引言:你可能一直在用错Cursor
周末改个功能,给Cursor描述需求后,它疯狂修改了10个文件,结果项目跑不起来了。回滚代码重来,这次小心翼翼地问了个简单问题,它却只讲理论不写代码。
这些场景是否似曾相识?
场景1:Agent模式改过头
"帮我在导航栏添加一个搜索框"
结果:AI重构了整个Header组件,连样式文件都改了,原本的功能全乱套了。
场景2:Ask模式不干活
"实现一个用户登录功能"
结果:AI写了1000字的技术方案和安全建议,但就是不写代码。
场景3:大需求直接扔给Agent
"给项目添加完整的权限系统"
结果:AI瞎写一通,数据库表设计有问题,前端鉴权逻辑也不对,还不如自己写。
场景4:Bug找不到根因
"用户偶尔会遇到支付失败,但日志里没有异常"
结果:传统调试手段失效,AI也只能靠猜,问题始终定位不到。
问题出在哪?
"Cursor的4种模式就像4种不同的武器,用错了不仅没效果,还可能适得其反。"
很多人只知道Cursor能"聊天写代码",却不知道它有4种完全不同的工作模式,每种模式的权限级别、适用场景、工作机制都不一样。
本文目标:
- ✅ 深度理解4种模式的设计理念和工作原理
- ✅ 掌握每种模式的最佳适用场景和边界
- ✅ 学会避开常见的模式误用陷阱
- ✅ 掌握模式组合使用的高级技巧
模式概览:4种模式的本质区别
快速对比:四大模式的核心差异
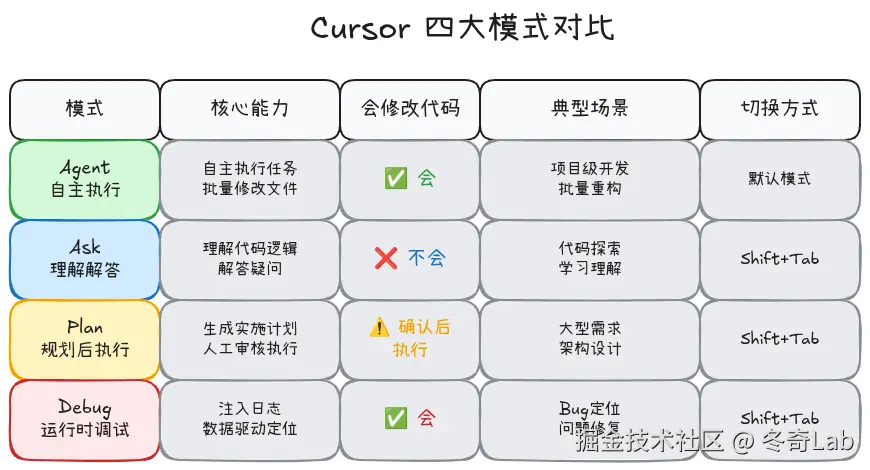
权限级别:从只读到自主执行
理解模式的关键在于权限级别:
rust
高权限 (可自主修改代码)
├─ Agent 模式: 完全自主,批量修改
└─ Debug 模式: 插入日志,精准修复
中权限 (需要确认后执行)
└─ Plan 模式: 生成方案,人工审核
低权限 (只读,不修改)
└─ Ask 模式: 纯理解,安全探索为什么需要权限分级?
- Agent权限太高: 小心翼翼用于已清晰的需求
- Ask权限太低: 放心大胆用于探索陌生代码
- Plan介于两者: 大需求先规划后执行,可控性高
- Debug专项能力: 针对Bug的特殊工作流
模式选择决策树
当你打开Cursor Chat,如何快速选择正确的模式?
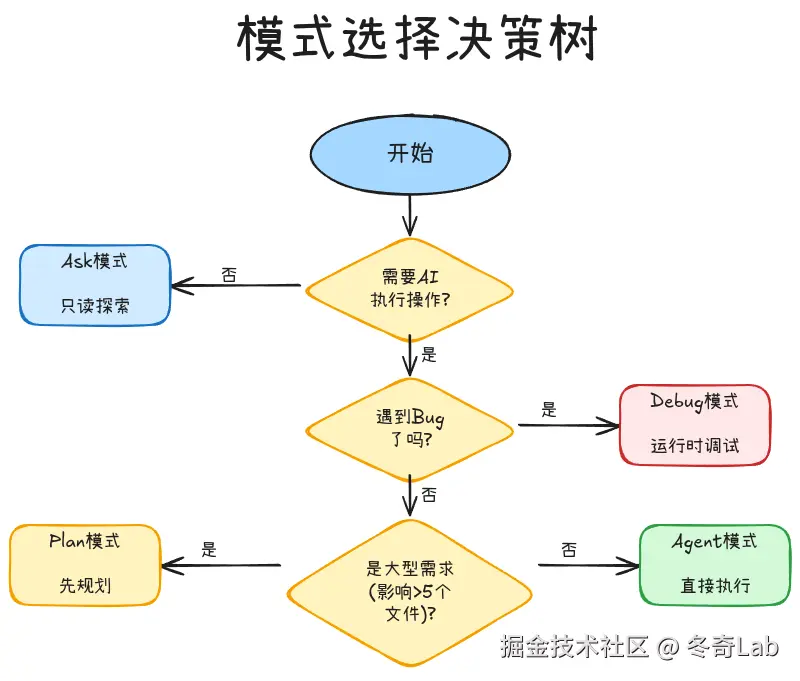
**快速判断法则**: 不确定用哪个?从低权限开始(Ask)→中权限(Plan)→高权限(Agent)。权限升级容易,降级难。
Agent模式:你的自动化工程助手
工作原理:5步自主执行
Agent模式是Cursor最强大的模式,它的工作流程:
markdown
用户需求
↓
1. 理解需求 → 分析项目上下文
↓
2. 制定计划 → 确定要修改哪些文件
↓
3. 探索代码 → 搜索相关实现
↓
4. 执行修改 → 批量修改多个文件
↓
5. 自主验证 → 检查语法和逻辑关键特点:
- 可以同时修改多个文件
- 可以创建新文件和目录
- 可以执行bash命令
- 可以自主搜索和分析代码
最适合的3个场景
场景1:跨文件功能实现
需求: "给所有API接口添加统一的错误处理和日志记录"
为什么用Agent: 涉及多个文件,需要统一处理模式
完整Prompt示例:
markdown
为项目中所有的API路由添加统一的错误处理:
1. 使用try-catch包裹所有路由处理函数
2. 添加详细的错误日志(包含请求ID、用户ID、时间戳)
3. 返回统一格式的错误响应:{code, message, requestId}
4. 保持现有功能和逻辑不变
参考:@file src/middleware/errorHandler.ts 的错误处理风格Agent的执行过程:
- 扫描
src/routes/找到15个路由文件 - 分析每个文件的现有结构
- 创建
src/utils/apiErrorHandler.ts统一工具 - 逐个文件添加错误处理
- 更新
src/middleware/logger.ts增强日志
效果对比:
- 修改文件: 17个(15个路由 + 2个新工具文件)
- 耗时: 3分钟
- 传统手工: 预计2小时
- 代码一致性: 完美统一
场景2:项目初始化和脚手架
需求: "创建一个Next.js 15项目,集成TypeScript + TailwindCSS + Shadcn/UI + Drizzle ORM"
为什么用Agent: 涉及大量配置文件和依赖安装
Prompt示例:
markdown
初始化一个现代化的Next.js项目:
1. 使用App Router(不要Pages Router)
2. 配置TypeScript严格模式
3. 集成TailwindCSS和Shadcn/UI
4. 配置Drizzle ORM连接PostgreSQL
5. 创建基础目录结构:components/lib/app/db
6. 添加.env.example模板
生成后帮我运行npm installAgent的能力展示:
- 创建20+个文件
- 安装15+个依赖
- 配置5个工具(ESLint/Prettier/TypeScript等)
- 生成示例代码
- 全程无需手动操作
场景3:批量代码重构
需求: "将项目中所有的class组件改为函数组件(使用Hooks)"
为什么用Agent: 机械性重复工作,容易出错
Prompt示例:
markdown
重构项目中的所有React class组件为函数组件:
1. 只修改@folder src/components目录
2. 转换规则:
- componentDidMount → useEffect
- this.state → useState
- this.props → 函数参数
3. 保持组件功能完全一致
4. 保留所有注释和PropTypes
5. 每改完一个文件就测试编译风险控制:
- Agent会逐个文件处理,不是一次性全改
- 你可以随时中断和回滚
- 建议先git commit保存当前状态
Agent模式的边界和陷阱
❌ 不适合的场景
1. 需求不明确时
makefile
❌ 差的需求: "帮我优化一下首页"
问题: 你自己都不知道要优化什么,AI更瞎猜
后果: Agent可能改一堆无关的代码
✅ 正确做法: 先用Ask模式探索问题,明确需求后再用Agent2. 核心业务逻辑
makefile
❌ 差的需求: "实现支付系统的风控逻辑"
问题: 业务规则复杂,AI理解可能有偏差
后果: 风控漏洞,资损风险
✅ 正确做法: 自己设计算法,用Agent辅助实现边缘功能3. 精细化UI调整
makefile
❌ 差的需求: "把这个按钮调得更好看一点"
问题: "好看"的标准主观,需要多次微调
后果: Agent每次都大改,来回折腾效率低
✅ 正确做法: 用Cmd+K内联编辑,手动调整样式Agent模式的高级技巧
技巧1:控制任务颗粒度
markdown
❌ 过于宽泛: "帮我完成用户管理功能"
→ AI不知道要做哪些具体功能,容易做错或做多
✅ 明确细节: "实现用户列表页面,包括:
1. 表格展示(列:姓名/邮箱/角色/状态/注册时间)
2. 分页(每页20条,使用@Codebase中的Pagination组件)
3. 搜索(支持按姓名和邮箱模糊搜索)
4. 角色筛选(下拉菜单:全部/管理员/普通用户)
约束:
- 复用现有的DataTable组件
- API已存在,使用GET /api/users
- 不要修改用户增删改功能"技巧2:用.cursorrules约束行为
在项目根目录创建 .cursorrules 文件:
markdown
# Agent模式约束规则
## 代码修改规范
- 修改前必须先理解现有实现,不要盲目重写
- 保持代码风格一致(参考已有代码)
- 不要删除注释和TODO标记
- 修改超过5个文件时必须向我确认
## 技术栈限制
- 前端只用React Hooks,禁止class组件
- 状态管理统一用Zustand,不要引入Redux
- 样式统一用TailwindCSS,不要写CSS文件
## 安全规范
- 所有用户输入必须验证和转义
- 不要在前端代码中硬编码密钥
- API调用必须有错误处理技巧3:善用"暂停"和"撤销"
Agent执行时你可以:
- 实时查看: 它在改哪个文件,改了什么
- 立即停止: 发现方向不对马上中断(Ctrl+C)
- 给出反馈: "不要改xx文件,只改yy"
- 快速回滚: 用Git撤销所有修改
**血泪教训**: Agent改完代码后,必须review再提交!别盲目信任AI,我见过太多"Agent制造的bug"事故。
Ask模式:安全的只读学习助手
核心价值:理解优于修改
"理解代码比修改代码更重要,Ask模式让你安心探索。"
为什么需要Ask模式?
想象你刚接手一个10万行的老项目:
- ❌ 直接用Agent改?太危险,可能改坏
- ❌ 慢慢读代码?时间不够,看不懂架构
- ✅ 用Ask探索: 安全、快速、深入理解
Ask模式的独特优势:
- 只读权限,绝对不会修改代码
- 可以提问任何问题,无心理负担
- 理解后再决定是否修改,风险可控
最适合的4个场景
场景1:新项目快速onboarding
markdown
Prompt 1: "这个项目的技术栈是什么?主要目录结构和职责?"
AI回答:
- 技术栈: Next.js 14 + TypeScript + TailwindCSS + Prisma
- 目录结构:
- app/: Next.js App Router页面
- components/: 可复用UI组件
- lib/: 工具函数和数据库客户端
- prisma/: 数据库schema
- 数据库: PostgreSQL,使用Prisma ORM
markdown
Prompt 2: "用户认证是怎么实现的?涉及哪些文件?"
AI回答:
- 使用NextAuth.js v5
- 核心文件:
- app/api/auth/[...nextauth]/route.ts: 认证配置
- lib/auth.ts: session和token工具
- middleware.ts: 路由守卫
- 认证流程: OAuth(GitHub/Google) + 邮箱密码
- Session存储: JWT token场景2:理解复杂业务逻辑
markdown
Prompt: "@file src/services/orderProcessor.ts
这个订单处理函数为什么要分3个阶段?
每个阶段失败了会怎么办?"
AI解释:
1. 阶段1-库存锁定:
- 防止超卖
- 失败→订单取消,释放库存
2. 阶段2-支付处理:
- 调用第三方支付
- 失败→自动重试3次,超时回滚库存
3. 阶段3-发货通知:
- 异步通知仓库
- 失败→记录到失败队列,定时重试
设计理念: 最终一致性,每步可回滚场景3:学习优秀代码实现
markdown
Prompt: "项目中的实时通知功能是怎么实现的?
为什么选这个方案?有什么优缺点?"
AI分析:
- 技术选型: Server-Sent Events(SSE),不是WebSocket
- 实现文件: @file app/api/notifications/stream/route.ts
- 选型理由:
✅ 单向推送,简单够用
✅ 自动重连
✅ HTTP协议,易部署
❌ 不支持服务端接收消息
- 适用场景: 通知推送、进度更新、日志流场景4:技术决策支持
markdown
Prompt: "我想添加全文搜索功能,
基于现有架构,应该用Algolia、Meilisearch还是PostgreSQL全文索引?
考虑成本、性能和维护复杂度"
AI建议:
- 当前架构: PostgreSQL数据库,Vercel部署
- 数据量: 约10万条商品数据
- 推荐方案: PostgreSQL全文索引
理由:
✅ 无需额外服务,成本低
✅ 数据同步简单
✅ 10万级性能足够
❌ 搜索功能不如专业方案
- 如果未来数据>100万,再考虑Meilisearch(开源,可自部署)Ask vs Agent:何时切换?
经典工作流:
vbnet
任务: 给项目添加国际化(i18n)支持
Step 1 - Ask模式: "这个项目用的什么框架?有没有i18n方案?"
AI回答: Next.js App Router,没有i18n,推荐next-intl
Step 2 - 自己判断:
- 需要支持中英文
- URL路径要包含语言标识(/en/xxx, /zh/xxx)
- next-intl符合需求
Step 3 - 再次Ask: "能解释一下next-intl的基本用法和配置吗?"
AI讲解: middleware配置、翻译文件结构、使用方法
Step 4 - 切换Agent: "集成next-intl到项目,
支持中英文,URL路径格式为/[locale]/xxx,
参考next-intl官方最佳实践"切换时机判断:
- Ask阶段: 探索、学习、理解
- 自己思考: 确定方案和细节
- Agent阶段: 执行实施
Ask模式的高级技巧
技巧1:精准的上下文引用
markdown
@file src/utils/payment.ts # 精确到单个文件
@folder src/components/ui # 批量分析目录
@Codebase # 全局搜索
@symbol handlePayment # 指定函数或类组合使用:
markdown
"@file src/services/userService.ts 中的
@symbol createUser 函数调用了哪些其他函数?
它们分别在@Codebase的什么位置?"技巧2:对话式深入追问
markdown
第1轮: "这个缓存系统是怎么工作的?"
AI回答: 使用Redis,LRU淘汰策略...
第2轮: "为什么选择LRU而不是LFU?"
AI回答: 业务特点是热点数据变化快...
第3轮: "如果要支持分布式缓存一致性,需要怎么改?"
AI回答: 引入Pub/Sub机制,监听key失效事件...**黄金法则**: 在不确定的情况下,永远先用Ask探索,再用Agent执行。宁可多问几轮,也别让Agent瞎改代码。
Plan模式:大型需求的架构师
独特价值:磨刀不误砍柴工
"大型需求先规划再动手,避免Agent瞎写一通。"
Plan模式解决什么问题?
传统Agent模式的痛点:
- ❌ 大需求直接扔给Agent → 方向跑偏,越改越乱
- ❌ 不知道AI要改哪些文件 → 担心改坏不敢用
- ❌ 需求复杂,自己也没想清楚 → Agent更瞎猜
Plan模式的价值:
- ✅ 生成详细计划,人工审核后再执行
- ✅ 可以修改计划,只执行其中几步
- ✅ 看到计划后发现问题,及时调整
- ✅ 执行过程可控,出问题易回滚
工作流程:先规划,后执行
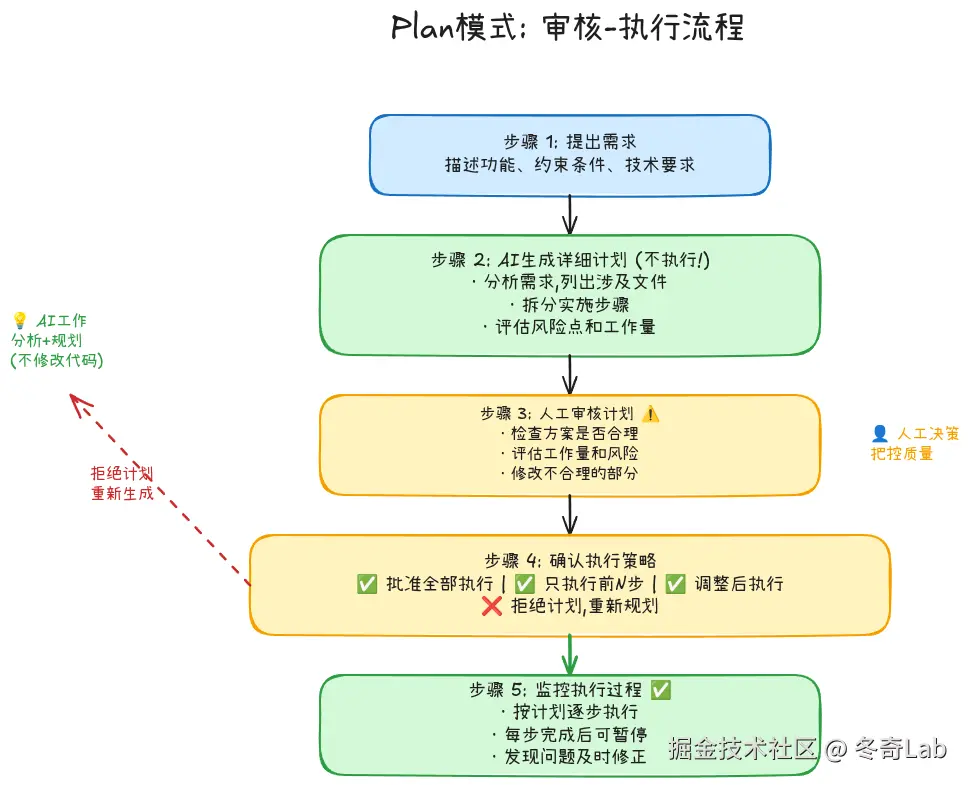
最适合的3个场景
场景1:新功能模块开发
需求: "为电商项目添加完整的购物车功能"
Plan模式的Prompt:
markdown
为项目添加购物车功能,请先生成详细实施计划:
功能需求:
1. 购物车数据管理(增删改查)
2. 库存同步和校验
3. 优惠券应用
4. 结算功能
技术要求:
- 后端API使用RESTful风格
- 前端状态管理用Zustand
- 数据库使用现有的PostgreSQL
请列出:
- 需要创建/修改的文件
- 数据库schema变更
- API接口设计
- 前端组件结构
- 潜在风险点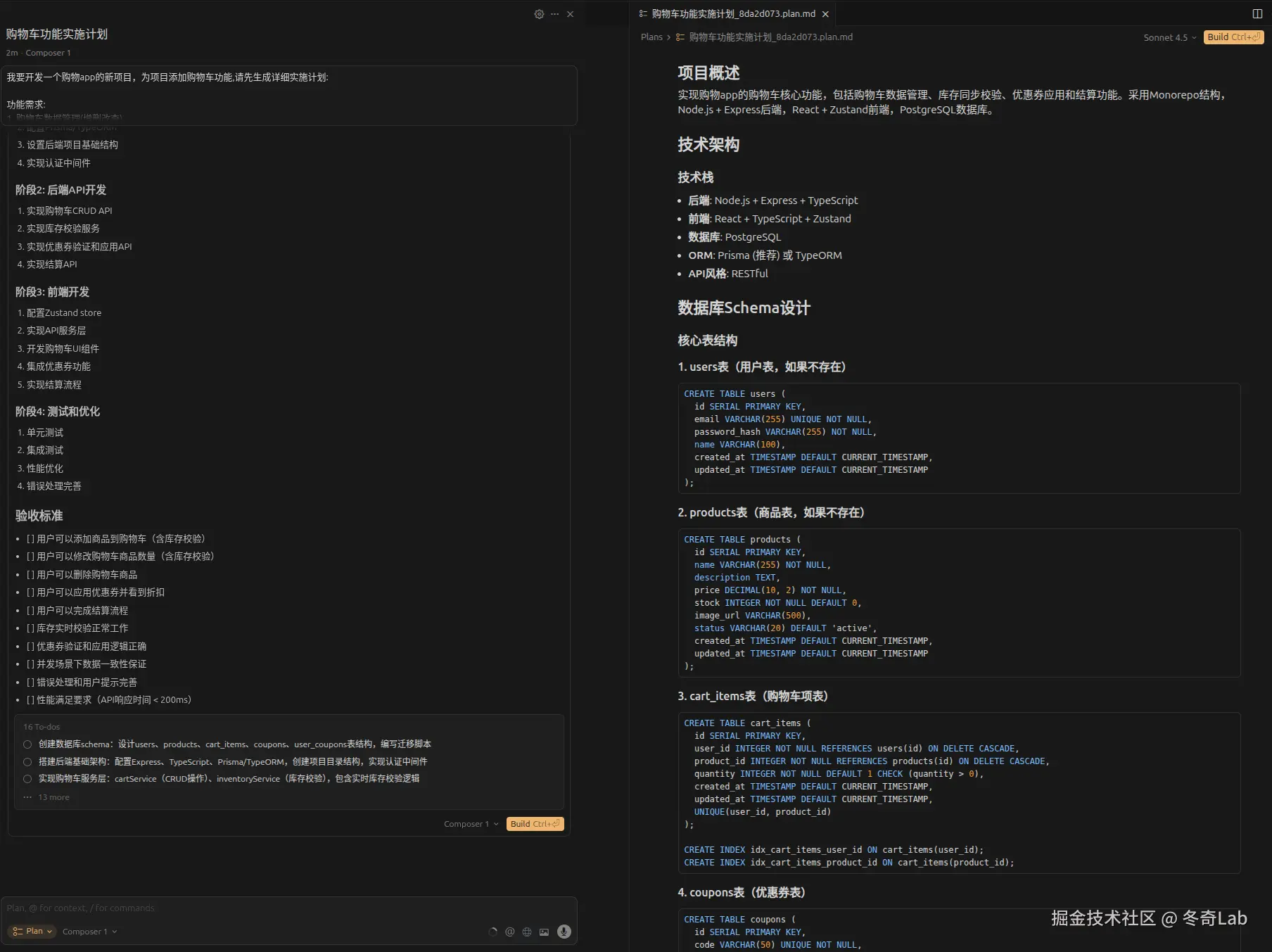
场景2:架构重构
需求: "将单体Next.js应用拆分为前后端分离架构"
Plan的价值:
- 先看整体拆分方案
- 评估工作量(可能需要1-2周)
- 识别高风险模块
- 制定回滚方案
- 分阶段实施,不影响线上
场景3:技术栈升级
需求: "从React 18升级到React 19"
Plan帮你:
- 识别不兼容的API
- 生成迁移清单
- 评估第三方库兼容性
- 制定分批升级策略(先dev分支测试)
- 准备降级预案
Plan vs Agent:什么时候必须用Plan?
必须用Plan的情况:
| 判断标准 | 说明 | 风险级别 |
|---|---|---|
| 影响文件>10个 | 改动范围大,容易失控 | 🔴 高 |
| 数据库schema变更 | 涉及数据迁移,不可逆 | 🔴 高 |
| 核心业务逻辑修改 | 影响线上用户,风险高 | 🔴 高 |
| 需要跨团队协作 | 需要对齐方案,避免冲突 | 🟡 中 |
| 技术选型决策 | 选错了成本高 | 🟡 中 |
可以直接用Agent的情况:
- ✅ 小功能添加(1-3个文件)
- ✅ UI样式调整
- ✅ Bug修复
- ✅ 配置文件修改
- ✅ 工具函数编写
Plan模式的高级用法
技巧1:迭代式规划
markdown
第1轮(高层规划):
"为项目添加支付功能,请生成高层实施计划"
→ AI输出: 3个阶段,8个大步骤
第2轮(细化某个阶段):
"针对'阶段2:支付渠道集成'这一步,
生成详细的实施计划"
→ AI输出: 支付宝/微信接入的详细步骤
第3轮(执行最细粒度):
"执行'集成支付宝SDK'这一步"
→ AI执行具体代码编写技巧2:在.cursorrules中定义计划模板
markdown
# Plan模式输出模板
当我使用Plan模式时,必须按以下格式输出:
## 1. 需求分析
- 核心功能点
- 技术约束
- 预期效果
## 2. 技术方案
- 技术选型及理由
- 架构设计
- 关键技术点
## 3. 实施计划
- 文件清单(创建/修改)
- 分步骤说明(带时间估算)
- 依赖关系
## 4. 风险评估
- 高风险项
- 缓解措施
- 回滚方案
## 5. 测试计划
- 单元测试覆盖
- 集成测试场景
- 性能测试指标**何时从Plan切换到Agent**: 当你看完计划觉得"嗯,就这么干!"时,就可以批准执行了。如果还有疑虑,继续追问AI细化计划。
Debug模式:运行时调试革命
突破性创新:从"猜测"到"数据驱动"
传统调试方式的痛点:
markdown
传统调试流程:
1. 复现bug → 不一定能复现
2. 打断点/加日志 → 猜测问题点
3. 分析日志 → 日志不够详细
4. 猜测原因 → 凭经验瞎猜
5. 改代码试错 → 可能改错地方
6. 重复2-5 → 浪费大量时间Cursor Debug模式的革命性突破:
markdown
Debug模式流程:
1. 描述bug现象 → AI生成多个假设
2. AI注入调试代码 → 精准插入日志
3. 复现bug → 自动收集运行时数据
4. AI分析数据 → 基于真实数据定位
5. AI提出修复 → 精准修改2-3行
6. 验证修复 → AI清理调试代码核心优势对比:
| 维度 | 传统调试 | Cursor Debug模式 |
|---|---|---|
| 定位方式 | 猜测+试错 | 数据驱动分析 |
| 日志插入 | 手动猜测位置 | AI自动注入关键点 |
| 问题复现 | 需要手动复现 | 引导你如何复现 |
| 修复精度 | 可能改错地方 | 精准定位到具体代码行 |
| 调试代码清理 | 容易遗漏 | AI自动清理 |
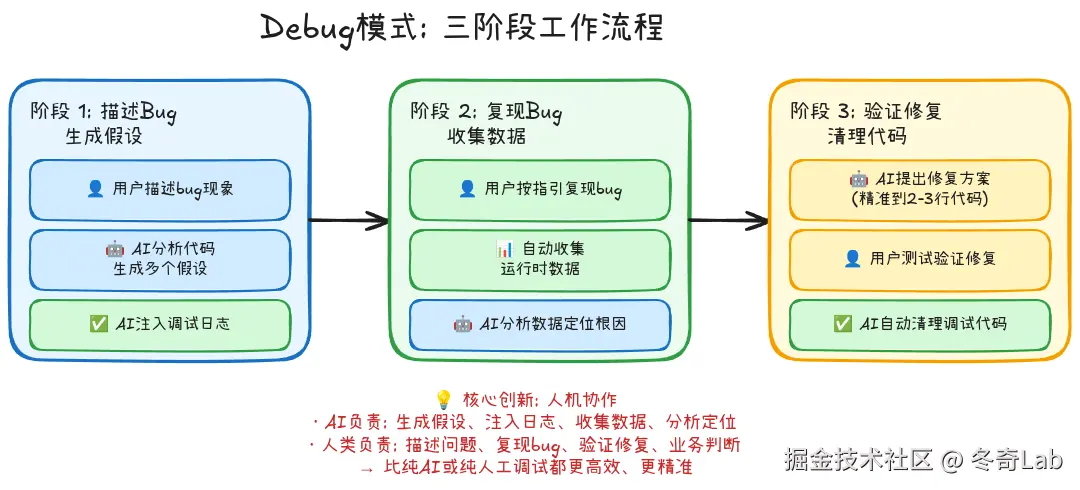
工作原理:三个阶段的人机协作
根据Cursor官方说明,Debug模式采用人机协作的工作流:
阶段1:描述Bug + AI生成假设
markdown
你的描述: "用户在支付页面点击'立即支付'后,
偶尔会卡住不跳转,但大部分时候正常"
AI的分析:
生成3个假设:
1. 支付API调用超时,未正确处理
2. 前端状态更新时机问题,按钮重复点击
3. 支付成功回调丢失,导致页面未跳转
计划插入日志的位置:
- 按钮点击事件
- API调用前后
- 状态更新时机
- 支付回调接收
- 页面路由跳转阶段2:复现Bug + 收集运行时数据
markdown
AI: "我已经注入了调试代码,请执行以下操作来复现bug:
1. 打开支付页面
2. 点击'立即支付'按钮
3. 如果卡住,不要刷新页面,等待10秒
4. 告诉我是否复现了问题"
你的操作: (按照指引复现)
AI收集到的数据:
[DEBUG] 按钮点击 → timestamp: 1234567890
[DEBUG] API调用开始 → orderId: ABC123
[DEBUG] API等待中 → elapsed: 5000ms
[DEBUG] API等待中 → elapsed: 10000ms
[DEBUG] API超时 → error: Request timeout
[ERROR] 未进入错误处理分支 ← 🔴 问题定位!阶段3:AI提出修复 + 人工验证
markdown
AI分析:
根因: API超时后,错误没有被catch,导致后续逻辑未执行
修复方案:
在 src/app/checkout/page.tsx:145 添加超时处理
修复代码:
try {
const result = await paymentAPI.create(orderData);
// ...
} catch (error) {
if (error.code === 'TIMEOUT') {
+ showErrorToast('支付请求超时,请重试');
+ setPaymentStatus('idle'); // 重置按钮状态
}
throw error;
}
你验证:
- 测试超时场景 → 正确显示错误提示
- 测试正常支付 → 功能正常
- 确认修复 → AI清理所有调试代码杀手级场景:传统方式无法解决的问题
场景1:间歇性Bug(概率性问题)
问题: "用户偶尔会遇到支付失败,但服务端日志显示成功"
传统方式的困境:
- 无法稳定复现
- 现有日志不够详细
- 怀疑是网络问题,但无法证明
Debug模式的解决:
markdown
Prompt: "支付流程偶尔失败,但服务端日志显示支付成功,
可能是前端未正确接收回调"
Debug模式的操作:
1. AI在支付链路的10个关键点注入日志:
- 支付API调用
- WebSocket连接状态
- 支付回调接收
- 本地状态更新
- 页面跳转触发
2. 等待用户触发(可能需要测试多次)
3. 收集到的异常数据:
[INFO] 支付API调用成功 → orderId: XYZ
[INFO] 等待支付回调...
[INFO] WebSocket消息接收 → type: payment_success
[ERROR] JSON解析失败 → 回调格式错误 ← 🔴 根因!
4. 定位问题:
服务端升级后,回调JSON格式变了,
前端解析代码未更新,导致数据丢失
5. 精准修复:
更新 src/lib/paymentSocket.ts:67
的JSON解析逻辑,兼容新旧格式场景2:性能问题定位
问题: "首页加载很慢,不知道瓶颈在哪"
Debug模式的Prompt:
markdown
"首页加载耗时超过5秒,
帮我定位性能瓶颈并注入性能监控"AI的操作:
javascript
// AI自动注入性能监控代码
console.time('API:获取商品列表');
const products = await fetchProducts();
console.timeEnd('API:获取商品列表'); // 3500ms ← 瓶颈!
console.time('图片懒加载初始化');
initLazyLoad();
console.timeEnd('图片懒加载初始化'); // 50ms
console.time('首屏渲染');
render(<HomePage products={products} />);
console.timeEnd('首屏渲染'); // 200ms定位结果: 商品列表API耗时3.5秒(一次性查询1000条)
AI建议: 改为分页加载,首屏只加载20条
场景3:状态管理问题
问题: "购物车数量显示不对,加了3件商品显示2件"
完整调试案例:
markdown
Step 1: 启动Debug模式
Prompt: "购物车数量显示错误,实际添加的数量和显示的对不上"
Step 2: AI注入日志
AI在以下位置插入日志:
- 添加商品按钮onClick
- Redux action dispatch
- Reducer计算逻辑
- Store state更新
- 组件useSelector读取
- 组件渲染
Step 3: 复现问题
操作: 连续添加3次商品A
收集到的运行时数据:
[DEBUG] 点击添加 → productId: A, quantity: 1
[DEBUG] Dispatch action → {type: 'ADD_ITEM', id: 'A', qty: 1}
[DEBUG] Reducer计算 → 当前总数: 1 ✅
[DEBUG] 点击添加 → productId: A, quantity: 1
[DEBUG] Dispatch action → {type: 'ADD_ITEM', id: 'A', qty: 1}
[DEBUG] Reducer计算 → 当前总数: 2 ✅
[DEBUG] 点击添加 → productId: A, quantity: 1
[DEBUG] Dispatch action → {type: 'ADD_ITEM', id: 'A', qty: 1}
[DEBUG] Reducer计算 → 当前总数: 3 ✅
[DEBUG] Store更新 → state.cart.total: 3 ✅
[DEBUG] 组件useSelector → 读取到 total: 2 ❌ 问题在这!
[DEBUG] 组件渲染 → 显示: 2
Step 4: AI分析根因
问题: useSelector使用了错误的selector函数
// 错误的代码
const total = useSelector(state =>
state.cart.items.length // ❌ 获取的是商品种类数,不是总数量
);
// 应该改为
const total = useSelector(state =>
state.cart.total // ✅ 正确的总数量字段
);
Step 5: 修复验证
AI修复代码 → 重新测试 → 显示正确 → 清理调试代码Debug模式的限制和最佳实践
使用前提:
- ✅ 项目可以运行(需要实际执行代码)
- ✅ 在开发环境使用(避免影响生产)
- ✅ 有复现步骤(即使是低概率)
注意事项:
- ⚠️ AI注入的日志可能影响性能,调试完记得清理
- ⚠️ 敏感数据(密码/token)注意脱敏
- ⚠️ 某些实时性要求高的代码谨慎使用
最佳实践:
- 描述要详细: 提供尽可能多的现象和上下文
- 配合复现: 按AI的指引精确复现问题
- 及时反馈: AI问你问题时,快速回答帮助定位
- 验证要充分: 修复后多测试几个场景
- 清理要彻底: 确认AI已移除所有调试代码
**Debug模式的哲学**: 不是让AI完全自主地修Bug,而是"AI负责机械性的日志插入和数据收集,你负责提供人类判断和业务知识"。这种人机协作比纯AI或纯人工都更高效。
模式组合:1+1>2的协同效应
掌握单个模式只是开始,真正的高手懂得组合使用。
经典组合套路
组合1: Ask → Plan → Agent (大型需求标准流程)
markdown
适用: 复杂功能开发、架构重构
完整流程:
Day 1:
1. Ask模式: 了解现有架构和技术栈
"现有的用户权限是怎么实现的?"
2. Ask模式: 研究类似功能的实现
"项目中有没有类似的RBAC实现可以参考?"
3. 自己思考: 确定技术方案
- 决定用RBAC模型
- 角色和权限的粒度设计
Day 2:
4. Plan模式: 生成详细实施计划
"为项目添加完整的RBAC权限系统,
包括角色管理、权限配置、前端鉴权组件"
5. 审核计划: 确认方案可行性,修改细节
6. 批准执行: 分3个阶段逐步实施
Day 3:
7. Agent执行: 按计划自动化开发
8. 发现Bug: 权限判断逻辑有问题
9. Debug模式: 精准定位修复组合2: Agent → Debug (快速开发 + 问题修复)
markdown
适用: 迭代开发、快速原型
流程:
1. Agent模式: 快速实现功能
"实现商品详情页,包括图片轮播、
规格选择、加入购物车"
2. 本地测试: 发现加购后数量不对
3. Debug模式: 定位是状态同步问题
4. Agent模式: 修复状态同步逻辑
5. 再次测试: 功能正常组合3: Ask → Agent → Ask (学习型开发)
makefile
适用: 学习新技术栈、实现陌生功能
流程:
1. Ask: "这个项目的表单验证是怎么做的?"
→ 了解使用了react-hook-form + zod
2. Ask: "能给我讲解一下zod schema的写法吗?"
→ AI讲解zod的基础用法
3. Agent: "参考现有的LoginForm,
实现一个用户注册表单,验证规则..."
→ AI生成代码
4. Ask: "为什么要用zodResolver而不是直接validate?"
→ 理解技术选型原因
5. Ask: "这样写有什么性能问题吗?"
→ 深入理解实现细节实战案例:添加用户权限系统
任务: 为SaaS平台添加完整的用户权限管理系统
3天实施流程:
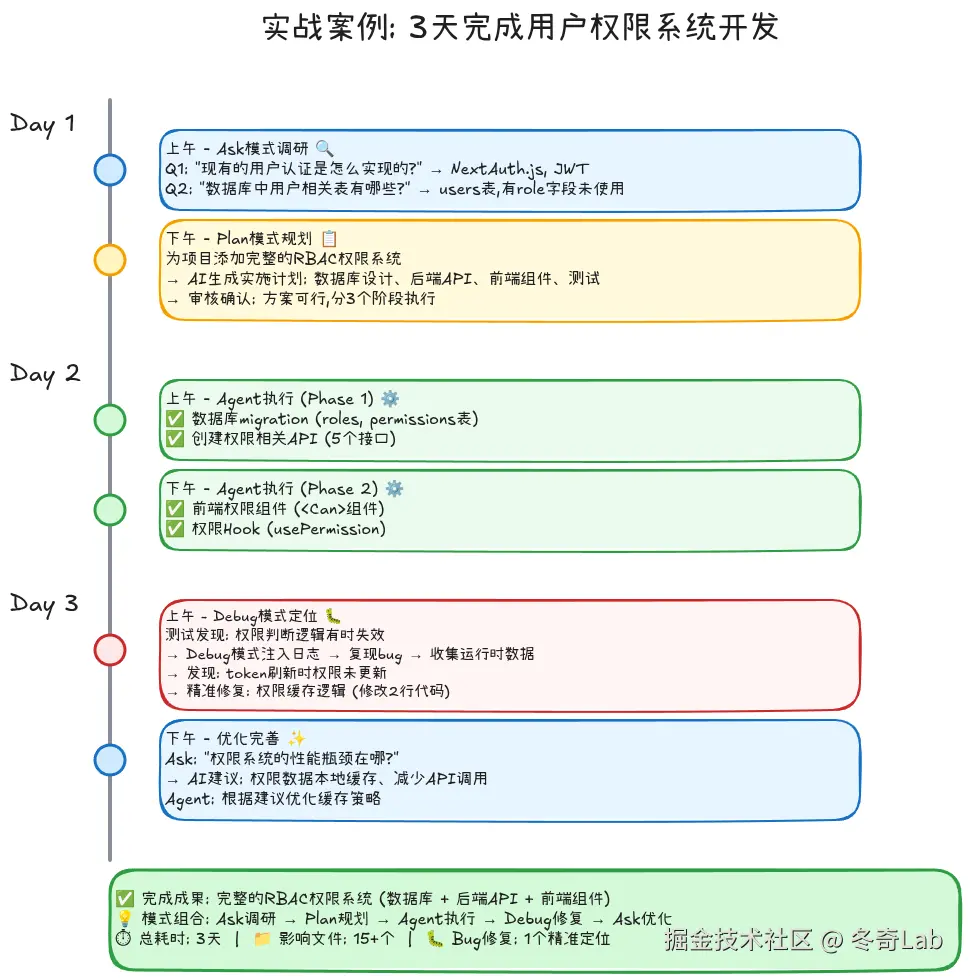
模式切换的黄金法则
法则1: 由慢到快,逐步升级
makefile
新项目: Ask探索 → Plan规划 → Agent执行
熟悉项目: Plan规划 → Agent执行
非常熟悉: Agent直接执行法则2: 按权限级别升级
scss
不确定 → Ask(只读,安全)
确定方案 → Plan(可控执行)
完全确定 → Agent(自主执行)法则3: 出问题就降级
rust
Agent改乱了 → 回退Plan,重新规划
Plan方案不对 → 回到Ask,深入理解
Debug定位不到 → 用Ask理解代码逻辑**高手的判断标准**: - 需求清晰度 < 70% → Ask模式 - 影响文件 > 10个 → Plan模式 - 遇到复杂Bug → Debug模式 - 其他情况 → Agent模式
避坑指南和最佳实践
4个常见错误及解决方案
错误1: 需求不明确就用Agent
markdown
❌ 错误做法:
Prompt: "帮我优化一下首页性能"
→ 你自己都不知道优化什么,AI更瞎猜
→ Agent可能改了一堆无关代码
✅ 正确做法:
1. 先用Debug模式分析性能瓶颈
2. 明确优化目标(如:首屏加载从5s降到2s)
3. 用Agent执行具体优化措施错误2: 小改动也用Plan模式
diff
❌ 错误做法:
改个按钮颜色也要生成计划
→ 计划本身比改代码还费时间
✅ 正确做法:
小改动直接用:
- 单行改动: 光标停留,Cmd+K内联编辑
- 几行改动: Agent模式快速修改
- 大批量改动: 才需要Plan规划错误3: Bug调试不用Debug模式
markdown
❌ 错误做法:
凭感觉瞎改,浪费大量时间
手动加console.log,改完忘记删
✅ 正确做法:
复杂Bug优先用Debug模式:
1. AI自动注入日志(不会忘记删)
2. 数据驱动分析(不靠猜)
3. 精准修复(不乱改)错误4: 盲目信任Agent输出
markdown
❌ 错误做法:
Agent改完不检查就git commit
→ 潜在bug进入代码库
✅ 正确做法:
Agent完成后必须:
1. Review改动(git diff查看所有修改)
2. 运行测试(npm test)
3. 本地验证功能
4. 再提交代码3个提升效率的黄金法则
法则1: 模式选择优先级
makefile
遇到任务时的思考顺序:
1️⃣ 这是Bug吗?
是 → Debug模式
2️⃣ 需求明确吗?
否 → Ask模式探索
3️⃣ 影响范围大吗(>10个文件)?
是 → Plan模式规划
4️⃣ 以上都不是?
→ Agent模式执行法则2: 善用模式组合
makefile
不要孤立使用单个模式:
单一模式(低效):
Agent模式 → 改乱了 → 手动修复 → 浪费时间
组合模式(高效):
Ask理解 → Plan规划 → Agent执行 → Debug修复法则3: 建立个人workflow模板
markdown
在.cursorrules中定义你的标准流程:
# 新功能开发标准流程
1. Ask模式: 理解现有架构
2. 自己设计: 技术方案和接口
3. Plan模式: 生成实施计划
4. Agent模式: 分阶段执行
5. Debug模式: 修复发现的问题
6. Ask模式: 代码review和优化建议
# 紧急Bug修复流程
1. Debug模式: 快速定位根因
2. Agent模式: 精准修复
3. Ask模式: 询问类似问题预防措施团队协作建议
如果团队使用Cursor,建议:
- 制定模式使用规范
markdown
团队约定:
- 修改>5个文件必须用Plan模式
- Bug修复优先用Debug模式
- 新人必须用Ask模式学习代码
- Agent修改必须有人review- 共享.cursorrules
bash
# 团队统一的规则文件
.cursorrules → 放在项目根目录,git提交
每个人都遵循统一的AI行为规范- 建立最佳实践库
markdown
记录团队的成功案例:
- 哪些场景用哪个模式效果好
- 常见问题的标准Prompt
- 踩过的坑和解决方案总结:模式的艺术
5个关键收获
-
4种模式 = 4种武器,场景决定选择
- Agent: 自主执行,效率最高但风险也高
- Ask: 只读探索,安全第一
- Plan: 先规划后执行,大需求必备
- Debug: 数据驱动,Bug克星
-
权限级别是核心概念
- 高权限(Agent/Debug): 确定性高时使用
- 中权限(Plan): 需要把控时使用
- 低权限(Ask): 不确定时使用
-
模式组合威力无穷
- Ask→Plan→Agent: 标准开发流程
- Agent→Debug: 快速迭代流程
- Ask→Agent→Ask: 学习型开发
-
错误使用的代价很高
- 用错模式浪费时间
- Agent瞎改代码造成bug
- 不用Debug盲目调试
-
掌握切换时机是关键
- 由慢到快逐步升级
- 出问题及时降级
- 根据熟悉度灵活调整
立即行动
- 回顾最近的Cursor使用,找出3次用错模式的情况
- 尝试用Debug模式解决一个困扰你的Bug
- 下次大需求开发,先用Plan模式规划
- 在.cursorrules中定义你的个人workflow
检查清单
在使用Cursor前,快速自检:
yaml
□ 这是Bug吗? → Yes: Debug模式
□ 需求清晰吗? → No: Ask模式探索
□ 影响>10个文件? → Yes: Plan模式
□ 核心业务逻辑? → Yes: 谨慎使用Agent
□ 有测试覆盖吗? → No: 先写测试再改代码
□ 改完会Review吗? → 必须Review!相关资源
系列文章
感谢阅读!如果这篇文章对你有帮助,欢迎点赞、收藏、分享。我们下期见!👋
有问题欢迎在评论区讨论,我会尽量回复每一条评论。