Apache Kafka 是一个强大的分布式流处理平台,适用于大规模数据处理和实时分析。它的高吞吐量、低延迟、可扩展性和容错性使其成为现代数据架构中的重要组件。无论是用于消息队列、日志聚合还是流式处理,Kafka 都提供了高效、可靠的解决方案。
一、核心特性
-
高吞吐量:
Kafka 能够处理高吞吐量的数据,支持每秒数百万条消息的读写,适用于大规模数据处理场景。
-
低延迟:
Kafka 的设计确保了低延迟的消息传递,通常在毫秒级别,适合对实时性要求较高的应用。
-
可扩展性:
Kafka 是一个分布式系统,可以轻松扩展到多个服务器,通过增加更多的 broker 来提高系统的处理能力。
-
持久化存储:
Kafka 将消息持久化存储在磁盘上,支持数据的可靠存储和故障恢复。
-
容错性:
Kafka 支持副本机制,确保数据的高可用性和容错性。即使部分节点故障,数据也不会丢失。
-
消息持久化和顺序保证:
Kafka 保证消息在分区内的顺序,并且可以配置消息的持久化策略,确保数据不会因为系统故障而丢失。
二、主要组件
-
Broker:
Kafka 集群由多个 broker 组成,每个 broker 是一个 Kafka 服务器实例,负责存储和管理消息。
-
Topic:
Topic 是 Kafka 中消息的分类,生产者将消息发送到特定的 topic,消费者从 topic 中读取消息。
-
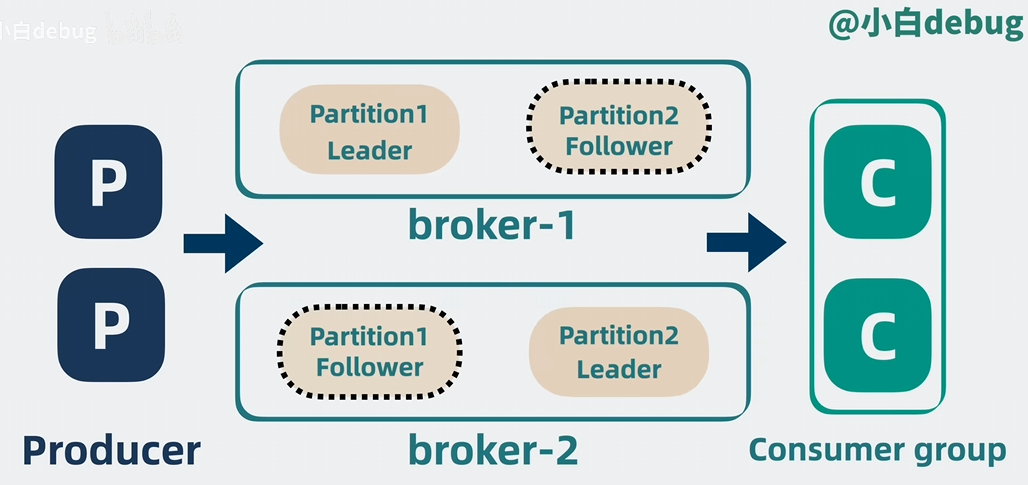
Partition:
为了提高可扩展性,每个 topic 可以被划分为多个分区(Partition),每个分区是一个有序的消息队列。
-
Producer:
生产者是向 Kafka 发送消息的应用程序,负责将数据写入指定的 topic。
-
Consumer:
消费者是从 Kafka 读取消息的应用程序,负责从 topic 中读取数据。
-
Consumer Group:
消费者组是一组消费者实例,它们共同消费一个 topic 的消息,确保每个消息只被组内的一个消费者处理。
三、使用场景
-
消息队列:
Kafka 可以作为高性能的消息队列使用,支持高吞吐量的消息传递和复杂的消费模式。
-
日志聚合:
Kafka 常用于收集和聚合系统日志,将日志数据集中存储和分析。
-
流式处理:
Kafka 与流处理框架(如 Apache Flink、Apache Spark Streaming)集成,支持实时数据处理和分析。
-
事件源:
Kafka 可以作为事件源系统的核心组件,支持事件驱动的架构。
-
微服务通信:
Kafka 用于微服务之间的异步通信,支持服务间的解耦和高可用性。
四、架构
Kafka 的架构基于分布式系统设计,具有以下特点:
-
分布式存储:
消息分布在多个 broker 上,通过分区和副本机制提高系统的可扩展性和容错性。
-
高可用性:
Kafka 支持副本机制,确保数据的高可用性。即使部分 broker 故障,系统仍然可以正常运行。
-
水平扩展:
Kafka 集群可以通过增加更多的 broker 来水平扩展,提高系统的处理能力。
-
消息持久化:
Kafka 将消息持久化存储在磁盘上,支持数据的可靠存储和故障恢复。
五、单元测试
生产
KafkaproducerTest.java
@BeforeEach 注解表示该方法在每个测试方法执行之前都会被调用
@AfterEach 注解表示该方法在每个测试方法执行之后都会被调用。
java
//包声明
package org.javaup;
//导包
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.util.Properties;
public class kafkaproducertest {//类声明
private KafkaProducer<String, String> producer;
@BeforeEach
public void setUp() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.100.128:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
producer = new KafkaProducer<>(props);
}
@AfterEach
public void tearDown() {
producer.close();
}
@Test
public void testSend() {
String topic = "test-topic";
String key = "test-key";
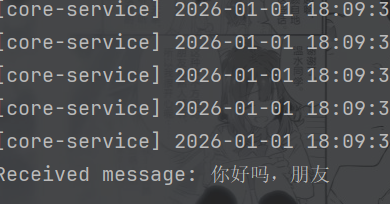
String value = "你好吗,朋友";
producer.send(new ProducerRecord<>(topic, key, value), (metadata, exception) -> {
if (exception == null) {
System.out.println("Message sent successfully: " + metadata.topic() + " " + metadata.partition() + " " + metadata.offset());
} else {
exception.printStackTrace();
}
});
// 等待消息发送完成
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}-
这个方法用于初始化 Kafka 生产者实例:
-
创建一个
Properties对象来存储 Kafka 生产者的配置。 -
设置
BOOTSTRAP_SERVERS_CONFIG,指定 Kafka broker 的地址。 -
设置
KEY_SERIALIZER_CLASS_CONFIG和VALUE_SERIALIZER_CLASS_CONFIG,指定键和值的序列化器。 -
使用这些配置创建一个
KafkaProducer实例。
-
java
@Test
public void testSend() {
String topic = "test-topic";
String key = "test-key";
String value = "你好吗,朋友";
producer.send(new ProducerRecord<>(topic, key, value), (metadata, exception) -> {
if (exception == null) {
System.out.println("Message sent successfully: " + metadata.topic() + " " + metadata.partition() + " " + metadata.offset());
} else {
exception.printStackTrace();
}
});
// 等待消息发送完成
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
@Test注解表示这是一个测试方法。这个方法用于测试 Kafka 生产者发送消息的功能:
定义要发送的消息的主题、键和值。
使用
producer.send方法发送消息,并提供一个回调函数来处理发送结果:
如果消息发送成功,打印成功信息。
如果发送失败,打印异常信息。
使用
Thread.sleep等待一段时间,确保消息发送完成
消费
KafkaconsumerTest.java
java
package org.javaup;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class kafkaconsumer {
private KafkaConsumer<String, String> consumer;
@BeforeEach
public void setUp() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.100.128:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "test-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("test-topic"));
}
@AfterEach
public void tearDown() {
consumer.close();
}
@Test
public void testReceive() {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("Received message: " + record.value());
}
}
}
}结果: