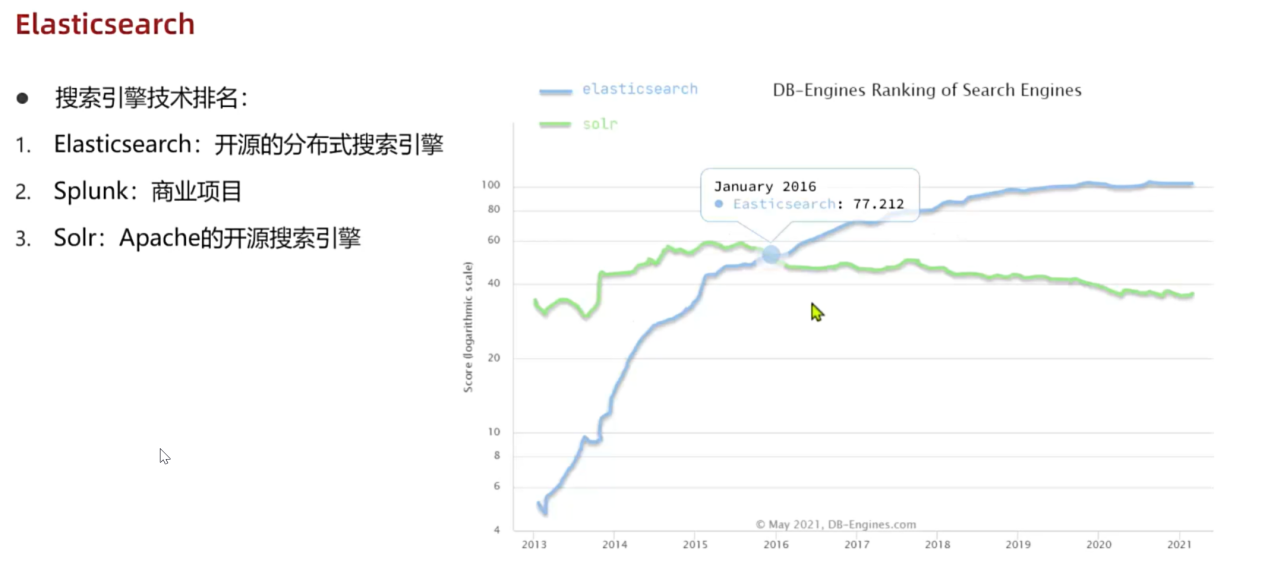
1.搜索引擎技术排名:
1.Elasticsearch:开源的分布式搜索引擎
2.Splunk:商业项目
3.Solr:Apache的开源搜索引擎
2.认识和安装
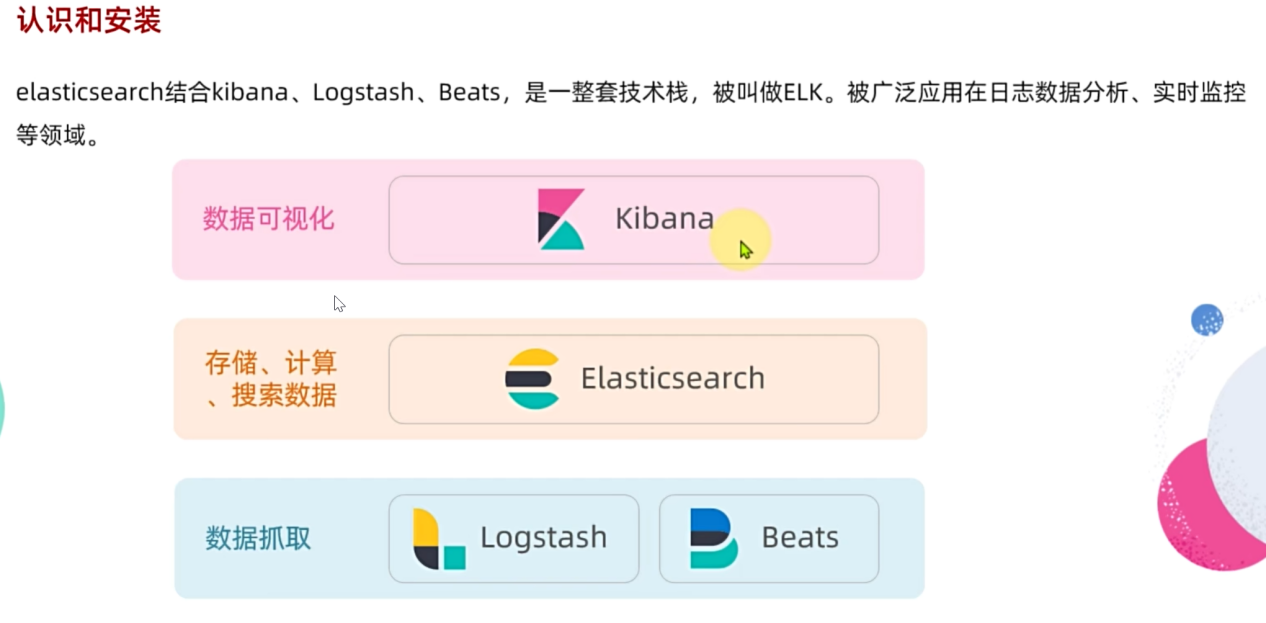
Elasticsearch结合kibana、Logstash、Beats,是一整套技术栈,被叫做ELK。被广泛应用在日志数据分析、实时监控等领域。
3.倒排索引:
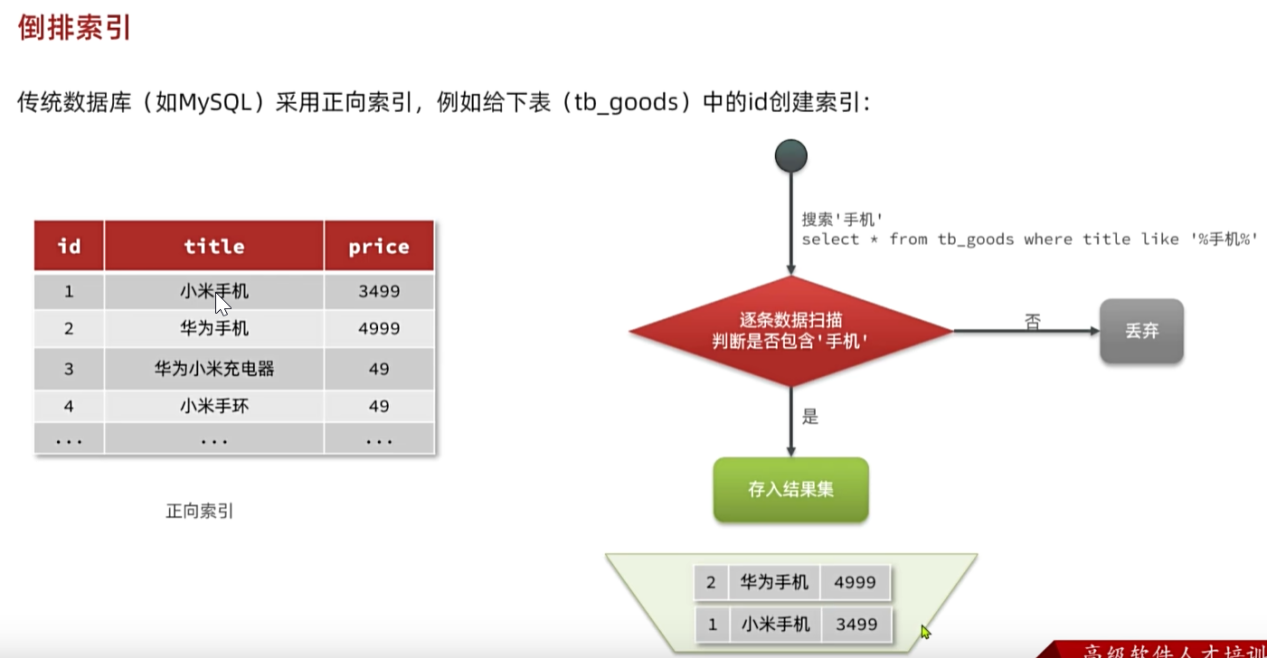
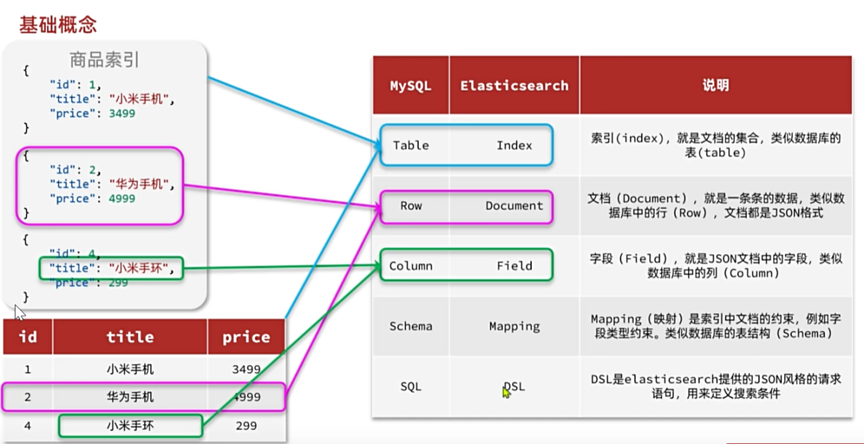
传统数据库(MySQL)采用正向索引,例如给下表(tb_goods)中的id创建索引:
Elasticsearch采用倒排索引:
文档(document):每条数据就是一个文档,对文档中的内容分词,得到的词语就是词条
词条(term):文档按语义分成的词语
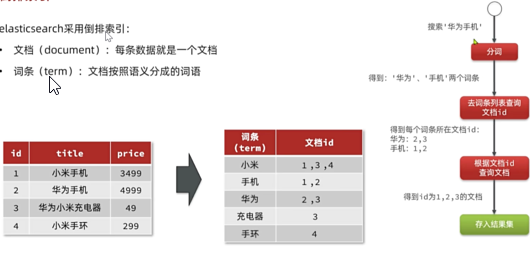
正向索引:基于文档id创建索引。根据id查询快,但是查询词条时必须先找到文档,而后判断是否包含词条
倒排索引:对文档内容分词,对词条创建索引,并记录词条所在文档的id.查询时先根据词条查询到文档id,而后根据文档id查询文档
4.IK分词器
IK分词器:中文分词器往往根据语义分析,比较复杂,这就需要用到中文分词器,例如IK分词器,IK分词器是林良益在2006年开源发布的,其采用的正向迭代最细颗粒度切分算法一直沿用至今。
POST /_analyze[ZW(1](#[ZW(1])
{
"analyzer":"standard",
"text":"xxxxx"
}
POST:请求方式
/_analyze:请求路径
请求参数,json风格:
Analyzer:分词器类型,这里是默认的standard分词器。
Text:要分词的内容。
分词器的作用:1.创建倒排索引时,对文档分词;2.用户搜索时,对输入的内容分词
IK分词器有几种模式?1.ik_smart:智能切分,粗粒度;2.ik_max_word:最细切分,细粒度IK分词器
扩展分词器词库中的词条:1.利用config目录的ikAnalyzer.cfg.xml文件添加拓展词典 2.在词典中添加拓展词条。
5.索引与映射
索引(index):相同类型的文档的集合
映射(mapping):索引中文档的字段约束信息,类似表的结构约束
Mapping是对索引库中文档的约束,常见的mapping属性包括:
1.type:字段数据类型,常见的简单类型有:
字符串:text(可分词的文本)、keyword(精确值)
数值:long、integer、short、byte、double、float
布尔:boolean
日期:date
对象:object
2.index:是否创建索引,默认为true
3.analyzer:使用哪种分词器
4.properties:该字段的子字段
索引是为了搜索或者排序
6.索引库操作:
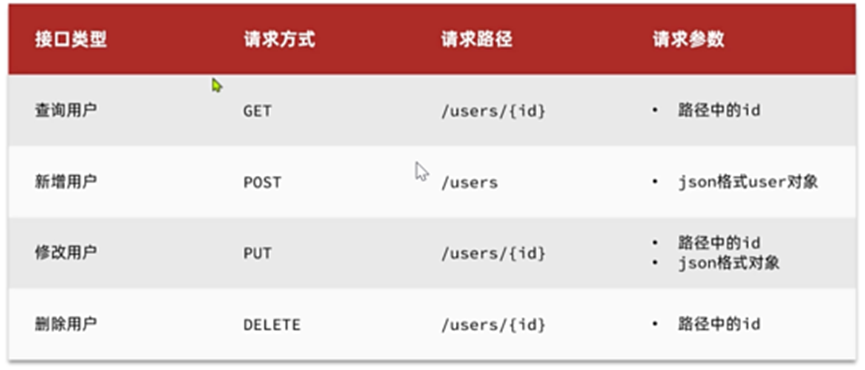
Elasticsearch提供的所有API都是Restful的接口,遵循Restful的基本规范:

查看索引库语法:
GET /索引库名
删除索引库的语法:
DELETE /索引库名
索引库和mapping一旦创建无法修改,但是可以添加新的字段,语法如下:

修改已有字段不可以,添加新的字段可以
索引库操作有哪些?
创建索引库:PUT/索引库名
查询索引库:GET/索引库名
删除索引库:DELETE/索引库名
添加字段:PUT/索引库名/_mapping
7.文档CRUD:
新增文档的请求格式如下:
POST/索引库名/_doc/文档id
{
"字段1":"值1",
"字段2":"值2",
"字段3":{
"子属性1":"值3",
"子属性2":"值4"
}"
}
修改文档:方式一:全量修改,会删除旧文档,添加新文档
PUT /索引名/_doc/文档id
{
"字段1":"值1",
"字段2":"值2",
}
方式二:增量修改,修改指定字段值
POST /索引库名/_update/文档id
{
"doc":{
"字段名":"新的值",
}
}

8.客户端初始化es:
1.引入es的RestHighLevelClient依赖:

2.因为SpringBoot默认的ES版本为7.17.0,所以我们需要覆盖默认的ES版本:如需要指定版本的ES:

3.初始化RestHighLevelClient:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.xx.xx:xxx")
));
9.用javaAPI方式进行创建、删除、查询索引库、对文档CRUD
(1)创建索引库javaAPI:
@Test
Void testCreateHotelIndex() throws IOException{
CreateIndexRequest request = new CreateIndexRequest("items");
//2.请求参数,MAPPING_TEMPLATE是静态常量字符串,内容是JSON格式请求体
Request.source(MAPPING_TEMPLATE,XcontentType.JSON);
Client.indices().create(request,RequestOptions.DEFAULT);
}
(2)删除索引库:
@Test
void testDeleteHotelIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("indexName");
Client.indices().delete(request,RequestOptions.DEFAULT);
}
(3)查询索引库信息:
@Test
Void testExistsHotelIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("indexName");
Client.indices().get(request,RequestOptions.DEFAULT);
}
(4)新增文档的javaAPI如下:
@Test
Void testIndexDocument() throws IOException{
IndexRequest request = new IndexRequest("indexName").id("1");
Request.source("{\"name\":\"Jack\",\"age\":21}",XContentType.JSON);
Client.index(request,RequestOptions.DEFAULT);
}
(5)删除文档的javaAPI如下:
@Test
Void testDeleteDocumentById() throws IOException {
DeleteRequest request = new DeleteRequest("indexName","1");
//删除文档
client.delete(request,RequestOption.DEFAULT);
}
(6)查询文档包含查询和解析响应结果两部分
@Test
Void testGetDocumentByid( ) throws IOException {
//创建request对象
GetRequest request = new GetRequest("indexName","1");
//发送请求,得到结果
GetResponse response = client.get(request,RequestOptions.DEFAULT);
//解析结果
String json = response.getSourceAsString( );
System.out.println(json);
}
文档操作两种方式:
方式一:全量更新。再次写入id一样的文档,就会删除旧文档,添加新文档。与新增的javaAPI一致
方法二:局部更新。只更新指定部分字段
@Test
Void testUpdateDocumentByid() throws IOException {
UpdateRequest request = new UpdateRequest("indexName","1");
Request.doc(xxxx);
Client.update(request,RequestOptions.DEFAULT);
}
(7)文档操作的基本步骤:
1.初始化RestHighLevelClient
2.创建XXXRequest.XXX是index、get、update、delete
3.准备参数(index和Update时需要)
4.发送请求。调用RestHighLevelClient#.xxx()方法,xxx是index、get、update、delete
5.解析结果(get时需要)
(8)批处理:
构建请求会用到一个名为BulkRequest来封装普通的CRUD请求
批处理API示例:
@Test
Void testBulk() throws IOException{
BulkRequest request = new BulkRequest();
//2.添加要批量提交的请求:以添加两个新增文档的请求为例:
Request.add(new IndexRequest("indexName")).id("101").source("json source",XcontentType.JSON));
Request.add(new IndexRequest("indexName").id("102").source("json source",XcontentType.JSON));
//发起bulk请求
Client.bulk(request,RequestOptions.DEFAULT);
}
10.DSL查询可以分为两大类:
叶子查询:一般在特定的字段里查询特定值,属于简单查询,很少单独使用。
复合查询:以逻辑方式组合多个叶子查询或者更改叶子查询的行为方式。
在查询以后,还可以对查询的结果做处理,包括:
1.排序:按照1个或多个字段值做排序
2.分页:根据from和size做分页,类似MySQL
3.高亮:对搜索结果中的关键字添加特殊样式,使其更加醒目
4.聚合:对搜索结果做数据统计以形成报表
查询所有
GET /indexName/_search
{
"query":{
"match_all":{
}
}
}
ES单次查询最大数据不能超过10000个
全文检索查询:利用分词器对用户输入内容分词,然后去词条列表中匹配。例如:match_query、multi_match_query
精确查询:不对用户输入内容分词,直接精确匹配,一般是查找keyword、数值、日期、布尔等类型。例如:ids、range、term
地理查询:用于搜索地理位置,搜索方式很多。例如:geo_distance、geo_bounding_box
Match查询:全文检索查询的一种,会对用户输入内容分词,然后去倒排索引库检索:
GET /indexName/_search
{
"query":{
"match":{
"FIELD":"TEXT"
}
}
}
Multi_match:与match查询类似,只不过允许同时查询多个字段
GET /indexName/_search
{
"query":{
"multi_match":{
"query":"TEXT",
"fields":"FIELD1","FIELD12"
}
}
}
全文检索有得分,默认按照得分排名显示
精确查询:词条级别查询,不对用户输入的搜索条件再分词,作为一个词条,与搜索的字段内容精确值匹配。所以推荐查找keyword、数值、日期、boolean类型的字段
全文检索查询:Match和multi_match的区别:match根据一个字段查询,multi_match:根据多个字段查询,参与查询字段越多,查询性能越差
精确查询:term查询:根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段 range查询:根据数值范围查询,可以是数值、日期的范围
11.复合查询
1.基于逻辑运算组合叶子查询,实现组合条件,bool;2.基于某种算法修改查询时的文档相关性算分,从而改变文档排名。Function_score、dis_max
布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
Must:必须匹配每个子查询,类似"与"
Should:选择性匹配子查询,类似"或"
Must_not:必须不匹配,不参与算分,类似"非"
Filter:必须匹配,不参与算分

排序和分页
ES支持对搜索结果排序,默认是根据相关度算分(_score)来排序,也可以指定字段排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
GET /indexName/_search
{
"query"{
"match_all":{}
},
"sort"[
{
"FIELD":"desc"//排序字段和排序方式ASC、DESC
}
]
}
ES默认情况下只返回top10的数据。如果想要查询更多数据就需要修改分页参数,ES中通过修改from、size参数来控制要返回的分页结果:
From:从第几个文档开始
Size:总共查询几个文档
GET /items/_search
{
"query":{
"match_all":{}
},
"from":0,//分页开始的位置,默认为0、表示从第几条记录开始(默认为0,表示从第一条开始)
"size":10,期望获取的文档总数
"sort":[
{"price": "asc"}
]
}
12.深度分页问题:
ES的数据一般采用分片存储,将一个索引中的数据分成N份,存储到不同节点上。查询数据时需要汇总各个分片的数据。
查找第100页数据,每页查找10条:
GET /hotel/_search
{
"from": 990,
"size": 10,
}
对数据排序,并找出第990-1000名数据
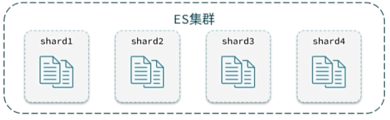
深度分页问题:有两种方案:search after分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。Scroll:原理将排序数据形成快照,保存在内存。
Search after模式:
优点:没有查询上限,支持深度分页
缺点:只能向后逐页查询,不能随机翻页
场景:数据迁移,手机滚动查询
13.es的api操作:
(1)搜索完整语法:
GET /item/_search
{
"query":{
"match":{
"name":"小米"
}
},
"from":0//分页开始的位置
"size":20//期望获取的文档总数
"sort":[
{"price":"asc"},//普通排序
],
"highlight":{
"fields":{//高亮字段
"name":{
"pre_tags":"<em>",//高亮字段的前置标签
"post_tags":"</em>"//高亮字段的后置标签
}
}
}
}
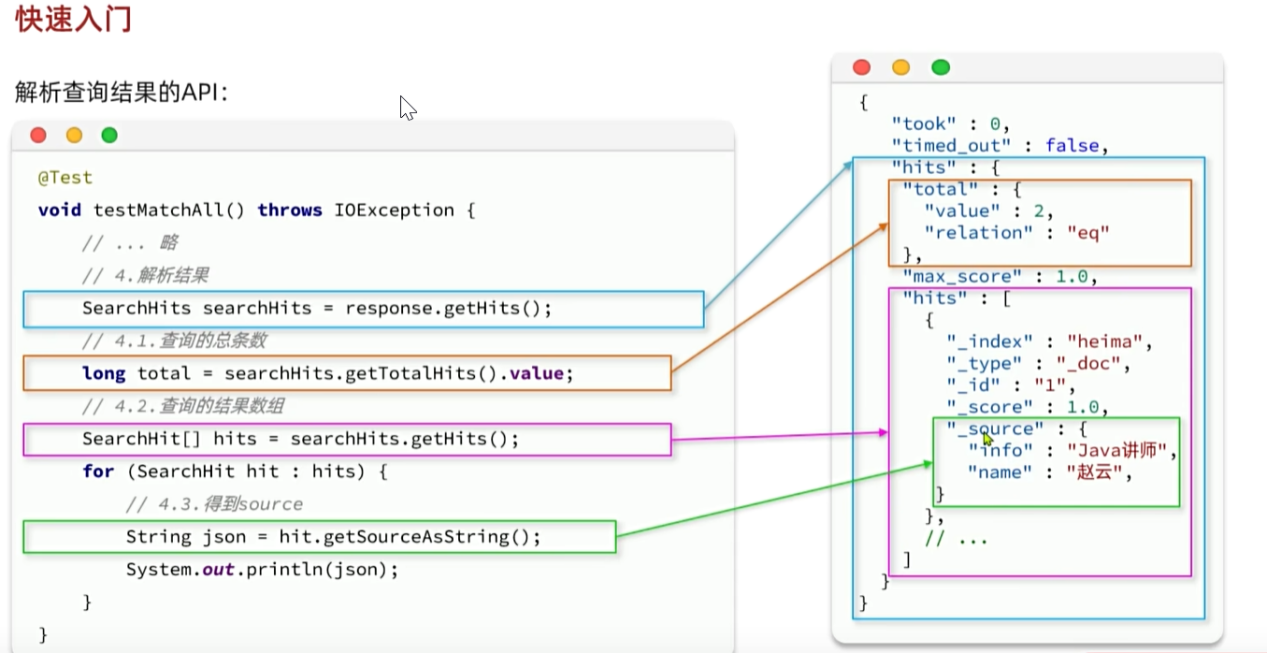
对应的Java后端写法:
@Test
Void testMatchAll( ) throw IOException {
//准备Request
SearchRequest request = new SearchRequest("indexName");
//组织DSL参数
request.source( ).query(QueryBuliders.matchAllQuery());
//发送请求,得到响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
}
全文检索的查询条件构造API如下:
Java后端语句QueryBuilders.matchQuery("name","脱脂牛奶")
和下面查询语句一样
GET /items/_search
{
"query":{
"match:{
"name":"脱脂牛奶"
}"
}
}
Java后端语句QueryBuilders.multiMatchQuery("脱脂牛奶","name","category");
和下面查询语句一样
GET /items/_search
{
"query":{
"multi_match":{
"query":"脱脂牛奶",
"field":"category","name"
}
}
}
(2)精确查询
Java后端语句QueryBuilders.termQuery("category","牛奶");//词条查询
和下面查询语句一样
GET /items/_search
{
"query":{
"item":{
"category":"牛奶"
}
}
}
Java后端语句QueryBuilders.rangeQuery("price").gte(100).lte(150)//范围查询gte、lte大于,小于
和下面查询语句一样
GET /items/_search
{
"query":{
"range":{
"price":{"gte":100,"lte":150}
}
}
}
Java后端语句布尔查询的查询条件
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();//创建布尔查询
boolQuery.must(QueryBuilders.termQuery("brand","华为"));//添加must条件
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(2500));//添加filter条件
上述布尔查询的条件语句和下面一样
GET /items/_search
{
"query":{
"bool":{
"must":[
{
"term": {"brand":"华为"}
}
],
"filter":[
{
"range":{
"price":{"lte":2500}
}
}
]
}
}
}
Java后端语句主要使用的是querybuilders来构建查询条件来实现对es内部操作一样的语句
与query类似,排序和分页参数都是基于request.source()来设置:
request.source().query(QueryBuilders.matchAllQuery());//查询
request.source().from(0).size(5)//分页
request.source().sort("price",SortOrder.ASC);
上述查询与分页语句和下面可视化窗口语句一样
GET /indexName/_search
{
"query":{
"match_all":{ }
},
"from":0,
"size":5,
"sort":[
{
"FIELD":"desc"
}
]
}
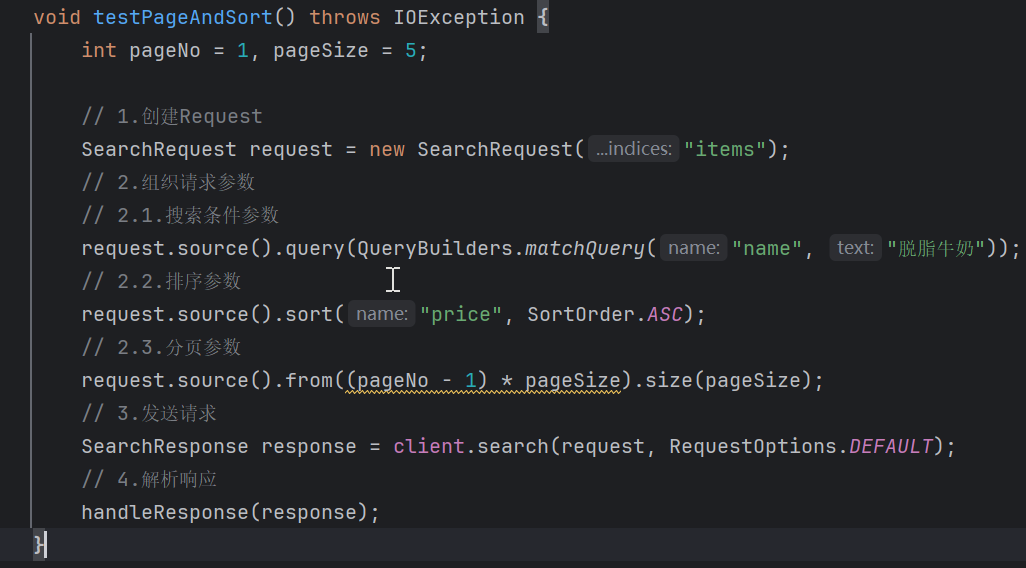
Java后端语句request.source().highlight(
SearchSourceBuilder.highlight()
.field("name")
.preTags("<em>")
.postTags("</em>")
)
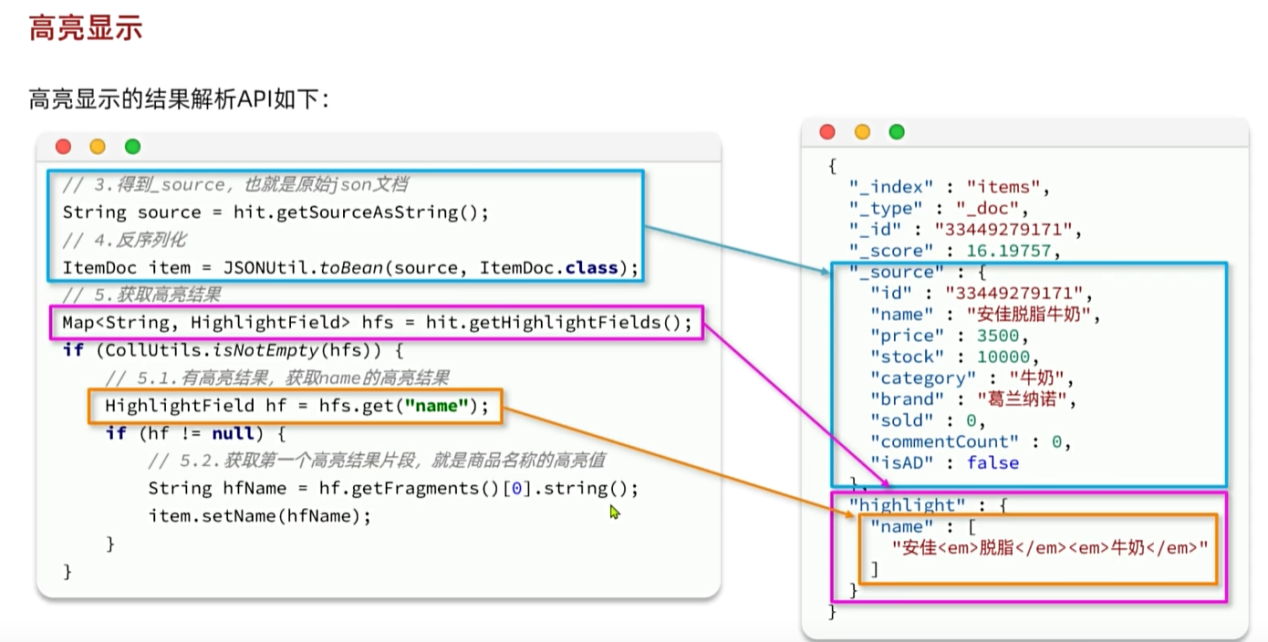
上述高亮显示语句与可视化窗口中的语句效果一致:
GET /items/_search
{
"query":{
"match":{
"name":"脱脂牛奶"
}
},
"highlight":{
"fields":{
"name"{
"pre_tags":"<em>",
"post_tags":"</em>"
}
}
}
}
14.数据聚合
数据聚合:可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
桶(Bucket)聚合:用来对文档做分组
TermAggregation:按照文档字段值分组
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
Avg:求平均值
Max:求最大值
Min:求最小值
Stats:同时求max、min、avg、sum等
管道(pipeline)聚合:其他聚合的结果为基础做聚合
参与聚合的字段必须是Keyword、数值、日期、布尔的类型的字段。
15.DSL聚合
统计所有商品中共有哪些商品分类,其实就是以分类(category)字段对数据分组。Category值一样的放在同一组,属于bucket聚合中的term聚合。
GET /items/_search
{
"query":{"match_all":{}},
"size":0, //设置size
"args":{
"cateAgg":{
"terms":{
"field":"category",
"size":20
}
}
}
}
}
默认情况下,Bucket聚合是对索引库的所有文档做聚合,可以限定聚合范围,加入query条件即可
对每个bukect内的数据进一步做数据计算和统计