Spring Data JPA 详解:ORM 映射、查询方法与复杂 SQL 处理
引言
在现代 Java 企业级开发中,数据持久层是核心模块之一,其设计直接影响系统的性能、可维护性与扩展性。Spring Data JPA 作为 Spring 生态对 JPA(Java Persistence API)的封装与增强,极大简化了数据持久层的开发工作量。它通过 ORM(对象关系映射)机制实现 Java 对象与数据库表的解耦,提供了统一的 Repository 接口规范,支持灵活的查询方式,同时兼容原生 SQL 操作,完美平衡了开发效率与业务复杂度适配能力。

- [Spring Data JPA 详解:ORM 映射、查询方法与复杂 SQL 处理](#Spring Data JPA 详解:ORM 映射、查询方法与复杂 SQL 处理)
- 引言
- [一、ORM 映射机制详解](#一、ORM 映射机制详解)
-
- [1.1 实体类与关联关系代码示例](#1.1 实体类与关联关系代码示例)
- [二、Repository 接口与查询方法](#二、Repository 接口与查询方法)
-
- [2.1 Repository 接口继承体系](#2.1 Repository 接口继承体系)
- [2.2 方法命名约定自动生成查询](#2.2 方法命名约定自动生成查询)
-
- [代码示例:UserRepository 接口](#代码示例:UserRepository 接口)
- [2.3 @Query 注解自定义查询](#2.3 @Query 注解自定义查询)
-
- [2.3.1 JPQL 查询示例](#2.3.1 JPQL 查询示例)
- [2.3.2 原生 SQL 查询示例](#2.3.2 原生 SQL 查询示例)
- [三、复杂 SQL 场景处理](#三、复杂 SQL 场景处理)
-
- [3.1 多表联查场景](#3.1 多表联查场景)
-
- [3.1.1 JPQL 多表联查(迫切左外连接)](#3.1.1 JPQL 多表联查(迫切左外连接))
- [3.1.2 原生 SQL 多表联查](#3.1.2 原生 SQL 多表联查)
- [3.2 动态条件查询(Specification)](#3.2 动态条件查询(Specification))
- [3.3 分页与排序](#3.3 分页与排序)
-
- [3.3.1 基础分页排序(结合方法命名)](#3.3.1 基础分页排序(结合方法命名))
- [3.3.2 Specification 分页排序](#3.3.2 Specification 分页排序)
- 四、数据流转流程图
- 五、总结与最佳实践建议
-
- [5.1 适用边界](#5.1 适用边界)
- [5.2 最佳实践建议](#5.2 最佳实践建议)
-
- [5.2.1 性能优化](#5.2.1 性能优化)
- [5.2.2 可维护性提升](#5.2.2 可维护性提升)
- [5.2.3 其他建议](#5.2.3 其他建议)
Spring Data JPA 的核心优势体现在三方面:一是简化开发 ,无需手动编写 DAO 层实现类,仅通过接口定义即可完成数据CRUD操作;二是查询能力强大 ,支持方法命名约定自动生成查询、JPQL 自定义查询及原生 SQL 查询,适配不同复杂度场景;三是生态无缝集成 ,可与 Spring Boot、Spring Cloud 等组件快速整合,支持事务管理、分页排序等原生 Spring 特性,降低技术栈整合成本。
📕个人领域 :Linux/C++/java/AI
🚀 个人主页 :有点流鼻涕 · CSDN
💬 座右铭 : "向光而行,沐光而生。"

一、ORM 映射机制详解
ORM 即对象关系映射,其核心思想是将 Java 领域模型中的对象与数据库中的表建立对应关系,通过注解或 XML 配置描述映射规则,由 JPA 提供商(如 Hibernate)自动完成对象与数据之间的转换,避免手动编写 JDBC 代码。Spring Data JPA 基于 JPA 规范,主要通过注解实现 ORM 映射,常用核心注解及功能如下:
-
@Entity:标识该类为 JPA 实体类,对应数据库中的一张表,类名默认作为表名(可通过 @Table 自定义)。
-
@Table:与 @Entity 搭配使用,指定实体类对应的数据库表名、schema、索引等信息。
-
@Id:标识实体类的主键字段,对应表中的主键列。
-
@GeneratedValue:指定主键生成策略,常用策略包括 AUTO(自动适配数据库)、IDENTITY(依赖数据库自增)、SEQUENCE(依赖数据库序列)、TABLE(通过中间表生成主键)。
-
@Column:描述实体类字段与表中列的映射关系,可指定列名、长度、是否可为空、是否唯一等属性。
-
@OneToMany / @ManyToOne:描述实体间的一对多、多对一关联关系,需指定 cascade(级联操作)、fetch(加载策略)等属性。
-
@ManyToMany:描述实体间的多对多关联关系,通常需要指定中间关联表。
-
@JoinColumn:指定关联关系中的外键列,用于一对一、多对一等关联场景。
1.1 实体类与关联关系代码示例
以下以"用户-订单"一对多关联场景为例,展示完整的实体类映射实现,包含主键策略、字段映射、关联关系配置及级联操作设置。
用户实体类(User.java)
java
package com.example.jpa.entity;
import jakarta.persistence.*;
import lombok.Data;
import java.util.List;
/**
* 用户实体类,与订单表为一对多关联
*/
@Data
@Entity
@Table(name = "t_user") // 对应数据库表t_user
public class User {
// 主键,采用数据库自增策略
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "user_id") // 对应表中user_id列
private Long userId;
// 用户名,非空,唯一
@Column(name = "username", nullable = false, unique = true, length = 50)
private String username;
// 邮箱,非空
@Column(name = "email", nullable = false, length = 100)
private String email;
// 年龄
@Column(name = "age")
private Integer age;
// 一对多关联订单表:一个用户可拥有多个订单
// cascade = CascadeType.ALL:级联增删改查
// fetch = FetchType.LAZY:懒加载,查询用户时不主动加载订单列表
// mappedBy = "user":指定关联关系由订单表的user字段维护
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.LAZY, mappedBy = "user")
private List<Order> orders;
}订单实体类(Order.java)
java
package com.example.jpa.entity;
import jakarta.persistence.*;
import lombok.Data;
import java.math.BigDecimal;
import java.time.LocalDateTime;
/**
* 订单实体类,与用户表为多对一关联
*/
@Data
@Entity
@Table(name = "t_order") // 对应数据库表t_order
public class Order {
// 主键,数据库自增策略
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "order_id")
private Long orderId;
// 订单编号,唯一
@Column(name = "order_no", nullable = false, unique = true, length = 32)
private String orderNo;
// 订单金额
@Column(name = "amount", nullable = false, precision = 10, scale = 2)
private BigDecimal amount;
// 订单创建时间
@Column(name = "create_time", nullable = false)
private LocalDateTime createTime;
// 多对一关联用户表:多个订单属于一个用户
// @JoinColumn指定外键列user_id,对应t_order表中的user_id字段
@ManyToOne(fetch = FetchType.EAGER) // 立即加载,查询订单时同时加载关联用户
@JoinColumn(name = "user_id", nullable = false)
private User user;
}上述示例中,通过注解完成了以下映射逻辑:User 实体对应 t_user 表,Order 实体对应 t_order 表;t_order 表通过 user_id 外键关联 t_user 表的 user_id 主键,形成一对多关联;同时配置了级联操作与加载策略,兼顾业务需求与性能优化。
二、Repository 接口与查询方法
Spring Data JPA 提供了 Repository 接口体系,作为数据访问层的核心规范,开发者只需定义接口并继承相应的父接口,即可获得默认的 CRUD 操作能力。同时,Spring Data JPA 支持两种自定义查询方式:基于方法命名约定自动生成查询、基于 @Query 注解编写 JPQL 或原生 SQL。
2.1 Repository 接口继承体系
核心父接口关系:Repository(顶层接口,无默认方法)→ CrudRepository(提供 CRUD 操作)→ PagingAndSortingRepository(扩展分页排序能力)→ JpaRepository(进一步扩展,支持批量操作、刷新缓存等)。实际开发中,通常直接继承 JpaRepository 即可满足大部分需求。
2.2 方法命名约定自动生成查询
Spring Data JPA 支持通过特定的方法命名规则,自动解析生成对应的 SQL 查询,无需编写任何查询语句。命名规则需遵循"动词+条件+属性"的格式,常用动词包括 findBy、countBy、deleteBy 等,条件支持等值、范围、模糊匹配等。
代码示例:UserRepository 接口
java
package com.example.jpa.repository;
import com.example.jpa.entity.User;
import org.springframework.data.jpa.repository.JpaRepository;
import java.util.List;
import java.util.Optional;
/**
* 用户数据访问接口,继承JpaRepository获得默认CRUD能力
* JpaRepository<实体类类型, 主键类型>
*/
public interface UserRepository extends JpaRepository<User, Long> {
// 1. 按用户名查询(等值匹配)
Optional<User> findByUsername(String username);
// 2. 按邮箱查询(等值匹配)
User findByEmail(String email);
// 3. 按年龄大于指定值查询(范围匹配)
List<User> findByAgeGreaterThan(Integer age);
// 4. 按用户名模糊匹配+年龄小于等于指定值查询(组合条件)
List<User> findByUsernameLikeAndAgeLessThanEqual(String usernamePattern, Integer age);
// 5. 统计指定年龄范围内的用户数量
long countByAgeBetween(Integer minAge, Integer maxAge);
// 6. 按用户名删除用户
void deleteByUsername(String username);
}上述方法会被 Spring Data JPA 自动解析为对应的 SQL 查询,例如 findByAgeGreaterThan(Integer age) 会生成 "SELECT * FROM t_user WHERE age > ?";findByUsernameLikeAndAgeLessThanEqual 会生成 "SELECT * FROM t_user WHERE username LIKE ? AND age <= ?"。该方式适用于简单查询场景,优势是开发高效、无需关注 SQL 语法。
2.3 @Query 注解自定义查询
对于复杂查询场景,方法命名约定可能会导致方法名过长、可读性差,此时可通过 @Query 注解编写 JPQL 或原生 SQL 实现自定义查询。JPQL 是面向实体的查询语言,与具体数据库无关;原生 SQL 则直接针对数据库表编写,适用于需利用数据库特有语法的场景。
2.3.1 JPQL 查询示例
java
package com.example.jpa.repository;
import com.example.jpa.entity.User;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.util.List;
public interface UserRepository extends JpaRepository<User, Long> {
// 1. 自定义JPQL查询:按用户名模糊匹配查询(参数通过位置绑定)
@Query("SELECT u FROM User u WHERE u.username LIKE %?1%")
List<User> findByUsernamePattern(String username);
// 2. 自定义JPQL查询:按年龄范围查询(参数通过名称绑定,更易读)
@Query("SELECT u FROM User u WHERE u.age BETWEEN :minAge AND :maxAge")
List<User> findByAgeRange(@Param("minAge") Integer minAge, @Param("maxAge") Integer maxAge);
// 3. 自定义JPQL更新操作(需添加@Modifying和@Transactional注解)
@Modifying
@Transactional
@Query("UPDATE User u SET u.email = :newEmail WHERE u.userId = :userId")
int updateUserEmail(@Param("userId") Long userId, @Param("newEmail") String newEmail);
}2.3.2 原生 SQL 查询示例
java
package com.example.jpa.repository;
import com.example.jpa.entity.User;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.util.List;
public interface UserRepository extends JpaRepository<User, Long> {
// 原生SQL查询:按用户名和年龄组合条件查询(需指定nativeQuery = true)
@Query(value = "SELECT * FROM t_user WHERE username LIKE %:username% AND age > :age", nativeQuery = true)
List<User> findByUsernameAndAgeNative(@Param("username") String username, @Param("age") Integer age);
// 原生SQL分页查询(需配合Pageable参数,注意表名是数据库实际表名)
@Query(value = "SELECT * FROM t_user WHERE age BETWEEN :minAge AND :maxAge ORDER BY user_id DESC",
countQuery = "SELECT COUNT(*) FROM t_user WHERE age BETWEEN :minAge AND :maxAge",
nativeQuery = true)
Page<User> findByAgeRangeNative(@Param("minAge") Integer minAge,
@Param("maxAge") Integer maxAge,
Pageable pageable);
}注意:使用 @Query 执行更新/删除操作时,必须添加 @Modifying 注解标识为修改操作,同时需配合 @Transactional 注解开启事务;原生 SQL 分页查询需指定 countQuery 用于统计总条数,否则无法实现分页功能。
三、复杂 SQL 场景处理
在实际业务开发中,经常面临多表联查、动态条件查询、复杂分页排序等场景,仅依靠方法命名或简单 @Query 注解难以满足需求。此时可结合 Specification、JPA Criteria API 或 @Query + nativeQuery 组合实现灵活适配,以下针对核心场景提供解决方案及代码示例。
3.1 多表联查场景
多表联查可通过 JPQL 关联查询、原生 SQL 联查或 Specification 关联查询实现。以下以"查询用户及其关联的订单列表"为例,展示两种常用方式。
3.1.1 JPQL 多表联查(迫切左外连接)
java
@Query("SELECT DISTINCT u FROM User u LEFT JOIN FETCH u.orders WHERE u.age > :age")
List<User> findUserWithOrders(@Param("age") Integer age);说明:LEFT JOIN FETCH 用于实现迫切左外连接,查询用户时同时加载关联的订单列表,避免懒加载导致的 N+1 查询问题;DISTINCT 用于去重,防止因关联查询导致的重复数据。
3.1.2 原生 SQL 多表联查
java
@Query(value = "SELECT u.*, o.order_no, o.amount " +
"FROM t_user u LEFT JOIN t_order o ON u.user_id = o.user_id " +
"WHERE u.age > :age ORDER BY u.user_id",
nativeQuery = true)
List<Object[]> findUserOrderNative(@Param("age") Integer age);说明:原生 SQL 联查直接操作数据库表,适用于复杂关联场景;查询结果返回 Object\[\] 数组,需手动映射为实体类或 DTO 对象。
3.2 动态条件查询(Specification)
当查询条件不固定(如多条件组合筛选,条件可能存在或不存在)时,使用 Specification 动态构建查询条件是最优方案。Specification 基于 JPA Criteria API 封装,支持动态拼接条件、多表关联、排序等功能。
代码示例:动态条件查询用户
java
package com.example.jpa.service;
import com.example.jpa.entity.User;
import com.example.jpa.repository.UserRepository;
import org.springframework.data.jpa.domain.Specification;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserService {
private final UserRepository userRepository;
// 构造方法注入
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
// 动态条件查询用户:支持用户名模糊匹配、年龄范围、邮箱存在性筛选
public List<User> findUsersByDynamicConditions(String username, Integer minAge, Integer maxAge, Boolean hasEmail) {
// 构建动态查询条件
Specification<User> specification = (root, query, cb) -> {
// 初始化条件列表
List<Predicate> predicates = new ArrayList<>();
// 1. 用户名模糊匹配(条件存在时添加)
if (username != null && !username.isEmpty()) {
predicates.add(cb.like(root.get("username"), "%" + username + "%"));
}
// 2. 年龄范围查询(条件存在时添加)
if (minAge != null && maxAge != null) {
predicates.add(cb.between(root.get("age"), minAge, maxAge));
} else if (minAge != null) {
predicates.add(cb.greaterThanOrEqualTo(root.get("age"), minAge));
} else if (maxAge != null) {
predicates.add(cb.lessThanOrEqualTo(root.get("age"), maxAge));
}
// 3. 邮箱非空筛选(条件为true时添加)
if (Boolean.TRUE.equals(hasEmail)) {
predicates.add(cb.isNotNull(root.get("email")));
}
// 组合所有条件并返回
return cb.and(predicates.toArray(new Predicate[0]));
};
// 执行查询
return userRepository.findAll(specification);
}
}说明:root 代表查询的实体类(User),可通过 root.get("属性名") 获取实体字段;cb(CriteriaBuilder)用于构建查询条件(如 like、between、and 等);predicates 列表用于存储动态条件,最终通过 cb.and 组合为完整查询条件。
3.3 分页与排序
Spring Data JPA 提供了 Pageable 接口实现分页排序功能,可与 Repository 方法、@Query 注解、Specification 结合使用,适配不同查询场景。
3.3.1 基础分页排序(结合方法命名)
java
// UserRepository接口方法
List<User> findByAgeGreaterThan(Integer age, Pageable pageable);
// 服务层调用
Pageable pageable = PageRequest.of(0, 10, Sort.by(Sort.Direction.DESC, "userId"));
// 分页查询结果(Page包含总条数、总页数、当前页数据等信息)
Page<User> userPage = userRepository.findByAgeGreaterThan(18, pageable);
// 获取当前页数据列表
List<User> userList = userPage.getContent();
// 获取总条数
long total = userPage.getTotalElements();3.3.2 Specification 分页排序
java
// 构建排序条件:按userId降序、age升序
Sort sort = Sort.by(
Sort.Order.desc("userId"),
Sort.Order.asc("age")
);
// 构建分页条件:第0页(页码从0开始),每页10条,附带排序
Pageable pageable = PageRequest.of(0, 10, sort);
// 结合动态条件与分页排序查询
Page<User> userPage = userRepository.findAll(specification, pageable);四、数据流转流程图
以下通过 Mermaid 流程图展示 Spring Data JPA 中从 Repository 方法调用到返回实体对象的完整数据流转过程,清晰呈现各组件的交互逻辑。
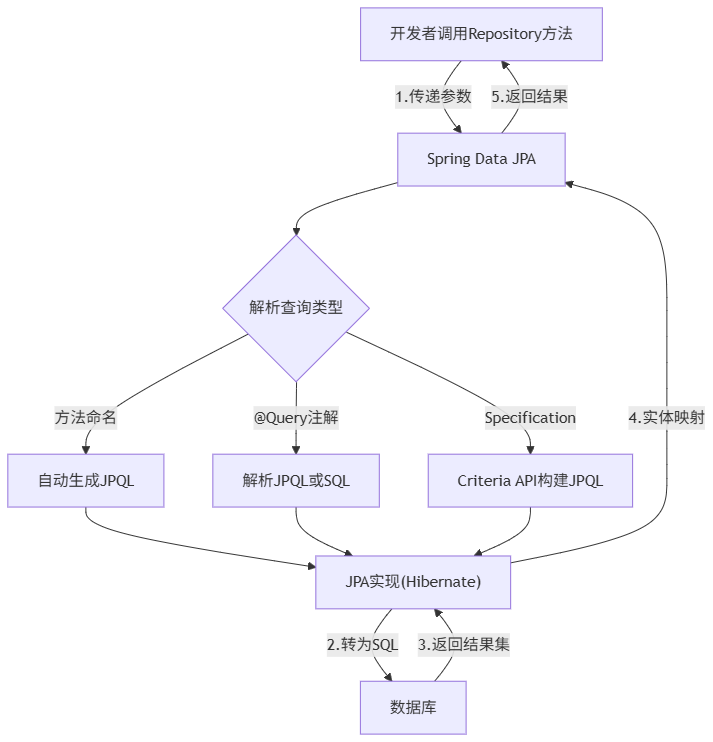
流程说明:1. 开发者调用 Repository 接口方法并传递参数;2. Spring Data JPA 框架根据查询类型解析生成对应的 JPQL 或原生 SQL;3. JPA 提供商将查询语句转换为数据库可执行的原生 SQL 并发送至数据库;4. 数据库执行 SQL 并返回结果集;5. JPA 提供商将结果集通过 ORM 机制映射为 Java 实体对象;6. 框架将实体对象或分页结果返回给开发者。
五、总结与最佳实践建议
5.1 适用边界
Spring Data JPA 适用于大多数 Java 企业级应用的数据持久层开发,尤其适合以下场景:一是中低复杂度的 CRUD 及查询业务,可大幅提升开发效率;二是需要跨数据库兼容的项目(JPQL 与数据库无关);三是 Spring 生态技术栈的项目,可实现无缝集成。
不适用于以下场景:一是对 SQL 执行效率要求极高的核心业务(原生 SQL 更易优化);二是需要频繁使用数据库特有语法(如存储过程、复杂函数)的场景;三是简单的单表操作且追求极致轻量化的项目(JDBC 或 MyBatis 更简洁)。
5.2 最佳实践建议
5.2.1 性能优化
-
合理配置加载策略:一对多、多对多关联默认使用懒加载(FetchType.LAZY),避免迫切加载导致的冗余数据查询;简单多对一关联可使用立即加载(FetchType.EAGER),平衡性能与开发效率。
-
避免 N+1 查询问题:多表关联查询时,使用 LEFT JOIN FETCH 迫切加载关联对象,或通过 @EntityGraph 注解指定关联加载属性。
-
分页查询必用 Pageable:避免一次性查询大量数据导致内存溢出,同时利用数据库分页语法(limit、offset)提升查询效率。
-
合理使用缓存:开启 JPA 二级缓存(针对高频查询的只读数据),减少数据库交互次数;同时避免缓存一致性问题。
5.2.2 可维护性提升
-
统一 Repository 接口规范:自定义基础 Repository 接口,封装通用查询方法,避免重复代码。
-
复杂查询优先使用 Specification:动态条件查询通过 Specification 实现,代码可读性与扩展性优于拼接 SQL 字符串。
-
避免业务逻辑侵入数据层:Repository 接口仅负责数据访问,复杂业务逻辑放在 Service 层处理,遵循分层架构原则。
-
注解规范使用:实体类映射注解明确指定列名、长度、约束等属性,避免依赖默认值,提升代码可读性与可移植性。
5.2.3 其他建议
一是开发阶段开启 SQL 日志打印(spring.jpa.show-sql=true),便于调试查询语句;二是生产环境避免使用 @Modifying 注解执行批量更新/删除,建议通过原生 SQL 或分批处理优化性能;三是针对复杂报表查询,可结合 MyBatis 混合使用,兼顾开发效率与查询性能。
总之,Spring Data JPA 作为一款高效的数据持久层框架,核心价值在于简化开发、统一规范。开发者需熟练掌握其 ORM 映射、查询方法及复杂场景处理技巧,结合业务需求合理选择技术方案,才能在提升开发效率的同时,保证
