写这个专题主要是因为最近在做高级人工智能的作业,发现自己还有很多基础上的知识缺陷,因此打算重新记录一下。本专题主要会以项目为导向,做项目------遇到问题------解决问题------做项目来进行。
本系列所有项目基于Windows下vscode、jupyter、pytorch(sklearn)完成
鸢尾花分类
鸢尾花分类是机器学习入门中最经典最容易的问题,首先它的任务很明确,即已知一些花的数据(包括花萼、花瓣的长、宽,问这个花是什么种类的)。其次,它的数据集是 sklearn 自带,无需手动下载、清洗、处理缺失值 / 异常值。另外,它也不需要复杂的数学知识,仅依靠距离公式就可以完成。最重要的是,它可以包含了**「数据加载→数据探索→数据预处理→划分训练集 / 测试集→模型构建→模型训练→模型预测→模型评估」** 这些机器学习的完整过程,可以很好的建立机器学习项目的框架。此外,它的扩展性也很高。
数据加载
python
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['品种'] = iris.target
# 把数字标签换成中文(更直观)
df['品种'] = df['品种'].map({0: '山鸢尾', 1: '变色鸢尾', 2: '维吉尼亚鸢尾'})
print("=== 数据前5行 ===")
print(df.head())
# 2. 查看数据基本统计信息(均值、标准差、最小值/最大值)
print("\n=== 数据统计信息 ===")
print(df.describe())
# 3. 查看每个品种的样本数量(确认数据均衡)
print("\n=== 各品种样本数 ===")
print(df['品种'].value_counts())首先加载数据集,作为机器学习最经典的项目,sklearn.datasets已经封装好了鸢尾花数据集
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)把 scikit‑learn 的 iris 数据集中的特征数组转换为 pandas DataFrame,并用 iris.feature_names 作为列名。
- 输入:
- iris.data:一个 NumPy 数组(通常形状 (150, 4),每行一个样本,每列一个特征)。
- iris.feature_names:包含列名的字符串列表(如 "sepal length (cm)" 等)。
- 输出:df 是一个带友好列名的 DataFrame,便于查看、选择列、可视化和后续数据处理
相较于numpy,pandas在数据分析上更有优势。
以上代码运行完毕后,就会有如下输出

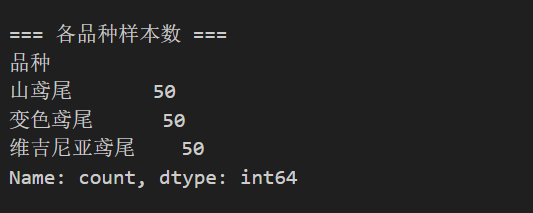
这里为了观看方便,我把标签映射成为中文,实际上并不需要这一步操作。通过这些可视化的步骤,我们对数据集的认识加深了,每一种花都有四个不同的特征,该数据集中,共有三种不同的鸢尾花。
数据探索
每一种花都有四个不同的特征,对于机器学习来说,并不是所有特征都有用的,甚至有些特征还可能会有负作用。原因在于,我们在制作数据集中,并不总是知道哪些数据是有用的,例如之后会做的糖尿病预测,性别、年龄、节食程度,这些会对糖尿病有影响吗?也许有也许没有,因此,我们需要一些方法来进行数据探索,其中最重要的就是特征工程。不过这是一个很复杂的问题,本文所讲的鸢尾花分类只有四个特征,在一些问题中,一个数据可能有上百个特征,因此这里仅做一些简单的探索。
python
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(8, 6))
sns.scatterplot(x='petal length (cm)', y='petal width (cm)', hue='品种', data=df, s=80)
plt.title('鸢尾花花瓣长度 vs 花瓣宽度')
plt.xlabel('花瓣长度(cm)')
plt.ylabel('花瓣宽度(cm)')
plt.legend()
plt.show()运行后有如下结果
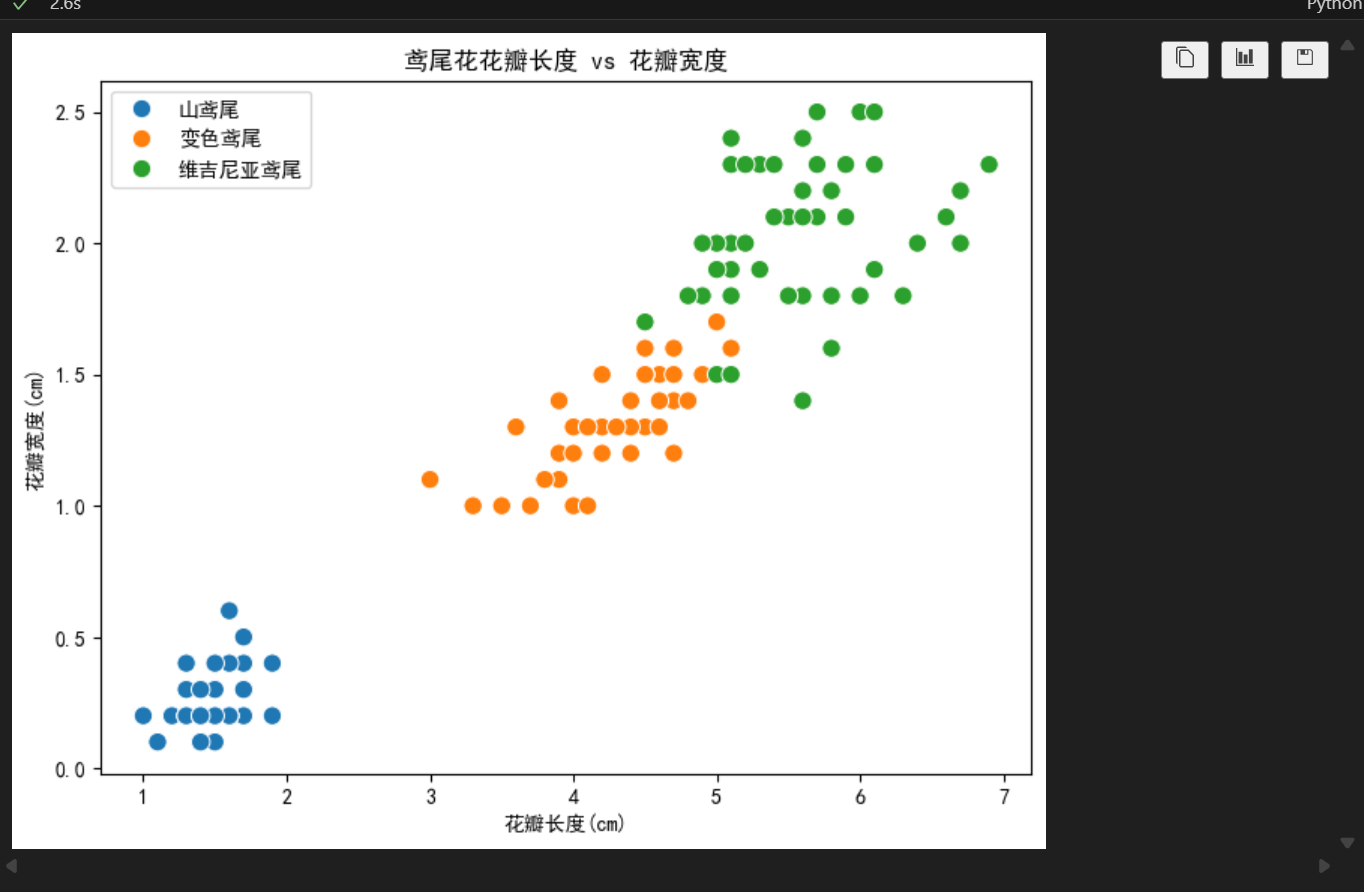
sns.scatterplot(x='petal length (cm)', y='petal width (cm)', hue='品种', data=df, s=80)的作用是在当前 DataFrame df 上绘制散点图,用花瓣长度(petal length (cm))作为 x 轴,花瓣宽度(petal width (cm))作为 y 轴;不同品种用不同颜色区分(hue='品种')。点的大小由 s=80 控制。
从图中我们可以看出,不同的鸢尾花的花瓣长度与宽度有着明显的区别,说明这两个特征对分类有着很大的作用。(当然,这是一种定性的分析,并不准确且低效,在后续详解特征工程时会介绍更通用的方法)
数据预处理
一般来说,对于一个机器学习项目,数据预处理是至关重要的,当然本例中的数据非常简单,没有缺失数据和异常数据,而且从sklearn.datasets中导入的数据集非常规范,不需要过多处理,只需要划分训练集与测试集即可。
- 训练集:给模型 "学本事" 的素材(带答案的练习题),模型在这上面学规律 / 记素材;
- 测试集:给模型 "考本事" 的考题(没做过的新题),用来检验模型的真实预测能力;
python
from sklearn.model_selection import train_test_split
try:
labels = None
if 'target' in df.columns:
y = df['target']
X = df.drop('target', axis=1)
elif '品种' in df.columns:
# 如果品种是中文标签,尝试映射回数字
if df['品种'].dtype == object:
mapping = {'山鸢尾':0, '变色鸢尾':1, '维吉尼亚鸢尾':2}
y = df['品种'].map(mapping)
X = df.drop('品种', axis=1)
else:
# 已经是数字
y = df['品种']
X = df.drop('品种', axis=1)
else:
# 退回到 iris 变量(如果存在)
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = pd.Series(iris.target)
except NameError:
# 如果 notebook 中没有 df 或 iris,会抛出异常
raise RuntimeError("找不到 df 或 iris,请先运行前面的单元格以构建数据。")
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 划分训练集和测试集 random_state保证结果可复现
from sklearn.preprocessing import StandardScaler # 标准化
scaler = StandardScaler() # 创建标准化对象
X_train = scaler.fit_transform(X_train) # 训练并转换训练集
X_test = scaler.transform(X_test) # 转换测试集下面介绍一下代码,try------except部分,主要是因为前面为了展示方便,将target映射成了中文,其核心只有两行:
python
X = df.drop('target', axis=1) # 特征变量
y = df['target'] # 目标变量- X = df.drop('target', axis=1)
- 从 DataFrame 删除名为 "target" 的列,得到特征矩阵 X(pandas DataFrame)。
- y = df'target'
- 取目标变量列,得到标签向量 y(pandas Series)。
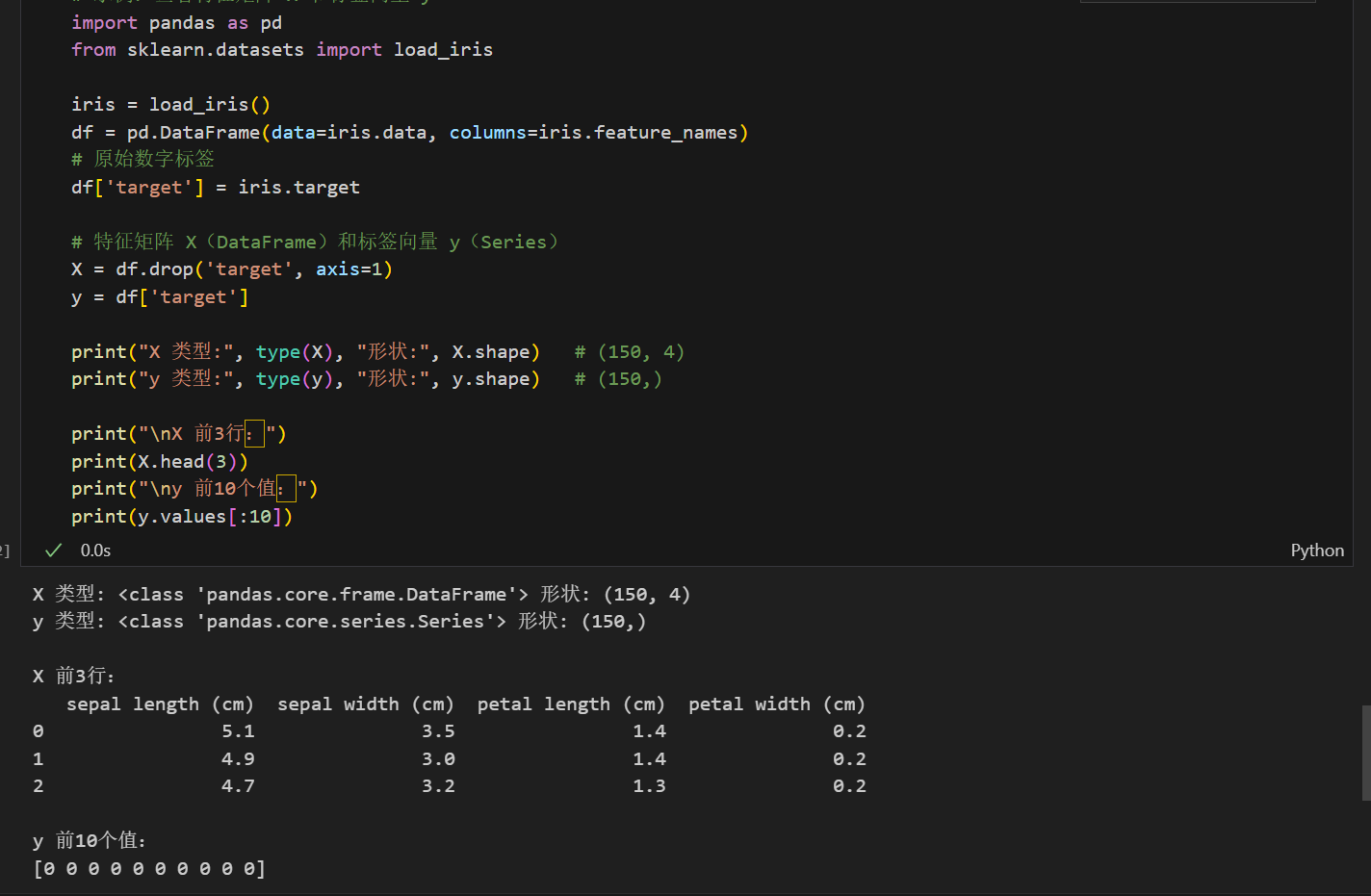
其中X,y的形状取值如图。
- train_test_split(...)
- 将数据随机划分成训练集和测试集。
- test_size=0.2 表示 20% 用作测试集,80% 用作训练集。
- random_state=42 固定随机种子,确保每次运行划分结果相同(可复现)。
- 返回顺序为 X_train, X_test, y_train, y_test(类型与输入一致,未变为数组)。
- 对 iris(150 条)而言:训练集 120 条,测试集 30 条(示例)。
- from sklearn.preprocessing import StandardScaler
- 引入标准化器:对每个特征做零均值、单位方差变换(z = (x - mean) / std)。
- scaler = StandardScaler()
- 创建 StandardScaler 实例,但此时未计算均值和方差。
- X_train = scaler.fit_transform(X_train)
- 在训练集上计算每个特征的均值和标准差(fit),并用这些参数把训练集转换为标准化后的数值(transform)。
- 返回的是 numpy 数组(而非 DataFrame)。
- X_test = scaler.transform(X_test)
- 使用在训练集上学到的均值和方差对测试集做相同变换。
通过这些处理,我们把150条数据集划分为了120条训练集(有特征有答案)和30条测试集(有特征无答案),这里需要再详细解释一下X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) 的作用,其有四个输出
- X_train:训练集的特征矩阵,形状为 (n_train, n_features)。用于训练模型(model.fit)和在训练集上 fit 标准化器/特征变换器。
- y_train:训练集的标签向量,长度 n_train。作为监督信号(即答案)传给 model.fit。
- X_test:测试集的特征矩阵,形状为 (n_test, n_features)。用于对训练好的模型进行预测(model.predict),在评估阶段作为输入;
- y_test:测试集的真实标签,长度 n_test。用于与预测结果比较来计算指标(accuracy、precision、recall 等),在模型开发中视为"未知答案"用于检验泛化能力。
模型构建与模型训练
本例中采用最简单的KNN聚类模型,它几乎不需要训练,因此这里只简单介绍一下原理
1. 生活类比
假设你不认识一种水果(比如莲雾),但你认识苹果、香蕉、橘子。你会怎么做?
- 先找和它「长得最像」的 3 个(K=3)水果(比如形状、颜色、大小最接近);
- 发现这 3 个里有 2 个是苹果,1 个是橘子;
- 你就会判断:这个不认识的水果,大概率和苹果是一类(少数服从多数)。
2. 对应到鸢尾花分类
鸢尾花有 3 个品种(山鸢尾、变色鸢尾、维吉尼亚鸢尾),4 个特征(花萼长、花萼宽、花瓣长、花瓣宽),KNN 做分类的逻辑和上面的水果识别完全一致:
- 已知样本:我们有 150 朵标注了「品种标签」的鸢尾花(相当于你认识的苹果、香蕉),每朵花都有 4 个特征数据;
- 未知样本:来了一朵没标注品种的鸢尾花(相当于你不认识的莲雾),也有 4 个特征数据;
- KNN 核心操作 :
- 先算这朵未知鸢尾花,和 150 朵已知鸢尾花的「相似度」(用「距离」衡量,距离越近 = 相似度越高,比如两朵花的 4 个特征数值都很接近,距离就小);
- 从近到远排序,选出距离最近的 K 朵(比如 K=5,就是选 5 个最像的已知鸢尾花);
- 统计这 K 朵花的品种:比如 5 朵里有 3 朵是变色鸢尾,2 朵是维吉尼亚鸢尾;
- 投票决定:未知鸢尾花的品种就是「变色鸢尾」(多数胜出)。
KNN算法仅有一个超参数n,作用是选多少个邻居来投票,比如上例中选择最近的五朵花,n就等于5,KNN的效果好坏,很大程度上取决于n的选择是否合理。
针对鸢尾花测试集里的每一朵未知品种的花,KNN 预测时会做 3 件事:
- 计算:测试花和训练集里 120 朵花的距离(判断相似度);
- 筛选:选出距离最近的 5 朵花(K=5);
- 投票:统计这 5 朵花的品种,多数品种就是测试花的预测品种。
对应到代码中如下
python
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=3) # 创建KNN分类器对象
model.fit(X_train, y_train) # 训练模型
# 评估
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
y_pred = model.predict(X_test) # 预测测试集
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Classification Report:\n", classification_report(y_test, y_pred))
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred))最终得到如下指标:
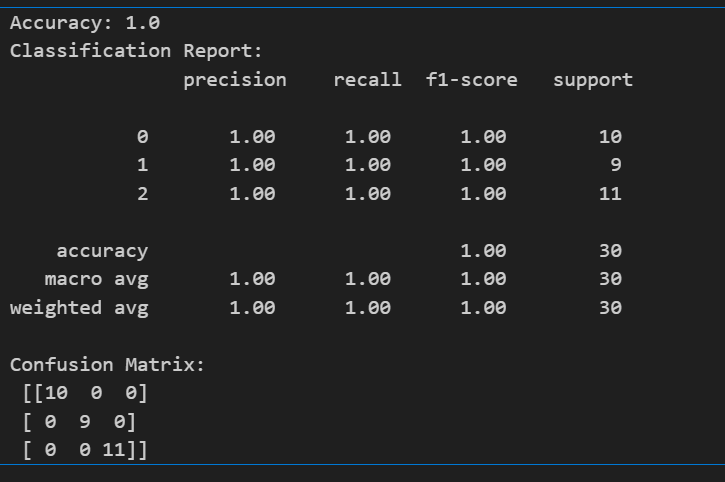
这里仅介绍一下准确率(accuracy):代码计算中用y_pred来代表预测值,y_test代表真实值,通过测试集中30个值有多少个预测正确来计算得到。可以看到KNN在这个问题中的结果是非常不错的,达到了100%的准确率。
总结
鸢尾花的分类包括了完成的机器学习框架,当然,其极大的弱化了数据预处理和模型构建部分。下一篇文章会继续探索鸢尾花的不同特征对的分类结果影响。