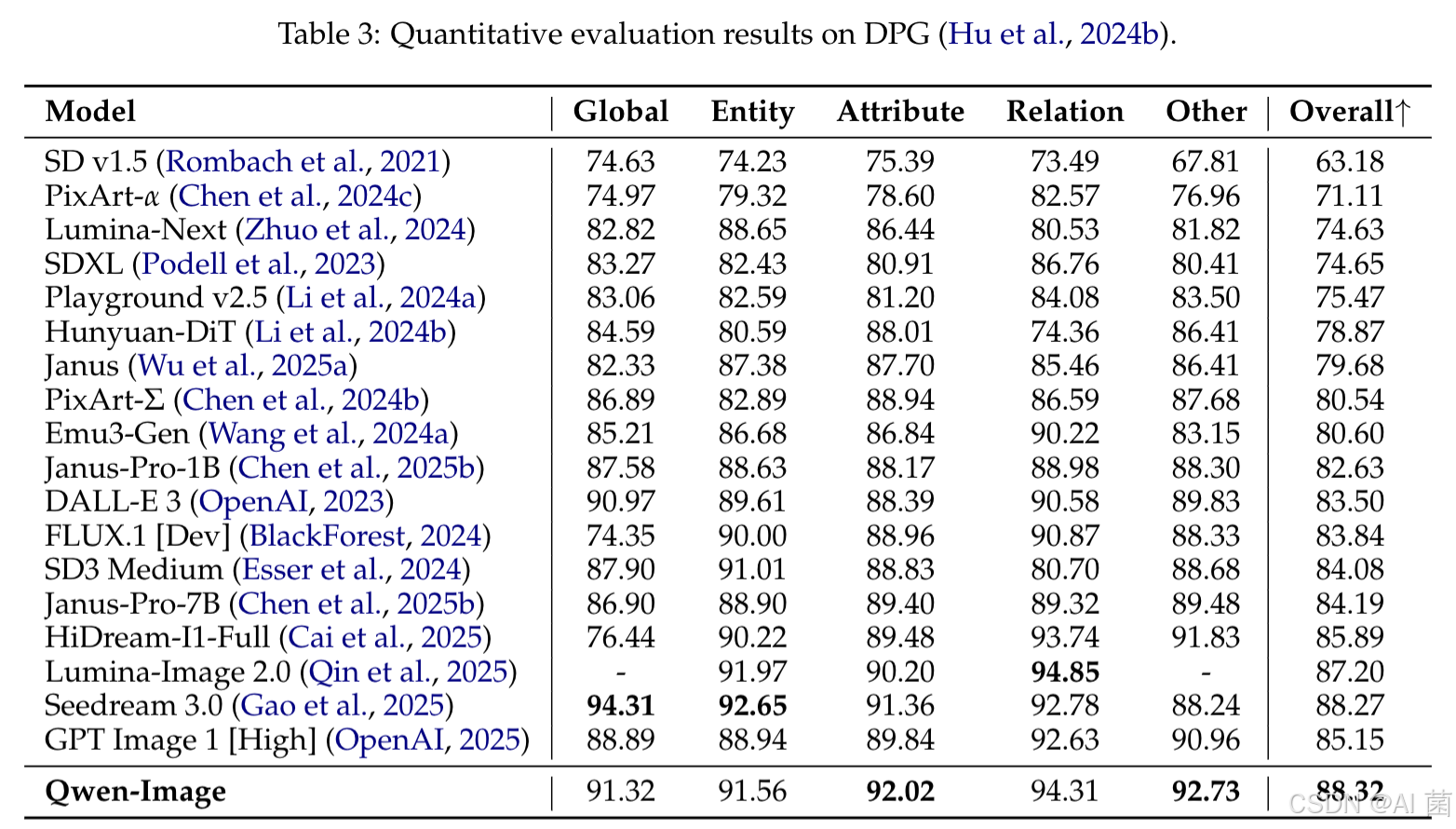
- 文本到图像生成:在 DPG 基准中取得 88.32 的总体得分,位列第一;GenEval 基准中 RL 增强模型达到 0.91 的总体得分,突破 0.9 阈值;OneIG-Bench 的中英文赛道均排名第一,尤其在对齐度和文本类别中表现突出;ChineseWord 基准中,Level-1、Level-2、Level-3 汉字渲染准确率分别达到 97.29%、40.53%、6.48%,总体准确率 58.30%,大幅领先对比模型;LongText-Bench 中中文长文本渲染准确率排名第一,英文排名第二。
- 图像编辑:GEdit-Bench 的中英文榜单均排名第一,G_O 得分分别为 7.56 和 7.52;ImgEdit 基准总体得分 4.27,位列第一;新视角合成在 GSO 数据集上 PSNR 达 15.11、SSIM 达 0.884、LPIPS 达 0.153,深度估计在多个数据集上达到扩散模型中的 SOTA 性能。
5.3 定性结果分析
- 文本渲染:Qwen-Image 能准确渲染长英文段落和复杂中文对联,避免字符缺失、错误或重复,支持多位置、多布局的文本生成,在幻灯片、海报等场景中实现合理的文本布局与视觉美学平衡。
- 图像生成:在多对象生成任务中能准确还原指定对象、位置和风格;在空间关系生成中精准捕捉人物与对象间的交互关系,符合文本提示要求。
- 图像编辑:文本与材质编辑中能保持原始风格并准确修改文本内容,成功呈现指定材质效果;对象增删改任务中保持未修改区域的一致性与风格对齐;姿态操控中保留头发丝等细细节,维持背景与人物特征一致性;链式编辑和新视角合成任务中展现出优异的语义连贯性与空间一致性。

6. 总结
Qwen-Image 通过全面的数据工程优化、渐进式课程学习策略、增强型多任务训练范式和高效的分布式训练架构,在复杂文本渲染和精准图像编辑两大核心任务上实现显著突破。该模型不仅支持多语言、多布局的高保真文本渲染,尤其在中文文本生成方面表现突出,还能在图像编辑中平衡语义连贯性与视觉一致性,同时具备强大的通用图像生成能力。
实验结果表明,Qwen-Image 在多个公共基准测试中均达到 SOTA 性能,验证了其技术鲁棒性与广泛适用性。作为图像生成模型,它重新定义了生成建模的优先级,强调文本与图像的精准对齐;作为图像理解模型,证明了生成式框架在经典理解任务中的有效性;作为跨模态模型,展现了在 3D 和视频生成领域的泛化潜力,为视觉 - 语言全场景系统的发展奠定了基础。