【进程创建 + 进程终止】目录
- 前言:
- ---------------进程创建---------------
-
- [1. 深挖系统调用fork!!!](#1. 深挖系统调用fork!!!)
- [2. 写时拷贝是怎么触发的?](#2. 写时拷贝是怎么触发的?)
- [3. 系统调用fork的常规用法有哪些?](#3. 系统调用fork的常规用法有哪些?)
- [4. fork调用失败的原因是什么?](#4. fork调用失败的原因是什么?)
- ---------------进程终止---------------
-
- [1. 进程终止了都干些什么?](#1. 进程终止了都干些什么?)
- [2. 进程的退出场景有哪些?](#2. 进程的退出场景有哪些?)
- [3. main函数的返回值有什么用?](#3. main函数的返回值有什么用?)
- [4. 如何查看退出码?](#4. 如何查看退出码?)
- [5. 为什么main函数的返回值是进程的退出码?](#5. 为什么main函数的返回值是进程的退出码?)
- [6. 进程的退出码有哪些?](#6. 进程的退出码有哪些?)
- [7. 细说进程退出的第三种情况 ------ 异常退出!!!](#7. 细说进程退出的第三种情况 —— 异常退出!!!)
- [8. 进程常见的退出方法有哪些?](#8. 进程常见的退出方法有哪些?)

往期《Linux系统编程》回顾:/------------ 入门基础 ------------/
【Linux的前世今生】
【Linux的环境搭建】
【Linux基础 理论+命令】(上)
【Linux基础 理论+命令】(下)
【权限管理】/------------ 开发工具 ------------/
【软件包管理器 + 代码编辑器】
【编译器 + 自动化构建器】
【版本控制器 + 调试器】
【实战:倒计时 + 进度条】/------------ 系统导论 ------------/
【冯诺依曼体系结构 + 操作系统基本概述】/------------ 进程基础 ------------/
【进程入门】
【进程状态】
【进程优先级】
【进程切换 + 进程调度】
前言:
hi ~,小伙伴们大家好久不见呀!(ノ≧∀≦)ノ
- 嗯 ~ o( ̄▽ ̄)o这次是真的好久不见了!鼠鼠这里估摸了一下,停更居然已经有 29 天了,几乎是一个月了,一转眼的时间一个月就这么过去了,且行且珍惜吧~(。・ω・。)
- 鼠鼠今天也是刚考完了试,而且 2025 年也马上就要结束啦!所以在离校前,鼠鼠决定先将《Linux系统编程》的第一座大山------进程,完结掉,毕竟就算是鼠鼠,做事也要有始有终嘛~
所以接下来,鼠鼠会连发三篇关于 【进程控制】 的内容,作为送给大家的 2025 年最后的告别吧(。・ω・。)ノ♡
| --------------- 2025 年 12 月 30 日(冬月十一)周二,冬二九 |
|---|
好了,我们开始学习今天的内容 【进程创建 + 进程终止】 吧,这部分内容是进程控制的入门关键🔑,也是彻底打通进程知识闭环的重要一环,核心内容剧透如下:(~ ̄▽ ̄)~
进程创建:我们会重点学习 Linux 中创建进程的核心函数 fork(),搞懂它的工作原理 ,对于进程的创建之前我们已经详细的介绍过了,这里我们将会深挖fork()并解答一些底层核心的问题💡(o゚▽゚)o进程终止:包括进程正常终止的几种方式(main 函数返回、调用 exit () 函数、调用 _exit () 函数)及其区别,以有趣的故事循序渐进的从原理层面搞懂进程终止的本质,以及其与main函数的关系( ̄▽ ̄)~■□~( ̄▽ ̄)这两个知识点是后续学习进程等待、进程替换的基础,掌握它们,你就能真正手动控制进程的生老病死,彻底搞定进程模块的核心操作啦!(੭ु ›ω‹ )੭ु⁾⁾
---------------进程创建---------------
1. 深挖系统调用fork!!!
在 Linux 系统里,
fork是非常关键的系统调用,它能从已存在的进程中创建出一个新进程。
- 新创建的进程被称为子进程,而原来的进程就是父进程
在刚开始学习进程相关知识时,我们首先掌握的就是通过系统调用
fork来创建进程的方法。关于
fork的使用方式 ------ 包括其函数调用、返回值特性等基础内容,我们之前已经进行过详细讲解,因此这里不再赘述。
当进程调用
fork函数后,控制会转移到内核中的fork相关代码,此时内核会执行以下操作:
- 为子进程 分配新的内存块 以及对应的内核数据结构
- 将父进程的部分数据结构内容拷贝到子进程中
- 把新创建的子进程 添加到系统的进程列表里
- 完成 fork 相关的内核操作后,fork 函数返回,随后系统的调度器会进行进程调度,决定后续是父进程还是子进程先继续运行
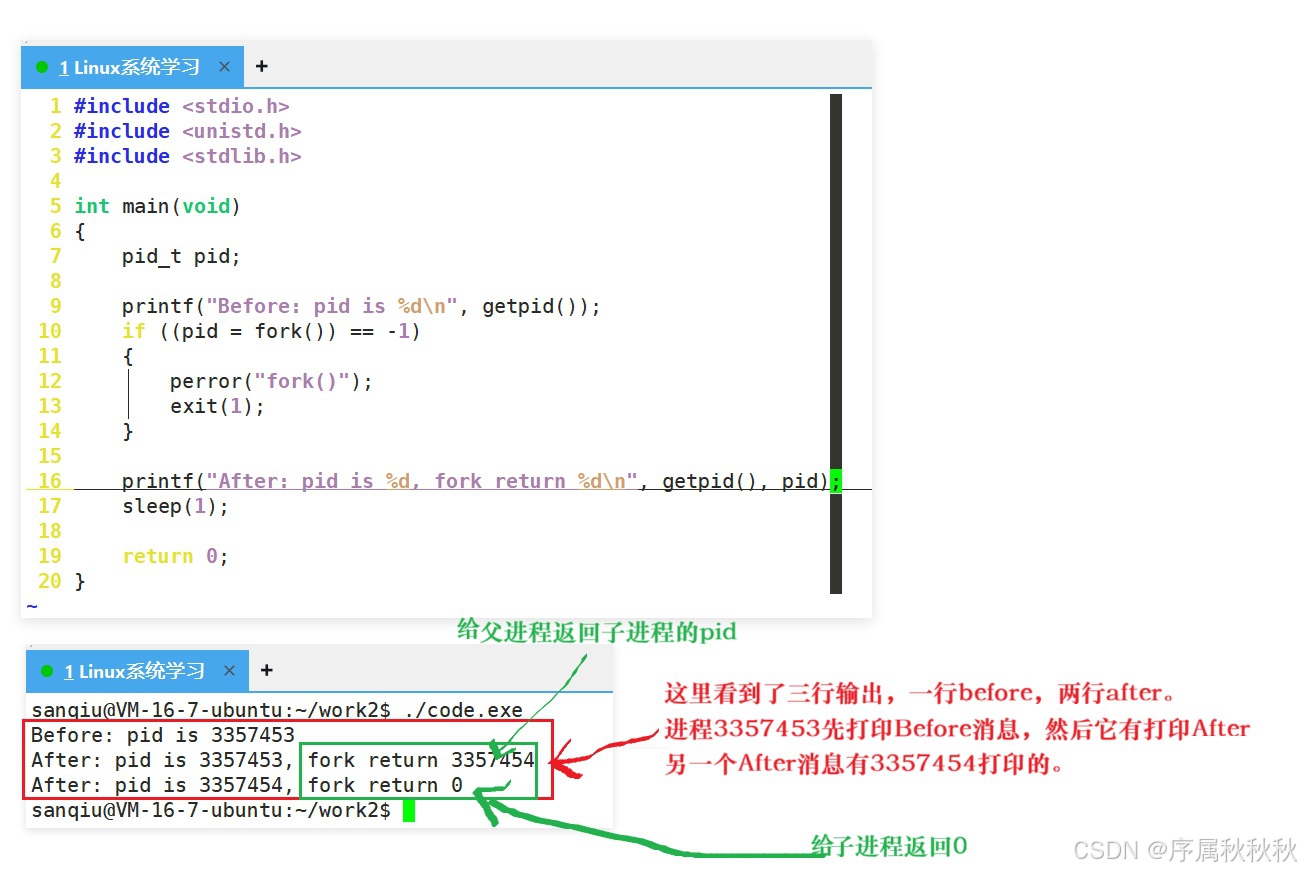
注意:调用fork()前后最大的区别就是会创建了一个子进程。
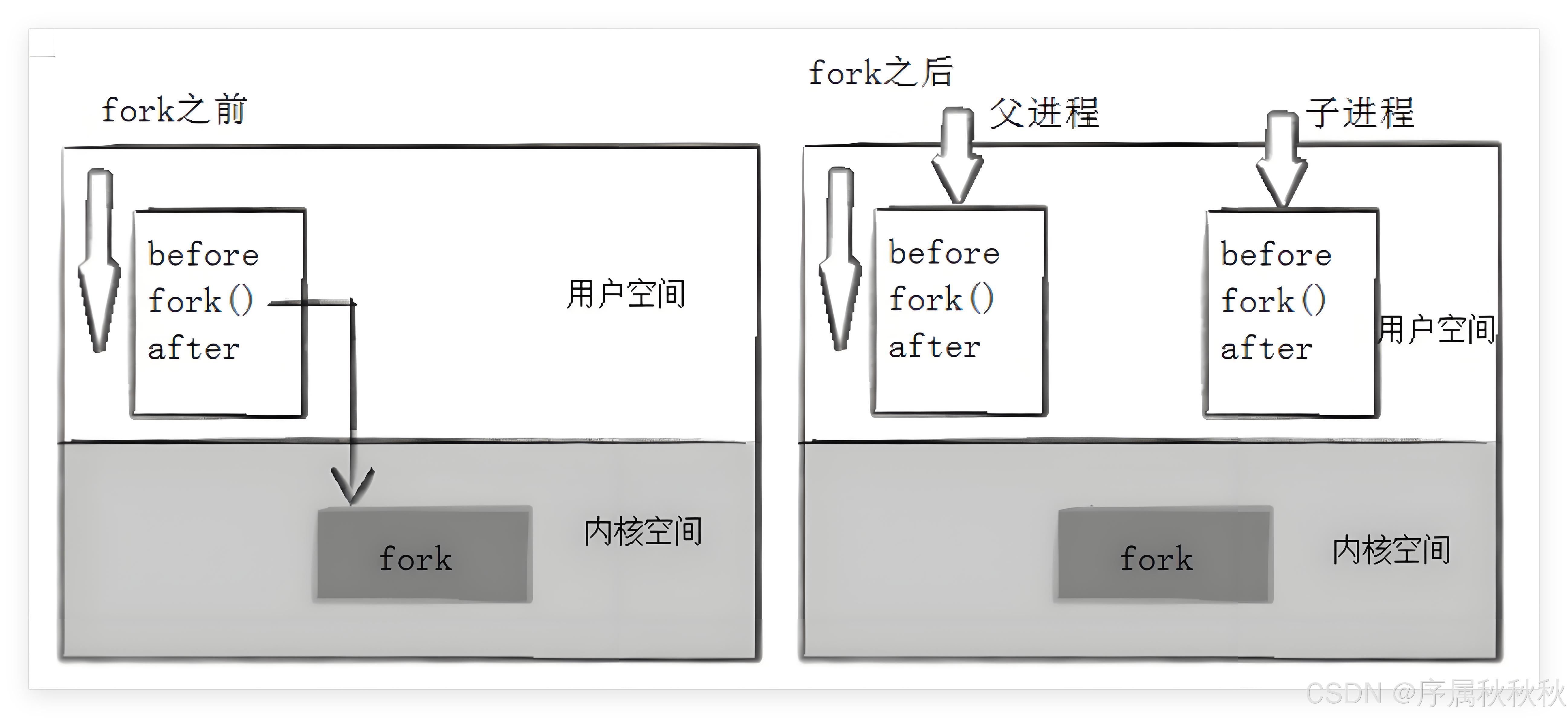
注意:子进程3357454没有打印Before,为什么呢?请看下面图示中的内容。
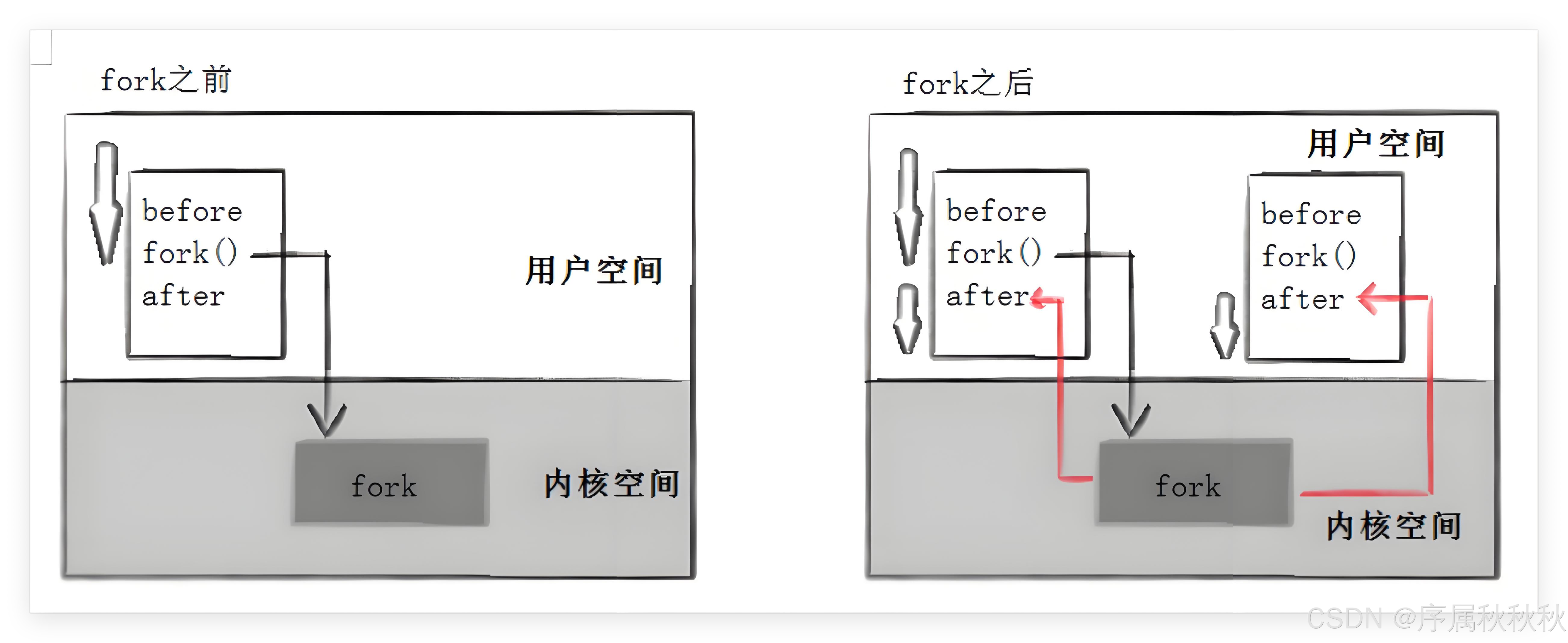
2. 写时拷贝是怎么触发的?
父进程拥有自己的数据段、代码段等内存区域,这些区域会通过父进程的页表,映射到物理内存的相应位置。
当创建子进程时,子进程会拷贝父进程的进程控制块(
task_struct)以及页表。此时,父进程和子进程的这些核心数据结构是相同的。
我们知道,页表中不仅存储着虚拟地址与物理地址的映射关系,还包含一个权限字段
- 通常,虚拟地址空间里代码段在页表中的权限被设置为 "只读" ,而数据段的权限是 "可读可写"
- 但当父进程创建子进程后,操作系统会把父进程数据段 在页表中的权限临时设置为 "只读"
- 要是后续子进程尝试对数据段进行写入修改操作,操作系统会先进行判断:
- 一方面:会确认该数据对应的虚拟地址与物理地址是存在且合法的
- 另一方面:会检查子进程的操作意图是访问数据段
这时,操作系统就会触发 写时拷贝(Copy-On-Write,COW) 机制。
简单来说:操作系统通过将数据段的权限设为 "只读",让子进程的写入操作失败,以此来触发写时拷贝流程。
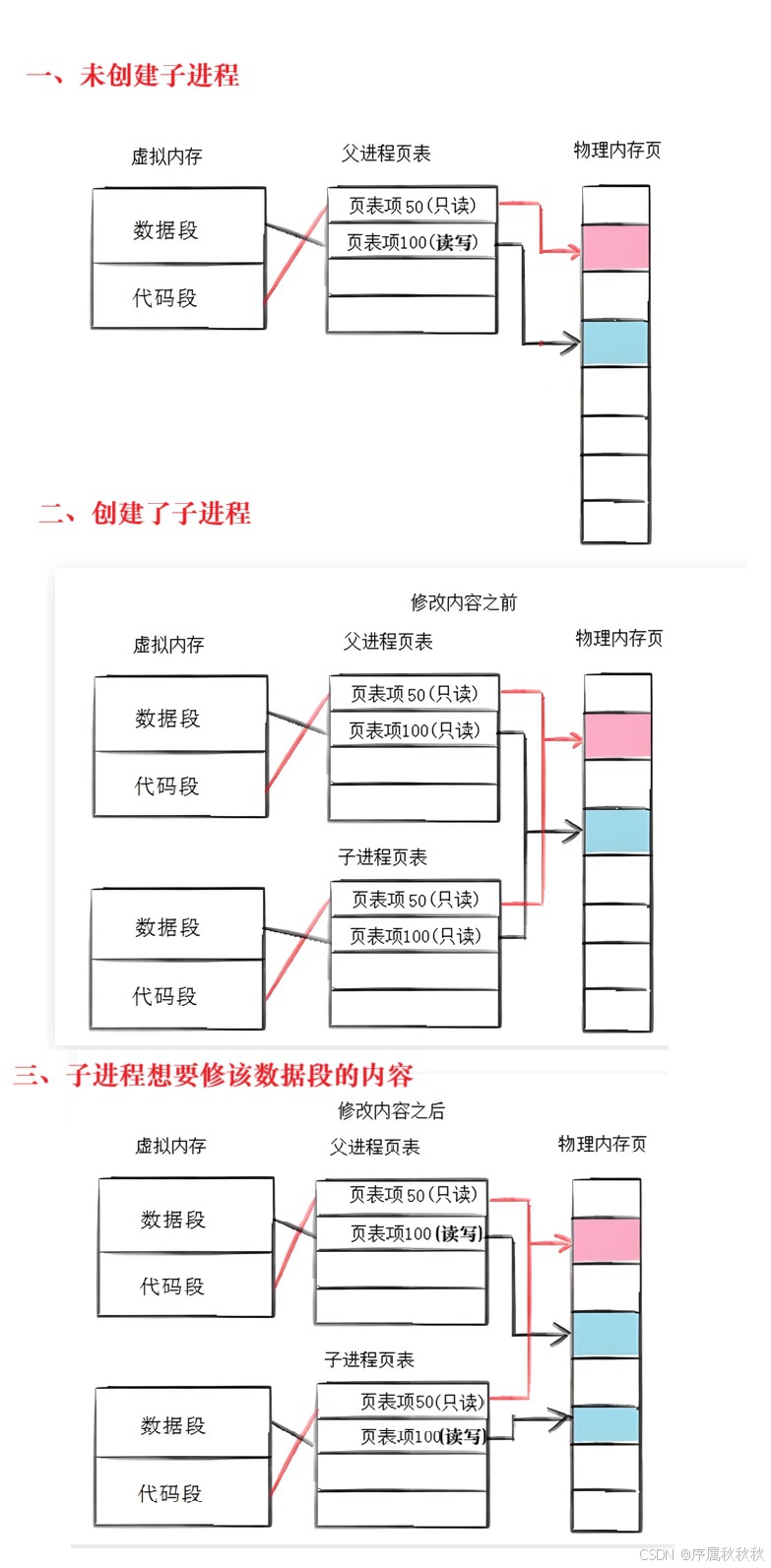
总结一下,子进程查询页表时,可能会遇到以下几种典型情况:
- 第一种情况:子进程根本查不到与该虚拟地址对应的物理地址,这意味着该虚拟地址尚未在物理内存中分配映射。
- 第二种情况:触发缺页中断。
- 缺页中断最常见的情形是,子进程要访问的虚拟地址对应的物理内容不在内存中
- 还有一种情况是,物理内容虽在内存中,但页表中该区域的权限为 "只读",而子进程进行了写入等不符合权限的操作
3. 系统调用fork的常规用法有哪些?
创建子进程的核心目的,往往是希望它能协助完成特定任务。
从实际应用场景来看,创建子进程主要有两种典型方式:
- 第一种方式是:让子进程与父进程协同执行同一程序的不同部分。
- 具体来说,父进程通过
fork创建子进程后,利用fork返回值的特性(父进程得到子进程 PID,子进程得到 0),通过if-else分支结构实现代码分流 ------ 比如:让父进程继续处理主线任务,而子进程则执行辅助性工作(如:数据计算、日志记录等)- 这种方式下,父子进程共享同一程序代码(因为代码段在页表中标记为只读,可安全共享),但通过条件判断各自执行不同的逻辑分支,实现 "分工协作"
- 第二种方式则是:让子进程执行一个全新的程序。
- 这种场景更常见于需要启动外部程序的情况:父进程创建子进程后,子进程会通过 exec 系列函数 (如:execl、execvp 等)加载并执行另一个可执行文件 ------ 此时子进程的虚拟地址空间会被新程序的代码段、数据段等覆盖,完全切换到新程序的运行逻辑
- 例如在 Shell 中输入命令时,Shell 进程(父进程)会
fork一个子进程,然后子进程通过exec加载并执行命令对应的程序(如:ls、cat等),这就是典型的 "创建子进程执行全新程序" 的场景这两种方式的本质区别在于:前者是 "同一程序内的分工",后者是 "启动全新程序的载体",但核心都是通过子进程的独立性,实现任务的并行处理或环境隔离。
4. fork调用失败的原因是什么?
我们先来思考调用
fork的核心目的:本质上是创建一个新的子进程,也就是完成 "进程创建" 的过程。而我们已经知道,进程的核心构成是 "PCB(进程控制块,
task_struct)+ 代码与数据"------ 前者是描述进程的元数据,后者是进程运行的实体内容。
由此可知,
fork调用失败的原因,本质上可归结为 "无法完整构建新进程的构成要素",具体分为两类:
- 内核数据结构创建失败:
- 创建子进程时,内核需要为其分配新的
task_struct(PCB)、mm_struct(虚拟地址空间描述符)以及页表等核心数据结构- 如果此时系统内存已极度紧张,无法为这些内核对象分配物理内存,
fork就会失败- 代码与数据映射失败:
- 虽然
fork采用 "写时拷贝" 机制,不会立即拷贝父进程的全部数据,但仍需为子进程建立与父进程共享的虚拟地址映射- 若因内存碎片过多或特殊内存限制,导致无法完成基础映射 setup,也会导致失败
简单来说 :fork 失败最常见的底层原因是系统内存资源不足,但在现代操作系统中,这种情况其实很少见 ------ 因为系统会通过虚拟内存、进程调度等机制提前规避极端内存不足的场景。
更常见的失败原因,其实是操作系统的进程数量限制:
- 为了避免进程无限制创建导致系统资源耗尽(如:过多进程占用 CPU 调度资源、耗尽进程 ID 等),操作系统会设置
全局的"最大进程数"限制(如:Linux 中的pid_max参数)- 同时也会
限制单个用户能创建的进程数量(如:通过ulimit配置)当系统或用户创建的进程数超过这些限制时,即便内存充足,
fork也会失败,返回-1
---------------进程终止---------------
1. 进程终止了都干些什么?
结合之前对进程创建的理解,我们已经知道:
创建一个进程,本质是操作系统为其新增了一套核心
"身份与资源标识"------ 包括独立的 PCB(task_struct)、虚拟地址空间(mm_struct)、页表,以及后续加载程序时对应的代码和数据(通过页表映射到物理内存)那么反过来,进程终止的核心逻辑,就是操作系统 "回收这些专属资源" 的过程------ 毕竟终止与创建本就是一对逆操作。
当一个进程完成任务或因异常退出时,操作系统会启动终止流程,核心是
清除该进程在系统中的所有 "痕迹",具体包括:
- 回收内存管理相关资源:
- 首先会销毁进程的虚拟地址空间描述符(
mm_struct),并清空对应的页表,解除虚拟地址与物理内存的映射关系- 随后若该进程的代码和数据在物理内存中没有其他进程共享(比如:未触发写时复制的私有数据,或已执行
exec加载的全新程序),操作系统会将这些物理内存页标记为 "空闲",供其他进程复用- 清理进程控制相关数据:回收进程的 PCB(
task_struct)中关联的各类资源,比如打开的文件描述符、占用的信号量、申请的 IPC 资源等,确保这些系统资源不会因进程终止而泄露
看到这里,可能有小伙伴会问:"之前学过的'僵尸进程',不也是进程终止后的一种状态吗?这和上面说的 "回收资源'有冲突吗?"
这里需要明确一点:僵尸状态是进程终止流程中的一个 "特殊中间态",而非完整的终止状态。
- 正常情况下,进程终止后会彻底释放所有资源(包括 PCB)
- 但僵尸进程的特殊之处在于:它的 "核心任务已完成"(代码和数据已释放、虚拟地址空间和页表已销毁),但PCB 并未被立即回收
- 因为 PCB 中还存储着进程的退出状态码(如:退出原因、返回值),操作系统需要保留这份信息,等待父进程通过
wait()或waitpid()系统调用读取- 只有当父进程读取了退出状态后,操作系统才会最终销毁僵尸进程的 PCB,完成整个终止流程
简言之:进程终止的终极目标是 "彻底清除进程的所有系统资源",而僵尸状态只是 "为传递退出信息而暂时保留 PCB" 的过渡状态,其本质是终止流程未完成的体现,而非与终止无关的独立状态。
2. 进程的退出场景有哪些?
首先我们需要明确:进程的退出并非只有 "正常结束" 这一种情况,结合实际运行场景,其退出可归纳为以下三类核心场景:
1. 代码运行完毕,结果正确(正常退出)
这种场景下,进程完整执行了预设的业务逻辑,且达到了预期目标,随后主动结束运行。
- 例如你编写的程序需要打开一个日志文件,并向其中写入 100 条字符串记录
- 程序成功完成文件打开、数据写入、资源清理(如:关闭文件描述符)等所有步骤,最终通过
return 0(主函数)或exit(0)(任意位置)等方式主动退出 ------ 这就是典型的 "结果正确的正常退出",进程的退出状态码通常为0(表示执行成功)
2. 代码运行完毕,结果不正确(异常路径退出)
这类场景中,进程的代码逻辑虽已完整执行(未中途中断),但未达成预期目标,最终通过 "异常处理路径" 退出。
- 仍以 "写文件" 为例:若程序尝试打开目标文件时,因 "文件不存在"、"权限不足" 等原因导致打开失败,此时程序会触发预设的异常处理逻辑(如:通过
if分支判断open()函数的返回值,打印错误信息后执行退出操作)- 虽然代码从头到尾跑完了,但核心任务(写文件)未完成,属于 "结果不正确的退出",进程的退出状态码通常为非
0值(如:1、2等,可用于标识具体错误类型)
3. 代码未运行完毕,异常终止(强制中断退出)
这种场景下,进程的代码逻辑未执行完成,就因外部干预或内部错误被强制终止。
常见原因包括:
- 内部错误触发:如程序访问野指针、数组越界、除零操作等,会触发操作系统的信号(如:Linux 下的
SIGSEGV段错误信号),导致进程直接终止- 外部信号干预:如用户通过
Ctrl+C发送SIGINT信号、其他进程通过kill命令发送终止信号(如:SIGKILL),进程会在收到信号后立即停止运行,代码执行流程被强行打断这类退出属于 "非预期终止",进程往往来不及执行资源清理逻辑,退出状态码由信号类型决定(而非程序主动设置)
综上 :进程的退出本质是 "运行生命周期的终结",但终结的原因、代码执行的完整性、结果的正确性,共同构成了上述三类不同的退出场景
3. main函数的返回值有什么用?
首先我们需要明确:
main函数作为程序的入口,其返回值并非毫无意义 ------ 它本质上是程序向操作系统传递 "执行结果状态" 的重要方式。具体来说,
main函数返回0或非0的值,对应着我们之前提到的两类 "代码运行完毕" 的进程退出场景:
- 当程序完整执行了所有逻辑且达成预期目标(即 "代码运行完毕,结果正确")时,
main函数通常返回0,以此告知操作系统 "本次执行成功"- 当程序虽执行完所有代码,但核心任务未完成(即 "代码运行完毕,结果错误")时,
main函数会返回一个非0的值(如:1、2等),这些值可用于区分具体的错误类型,让操作系统或父进程知晓执行失败的大致原因从底层实现来看,main 函数的返回值是通过 CPU 寄存器 传递的。
具体过程可简单理解为:
- 当程序执行到 return 语句时(如:
return 0;或return 1;),编译器会将返回值写入一个特定的寄存器(例如:x86 架构中的eax寄存器,ARM 架构中的r0寄存器)- 当 main 函数执行完毕后,操作系统会读取该寄存器中的值,并将其作为进程的 "退出状态码" 保存起来(存储在进程的 PCB 中),供父进程通过 wait() 等系统调用获取
本质上,这一过程对应的汇编指令就是两条
move操作:
- 第一条:将返回值从内存(变量或常量)移动到寄存器
- 第二条:则由操作系统将寄存器中的值移动到存储进程状态的内存区域(如:PCB 的特定字段)
这种通过寄存器传递返回值的设计,既高效又统一,成为了程序与操作系统之间传递执行状态的标准机制。
小故事:被关心的失败者
为什么程序运行完毕但结果不正确时,退出码要用非 0 值呢?
这背后其实蕴含着一种 "关注异常" 的设计逻辑 ------ 就像现实生活中,人们往往对 "符合预期的常态" 习以为常,却会格外留意 "偏离预期的异常"。
举个生活中的例子:
- 如果一个学生每次考试都能稳定拿到 100 分(满分),家长通常不会特意追问 "为什么又考了 100 分"------ 因为这符合 "优秀" 的预期
- 但如果这个学生某次只考了 20 分,家长一定会立刻追问 "为什么考得这么差"问题出在哪里
程序的退出码设计也是同理:
- 用
0表示 "运行完毕且结果正确",就像 "考了 100 分"------ 这是最理想的预期状态,无需额外解释- 而当程序运行完毕但结果不正确时(比如 :任务未完成、参数错误、资源获取失败等),我们需要用非 0 值作为退出码 ------ 这就像 "考了 20 分",本质是在传递 "异常信息"
更重要的是,非 0 值有很多可能(1、2、3...... 甚至更大的整数),这就为 "区分具体错误原因" 提供了空间:操作系统或父进程可以通过不同的非 0 退出码,判断程序失败的类型。
例如,在很多程序中:
1可能表示 "通用错误"2可能表示 "参数输入错误"3可能表示 "文件不存在"- 以此类推
这种设计让程序的错误信息传递更精准 ------ 就像学生成绩单上的具体分数能反映知识掌握的薄弱点一样,不同的非 0 退出码能帮助开发者或系统快速定位问题所在,这正是用非 0 值表示 "运行完毕但结果不正确" 的核心原因。
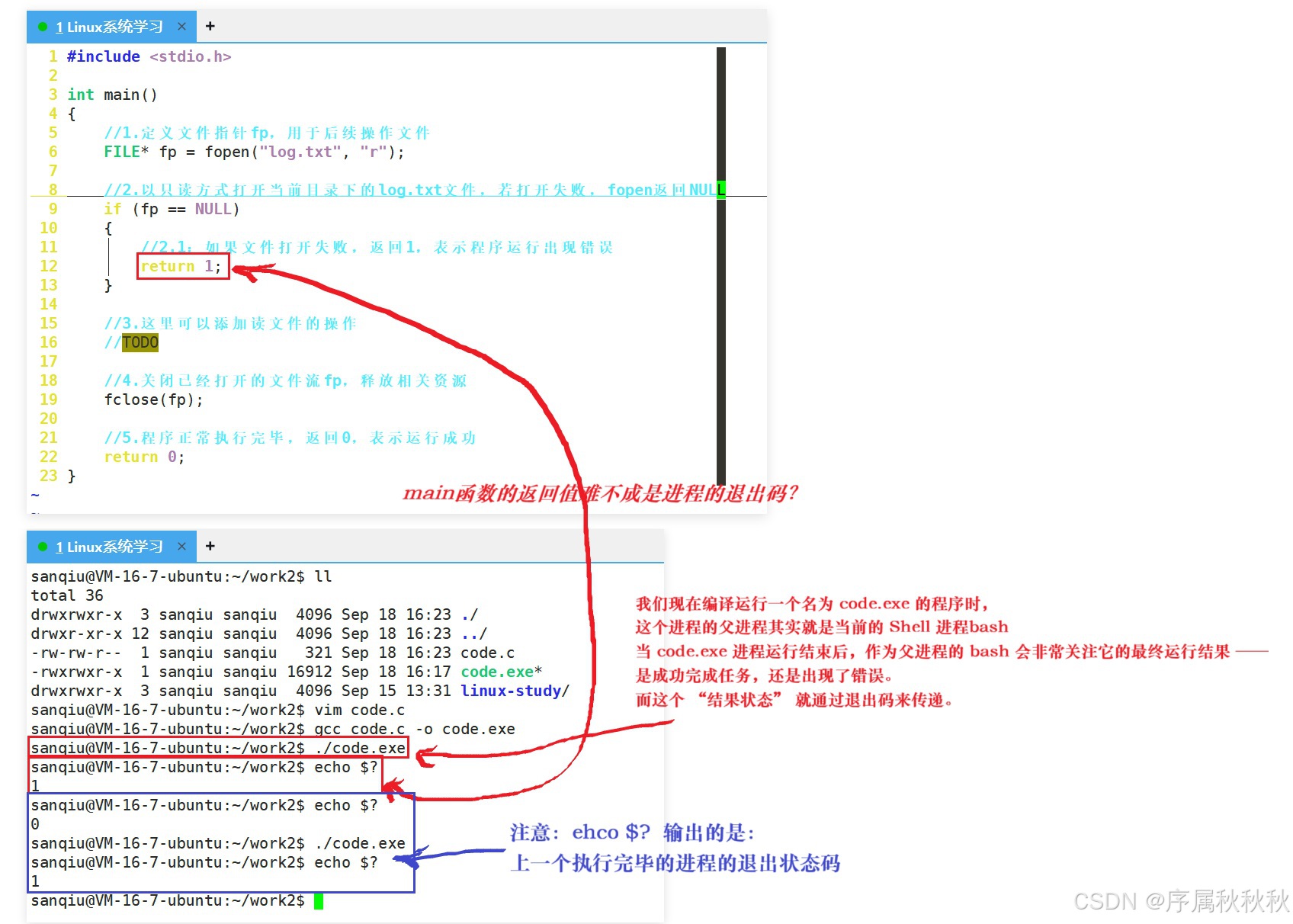
4. 如何查看退出码?
可能有小伙伴会问:"我们平时并没有直接看到这个退出码啊,它到底存在哪里呢?"
其实,在 Shell 环境中,我们可以通过一个特殊的命令来查看它 ------ 输入 echo $? 即可打印出最近一个前台进程的退出码
例如:当
./proc运行结束后,立即执行echo $?,终端就会显示它的退出码:
- 如果返回
0,说明程序正常运行且结果正确- 如果返回非
0值(如:1、2等),则表示程序运行过程中出现了特定错误这个 $? 是 Shell 中的一个特殊变量,专门用于存储 "上一个执行完毕的进程的退出状态码" ,因此也常被称为 "进程退出码变量"
通过它,父进程(如:
bash)可以获取子进程的执行结果,我们也能据此判断程序的运行状态,这在脚本编写或程序调试中是非常实用的技巧。
5. 为什么main函数的返回值是进程的退出码?
当进程即将退出时:
- main 函数的返回值会被写入该进程的**进程控制块(PCB,即 task_struct)**中
- 在 Linux 系统的 task_struct 里存在一个整型变量 exit_code,用于存储进程的退出码
这个设计使得进程的退出状态有了 "实体载体",可以被系统或其他进程查询。
这也就解释了为什么我们通过
echo $?就能获取上一个进程的退出码:
$?是 Shell 维护的一个特殊变量,它会在每个前台进程退出后,自动从该进程的task_struct中读取exit_code并存储起来- 当我们执行
echo $?时,本质上就是打印这个变量中保存的 "上一个进程的退出码"
综上所述:
- main 函数的返回值与进程的退出码是完全对应的 ------main 函数的返回值最终会成为进程的退出码
- 并通过 PCB 中的
exit_code字段被系统记录和传递,这是程序与操作系统、进程与进程之间传递执行状态的核心机制
6. 进程的退出码有哪些?
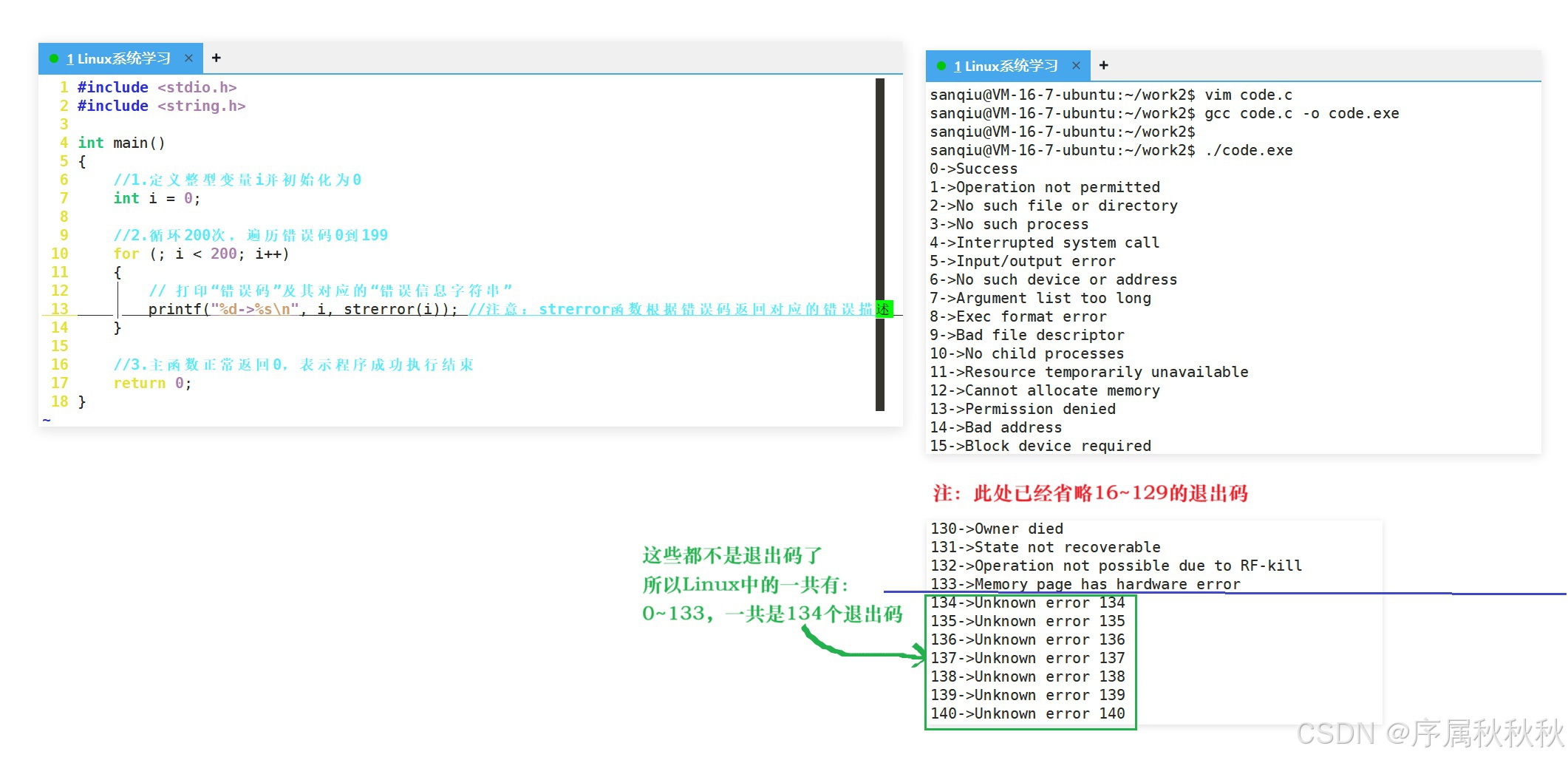
好了,现在我们已经了解了 Linux 中进程退出码的基本概念和底层原理。
那么在平时的编程实践中,我们具体该如何使用它呢?
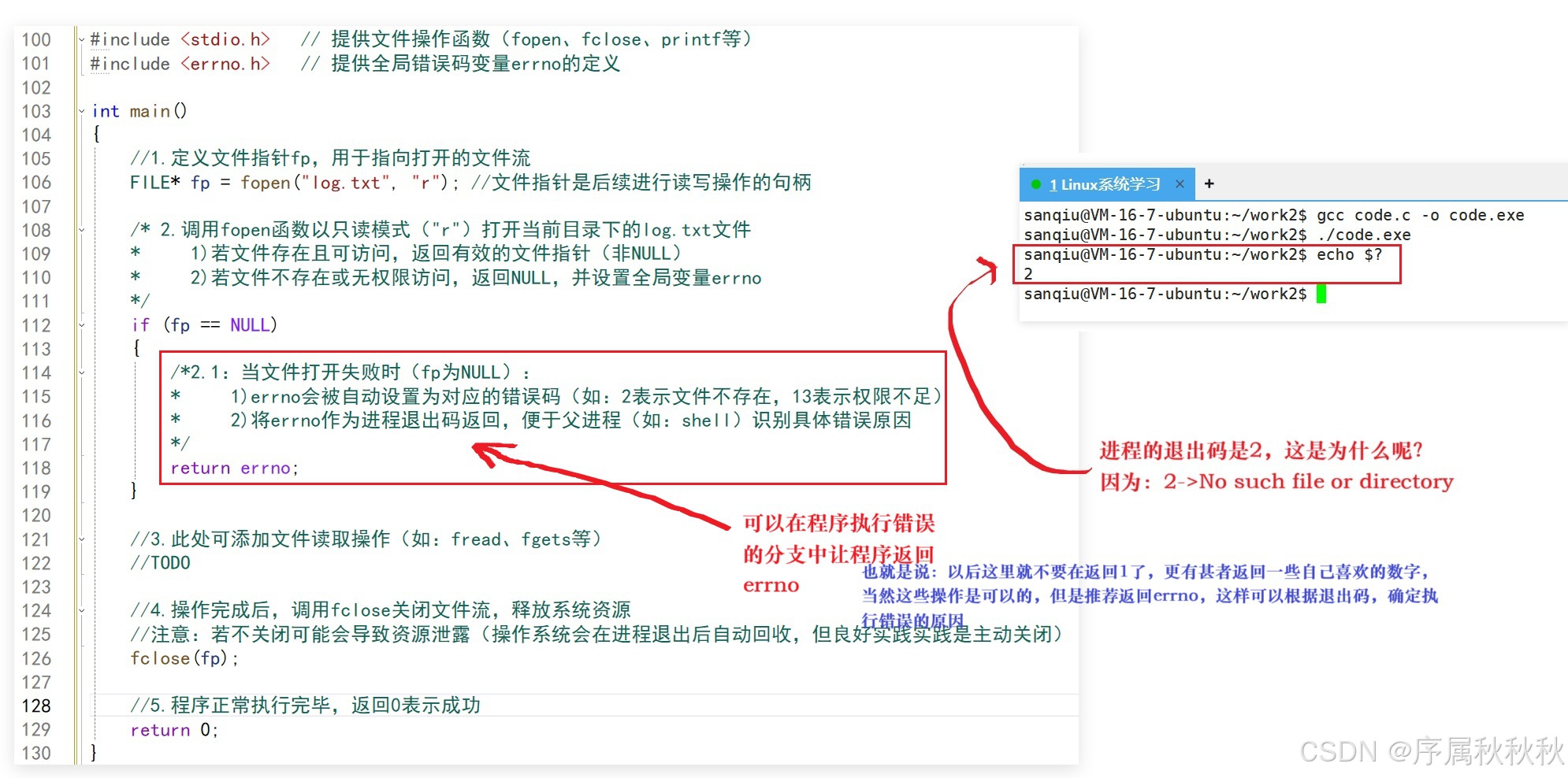
cpp
#include <stdio.h> // 提供文件操作函数(fopen、fclose、printf等)
#include <errno.h> // 提供全局错误码变量errno的定义
int main()
{
//1.定义文件指针fp,用于指向打开的文件流
FILE* fp = fopen("log.txt", "r"); //文件指针是后续进行读写操作的句柄
/* 2.调用fopen函数以只读模式("r")打开当前目录下的log.txt文件
* 1)若文件存在且可访问,返回有效的文件指针(非NULL)
* 2)若文件不存在或无权限访问,返回NULL,并设置全局变量errno
*/
if (fp == NULL)
{
/*2.1:当文件打开失败时(fp为NULL):
* 1)errno会被自动设置为对应的错误码(如:2表示文件不存在,13表示权限不足)
* 2)将errno作为进程退出码返回,便于父进程(如:shell)识别具体错误原因
*/
return errno;
}
//3.此处可添加文件读取操作(如:fread、fgets等)
//TODO
//4.操作完成后,调用fclose关闭文件流,释放系统资源
//注意:若不关闭可能会导致资源泄露(操作系统会在进程退出后自动回收,但良好实践实践是主动关闭)
fclose(fp);
//5.程序正常执行完毕,返回0表示成功
return 0;
}
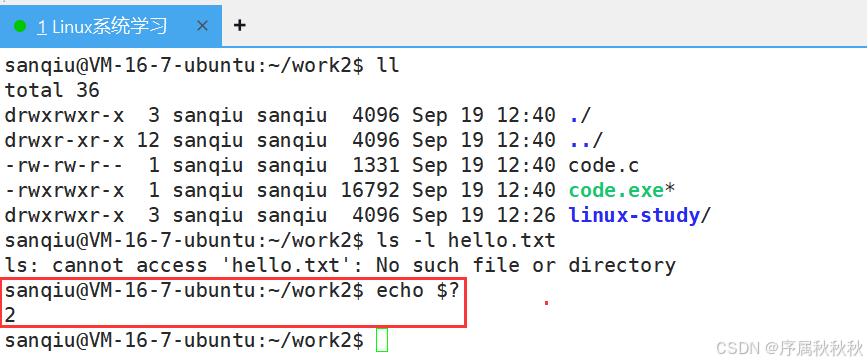
7. 细说进程退出的第三种情况 ------ 异常退出!!!
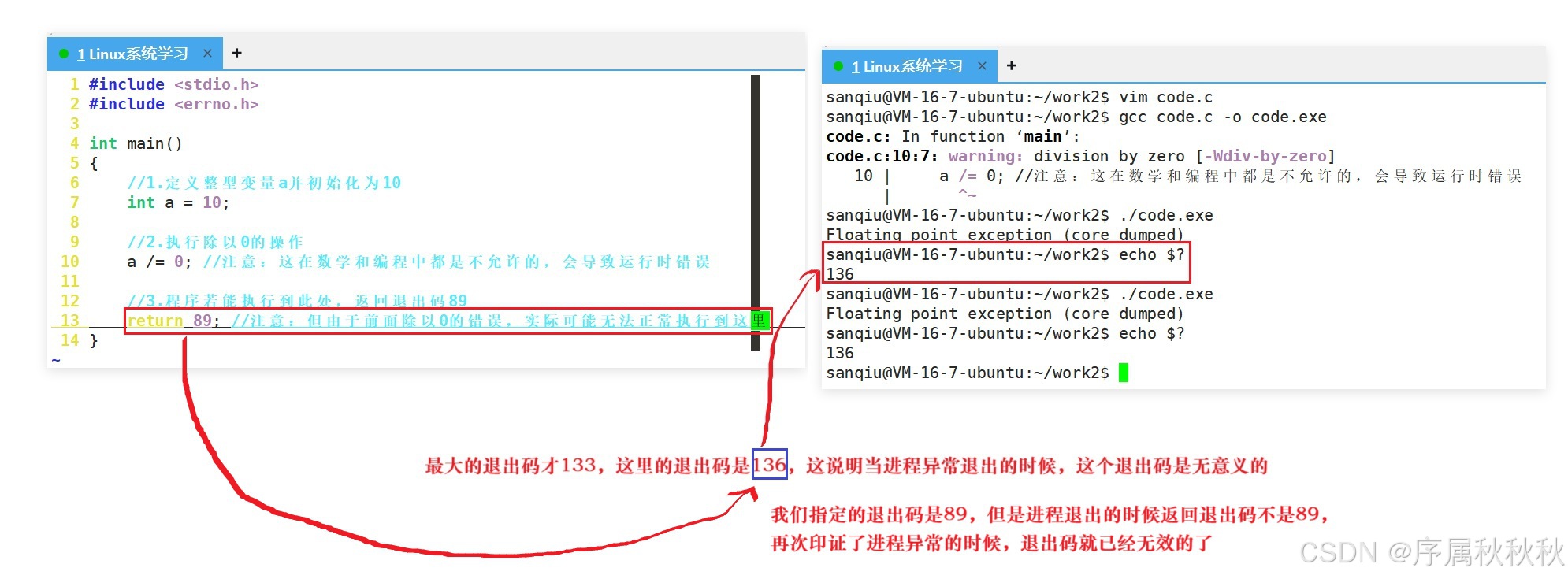
关键结论 :一旦程序因异常终止,进程的退出码就失去了意义
我们可以用 "参加考试" 的场景来类比进程的三种退出状态,这样更容易理解:
- 情况一:考试及格(对应 "代码运行完毕,结果正确")
- 考生完整完成了所有题目,答案符合评分标准,最终顺利通过考试
- 这就像程序按预设逻辑执行完毕,达成了预期目标(如:文件成功写入、数据计算正确),此时进程会主动返回
0作为退出码,传递 "执行成功" 的明确信息
- 情况二:考试不及格(对应 "代码运行完毕,结果不正确")
- 考生虽完整答完了试卷,但答案错误较多,未达到及格标准
- 这对应程序虽跑完了所有代码,但核心任务未完成(如:文件打开失败、参数处理错误),此时进程会返回非
0的退出码(如:1、2等),每个值可对应不同的错误类型,方便定位问题
情况三:考场上作弊被抓(对应 "代码异常终止")
- 考生在考试中途因作弊被监考老师当场制止,试卷未答完就被带离考场 ------ 此时 "分数" 已不再重要,因为考试过程被强行中断,不存在 "完整的答题结果"
- 进程的异常终止也是同理:当程序触发严重错误(如:访问野指针、数组越界)或收到外部终止信号(如:用户按
Ctrl+C发送的SIGINT信号、系统发送的SIGSEGV段错误信号)时,会被操作系统强行中断,根本来不及执行main函数的return语句或exit()函数来设置退出码- 这种情况下,进程的 "退出状态" 由触发终止的信号类型决定(而非退出码),操作系统会记录进程是因哪个信号终止的,此时再讨论 "退出码是多少" 已无意义 ------ 就像作弊被抓的考生,没人会关心他 "能考多少分" 一样
8. 进程常见的退出方法有哪些?
return语句
一个进程若要结束自己的生命周期,通常有哪些退出方式呢?
这是最符合我们编程直觉的退出方式 ------
main函数作为程序的入口,其执行流程的终结也意味着整个进程的结束。具体来说,当 main 函数执行到 return 语句时:
- 会将返回值(即:进程退出码)传递给操作系统
- 随后操作系统会启动进程终止流程:回收进程的 PCB、页表、虚拟地址空间等资源,最终完成进程的清理。
需要特别注意的是:
- 只有 main 函数的 return 才会触发进程退出
- 如果在其他自定义函数(如:
func()、calc()等)中使用 return,仅仅表示该函数的调用结束,程序会返回到函数调用处继续执行后续逻辑,并不会影响整个进程的运行状态
exit函数
exit函数:是 C 语言标准库中用于终止进程的核心函数。
- 它接收一个名为 status 的整型参数 ------ 这个参数本质上就是进程的退出码,与
main函数的返回值所代表的含义完全一致- 具体来说,
exit(status)的执行效果,与在main函数中执行return status是等价的:
- 两者都会将
status作为进程的退出码写入 PCB 的exit_code字段- 随后触发操作系统的进程终止流程,回收进程占用的内存、文件描述符等资源
但
exit函数的灵活性远高于main函数的return:
return仅能在main函数中触发进程退出- 而
exit可以在程序的任何函数(包括自定义函数、库函数调用等)中调用,一旦执行就会直接终止整个进程
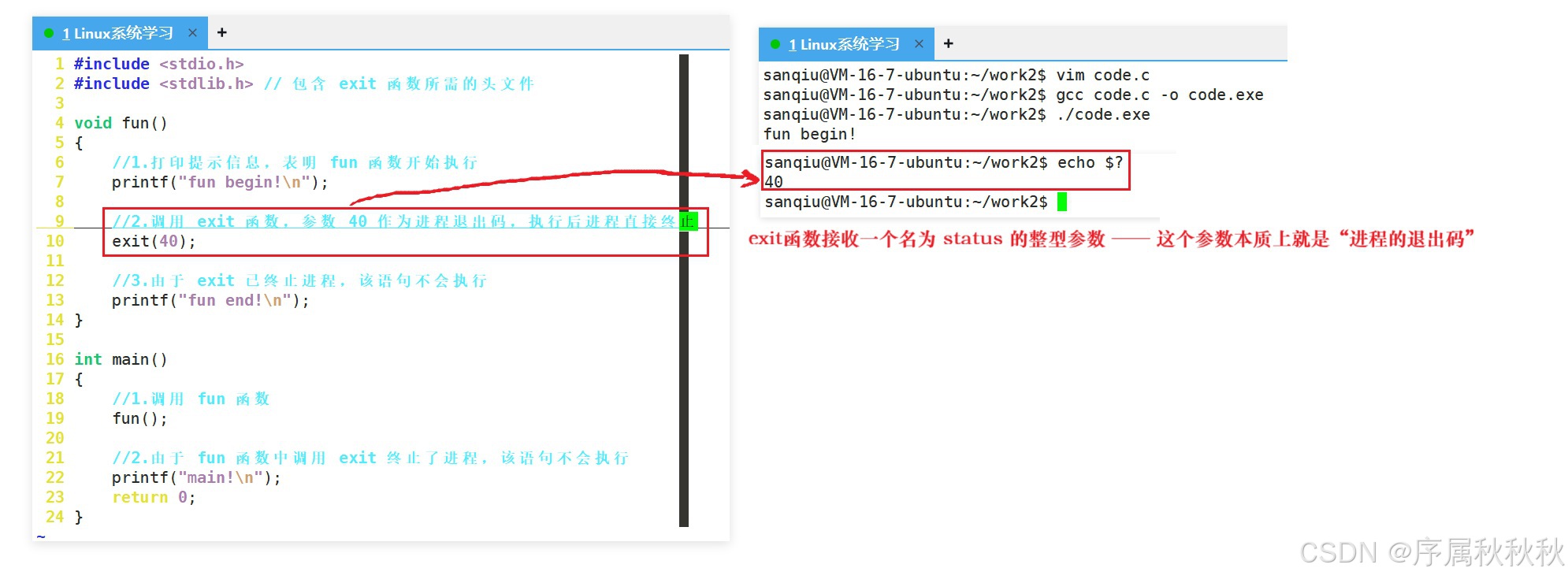
例如下面两段代码的执行结果完全相同,最终进程的退出码均为
2:代码 1:通过 main 函数 return 设置退出码
c#include <stdio.h> int main() { printf("进程即将退出\n"); return 2; //注意:main函数return,退出码为2 }
代码 2:通过 exit 函数设置退出码
c#include <stdio.h> #include <stdlib.h> // exit函数需包含此头文件 void test() { printf("在自定义函数中调用exit\n"); exit(2); //注意:任意函数中调用exit,退出码为2,直接终止进程 } int main() { test(); printf("此语句不会执行(进程已被exit终止)\n"); return 0; }从本质上看:main 函数的 return 其实是一种 "特殊的退出触发"
- 当
main函数执行return时,编译器会在底层自动插入调用exit(return_value)的逻辑- 因此两者最终都会通过相同的路径完成进程退出,仅在调用场景上存在差异
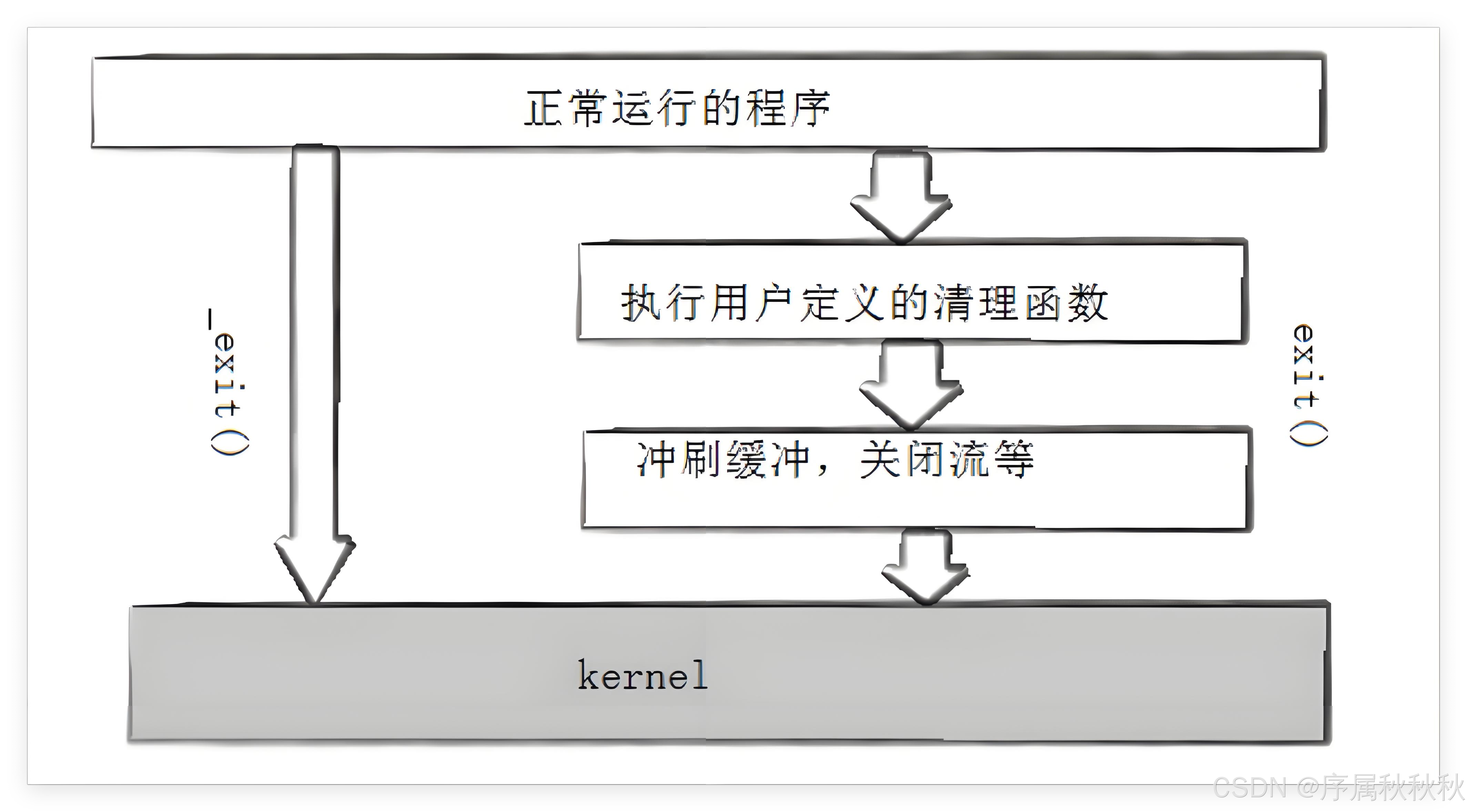
_exit系统调用
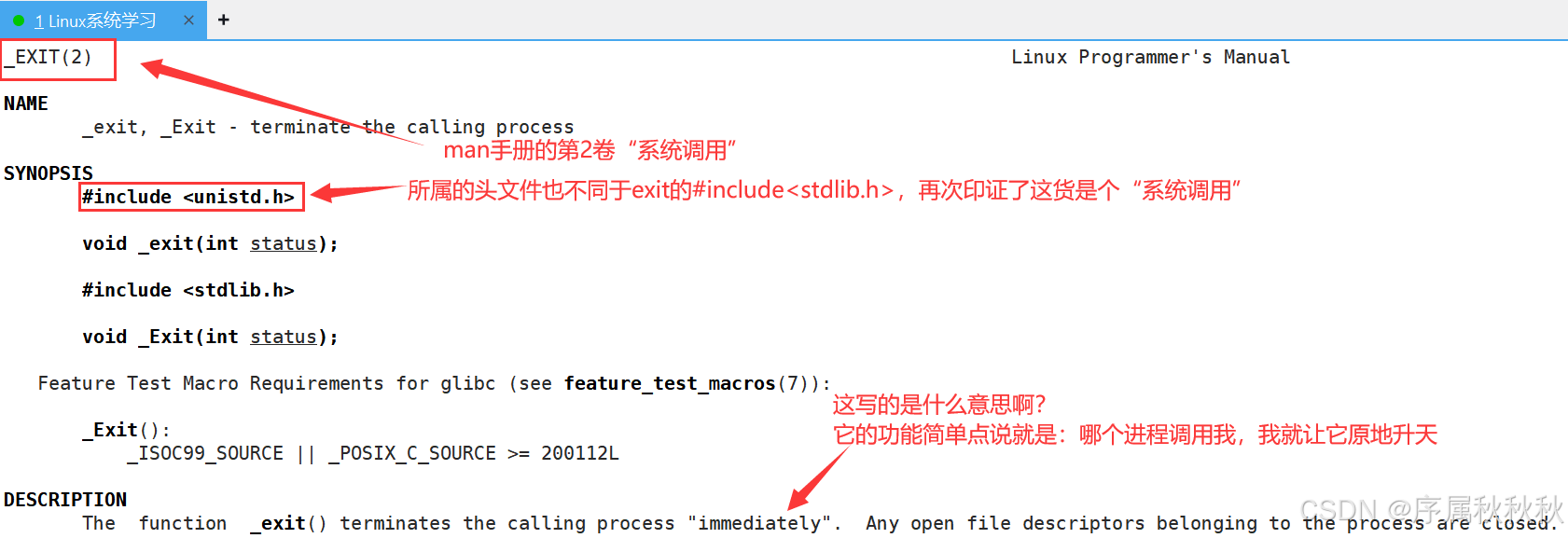

思考与探究 :
exit标准函数和_exit系统调用有什么区别?
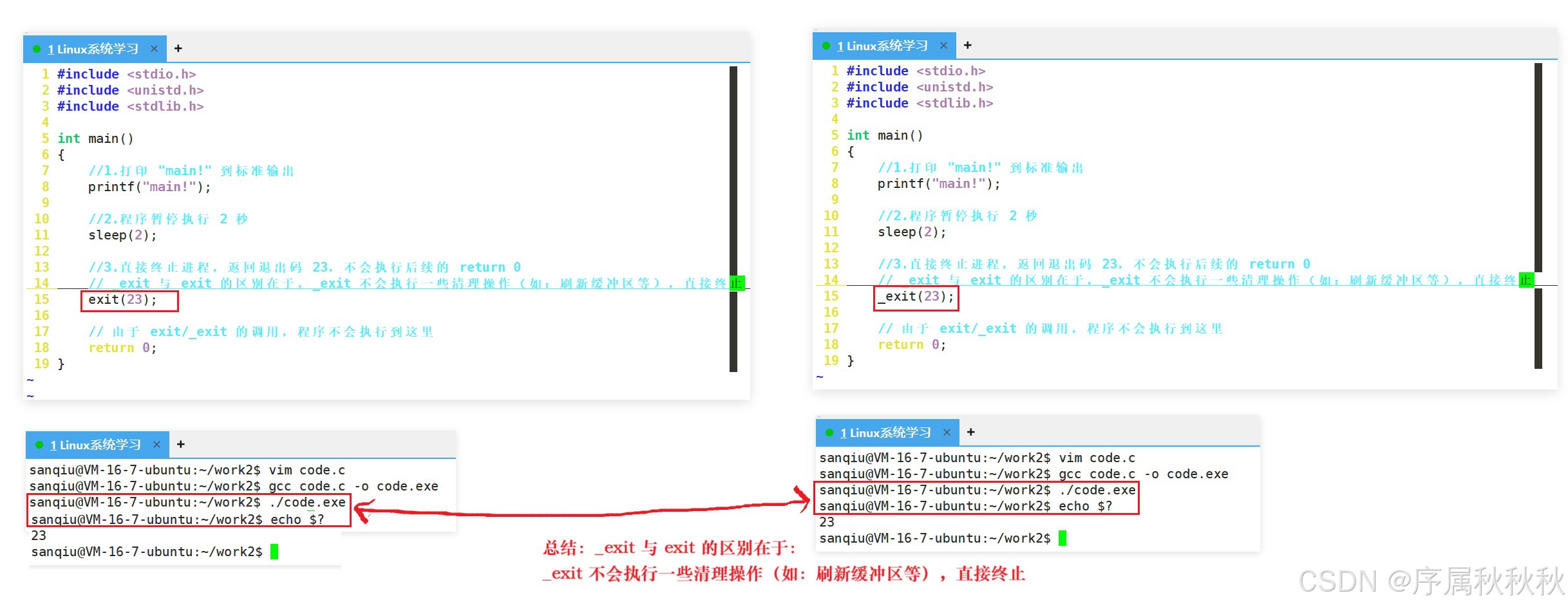
其实这一点不难理解,核心在于
exit和_exit的本质区别:
- exit 是 C 语言标准库函数,而 _exit 是 Linux 系统调用,二者属于 "上层封装" 与 "底层实现" 的关系
- 库函数往往需要通过调用系统调用来完成其核心功能,进程终止这类直接操作操作系统资源的任务更是如此,毕竟,进程的生命周期由操作系统统一管理,库函数本身没有权限直接终止进程
所以
exit函数的底层逻辑,本质上还是通过调用_exit这个系统调用来触发操作系统的进程终止流程,从这个角度看,两者都能实现进程终止的效果,其实并不奇怪。
但为什么二者在 "打印输出" 的表现上会有差异呢?
这恰恰能帮我们断定一个关键结论:C 语言中的标准I/O缓冲区(如:printf 依赖的缓冲区)并不在操作系统内核中,而是由 C 标准库提供的用户态缓冲区
我们可以反推验证这一点:
- 如果缓冲区存在于操作系统内部,那么无论调用
exit还是_exit,最终都会进入内核执行进程终止逻辑- 缓冲区的处理结果应该完全一致 ------ 要么两者都触发刷新,要么两者都不刷新
但实际情况是:
exit函数在调用_exit之前,会先执行一系列 "用户态清理操作",其中就包括主动刷新 C 标准库维护的 I/O 缓冲区(比如:把printf未输出的内容打印到终端)_exit则会直接进入内核终止进程,跳过所有用户态的清理步骤,自然不会刷新 C 库的缓冲区这种 "行为差异" 只有一个合理的解释 :缓冲区属于 C 标准库的用户态组件,而非操作系统内核的一部分
- 也正因为如此,作为库函数的
exit能对其进行处理- 而作为系统调用的
_exit则不会干预用户态的资源