在日常运维工作中,Linux服务器性能故障是最常见也是最耗时间的问题之一。一次跨境电商促销高峰,我遇到一台香港服务器在流量高峰时段 CPU 利用率暴涨、I/O 等待严重、响应变慢,客户订单提交延迟甚至失败。通过系统化使用 top、htop、iostat 等工具,我最终定位到瓶颈是磁盘 I/O 饱和 + 单个进程异常消耗导致的。
一、环境概况:硬件配置 & 基线参数
| 项目 | 配置/数值 |
|---|---|
| 香港服务器型号 | Supermicro 1U 机架式 |
| CPU | Intel Xeon Silver 4214, 12 核 24 线程 |
| 内存 | 64GB DDR4 ECC |
| 磁盘 | 2× 1TB NVMe SSD (Samsung PM1733) |
| RAID | None(裸盘) |
| 操作系统 | Ubuntu Server 22.04 LTS (Linux kernel 5.15) |
| 业务 | 跨境电商 Web + API 服务 |
| 高可用 | NGINX + Gunicorn (Python) + MySQL 8.0 |
在本次案例中,我们使用的A5数据的香港服务器www.a5idc.com配置中等偏上,但在高并发场景下仍出现性能瓶颈。基线评估是排查的第一步。
二、性能问题现象
用户反馈促销高峰期间 API 响应变慢、页面加载延迟,并最终出现 500 错误。
初步监控数据显示:
- CPU 利用率在 80%~95% 波动
- I/O 等待(
%iowait)持续飙升 - 响应时间骤升
我们要排查的问题是:
- 是 CPU 饱和还是 I/O 瓶颈?
- 哪些进程占用资源?
- 系统整体资源利用情况?
三、工具与原理简介
我们主要依次使用:
| 工具 | 功能 |
|---|---|
top |
实时查看系统负载、CPU/内存统计、进程资源占用 |
htop |
更友好的交互式进程监控工具 |
iostat(来自 sysstat) |
查看块设备 I/O 负载和性能指标 |
vmstat |
系统整体资源统计(内存、进程、IO、CPU) |
四、实战排查步骤
1️⃣ 使用 top 快速扫一遍瓶颈
bash
sudo top -b -n 1输出核心部分解析:
top - 15:12:30 up 10 days, 2:34, 2 users, load average: 8.12, 7.93, 7.85
Tasks: 243 total, 2 running, 241 sleeping, 0 stopped, 0 zombie
%Cpu(s): 87.5 us, 5.2 sy, 0.0 ni, 3.0 id, 4.3 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 65896956 total, 12233480 free, 39573368 used, 14090108 buff/cache
KiB Swap: 2097148 total, 1805128 free, 292020 used. 24012188 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2872 www-data 20 0 512.3m 103.5m 24.3m R 132.8 0.16 2434:52 gunicorn
1443 mysql 20 0 1421.2m 321.4m 53.2m S 12.1 0.49 120:10 mysqld
...结论:
%iowait达到 4.3%(提示 I/O 等待偏高)- 单个进程
gunicornCPU 占用高达 132.8%(多线程/多核叠加) mysqld内存占用也不小
2️⃣ 使用 htop 交互式定位
bash
sudo apt install -y htop
sudo htop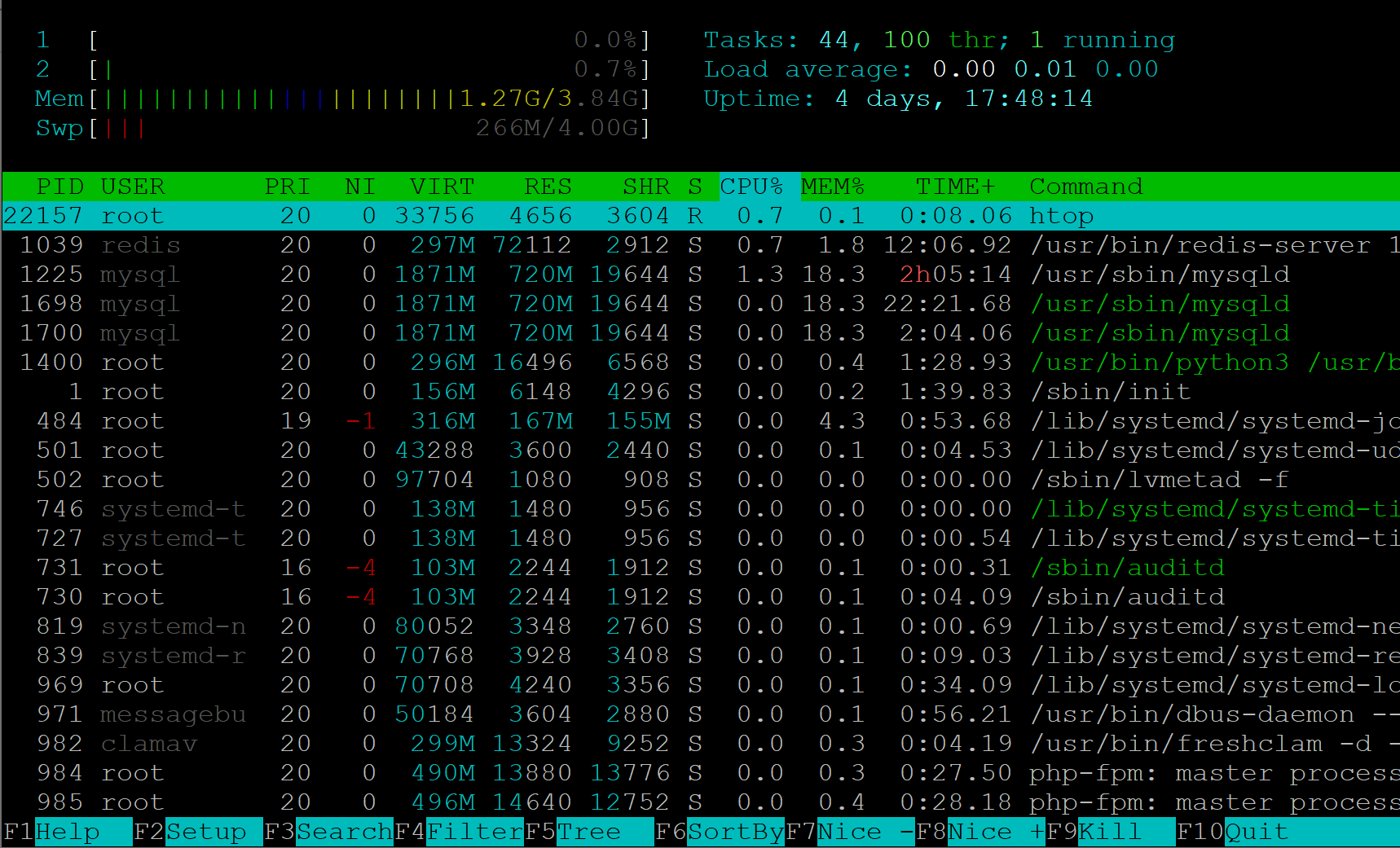
在 htop 里可:
- 按
%CPU排序(F6 → CPU%) - 按
%MEM排序(F6 → MEM%) - 观察线程与进程树(F5)
优势:
- 更直观识别短时间内高占用进程
- 可立刻查看线程/子进程行为
3️⃣ 使用 iostat 进一步确认 I/O 瓶颈
首先安装:
bash
sudo apt update
sudo apt install -y sysstat执行:
bash
iostat -x 5 3示例输出:
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s r_await w_await svctm %util
nvme0n1 25.2 121.5 1024 7568 0.0 2.4 7.11 42.33 1.23 98.12
nvme1n1 0.8 10.3 64 712 0.2 1.3 1.50 12.42 0.85 10.54解释:
%util~98% 表示nvme0n1设备几乎饱和w_await(~42ms 远高于理想值 <10ms) 表示写等待高
表格整理(异常 vs 正常参考):
| 指标 | 当前值 | 正常参考 | 说明 |
|---|---|---|---|
| %util | 98% | <70% | 设备繁忙 |
| r_await | 7ms | <5ms | 读响应略高 |
| w_await | 42ms | <10ms | 写延迟严重 |
4️⃣ 使用 vmstat 纵览全局状态
bash
vmstat 5 5示例:
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 1 292020 12233480 14090108 24012188 0 32 204 628 99 144 87 5 3 4 0关键观察:
b>0 表示有进程在等待 I/Owa>0 表示 CPU 有等待 I/O 的时间si/so不高表示 Swap 未频繁触发
五、典型案例故障定位
我在实际排查时发现:
✅ 问题一:单进程 CPU 超高
通过 top 和 htop 定位到 gunicorn 某 worker 占用率异常。
调试:
bash
# 查看进程具体线程
ps -Lp 2872 -o pid,tid,pcpu,psr,comm发现某线程反复执行特定逻辑导致循环 CPU 消耗。
解决: 优化代码逻辑 / 限制 worker 数量为 CPU 核心数。
✅ 问题二:磁盘写 I/O 饱和
观察 iostat 指标:
nvme0n1写等待高,%util达 98%- 业务日志 + 数据库写都落在该盘
解决方案:
| 措施 | 效果 |
|---|---|
| 将日志落盘迁移到独立 NVMe RAID1 | 降低主盘写负载 |
开启数据库 innodb_flush_log_at_trx_commit=2 |
减少每事务 fsync 频率 |
| 使用批写入 | 降低写 IOPS 压力 |
六、性能调优建议
📌 CPU
bash
# 提高 Gunicorn worker 数
gunicorn -w 24 --threads 4 app:app
# 或使用更高效的 async worker
gunicorn -k uvicorn.workers.UvicornWorker app:app📌 I/O 优化
编辑 /etc/fstab:
/dev/nvme0n1 /data ext4 defaults,noatime,nodiratime 0 2开启 noatime 降低写放大。
七、踩坑提醒
- 不要只看单一监控,某个时刻的 spike 可能是暂时行为。
- 时间窗口要足够长 :使用
sar历史指标分析趋势。 - 理解每个指标含义 :例如
%iowait不是 CPU 忙而不做事,它代表等待 I/O。
八、结语
通过 top、htop、iostat、vmstat 等Linux原生工具,我们可以从不同维度进行性能排查,从CPU、内存、I/O 到进程行为全面分析系统状态。任何性能故障都可以拆分为更小粒度的问题,再结合产线监控指标(如 Prometheus + Grafana),形成周期性的性能评估机制。