文章目录
- 每日一句正能量
- [第6章 Kafka分布式发布订阅消息系统](#第6章 Kafka分布式发布订阅消息系统)
- 章节概要
- [6.2 Kafka工作原理](#6.2 Kafka工作原理)
-
- [6.2.1 Kafka核心组件介绍](#6.2.1 Kafka核心组件介绍)
- [6.2.2 Kafka工作流程分析](#6.2.2 Kafka工作流程分析)

每日一句正能量
每个人都有他的路,每条路都是正确的。人的不幸在于他们不想走自己那条路,总想走别人的路。
第6章 Kafka分布式发布订阅消息系统
章节概要
Kafka是一个高吞吐量的分布式发布订阅消息系统,它在实时计算系统中有着非常强大的功能。通常情况下,我们使用Kafka构建系统或应用程序之间的数据管道,用来转换或响应实时数据,使数据能够及时的进行业务计算,得出相应结果。本章将针对Kafka工作原理、Kafka集群部署以及Kafka的基本操作进行详细讲解。
6.2 Kafka工作原理
6.2.1 Kafka核心组件介绍
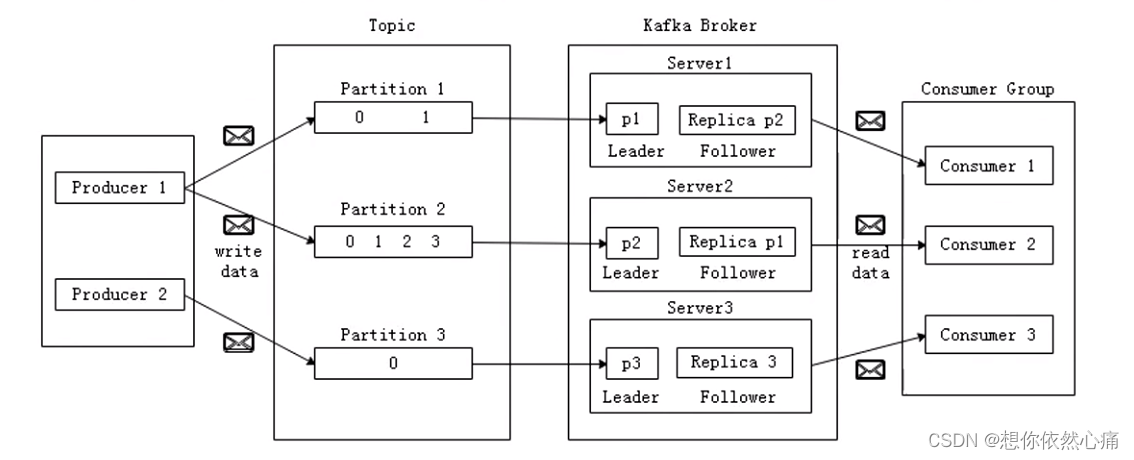
在深入学习Kafka之前,有必要先了解Kafka系统的核心组件,图展示了Kafka的组件结构及各组件之间的关系。
| 组件名称 | 相关说明 |
|---|---|
| Topic (主题) | 特定类别的消息流称为主题,数据存储在主题中,主题被拆分成分区 |
| Partition (分区) | 主题的数据分割为一个或多个分区,每个分区的数据使用多个segment文件存储,分区中的数据是有序的 |
| Offset (偏移量) | 每个分区消息具有的唯一序列标识 |
| Replica (副本) | 副本只是一个分区的备份,它们用于防止数据丢失 |
| Producer (生产者) | 生产者即数据的发布者,该角色将消息发布到Kafka集群的主题中 |
| Consumer (消费者) | 消费者可以从Broker中读取数据,消费者可以消费多个主题数据 |
| Broker (消息代理) | Kafka集群包含一个或多个服务器,每个Kafka服务节点成为Broker, Broker接收到消息后,将消息追加到segment文件中 |
| Leader (领导者) | 负责分区的所有读写操作,每个分区都有一个服务 器充当Leader |
| Follower (追随者) | 跟随领导指令信息,如果Leader发生故障,则选举出一个Follower作为新的Leader |
Kafka集群是由生产者(Producer) 、消息代理服务器(Broker Server)、消费者(Consumer) 组成。发布到Kafka集群的每条消息都有一个主题(Topic) ,可以简单的将主题认作是数据库的数据表名。不在物理意义上可以把主题看作是分区的日志文件,每个分区都是有序的,不可变的记录序列,新的消息会不断地追加到日志中,分区中的每条消息都会按照时间顺序分配一个递增的顺序编号,即图中Partition 1的0、1两个偏移因子,通常被称为偏移量(Offset), 这个偏移 量能够定位当前分区中的每一条消息。 Partition 2中有4个偏移量,Partition 3则有1个偏移量。
分区日志是以分布式的方式存储在Kafka集群上,为了故障容错,每个分区都会以副本的方式复制到其它Broker节点上,如果一个主题的副本数是1,那么Kafka在集群中为每个分区创建1个副本,通过在Zookeeper集群上创建临时节点来实现选举(这是利用了Zookeeper强一致性的特性, 一个节点只能被一个客户端创建成功) ,其中一个分区会作为Leader (如图中的p1或p2或p3),其它副本分区作为Follower。 Leader负责所有客户端的读写操作,Follower负责从它的Leader中同步数据,当Leader发生故障时, Follower就会从该副本分区的Follower角色中选取新的Leader。因为每个分区的副本中只有Leader分区接收读写,所以每个服务端中都会有Leader分区,以及另外一些分区的Follower副本,这样Kafka集群的所有服务端整体.上对客户端是负载均衡的。
Kafka的消费者通过订阅主题来消费消息,并且每个消费者都会设置一个消费组名称(Consumer Group)。由于生产者发布到主题的每一条消息只会发送给一 个消费者, 因此要实现传统消息系统的点对点模式,可以让每个消费者都拥有一个相同的消费组,这样消息就会负载均衡到所有的消费者了;而实现发布订阅模式的话,则每个消费者的消费组名称都不相同,这样每条消息就会广播给所有的消费者了。同一个消费组下有多个消费者互相协调进行消费工作. Kafka会将所有的分区平均分配给所有的消费者实例对象.这样每个消费者都可以分配到平均数量的分区。
6.2.2 Kafka工作流程分析
Kafka的结构含有众多组件,每个组件相互协调工作,其工作流程主要分为生产者生产消息过程和消费者消费消息过程。
- 生产者生产消息过程
生产者向Kafka集群中生产消息,可以通过一张图进行概括,具体如图6-4所示。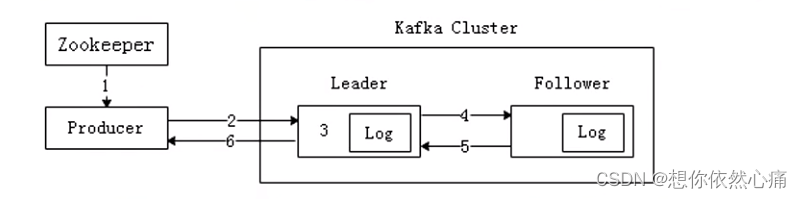
生产者向Kafka集群中生产消息。Producer是消息的生产者,通常情况下,数据消息源可是服务器日志、业务数据及Web服务数据等,生产者采用推送的方式将数据消息发布到Kafka的主题中,主题本质就是一个目录,而主题是由Partition Logs(分区日志)组成,每条消息都被追加到分区中。
从图可以看出,Producer生产 消息流程可以简单分为6步,具体如下:
- Producer先读取Zookeeper的"/brokers/.../state"节点中找到该Partition的Leader。
- Producer将消息发送给Leader。
- Leader负责将消息写入本地分区Log文件中。
- Follower从Leader中读取消息,完成备份操作。
- Follower写入本地Log文件后,会向Leader发送Ack,每次发送消息都会有一个确认反馈机制,以确保消息正常送达。
- Leader收到所有Follower发送的Ack后,向Producer发送Ack,生产消息完成。
Producer是消息的生产者,通常情况下,数据消息源可以是服务器日志、业务数据以及Web服务数据等,生产者采用推送的方式将数据消息发布到Kafka的主题中,主题本质就是一个目录, 而主题是由Partition Logs (分区日志)组成,每条消息都被追加到分区中。
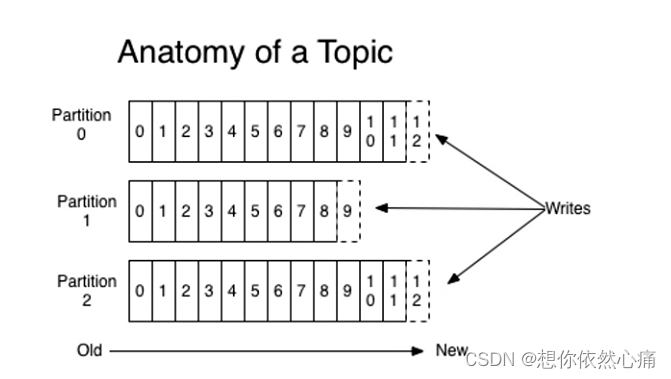
在图中,主题结构有3个分区,每个分区的偏移量都是从开始的,不同分区之间的偏移量都是独立的,不会相互影响,生产的消息会不断地追加到分区日志中,其中每一个消息都被赋予了一个唯一的Offset值, 发布到主题的每条消息都包括键值和时间戳,原始的消息内容和分配的偏移量以及其他一些元数据信息最 后都会存储到分区日志文件中,消息的键也可以不用设置,这种情况下消息会均衡地分布到不同的分区。
最终主题的数据保存在Broker中,-个主题可以有多个分区,在物理节点上,每个分区对应一个文件夹,该文件夹中存储的是当前分区的所有消息和索引文件。Kafka针对每个分区数据可以进行备份操作(在server.properties配置文件中设置default.replication.factor),若没有分区备份,一旦Broker发生故障, 其所有的分区数据都不会被消费。
Kafka分区策略:
Kafka默认的分区策略有三点,其一是如果在发消息的时候指定了分区,则消息发送到指定的分区中,其二是如果没有指定分区,但消息的Key不为空,则基于Key的哈希值来选择一个分区,其三是如果既没有指定分区,且消息的Key值为空,则用轮询的方式选择一个分区。分区不仅可以方便的在集群中扩展,还可以提高并发读取消息的能力。
- 消费者消费消息过程
消息由生产者发布到Kafka集群后,会被消费者消费,消息的消费模型有两种:推送模型(Push) 和拉取模型(Pull)。
基于推送模型的消息系统,是由消息代理记录消费者的消费状态,消息代理将消息数据推送给消费者后,就标记这条消息被消费了,如果此时消费者由于网络抖动或者宕机等原因造成消息数据丢失,那么在数据准确性要求高的业务中,后果是非常严重的。消息发送速率是由Broker决定的,其目标是尽可能以最快的速度传递消息,但这样很容易造成网络阻塞。
Kafka采用拉取模型,由消费者记录消费状态,根据主题、Zookeeper集群地址和要消费消息的偏移量, 每个消费者互相独立地按顺序读取每个分区的消息。
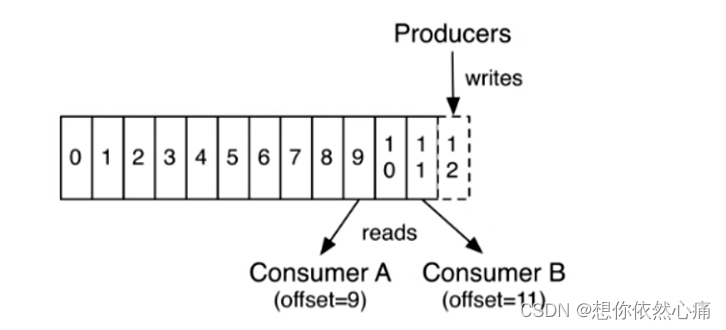
在图中,Consumer A、Consumer B两个消费者读取的是同一个主题的消息,当前状态下,消费者A读取到数据偏移量是9,消费者B读取到数据偏移量是11,生产者正在向偏移量为12的地址写入数据,最新写入的数据如果还没有达到备份数量时,偏移量为12的数据是对消费者不可见的。采用由消费者控制偏移量,这样消费者就可以按照任意的顺序消费信息了,消费者可以重置回之前设置的偏移量,重新处理之前已经消费的消息,或者直接选择最近的消费位置开始消费。
在某些消息系统中,消息代理会在消息被消费之后立即删除消息。如果有不同类型的消费者订阅同一个主题,消息代理可能需要冗余地存储同-消息;或者等所有消费者都消费完才删除,这就需要消息代理跟踪每个消费者的消费状态,这种设计很大程度上限制了消息系统的整体吞吐量和处理延迟。Kafka的设计方法使生产者发布的所有消息都保存在Kafka集群中,不管消息有没有被消费,用户可以通过设置保留时间清理过期的数据,例如,保留策略设置为两天,那么,在消息发布之后,它可以被不同的消费者消费,在两天之后,这条消息就会过期,过期的消息就会被自动清理掉。
Kafka采用拉取模型的消费方式,它可简化消息代理的设计,消费者可自主控制消费消息的速率以及消费方式(批量消费、逐条消费),同时还能选择不同的提交方式从而实现不同的传输语义。
小提示:
拉取模型也有缺点,如果Kafka集群中没有数据,消费者可能会陷入循环中,一直等待消息到达,为了避免这种情况,可以在consumer.properties设置参数,允许消费者请求在等待数据到达的"长轮询"中进行阻塞(并且可选择等待到达给定的字节数,以确保传输数据大小)。
转载自:https://blog.csdn.net/u014727709/article/details/144042829
欢迎 👍点赞✍评论⭐收藏,欢迎指正